在大型语言模型(LLM)和文档理解的世界中,"上下文窗口"和"Token 成本"一直是制约效率和规模的核心痛点。处理一份长达数百页的报告、合同或历史记录,意味着动辄数万甚至数十万的 Token 消耗和高昂的计算开销。
DeepSeek AI 近期推出的 DeepSeek-OCR,"轻松"解决这一痛点。它是一款前沿工具,专注于视觉-文本压缩和**光学字符识别(OCR)**,官方将其定位为 "Contexts Optical Compression"(语境光学压缩)的初步研究成果。它可以用视觉压缩长文本,将 LLM 的效率提升 10 倍!
DeepSeek-OCR 是什么?
我们先来介绍介绍这个 DeepSeek 近期发布的 DeepSeek-OCR。它是 DeepSeek AI 推出的一个前沿工具,专注于视觉-文本压缩 和**光学字符识别(OCR)**。
简单来说,这个系统的工作机制是:它先将大量的文本信息(如长文档)转换为一种视觉表征(图像形式),再由模型读取并处理,以此实现视觉文本压缩。
它不仅具备传统的 OCR 功能------能够从扫描件、PDF 或图片等图像中提取文字,更有突破性的用途:它可以将长上下文、复杂的表格、图形乃至整个文档作为视觉输入,通过编码大幅减少所需的 Token 数量。
总的来说, DeepSeek-OCR 是一个集成了 OCR 功能和文档理解能力 的工具,它通过将"文本 + 文档"转换为视觉表征,实现了节省 Token、加速处理并扩展上下文窗口的目标。
核心原理:视觉编码如何实现 Token 的"极限压缩"?
背景痛点
在传统 LLM 或文档理解系统中,"上下文过长"一直是核心痛点:将一份报告、PDF、表格或图表中的所有文字逐字 作为文本 Token 输入,会不可避免地消耗巨量的 Token(即成本)、内存 **/显存以及处理时间**。
DeepSeek-OCR 提出了一种突破性的 "视觉文本压缩"(Vision-Text Compression)思路:它将文字和文档先视觉编码 成图像形式,然后由模型来读取这些视觉输入。核心在于,视觉编码后产生的 "视觉 Token" 数量远少于原始的文本 Token,从而实现了 Token 数量的根本性节省。
主要组件与工作机制
该系统由两大核心组件构成:
- 视觉编码器**(DeepEncoder):** 负责将大量文本或文档转化为高分辨率图像或视觉表征。
- 解码器(例如 DeepSeek3B-MoE): 负责读取这些视觉输入,最终输出文字、结构化数据或深层理解。
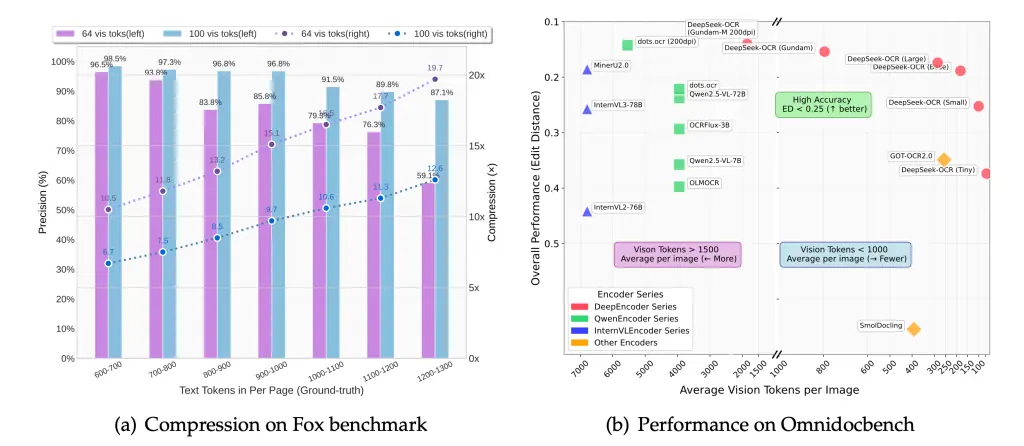
在其学术论文中,作者分享了关键指标:当压缩比(文本 Token 数/视觉 Token 数)小于 10 倍时,OCR 解码精度可以保持在约 97%。但如果压缩比激进到 **~20 倍**,精度会下降至约 60%。
这意味着: 传统方法可能需要 10,000 个文本 Token,而采用视觉编码方法,仅需约 1,000 个视觉 Token(实现 10 倍压缩)就能基本保留信息,极大地提升了效率。在 Reddit 上,相关的讨论也印证了这一点:
"DeepSeek figured out how to get 10x better compression using vision tokens than with text tokens!"
