在传统神经网络架构中,权重系数的计算通常依赖于X与Y的关联性建模,但自注意力机制提出了一种创新范式。
该机制能够更有效地捕捉输入序列X内部各元素间的动态关联,并量化这些关联对Y输出的影响权重,进而显著增强模型的泛化能力。
作为深度学习领域的重要突破,自注意力机制已得到广泛应用,其核心思想更构成了Transformer模型的基础架构。
对于自注意力机制的内容本文从以下三个方面讲述:
1、什么是自注意力机制?
2、注意力评分函数有哪些?
3、什么是多头注意力?
一、什么是自注意力机制?
传统模型通常聚焦于X与Y的关联分析,而自注意力机制的创新之处在于揭示了X内部元素间潜在的重要关联。
以文本预测任务为例,模型不仅需要理解前文句子的表层含义,还需捕捉句子内部词汇组合对后续内容产生的深层影响。
为解决这一挑战,自注意力机制通过动态计算序列中每个元素(如a1与a2、a3的交互关系)的关联强度,结合反向传播算法,智能识别对当前任务最具关键性的特征部分。
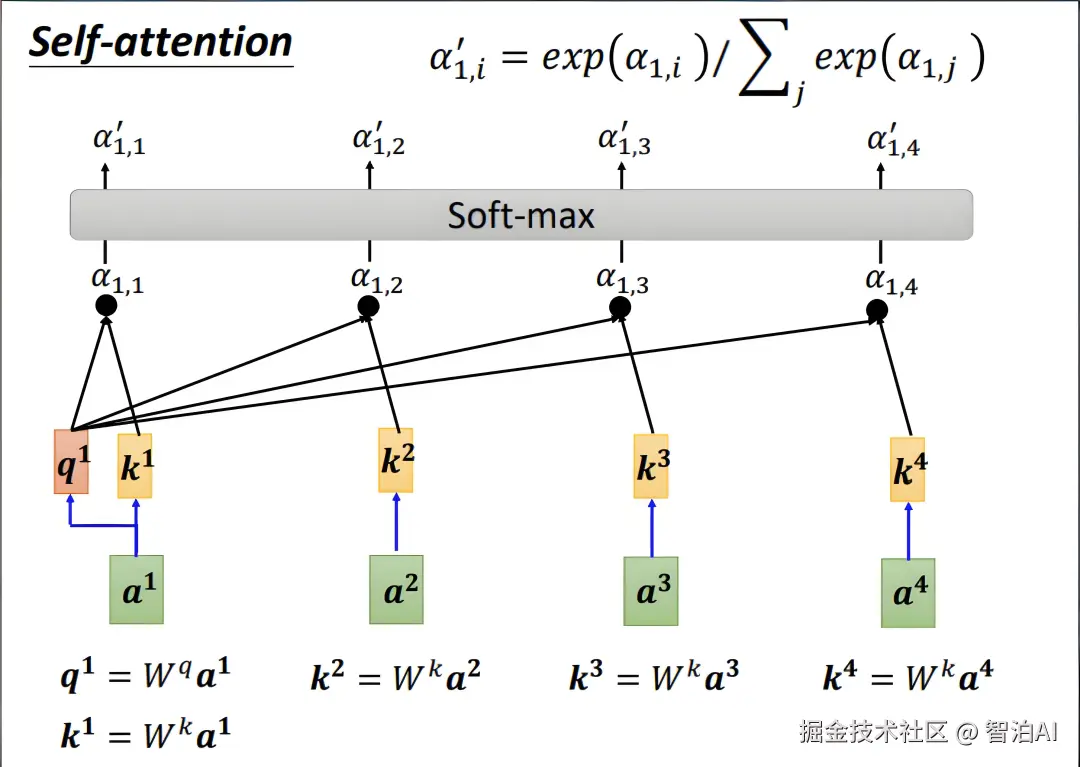
二、注意力评分函数有哪些?
常见的注意力评分函数有两种,一种是加性注意力 ,另一种是缩放点积注意力。
加性注意力:该评分函数不用考虑查询q和键k是否长度一致,其公式为:
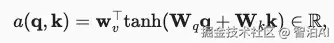
q代表查询,k代表键,但是自注意力中这两者是相同的,都是输入张量X。

缩放点积注意力:该评分函数需要查询q和键k保持长度一致,其公式为:
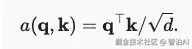

三、什么是多头注意力机制?
多头注意力机制就是将多个注意力汇聚的结果拼接在一起,这样得出来的结果会包含更多的行为信息,如下图所示:
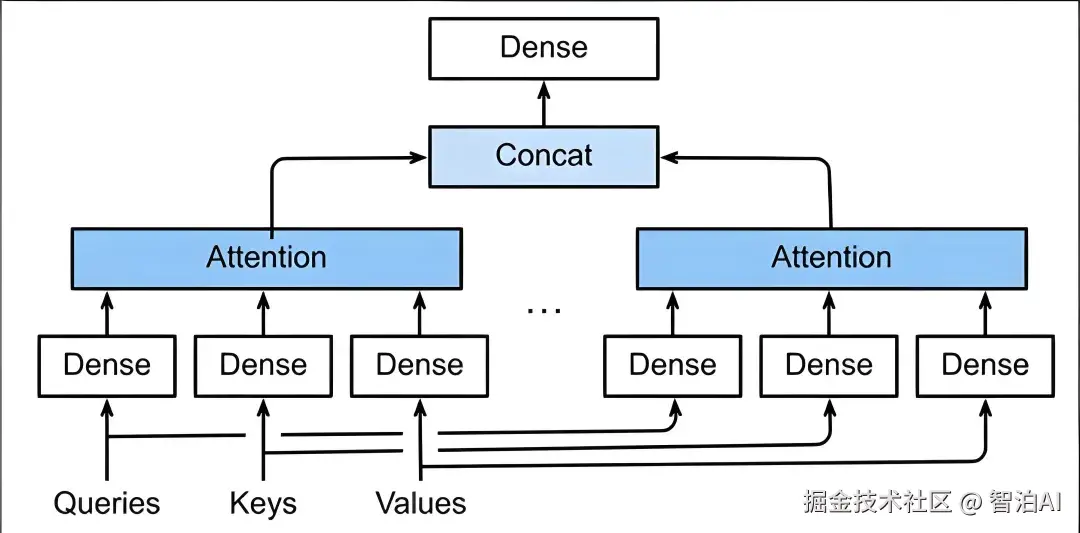
代码实现如下:
ini
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
# 分割d_model维度为num_heads
self.depth = d_model // num_heads
# 定义线性变换层
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
# 定义线性变换层来合并多头输出
self.dense = nn.Linear(d_model, d_model)
self.num_heads = num_heads
self.scale = 1 / (self.depth ** 0.5)
def split_heads(self, x, batch_size):
# 将输入x分割成多个头
x = x.reshape(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3)
def forward(self, v, k, q, mask=None):
batch_size = q.shape[0]
# 分割头
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
# 计算注意力分数, 此处为缩放点积注意力
scores = torch.matmul(q, k.transpose(-2, -1)) * self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 应用softmax获得注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 计算加权和
output = torch.matmul(attention_weights, v)
# 合并头
output = output.permute(0, 2, 1, 3).contiguous().reshape(batch_size, -1, self.num_heads * self.depth)
# 应用线性变换层
output = self.dense(output)
return output, attention_weights更多AI大模型学习视频及资源,都在智泊AI。