
Java 大视界 -- Java 大数据机器学习模型在智能客服多轮对话系统中的优化策略
- 引言
- 正文
-
-
- 一、智能客服多轮对话系统现状及挑战
-
- [1.1 行业现状](#1.1 行业现状)
- [1.2 面临挑战](#1.2 面临挑战)
- [二、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的技术概述](#二、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的技术概述)
-
- [2.1 技术原理](#2.1 技术原理)
- [2.2 技术优势](#2.2 技术优势)
- [三、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的优化策略](#三、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的优化策略)
-
- [3.1 数据预处理优化](#3.1 数据预处理优化)
- [3.2 模型选择与优化](#3.2 模型选择与优化)
- [3.3 对话策略优化](#3.3 对话策略优化)
- 四、实际案例分析
-
- [4.1 系统实施](#4.1 系统实施)
- [4.2 实施效果](#4.2 实施效果)
-
- 结束语
- 🗳️参与投票和联系我:
引言
亲爱的 Java 和 大数据爱好者们,大家好!在数字化转型的浪潮中,Java 大数据技术凭借强大的功能与丰富的生态,为诸多行业带来了深刻变革。
随着互联网和人工智能技术的飞速发展,客户服务场景变得日益复杂多样。智能客服作为提升服务效率和质量的重要手段,在各行业得到了广泛应用。多轮对话系统作为智能客服的核心组成部分,能够与客户进行自然、流畅的交互,深入理解客户需求,提供更加精准、个性化的服务。然而,构建高效、准确的多轮对话系统并非易事,面临着意图识别不准确、对话逻辑混乱、知识储备不足,以及在复杂业务场景下难以满足客户多样化需求等诸多挑战。基于 Java 的大数据机器学习模型,为智能客服多轮对话系统的优化提供了系统性的解决方案。本文将深入探讨这一技术在智能客服领域的应用,结合真实案例与详实代码,为智能客服开发者、数据科学家以及技术爱好者,提供极具实操价值的技术参考。

正文
一、智能客服多轮对话系统现状及挑战
1.1 行业现状
近年来,智能客服在金融、电商、电信等多个行业得到了广泛应用,显著提升了客户服务的效率和质量,成为企业数字化转型的重要组成部分。
-
金融行业:智能客服在金融行业的应用,极大地提高了服务效率和客户满意度。以招商银行为例,其智能客服 "小招" 能够快速响应客户的咨询,解答账户查询、理财产品介绍、贷款业务办理等常见问题。据统计,"小招" 每天能够处理数十万条客户咨询,解答率高达 85% 以上,有效减轻了人工客服的工作压力,提升了银行的服务能力。
-
电商行业:电商平台的智能客服为客户提供了便捷的购物体验。以阿里巴巴的阿里小蜜为例,它可以为客户提供商品推荐、订单查询、售后服务等一站式服务。在 "双 11" 等购物高峰期,阿里小蜜每天能够处理数亿条客户咨询,为电商平台的稳定运营和销售增长提供了有力保障。
-
电信行业:电信运营商的智能客服帮助客户解决业务办理、账单查询、故障报修等问题。以中国移动的智能客服为例,它能够通过自然语言交互,快速为客户办理业务,提高了服务的便捷性和及时性。据统计,中国移动的智能客服每月能够处理数千万条客户咨询,客户满意度达到 80% 以上。
1.2 面临挑战
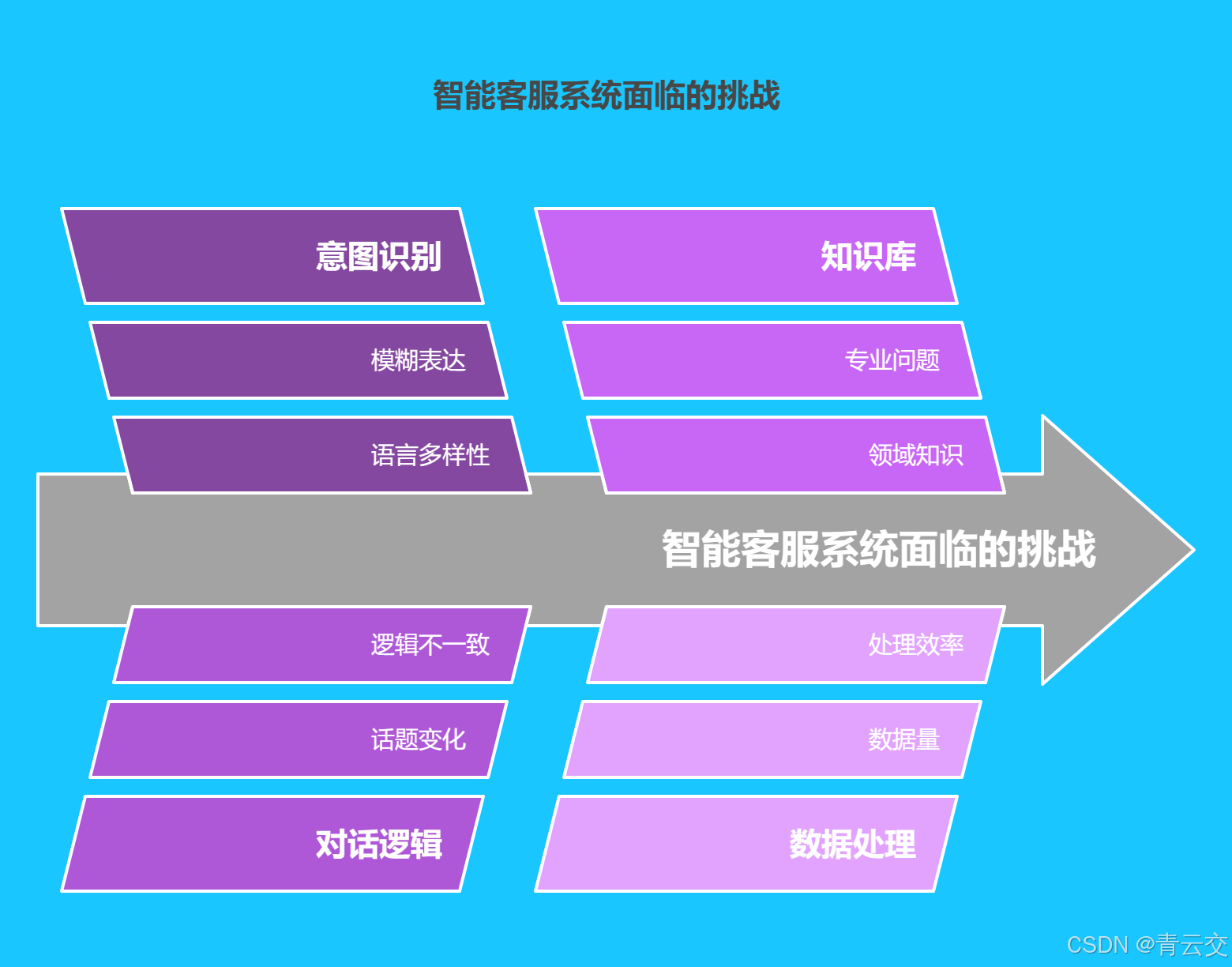
