2025.10.22 《Inside the C++ Object Model》
文章目录
- 前言
- [第1章 关于对象](#第1章 关于对象)
-
- [1.1 C++对象模式](#1.1 C++对象模式)
- [1.2 关键词所带来的差异](#1.2 关键词所带来的差异)
- [1.3 对象的差异](#1.3 对象的差异)
- [第2章 构造函数语义学](#第2章 构造函数语义学)
-
- [2.1 默认构造函数的构造操作](#2.1 默认构造函数的构造操作)
- [2.2 拷贝构造函数的构造操作](#2.2 拷贝构造函数的构造操作)
- 未完工
前言
什么是C++对象模型
有两个层面可以解释:
- 语言中直接支持面向对象程序设计的部分
- 对于各种支持的底层实现机制
语言层面可以在众多C++书籍中体现,本书主要专注于第二点。
然而具体的底层实现往往根据编译器或操作系统的不同而有所变化,本书中如果有重大的实现技术差异会分别讨论,如果只是一种方法的迭代则会说明历史演化。
除非有必要,否则本笔记时只会记录书中一种主要方法的最新实现。
本书作者Stanley Lippman是C++大师级人物,也是《C++ Primer》等书的作者,参与开发了第一套C++编译器。
本书的章节没有必然联系,可以先阅读不那么晦涩的第一、三、四章。
中文版使用了部分英文和繁体中文的术语,本笔记会视情况替换。
第1章 关于对象
加上封装后的布局成本
C语言本身不支持将数据和函数关联起来,而面向对象的C++可以定义抽象模型将数据和函数封装在一起,尽管在代码上看起来更加复杂,但并不会增加布局成本,因为其数据部分就和C语言的结构体一样,每个函数也只会产生一个实例。
但引入virtual确实会产生额外负担。
1.1 C++对象模式
非虚函数并不存放在对象中,编译器对于普通函数的调用,是通过名称修饰生成唯一符号后编译时解析来实现的,静态绑定,由编译器直接生成调用指令。而虚函数是动态绑定,虽然也不在对象中,但指向虚函数表的指针存放在对象中。
所以对象模型主要是如何存储数据和虚函数,布局空间内直接存储数据本身的缺点是若数据发生修改需要重新编译,如果对数据的存储也使用指针间接存取则会产生额外的空间和存取开销。
C++对象模型采用的是前者,这部分的示例转自C++对象模型
cpp
class Base {
public:
Base(int);
virtual ~Base(void);
int getIBase() const;
static int instanceCount();
virtual void print() const;
protected:
int iBase;
static int count;
};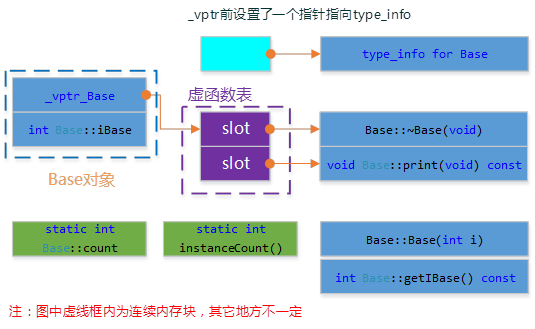
在此模型中,非静态数据成员被放置到对象内部,静态数据成员, 静态和非静态函数成员都被放到对象之外。
对于虚函数的支持则分两步:
- 每一个类产生一堆指向虚函数的指针,放在表格之中。这个表格称之为虚函数表vtbl。
- 每一个对象被添加了一个指针vptr,指向相关的虚函数表vtbl。vptr的设定和重置都由每一个类的构造函数,析构函数和拷贝赋值运算符自动完成。
虚函数表还设置了一个指向type_info的指针,包括对象继承关系,用于RTTI(服务多态)。通常位于虚函数表的第一个条目或前一个地址,甚至其他的位置,具体取决于编译器的实现,C++标志并没有规定。
一般继承
对于单继承,派生类的对象模型会在基类的基础上扩充已有存在的虚函数表(父子并不是公用一个虚函数表,每个类都有自己的虚函数表)
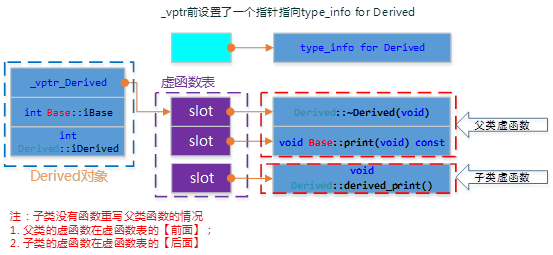
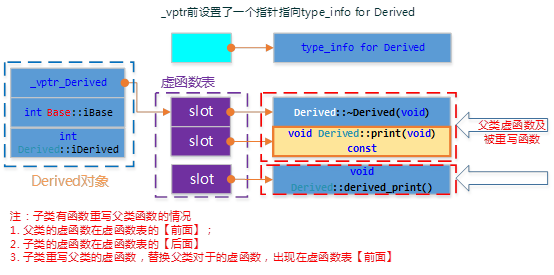
如果派生类有重写函数,则会覆盖基类对应虚函数的地址:
如果是多继承,按照上述模型则可能出现的多个派生类重写函数重复覆盖基类函数的情况,当出现重复继承时还会导致拥有多个重复的虚函数指针指向基类虚函数表。
虚继承
虚继承是为了解决多继承的问题,对于虚继承,派生类的对象模型会多添加一个虚函数表指针,原本应该把父子虚函数合在一个表中,现在用两个虚函数指针分别存放基类表和自己的表,中间用一个4字节的0x0来分隔,且自己的表在前。
具体而言,派生类的内存结构,首先是自己的虚函数表,然后是派生类的数据成员,然后是0x0,之后就是基类的虚函数表,之后是基类的数据成员。当然如果派生类没有自己的虚函数则不会有虚函数表,但依然有0x0做父子间隔。
如果派生类重载了基类的虚函数,则会替换基类表里的对应函数。
