What is agentic AI? 什么是自主 AI?
Non-agentic workflow
要求写一篇文章时,直接从头写到尾。
Agentic workflow
要求写一篇文章时,会有web research,根据web pages内容编写草稿,对草稿进行修改,进一步web research等。这种工作流倾向于先做思考和研究,然后做修改和进一步思考和研究。由于经过迭代处理,agentic workflow工作耗时更长,但是能产生更好的工作成果。因此一个agentic workflow(自主型 AI 工作流程)是一个基于 LLM 的app执行多个步骤完成任务的过程。
Essay-Writing Example:
1、LLM:用LLM写文章大纲。
2、LLM+Web search:用LLM决定在搜索引擎的搜索词,调用search API搜索相关网页。
3、LLM:下载网页内容喂给LLM,写初稿。
4、LLM:反思和决定修改。
5、human:关键节点,可以进行人机交互。通过人工审核,进行进一步修正。
视频演示了Research Agent编写文章的过程。通过分步骤,采集资料,深入思考和修正,写出的文章效果会比只给LLM一个prompt好得多。
Degrees of autonomy 自主性程度
两种自主性程度的Agentic AI:
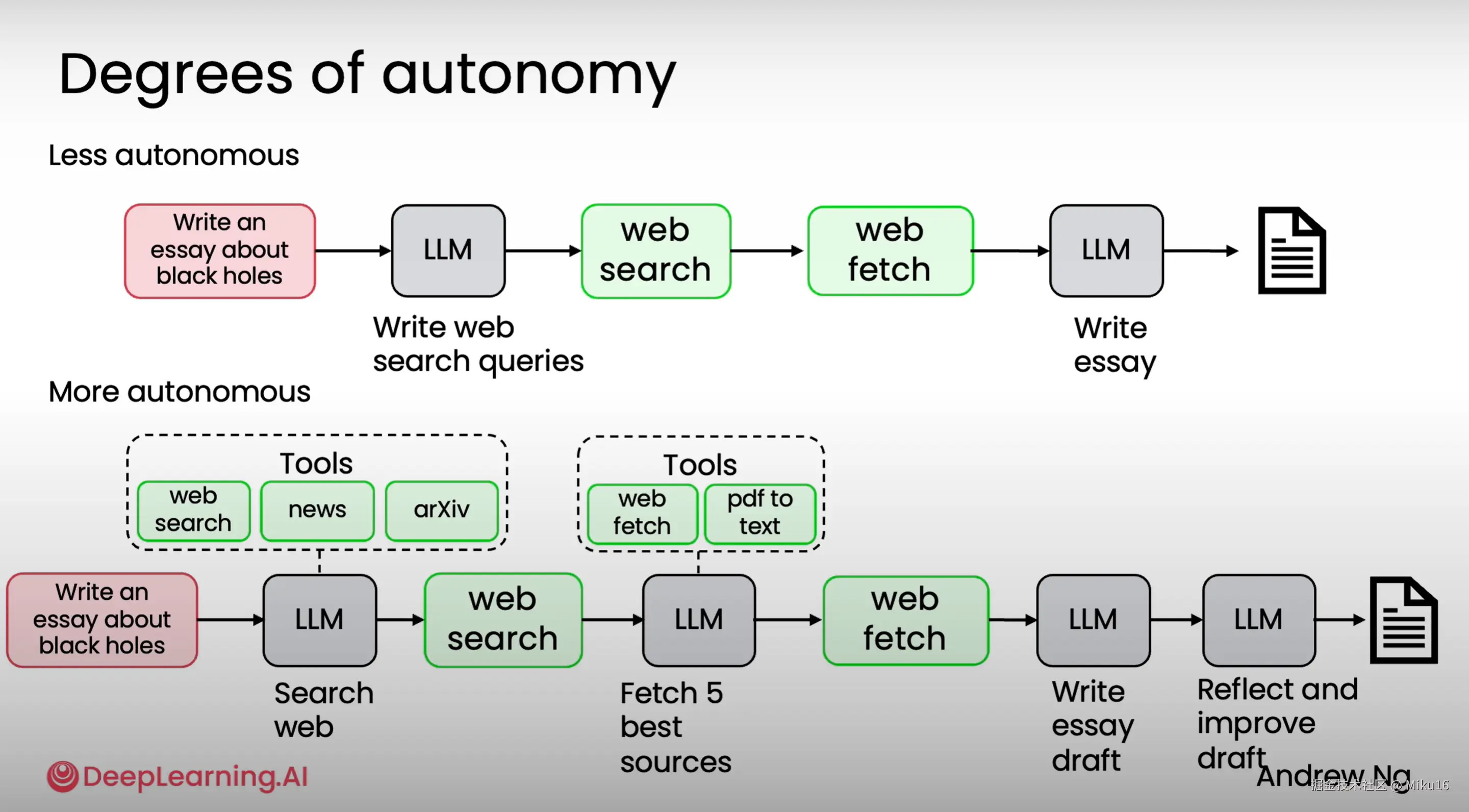
两种自主性程度的Agentic AI: 1、自主性低,线性执行步骤,程序员决定度较高的代理。 2、自主性高,LLM决定步骤顺序(如从多个Tool中选择调用)而非程序员预先设定。
Agentic AI自主性谱系图

