2025.12.23
这篇文章发表于《Medical Image Analysis》期刊(2026 年第 109 卷),由南方科技大学、香港大学等机构学者联合撰写,聚焦医疗图像 - 文本预训练中的噪声鲁棒性问题,提出一种名为 MIRAGE 的新型多模态学习框架。
Title 题目
01
MIRAGE: Medical image-text pre-training for robustness against noisy environments
MIRAGE:针对嘈杂环境鲁棒性的医学图像-文本预训练
文献速递介绍
02
对比学习(CL)的视觉-语言预训练(VLP)在自然图像处理领域取得了巨大进展,得益于大规模图像-文本数据集。然而,医学领域受限于数据获取、标注成本及隐私法规,导致数据集规模小且常含有噪声,如来自PMC-OA数据集的自动提取引入的假阳性(FP)和假阴性(FN)。传统CL方法(InfoNCE损失)在噪声环境中容易过拟合和产生过自信的预测。现有VLP方法主要依赖数据清洗或通用领域滤波器,但在医学领域因缺乏标注数据或域差异而失效。本文提出MIRAGE框架,通过最优传输(OT)对比损失和跨模态最近邻策略解决FP和FN问题,并引入自适应梯度平衡策略稳定训练,旨在成为首个同时处理医学VLP中FP和FN问题的框架。
Aastract摘要
02
对比视觉-语言预训练模型在通用大规模多模态数据集上取得了显著成功。然而,在医学领域,由于数据收集和专家标注成本高昂,导致数据集规模小且噪声大,严重限制了模型性能。为解决这一挑战,本文提出了MIRAGE框架。该框架旨在处理医学图像-文本预训练中不匹配的假阳性(FP)和语义相关的假阴性(FN)问题。传统基于交叉熵的优化方法在噪声环境中表现不佳,难以区分噪声样本并可能过拟合。MIRAGE引入了一种基于最优传输的对比损失,利用最近跨模态邻居先验有效识别噪声样本,从而减少其负面影响。此外,本文提出了一种自适应梯度平衡策略,以减轻噪声样本梯度带来的影响。在六项任务和14个数据集上的广泛实验表明,MIRAGE的性能优于现有先进方法,并具有强大的跨数据集泛化能力,同时为医学数据噪声估计提供了新见解。
Method 方法
03
MIRAGE框架的核心是结合最优传输(OT)对比损失和自适应梯度平衡策略来处理噪声。首先,通过松弛OT公式,将其集成到对比学习中,其中传输成本Cij量化了识别不匹配对所需的努力,并捕获FP和FN中的噪声。接着,提出基于最近邻(NN)的噪声估计方法,利用图像-文本对的NN文本嵌入(Qi)与配对文本(Ti)之间的语义距离,定义匹配成本函数Cij。该成本函数能够适应数据语义结构,有效区分干净和噪声样本。为了防止训练后期过拟合噪声数据,引入自适应梯度平衡策略,根据样本的估计匹配得分(Sii)动态调整每个正样本对InfoNCE损失的贡献,并通过凸插值结合InfoNCE梯度和基于NN的梯度,确保在噪声环境下的稳定优化。
Discussion讨论
04
MIRAGE在通用医学任务上表现出色,但与专门的3D成像模型仍有差距,这主要源于架构和数据层面限制,因其主要基于2D预训练,缺乏显式的3D图像-文本语义理解。未来工作将探索3D模态特定适配和构建大规模3D图像-文本数据集。另一个重要方向是公平性和偏见缓解,因为现有公开数据集缺乏患者层面的人口统计或站点元数据。尽管如此,MIRAGE通过其NN机制和最优传输公式,能够有效减轻头部类偏见并保留长尾语义,Hellinger距离显著低于CLIP。未来将纳入公平性感知的预训练策略。此外,虽然MIRAGE在RAG框架中展现潜力,但其性能仍落后于专门RAG系统,这可能与预训练数据非RAG专用监督有关。最后,作者指出工作仍处于算法层面,距离实际临床部署尚有距离,未来将加强与临床任务的联系,探索代理工作流和人机交互,并关注可解释性和隐私风险。
Conclusion结论
05
本文提出了一种无需数据过滤的、针对医学领域的鲁棒对比视觉-语言预训练框架MIRAGE。该框架引入了新颖的最优传输对比损失,结合跨模态最近邻噪声估计方法,以缓解InfoNCE损失的过自信问题。同时,为确保训练稳定性,提出了一种自适应梯度平衡策略。在真实和合成噪声数据上的实验结果证明了所提MIRAGE框架的有效性和鲁棒性。
Results结果
06
MIRAGE在六项下游任务(零样本分类、KNN分类、图像-文本检索、视觉问答、多模态检索增强生成)和14个数据集上进行了广泛评估,均表现出卓越性能。在零样本分类中,MIRAGE平均性能最高,特别是在Kappa和AUC指标上。在单模态表示(KNN分类)评估中,MIRAGE在图像和文本KNN分类中均显著优于其他方法。在图像-文本检索任务上,MIRAGE在PMC-OA-Test和ROCO-V2数据集上均持续超越现有方法。在VQA任务中,MIRAGE在Slake和PMC-VQA上达到了最佳总体性能。在多模态RAG任务中,MIRAGE在VQA和报告生成指标上均有显著提升。组件分析表明,OT对比损失和自适应梯度平衡策略对性能提升至关重要。鲁棒性评估显示,MIRAGE在不同噪声水平下始终优于CLIP,并且在高噪声下仍能保持有意义的语义学习。成本函数评估确认了最近邻文本(NN-T)作为成本函数的优越性。此外,文章还探讨了不同视觉编码器下的泛化能力,并初步探索了MIRAGE在3D医学成像中的应用潜力,均取得优异结果。统计分析也验证了MIRAGE性能提升的统计学鲁棒性。
Figure 图
07
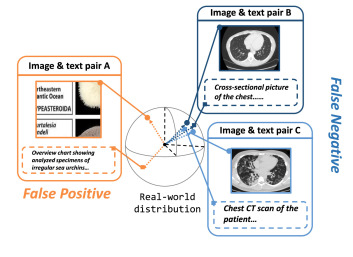
图1. PMC-OA数据集中代表性的假阳性(FP)和假阴性(FN)案例。
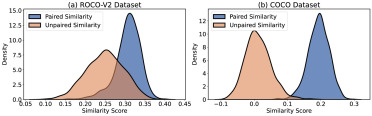
图2. 使用DFN模型(Fang et al., 2024)从(a) ROCO-V2(医学数据集)和(b) COCO(自然数据集)中提取的配对和非配对图像-标题对的相似性得分分布。
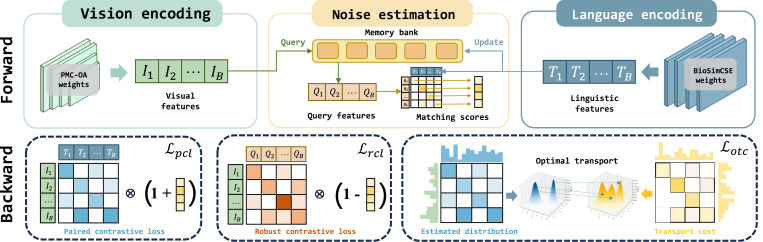
图3. 所提出的MIRAGE整体框架。在前向传播过程中,内存库为每张图像检索最近的文本嵌入,以估计整个批次的噪声水平。在反向传播过程中,估计的噪声通过自适应梯度平衡策略融入最优传输对比损失。
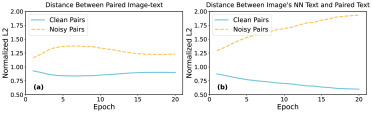
图4. 训练时对30%图像-文本进行打乱的可视化归一化L2距离:(a) 每张图像与其配对文本之间的距离;(b) 每张图像的最近邻(NN)文本与其配对文本之间的距离。
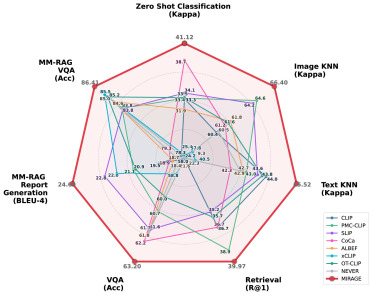
图5. MIRAGE与最先进方法在各项任务上的性能对比分析。
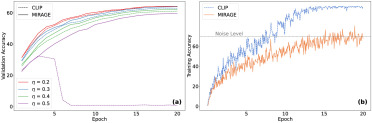
图6. MIRAGE和CLIP在噪声环境中的表现:(a) 不同噪声水平下的验证对比准确率;(b) 噪声水平η=0.3时的训练准确率收敛模式。
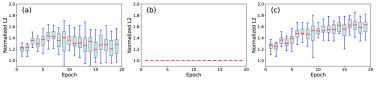
图7. 随机采样的噪声图像-文本嵌入之间的归一化L2距离,对比:(a) 大InfoNCE权重(1.0),(b) 小InfoNCE权重(0.01),以及(c) 自适应梯度平衡。