为什么视觉比文本 Token "更高效"?
从信息熵和表示方式的角度来看,传统的文本 Token 化(按单词/子词拆分)有时是碎片化 的。而将整段文字、复杂的表格、布局和图形以图像形式编码,则能完整保留整体的语义、结构和空间信息 。模型可以直接从全局入手进行提取和理解,自然减少了逐 Token 处理的开销。 Hacker News 上的用户讨论的时候也提到了这一点:
"Why does this work, is it that text tokens are still too 'granular'... switching to vision tokens escaping the limitation of working 'one word-ish at a time'..."
在实际应用中,DeepSeek 官方强调,在某些文档理解基准(例如 OmniDocBench)的测试中,该方法仅用 100 个视觉 Token,就超越了传统 OCR 系统使用数千个文本 Token 所能达到的性能。
节省 Token 与成本的直接优势
逻辑非常直接:输入给 LLM 的 Token 数量大幅减少,意味着 LLM 的计算量、所需的显存 **、以及 API 调用费用都将随之下降**,这对于使用付费 Token 模型的用户来说尤其重要。
这种方法对处理**"长文档"和"大规模文档批量处理"场景尤为有利:用户不必将文档中的每一个字都进行 Token 化,而是先通过视觉编码 实现压缩,再进行理解,极大地缩短了有效上下文长度**。
因此,在扩展 LLM 上下文、高效准备大规模训练数据 以及多页文档的快速 OCR 等场景中,DeepSeek-OCR 的价值将得到充分体现。
使用局限与注意事项
- 精度与压缩比的权衡: 压缩比越高,精度下降越明显。当压缩比激进至 ∼20 倍时,模型精度可能降至约 60%。
- 资源投入: 虽然减少了 Token 成本,但运行视觉编码器 和解码器 仍需要 GPU 资源,并非"免费午餐"。
- 输入质量依赖: 文档质量、布局复杂度、语言种类以及扫描质量等因素都会显著影响最终的识别效果。
- 流程瓶颈转移: 尽管 Token 数减少,但如果输入是图像,整个流程将包括图像预处理和 OCR 识别环节,这与传统纯文本 Token 化流程有着不同的性能瓶颈。
DeepSeek-OCR 能解决哪些实际问题?
以下是一些典型的应用场景:
- 批量高精度文档 OCR **:** 将大量扫描件、PDF、论文、合同和图表等转换为可编辑文本或结构化数据。DeepSeek-OCR 在文档、表格和图形场景表现尤为出色。
- 突破长上下文限制: 当面对一本著作、超长报告或海量历史记录时,传统 Token 化方法可能因长度限制而无法输入。视觉编码压缩能将**更长的内容高效"打包"**,输入模型,有效扩展上下文窗口。
- 复杂结构化数据理解: 由于视觉编码完整保留了文档的布局、图形和表格结构,模型能够实现对复杂文档的深度理解,而非仅仅是简单识别"文字串"。
- 高效训练数据 准备: 在训练大型模型(VLM、LLM)时,需要处理海量的文档数据。DeepSeek-OCR 可用于快速转录和提取大规模文档,为下游训练流程提供高质量语料。官方数据显示,"单个 A100 GPU 每天可处理超过 200,000 页"。
- 智能化应用赋能: 可作为核心组件,赋能如智能问答、文档检索、知识库构建、合同智能审查、发票/财务报表自动化处理等各类智能化应用。
如何快速上手 DeepSeek-OCR?