Agentic AI自主性谱系图
当前低自主性的apps很多,高自主性的由于不易控制,不可预测性,还存在大量研究。
Benefits of agentic AI 自主 AI 的优势
1、提高性能
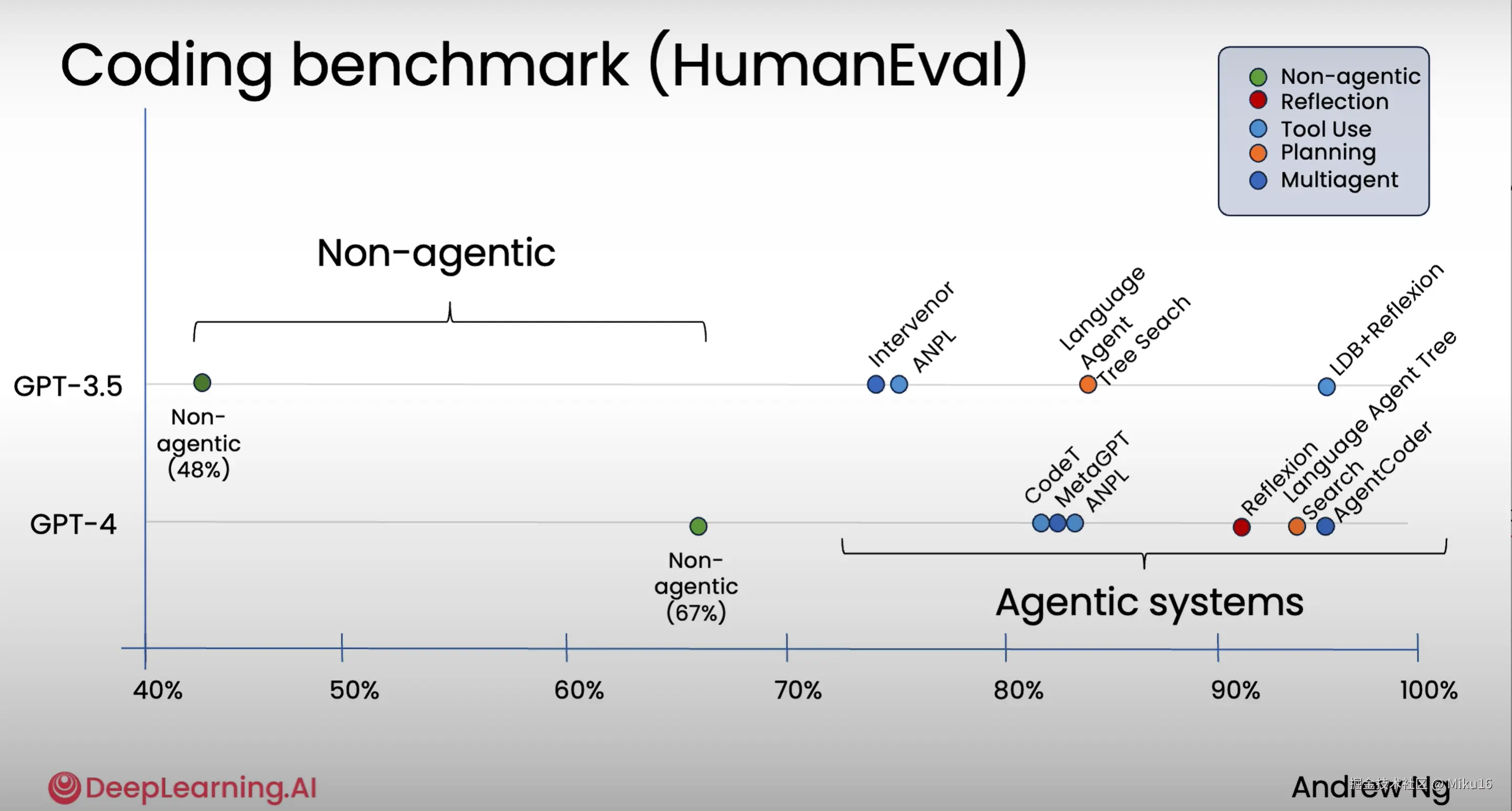
1、agentic workflows自主性工作流能给大模型带来更高的性能表现。上一代模型到下一代模型迭代的进步尽管很大,但是上一代模型通过agentic workflows的改进变化更大。
2、并行化
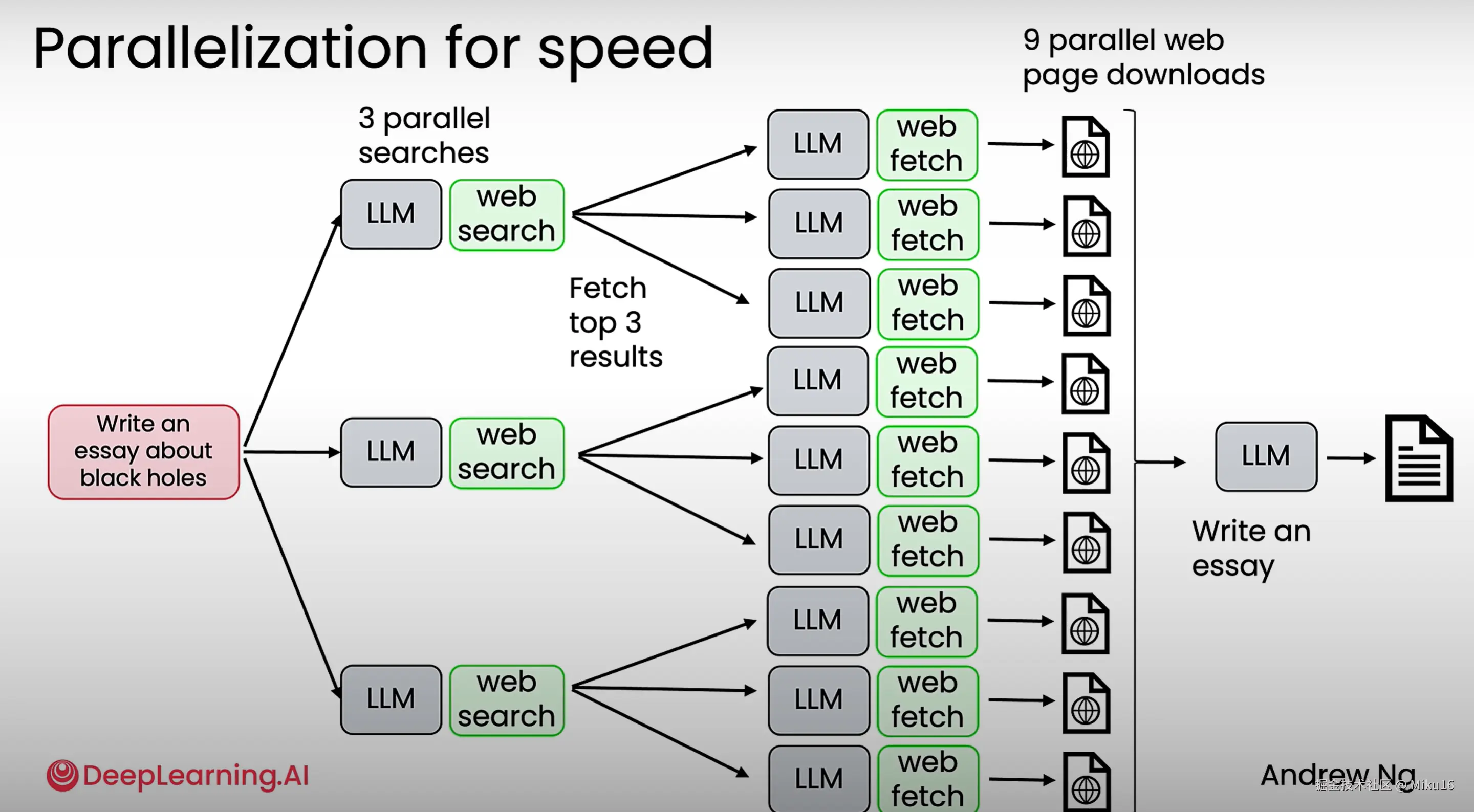
2、agentic workflows可以并行处理任务,更快地完成任务。
3、模块化
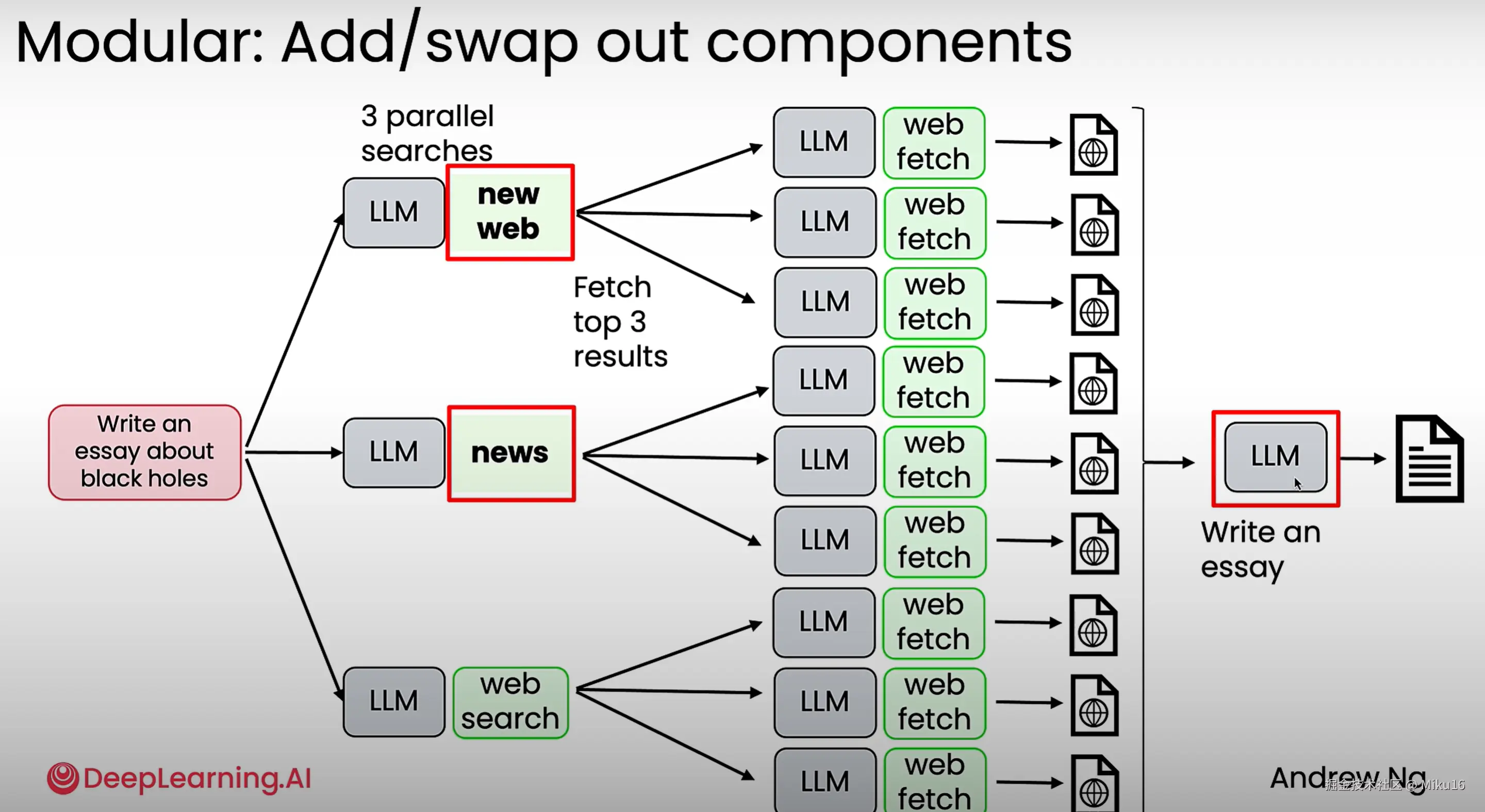
3、模块化组装:使得便于增加和更改tool组件和大模型等。
总结

Agentic AI applications 代理式 AI 应用
示例1:发票处理工作流
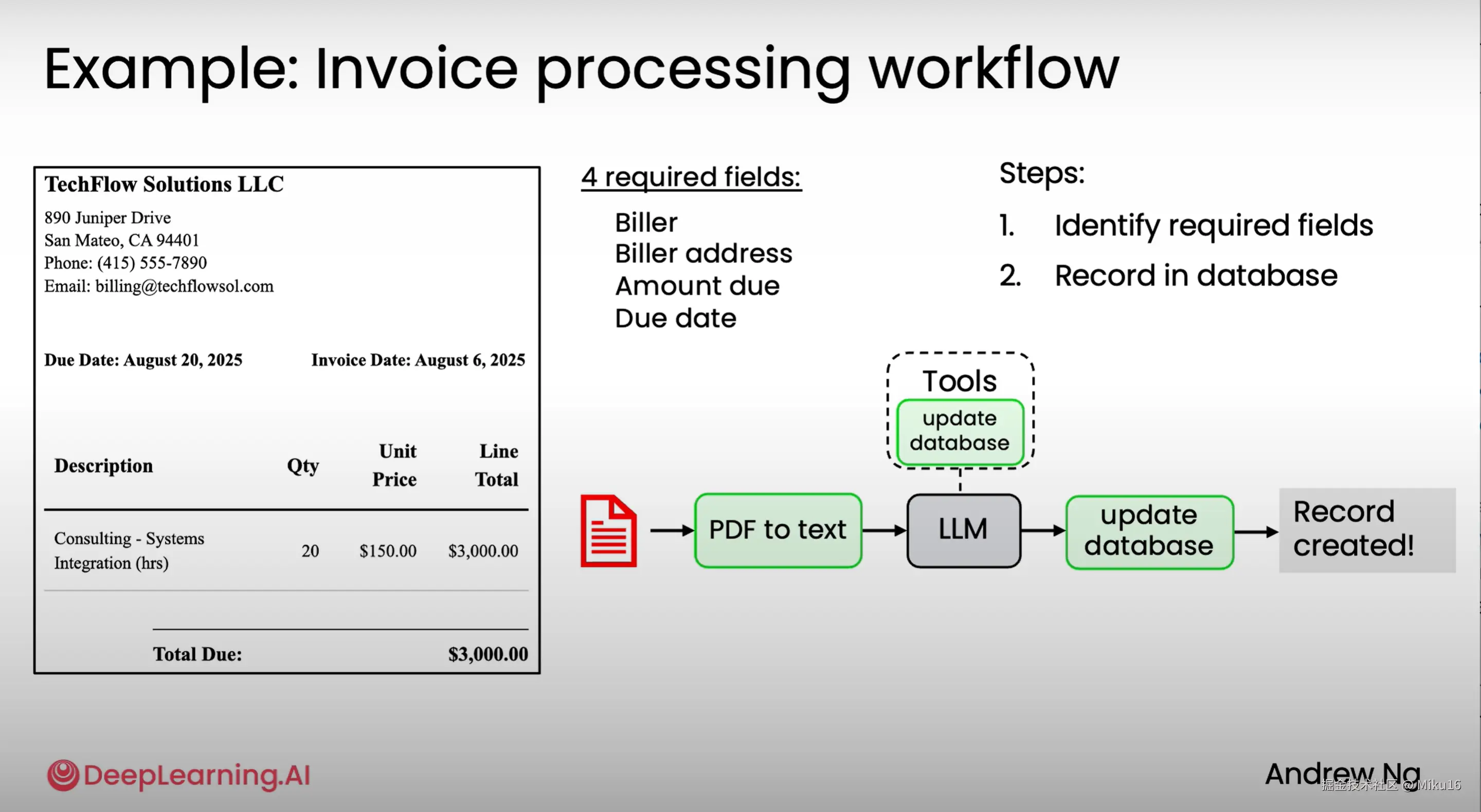
PDF文档->PDF to text->LLM(调用更新数据库的tool)->更新数据库->创建记录。
像这类有明确流程需要遵循的任务,往往可能对自主型人工智能更容易执行,因为有逐步执行的步骤遵循。
示例2:回复客户邮件
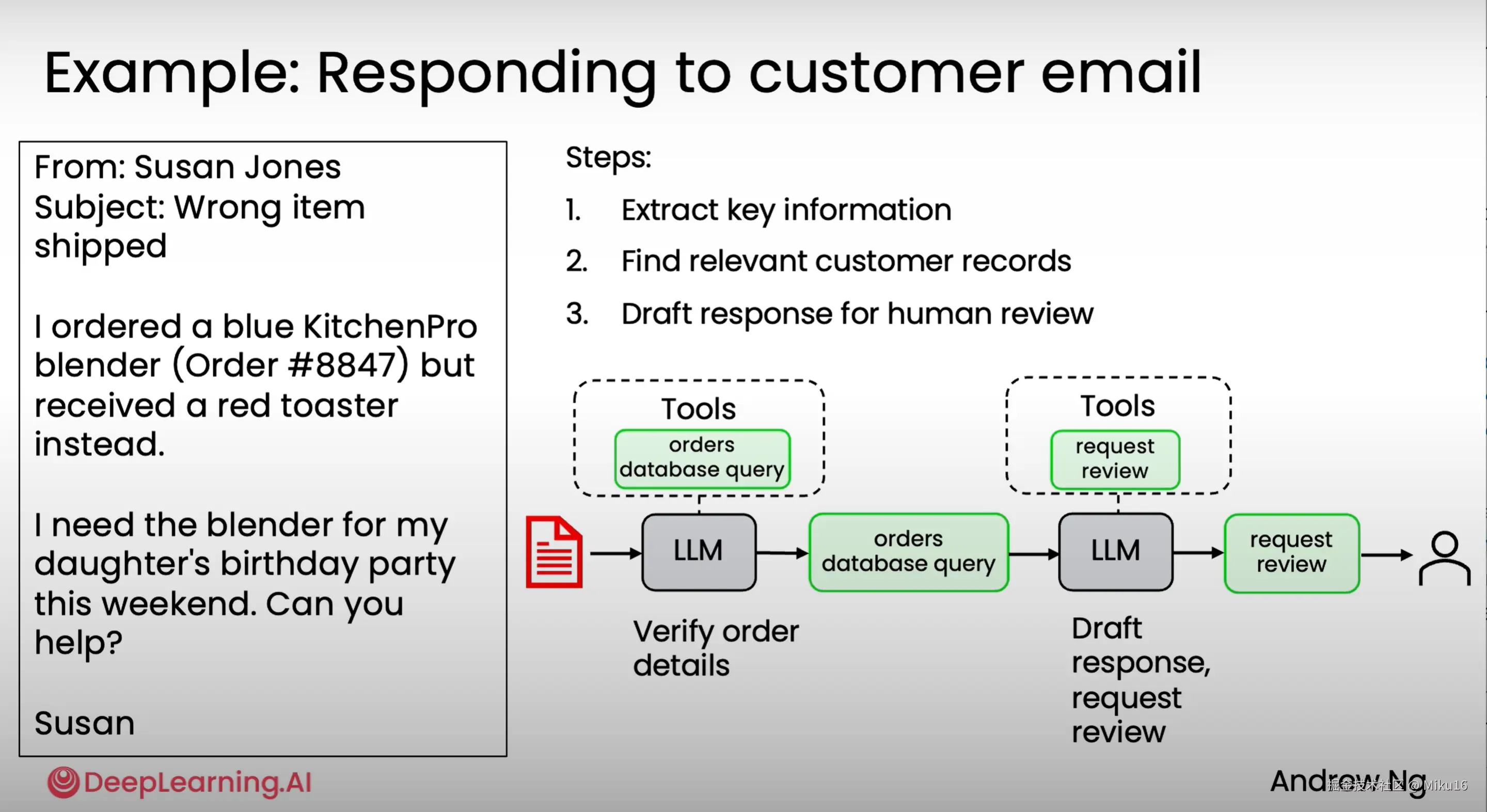
收到客户邮件,输入到LLM,进行验证或提取订单详情。当email是订单相关内容时,LLM调用订单数据库工具,查询订单数据库的记录。将订单详情发送到LLM,LLM生成回复邮件的草稿,接着LLM调用"请求审核工具",将draft草稿加入到人工审核队列中,审核通过后回复给客户。