尽管智能客服多轮对话系统在行业内得到了广泛应用,但在实际使用过程中,仍然面临着一系列严峻的挑战。
-
意图识别难题:自然语言具有高度的复杂性和多样性,客户的表达方式千差万别,这给意图识别带来了极大的困难。客户可能使用模糊、隐喻、口语化的语言进行提问,甚至存在语法错误,导致智能客服无法准确理解客户的意图。例如,客户可能会问 "我最近手头紧,有没有什么好办法",智能客服很难直接判断客户是需要贷款服务,还是寻求理财建议。
-
对话逻辑混乱:多轮对话系统需要维护清晰的对话逻辑,确保对话的连贯性和一致性。然而,在实际应用中,由于对话场景的复杂性和不确定性,对话逻辑容易出现混乱。例如,在一次多轮对话中,客户可能突然改变话题,或者提出与之前话题相关但又有所不同的问题,智能客服如果不能及时调整对话逻辑,就会导致客户体验下降。
-
知识储备不足:智能客服的知识储备有限,对于一些专业性强、领域知识丰富的问题,往往无法给出准确的回答。例如,在金融领域,对于一些复杂的金融产品和投资策略,智能客服可能无法提供详细的解释和建议。
-
数据处理压力:随着数据量的不断增长,如何高效地处理和分析海量的客户对话数据,也是智能客服多轮对话系统面临的重要挑战。传统的数据处理方法在面对大规模数据时,往往存在处理速度慢、效率低等问题,无法满足智能客服实时性的要求。
二、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的技术概述
2.1 技术原理
基于 Java 的大数据机器学习模型在智能客服多轮对话系统中,主要涉及自然语言处理(NLP)、深度学习、大数据处理等技术。这些技术相互融合,为智能客服多轮对话系统的优化提供了强大的技术支持。
2.1.1 自然语言处理(NLP):自然语言处理技术是智能客服多轮对话系统的基础,它主要包括词法分析、句法分析、语义理解、文本生成等模块。
-
词法分析:词法分析用于将文本分割成单词或词组,识别词性和词形变化。在 Java 中,可以使用 HanLP 工具包实现词法分析功能。HanLP 提供了丰富的词法分析算法,能够准确地对中文文本进行分词和词性标注。例如:
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;import java.util.List;
public class LexicalAnalysis {
public static void main(String[] args) {
String text = "我想查询账户余额";
ListtermList = HanLP.segment(text);
for (Term term : termList) {
System.out.println(term);
}
}
} -
句法分析:句法分析用于分析句子的语法结构,确定句子的主谓宾、定状补等成分。Stanford CoreNLP 是一个功能强大的自然语言处理工具包,在 Java 中可以使用它进行句法分析。示例代码如下:
import edu.stanford.nlp.pipeline.CoreDocument;
import edu.stanford.nlp.pipeline.CorePipeline;
import java.util.Properties;public class SyntacticAnalysis {
public static void main(String[] args) {
String text = "我在电商平台上购买了商品";
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, parse");
