Postgres 17 与 18 的基准测试
Postgres 18 于几周前发布,它的改进引起了大量炒作。最值得注意的是,Postgres 18 引入了 io_method 配置选项 ,允许用户更好地控制磁盘 I/O 的处理方式。
将其设置为 sync 会导致与 17 及更早版本相同的行为。通过此设置,所有 I/O 都通过同步请求进行。
18 引入了两种替代方案: worker 和 io_uring (默认 worker )使 Postgres 使用专用的后台工作进程来处理所有 I/O 操作 io_uring 是许多人出于性能原因而兴奋的变化,因为它使用 Linux io_uring 接口允许所有磁盘读取异步进行。希望这可以显着提高 I/O 性能。
我们进行了详细的基准测试来比较 Postgres 17 和 18 的性能。让我们看看这些改进是否真的像人们所宣传的那样。
基准配置
sysbench 用于执行基准测试 io_uring 改进仅适用于读取 ,因此这里的重点将放在 oltp_read_only 基准测试上。这包括 点查询 和 范围扫描 和 聚合查询,这些查询由 --range_size 参数控制。虽然对写入和读/写组合性能进行基准测试也很有趣,但坚持 只读请求 有助于集中讨论。我们将数据大小设置为 TABLES=100 和 SCALE=13000000 这将生成一个 ~300 GB 的数据库(100 个表,每个表有 1300 万行)。
基准测试是在四种不同的 EC2 实例配置上进行的:
| Instance | vCPUs | RAM | Disk | Disk type | IOPS | Throughput |
|---|---|---|---|---|---|---|
| r7i.2xlarge | 8 | 64 GB | 700 GB | gp3 | 3,000 | 125 MB/s |
| r7i.2xlarge | 8 | 64 GB | 700 GB | gp3 | 10,000 | 500 MB/s |
| r7i.2xlarge | 8 | 64 GB | 700 GB | io2 | 16,000 | - |
| i7i.2xlarge | 8 | 64 GB | 1,875 GB | NVMe | 300,000 | - |
所有这些实例都在相同(或极其相似)的 Intel CPU 上运行。我们使用 i7i 实例,以展示 Postgres 使用快速本地 NVMe 驱动器的能力。这就是我们用于 PlanetScale Metal 的,并且已经看到了 Postgres 17 的惊人性能结果 。许多其他云提供商仅提供一种网络附加存储形式,而我们提供两种选择。
