普通 CNN(卷积神经网络)只能处理固定大小的输入图片,是因为网络的最后几层(尤其是全连接层)要求输入张量的维度固定。
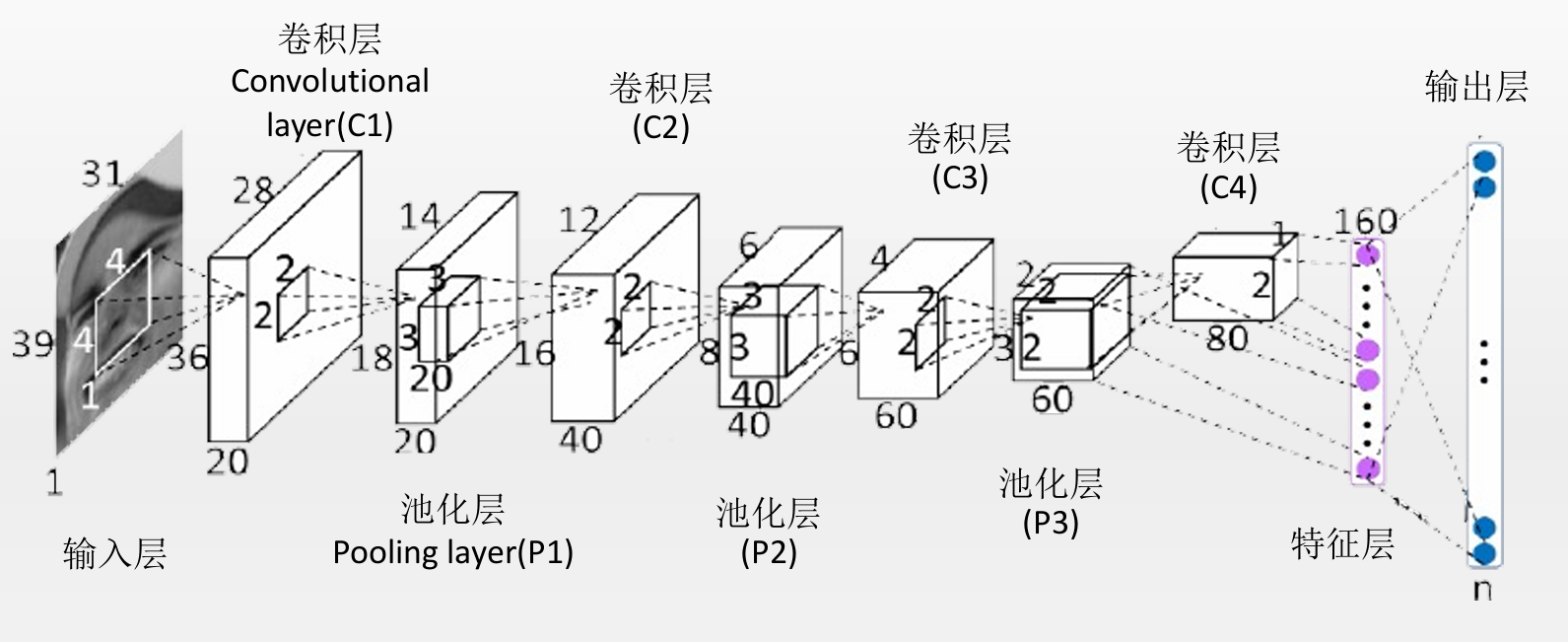
一、卷积层 (Convolutional Layers)不要求固定尺寸
卷积层的运算是局部的 、共享权重的,例如一个 3×3 的卷积核在整张图上滑动。
这种操作与输入图像的宽高无关(只要比卷积核大),所以输入可以是 32×32、128×128、224×224......
