一、卷积神经网络CNN
一、CNN图像原理
1、了解图像的原理
在深度学习中,通过神经网络模拟人脑的工作方式来处理和分析图像数据。
图像在计算机中是一堆按顺序排列的数字,数值为0到255。0表示最暗,255表示最亮,每个数字代表像素点的亮度或颜色值。这些数字矩阵被输入到神经网络中进行处理和学习。神经网络由多个层组成,每一层都包含一些神经元,这些神经元通过学习从输入数据中提取特征。
2、举例

例如上述的一张图片,为只有黑色和白色的灰度图,每个小方块代表一个像素点,每个像素点上有其对应的像素值,像素值的大小决定像素的明暗程度。

大多数图片表达方式都是RGB的颜色模型,可表示为红(red)、绿(green)、蓝(blue)三种颜色,即一张图片由红、绿、蓝三原色的色光以不同的比例相加,以产生多种多样的色光,RGB颜色模型中,单个矩阵就扩展成了有序排列的三个矩阵,也可以用三维张量去理解。 其中的每一个矩阵又叫这个图片的一个channel(通道),宽, 高, 深来描述。
二、CNN图像识别
1、画面不变性
知道一个物体不管在画面左侧还是右侧,都会被识别为同一物体,这一特点就是不变性,例如有一张图片想要使用卷积神经网络训练并识别它,那么就要让他经历位置的旋转、移动、颜色的各种变化等等,对这些图片进行训练然后去识别,能够正确识别即可表示为图像不变性。

2、主要表现
1)平移不变性
CNN对于图像中物体的平移(即位置的改变)具有一定的不变性。即使物体在图像中移动了一些,CNN仍然能够正确地识别它。这是因为CNN中的卷积层对输入图像的局部区域进行特征提取,并且在后续的池化层中进行降采样,所以即使物体移动了一点,某些特征仍然能够被正确检测到。
2)尺度不变性
CNN对于图像中物体的尺度(即大小的改变)具有一定的不变性。即使物体的大小发生变化,CNN仍然能够正确地识别它。这是因为在卷积层中使用的滤波器是局部感知场,可以检测到物体的不同尺度的特征。
3)旋转不变性
CNN对于图像中物体的旋转具有一定的不变性。即使物体发生了旋转,CNN仍然能够正确地识别它。这是因为卷积层中的滤波器能够检测到旋转不变的特征,例如边缘和纹理。
三、传统神经网络识别

1)数据预处理
首先,将图像数据进行预处理,包括缩放、裁剪、归一化等操作。这些操作有助于提高模型的鲁棒性和减少计算负担。
2)特征提取
将预处理后的图像数据转化为向量形式。通常使用特征提取方法,如边缘检测、颜色分布等,将图像转化为有意义的特征向量。这些特征向量可以直接作为输入数据供神经网络处理。
3)搭建神经网络模型
定义一个前馈神经网络模型。前馈神经网络由输入层、隐藏层和输出层组成。隐藏层可以包含多个层,每个层包含多个神经元。每个神经元通过权重和激活函数将上一层的输出传递给下一层。
4)模型训练
使用带有标记的训练数据集对神经网络模型进行训练。在训练过程中,通过反向传播算法计算模型参数的梯度,并使用优化算法(如随机梯度下降)更新模型参数,以使模型能够更好地拟合训练数据。
5)模型评估和预测
使用带有标记的测试数据集对训练好的模型进行评估。通过计算模型在测试数据上的准确率、精确率、召回率等指标,可以评估模型的性能和泛化能力。对于新的未知图像,将其输入训练好的模型中,通过前向传播算法计算模型的输出。输出通常是一个概率分布,表示图像属于各个类别的概率。可以选择概率最高的类别作为图像的分类结果。
6)缺点
传统神经网络在图像识别任务上的性能可能相对较弱,因为它往往难以自动地提取和学习到更高级别、更抽象的特征表示。
最好的解决办法就是用大量物体位于不同位置的数据训练,同时增加网络的隐藏层个数从而扩大网络学习这些变体的能力。
四、卷积神经网络识别图片
1)如何识别稍微变形的图片