在进行基准测试之前,每个服务器都会经过 10 分钟的查询负载预热。
在每一种配置中,我们都以以下配置运行 sysbench oltp_read_only 基准测试,每次持续 5 分钟:
- 单个连接和
--range_size= 100 - 10 个连接和
--range_size= 100 - 50 个连接和
--range_size= 100 - 单个连接和
--range_size= 10,000 - 10 个连接和
--range_size= 10,000 - 50 个连接和
--range_size= 10,000
这导致总共 24 个 5 分钟基准测试运行。这 24 种配置每种运行四次!在 Postgres 17 上运行一次,在 Postgres 18 上运行一次,使用 io_method=worker 、 io_method=io_uring 和 io_method=sync 。这总共产生了 96 种基准测试组合。
这是一个极其 I/O 密集型的工作负载。数据大小(300 GB)远远超过 RAM 大小(64 GB),因此这里执行的查询将需要大量的磁盘访问。
Single connection 单连接
虽然单个连接是不切实际的生产工作负载,但它为不同的 I/O 设置如何影响直线性能提供了基准。让我们评估一下我们可以在这里实现的 QPS。
以下是所有 单连接 运行的平均 QPS,其中 --range_size 值设置为默认值 100。这意味着完整的读取工作负载由点查询和对 100 行序列进行扫描/聚合的查询组合组成。
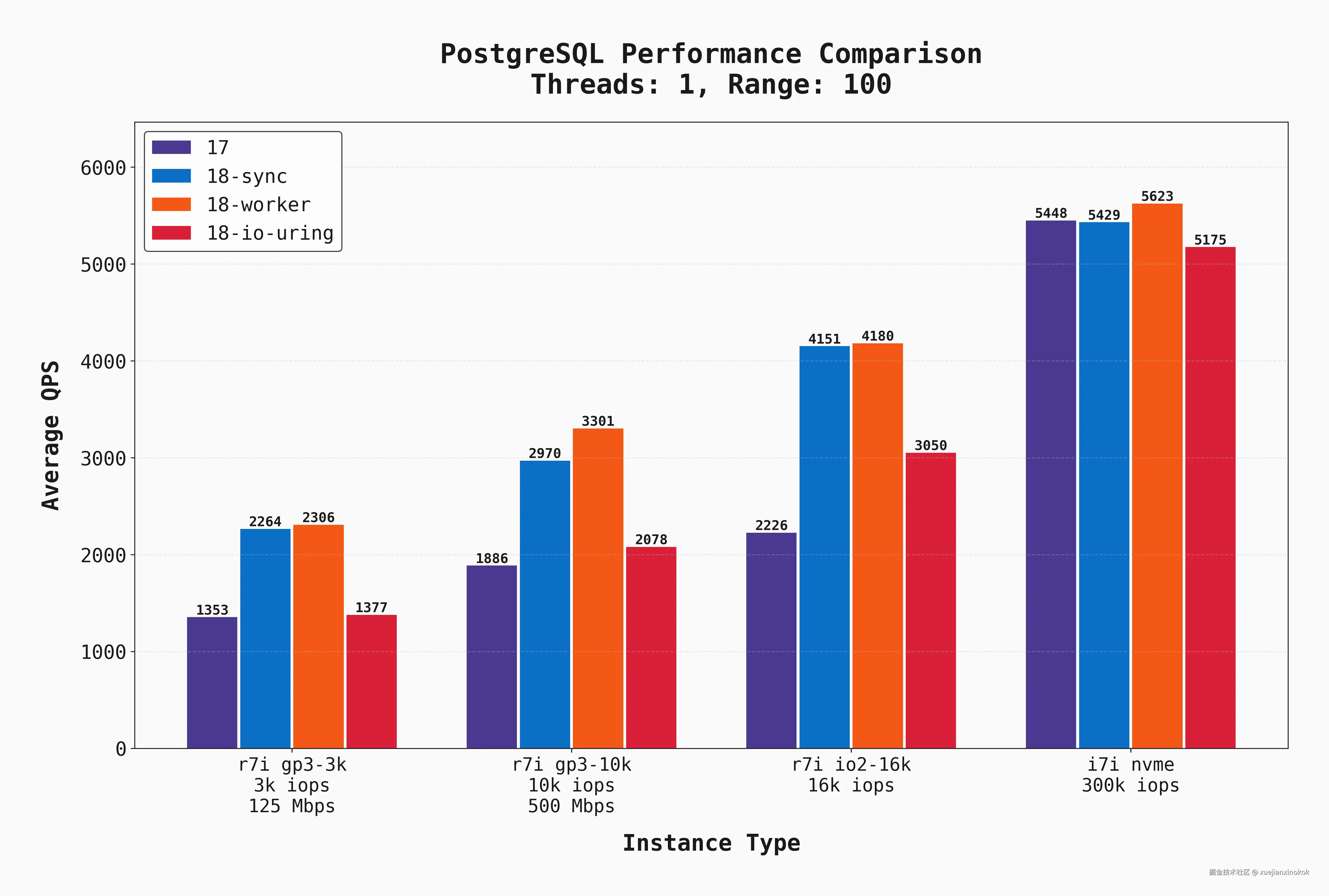
有几件事是清楚的:
- 在网络附加存储(gp3、io2)上,
sync和worker模式下的 Postgres 18 的性能明显优于使用io_uring的 17 和 18。我承认,这让我很惊讶!我的预期是io_uring性能会与所有这些选项一样好,甚至更好。 - gp3 甚至 io2 的延迟显然是造成这种差异的一个因素。在具有低延迟本地 NVME 驱动器 的实例上,所有选项都更加均匀匹配。
- gp3 甚至非常昂贵的 io2 驱动器的延迟/IOPS 都是一个限制因素。本地磁盘在所有配置中都表现出色。
- 对于那些非常简单、短暂执行、几乎没有锁竞争或磁盘 I/O 的查询,Postgres 18 的基础执行速度(CPU级原始性能)比以前的版本快得多 .这是令人兴奋的改进.
