
在存算一体架构下,StarRocks 通过 Failover Group、Backup & Restore 以及 Insert Into Files 等机制,实现了集群级的灾备与数据的备份和恢复能力。伴随性能优化与功能演进的持续推进,StarRocks 不断强化系统的稳定性与可用性,以满足企业日益增长的实时分析与高可用需求。
在 3.5 版本 中,StarRocks 推出了全新的 Cluster Snapshot 快照恢复机制,进一步完善了数据安全与灾备体系。
Snapshot 提供了一种高效、低成本、自动化的数据保护方式,显著提升系统的可用性与容灾能力,弥补了此前存算分离架构在备份与恢复方面的空缺。
当系统发生故障、误操作或区域性宕机时,Snapshot 可在分钟级 完成快速恢复,最大限度减少数据丢失与业务中断风险。通过将完整集群状态进行快照化并备份至对象存储,Snapshot 简化了传统灾备方案的复杂流程,使灾难恢复更加高效与便捷。这一机制尤其适用于 金融、零售、SaaS 等对系统稳定性要求极高的关键业务场景。
在此基础上,本文结合 StarRocks 在 Kubernetes 环境中的实际部署实践,进一步介绍了存算分离架构下的灾备机制、恢复流程及快照策略,帮助用户在集群异常或故障场景中快速恢复系统状态,保障业务连续性与数据安全。
名词解释
Cluster Snapshot:
在存算分离架构下,StarRocks 3.5 新增支持集群级别的 Snapshot 功能,提供完整的集群快照能力。Snapshot 可自动创建,记录集群在某一时间点的完整状态(包括 catalog、database、table、user 等元数据),并存储于对象存储中,实现快速的原地或异地恢复。Snapshot不包含外部依赖对象,比如 catalog 依赖的外部配置文件、本地 UDF jar 包等。
Cluster Snapshot 包含两部分内容:Metadata Snapshot 和 Data Snapshot。
- Metadata Snapshot
FE 定期通过 checkpoint 的方式生成的 image 文件为 **Metadata Snapshot。**image 文件中包含了集群的元数据信息,包括库表,用户,权限等相关内容。
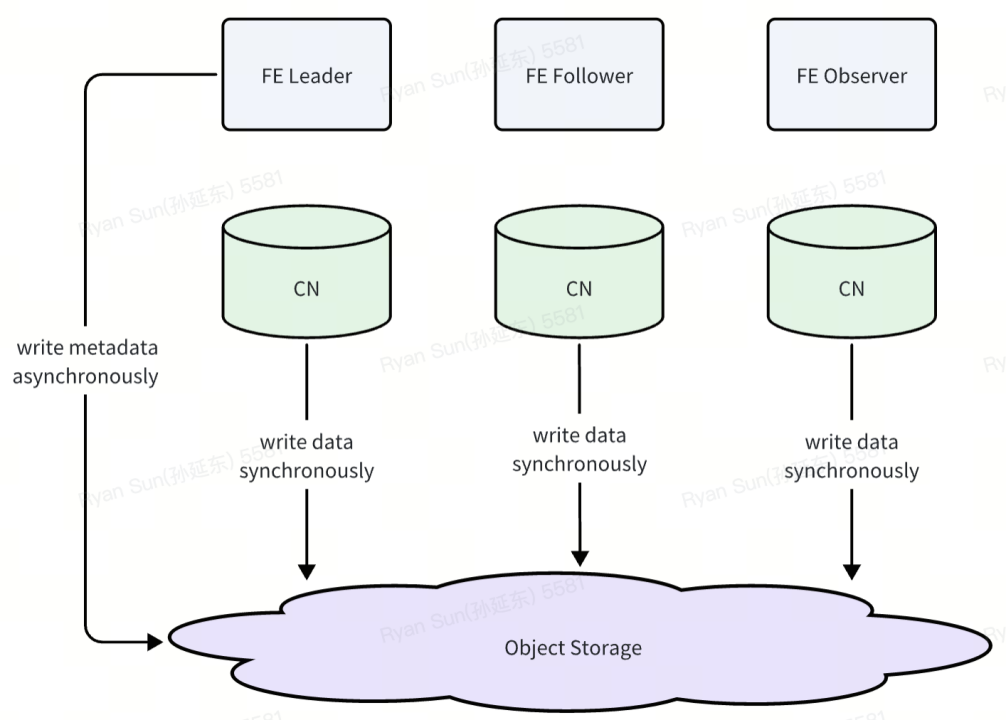
- Data Snapshot
在存算分离的架构中,数据会存储在对象存储上。而对象存储具有高可靠,接近无限容量等特性。所以在 Snapshot 产生的过程中,我们并不需要对数据进行拷贝,只需要保留 Metadata Snapshot 对应的那些数据版本即可。在恢复时可以将元数据与对应的数据版本进行映射。
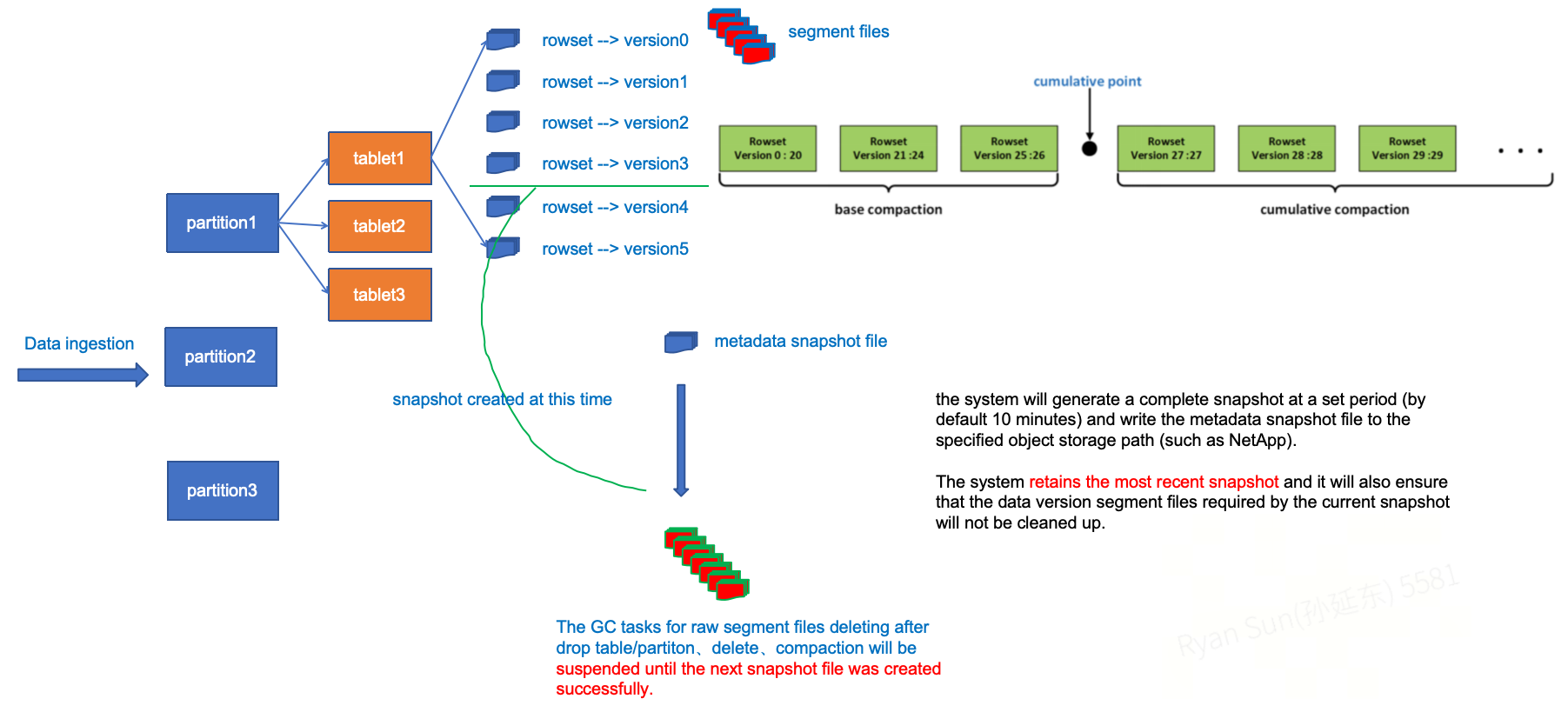
在启用集群自动快照功能后,系统会按照设定周期(默认每 10 分钟)生成一份完整快照,并将 FE 的元数据 image 文件写入指定的对象存储路径。因为原始数据文件本身就已经保存在对象存储中,因此数据层面不会发生额外的数据搬迁,系统默认保留最近一次快照及其所依赖的数据版本。
如上图所示,针对每个 tablet 的数据导入都会产生一个对应版本的 rowset。对于已经包含在未删除的 metadata snapshot 的 tablets,涉及到因为 drop table/partition、delete、Compaction 等操作需要后期 GC 删除无用文件的 GC 任务会在下一个 metadata snapshot 生成之前被阻塞,从而确保当前快照所需的数据版本不会被清理。
**Automated cluster snapshot:**系统会根据设置的快照保留周期,自动创建和保存最新的集群状态快照,且只会保留一个最新可用快照。
Cluster **Restore:**当需要恢复时,用户只需在新集群或原集群中指定快照在对象存储上的路径与存储卷配置,即可将系统恢复至指定时间点状态。恢复过程将自动加载元数据并清理冗余数据,确保数据一致性和可用性。
设计 目标
StarRocks存算分离架构支持自动化快照功能,通过快照实现集群的本地或远程恢复。快照的存储位置与数据目录保持一致。利用快照保存最新 checkpoint 版本中的数据信息,支持恢复集群到最近一次快照状态;
在每次生成新的快照文件时,系统会自动创建对应的快照,并删除历史快照文件,仅保留最新版本。因此,每个集群中自动化快照始终只有一个。
自动化快照由系统自动触发,用户可以通过 SQL 命令修改参数,以控制快照生成的周期。
限制:当前仅支持存算分离架构。
具体操作
由于篇幅所限,关于自动化集群快照的开启、关闭,以及集群快照与任务信息的查看等具体操作步骤,请参见官方文档,此处不再展开。