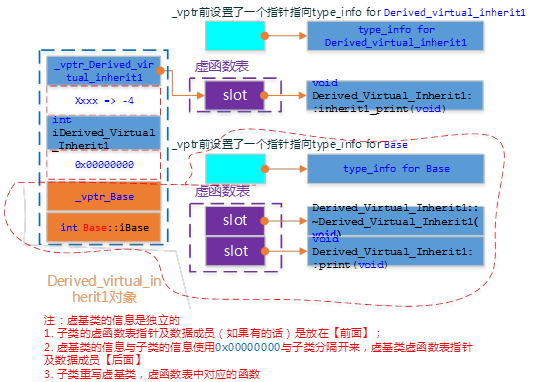
多重继承
cpp
class X { public: int i; };
class A : public virtual X { public: int j; };
class B : public virtual X { public: double d; };
class C : public A, public B {public: int k; };具体对象模型内存布局(忽略内存对齐和分隔,C没有虚函数所以没有vptr_C)
| A对象 | 说明 |
|---|---|
| vptr_A | 指向A的虚函数表 |
| A::j (int) | A自身数据成员 |
| X::i (int) | 虚基类X的子对象 |
| C对象 | 说明 |
|---|---|
| vptr_A | 指向C中A部分的虚表 |
| A::j (int) | 从A继承的数据 |
| vptr_B | 指向C中B部分的虚表 |
| B::d (double) | 从B继承的数据 |
| C::k (int) | C自身的数据成员 |
| X::i (int) | 共享的虚基类X子对象 |
对象模型如何影响程序
有函数foobar(),返回值为class X,其中X只定义了一个拷贝构造、虚析构、虚函数foo()(假设有子类实现,也就是会发生多态)
cpp
X foobar() {
X xx;
X *px = new X;
xx.foo(); // 正常函数调用
px->foo(); // 触发虚函数机制。(*px).foo()等价
delete px;
return xx;
}这个函数在编译器内部可能转化为:
cpp
// 虚拟的C++代码
void foobar( X &_result) { // 成员函数调用隐含对象参数
// 构造_result,取代局部变量 xx
_result.X::X();
// X *px = new X 的过程
px = _new(sizeof(X)); // 分配空间
if ( px != 0 ) px->X::X(); // 分配成功后调用构造
// xx.foo() 的过程,正常成员函数调用
foo( &_result );
// px->foo 的过程,使用了虚机制。
( *px->vtbl[2] )(px) // (*px->vtbl[2])是实际调用的成员函数,(px)是传入对象地址
// delete px 的过程
( *px->vtbl[1] )(px); // 调用析构
_delete(px); // 回收空间
// 没有创建并销毁局部对象xx,而是直接构造使用_result,因此也没有返回值
return;
}可以看出编译器对返回临时对象xx做了优化,如果有左值接收函数返回,_result将直接构造在左值的地址上,避免多次拷贝。
虚函数只有通过指针或引用才能也必然触发,即使基类指针指向的也是基类对象,一样会触发。因为编译器在编译时无法判断基类指针或引用指向的到底是哪个类型,所以只能在运行时通过虚机制动态完成调用。
1.2 关键词所带来的差异
C++为了兼顾C语言会有很多奇奇怪怪的规定,例如:
cpp
// 声明和定义混用class和struct,通过编译
struct MyData;
class MyData {};
// 通过编译
template < class Type >
struct mumble {};
// 编译报错
template < struct Type >
struct mumble {};在C++中struct和class实际上没有区别,只是人为做了概念区分,保留struct只为兼容C语言,而模板并不打算和C语言兼容,因此规定用struct会报错。
如果需要把某个class中的数据传递给C函数,可以用struct封装。
1.3 对象的差异
范式paradigm:一种环境设计和方法论的模型或范例。面向对象设计就是一种系统和软件的开发范式。
指针的类型
一个指针或引用无论何种类型本身需要的内存都是固定的(32位4字节,64位8字节),不同类型的指针差异只在于其寻址出来的对象类型不同,即指针类型会告诉编译器如何解释地址中的内容及其大小。这就是为什么void*可以持有一个地址,但不能操作它。
对象类型将在编译期决定两点:固定的可用接口和接口的访问等级。比如基类指针不能调用只属于派生类的成员。
换句话说,将对象指给不同类型的指针并不会对内存上的对象布局产生什么影响,只会影响对指向内存的大小和内容解释方式。