CorePipeline pipeline = new CorePipeline(props);
CoreDocument document = new CoreDocument(text);
pipeline.annotate(document);
System.out.println(document.sentences().get(0).dependencyParse());
}
} -
语义理解:语义理解用于理解文本的含义,识别客户的意图。语义理解是自然语言处理中的关键环节,它需要结合词法分析、句法分析和语境信息,准确地理解客户的需求。
-
文本生成:文本生成用于根据对话策略和客户需求,生成相应的回复文本。文本生成需要考虑语言的流畅性、准确性和合理性,以提供自然、友好的对话体验。
2.1.2 深度学习:深度学习技术在自然语言处理领域取得了显著的成果,为智能客服多轮对话系统的优化提供了强大的技术支持。常用的深度学习模型包括循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)、Transformer 等。
-
RNN 及其变体:RNN 能够处理序列数据,在自然语言处理中得到了广泛应用。LSTM 和 GRU 是 RNN 的变体,它们通过引入门控机制,解决了 RNN 中的梯度消失和梯度爆炸问题,能够更好地处理长序列数据。
-
Transformer:Transformer 模型采用了自注意力机制,能够更好地捕捉文本中的长距离依赖关系,在机器翻译、文本摘要、问答系统等任务中取得了优异的成绩。在 Java 中,可以使用 Deeplearning4j 框架实现 Transformer 模型。
2.1.3 大数据处理:随着智能客服产生的对话数据量不断增长,需要借助大数据处理技术对海量数据进行高效的存储、处理和分析。常用的大数据处理框架包括 Hadoop、Spark 等。
-
Hadoop:Hadoop 采用分布式文件系统(HDFS)和 MapReduce 计算模型,能够实现大规模数据的分布式存储和并行计算。HDFS 将数据分割成多个块,存储在不同的节点上,提高了数据的可靠性和可用性。MapReduce 则将大规模数据处理任务分解为多个小任务,在多个节点上并行执行,提高了数据处理的效率。
-
Spark:Spark 在 Hadoop 的基础上进行了优化,引入了弹性分布式数据集(RDD)的概念,支持内存计算,大大提高了数据处理的速度。Spark 还提供了丰富的机器学习库和自然语言处理库,方便开发者进行数据处理和模型训练。
2.2 技术优势
与传统的智能客服技术相比,基于 Java 的大数据机器学习模型具有显著的优势。
-
跨平台性与丰富类库:Java 作为一种广泛应用的编程语言,具有良好的跨平台性,能够在不同的操作系统和硬件环境中运行。同时,Java 拥有丰富的类库,涵盖了自然语言处理、深度学习、大数据处理等多个领域,为开发者提供了便捷的开发工具。
-
数据驱动的学习能力:大数据机器学习模型能够充分利用海量的客户对话数据,通过深度学习算法自动学习客户的语言习惯、行为模式和需求偏好,提高智能客服的准确性和适应性。随着数据量的不断增加,模型的性能也会不断提升。
-
高效的数据处理能力:这些技术能够与大数据处理框架进行深度集成,实现对海量数据的高效处理和分析。通过分布式计算和并行处理技术,能够快速处理大规模的客户对话数据,满足智能客服在实际应用中的性能要求。
-
良好的可扩展性和灵活性:基于 Java 的大数据机器学习模型具有良好的可扩展性和灵活性,能够根据业务需求和场景变化进行定制化开发。开发者可以根据实际情况选择合适的技术和模型,对智能客服多轮对话系统进行优化和升级。