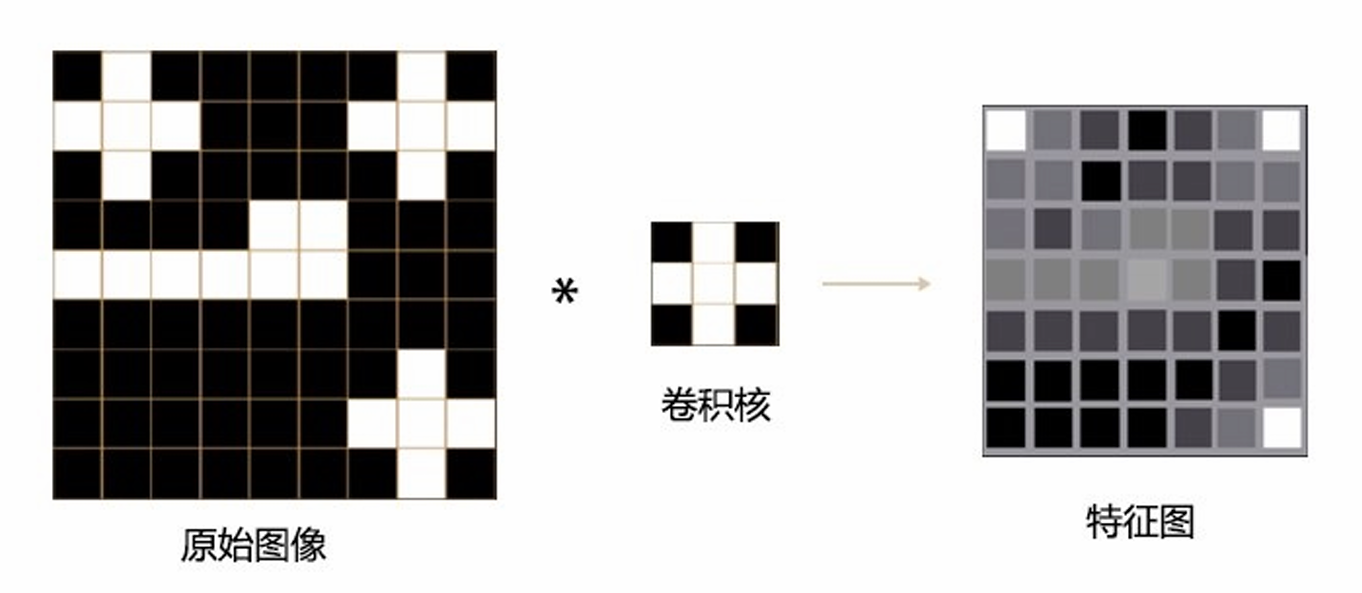
输出的特征图大小会随输入的大小变化而变化。
✅ 因此,卷积层对输入图像大小是灵活的。
🔹 二、全连接层的输入是固定维度的向量
在卷积层之后,特征图通常会被"拉平"(Flatten)成一维向量,然后输入全连接层。例如:
假设卷积层的输出特征图形状为
(Channels,Height,Width)=(256,7,7)
Flatten 后就变成长度为 256×7×7=12544 的向量。
如果这一层连接到一个具有 4096 个神经元的全连接层,那么权重矩阵形状是:
4096×12544
⚠️ 如果输入图片尺寸改变,例如从 224×224改成 256×256,输出特征图大小就不再是 7×7, 可能变为 8×8,
此时 Flatten 后的向量长度也变了,原来的权重矩阵尺寸就不再匹配。
💡三、SPPNet
何恺明等人在2014年ECCV上提出的基于空间金字塔池化(SPP-Net)的卷积神经网络(CNN)物体检测方法(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)。SPP-Net通过引入空间金字塔池化层,解决了传统CNN需要固定输入尺寸的问题,使网络能够接受任意大小的图片作为输入,并在卷积层与全连接层之间实现特征向量的统一尺寸输出,从而提升了检测精度与计算效率。
SPPNet 的思路非常巧妙:不直接固定输入图像的尺寸,而是固定卷积后输出的"池化特征数量"。
