目录
[第1章 基础知识](#第1章 基础知识)
[1.1 帧率](#1.1 帧率)
[1.2 分辨率](#1.2 分辨率)
[第2章 图像检测](#第2章 图像检测)
[2.1 图像检测流程](#2.1 图像检测流程)
[2.2 框架选择](#2.2 框架选择)
[2.3 图像处理脚手架](#2.3 图像处理脚手架)
[第3章 线程池处理一路视频流](#第3章 线程池处理一路视频流)
[3.1 基本思路](#3.1 基本思路)
[3.2 如何保证输出顺序与输入视频帧顺序一致](#3.2 如何保证输出顺序与输入视频帧顺序一致)
[3.2 工程应用](#3.2 工程应用)
[3.2.1 图像检测任务](#3.2.1 图像检测任务)
[3.2.2 线程池](#3.2.2 线程池)
[3.2.3 主线程](#3.2.3 主线程)
[第4章 线程池处理多路视频流](#第4章 线程池处理多路视频流)
[4.1 工程应用一(不推荐)](#4.1 工程应用一(不推荐))
[4.1.1 为每路 RTSP 流独立管理一套上下文](#4.1.1 为每路 RTSP 流独立管理一套上下文)
[4.2 工程应用二(推荐)](#4.2 工程应用二(推荐))
第1章 基础知识
1.1 帧率
帧率(FPS, Frames Per Second)是指每秒显示的画面帧数。帧率越高,画面越流畅,动态效果越好。常见的帧率有24fps、30fps、60fps等。帧率:动态画面的流畅度。
- 24fps:电影行业的标准帧率,足以捕捉并展现大部分动态场景。
- 30fps:网络视频和电视节目的常见帧率,提供更为流畅的观看体验。
- 60fps及以上:高帧率视频在快速移动的场景中表现出色,但并非所有设备都支持高帧率播放。
1.2 分辨率
分辨率是指视频画面在一定区域内包含的像素点的数量。像素是构成图像的最小单位,每个像素都有特定的颜色和亮度。分辨率通常以"宽×高"的形式表示,如1920×1080,这代表视频的水平方向有1920个像素,垂直方向有1080个像素。
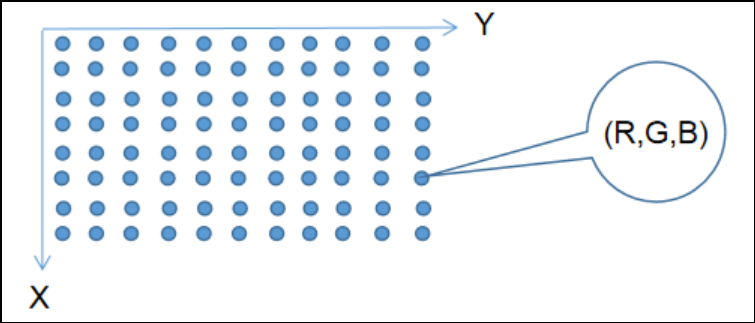
美国电影电视工程师协会(SMPTE)制定了一系列的高清数字电视格式标准,其中包含了常用的分辨率标准:
- 720P: 其有效显示格式为1280×720,采用逐行扫描(Progressive scanning)方式
- 1080P:其有效显示格式为1920×1080,也是采用逐行扫描方式。
- 1080i: 与1080p相对,1080i采用隔行扫描(Interlace scanning),也是1920×1080的分辨率。这种格式在传输过程中可能提供更高的帧率,但图像质量相对于1080p可能会有所降低。
- 2K:水平分辨率达到约2000像素,最标准的2K分辨率为2048×1024,常见的2K分辨率为2560×1440(16:9)。(UHDTV1)4K:UHDTV1由SMPTE ST 2036-1标准定义的VHD超高清系统,其分辨率为3840×2160(16:9)。(UHDTV2)
- 8K:UHDTV2同样由SMPTE ST 2036-1标准定义的VHD超高清系统,分辨率达到7680×4320。
第2章 图像检测
2.1 图像检测流程
2.2 框架选择
目标检测:yolo系列
推理框架:OpenCV C++
2.3 图像处理脚手架
第3章 线程池处理一路视频流
为什么要做线程池来做视频流检测?