三、基于 Java 的大数据机器学习模型在智能客服多轮对话系统中的优化策略
3.1 数据预处理优化
数据预处理是构建智能客服多轮对话系统的重要环节,它直接影响到机器学习模型的训练效果和性能。在数据采集阶段,应尽可能收集多样化、高质量的客户对话数据,包括不同行业、不同场景、不同表达方式的对话数据。在数据清洗阶段,需要去除数据中的噪声、重复数据和无效数据,提高数据的质量。在数据标注阶段,应准确标注客户的意图和对话行为,为模型训练提供准确的标签。
3.1.1 数据采集:数据采集是数据预处理的第一步,采集到的数据质量直接影响后续的分析和模型训练。可以通过多种渠道收集客户对话数据,如在线客服聊天记录、电话客服录音转文字、社交媒体评论等。在采集数据时,应注意数据的多样性和代表性,确保数据能够覆盖各种对话场景和客户需求。
3.1.2 数据清洗:数据清洗是去除数据中的噪声、重复数据和无效数据的过程。以下是使用 Java 实现数据清洗的示例代码,包括去除 HTML 标签、特殊字符和停用词等操作:
java
import java.util.regex.Pattern;
import java.util.Set;
import java.util.HashSet;
public class DataCleaning {
// 去除文本中的HTML标签
public static String removeHtmlTags(String text) {
return Pattern.compile("<[^>]+>").matcher(text).replaceAll("");
}
// 去除文本中的特殊字符
public static String removeSpecialCharacters(String text) {
return text.replaceAll("[^a-zA-Z0-9\\s]", "");
}
// 去除停用词
public static String removeStopWords(String text) {
Set<String> stopWords = new HashSet<>();
// 添加常用停用词
stopWords.add("的");
stopWords.add("了");
stopWords.add("是");
StringBuilder result = new StringBuilder();
for (String word : text.split(" ")) {
if (!stopWords.contains(word)) {
result.append(word).append(" ");
}
}
return result.toString().trim();
}
public static void main(String[] args) {
String dirtyText = "<p>我想, 查询账户余额!</p>";
String cleanText = removeStopWords(removeSpecialCharacters(removeHtmlTags(dirtyText)));
System.out.println("原始文本: " + dirtyText);
System.out.println("清洗后文本: " + cleanText);
}
}3.1.3 数据标注:数据标注是为数据添加标签的过程,以便模型能够学习到数据中的模式和规律。在智能客服多轮对话系统中,需要标注客户的意图和对话行为。可以采用人工标注和自动标注相结合的方式,提高标注的效率和准确性。