这是相同的测试,但使用了 --range_size=10000 。这意味着工作负载具有更大的扫描/聚合,这意味着更多的顺序 I/O 和更低的 QPS:
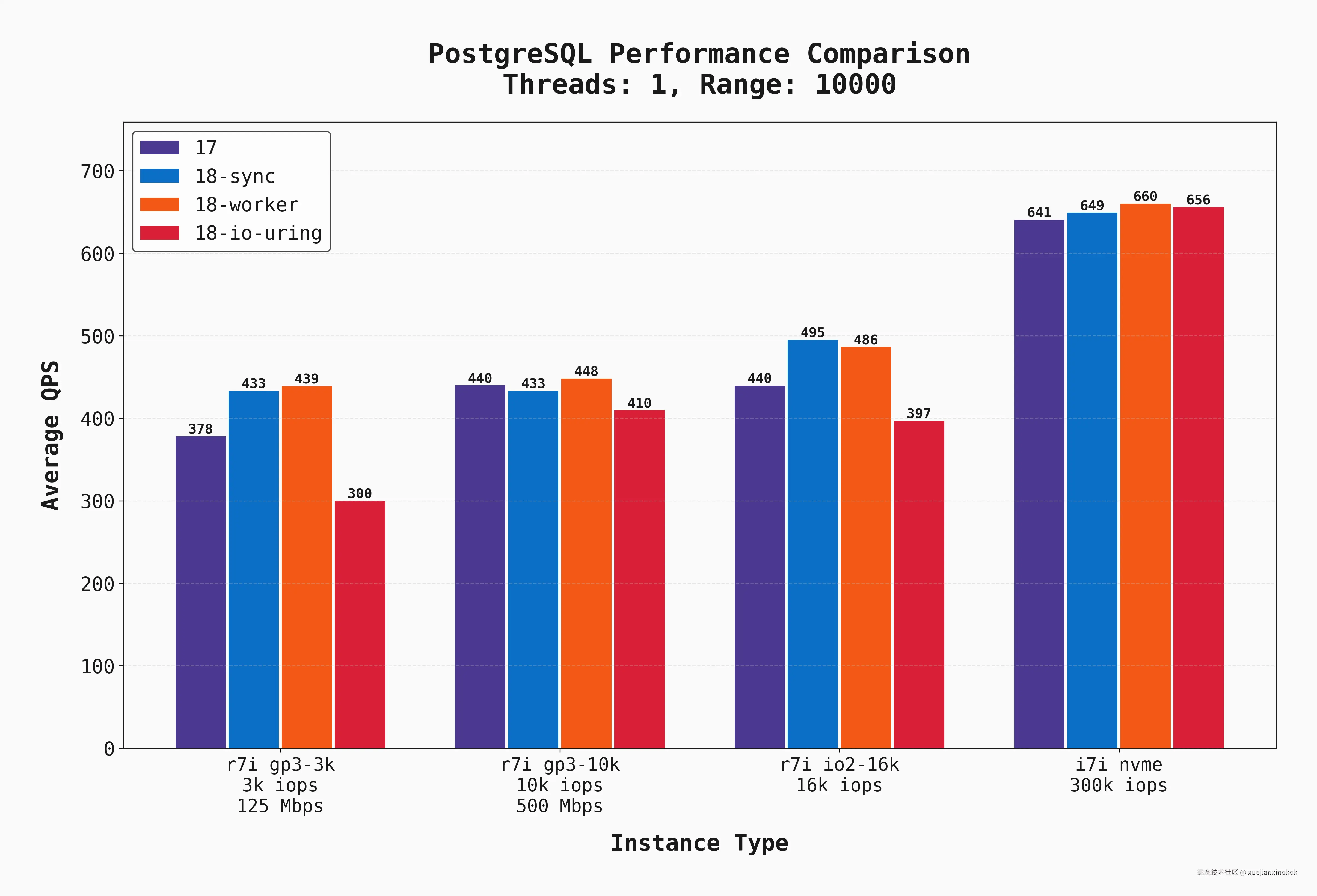
本地磁盘仍然明显表现优异,但其他三个选项之间的差异不那么明显。这是由于 (a) 更多顺序 I/O 但更重要的是 (b) 更多 CPU 工作(聚合 10k 行比聚合 100 行更耗费 CPU 资源)。此外,postgres 17 和 18 之间的差异要小得多。
下面是一个交互式视觉效果,比较了所有实例类型的 Postgres 17 结果与 Postgres 18 上表现最佳的 workers。单击缩略图可在图表中添加或删除线条,并比较各种组合。这是基于 10 秒的采样率。 