🔗:https://docs.mirrorship.cn/zh/docs/administration/cluster_snapshot/
Kubernetes 部署环境下的恢复流程
在 Kubernetes 部署环境中,为了能够让 operator 在 "disasterRecovery" 模式下优雅地完成调谐,引入了 disasterRecovery 和 disasterRecoveryStatus 配置项;
spec:
disasterRecovery:
generation: 1
enabled: true
status:
disasterRecoveryStatus:
phase: todo/doing/done
reason: ""
observedGeneration: 1
startTimestamp: xxx
endTimestamp: yyy 配置项 "disasterRecovery" 的 "enabled" 必须为 true;
disasterRecoveryStatus.phase 表示灾难恢复的阶段,包括:todo待执行、doing执行中、done已完成,disasterRecoveryStatus的更新逻辑如下:
-
当 Operator 检测到首次进入灾备模式(disasterRecoveryStatus 为空)或 observedGeneration < generation 时,灾备模式进入 TODO 阶段。
-
在下发修改后的 StatefulSet 后,将 disasterRecoveryStatus.phase 更新为 doing 状态。该状态的持续时间取决于灾备操作的完成时间。
a. Operator 会定期检查 FE Pod 的状态:首先确认其所属的 generation;其次确认 Pod 是否处于 Ready 状态。
-
当 FE Pod 处于 Ready 状态后,将 disasterRecoveryStatus.phase 更新为 done 阶段。
-
随后,Operator 会根据 StarRocksCluster 的配置,正常启动集群。
如何在已运行的集群上执行灾备恢复
推荐在一个空的 StarRocks 集群上启用灾备。如果使用的是已有的 StarRocks 集群,在启用灾备之前需要清理 FE 组件的元数据 和 CN 组件的数据。
1.清理旧的元数据
a. 手动将 FE StatefulSet 的副本数设置为 0;
b. 删除对应的 FE 元数据 PVC。
- 清理旧的数据
a. 手动将 CN StatefulSet 的副本数设置为 0;
b. 删除对应的 CN Cache存储 PVC。
- 启动灾难恢复
4. 异常情况处理
a. CN 本地缓存清理
1). 在就地恢复(inplace recovery) 的场景下,本地 CN 节点可能仍然保留旧的缓存数据。 由于 ID 生成器被重置,相同的文件名可能对应不同的内容,从而导致缓存损坏。
2). 需要手动清理缓存:可以通过登录 Pod 清理缓存,或者强制删除 PV/PVC 卷,让 StatefulSet 为 CN 节点重新创建新的卷。
b. FE 节点就地恢复
1). 在某些情况下,现有 FE 节点可能已经形成一个高可用(HA)集群。在恢复后,fe-0 节 点会使 用新的元数据完成恢复,但 fe-1、fe-2 节点可能仍然保留旧的元数据,并继续形 成 一个 HA 集 群(其中可能有一个是 leader)。
2). 恢复完成后,可能会出现 fe-0 成为 leader(正确状态),而 fe-1/fe-2 形成另一个集群的 情 况。
3). 需要手动检查,并清理 fe-1、fe-2 的元数据目录,以确保能够从这种状态下恢复。
c. generation 字段可用于多次执行灾备。例如,如果上一次的灾备结果不符合预期,可以手动 修改相 关配置并提升 generation 的值,从而重新执行一次灾备。
d. 如果 FE 在生成快照时异常退出,S3 上可能会出现两个快照,此时需要使用较旧的快照进行 恢复。
➜ disaster-recovery git:(master) ✗ s3cmd ls s3://ydx-starrocks-cluster-bucket/data/5b0125af-7ff6-45df-9b60-c896797458ba/meta/image/
DIR s3://ydx-starrocks-cluster-bucket/data/5b0125af-7ff6-45df-9b60-c896797458ba/meta/image/automated_cluster_snapshot_1739446285344/