有上述一个标准的X图片(左侧),如何才能识别略微变形的图片X(右侧),此时可以利用一个卷积核来不停地扫描整幅原始图片中的部分内容,将图片一块一块的取出,得到原始图片的数据信息,然后再将待测试的图片以同样的方式取出,比对两幅图像中的构造来判断结果,例如下图所示:
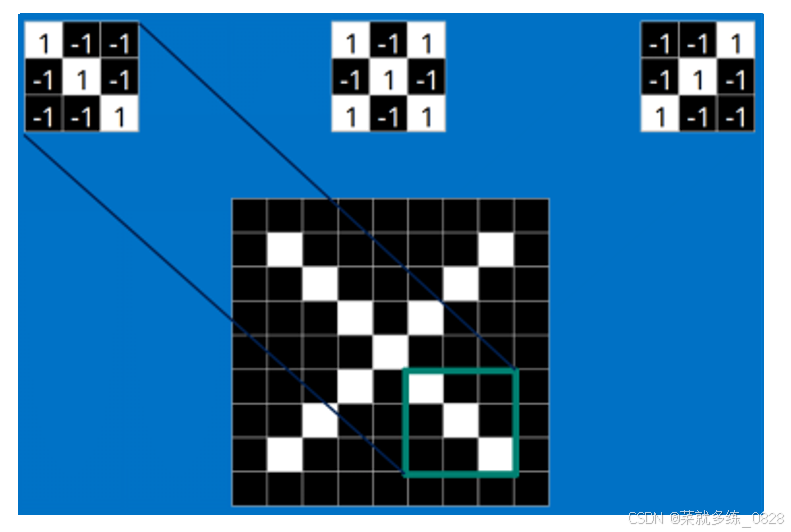
2)什么是卷积核
卷积核也称为滤波器或特征检测器,在CNN中,卷积核是一个小的矩阵或张量,它通过与输入的图像进行卷积操作来提取图像中的特征。卷积操作可以看作是将卷积核与输入数据的某一部分进行点积运算,然后将结果相加得到一个输出值。
卷积核的大小通常是正方形的,并且由多个通道组成,其中每个通道对应一个特征。例如,可以有一个大小为3x3x3的卷积核,其中3x3表示卷积核的空间大小,3表示输入图像的通道数。
3)操作方式

即首先有一张图片,然后设置一个卷积核,将这个卷积核顺序对应图片的每一个位置,将然后使其进行点乘,将相乘的结果求和得到一个值即为卷积后图片的像素点的像素值,最终内积完得到一个结果叫特征图。
4)举例
对于一张彩色图像,其由三个通道的颜色构成,所以对其进行卷积操作的时候也是需要使用一个卷积核分别对每个通道的图片进行内积操作,每张图片中的一个部位和卷积核相乘后求和得到一个值,然后再将三个通道相乘得到的值相加即可得到卷积后的单个像素值,如下所示:
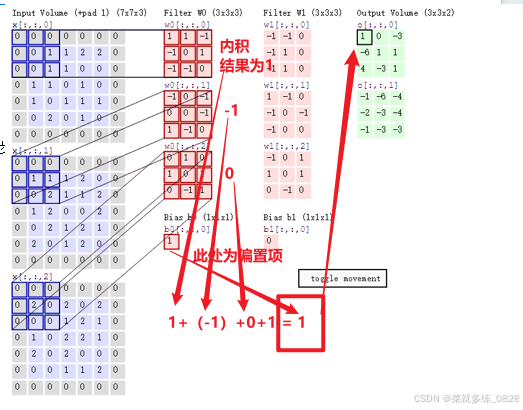
一个卷积核肯定难以完全的到所有图片的数据信息,所以有了第二个卷积核,甚至更多的卷积核使用同样的操作,再次得到一个新的卷积后的结果,多个卷积核做内积后得到多个结果即可表示为该图片的多个特征,即为多个特征图。

5)卷积操作存在的问题
a. 步长stride:卷积核每次滑动的位置步长。
b. 卷积核的个数:决定输出的depth厚度。同时代表卷积核的个数。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
上图表示为,数据窗口每次移动两个步长取3*3的局部数据,即stride=2。 两组神经元(卷积核),即depth=2,意味着有两个滤波器, zero-padding=1。
三、卷积神经网络原理
1、图片经过卷积核处理后的样子