3.2 模型选择与优化
选择合适的机器学习模型是构建高效智能客服多轮对话系统的关键。在实际应用中,应根据业务需求和数据特点,选择最适合的模型。例如,对于意图识别任务,可以选择基于 Transformer 的 BERT 模型,它在自然语言理解任务中表现出色;对于对话生成任务,可以选择基于循环神经网络的 Seq2Seq 模型,它能够生成连贯、自然的回复文本。同时,还可以通过调优模型参数、增加训练数据量、采用模型融合等方法,进一步提高模型的性能。
3.2.1 意图识别模型:基于 Transformer 的 BERT 模型在意图识别任务中表现优异。以下是使用 Java 和 Deeplearning4j 实现简单的文本分类模型(可用于意图识别)的示例代码,通过详细的注释帮助理解模型的构建和训练过程:
java
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.util.ArrayList;
import java.util.List;
public class TextClassification {
public static void main(String[] args) throws Exception {
// 生成模拟文本数据和标签
List<INDArray> featuresList = new ArrayList<>();
List<INDArray> labelsList = new ArrayList<>();
// 模拟数据添加逻辑,此处简单模拟一些数据
for (int i = 0; i < 100; i++) {
INDArray feature = Nd4j.rand(1, 10);
INDArray label = Nd4j.zeros(1, 2);
label.putScalar(0, i % 2, 1);
featuresList.add(feature);
labelsList.add(label);
}
INDArray features = Nd4j.stack(featuresList, 0);
INDArray labels = Nd4j.stack(labelsList, 0);
DataSet dataSet = new DataSet(features, labels);
SplitTestAndTrain testAndTrain = dataSet.splitTestAndTrain(0.8);
DataSet trainingData = testAndTrain.getTrain();
DataSet testData = testAndTrain.getTest();
int numInputs = features.columns();
int numOutputs = labels.columns();
MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new DenseLayer.Builder().nIn(numInputs).nOut(100)
.activation(Activation.RELU).build())
.layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOGLOSS)
.nIn(100).nOut(numOutputs).activation(Activation.SOFTMAX).build())
.build();