答:配电房的RTSP帧率是25FPS。模型检测一帧图像需要18ms,想要做到实时推理检测是不可能,所以需要使用多线程。然而线程的创建和销毁很消耗CPU资源,所以我们为了减轻CPU的资源消耗提前创建好一个线程池。
3.1 基本思路

(1)创建一个线程池(线程池中包含4个线程对象,线程对象本质是一个图像处理对象);
(2)创建一个生产者线程,生产者线程获取视频流中每一帧图像,并且递交到线程池中的任务队列中。注意提交的时候需要将帧ID也提交过去。即任务队列是一个存放未处理帧ID和帧的容器。
cpp
std::queue<std::pair<int, cv::Mat>> tasks;(3)创建一个消费者线程,消费者线程从线程池中的结果容器中获取检测好的结果。注意消费者线程在获取检测结果帧的同时需要同时带着帧ID去获取。即存放检测结果的容器是存放具体帧和具体帧对应的结果的容器。
cpp
std::map<int, cv::Mat> img_results;3.2 如何保证输出顺序与输入视频帧顺序一致
| 帧ID | 线程ID | 处理时间 | 完成时间 |
|---|---|---|---|
| 0 | 0 | 20 ms | 20 ms |
| 1 | 1 | 40 ms | 40 ms |
| 2 | 2 | 10 ms | 10 ms |
| 3 | 3 | 18ms | 18 ms |
| 4 | 2 | 5 ms | 5 ms |
工程jiegou是 生产者 + 消费者 + 线程池(多个线程) 的结构:
-
生产者线程从 RTSP 获取视频帧,依次编号(例如 id = 0, 1, 2, 3, ...),然后调用:
cpp
threadPool.submitTask(frame, id);队列中的结构:
{(第0帧,cv::Mat), (第1帧,cv::Mat), (第2帧,cv::Mat), (第3帧,cv::Mat), (第4帧,cv::Mat), ..........}
注意:在queue容器中未检测的视频帧,是按照帧顺序来存放的。
- 多个**工作线程(线程池中的图像处理对象)**并发执行:
cpp
imgProcessObj->run(task.second, resultImg);所以帧的处理是并行异步完成的。
- 处理完成的结果保存到map中
cpp
{
std::lock_guard<std::mutex> lock(mtx2);
img_results.insert({task.first, resultImg});
cv_result.notify_one();
}map中的结构(仅仅针对表中的4帧数据)
{(第2帧,cv::Mat), (第4帧,cv::Mat), (第3帧,cv::Mat), (第0帧,cv::Mat), (第1帧,cv::Mat), ..........}
注意:在map容器中检测完的视频帧,并不是按照帧顺序来存放的,而是谁先检查完毕,先存放谁。
- 消费者线程,从map中来获取检测结果时,就需要一个自增的ID来map中获取帧。
3.2 工程应用
3.2.1 图像检测任务
cpp
#ifndef IMGPROCESS_H
#define IMGPROCESS_H
#include <opencv2/opencv.hpp>
class CImgProcess {
public:
explicit CImgProcess();
~CImgProcess();
public:
void run(cv::Mat &srcImg, cv::Mat &resultImg);
};
#endif /**IMGPROCESS_H */
cpp
#include "imgprocess.h"
CImgProcess::CImgProcess()
{
}
CImgProcess::~CImgProcess()
{
}
void CImgProcess::run(cv::Mat &srcImg, cv::Mat &resultImg)
{
// 确保源图像不是空的
if(srcImg.empty()) {
std::cerr << "src NULL" << std::endl;
return;
}
// 使用OpenCV的cvtColor函数将图像转换为灰度图像
cv::cvtColor(srcImg, resultImg, cv::COLOR_BGR2GRAY);
}3.2.2 线程池
cpp
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <opencv2/opencv.hpp>
#include "imgprocess.h"
class CThreadPool
{
public:
explicit CThreadPool();
~CThreadPool();
public:
/**设置线程池 */
void setUp(int threadCount);
/**提交要处理的任务 */
int submitTask(const cv::Mat &img, int id);
/**获取任务处理结果 */
int getTargetResult(cv::Mat &resultImg, int id);
/**停止所有线程 */
void stopAll();
private:
/**线程池的工作场 */
void worker(int id);
private:
/**线程池当前状态,默认是没有停止运行的。也就是stop = false*/
bool stop;
/**处理任务的对象 */
std::vector<std::shared_ptr<CImgProcess>> taskProcessorObj;
/**线程对象 */
std::vector<std::thread> threads;
/**待处理的任务 */
std::queue<std::pair<int, cv::Mat>> tasks;
/**处理任务的对象去获取任务时需要一把锁 */
std::mutex mtx1;
/**处理任务的对象去获取任务时需要一把锁, 这把锁的条件变量 */
std::condition_variable cv_task;
/**处理对象,处理完成的结果 */
std::map<int, cv::Mat> img_results;
/**处理任务的对象,处理完成的结果需要放置到Map中,所以需要一把锁 */
std::mutex mtx2;
/**处理任务的对象,处理完成的结果需要放置到Map中,所以需要一把锁,这把锁自然要一个条件变量 */
std::condition_variable cv_result;
};
#endif /**THREADPOOL_H */
cpp
#include "threadpool.h"
#include <iostream>
#include <chrono>
// 构造函数
CThreadPool::CThreadPool()
: stop(false)
{
}
// 析构函数
CThreadPool::~CThreadPool()
{
stopAll();
}
// 设置线程池大小和初始化
void CThreadPool::setUp(int threadCount)
{
// 创建处理任务的对象
for (int i = 0; i < threadCount; ++i) {