High concurrency 高并发
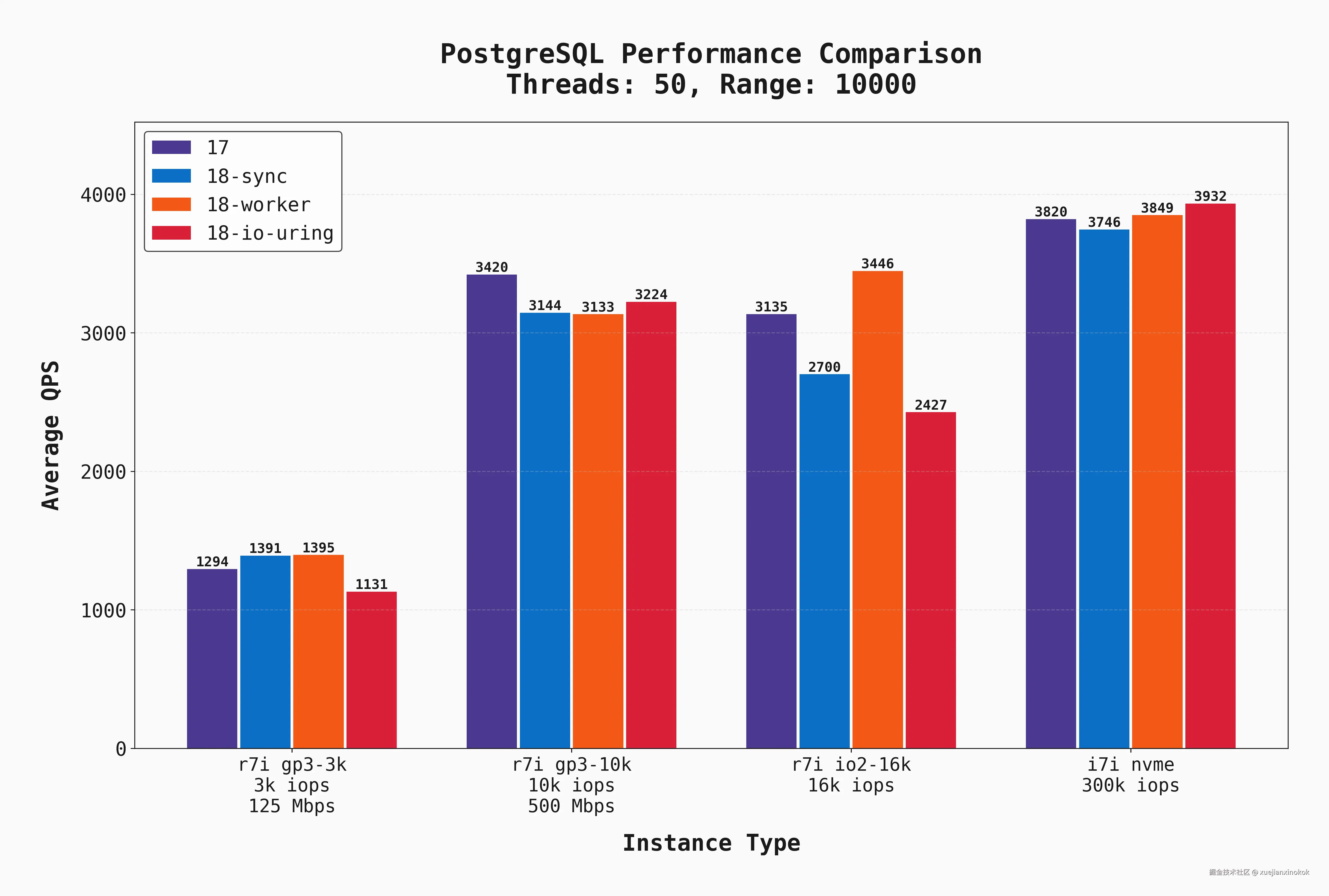
在实际场景中,我们有许多同时发生的连接和许多读取操作。让我们看看这些服务器如何处理相同的基准,但在 50 个连接上负载要高得多。
当然, oltp_read_only 不会捕获真实的 OLTP 工作负载,特别是因为它不包括写入,但我们使用它作为具有高读取需求的工作负载的代理。下面,我们显示了所有 50 个连接 oltp_read_only 与 --range_size=100 的平均 QPS。
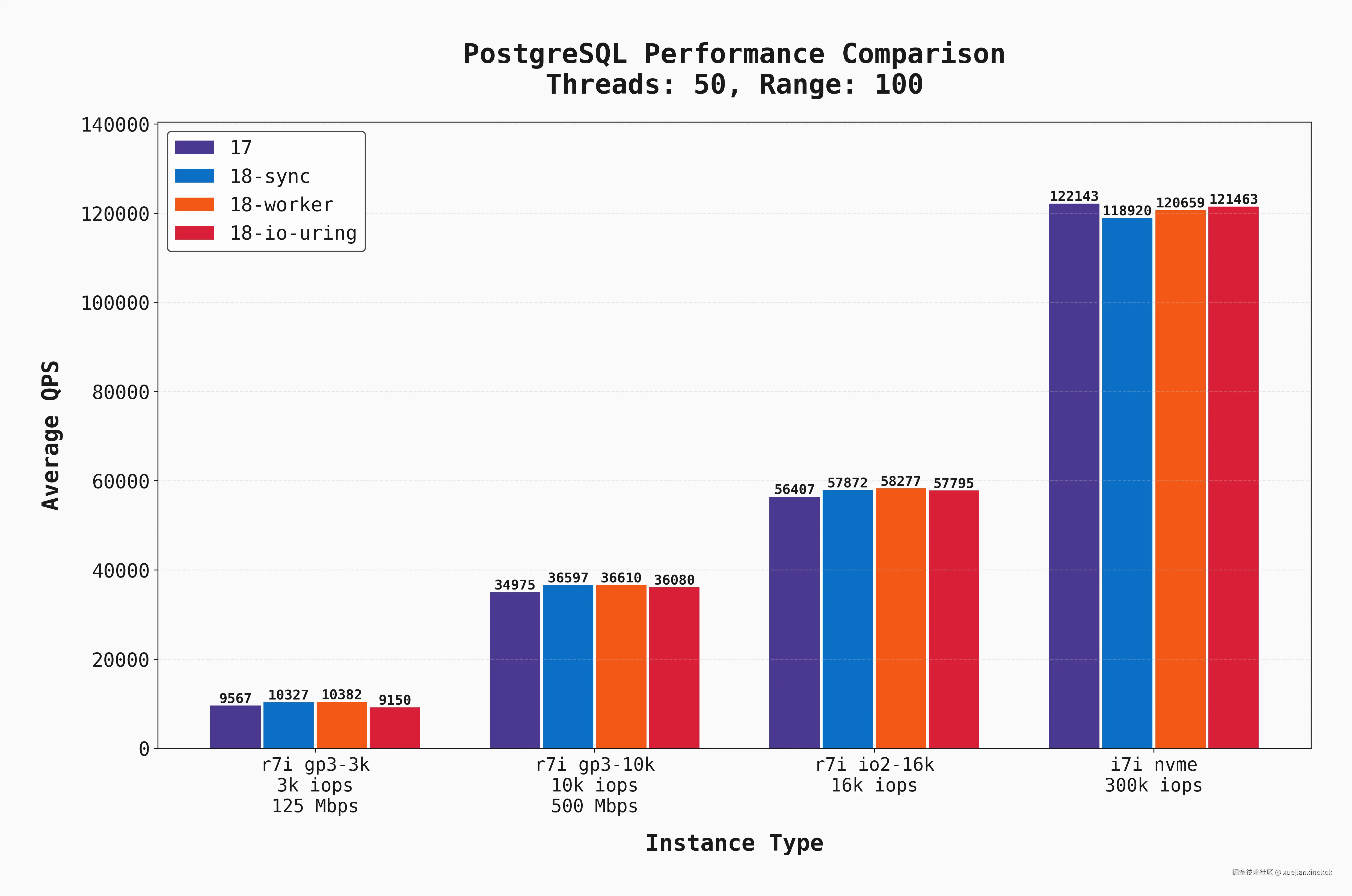
现在,随着并行度的提高和 I/O 需求的增加,有几点变得清晰起来:
- IOPS 和吞吐量是每个 EBS (根卷存储在 Amazon EBS (Elastic Block Store) 上)支持的实例的明显瓶颈。在这种情况下,不同的版本/ I/O 设置不会产生巨大的差异。
- 随着我们提高 EBS 性能,QPS 也同步增长,并且本地 NVME 实例的性能优于所有实例。
- 具有
sync和workerPostgres 18 在所有 EBS 支持的实例上均以微弱优势获得最佳性能。
同样,基准相同,但使用 --range_size=10000 。
gp3-10k 和 io2-16k 实例更接近本地磁盘性能。但是,这是因为我们使基准测试更加受 CPU 约束而非受 I/O 约束 ,因此本地磁盘的低延迟优势较小(尽管仍然是最好的!)但重要的是,我们终于有了一个 io_uring 获胜的场景!在 NVMe 实例上,它的性能略优于其他选项。
下面我们再次比较 Postgres 17 和 Postgres 18 worker 的结果。单击缩略图可在图表中添加或删除线条,并比较各种组合。 
Moderate concurrency 中等并发
这些相同的基准测试也使用 10 个并发连接执行。结果非常相似,因此不会全部显示,但我确实想指出这个图表,其中 --range_size=100 :
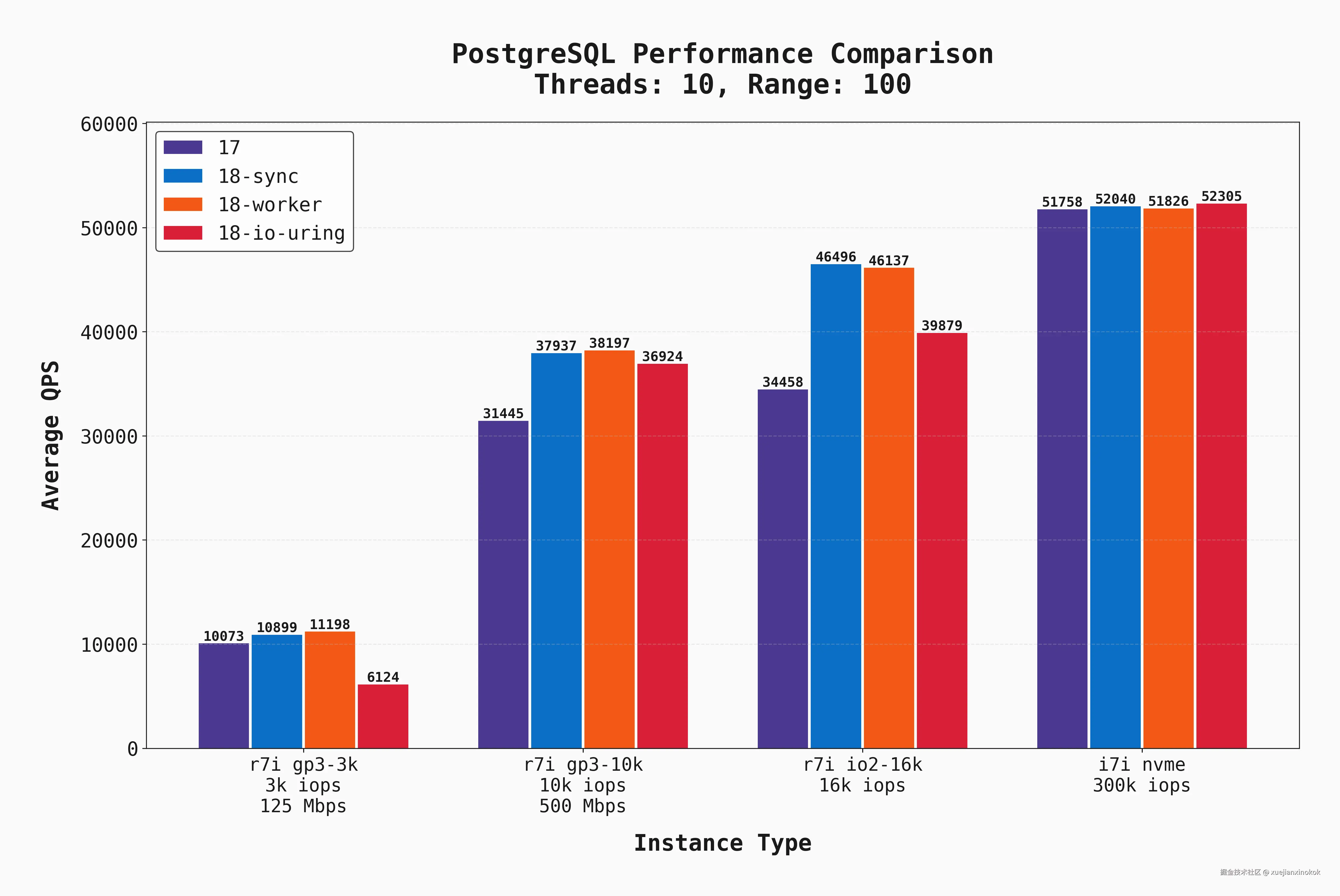
仔细查看第一个条形组(对于 gp3-3k )。io_uring 设置 io_uring 性能明显差于 其他设置。但是,如果在有 50 个连接时查看图表的同一部分, io_uring 性能仅比其余部分稍差。对我来说,这表明当有大量 I/O 并发时, io_uring 性能良好,但在低并发场景中,它并没有那么有益。
Cost 成本
在比较基础设施设置时,始终应考虑成本。以下是 AWS 中每个服务器配置的按需成本:
r7i搭配 gp3 3k IOPS 和 125 Mbps: 442.32 美元/月r7i搭配 gp3 10k IOPS 和 500 Mbps: 每月 492.32 美元r7i搭配 io2 16k IOPS: 每月 1,513.82 美元- 带有本地 NVMe(无 EBS)的
i7i: 551.15 美元/月
请记住,前三款只有 700 GB 的存储空间,而 i7i 存储空间为 1.8 TB!带有本地 NVMe 磁盘的服务器显然是性价比最高的。
为什么 io_uring 不是最快的?