MultiLayerNetwork model = new MultiLayerNetwork(config);
model.init();
model.setListeners(new ScoreIterationListener(10));
DataSetIterator trainIter = new ListDataSetIterator(trainingData.asList(), 16);
for (int i = 0; i < 10; i++) {
model.fit(trainIter);
}
DataSetIterator testIter = new ListDataSetIterator(testData.asList(), 16);
Evaluation eval = new Evaluation(numOutputs);
while (testIter.hasNext()) {
DataSet t = testIter.next();
INDArray output = model.output(t.getFeatures());
eval.eval(t.getLabels(), output);
}
System.out.println(eval.stats());
}
}3.2.2 对话生成模型:基于循环神经网络的 Seq2Seq 模型在对话生成任务中应用广泛。下面通过 Java 和 Deeplearning4j 实现一个简易的 Seq2Seq 模型,借助详细注释,助力理解模型的构建与训练过程:
java
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.GradientNormalization;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.GravesLSTM;
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.util.ArrayList;
import java.util.List;
public class Seq2SeqModel {
public static void main(String[] args) throws Exception {
int batchSize = 16;
int timeSteps = 10;
int inputSize = 5;
int outputSize = 5;
List<INDArray> inputList = new ArrayList<>();
List<INDArray> labelList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
INDArray input = Nd4j.randn(batchSize, timeSteps, inputSize);
INDArray label = Nd4j.randn(batchSize, timeSteps, outputSize);
inputList.add(input);
labelList.add(label);
}
INDArray inputData = Nd4j.stack(inputList, 0);
INDArray labelData = Nd4j.stack(labelList, 0);
DataSet dataSet = new DataSet(inputData, labelData);
SplitTestAndTrain testAndTrain = dataSet.splitTestAndTrain(0.8);