示例3:客户服务智能体

需要具备更广泛的问题回答能力。
- 如客户查询有无黑色或蓝色牛仔裤,则agent需要查询2次库存和生成回复。
- 如客户要求退货,则需要先验证用户购买记录,检查是否符合退货政策,若符合则发起退货装箱单,并更新数据库记录状态为退货待处理。
示例4: Visual Compute Use
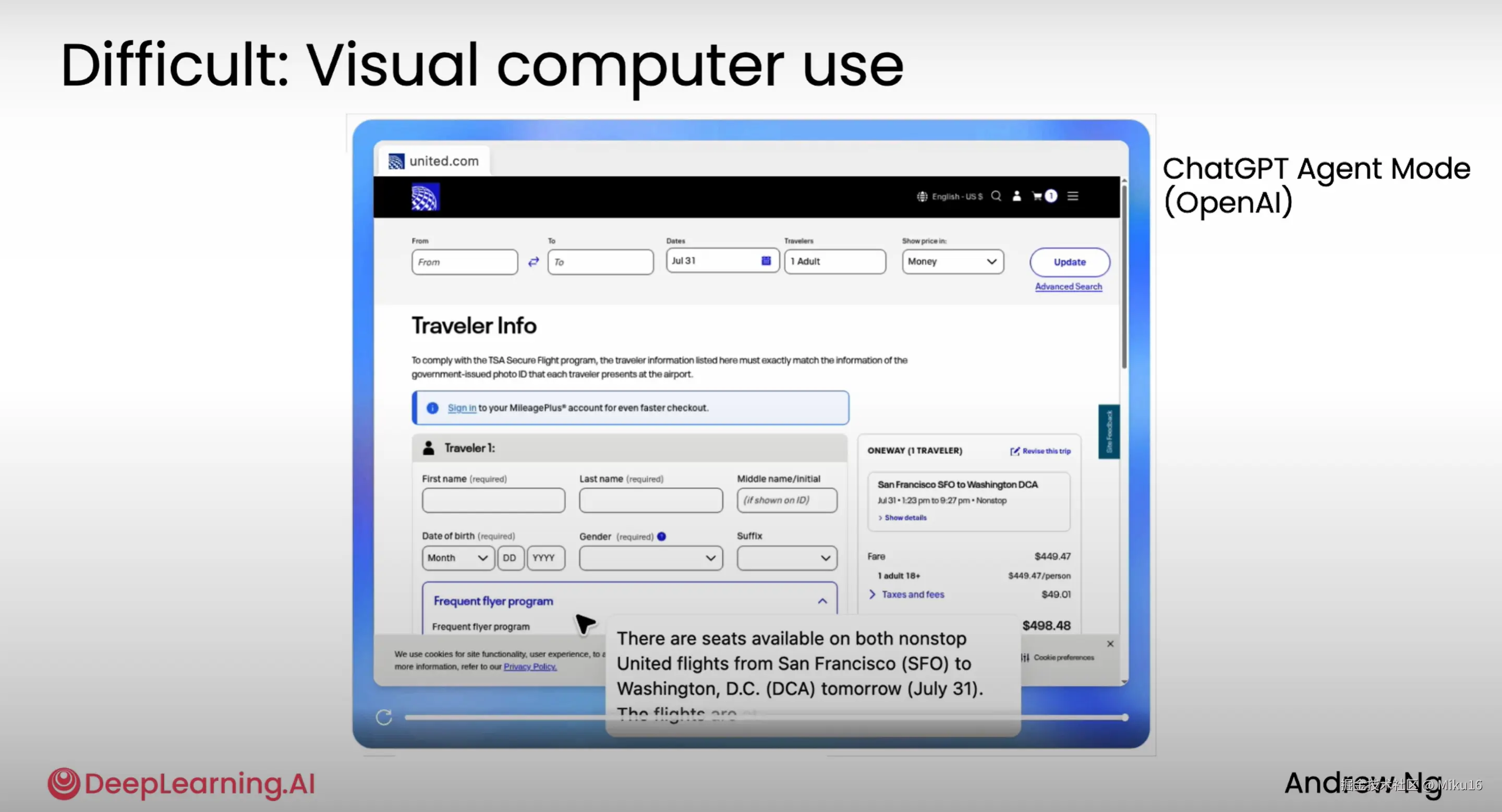
Agent根据用户指令,自动地操作浏览器查询机票信息。
总结
Task decomposition: Identifying the steps in a workflow 任务分解:识别工作流中的步骤
示例1:Research Agent for writing an Essay
直接生成:

LLM根据主题直接写文章
3步工作流:

1、根据主题写文章大纲 2、网页搜索相关内容 3、LLM根据搜索内容和大纲写文章
5步工作流:

1、根据主题写文章大纲 2、网页搜索相关内容 3、LLM根据搜索内容和大纲写文章初稿 4、考虑哪些部分需要修改 5、修改初稿

示例2:回复客户邮件

1、抽取关键信息。(LLM) 2、查找相关客户记录。(LLM+函数调用查询订单数据库信息) 3、根据订单记录写回复内容,调用email API发送回复邮件。(LLM+send email)
示例3:发票处理

1、PDF->text,找到所需信息。(LLM) 2、创建新的数据库记录。(LLM+函数调用更新订单数据库记录)
方法论总结
"So to summarize, one of the key skills in building agentic workflows is to look at a bunch of stuff that maybe someone does and to identify the discrete steps that it could be implemented with. And when I'm looking at the individual discrete steps,one question I'm always asking myself is, can this step be implemented with either an LLM or with one of the tools such as an API or a function call that I have access to? And in case the answer is no, I'll then often ask myself, how would I as a human do this step? And is it possible to decompose this further or break this down into even smaller steps that then maybe is more amenable to implementation with an LLM or with one of the software tools that I have?"