std::shared_ptr<CImgProcess> taskProcessorObjItem = std::make_shared<CImgProcess>();
taskProcessorObj.push_back(taskProcessorObjItem);
}
// 创建线程
for (int i = 0; i < threadCount; ++i) {
threads.emplace_back(&CThreadPool::worker, this, i); // 注意这里传递了 'this'
}
}
// 工作线程执行的任务
void CThreadPool::worker(int id)
{
while (!stop) {
std::pair<int, cv::Mat> task;
std::shared_ptr<CImgProcess> imgProcessObj = taskProcessorObj[id];
{
std::unique_lock<std::mutex> lock(mtx1);
cv_task.wait(lock, [this] { return !tasks.empty() || stop; });
if (stop) {
return;
}
task = tasks.front();
tasks.pop();
}
cv::Mat resultImg;
imgProcessObj->run(task.second, resultImg);
{
std::lock_guard<std::mutex> lock(mtx2);
img_results.insert({task.first, resultImg});
cv_result.notify_one();
}
}
}
// 提交任务到线程池
int CThreadPool::submitTask(const cv::Mat &img, int id)
{
{
std::lock_guard<std::mutex> lock(mtx1);
tasks.push({id, img});
}
cv_task.notify_one();
return 0;
}
// 获取任务结果
int CThreadPool::getTargetResult(cv::Mat &resultImg, int id)
{
int loop_cnt = 0;
while (img_results.find(id) == img_results.end()) {
std::this_thread::sleep_for(std::chrono::milliseconds(5));
loop_cnt++;
if (loop_cnt > 1000) {
std::cout << "getTargetImgResult timeout" << std::endl;
return -1;
}
}
std::lock_guard<std::mutex> lock(mtx2);
resultImg = img_results[id];
img_results.erase(id);
return 0;
}
// 停止所有工作线程
void CThreadPool::stopAll()
{
stop = true;
cv_task.notify_all();
for (auto& thread : threads) {
if (thread.joinable()) {
thread.join();
}
}
}3.2.3 主线程
cpp
#include <iostream>
#include <opencv2/opencv.hpp>
#include <memory>
#include "imgprocess.h"
#include "threadpool.h"
#if 0
const std::string ImgPath = "E:/Mytest/test20250430/apple.jpg";
int main(int argc, char **argv){
cv::Mat srcImg = cv::imread(ImgPath, cv::IMREAD_COLOR);
if(srcImg.empty()){
std::cerr << "Failed to load image: " << ImgPath << std::endl;
return -1;
}
cv::Mat resultImg;
std::shared_ptr<CImgProcess> imgProcess = std::make_shared<CImgProcess>();
imgProcess->run(srcImg, resultImg);
cv::namedWindow("abc");
cv::imshow("abc", resultImg);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
#endif
// 设置 RTSP 流地址
std::string rtsp_url1 = "rtsp://admin:bpg123456@10.10.12.228:554/h264/2/main/av_stream";
static int g_frame_start_id = 0; // 读取视频帧的索引
static int g_frame_end_id = 0; // 模型处理完的索引
// 创建线程池
static CThreadPool *yolov5_thread_pool = nullptr;
bool end = false;
/**获取视频流(生产者) */
void read_stream(std::string rtsp_addr);
/**获取处理结果(消费者) */
void get_results(bool record = false);
int main(int argc, char **argv){
// 实例化线程池
yolov5_thread_pool = new CThreadPool();
yolov5_thread_pool->setUp(4);
// 读取视频
std::thread read_stream_thread(read_stream, rtsp_url1);
// 启动结果线程
std::thread result_thread(get_results, true);
// 等待线程结束
read_stream_thread.join();
result_thread.join();
return 0;
}
void read_stream(std::string rtsp_addr)
{
// 读取视频
cv::VideoCapture cap(rtsp_addr);
if (!cap.isOpened())
{
std::cout << "Failed to open video file: " << rtsp_addr << std::endl;
}
// 获取视频尺寸、帧率
int width = cap.get(cv::CAP_PROP_FRAME_WIDTH);
int height = cap.get(cv::CAP_PROP_FRAME_HEIGHT);
int fps = cap.get(cv::CAP_PROP_FPS);
printf("Video size: %d x %d, fps: %d", width, height, fps);