多态是面向对象模型(object-oriented)的重要部分,通过额外的间接性负担提供了类型上的弹性,允许继一个抽象的公共接口后封装相关类型。如果没有多态机制,只能叫object-based,也叫抽象数据类型模型(abstract data type model, ADT)。
第2章 构造函数语义学
构造函数是特殊的静态成员函数。
explicit关键字用于禁止隐式转换,尤其对于单一参数的构造函数(准确地说是参数数量相同),如三个单参构造函数的参数分别是int、char、double,就可以因为隐式转换而导致调用错误。
再比如 Widget w2(w1); 和 Widget w2=w1;
在拷贝构造函数没有加explicit时是等价的,后者会发生隐式转换调用前者,若加了explicit则会编译失败。
C++11后也可用于运算符重载,例如防止意外的布尔转换。
2.1 默认构造函数的构造操作
"编译器会在需要的时候生成默认构造函数"
然而这里的"在需要的时候"指的是编译器需要,不是程序需要,生成的内容也仅限于编译器所需。
cpp
class Foo { public: int val; Foo *pnext; };
void foo_bar() {
Foo bar;
if (bar.val == 0 && bar.pnext == nullptr) {
...
};
}显然这段程序希望Foo生成默认构造函数将bar的变量都初始化为0,然而实际上编译器并不会为它生成默认构造函数,即使生成了也不一定就会对成员数据进行初始化。
尽管后来C++手册改成了"如果用户没有定义构造函数,则编译器会隐式生成可能无用的默认构造函数",但其实并没有改变行为事实,只是改了文案。
注:未初始化的变量中,只有全局变量才会在程序启动时清0,栈上的局部变量和堆上的变量内容将是所在内存上次被使用后的遗迹。
何时会生成有用的构造函数?
首先默认用户没有定义构造函数,否则编译器不会自动生成。
内含带有默认构造函数的成员对象
如果类内含一个成员对象,该成员对象有默认构造函数,则编译器隐式生成的构造函数就会有必要的代码去调用它保证成员的初始化。
这里有几个问题,之后的几种情况也是一样的处理:
1、如果在C++不同的编译模块(文件)中都需要给同一个类生成默认构造函数,如何避免生成多个呢?
编译器自动生成的构造、析构、拷贝、构造函数默认以inline方式完成,内联函数是静态链接,不会被文件以外者看到。如果函数太复杂不适合做成inline,则会生成一个explicit的非内联静态实例。
2、如果类含有一个带有默认构造函数的成员对象,但用户定义了构造函数,此时该成员对象如何初始化?
编译器会往已有的每一个构造函数中扩充代码,先去调用必要的默认构造函数。
3、为什么是持有默认构造函数的内含对象?
因为如果是有参的,则成员初始化就从编译器需要变成了程序需要,程序员就必须手动在构造函数中显式调用。
派生于带有默认构造函数的基类
类似的,如果类是从一个有默认构造函数的基类继承过来的,则也会生成有用的默认构造函数,因为继承相当于隐含一个基类成员对象。
带有虚函数的类
类声明了虚函数或继承树中有虚函数,即该类持有虚函数。
默认生成的构造函数会进行虚机制的准备,即生成虚函数表和添加其指针。且其虚函数的调用操作会被编译器改写成虚机制。
带虚基类的类
虚基类的实现在不同编译器间差异巨大,但它们都必须保证虚基类在每一个派生类对象中的位置能够在执行期准备妥当。
cpp
class X { public: int i; };
class A : public virtual X { public: int j; };
class B : public virtual X { public: double d; };
class C : public A, public B {public: int k; };
// pa的类型可变,因此编译期无法确定pa->i的位置
void foo( const A* pa ) { pa->i = 1024; }
main() {
foo(new A);
foo(new C);
}为什么 X::i 的位置编译期无法确定?
因为虚继承的派生类对象模型会把基类的对象放到最后面共享,而不是正常继承中的最前面,所以基类成员数据的地址会因为不同派生类自身的成员数据而变化。
为确保对 X::i 的存取操作可以延迟到执行期才决定,编译器在会在派生类的构造函数中添加一个指针(例如_vbcX),该指针指向虚基类X,用于在执行期确定X中的成员变量位置。
void foo( const A* pa ) { pa->i = 1024; }会变成void foo( const A* pa ) { pa->_vbcX->i = 1024; }
即通过_vbcX间接寻址。