最近DeepSeek-OCR的消息又掀起了一股国产之光的热潮,同样呢,另外一个 OCR,PaddleOCR-VL也不容小觑,直接站在 OCR 领域的顶峰,一览众山小。
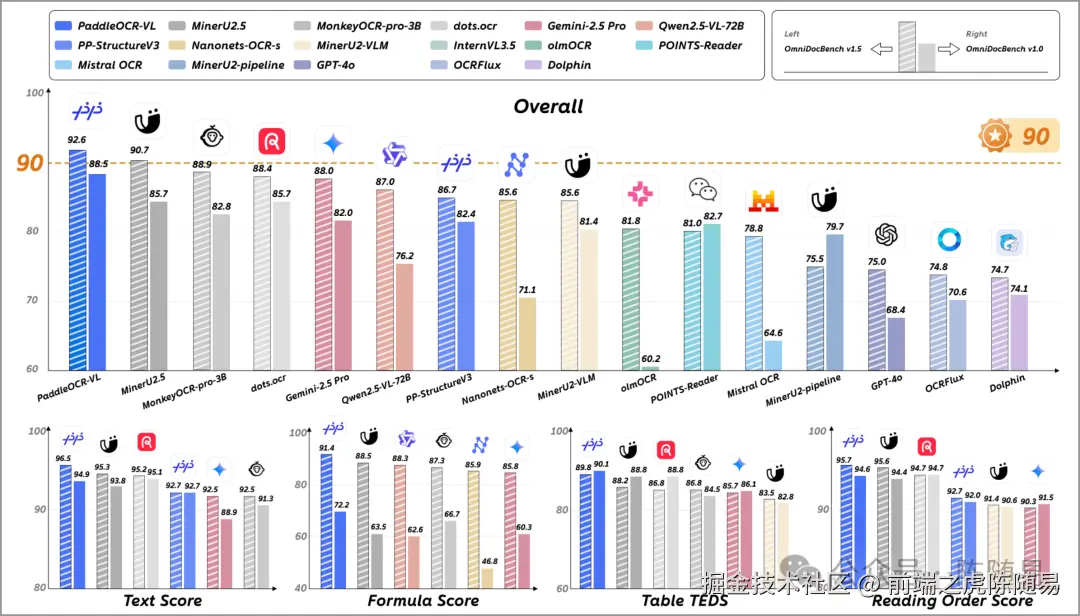

如上图,可以看到,在一众 OCR 技术中,PaddleOCR-VL遥遥领先,但不知道大家发现一个问题没有,里面怎么没有DeepSeek-OCR呢?这是因为,DeepSeek-OCR和PaddleOCR-VL虽然都带了OCR,但两者区别还是挺大的。
DeepSeek-OCR主要是用视觉技术去提取文本,从而极大地降低上下文的 Token 大小,来达到更高的信息利用率,从而达到一次性处理更大的文档,更多的信息。
而PaddleOCR-VL这个OCR,则是我们真正所理解的那个OCR,也就是图文识别,把图片中的信息识别成方便我们编辑的文字或公式等。
一个月三家开源,OCR 领域暗潮涌动
仔细观察就会发现,仅仅一个月内,DeepSeek、百度、上海 AILab 三家公司纷纷发布并开源最新 OCR 模型。10 月 21 日当天,Huggingface 全球模型趋势热榜前三模型全是 OCR 模型:
- 第一名:百度飞桨 PaddleOCR-VL(已持续登顶 5 天)
- 第二名:DeepSeek-OCR
- 第三名:Nanonet OCR
这种集体爆发绝非偶然。各大厂商在 OCR 赛道上的激烈竞争,恰恰说明了文档解析能力在 AI 应用中的战略地位------无论是知识库构建、文档智能处理,还是多模态应用,OCR 都是最基础也最关键的一环。
榜单说话:OmniBenchDoc V1.5 全面 SOTA
PaddleOCR-VL 的强大不是自吹自擂,而是在最新的 OmniBenchDoc V1.5 榜单 中取得了综合性能全球第一 的成绩。更让人惊叹的是,在文档解析的四大核心能力维度上,PaddleOCR-VL 实现了全线 SOTA(State of the Art,业界最佳),刷新了全球 OCR VL 模型的性能天花板。
这不是简单的"参数堆砌"------核心模型参数仅 0.9B,却能在轻量级的前提下实现最高精度,这才是真正的技术突破。
实测表现:不只是识字,更像是"读懂"
下面分享一些PaddleOCR-VL具体的测试案例,来实际体验这个技术的强大和科技的魅力。
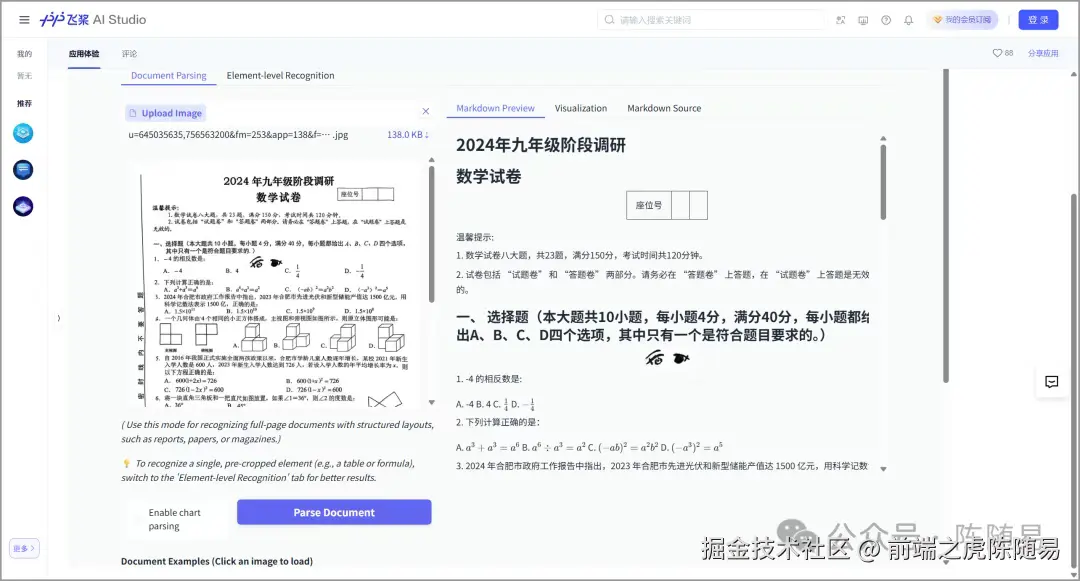
试卷识别:不仅文字准确识别了,公式也不在话下,就连排版也相当还原了。这种能力对于教育数字化意义重大------传统 OCR 往往会把公式识别得支离破碎,而 PaddleOCR-VL 能够理解公式的整体结构。
复杂公式识别:这是 OCR 技术的"珠穆朗玛峰"。分数、根号、积分符号层层嵌套,PaddleOCR-VL 依然能够准确还原,这背后是对数学符号语义的深度理解。
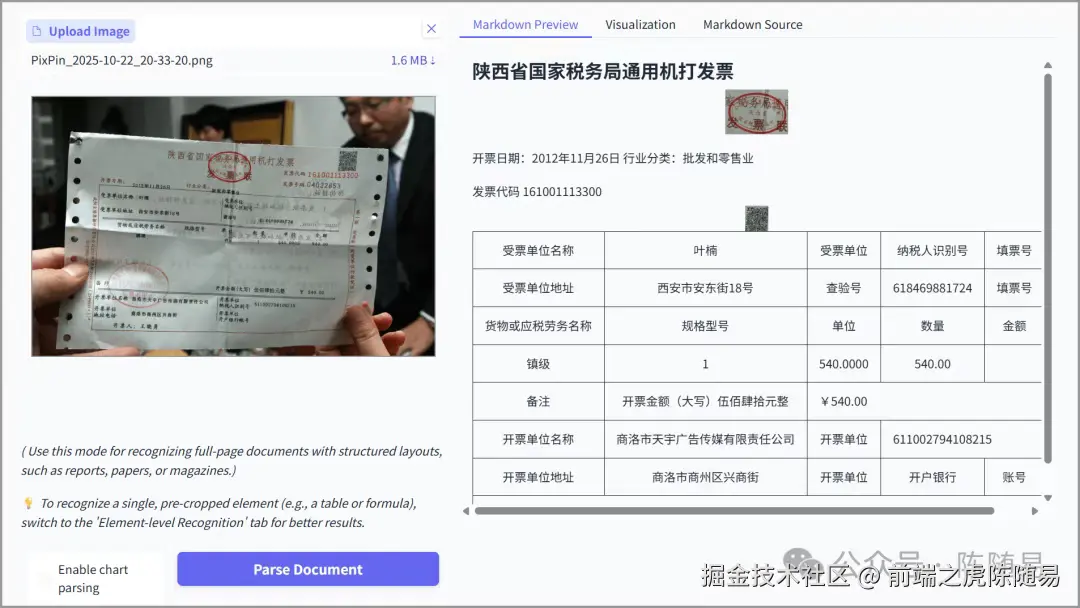
干扰环境下的发票识别:像这种拿在手中,背面字体影响的发票也能正确识别。传统 OCR 遇到背景干扰往往会"抓瞎",而 PaddleOCR-VL 能够区分前景与背景信息。

医生手写处方识别:说实话,这是第一次看懂了医生写的是啥。手写体识别一直是 OCR 领域的老大难问题,尤其是医生的"天书"处方。PaddleOCR-VL 在这方面的突破,对于医疗数字化和用药安全都有重要意义。
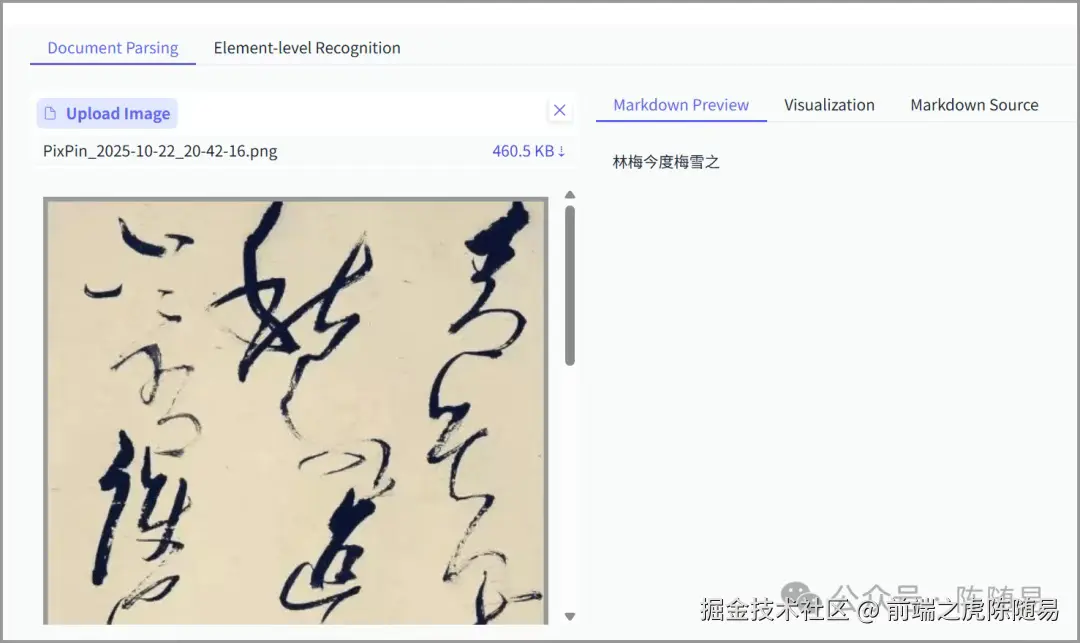
草书识别:这已经不是简单的"字符识别",而是需要理解汉字的书写规律和上下文语义。能做到这一点,说明模型已经具备了一定的"文化理解"能力。