DIR s3://ydx-starrocks-cluster-bucket/data/5b0125af-7ff6-45df-9b60-c896797458ba/meta/image/automated_cluster_snapshot_1739446405766/Kubernetes 部署环境下的灾备恢复实践
为了让用户更简单方便地参考本文档,我们使用 kube-starrocks Helm Chart 来部署集群。请注意:
-
必须使用 v1.10.0 以上版本的 Operator 和 YAML Manifest;
-
我们在文档中使用 xxx 来替代敏感信息,请根据实际情况设置为合理的值。
创建可用的集群
首先,准备 ./starrocks-values.yaml 配置文件。
operator:
starrocksOperator:
image:
repository: starrocks/operator
tag: v1.10.0
imagePullPolicy: IfNotPresent
replicaCount: 1
resources:
requests:
cpu: 1m
memory: 20Mi
starrocks:
starrocksCluster:
enabledBe: false
enabledCn: true
starrocksCnSpec:
config: |
sys_log_level = INFO
# ports for admin, web, heartbeat service
thrift_port = 9060
webserver_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
image:
repository: starrocks/cn-ubuntu
tag: 3.4.1
replicas: 3
resources:
limits:
cpu: 8
memory: 8Gi
requests:
cpu: 1m
memory: 10Mi
storageSpec:
name: cn
logStorageSize: 1Gi
storageSize: 10Gi
starrocksFESpec:
feEnvVars:
- name: LOG_CONSOLE
value: "1"
config: |
LOG_DIR = ${STARROCKS_HOME}/log
DATE = "$(date +%Y%m%d-%H%M%S)"
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx8192m -XX:+UseG1GC -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time -XX:ErrorFile=${LOG_DIR}/hs_err_pid%p.log -Djava.security.policy=${STARROCKS_HOME}/conf/udf_security.policy"
http_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
sys_log_level = INFO
run_mode = shared_data
cloud_native_meta_port = 6090
enable_load_volume_from_conf = true
cloud_native_storage_type = S3
aws_s3_path = xxx
aws_s3_region = xxx
aws_s3_endpoint = xxx
aws_s3_access_key = xxx
aws_s3_secret_key = xxx
# we add this configuration because we want to get cluster snapshot quickly
automated_cluster_snapshot_interval_seconds = 60
replicas: 3
image:
repository: starrocks/fe-ubuntu
tag: 3.4.1
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 1m
memory: 20Mi
storageSpec:
logStorageSize: 1Gi
name: fe-storage
storageSize: 10Gi注意:我们将 automated_cluster_snapshot_interval_seconds 设置为按每分钟触发。
接下来,使用 Helm 创建集群。
helm install -f ./starrocks-values.yaml starrocks starrocks-community/kube-starrocks --version 1.10.0
