一、什么是蓝图?
蓝图不是Flask应用的子集,而是组织应用代码和扩展应用的方式。它允许我们将大型应用拆分为可重用的模块,每个模块专注于特定的业务功能。
AI智能体系统设计相关文章:
👉《04_AI智能体系统设计之工具调用人工干预机制深度解析》
AI智能体开发环境搭建相关文章:
👉《06_AI智能体开发环境搭建之Miniconda零基础安装配置指南》
👉《07_AI智能体开发环境搭建之Poetry安装适用指南,Python开发者告别依赖管理烦恼》
👉《08_AI智能体开发环境搭建之Conda与Poetry的完美整合创建虚拟环境》
👉《09_AI智能体开发环境搭建之Redis安装配置完整指南》
👉《10_AI智能体开发环境搭建之Qdrant向量搜索引擎安装配置全攻略》
👉《11_AI智能体开发环境搭建之VSCode安装配置与效率提升完整指南》
👉《12_AI智能体开发环境搭建之PyCharm社区版安装配置全攻略,打造高效的Python开发环境》
AI智能体开发架构搭建相关文章:
👉《13_AI智能体开发架构搭建之资深开发者的初始化项目实践》
👉《14_AI智能体开发架构搭建之资深开发者的项目依赖管理实践》
👉《15_AI智能体开发架构搭建之生产级架构全局配置管理最佳实践》
👉《17_AI智能体开发架构搭建之Flask集成swagger在线文档实践》
👉《18_AI智能体开发架构搭建之集成DeepSeek-V3与BGE-M3的最佳实践指南》
👉《19_AI智能体开发架构搭建之基于Qdrant构建知识库最佳实践指南》
👉《20_AI智能体开发架构搭建之构建高可用网络爬虫工具最佳实践指南》
更多相关文章内容: 👉《AI智能体从0到企业级项目落地》专栏
配套视频教程👉《AI智能体实战开发教程(从0到企业级项目落地)》共62节(已完结),从零开始,到企业级项目落地,这套课程将为你提供最完整的学习路径。不管你是初学者还是有一定经验的开发者,都能在这里获得实实在在的成长和提升。
二、为什么选择蓝图架构?
2.1 模块化
蓝图允许我们将应用划分为不同的模块,对于大型应用,将所有代码放在一个文件中是不现实的。蓝图允许我们将应用分成多个文件,每个文件对应一个蓝图,这样代码结构更清晰。使得应用更易于维护和管理,特别是在大型应用中。
2.2 可复用性
蓝图定义了一组可以被多个应用复用的操作。如果你有一个通用的功能(比如用户认证、管理员界面等),你可以将其做成一个蓝图,然后在多个应用中复用。
2.3 延迟绑定
蓝图允许我们将应用的路由和其他的操作延迟到应用注册蓝图时再绑定。这意味着我们可以在应用初始化时注册蓝图,从而避免在定义蓝图时需要应用实例。
2.4 URL前缀和子域名
蓝图可以有自己的URL前缀或子域名,这使得我们可以将不同的功能模块放在不同的URL路径下。
