Dexbotic 开源深度解析:重构具身智能 VLA 研发的技术基石与实现路径

大家好,我是AI算法工程师七月,曾在华为、阿里任职,技术栈广泛,爱好广泛,喜欢摄影、羽毛球。目前个人在烟台有一家企业星瀚科技。
我会在这里分享关于 编程技术、独立开发、行业资讯,思考感悟 等内容。爱好交友,想加群滴滴我,wx:swk15688532358,交流分享
如果本文能给你提供启发或帮助,欢迎动动小手指,一键三连 (点赞、评论、转发),给我一些支持和鼓励,谢谢。
作者:七月 链接:julyblog 来源:七月 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Dexbotic 开源
今天的 VLA 研究分散在各个机构,每个研究团队都在用自己的规则"下棋"。他们采用不同的数据格式,基于不同的模型架构,运行在不同的实验环境中。这种碎片化的研发状态,让全球研究陷入了一场低效的"中盘缠斗"。一个根本性的问题被长期搁置:一个算法在另一个实验室表现不佳,我们很难判断,究竟是因为设计缺陷,还是仅仅因为"水土不服"。当公平比较都难以实现时,有效的知识积累与真正的技术进步又从何谈起?为打破这一困境,Dexmal 原力灵机开源了 Dexbotic。
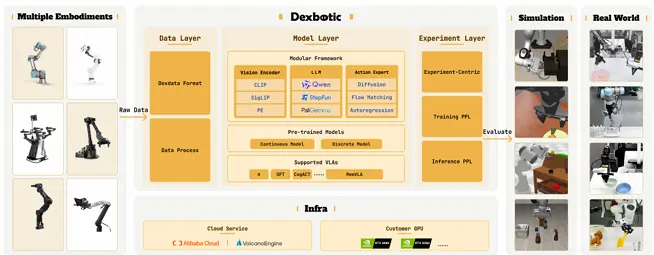
作为一套基于 PyTorch 框架的开源视觉-语言-动作模型工具箱,Dexbotic 从数据、模型到实验三个层面,为具身智能研究者提供了一种标准化、模块化且高性能的一站式科研基础设施。它的出现,显著提升 VLA研究的工程效率,或将为具身智能落下"第三十七手"。
这次的 Dexbotic,解决的是"训练标准缺失"的问题。
就像计算机视觉有 MMDetection,NLP 有 Transformers 库,Dexbotic 试图成为具身智能领域的标准化工具箱。
添加图片注释,不超过 140 字(可选)
总结来说,Dexbotic 提供了一套同时支持多个主流 VLA 算法的代码库,用户只需配置一次环境,基于所提供的预训练模型,即可在各类仿真环境中复现各类主流 VLA 算法。
不用再从头配环境,不用再猜别人的参数,更不用担心预训练模型过时。
老规矩,先放传送门:
官网: Dexbotic Paper : dexbotic.com/Dexbotic_Te... GitHub: github.com/Dexmal/dexb... Hugging Face: huggingface.co/collections...
现在我们一起看看 Dexbotic 到底做了什么?
Dexbotic 做了什么?
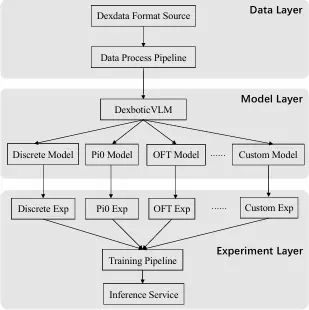
简单点说,Dexbotic 做了三件事:统一框架、统一数据、提供更强的预训练模型 。
统一数据
传统VLA研究经常因为数据往往格式各异、命名混乱,视频、传感器状态与文本描述难以统一对齐而陷入混乱,各种信息常需手工对齐,既耗时又易错。
对此,Dexbotic设计了一种名为Dexdata的统一高效的数据格式,为UR5、Franka、ALOHA、ARX5等多款主流机器人提供统一的数据格式。
在Dexdata格式中,所有内容被结构化存储为两个核心目录:视频目录与JSONL目录,视频目录中存储.mp4格式的视频文件,而JSONL目录中存储对应的文本信息。每个JSONL文件包含单个机器人任务的完整数据,还包含index_cache.json文件,用于记录所有任务的元数据并加速数据访问。
基于Dexdata格式的数据,系统将自动执行数据处理流程,提取图像、文本及状态信息用于模型训练,提高训练效率。相比Lerobot与RLDS等格式,Dexdata在数据加载与模型训练阶段能显著节省存储空间。
添加图片注释,不超过 140 字(可选)
数据标准化是研究的基础,实则决定了后续多机器人、多视角的可拓展性,也决定了具身智能的规模化发展潜力。
Dexdata的创新之处,就在于没有局限于单一机器人类型,而是构建了可拓展的通用框架,让不同机器人的数据能够在同一框架下复用。Dexmal原力灵机团队还表示,他们将持续扩展Dexdata的适配范围,让更多机器人平台接入这一标准。把所有 VLA 模型抽象成两部分:视觉-语言模型(VLM)+ 动作专家(Action Expert)。VLM 负责「看懂」和「理解」,Action Expert 负责「执行」。这样一来,不管你用的是扩散模型还是流匹配,底层的 VLM 都可以复用,就这么简单。
提供更强的预训练模型
Dexbotic从零开始预训练了视觉-语言模型DexboticVLM, 既可以直接支持离散VLA训练,也可以作为现有VLA策略的基座模型。该模型采用模块化设计,整合了CLIP作为视觉编码器、两层MLP作为投影层、Qwen2.5作为大语言模型。
Dexbotic 提供了两种预训练模型:
离散型预训练模型(Dexbotic-Base): 适用于通用VLA策略,模型使用了来自Open-X Embodiment数据集、RLBench、Libero、Maniskill2等多个仿真器的数据,并融合了UR5等真实机械人的数据。,用离散化token形式来学习动作空间。研究者可直接在此模型上微调,复现π0、OFT、CogACT、MemoryVLA等主流算法,而无需从零训练。
添加图片注释,不超过 140 字(可选)
连续型预训练模型(Dexbotic-CogACT): 专为连续动作策略设计,包括单臂和双臂两个版本。单臂模型基于Dexbotic-Base进行连续表征预训练,数据来自Open-X Embodiment子集与团队私有数据集;双臂版本包含来自8种真实单臂机器人(UR5、Franka、UniTree Z1、Realman GEN72、ARX5等)的52个任务数据,还进一步引入Robomind、AgiBot World 及 ALOHA双臂数据,以支持多视角输入与双臂任务。
Dexbotic这种同时覆盖离散与连续动作策略的设计,精准击中了当前VLA研究的核心需求差异,既兼顾了学术研究的开放性,又考虑了产业落地的实用性。
目前,DexboticVLM了同时提供支持π0、OpenVLA-OFT、CogACT、MemoryVLA等多种VLA策略的统一代码库,用户仅需一次环境配置即可复现多种VLA方法。另外,用户也可以便捷地自定义新的VLA模型。这就让研究者无需重复搭建环境,也能轻松横向比较不同策略的性能,从而在统一标准下推动算法的进化。
基于最新的 Qwen2.5,从头预训练了一个视觉-语言模型,叫 DexboticVLM 。然后,基于这个模型,重新训练了几个主流的 VLA 算法------Pi0、CogACT、OpenVLA-OFT、MemoryVLA。效果也很明显。
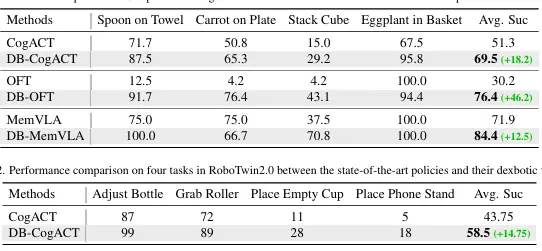
拿 SimplerEnv 这个仿真环境来说,它包含 4 个操作任务:把勺子放在毛巾上、把胡萝卜放在盘子上、堆叠方块、把茄子放进篮子。
CogACT 官方版本的平均成功率是 51.3%,用了 Dexbotic 的预训练模型之后,直接飙到 69.5%------提升了 18 个百分点。

