一、为什么必须厘清三者关系?
在企业构建现代数据基础设施(Modern Data Stack)的过程中,"数据湖""数据仓库""ETL"是三个高频但常被误用的概念。实践中常见误区包括:
-
将数据湖视为数据仓库的"替代品"或"升级版";
-
认为引入数据湖后可省略ETL流程;
-
混淆数据湖与数据仓库的适用边界,导致架构冗余或性能瓶颈。
实际上,三者并非竞争关系,而是在不同数据生命周期阶段承担不同职责的互补组件。理解其本质差异与协同机制,是设计高效、可扩展、治理合规的企业级数据架构的前提。
二、企业数据流的三层架构模型
现代企业数据体系通常遵循"来源 → 处理 → 存储/分析"的三层架构:
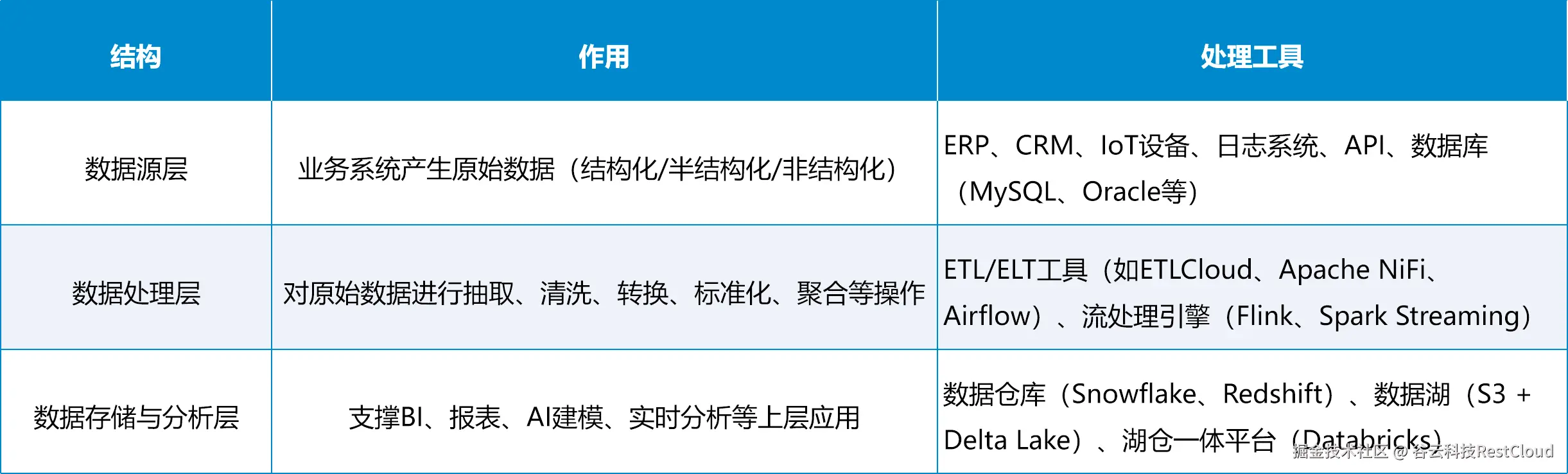
三、数据湖:原始数据的统一归档与探索平台
1.技术定义
一个集中式的存储库,通常建立在低成本的对象存储(如AWS S3、Azure Blob Storage)或分布式文件系统(如HDFS)之上,用于存储任意规模、所有类型的原始数据。
2.关键技术特征
Schema-on-Read:在数据写入时不强加数据结构(Schema)。只有在数据被读取和分析时,才应用相应的Schema。这提供了极大的灵活性。
多数据类型支持:能够原生存储结构化(数据库表)、半结构化(JSON, XML, CSV)、非结构化(日志文件, 图片, 视频)数据。
低成本存储:基于对象存储的架构,使得海量数据存储的成本显著低于传统存储。
四、数据仓库:面向决策的结构化分析引擎
1.技术定义
一个为联机分析处理(OLAP) 高度优化的数据库系统,用于存储和管理来自交易系统的、经过清洗和转换的结构化数据,以支持复杂的查询和报表。