2.5 便于团队开发
不同的开发者可以负责不同的蓝图,并行开发,最后整合到一起。
三、蓝图模块化知识库服务
在 app 目录下创建 blueprints 的 python 包,并创建 knowledge.py 文件,编写使用Flask蓝图模块化知识库服务的代码实现
import asyncio
import uuid
import re
from flask import request
from urllib.parse import urlparse
from flask_restx import Namespace, Resource, fields
from langchain.text_splitter import RecursiveCharacterTextSplitter
from app.core import knowledge_base
from app.utils import config, setup_logging, load_documents_from_urls
# 初始化日志配置
logger = setup_logging()
# 创建命名空间
knowledge_ns = Namespace('knowledge', description='知识库管理操作')
# 定义数据模型
document_model = knowledge_ns.model('Document', {
'content': fields.String(required=True, description='文档内容'),
'metadata': fields.Raw(description='元数据', default={}),
'doc_id': fields.String(description='文档ID')
})
url_upload_model = knowledge_ns.model('UrlUpload', {
'urls': fields.List(fields.String, required=True, description='URL列表')
})
upload_response_model = knowledge_ns.model('UploadResponse', {
'success': fields.Boolean(description='操作状态'),
'doc_id': fields.String(description='文档ID'),
'message': fields.String(description='消息'),
'error': fields.String(description='错误信息', default=None),
'details': fields.String(description='错误详情', default=None)