# make sure the cluster has been successfully deployed
kubectl get pods
NAME READY STATUS RESTARTS AGE
kube-starrocks-cn-0 1/1 Running 0 23s
kube-starrocks-fe-0 1/1 Running 0 79s
kube-starrocks-fe-1 1/1 Running 0 79s
kube-starrocks-fe-2 1/1 Running 0 79s建表与写入数据
连接 FE
# enter FE pod
kubectl exec -it kube-starrocks-fe-0 bash
# use mysql client to login
mysql -h 127.0.0.1 -P9030 -uroot
...
mysql> 执行以下 SQL 语句:
# create database and table
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
-- create table
CREATE TABLE source_wiki_edit
(
event_time DATETIME,
channel VARCHAR(32) DEFAULT '',
user VARCHAR(128) DEFAULT '',
is_anonymous TINYINT DEFAULT '0',
is_minor TINYINT DEFAULT '0',
is_new TINYINT DEFAULT '0',
is_robot TINYINT DEFAULT '0',
is_unpatrolled TINYINT DEFAULT '0',
delta INT DEFAULT '0',
added INT DEFAULT '0',
deleted INT DEFAULT '0'
)
DUPLICATE KEY(
event_time,
channel,user,
is_anonymous,
is_minor,
is_new,
is_robot,
is_unpatrolled
)
PARTITION BY RANGE(event_time)(
PARTITION p06 VALUES LESS THAN ('2015-09-12 06:00:00'),
PARTITION p12 VALUES LESS THAN ('2015-09-12 12:00:00'),
PARTITION p18 VALUES LESS THAN ('2015-09-12 18:00:00'),
PARTITION p24 VALUES LESS THAN ('2015-09-13 00:00:00')
)
DISTRIBUTED BY HASH(user);
-- insert data
INSERT INTO source_wiki_edit
VALUES
("2015-09-12 00:00:00","#en.wikipedia","AustinFF",0,0,0,0,0,21,5,0),
("2015-09-12 00:00:00","#ca.wikipedia","helloSR",0,1,0,1,0,3,23,0),
("2015-09-12 08:00:00","#ca.wikipedia","helloSR",0,1,0,1,0,3,23,0);
-- select data
mysql> select * from source_wiki_edit;
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
| event_time | channel | user | is_anonymous | is_minor | is_new | is_robot | is_unpatrolled | delta | added | deleted |
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
| 2015-09-12 00:00:00 | #ca.wikipedia | helloSR | 0 | 1 | 0 | 1 | 0 | 3 | 23 | 0 |
| 2015-09-12 00:00:00 | #en.wikipedia | AustinFF | 0 | 0 | 0 | 0 | 0 | 21 | 5 | 0 |
| 2015-09-12 08:00:00 | #ca.wikipedia | helloSR | 0 | 1 | 0 | 1 | 0 | 3 | 23 | 0 |