DataSet trainingData = testAndTrain.getTrain();
DataSet testData = testAndTrain.getTest();
MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.weightInit(WeightInit.XAVIER)
.gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue)
.gradientNormalizationThreshold(1.0)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(inputSize)
.nOut(100)
.activation(Activation.TANH)
.build())
.layer(1, new RnnOutputLayer.Builder(LossFunctions.LossFunction.MSE)
.nIn(100)
.nOut(outputSize)
.activation(Activation.IDENTITY)
.build())
.build();
MultiLayerNetwork model = new MultiLayerNetwork(config);
model.init();
model.setListeners(new ScoreIterationListener(10));
DataSetIterator trainIter = new ListDataSetIterator(trainingData.asList(), batchSize);
for (int i = 0; i < 10; i++) {
model.fit(trainIter);
}
DataSetIterator testIter = new ListDataSetIterator(testData.asList(), batchSize);
Evaluation eval = new Evaluation(outputSize);
while (testIter.hasNext()) {
DataSet t = testIter.next();
INDArray output = model.output(t.getFeatures());
eval.evalTimeSeries(t.getLabels(), output);
}
System.out.println(eval.stats());
}
}3.2.3 模型优化技巧:
-
参数调优:借助随机搜索、网格搜索等方法,寻找模型的最优超参数。以网格搜索为例,通过设定不同参数值的组合,对模型进行训练和评估,从而确定最优参数。
-
增加训练数据量:收集更多的客户对话数据,丰富数据的多样性,以提升模型的泛化能力。
-
模型融合:将多个不同的模型进行融合,如将 BERT 模型和 LSTM 模型进行融合,综合利用不同模型的优势,提高模型的性能。下面以简单的加权平均融合为例,展示模型融合的实现思路:
java
// 假设已经训练好model1和model2
INDArray output1 = model1.output(features);
INDArray output2 = model2.output(features);
// 设定融合权重
double weight1 = 0.6;
double weight2 = 0.4;
INDArray finalOutput = output1.mul(weight1).add(output2.mul(weight2));3.3 对话策略优化