如果您想亲自体验 DeepSeek-OCR 的强大功能,下面是一个基本的上手流程:
环境准备
基础要求: Python 环境(建议 3.10+)、CUDA (例如 11.8)、PyTorch 和 Transformers 库。
安装依赖(以官方说明环境为例):
ini
pip install torch==2.6.0 transformers==4.46.3 tokenizers==0.20.3 einops addict easydict
pip install flash-attn==2.7.3 --no-build-isolation模型加载与推理代码(Python)
在 NVIDIA GPU 上使用 Huggingface transformers 进行推理的话:
ini
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
# infer(self, tokenizer, prompt='', image_file='', output_path = ' ', base_size = 1024, image_size = 640, crop_mode = True, test_compress = False, save_results = False):
# Tiny: base_size = 512, image_size = 512, crop_mode = False
# Small: base_size = 640, image_size = 640, crop_mode = False
# Base: base_size = 1024, image_size = 1024, crop_mode = False
# Large: base_size = 1280, image_size = 1280, crop_mode = False
# Gundam: base_size = 1024, image_size = 640, crop_mode = True
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)接着,将您的图像文件(如扫描文档、PDF 页面截图)作为输入,调用模型进行推理。具体的 API 使用方法,建议参照 Hugging Face 页面上的官方 README。
最后,检查模型输出,提取所需的文字或结构化数据,并可选择将其送入下游的 LLM 进行深度理解。
部署与规模化建议
- 对于实验或小规模用例,本地或云端的消费级/入门级 GPU 即可满足需求。
- 若是规模化处理(如大量文档批量处理或实时服务),则强烈建议使用高性能云 GPU 实例,并注意进行模型并行、批处理和 I/O 优化以提升吞吐量。
- 考虑对 OCR 提取结果进行缓存和预处理,以避免不必要的重复计算。
如果你选择使用云环境来运行 DeepSeek-OCR,那么推荐使用 DigitalOcean Gradient™ AI GPU Droplets 云服务器。
DigitalOcean 提供的 Gradient™ AI GPU Droplets 拥有多种 GPU 规格选择,支持按需实例、裸金属服务器,涵盖了从面向高性能计算的 NVIDIA H200、H100 到更具性价比的 AMD MI300X、AMD MI325X、 RTX6000 Ada 等。而且,DigitalOcean 的 GPU 服务器总体成本比 AWS、GCP 更具性价比。DigitalOcean 还通过中国区独家战略合作伙伴卓普云(aidroplet.com),专门为中国区企业客户提供商业合作咨询、技术支持等服务。
采用 DigitalOcean Gradient™ AI GPU Droplets 云服务能够在短时间内 处理大量的数据需求,而 DeepSeek-OCR 本身对 Token 的压缩,将进一步节省整体运营成本(包括云资源消耗费和潜在的模型调用费)。
写在最后
DeepSeek-OCR 是一款极具创新性和前瞻性 的工具。它巧妙地利用视觉编码和 OCR 技术,将文档转换为视觉表示,从而有效地实现了Token 消耗的降低、上下文长度的扩展和文档处理效率的提升。无论您是进行大规模文档处理、高精度 OCR,还是需要扩展 LLM 的上下文窗口,DeepSeek-OCR 都值得您深入探索和实践。
在云部署环节,DigitalOcean GPU Droplet 是一个优秀且可靠的选择:它具备操作简便、规格灵活、成本可控 等优势。如果您决定尝试,选用 1 个 H200 GPU 并搭配充足的内存与存储配置,将能为您提供强大的运行环境。
最后,如果您正在寻找一个上手简单、可扩展 且支持主流 GPU 的云环境来运行 DeepSeek-OCR 或其他 AI 模型,DigitalOcean GPU Droplets 无疑是您的理想选择。它提供预装驱动和 ML 镜像 、灵活的 GPU 规格、按需计费模式以及全球数据中心支持,能助您迅速将"模型"转化为"可运行、可部署的生产力"。如需了解更多,可咨询 DigitalOcean 中国区独家战略合作伙伴卓普云 aidroplet.com。