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
3 rows in set (0.34 sec)生成集群快照
启动备份:
mysql> ADMIN SET AUTOMATED CLUSTER SNAPSHOT ON STORAGE VOLUME builtin_storage_volume;
Query OK, 0 rows affected (0.10 sec)等待备份完成
mysql> SELECT * FROM INFORMATION_SCHEMA.CLUSTER_SNAPSHOT_JOBS;
+------------------------------------------+--------+---------------------+---------------------+-------------+-------------+---------------+
| SNAPSHOT_NAME | JOB_ID | CREATED_TIME | FINISHED_TIME | STATE | DETAIL_INFO | ERROR_MESSAGE |
+------------------------------------------+--------+---------------------+---------------------+-------------+-------------+---------------+
| automated_cluster_snapshot_1739857978127 | 10136 | 2025-02-18 13:52:58 | 2025-02-18 13:54:17 | FINISHED | | |
| automated_cluster_snapshot_1739858117584 | 10137 | 2025-02-18 13:55:17 | NULL | SNAPSHOTING | | |
+------------------------------------------+--------+---------------------+---------------------+-------------+-------------+---------------+
2 rows in set (0.02 sec)
mysql> SELECT * FROM INFORMATION_SCHEMA.CLUSTER_SNAPSHOTS;
+------------------------------------------+---------------+---------------------+---------------+--------------------+------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------+
| SNAPSHOT_NAME | SNAPSHOT_TYPE | CREATED_TIME | FE_JOURNAL_ID | STARMGR_JOURNAL_ID | PROPERTIES | STORAGE_VOLUME | STORAGE_PATH |
+------------------------------------------+---------------+---------------------+---------------+--------------------+------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------+
| automated_cluster_snapshot_1739857978127 | AUTOMATED | 2025-02-18 13:52:58 | 253 | 114 | | builtin_storage_volume | s3://xxx/7351ce6a-f4a4-4937-a876-cb8801085aea/meta/image/automated_cluster_snapshot_1739857978127 |
+------------------------------------------+---------------+---------------------+---------------+--------------------+------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------+注意:由于我们设置了每分钟执行一次备份,下面使用的备份路径可能与上文不同。最终结果可以通过 S3 查看。