})
search_request_model = knowledge_ns.model('SearchRequest', {
'query': fields.String(required=True, description='搜索查询'),
'top_k': fields.Integer(description='结果数量', default=3),
'score_threshold': fields.Float(description='分数阈值', default=0.7)
})
search_result_model = knowledge_ns.model('SearchResult', {
'id': fields.String(description='文档ID'),
'content': fields.String(description='文档内容'),
'score': fields.Float(description='匹配分数'),
'metadata': fields.Raw(description='元数据')
})
search_response_model = knowledge_ns.model('SearchResponse', {
'success': fields.Boolean(description='操作状态'),
'query': fields.String(description='查询内容'),
'results': fields.List(fields.Nested(search_result_model))
})
knowledge_status_model = knowledge_ns.model('KnowledgeStatus', {
'collection': fields.String(description='集合名称'),
'status': fields.String(description='状态'),
'vectors_count': fields.Integer(description='向量数量'),
'indexed_vectors_count': fields.Integer(description='已索引向量数量'),
'points_count': fields.Integer(description='点数量')
})
@knowledge_ns.route('/upload')
class DocumentUpload(Resource):
@knowledge_ns.doc('upload_document')
@knowledge_ns.expect(document_model)
@knowledge_ns.response(200, '文档上传成功', upload_response_model)
@knowledge_ns.response(400, '无效请求')
@knowledge_ns.response(500, '服务器内部错误')
def post(self):
"""上传文档到知识库"""
try:
data = request.json
content = data.get('content')
metadata = data.get('metadata', {})
doc_id = data.get('doc_id')
if not content:
return {
"success": False,
"error": "缺少必填字段: content"
}, 400
# 生成文档ID
base_doc_id = doc_id or str(uuid.uuid4())
# 从配置获取文本分割参数
chunk_size = getattr(config, 'DOCUMENT_CHUNK_SIZE', 1000)
chunk_overlap = getattr(config, 'DOCUMENT_CHUNK_OVERLAP', 200)
# 创建文本分割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ".", "?", "!", ";"]
)
# 清理多余空白
cleaned_content = re.sub(r'\s+', ' ', content).strip()
# 分割文本
documents = splitter.create_documents([cleaned_content])
chunks = [doc.page_content for doc in documents]
# 如果只有一个块,直接添加整个文档
if len(chunks) == 1:
document = {
"id": base_doc_id,
"content": chunks[0],
"metadata": metadata
}
# 添加到知识库
knowledge_base.add_document_sync(document)
return {
"success": True,
"doc_id": base_doc_id,
"message": "文档已添加到知识库",
"chunks_count": 1
}
# 为每个块创建文档并添加到知识库
processed_count = 0
chunk_ids = []
for idx, chunk in enumerate(chunks):
# 生成块ID
chunk_id = f"{base_doc_id}_chunk_{idx}"