它在卷积层之后加入一个 Spatial Pyramid Pooling (SPP) 层:
- SPP层可以接受任意大小的特征图;
- 然后输出一个固定长度的特征向量,用于连接全连接层。
这样,全连接层输入固定,但卷积层输入(即图像大小)就不再受限了。
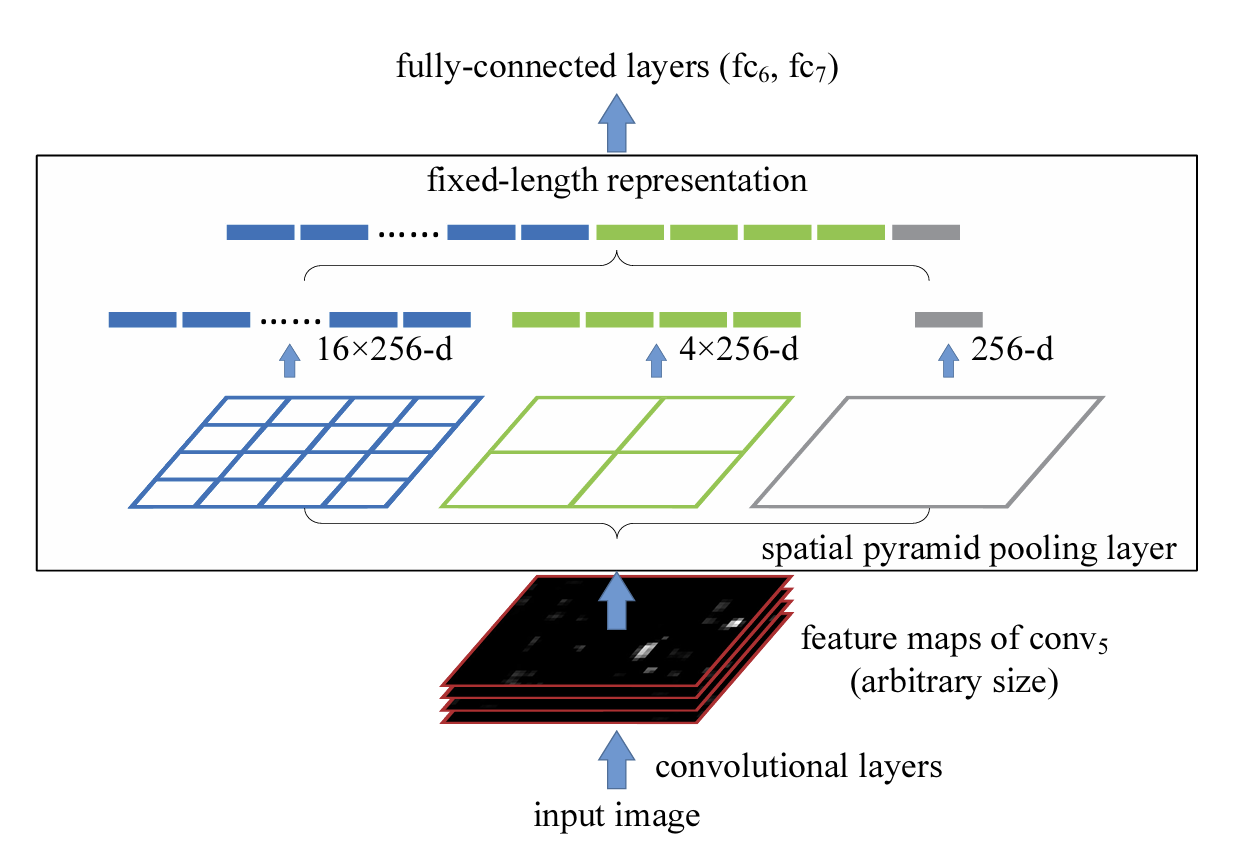
⚙️ SPP 的核心思想:像"分格子取代表值"
想象你有一张任意大小的图片(比如 400×400,或者 600×300)。
传统方法要先统一缩放成固定尺寸再送进 CNN。
但 SPP 不这么做,而是采取下面的策略:
步骤 1:多尺度划分(不同「网格」大小)
把这张图片(或者更准确地说,是"卷积层输出的特征图")
按照不同的网格标准切成块,例如:
| 金字塔层级 | 网格划分 | 块数(每通道) |
|---|---|---|
| 第1层 | 4×4 | 16个块 |
| 第2层 | 2×2 | 4个块 |
| 第3层 | 1×1 | 1个块 |
这些不同尺度的"划分层级"共同组成了所谓的空间金字塔(Spatial Pyramid)。
步骤 2:块内池化(取每块最强特征)
对于每个划分的块执行一次 池化操作(通常是最大池化 max pooling) 。
也就是说:
- 每个块 → 输出一个代表值(比如该区域中最强特征)
- 所有块的代表值拼在一起 → 一组固定长度的特征
例如
16+4+1=21
这就是文字中提到的"输出21个特征"。
无论输入图片原始尺寸是多少,
最后输出的特征数量总是固定的(21个),不再依赖输入大小。