s3cmd ls s3://xxx/data/7351ce6a-f4a4-4937-a876-cb8801085aea/meta/image/
sDIR s3://xxx/data/7351ce6a-f4a4-4937-a876-cb8801085aea/meta/image/automated_cluster_snapshot_1739858235830/删除已创建的集群
# 卸载 StarRocks 集群
helm uninstall starrocks
# 删除持久化的数据
kubectl get pvc | awk '{if (NR>1){print $1}}' | xargs kubectl delete pvc
persistentvolumeclaim "cn-data-kube-starrocks-cn-0" deleted
persistentvolumeclaim "cn-log-kube-starrocks-cn-0" deleted
persistentvolumeclaim "fe-storage-log-kube-starrocks-fe-0" deleted
persistentvolumeclaim "fe-storage-log-kube-starrocks-fe-1" deleted
persistentvolumeclaim "fe-storage-log-kube-starrocks-fe-2" deleted
persistentvolumeclaim "fe-storage-meta-kube-starrocks-fe-0" deleted
persistentvolumeclaim "fe-storage-meta-kube-starrocks-fe-1" deleted
persistentvolumeclaim "fe-storage-meta-kube-starrocks-fe-2" deleted创建用于灾备的新集群
我们将复用之前的 starrocks-values.yaml 文件,因此请确保存储文件已妥善保存。接着,准备一个名为 cluster_snapshot.yaml的新文件,其中的内容就是我们在灾备中需要配置的内容。
starrocks:
starrocksCluster:
disasterRecovery:
enabled: true
generation: 1
starrocksFESpec:
# mount the cluster_snapshot.yaml
configMaps:
- name: cluster-snapshot
mountPath: /opt/starrocks/fe/conf/cluster_snapshot.yaml
subPath: cluster_snapshot.yaml
configMaps:
- name: cluster-snapshot
data:
cluster_snapshot.yaml: |
# information about the cluster snapshot to be downloaded and restored
cluster_snapshot:
cluster_snapshot_path: s3://xxx/data/7351ce6a-f4a4-4937-a876-cb8801085aea/meta/image/automated_cluster_snapshot_1739858235830
storage_volume_name: builtin_storage_volume
# Operator will add the other FE followers automatically
# just leave it blank
frontends:[]
# Operator will add the CN nodes automatically
# just leave it blank
compute_nodes:[]
# used for restoring a cloned snapshot
storage_volumes:
- name: builtin_storage_volume
type: S3
location: s3://xxx/data
comment: my s3 volume
properties:
- key: aws.s3.region
value: xxx
- key: aws.s3.endpoint
value: xxx
- key: aws.s3.access_key
value: xxx
- key: aws.s3.secret_key
value: xxx部署集群的命令与第一次不同,这里我们需要同时指定两个 YAML 文件,其中 cluster_snapshot.yaml 是专门用于本次灾备的配置文件。