图8. 图像-配对文本相似性与图像-最近邻文本相似性在不同数据集上的散点图。噪声水平越高,两种相似性之间的相关性越低。

图9. 经检索任务评估的MIMIC数据集中采样的类别分布图。从左到右依次为:MIRAGE检索到的报告标签;CLIP检索到的报告标签;以及真实报告标签。

图10. 训练过程中最近邻匹配的演变,基于在不同时期具有前1%最高匹配分数的代表性样本。红色高亮词表示不匹配,绿色高亮词表示一致匹配。
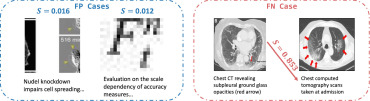
图11. MIRAGE检测到的代表性假阳性(FP)和假阴性(FN)案例的可视化,其中S表示匹配分数。
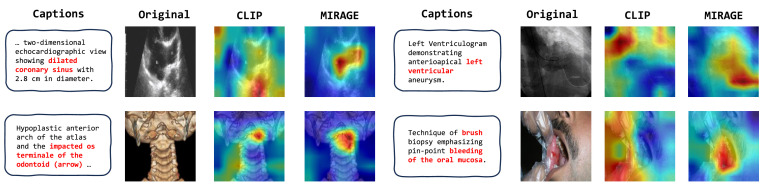
图12. CLIP和MIRAGE局部图像-文本相似性的对比可视化。标题中的关键词以红色高亮显示。