不同的卷积核处理完得到的结果不同,但是结果的轮廓一样
2、卷积神经网络的系统
CNN的系统结构包括多个层级,一般包括输入层、卷积层、池化层、全连接层和输出层。

输入层:接收原始图像作为输入。
卷积层:通过应用卷积核对输入图像进行卷积操作,提取图像的特征。每个卷积层可以包含多个卷积核,每个卷积核负责提取不同的特征。
激活函数层:通过应用非线性的激活函数(如ReLU)来引入非线性变换,增强网络的表达能力。
池化层:通过减少空间维度,降低特征图的大小,同时保留主要的特征。常用的池化操作包括最大池化和平均池化。
全连接层:将池化层的输出连接到一个或多个全连接层,进行全局特征关联,提取更高级别的特征。
输出层:最后一个全连接层通常是一个softmax层,用于输出模型的预测结果。
通过反向传播算法,CNN可以从标记的训练数据中学习到最优的网络参数,以便能够准确地识别和分类图像。
3、卷积层计算结果
有一张图片经过卷积核处理后得到一个特征图,原图的宽度为W1,高度为H1,卷积核的长度为FH,宽度为FW,卷积核滑动的步长为S,图片边界填充的层数为P,求处理完的特征图的长度H2,宽度W2,有如下公式即可表达:

例如:
输入数据为32*32*3的图像(3表示3个通道,三张图片),用10个5*5*3的卷积核来进行操作,步长为1,边界0填充为2,最终输出结果为?
(32-5+2*2)/1 +1 =32,输出规模为32*32*10的特征图
(此处可记住一个值5 1 2,表示为卷积核个数为5,步长为1,填充层数为2,输入图片和输出图片大小一致)
四、池化层Pooling
1)作用
池化层是一种降采样,减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。
2)常见的池化层
平均池化(average pooling):计算图像区域的平均值作为该区域池化后的值。
最大池化(max pooling):选图像区域的最大值作为该区域池化后的值。是最为常见的。
全局平均池化、全局最大池化。
3)池化层操作方法
与卷积层类似,池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为 池化窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,池化层不包含参数。

通常来说,CNN的卷积层之间都会周期性地插入池化层。
4)最大池化的原理分析
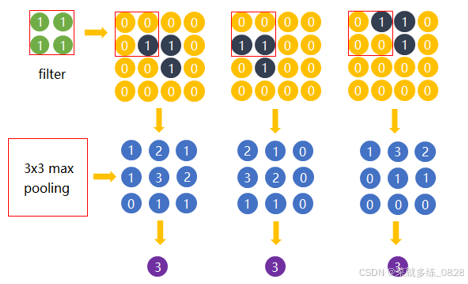
如图所示,首先对一幅图像做卷积处理,然后得到的结果做最大池化得到一个值3,然后对特征相同位置不同的另外几幅图像分别作卷积以及池化处理,最终得到的结果同样是相同的,此时即可发现图像特征的位置不影响结果
五、全连接层
当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。 全连接层 (也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。 通常卷积网络的最后会将末端得到的长方体平摊(flatten)成一个长长的向量,并送入全连接层配合输出层进行分类。


六、感受野
感受野 (receptive field)是指卷积层中一个神经元(或滤波器)对输入层的区域的感知范围。换句话说,它表示了一个神经元能够"看到"的输入数据的局部区域,其大小取决于神经网络的结构,具体而言,它取决于卷积层的滤波器大小、步幅和填充方式。

例如,一个卷积神经网络的第一个卷积层,滤波器大小为3x3,步幅为1,没有填充。在这种情况下,一个神经元的感受野将是3x3的局部区域。如果有多个卷积层堆叠在一起,每一层都应用相同的滤波器大小和步幅,那么随着网络的深度增加,感受野也将逐渐增大。