"总结来说,构建智能体工作流的关键技能之一是审视某人可能执行的一系列任务,并识别出可以将其分解为的离散步骤。当我审视各个离散步骤时,我经常问自己的一个问题是:这个步骤是否可以通过LLM或者我拥有的工具(如API或函数调用)来实现?如果答案是否定的,那么我通常会问自己:作为人类,我会如何执行这个步骤?是否有可能进一步分解这个步骤,或者将其拆分成更小的步骤,从而使其更适合用LLM或我拥有的软件工具来实现?"
Evaluation agentic AI (evals) 评估自主型 AI(evals)
使用Code进行客观评估

构建好代理式AI的要点,在于做好严格的评估过程。对agentic workflows进行评估的能力对构建workflows的能力至关重要。与其提前构建评估,更建议只需看每一步的输出结果,并手动地查找希望改进的地方。
比如该示例输出内容中不恰当地包含了竞争对手公司。许多公司不希望他们的agents提及竞争对手公司,因为很尴尬。比如agent在对话时,提到自己公司的某些服务胜于对手公司等。这种问题在构建agentic workflow前很难预料到。所以最佳实践是先构建workflows,然后检查和找出不满意的地方,然后找到评估和改进的方法,消除不满意的地方。

要避免agent提到竞争公司的名字,可以添加一个评估来跟踪记录该错误发生的频率。根据对手公司名单,编写代码,在输出内容中搜索出现了多少次的竞争对手公司名字,并统计次数,作为整体回复的一部分。由于次数是可以客观统计的,所以可以通过编写代码来检查该错误发生频率。