对话策略决定了智能客服如何与客户进行交互,是影响客户体验的重要因素。在设计对话策略时,应充分考虑客户的需求和心理,采用合理的对话流程和话术。除了常规的对话策略,还可引入知识图谱和强化学习,提升对话的质量和效果。
-
常规对话策略:在对话开始时,主动问候客户,了解客户的需求;在对话过程中,及时回应客户的问题,提供准确、有用的信息;在对话结束时,询问客户是否还有其他需求,确保客户的问题得到彻底解决。同时,采用个性化的对话策略,根据客户的历史记录和偏好,提供个性化的服务。
-
引入知识图谱:知识图谱能够整合多源知识,为智能客服提供丰富的知识支持。通过知识图谱,智能客服可以更好地理解客户的问题,提供更准确的回答。例如,在金融领域,构建金融知识图谱,将金融产品、投资策略、市场动态等知识进行整合,当客户提出相关问题时,智能客服可以从知识图谱中获取信息,给出准确的解答。
-
强化学习优化:强化学习通过让智能客服在与客户的交互过程中不断学习,优化对话策略。智能客服根据客户的反馈,调整对话策略,以最大化客户满意度。下面通过简单的 Q - Learning 算法,展示强化学习在对话策略优化中的应用思路:
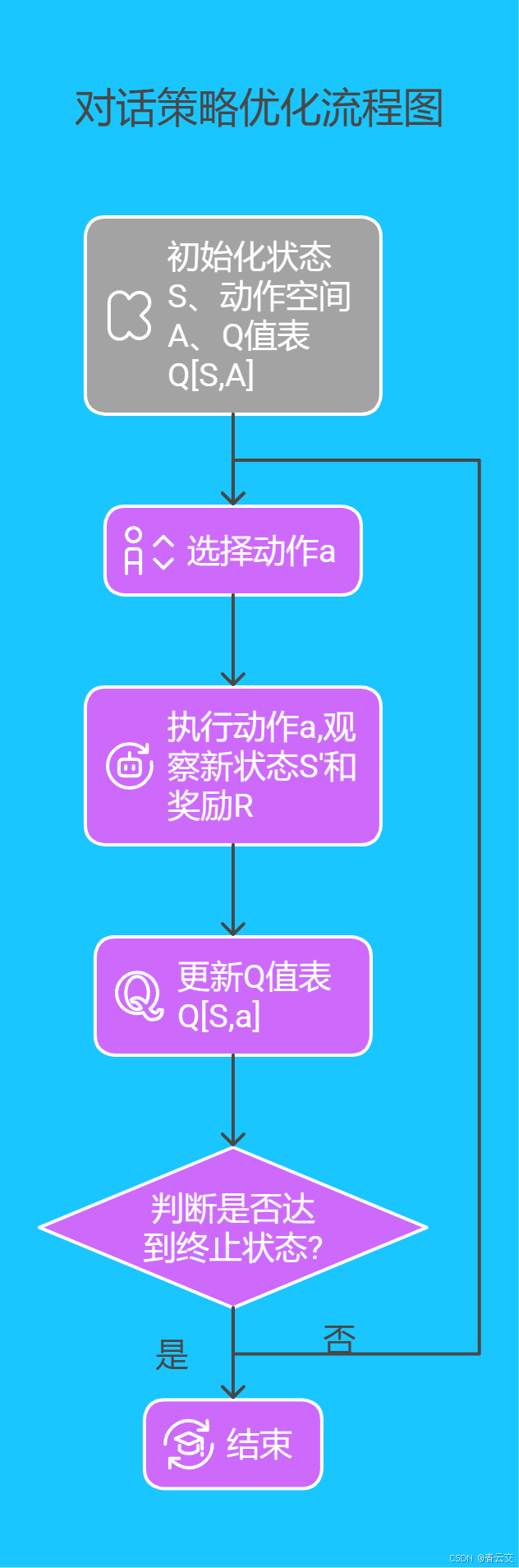
具体实现时,首先定义状态空间、动作空间和奖励函数,然后通过不断迭代更新 Q 值表,优化对话策略。
四、实际案例分析
某大型金融科技公司在智能客服多轮对话系统中,引入了基于 Java 的大数据机器学习模型,取得了显著的成效。
4.1 系统实施
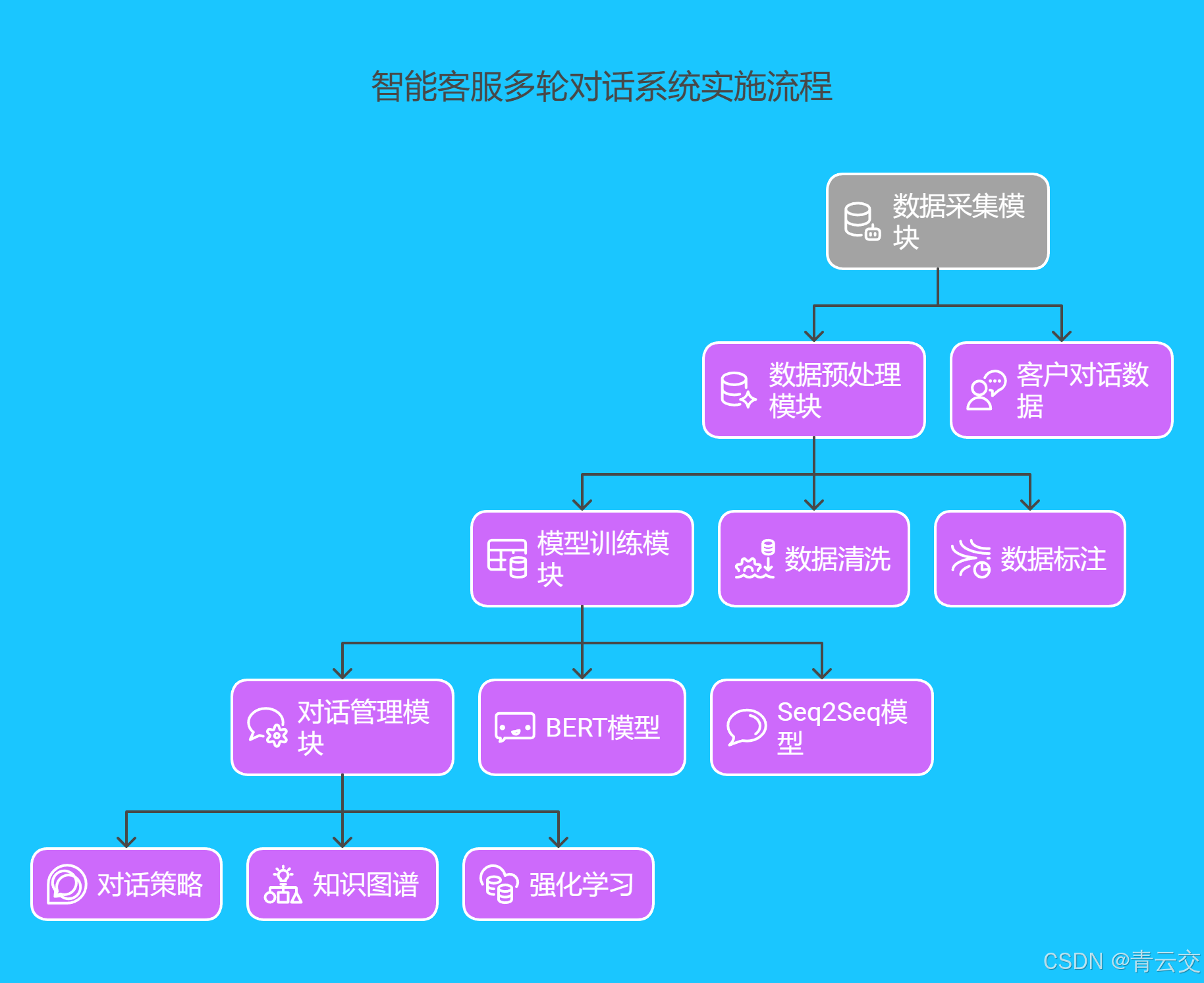
该公司部署了一套基于 Java 的智能客服多轮对话系统,包括数据采集、数据预处理、模型训练、对话管理等模块。在数据采集模块,通过收集客户在金融服务过程中的对话数据,建立了大规模的客户对话数据集;在数据预处理模块,使用数据清洗、标注等技术,提高了数据的质量;在模型训练模块,采用基于 Transformer 的 BERT 模型进行意图识别,采用基于循环神经网络的 Seq2Seq 模型进行对话生成,并通过调优模型参数、增加训练数据量、采用模型融合等方法,提高了模型的性能;在对话管理模块,设计了合理的对话策略,引入知识图谱和强化学习,实现了与客户的自然、流畅交互。以下是系统架构图:
4.2 实施效果
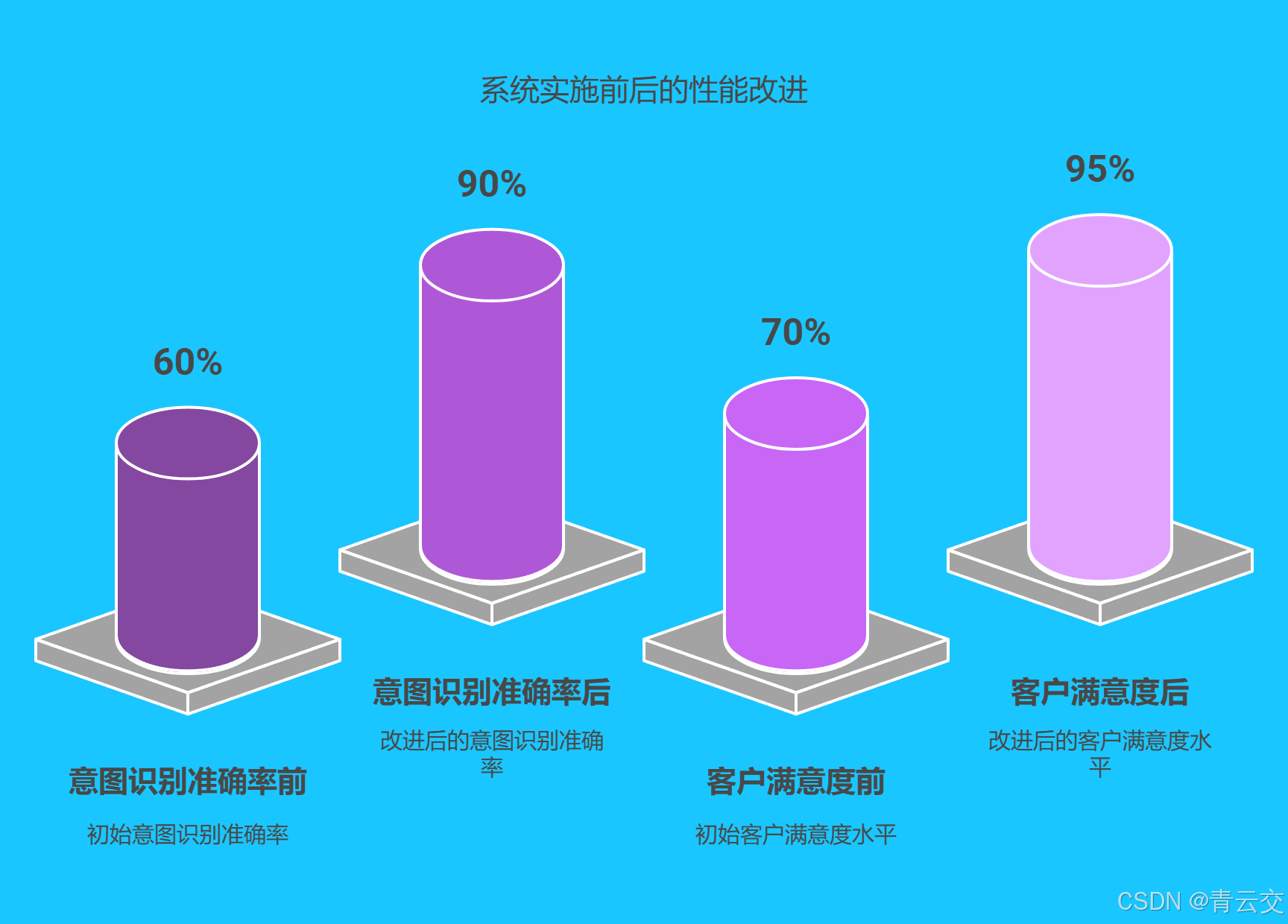
系统实施后,该金融科技公司在客户服务方面取得了显著的成效。智能客服的意图识别准确率从 60% 提高到了 90%,对话生成的质量得到了明显提升,客户满意度从 70% 提高到了 95%。同时,通过自动化的客户服务,有效降低了客服成本,提高了服务效率。具体数据如下表所示:
| 指标 | 实施前 | 实施后 | 提升幅度 |
|---|---|---|---|
| 意图识别准确率 | 60% | 90% | 30% |
| 客户满意度 | 70% | 95% | 25% |
结束语
亲爱的 Java 和 大数据爱好者们,基于 Java 的大数据机器学习模型为智能客服多轮对话系统的优化提供了强大的技术支持,显著提升了智能客服的性能和客户体验。
亲爱的 Java 和 大数据爱好者们,在在优化智能客服多轮对话系统时,你采用过哪些独特的方法?对于基于 Java 的大数据机器学习模型在智能客服中的应用,你有哪些实践经验或新的想法?欢迎在评论区分享您的宝贵经验与见解。
诚邀各位参与投票,推动智能客服多轮对话系统发展,哪项技术优化最为关键?快来投出你的宝贵一票。