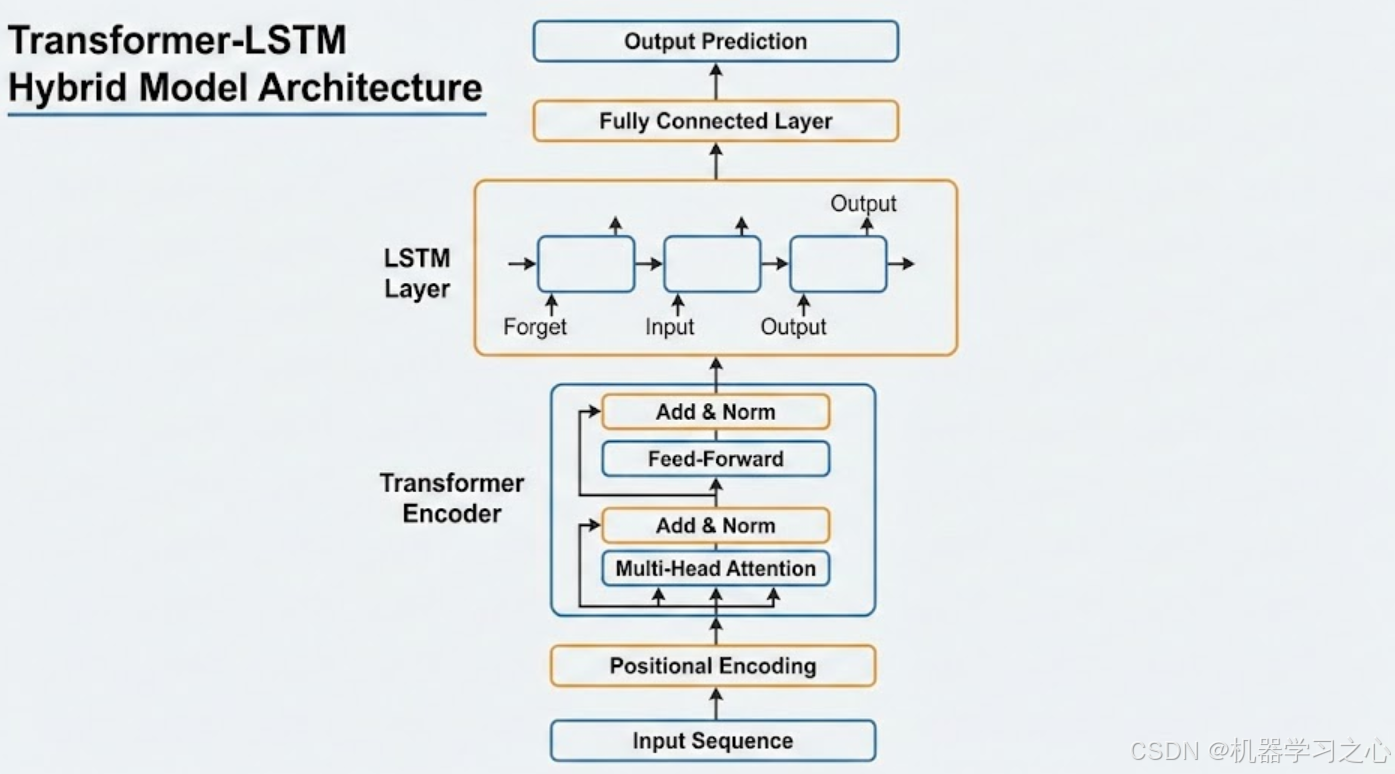
一个典型的 Transformer-LSTM 混合模型 架构。这种设计结合了 Transformer 处理全局关联的能力和 LSTM 处理时序序列的优势。
1. 混合分层架构 (Hybrid Layering)
模型并没有简单地替换某个组件,而是采用串联堆叠的方式:
- 底层为 Transformer Encoder:作为特征提取器,利用自注意力机制(Self-Attention)捕捉输入序列中任意两个位置之间的全局依赖关系。
- 顶层为 LSTM 层:在 Transformer 提取的深度特征基础上,进一步强化对时间序列方向性和局部连续性的建模。
2. 核心组件的功能分配
-
Transformer Encoder (全局感知):
-
多头注意力 (Multi-Head Attention):让模型能够同时关注序列中不同位置的信息,解决了传统 RNN 难以处理超长距离依赖的问题。
-
位置编码 (Positional Encoding):由于 Transformer 本身不具备处理顺序的能力,这一层为输入数据注入了位置信息。
-
LSTM Layer (时序精炼):
-
门控机制 (Forget/Input/Output Gates):LSTM 通过遗忘门和输入门精细地控制信息的流转,能够捕捉更加细腻的局部时序波动。
-
序列平滑:在某些预测任务中,LSTM 可以对 Transformer 输出的特征进行某种程度的"平滑"或"序列化约束"。
3. 该结构的优势
与单一模型相比,这种混合结构具有以下优点:
| 特点 | 优势描述 |
|---|---|
| 特征提取能力 | Transformer 能够比 LSTM 更高效地从原始数据中提取高阶特征。 |
| 并行计算 | 底层的 Transformer 部分可以实现高度并行化,提升训练效率。 |
| 时序稳定性 | 在序列预测(如电力负荷、股票、气象预测)中,加入 LSTM 往往能提高模型对时间方向敏感性的捕捉。 |
| 缓解梯度问题 | Transformer 减轻了 LSTM 在处理极长序列时的梯度消失风险,而 LSTM 则增强了对短期趋势的建模。 |
4. 典型应用场景
这种结构常用于 复杂时间序列预测。Transformer 负责识别长期的季节性、周期性规律,而 LSTM 负责捕捉短期的趋势和突发性的波动。