chunk_ids.append(chunk_id)
# 创建块文档对象
chunk_doc = {
"id": chunk_id,
"content": chunk,
"metadata": {
**metadata,
"document_id": base_doc_id,
"chunk_index": idx,
"total_chunks": len(chunks)
}
}
# 添加到知识库
knowledge_base.add_document_sync(chunk_doc)
processed_count += 1
logger.info(f"文档分割处理完成: 原文档ID={base_doc_id}, 分割为{len(chunks)}个块, 成功添加{processed_count}个块")
return {
"success": True,
"doc_id": base_doc_id,
"chunk_ids": chunk_ids,
"chunks_count": len(chunks),
"message": f"文档已分割为{len(chunks)}个片段并添加到知识库"
}
except Exception as e:
logger.exception(f"文档上传失败: {str(e)}")
return {
"success": False,
"error": "服务器内部错误"
}, 500
@knowledge_ns.route('/upload_from_urls')
class UrlUpload(Resource):
@knowledge_ns.doc('upload_from_urls')
@knowledge_ns.expect(url_upload_model)
@knowledge_ns.response(200, 'URL文档上传成功', upload_response_model)
@knowledge_ns.response(400, '无效请求')
@knowledge_ns.response(500, '服务器内部错误')
def post(self):
"""从URL列表加载文档并添加到知识库"""
try:
data = request.json
urls = data.get('urls', [])
if not urls:
return {
"success": False,
"error": "URL列表不能为空"
}, 400
# 安全过滤URL(仅允许http/https协议)
filtered_urls = []
for url in urls:
# 确保URL是字符串
url_str = str(url).strip()
if not url_str:
continue
