文章目录
-
- [Deepseek ocr 这模型](#Deepseek ocr 这模型)
- 使用用再说
-
- 先下下来尝试一下
- [搭配环境 【conda环境】](#搭配环境 【conda环境】)
- [使用 hf-mirror.com 替换 https://huggingface.co](#使用 hf-mirror.com 替换 https://huggingface.co)
- 报错指南
- 最终结果
- Todo后续会使用gradio来体验
- 有兴趣拉一下
Deepseek ocr 这模型
在人工智能时代,光学字符识别(OCR)技术已成为数字化转型的核心引擎,从文档扫描到知识提取,其应用正日益扩展。2025年10月20日,DeepSeek-AI团队开源了DeepSeek-OCR模型,这款约30亿参数的视觉-语言模型(VLM)以"上下文光学压缩"(Contexts Optical Compression)为核心创新,通过将长文本转化为视觉令牌,实现7-20倍的压缩率,同时保持高精度。该模型在撰写本文戒指10月23日10:00已在GitHub上迅速积累超过12K星,备受Andrej Karpathy等行业大咖青睥。本文从源码分析、架构设计、本地案例验证及实际使用场景四个维度,深入剖析DeepSeek-OCR的效果与潜力,揭示其在OCR领域的突破性价值。
说了很多,模型参数(3B)足够本地运行了,本人mac 本地环境,想针对该模型进行工作适配。
模型下载
https://huggingface.co/deepseek-ai/DeepSeek-OCR镜像地址
https://hf-mirror.com/deepseek-ai/DeepSeek-OCR使用用再说
先下下来尝试一下
shell
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git如果网络有问题使用如下
shell
git clone https://gitee.com/ZhangALiang/DeepSeek-OCR.git本人在镜像上用pdf mathTranslate生成了一份中文版论文。可以对照着看。
搭配环境 【conda环境】
shell
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr下载依赖