2.关键技术特征
Schema-on-Write:在数据写入之前,必须定义严格的数据模型(如星型模式、雪花模式)。数据必须符合此Schema才能入库,确保了数据的规范性和一致性。
高性能查询:采用列式存储、MPP(大规模并行处理)架构、数据压缩和索引等技术,专门优化了大数据集的聚合和扫描操作。
SQL支持:提供强大的SQL支持,是业务分析师和报表工具的标准接口。
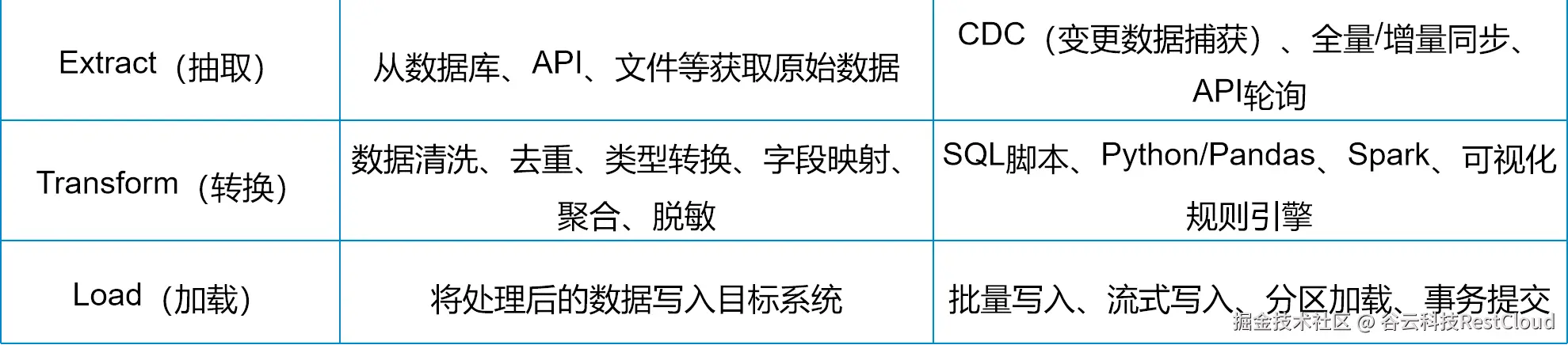
五、ETL:数据流动的中枢引擎与治理抓手
1. 技术定义
ETL是一套数据集成流程,负责从异构源系统抽取数据,进行清洗、转换、标准化后,加载至目标存储系统(如数据仓库或数据湖)。
2. 三大核心阶段
3. ETL vs ELT 的演进
传统ETL:转换在中间计算层完成,适合结构化数据、强治理场景。
现代ELT:先将原始数据加载到目标系统,再利用其强大的计算能力完成转换,更适合云原生、高并发、半结构化数据场景。
六、三者关系:协同而非替代
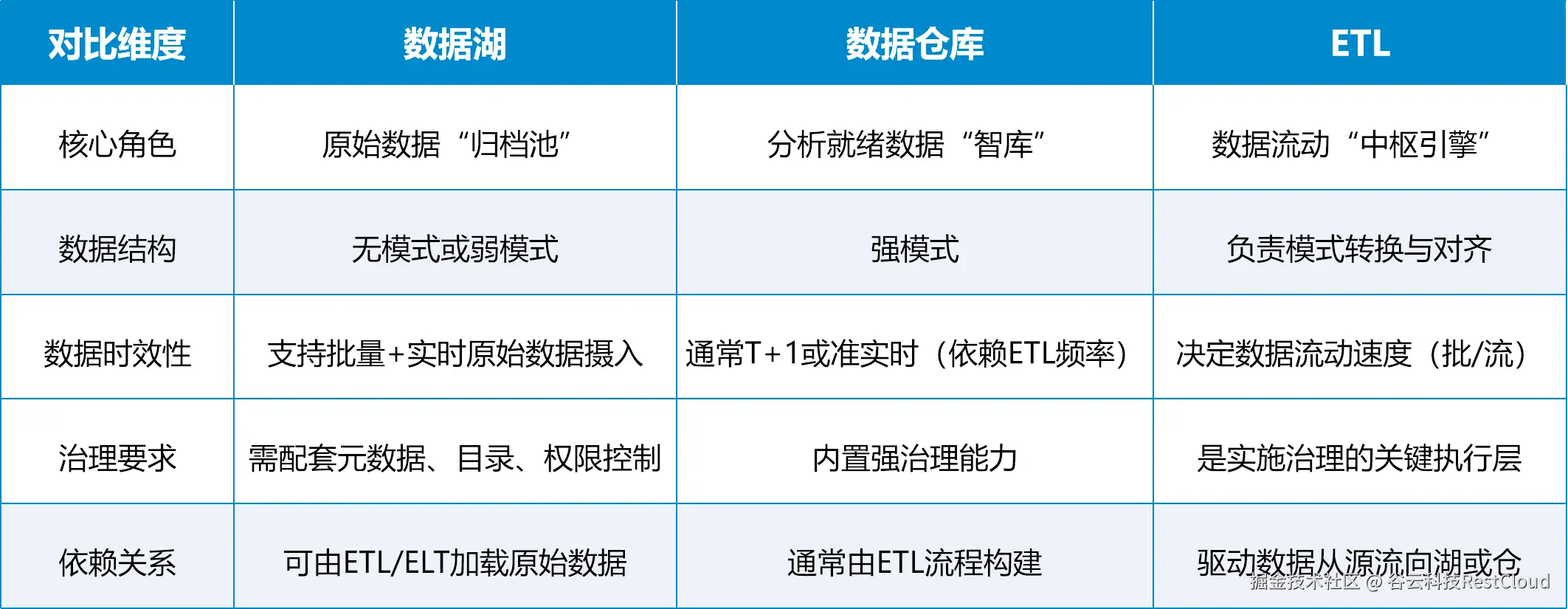
七、三位一体,驱动数据价值闭环
从技术本质上看,数据湖、数据仓库与ETL的关系是专业化分工的必然结果:
-
数据湖 解决了海量、多类数据低成本存储 和灵活性的问题。
-
数据仓库 解决了加工后数据高性能查询 和严谨治理的问题。
-
ETL 则解决了数据从"原始"到"精炼"的自动化加工 与质量管控问题。
理解并正确架构这三者的关系,是构建一个既能应对未知探索、又能支撑高效决策的现代化数据平台的关键。它们共同编织了一张覆盖数据全生命周期管理的技术网络,是企业数据驱动战略得以实现的坚实底座。