使用LLM进行主观评估
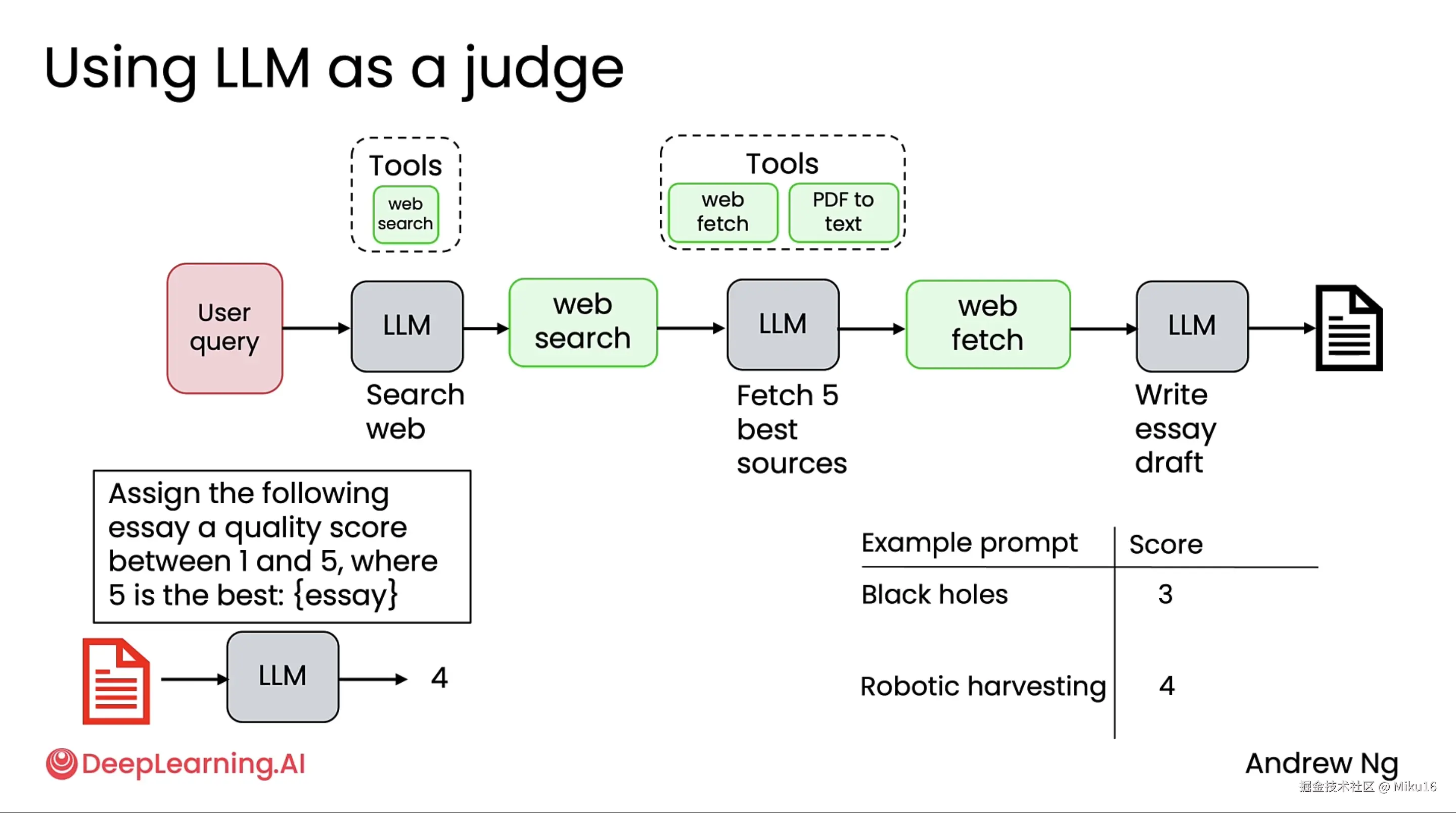
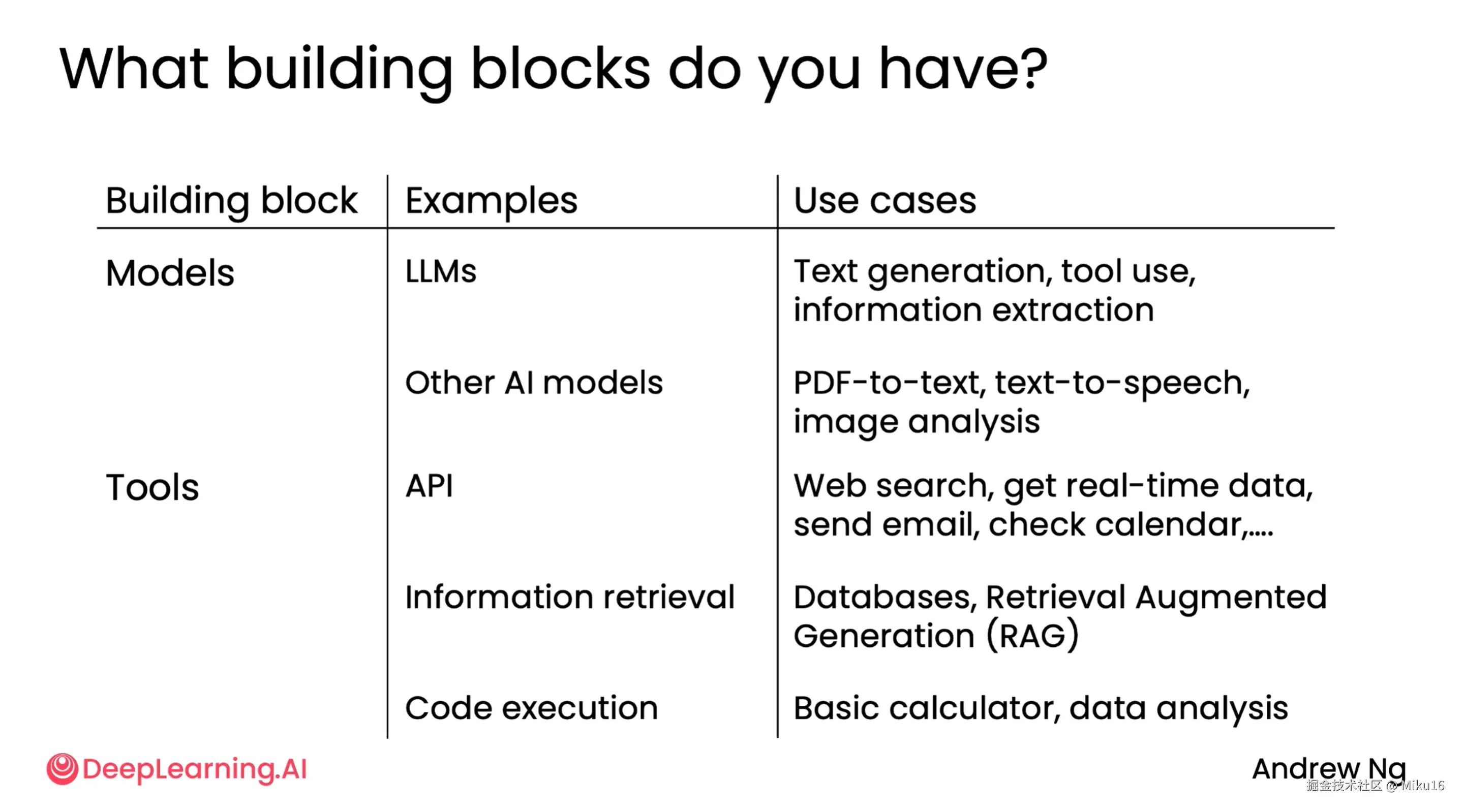
对于主观性的问题,当评估标准不清晰时,常用LLM作为评估者来评估输出内容。比如构建research agent时,用另外的一个LLM来读取agent生成的文章并进行打分。通过改进agent,从而得以看到评估分数的提高。
总结

本节所学的两种评估方式: 1、通过编写的代码进行偏客观的评估。 2、通过LLM作为裁判进行偏主观的评估。
后续 module 4 要学的评估: 1、端到端评估,需要衡量整个agent的输出质量。 2、组件级评估:需要衡量工作流每一步的输出质量。 3、评估中间结果:检查每一步的中间输出内容,以判断有哪些不符合期望,并进行改进。
Agentic design patterns 代理设计模式
四种设计模式:

四种设计模式: 1、Reflection 2、Tool use 3、Planning 4、Multi-agent collaboration
Reflection
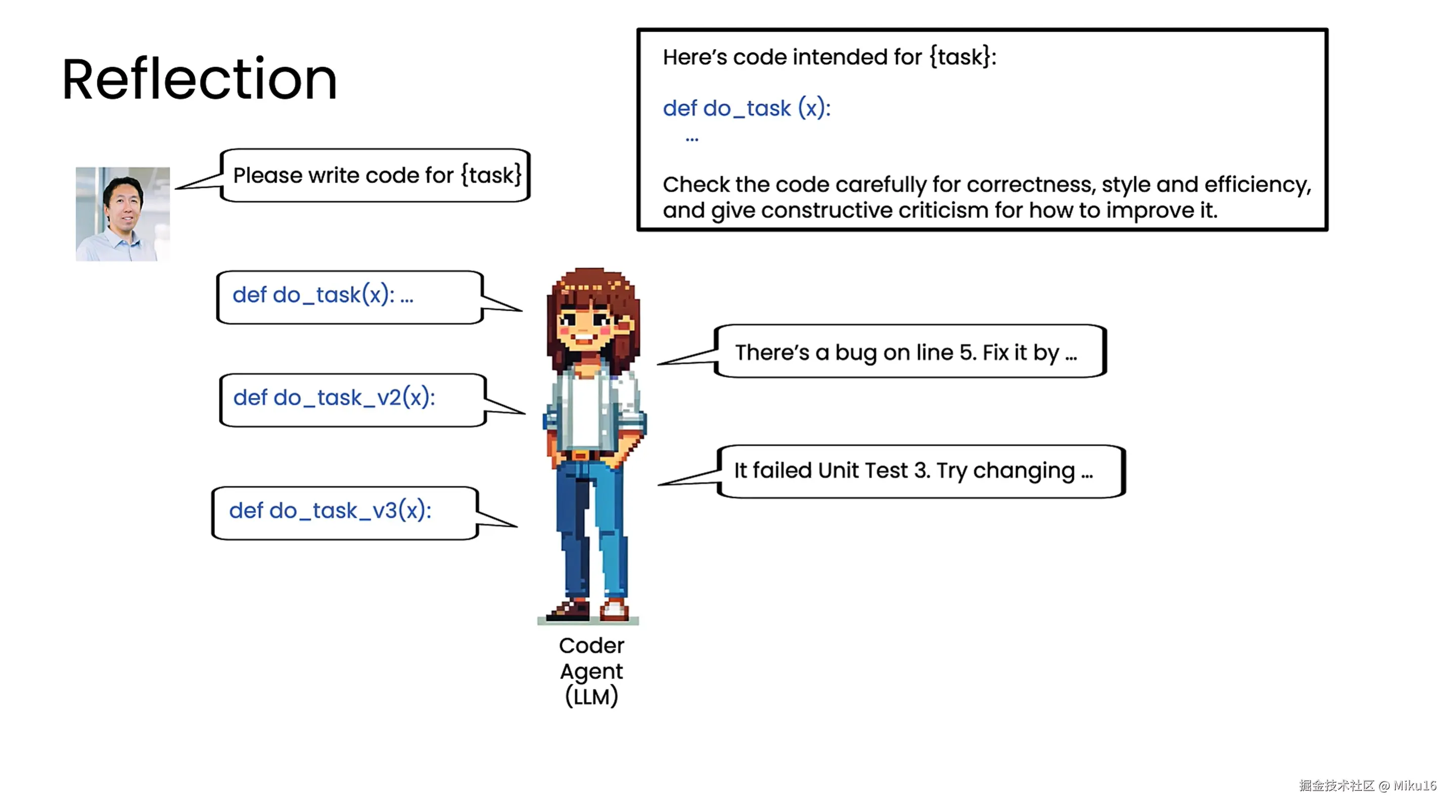