helm install -f ./starrocks-values.yaml -f cluster_snapshot.yaml starrocks starrocks-community/kube-starrocks --version 1.10.0灾难恢复的详细流程如下:
-
Operator 会启动一个 FE Pod,并启用灾难恢复。
ignore the operator pod
kubectl get pods
NAME READY STATUS RESTARTS AGE
kube-starrocks-fe-0 1/1 Running 0 4m37s
此时,当我们检查 StarRocksCluster 的状态时,显示结果如下:
kubectl get src kube-starrocks -oyaml | less
status:
phase: running
disasterRecoveryStatus:
observedGeneration: 1
phase: doing
reason: disaster recovery is in progress
startTimestamp: "1739860263"-
灾难恢复完成后,Operator 会自动启动其他 Pods。
kubectl get pods
NAME READY STATUS RESTARTS AGE
kube-starrocks-cn-0 1/1 Running 0 7m54s
kube-starrocks-fe-0 1/1 Running 0 7m1s
kube-starrocks-fe-1 1/1 Running 0 7m54s
kube-starrocks-fe-2 1/1 Running 0 7m54s
集群状态显示如下:
kubectl get src kube-starrocks -oyaml | less
status:
phase: running
disasterRecoveryStatus:
endTimestamp: "1739861262"
observedGeneration: 1
phase: done
reason: disaster recovery is done
startTimestamp: "1739860263"验证灾备是否成功
检查数据恢复是否完成。
# enter the pod
kubectl exec -it kube-starrocks-fe-0 bash
# connect mysql
mysql -h 127.0.0.1 -P9030 -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 0
Server version: 8.0.33 branch-3.4-12d148f
Copyright (c) 2000, 2025, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
# get the data
mysql> USE quickstart;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from source_wiki_edit;
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
| event_time | channel | user | is_anonymous | is_minor | is_new | is_robot | is_unpatrolled | delta | added | deleted |
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
| 2015-09-12 08:00:00 | #ca.wikipedia | helloSR | 0 | 1 | 0 | 1 | 0 | 3 | 23 | 0 |
| 2015-09-12 00:00:00 | #ca.wikipedia | helloSR | 0 | 1 | 0 | 1 | 0 | 3 | 23 | 0 |
| 2015-09-12 00:00:00 | #en.wikipedia | AustinFF | 0 | 0 | 0 | 0 | 0 | 21 | 5 | 0 |
+---------------------+---------------+----------+--------------+----------+--------+----------+----------------+-------+-------+---------+
3 rows in set (2.00 sec)