shell
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0
pip install -r requirements.txt注意,本人使用pip install torch2.6.0 torchvision0.21.0 torchaudio2.6.0 --index-url https://download.pytorch.org/whl/cu118 无法下载。
也没有安装pip install flash-attn2.7.3 --no-build-isolation也就是没有使用vllm
使用 hf-mirror.com 替换 https://huggingface.co
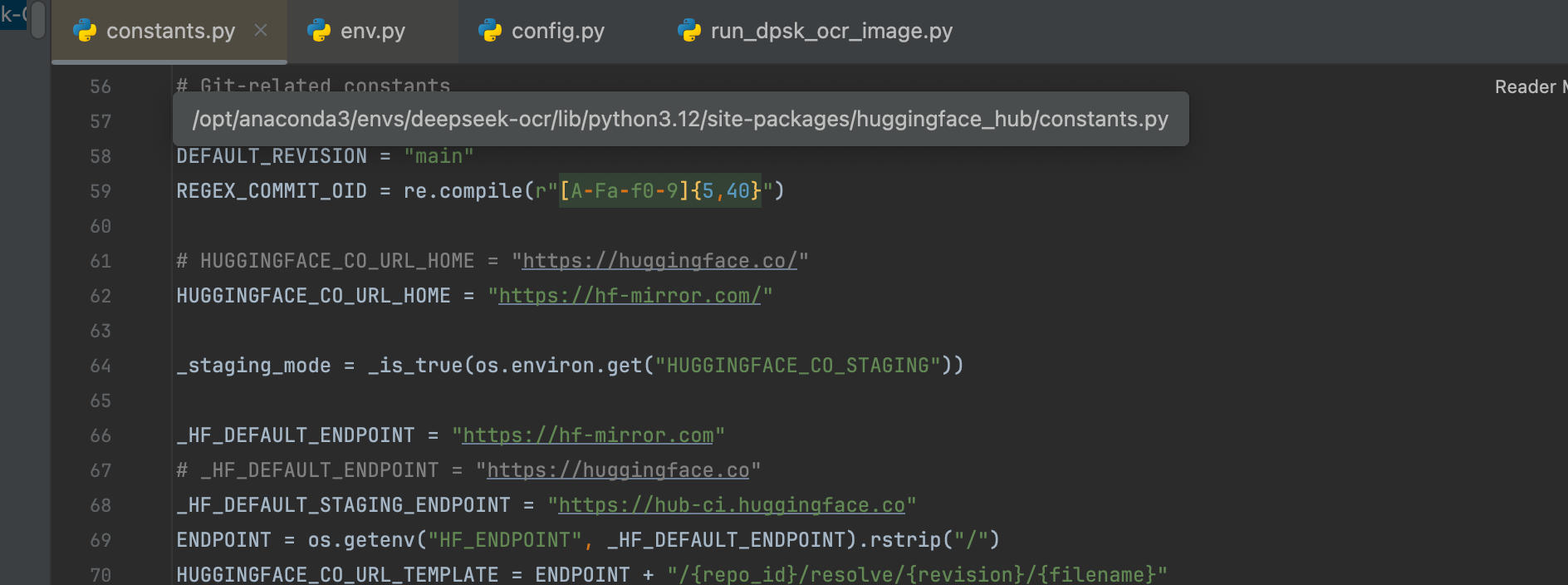
python
# HUGGINGFACE_CO_URL_HOME = "https://huggingface.co/"
HUGGINGFACE_CO_URL_HOME = "https://hf-mirror.com/"
_HF_DEFAULT_ENDPOINT = "https://hf-mirror.com"