// 画面
cv::Mat img;
while (true)
{
// 读取视频帧
cap >> img;
if (img.empty())
{
printf("Video end.");
// 等待一下没有处理结束的画面
std::this_thread::sleep_for(std::chrono::milliseconds(5000));
end = true;
break;
}
// 提交任务,这里使用clone,因为不这样数据在内存中可能不连续,导致绘制错误
yolov5_thread_pool->submitTask(img.clone(), g_frame_start_id++);
}
// 释放资源
cap.release();
}
void get_results(bool record)
{
// 记录开始时间
auto start_all = std::chrono::high_resolution_clock::now();
int frame_count = 0;
std::string fps_str;
std::string duration_str;
cv::VideoWriter writer;
if(record)
{
writer = cv::VideoWriter("thread_pool_demo.mp4", cv::VideoWriter::fourcc('a', 'v', 'c', '1'), 30, cv::Size(1280, 720));
}
// 开始计时
auto start_1 = std::chrono::high_resolution_clock::now();
while (true)
{
// 结果
cv::Mat img;
auto ret = yolov5_thread_pool->getTargetResult(img, g_frame_end_id++);
// 如果读取完毕,且模型处理完毕,结束
if (end && ret != 0)
{
break;
}
frame_count++;
// all end
auto end_all = std::chrono::high_resolution_clock::now();
auto elapsed_all_2 = std::chrono::duration_cast<std::chrono::microseconds>(end_all - start_all).count() / 1000.f;
// 每隔1秒打印一次
if (elapsed_all_2 > 1000)
{
printf("Method2 Time:%fms, FPS:%f, Frame Count:%d", elapsed_all_2, frame_count / (elapsed_all_2 / 1000.0f), frame_count);
fps_str = std::to_string(frame_count) + "fps";
frame_count = 0;
start_all = std::chrono::high_resolution_clock::now();
}
if(record)
{
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end_all - start_1).count() / 1000.f;
duration_str = std::to_string(duration) + "ms";
cv::putText(img, fps_str , cv::Point(10, 30), cv::FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 0, 255), 2);
cv::putText(img, duration_str, cv::Point(10, 50), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
// 写入视频帧
writer << img;
}
}
// 结束所有线程
yolov5_thread_pool->stopAll();
if (writer.isOpened())
{
writer.release();
}
printf("Get results end.");
}第4章 线程池处理多路视频流
4.1 工程应用一(不推荐)
4.1.1 为每路 RTSP 流独立管理一套上下文
cpp
struct StreamContext
{
std::string rtsp_url;
std::atomic<int> frame_start_id{0};
std::atomic<int> frame_end_id{0};
std::atomic<bool> end{false};
CThreadPool *thread_pool = nullptr;
std::thread read_thread;
std::thread result_thread;
};
int main(int argc, char **argv)
{
std::vector<std::string> rtsp_urls = {
"rtsp://admin:pwd@10.10.12.228:554/h264/2/main/av_stream",
"rtsp://admin:pwd@10.10.12.229:554/h264/2/main/av_stream",
"rtsp://admin:pwd@10.10.12.230:554/h264/2/main/av_stream",
// ... 共10路
};
std::vector<std::unique_ptr<StreamContext>> streams;
for (auto &url : rtsp_urls)
{
auto ctx = std::make_unique<StreamContext>();
ctx->rtsp_url = url;
ctx->thread_pool = new CThreadPool();
ctx->thread_pool->setUp(4); // 每路4线程(或共享全局线程池)
ctx->read_thread = std::thread(read_stream, std::ref(*ctx));
ctx->result_thread = std::thread(get_results, std::ref(*ctx), true);
streams.push_back(std::move(ctx));
}
// 等待所有线程结束
for (auto &ctx : streams)
{
ctx->read_thread.join();
ctx->result_thread.join();
ctx->thread_pool->stopAll();
delete ctx->thread_pool;
}
return 0;
}**1路视频流创建一个线程池(4个处理线程) + 一个生产者线程 + 一个消费者线程 = 6个线程。**假设现场有40路视频流,就会创建240个线程。
4.2 工程应用二(推荐)
把每路 StreamContext 的线程池改成 共享全局线程池 ,只保留每路的 read_thread 和 result_thread。