单个coder agent的reflection模式: 1、命令coder agent生成一段代码do_task用于执行某个task。 2、将do_task的内容作为提示词的一部分,命令agent生成仔细检查,并生成严谨的评判意见以帮助改进。 3、将reflect的内容交给agent,重新生成代码do_task_v2。 4、运行do_task_v2,出现报错。 5、将报错信息作为提示词的一部分,命令agent生成修复代码do_task_v3。 6、运行do_task_v3,成功执行task。
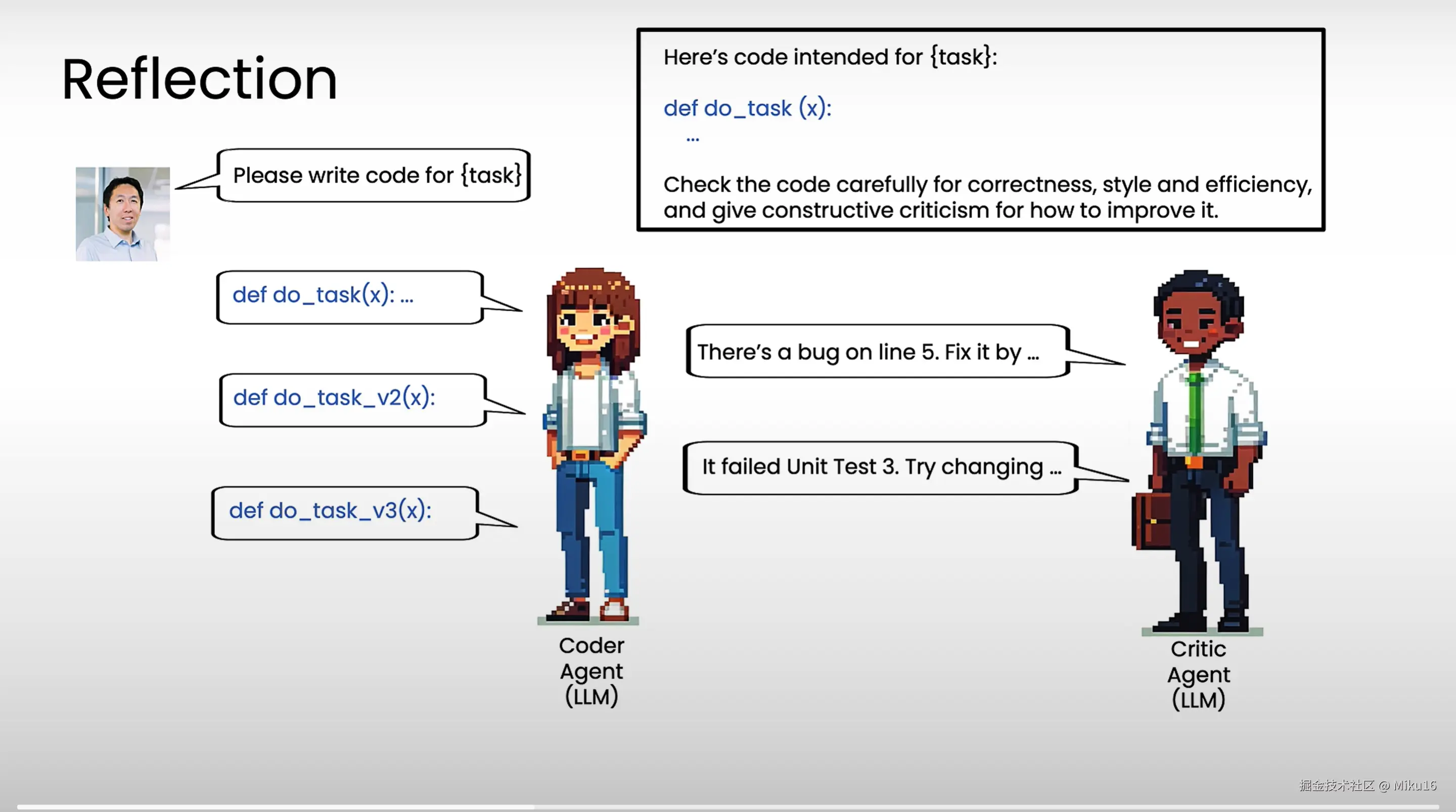
multi-agent reflection模式: 1、命令coder agent生成一段代码do_task用于执行某个task。 2、将do_task的内容作为提示词的一部分,命令critic agent生成仔细检查,并生成严谨的评判意见以帮助改进。 3、将reflect的内容交给coder agent,重新生成代码do_task_v2。 4、critic agent运行do_task_v2,出现报错。 5、将报错信息作为提示词的一部分,命令coder agent生成修复代码do_task_v3。 6、运行do_task_v3,成功执行task。
结论:Reflection是一种常见的设计模式,可以让LLM检查自己的输出结果,或者引入外部信息,比如运行代码,获取报错信息,将其作为反馈来帮助迭代和生成更优输出。