# _HF_DEFAULT_ENDPOINT = "https://huggingface.co"报错指南
model镜像无法下载
python
# 1. 设置镜像源(核心)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# (可选)2. 设置本地缓存路径(避免每次下载到默认目录)
os.environ["HUGGINGFACE_HUB_CACHE"] = "./my_hf_cache"报错cuda错误
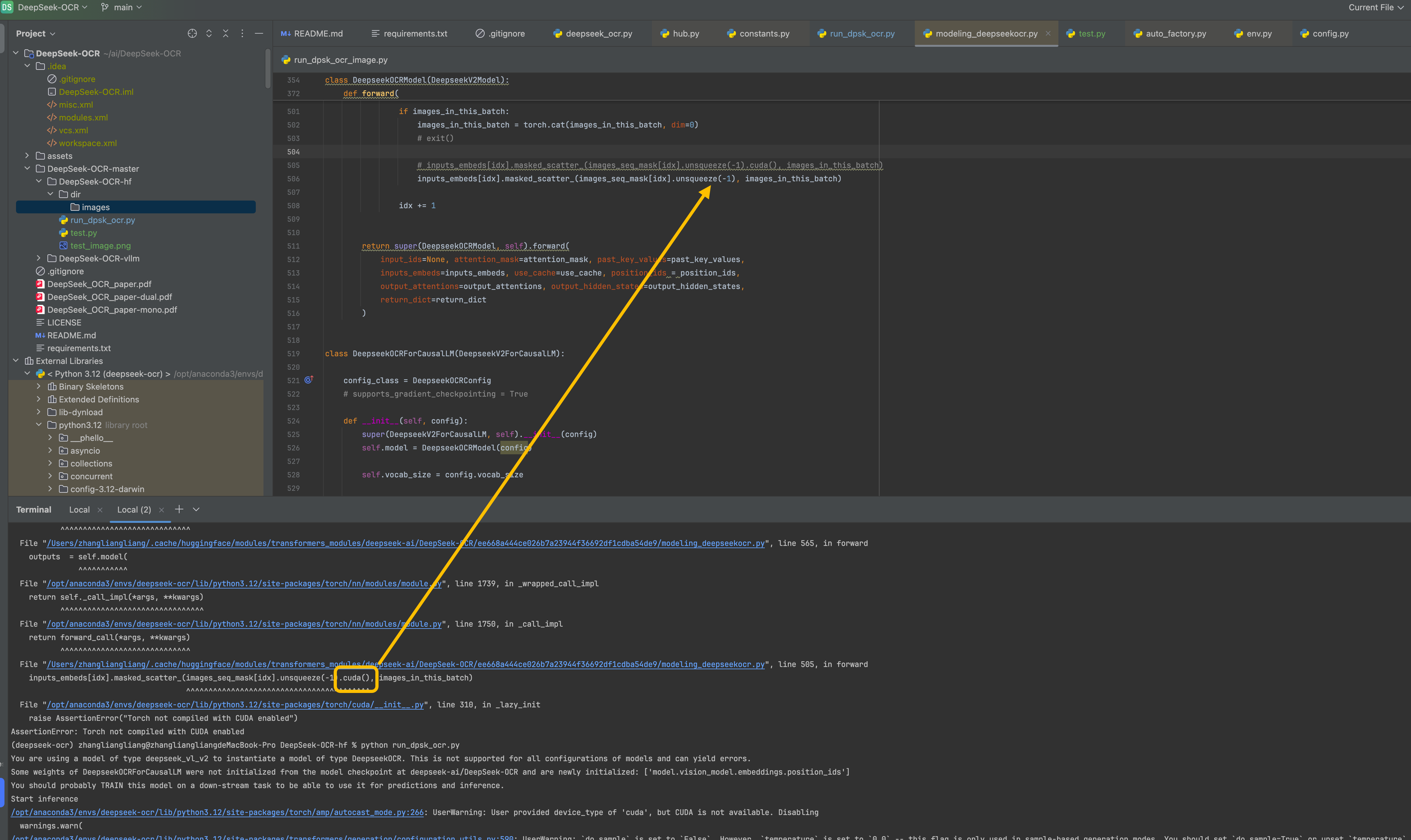
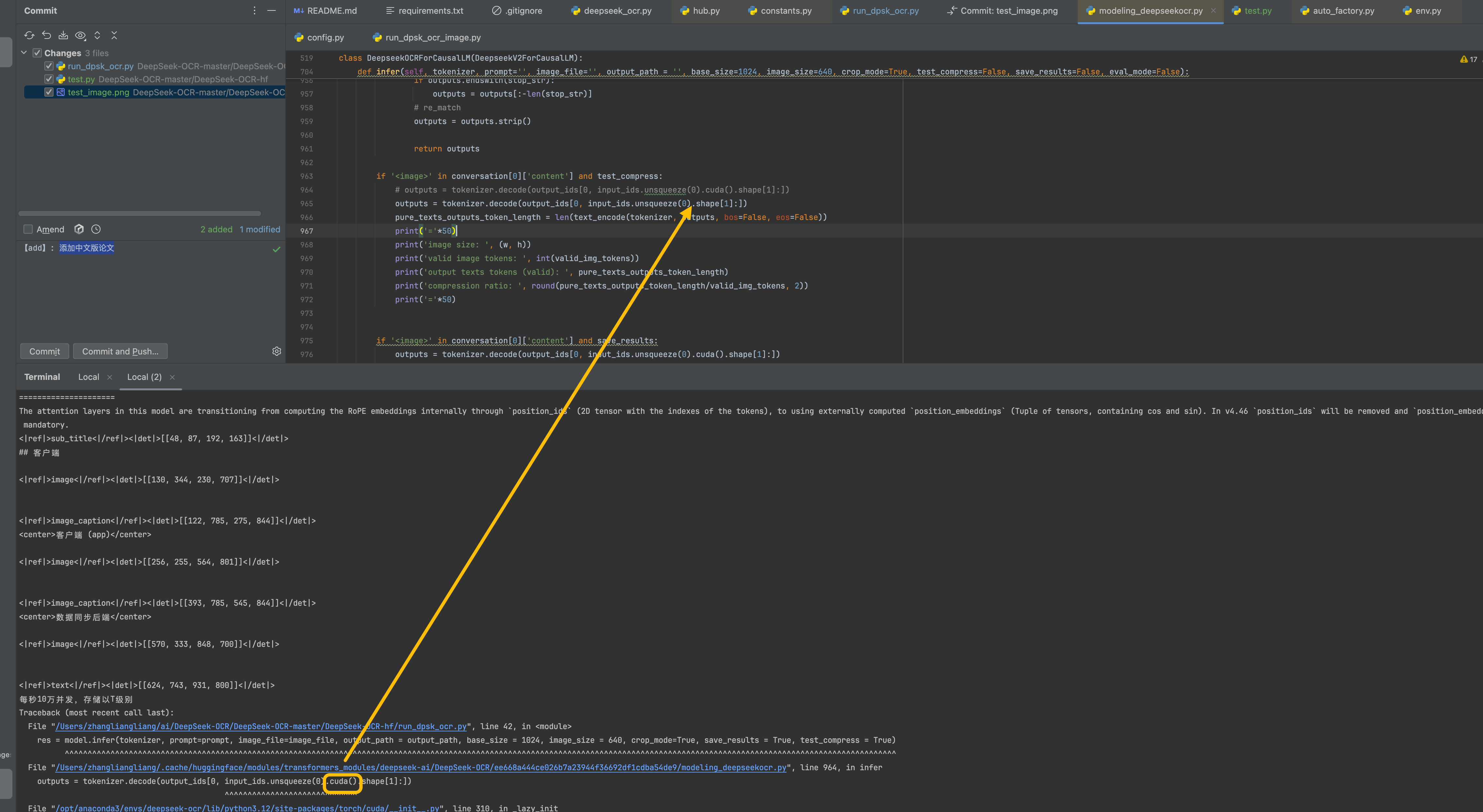
由于本地是mac的,不支持cuda,那么出现cuda错误,那么就跳转到指定位置,对cuda()注解掉就行。
在这里插入图片描述
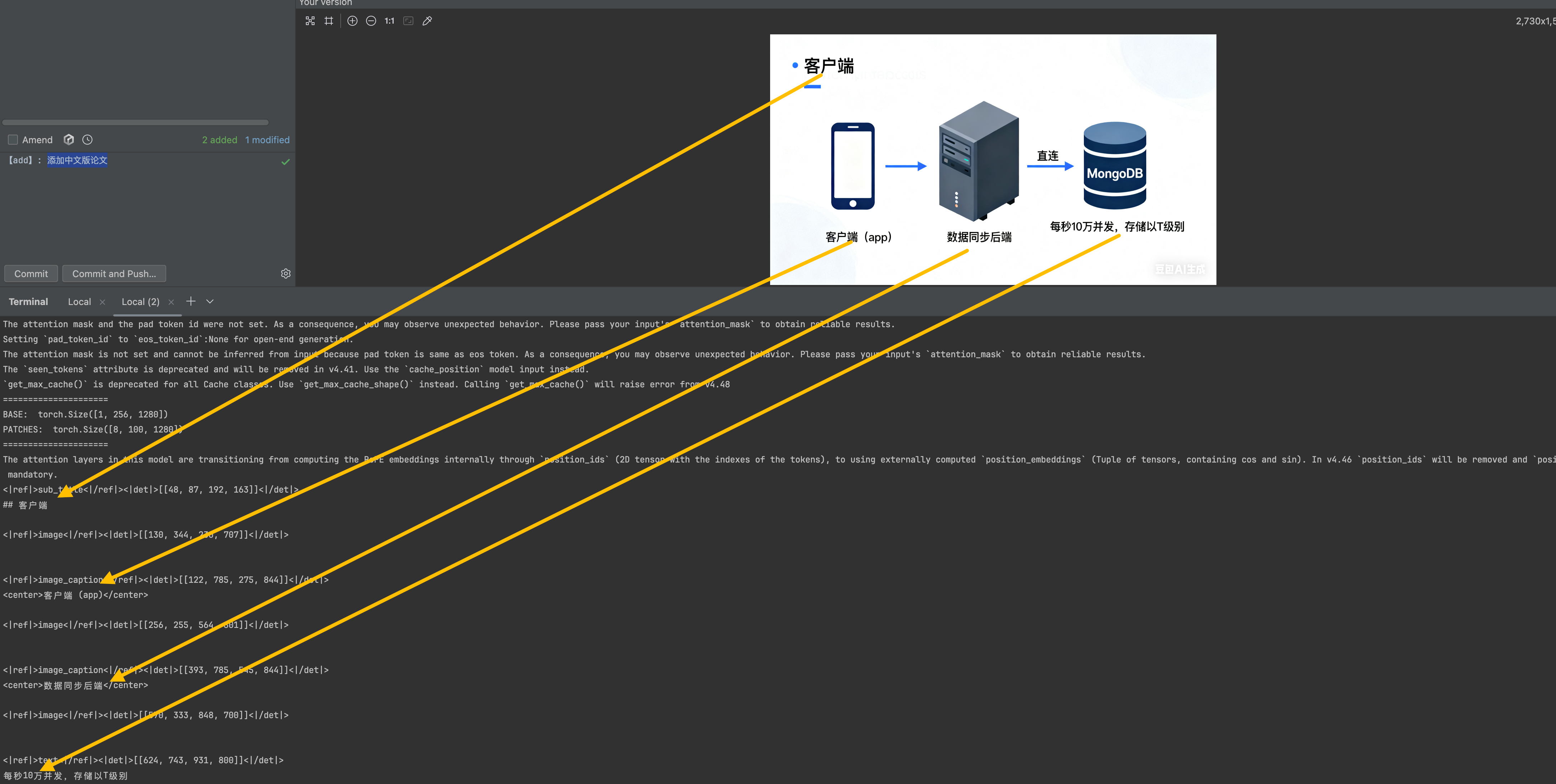
最终结果
识别还是挺准的。就是有点慢
Todo后续会使用gradio来体验
有兴趣拉一下
代码在
而且输出内容。有文字内容,同时还有图像分割。