技术深度:轻量但不轻薄
可以看到,PaddleOCR-VL 的能力令人惊叹。其实 OCR 也不是现在才出来的产物,而是发展了很多年了,但 PaddleOCR-VL 在 OCR 领域将其上限又拔高了。
让我们看看一些关键数据:
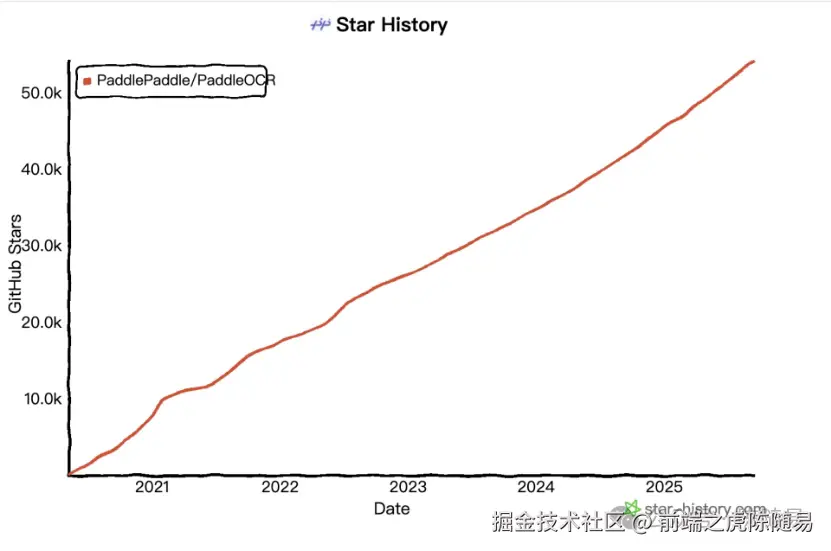
PaddleOCR-VL 模型由百度飞桨 Paddle OCR 团队出品。值得关注的是,PaddleOCR 是 GitHub 社区中唯一一个 Star 数超过 50k 的中国 OCR 项目 。开源已 5 年,累计下载量突破 900 万 ,被超过 5.9k 开源项目直接或间接使用。这个生态影响力,在国内开源项目中确实少见。
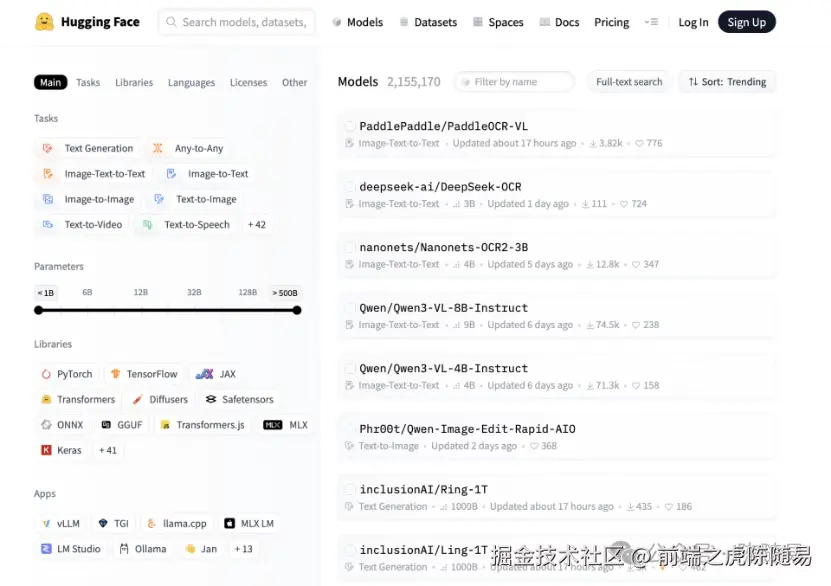
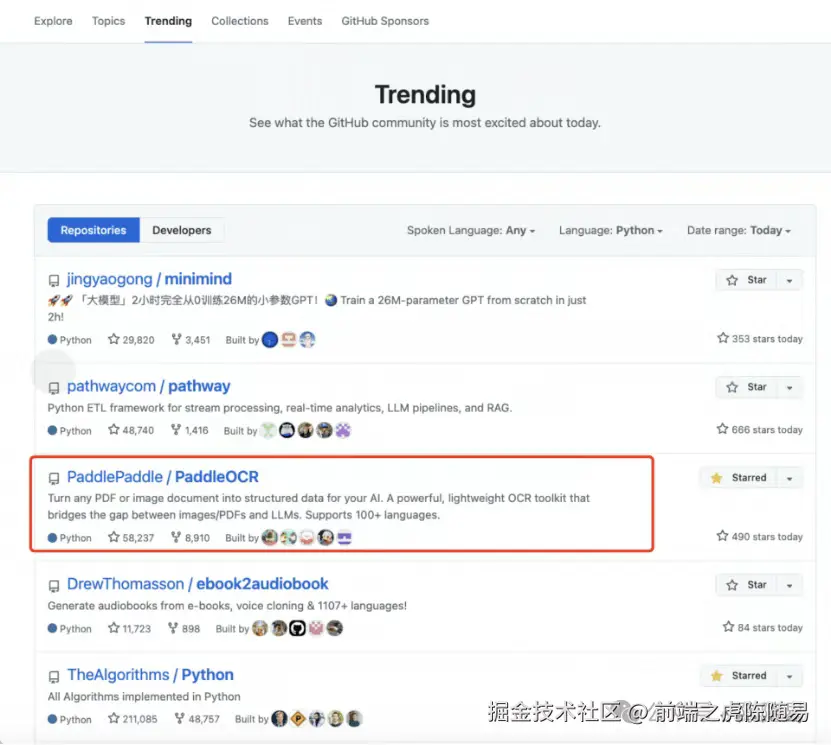
市场反应最能说明问题:PaddleOCR-VL 一经发布,便在 Huggingface Trending、Github Trending、ModelScope Trending 等多个榜单排名前列,并持续登顶 5 天。这种热度不是营销出来的,而是实打实的技术认可。
三个核心突破点
-
轻量高效:参数仅 0.9B,可以在极低计算开销下即可实现高精度识别。这意味着部署成本大幅降低,边缘设备也能跑起来。
-
多语言支持:支持 109 种语言,包括但不限于中文、英语、法语、日语、俄语、阿拉伯语、西班牙语等。这种覆盖面在开源 OCR 模型中并不多见。
-
版面理解 :能够像人一样理解复杂的图文版面。传统 OCR 仅能逐行识别文字,PaddleOCR-VL 能够做到真正
读懂文档结构------这是从"识别"到"理解"的质变。
写在最后
AI 的快速发展,仿佛让我们提前来到了未来世界。而 PaddleOCR-VL 的突破,让这个未来世界更加神奇且魔幻。
从技术指标到实际表现,从开源生态到市场反应,PaddleOCR-VL 在 OCR 领域的领先地位已经确立。更重要的是,它的开源属性让这项技术能够惠及更多开发者和应用场景。
在 AI 大模型扎堆的今天,专注垂直领域的技术突破同样值得关注。毕竟,真正改变我们工作和生活的,往往不是那些参数惊人的大模型,而是这些能够解决实际问题的"小而美"的技术。