Tool use
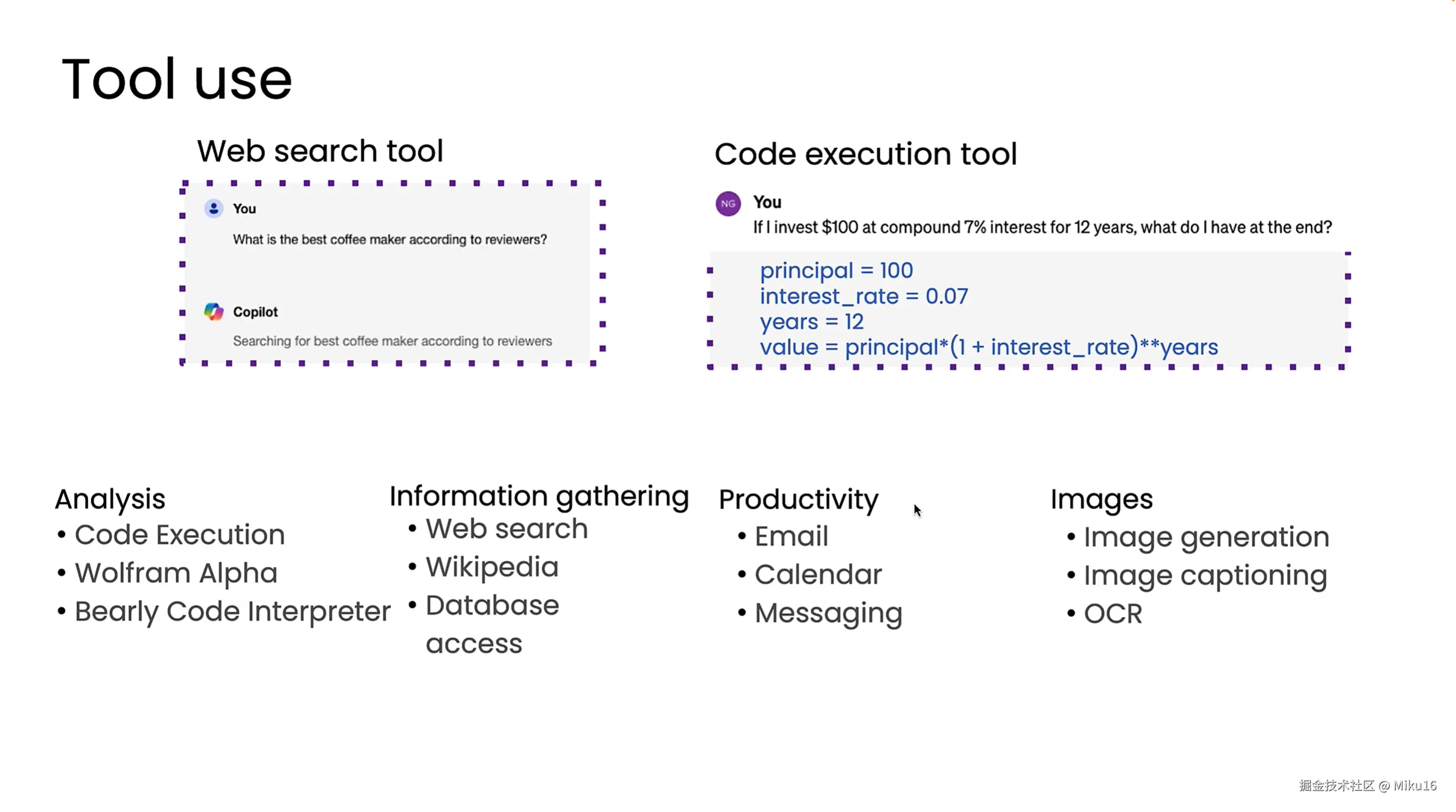
LLM+Tool/meaning function -> work
example: LLM + Web search tool -> 搜索最好的咖啡机 LLM + Code execution tool -> 计算投资回报
目前有许多工具可用,比如数据分析、信息收集、生产应用、图像处理等。LLM决定调用何种工具和函数的能力,使其功能更强。
Planning
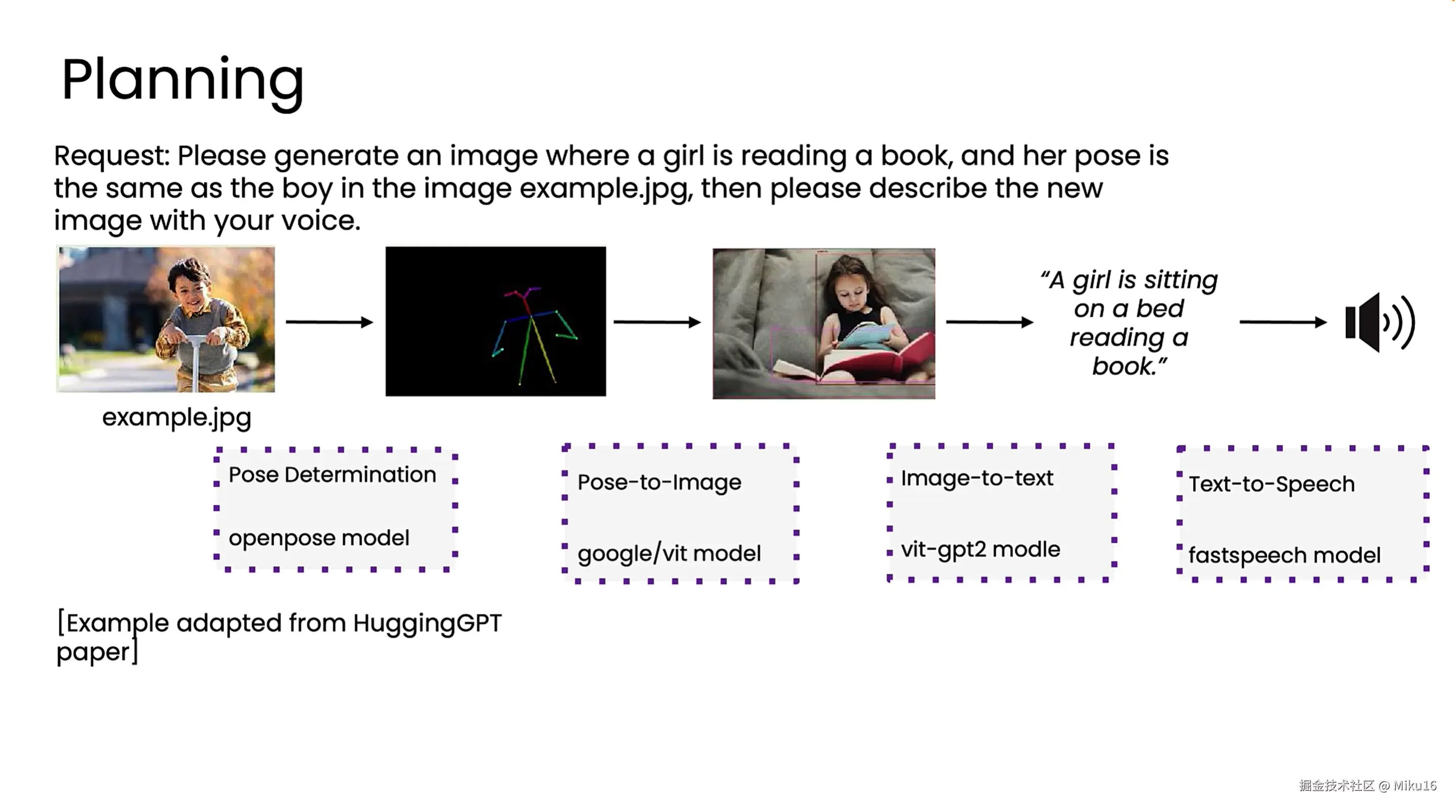
HuggingGPT的案例 1、找一个姿态确定模型来确定男孩姿态。 2、绘制姿态图。 3、根据姿态图生成女孩图片。 4、根据女孩图片生成文本描述。 5、使用TTS模型生成语音描述。
在Planning中,LLM自己决定它需要采取的行动序列。该案例中,是一系列的API顺序调用。目前,Planning还是较难控制和实验性的,但有时也有好的效果。
Multi-agent workflows

示例1:图中为ChatDev项目,多智能体有不同的角色,包括CEO,程序员,测试员,设计师等,像虚拟软件公司一样进行合作,协同完成一系列软件开发任务。
示例2:写一份营销手册。需要researcher进行研究,marketer编写营销文案,editor编辑和润色文本。构建三个agent来协同工作。