较小的感受野能够捕捉到输入数据的细节和局部特征,而较大的感受野则能够捕捉到更宽范围的上下文信息和全局特征。
七、卷积神经网络的多种模型
LeNet:第一个成功的卷积神经网络应用
AlexNet:类似LeNet,但更深更大。使用了层叠的卷积层来抓取特征(通常是一个卷积层马上一个max pooling层)
ZF Net:增加了中间卷积层的尺寸,让第一层的stride和filter size更小。
GoogLeNet:减少parameters数量,最后一层用max pooling层代替了全连接层,更重要的是Inception-v4模块的使用。
VGGNet:只使用3x3 卷积层和2x2 pooling层从头到尾堆叠。
ResNet:引入了跨层连接和batch normalization。
DenseNet:将跨层连接从头进行到尾。
一、卷积神经网络CNN
1、什么是CNN
卷积神经网络是一种深度学习模型,主要应用于图像和视频处理任务。它的设计灵感来源于生物视觉系统的工作原理。
2、核心
核心是卷积层,这是一种通过在输入数据上应用滤波器(也称为卷积核)来提取特征的操作。卷积层的输出是一系列的特征图,每个特征图表示一种特定的图像特征,例如边缘、纹理等。这种特征提取的方式可以捕捉到图像中的局部模式,并且在不同位置共享参数,从而提高了模型的效率和泛化能力。
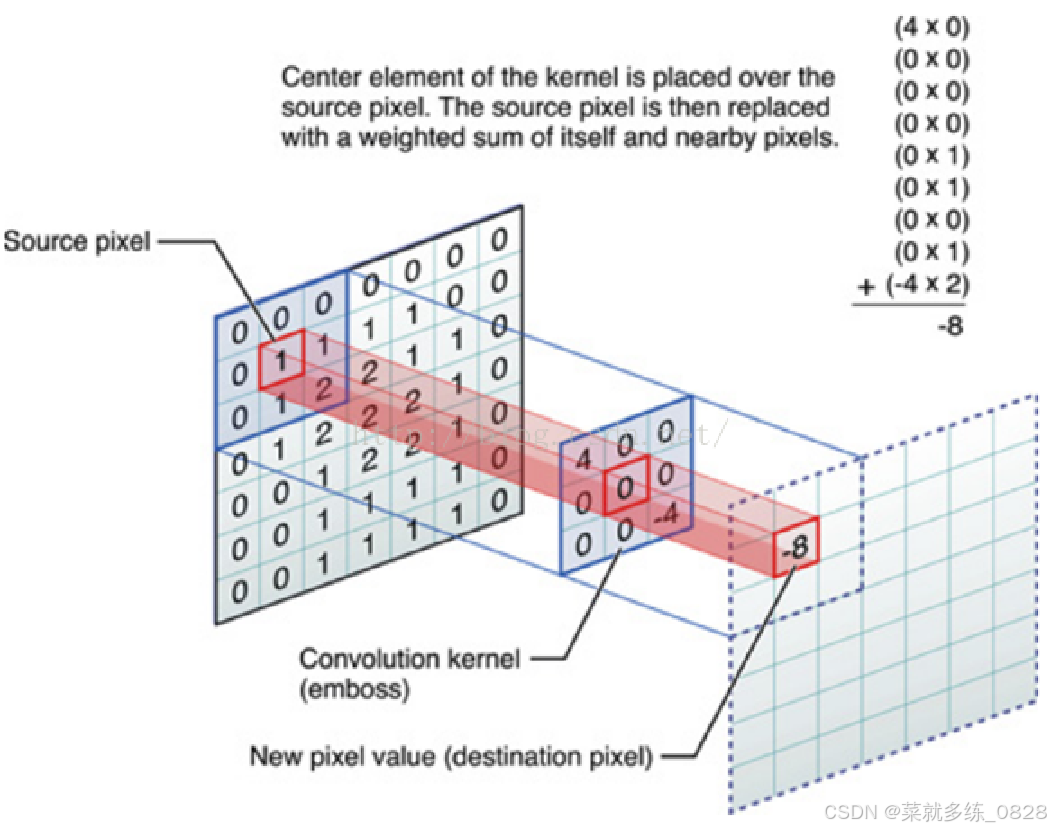
3、构造
CNN还包括池化层 ,用于减小特征图的尺寸 ,降低计算复杂度,增加模型的平移不变性。
卷积神经网络还可以包含多个卷积层和池化层的堆叠 ,以及全连接层(Fully Connected Layer)用于进行分类或回归等任务。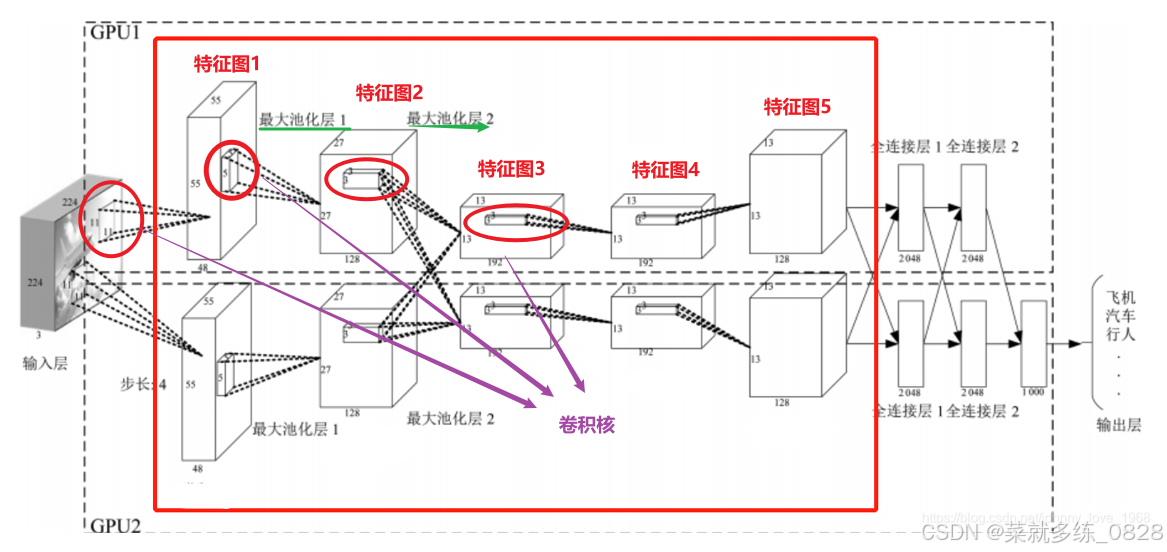
二、案例实现
1、下载训练集、测试集
通过现有的库调用其用法直接去下载现成的手写数字的数据集,这些手写数字集共有70000张图片,这些图片都有其对应的标签,大小为28*28,灰度图,数字居中,直接使用即可。
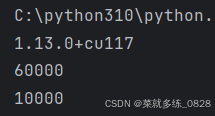
将这70000张图片,60000张当做训练集,10000张当做测试集。
import torch
print(torch.__version__)
"""MNIST包含70,000张手写数字图像:60,000张用于训练,10,000张用于测试。
图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。"""
from torch import nn # 导入神经网络模块
from torch.utils.data import DataLoader # 数据包管理工具,打包数据,