parsed = urlparse(url_str)
if parsed.scheme not in ['http', 'https']:
logger.warning(f"跳过非HTTP(S)协议URL: {url_str}")
continue
filtered_urls.append(url_str)
if not filtered_urls:
return {
"success": False,
"error": "没有有效的URL可处理"
}, 400
# 调用异步函数加载并分割文档
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
results = loop.run_until_complete(
load_documents_from_urls(urls=filtered_urls)
)
# 添加到知识库(同步方式)
processed_count = 0
for doc in results:
try:
knowledge_base.add_document_sync(doc)
processed_count += 1
except Exception as e:
logger.error(f"添加文档失败 (ID: {doc.get('id', 'unknown')}): {str(e)}")
return {
"success": True,
"total_urls": len(filtered_urls),
"processed_chunks": processed_count,
"message": f"成功处理 {len(results)} 个文档片段"
}
finally:
loop.close()
except Exception as e:
logger.exception(f"URL文档处理失败: {str(e)}")
return {
"success": False,
"error": "服务器内部错误"
}, 500
@knowledge_ns.route('/search')
class KnowledgeSearch(Resource):
@knowledge_ns.doc('search_knowledge')
@knowledge_ns.expect(search_request_model)
@knowledge_ns.response(200, '搜索成功', search_response_model)
@knowledge_ns.response(400, '无效请求')
@knowledge_ns.response(500, '服务器内部错误')
def post(self):
"""在知识库中搜索"""
try:
data = request.json
query = data.get('query')
top_k = data.get('top_k', config.TOP_K)
score_threshold = data.get('score_threshold', config.SCORE_THRESHOLD)
if not query or not isinstance(query, str):
return {
"success": False,
"error": "缺少或无效的查询参数"
}, 400
# 执行搜索
results = knowledge_base.retrieve_sync(
query=query,
top_k=top_k,
score_threshold=score_threshold
)
# 转换为字典
results_data = [result.dict() for result in results]
return {
"success": True,
"query": query,
"results": results_data
}
except Exception as e:
logger.exception(f"知识库搜索失败: {str(e)}")
return {
"success": False,
"error": "服务器内部错误"
}, 500
@knowledge_ns.route('/status')
class KnowledgeStatus(Resource):
@knowledge_ns.doc('knowledge_status')
@knowledge_ns.response(200, '成功获取知识库状态', knowledge_status_model)
@knowledge_ns.response(500, '服务器内部错误')
def get(self):
"""获取知识库状态"""
try:
# 获取集合信息
collection_info = knowledge_base.client.get_collection(
knowledge_base.collection_name
)
return {
"collection": knowledge_base.collection_name,
"status": "active",
"vectors_count": collection_info.vectors_count,
"indexed_vectors_count": collection_info.indexed_vectors_count,
"points_count": collection_info.points_count
}
except Exception as e:
logger.exception(f"获取知识库状态失败: {str(e)}")
return {
"success": False,
"error": "服务器内部错误"
}, 500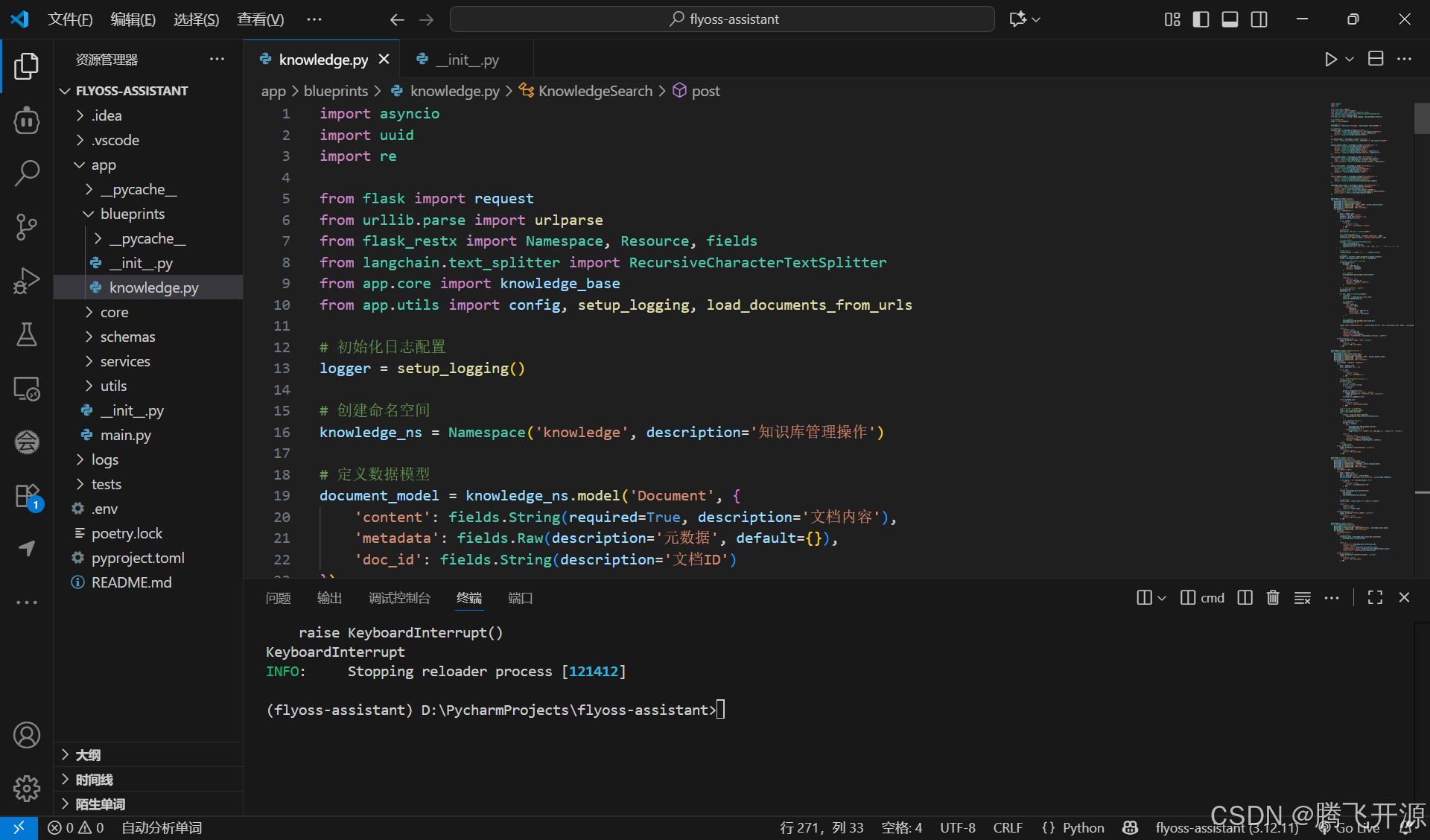
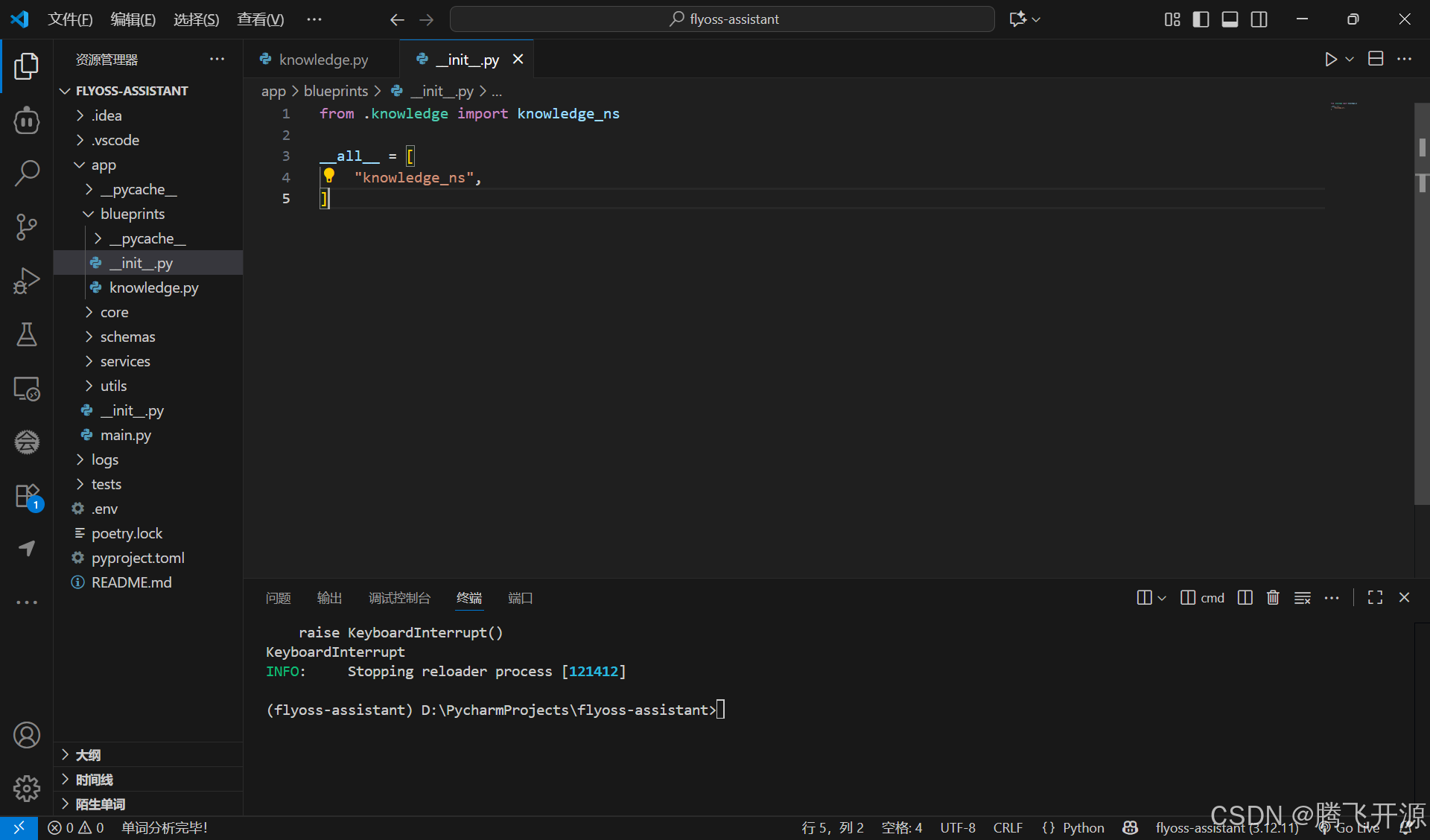
在 app 目录下 blueprints 包创建 init.py 文件,导入知识库服务
from .knowledge import knowledge_ns
__all__ = [
"knowledge_ns",
]
在 app 目录下的 init.py 文件注册知识库服务蓝图模块的命名空间
from app.blueprints import knowledge_ns
# 使用装饰器注册API根路由
@api.route('/api', endpoint='api_root')
class ApiRootResource(Resource):
@api.doc('api_root')
@api.response(200, 'API状态信息')
def get(self):
"""API根端点"""
return {
"api_version": "1.0",
"endpoints": {
"knowledge": "/knowledge",
"documentation": "/docs"
}
}
# 注册命名空间
api.add_namespace(knowledge_ns, path='/knowledge')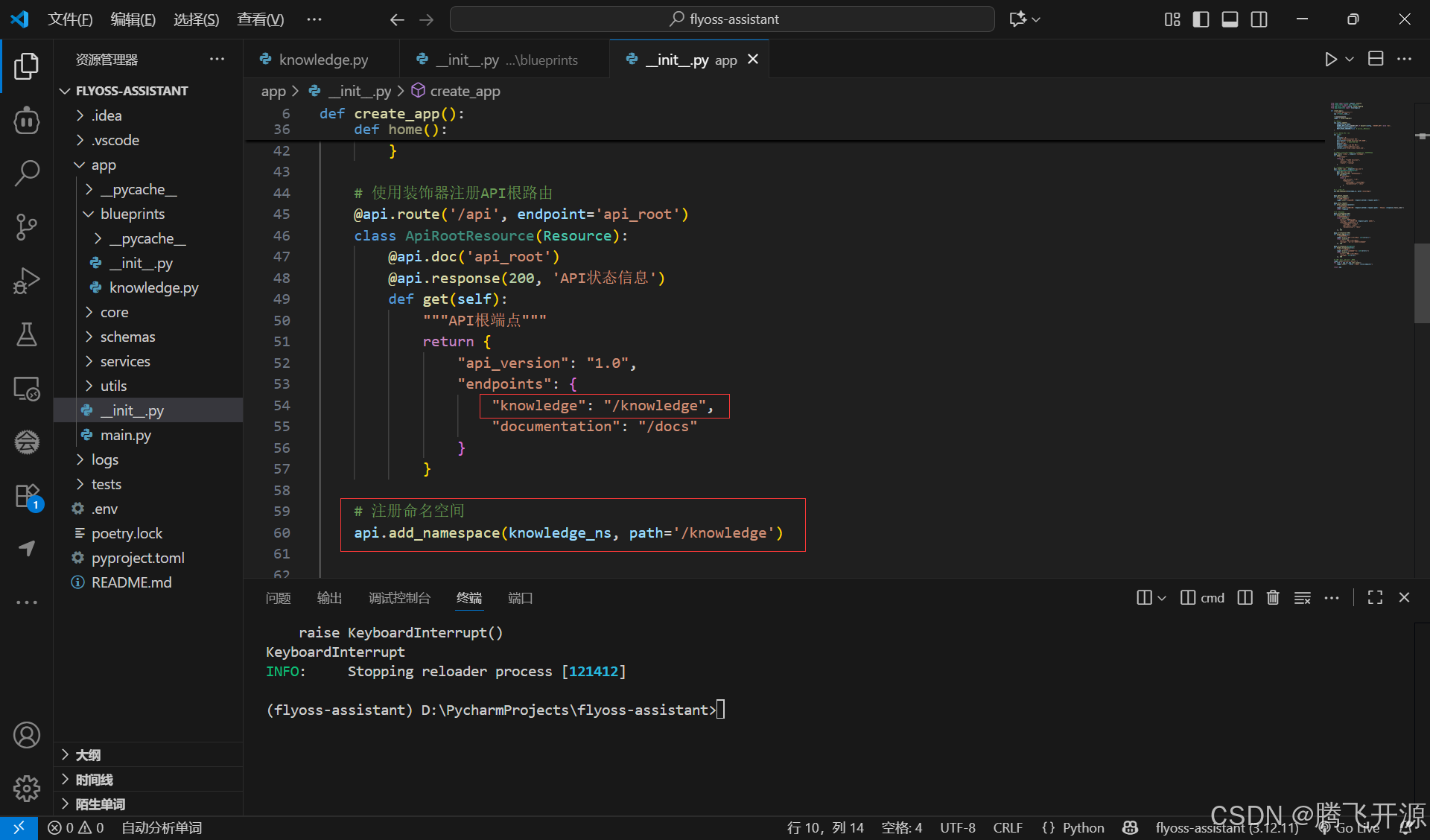
四、使用 swagger 在线文档测试
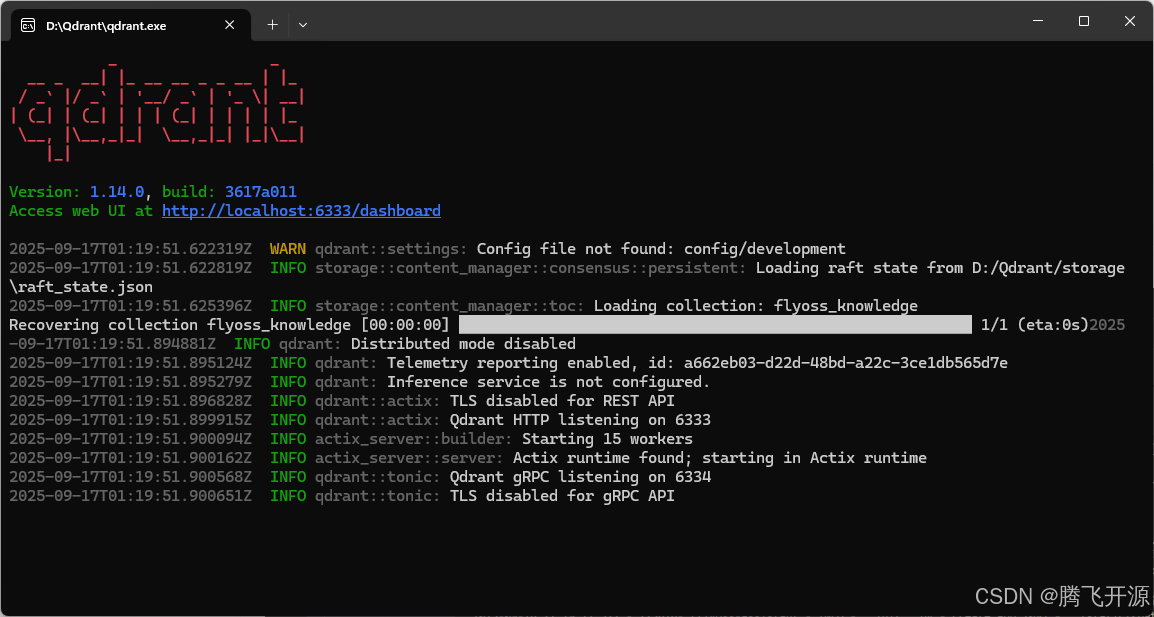
启动Qdrant向量数据库
启动项目
poetry run uvicorn app.main:app --reload --host 0.0.0.0 --port 8000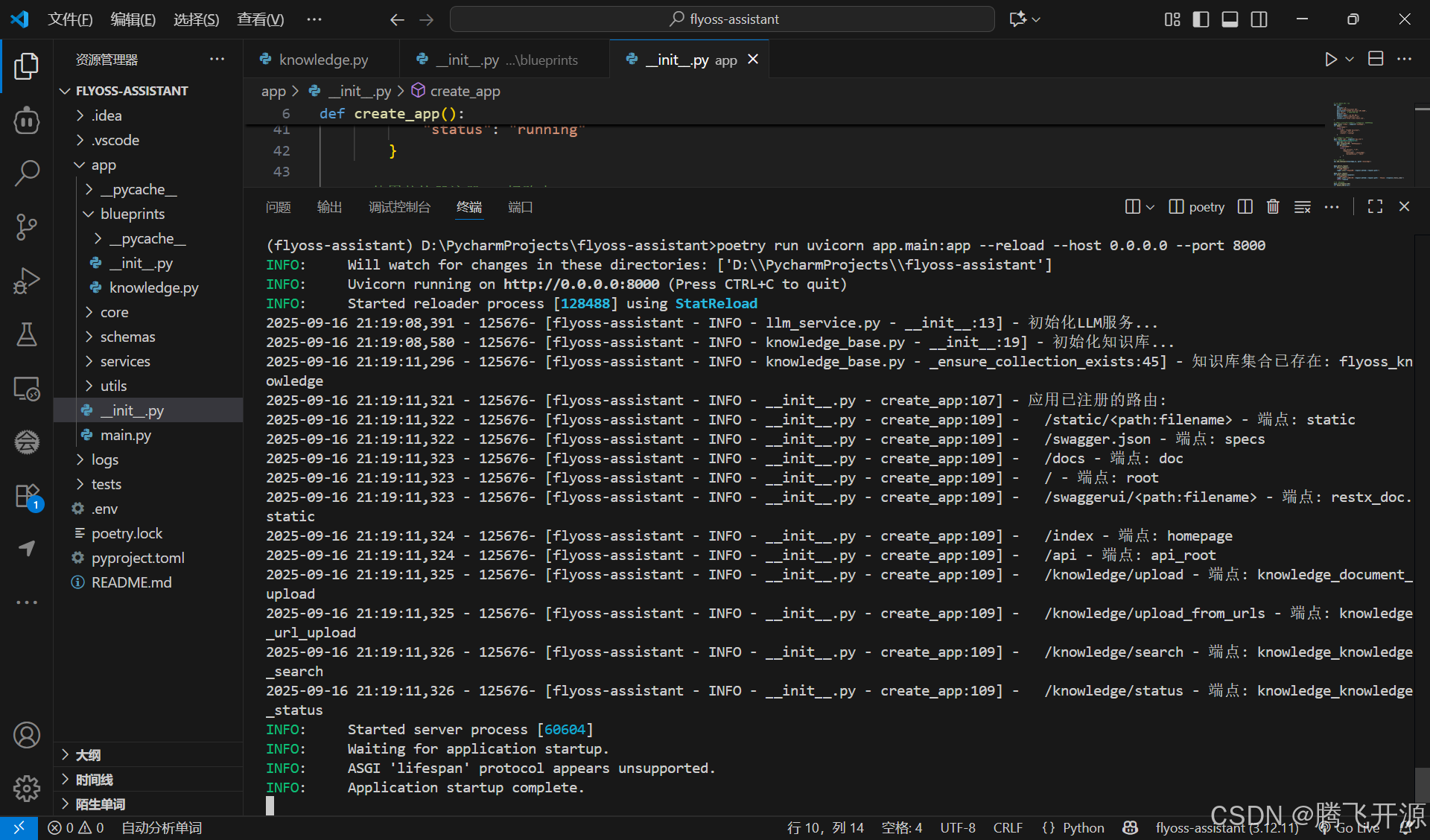
访问在线文档:http://localhost:8000/docs
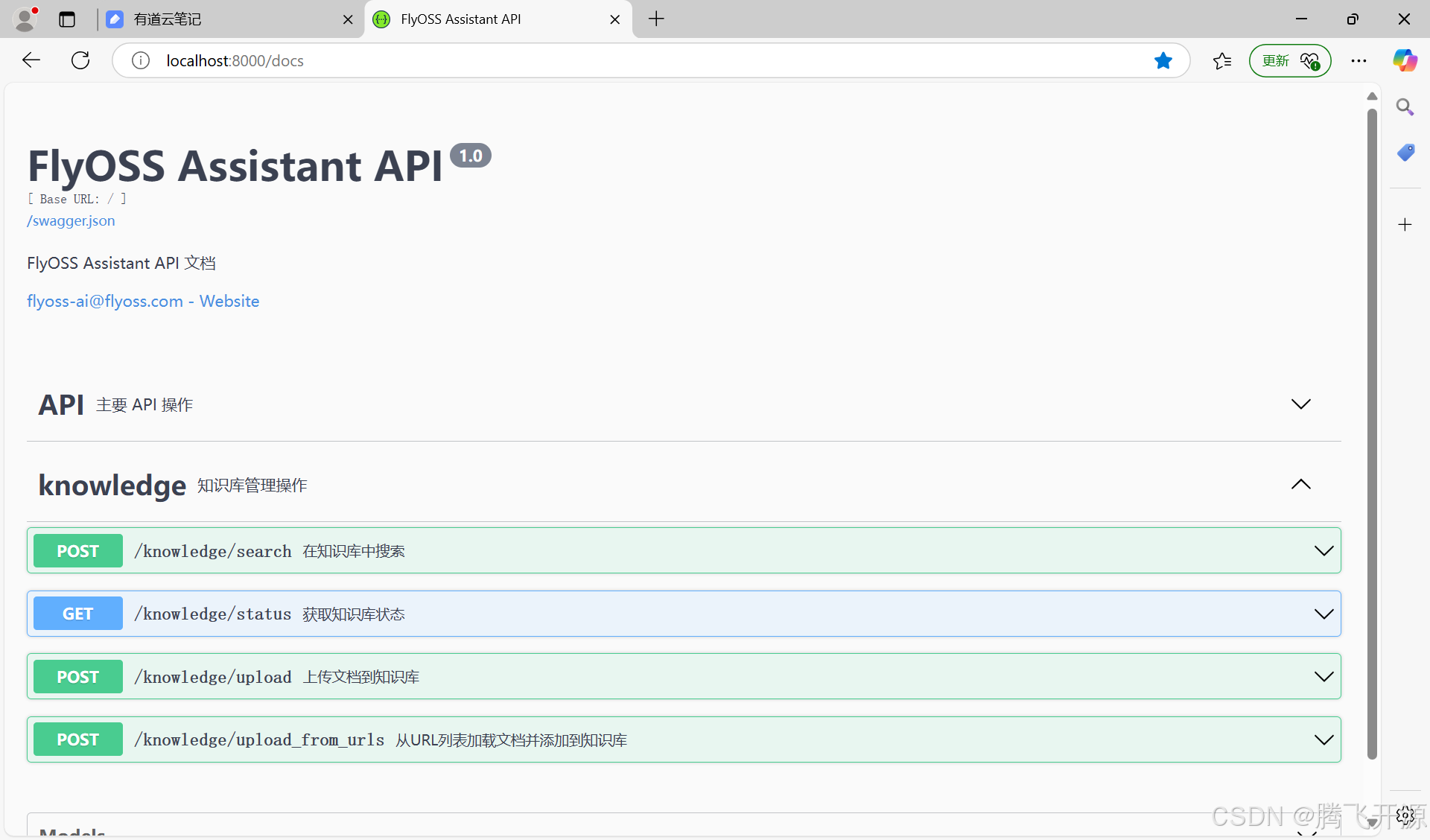
测试
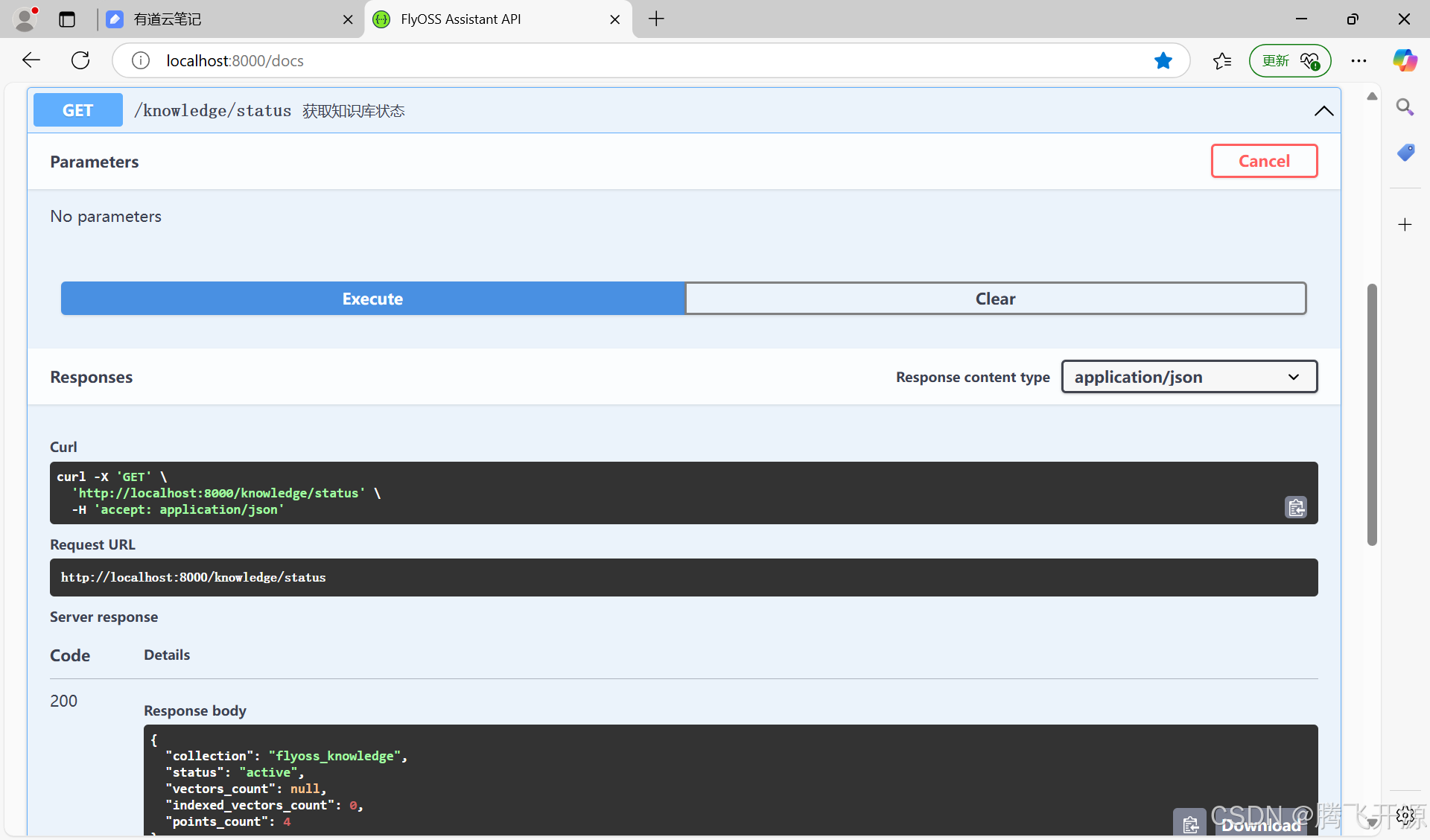
总结
通过Flask蓝图实现的模块化架构,我们构建了一个:
- 可维护:代码结构清晰,新人快速上手
- 可扩展:新功能以蓝图形式无缝集成
- 可测试:模块独立,测试覆盖简单
- 可部署:支持特性开关和渐进式发布
这种架构模式特别适合AI应用的后端开发,其中不同模块(知识库、对话、认证)有明确的业务边界和技术特点。