添加图片注释,不超过 140 字(可选)
OFT 更夸张:官方版本只有 30.2%,用了 Dexbotic 之后变成 76.4%------提升了 46 个百分点。
再看 CALVIN 这个长时任务基准。它要求机器人连续完成多个指令,比如"先打开抽屉,再拿出红色方块,然后放到桌上"。这考验的是机器人的长时记忆和任务规划能力。CogACT 官方版本平均能连续完成 3.25 个任务,用了 Dexbotic 之后能完成 4.06 个------提升了 25%。
意味着同样的算法,用了更好的基础模型,性能起飞了。
当然,仿真环境的成功率再高,也不如真机测试来得实在。
Dexmal 原力灵机团队在真实机器人上做了大量实验,包括 UR5e、Franka、ALOHA、ARX5 等多种平台。

添加图片注释,不超过 140 字(可选)
从视频可以看到,有些任务的成功率已经很高了------比如用 UR5e 摆盘子,成功率达到 100%;用 ALOHA 叠碗,成功率 90%;用 ARX5 搜索绿色盒子,成功率 80%。
统一框架
在传统的VLA开发流程中,研究者需要手动配置大量YAML文件,这些配置复杂、易错,不仅浪费大量时间,也容易让科研的可复现性陷入混乱。
而Dexbotic秉持着"实验为中心"的理念,重塑了这一流程。它创新性引入的实验脚本机制, 把一套复杂的实验配置,简化为一套可继承的脚本体系,在确保系统稳定性的同时支持快速实验迭代开发。
具体来说,用户不再需要手动维护庞杂的配置文件,可基于base_exp脚本继承配置,修改优化器、数据、模型等字段,不必复制完整文件即可创建新的实验方案。运行命令格式为:python xxx_exp.py -task train。
这样的机制就意味着,研究人员的时间不再浪费在环境修补与路径兼容上,而能真正投入到算法优化本身,提升研究单位产出。不仅提升了个体效率,更能加速整个行业的技术迭代速度,形成良性创新循环。
Dexbotic同时支持云端与本地一体化训练, 它既可运行在阿里云、火山引擎等大规模云训练平台上,也适配RTX 4090等消费级显卡的本地训练环境。这让研究门槛被大幅降低,中小型团队甚至个人研究者,都可以以更低成本参与到具身智能的创新浪潮中。可以说,Dexbotic让做实验本身重新变成了一件轻松、高效且透明的事情。