鉴于我对 Postgres 18 的新 io_uring 功能感到兴奋,我期待它能在更多场景中获胜。那么这里发生了什么?
首先,这是一种非常特殊的工作负载类型。它是只读的,并且结合了点查询、范围扫描和范围聚合 io_uring 肯定还有其他工作负载可以发挥其作用。通过不同的 postgresql.conf 调整,我们也有可能看到 io_uring 的改进。
在撰写本文时,我偶然发现了 Tomas Vondra 的精彩博客, 其中讨论了新的 io_method 选项、如何调整它们以及每种选项的优缺点。他针对为什么 workers 性能优于 io_uring 提出了几个很好的观点,我建议您阅读一下。简而言之:
-
索引扫描(尚未)使用 AIO。
-
尽管 I/O 通过
io_uring在后台发生,但校验和 / memcpy 仍然可能成为瓶颈。 -
从单个进程的角度来看,
workers可以实现更好的 I/O 并行性。
因此,在某些情况下, io_uring 并不总是表现得更好!我很乐意看到其他人的进一步基准测试,涵盖配置上的其他工作负载类型。您可以在附录中找到用于这些测试的许多配置。
结论
虽然测试范围很窄,但这是一个有趣的实验,用于比较 Postgres 版本和 I/O 设置的性能。我的主要收获是:
- Postgres 18 带来了良好的 I/O 改进和配置灵活性。维护团队做得很好!
- 本地磁盘无疑是赢家。 当拥有低延迟 I/O 和极高的 IOPS 时,其他因素就变得不那么重要了。这就是 PlanetScale Metal 能够提供一流数据库性能的原因。
- 使用
io_method=worker作为新的默认设置是一个不错的选择。它具有io_uring的许多"异步"优势,而不依赖于特定的内核接口,并且可以通过设置io_workers=X进行调整。 - 不存在一种适合所有情况的最佳 I/O 配置。
- 尽管确实有好处,但新的
workersI/O 配置对网络附加存储场景的帮助并不像人们希望的那样大。
附录:测试数据库配置
以下是用于此基准测试的一些关键的自定义调整的 Postgres 配置:
properties
shared_buffers = 16GB # 25% of RAM
effective_cache_size = 48GB # 75% of RAM
work_mem = 64MB
maintenance_work_mem = 2GB
wal_level = replica
max_wal_size = 16GB
min_wal_size = 2GB
wal_buffers = 16MB
checkpoint_completion_target = 0.9
random_page_cost = 1.1
effective_io_concurrency = 200
default_statistics_target = 100
max_worker_processes = 8
max_parallel_workers_per_gather = 4
max_parallel_workers = 8
max_parallel_maintenance_workers = 4
bgwriter_delay = 200ms
bgwriter_lru_maxpages = 100
bgwriter_lru_multiplier = 2.0
autovacuum = on
autovacuum_max_workers = 4
autovacuum_naptime = 10s
autovacuum_vacuum_scale_factor = 0.05
autovacuum_analyze_scale_factor = 0.025
logging_collector = on
...more log configs...
shared_preload_libraries = 'pg_stat_statements'
track_activity_query_size = 2048
track_io_timing = on
jit = on
# io_workers left at default = 3原文: Postgres 17 与 18 的基准测试(Benchmarking Postgres 17 vs 18 --- PlanetScale)
PostgreSQL 18 中的 AIO 调优(Tuning AIO in PostgreSQL 18 - Tomas Vondra)