from torchvision import datasets # 封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor # 数据转换,张量,将其他类型的数据转换为tensor张量,numpy arrgy,
"""下载训练数据集,图片+标签"""
training_data = datasets.MNIST( # 跳转到函数的内部源代码,pycharm 按下ctrl +鼠标点击
root='data', # 表述下载的数据存放的根目录
train=True, # 表示下载的是训练数据集,如果要下载测试集,更改为False即可
download=True, # 表示如果根目录有该数据,则不再下载,如果没有则下载
transform=ToTensor() # 张量,图片是不能直接传入神经网络模型
# 表示制定一个数据转换操作,将下载的图片转换为pytorch张量,因为pytorch只能处理张量tensor类型的数据
)
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor() # Tensor是在深度学习中提出并广泛应用的数据类型,它与深度学习框架(如 PyTorch、TensorFlo
) # NumPy 数组只能在CPU上运行。Tensor可以在GPU上运行,这在深度学习应用中可以显著提高计算速度。
print(len(training_data))
print(len(test_data))实现结果就是当前代码的目录多出了一个data文件,里面存放的就是下载好的手写数字的图片,打印内容为下载的图片个数
2、展示部分图片
取出9张图片,将其展示在画布上
from matplotlib import pyplot as plt # 导入绘图库
figure = plt.figure() # 设置一个空白画布
for i in range(9):
img,label = training_data[i+59000] # 提取第59000张图片开始,共9张,返回图片及其对应的标签值
figure.add_subplot(3,3,i+1) # 在画布创建3行3列的小窗口,通过遍历的值i来确定每个画布展示的图片
plt.title(label) # 设置每个窗口的标题,设置标签为上述返回的标签值
plt.axis('off') # 取消画布中的坐标轴的图像
plt.imshow(img.squeeze(),cmap='gray') # plt.imshow()将NumPy数组data中的数据显示为图像,并在图形窗口中,
a = img.squeeze() # img.squeeze()从张量img中去掉维度为1的。如果该维度的大小不为1,则张量不会改变。
plt.show()运行结果:

三、图片打包
因为图片的数量太多,将其一张一张的放入GPU进行计算太耗费时间,而且还浪费资源,所以将64张图片打包成一份,将这一整个数据包传入GPU使其计算,这样大大增加了运行的效率。
train_dataloader = DataLoader(training_data,batch_size=64) # 调用上述定义的DataLoader打包库,将训练集的图片和标签,64张图片为一个包,
test_dataloader = DataLoader(test_data,batch_size=64) # 将测试集的图片和标签,每64张打包成一份
for x,y in test_dataloader:
# x是表示打包好的每一个数据包,其形状为[64,1,28,28],64表示批次大小,1表示通道数为1,即灰度图,28表示图像的宽高像素值
# y表示每个图片标签
print(f"shape of x[N,C,H,W]:{x.shape}") # 打印图片形状
print(f"shape of y:{y.shape}{y.dtype}") # 打印标签的形状和数据类型
break # 跳出并终止循环,表示只遍历一个包的数据情况四、判断当前使用的CPU还是GPU
"""判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU""" # 返回cuda,mps,cpu, m1,m2集显CPU+GPU RTX3060
device = "cuda" if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") # 字符串的格式化。CUDA驱动软件的功能:pytorch能够去执行cuda的命令,cuda通过GPU指令集
# 神经网络的模型也需要传入到GPU,1个batchsize的数据集也需要传入到GPU,才可以进行训练。五、定义卷积神经网络
"""定义神经网络"""
class CNN(nn.Module): # 继承nn算法中的Module
def __init__(self): # 这里输入大小为(1,28,28)
super(CNN,self).__init__()
self.conv1 = nn.Sequential( # 第一层卷积, 将多个层组合成一起。
nn.Conv2d( # 二维卷积成,2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=1, # 输入图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16, # 输出多少个特征图,也可表示卷积核的个数
kernel_size=5, # 卷积核大小,5*5
stride=1, # 卷积核移动的步长
padding=2, # 边缘填充层数
), # 输出的特征图为(16*28*28)
nn.ReLU(), # 设置激活层,引入非线性,增强表达能力,relu层,不会改变特征图的大小(16*28*28)
nn.MaxPool2d(kernel_size=2), # 池化层,大小为2*2,进行最大池化,压缩图像大小,输出结果为:(16*14*14)
)
self.conv2 = nn.Sequential( # 第二层卷积, 输入(16*14*14),定义两个二维卷积层,用于连续卷积
nn.Conv2d(16,32,5,1,2), # 输出(32*14*14)
nn.ReLU(), # relu层(32*14*14)
nn.Conv2d(32,32,5,1,2), # 输出(32*14*14)
nn.ReLU(), # (32,14,14)
nn.MaxPool2d(2), # 最大池化,输出(32*7*7)
)
self.conv3 = nn.Sequential( # 输入(32*7*7)
nn.Conv2d(32, 64, 5, 1, 2), # (64*7*7)
nn.ReLU(), # 输出(64*7*7)
)
self.out = nn.Linear(64*7*7,10) # 全连接层得到的结果
def forward(self, x): # 定义前向传播
x = self.conv1(x) # 对传入模型的图片数据进行第一层卷积处理
x = self.conv2(x)
x = self.conv3(x) # 输出(64,64,7,7)
x = x.view(x.size(0),-1) # 重新调整张量的形状,即flatten操作,结果为:(batch_size,64*7*7)
# x.size(0)表示获取第一个维度的大小,-1表示自动计算维度大小
# x.view(x.size(0),-1)将张量x重新调整为两维张量,其中第一维的大小保持不变(即x.size(0)),而第二维的大小是自动计算的,以确保总元素数量与原始张量相同。
output = self.out(x)
return output
model = CNN().to(device) # 将模型传入GPU
print(model) # 打印模型的结构六、训练、测试模型
def train(dataloader,model,loss_fn,optimizer): # 导入参数,dataloader表示打包,数据加载器,model导入上述定义的神经网络模型,loss_fn表示损失值,optimizer表示优化器
model.train() # 模型设置为训练模式
# 告诉模型,我要开始训练,模型中权重w进行随机化操作,已经更新w。在训练过程中,w会被修改的
# #pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
# 一般用法是:在训练开始之前写上model.train(),在测试时写上model.eval()。
batch_size_num = 1
for x,y in dataloader: # 遍历打包的图片的每一个包中的每一张图片及其对应的标签,其中batch为每一个数据的编号
x,y = x.to(device),y.to(device) # 把训练数据集和标签传入cpu或GPU
pred = model.forward(x) # 模型进行前向传播,输入图片信息后得到预测结果,forward可以被省略,父类中已经对次功能进行了设置。自动初始化w权值
loss = loss_fn(pred,y) # 调用交叉熵损失函数计算损失值loss,输入参数为预测结果和真实结果,
# Backpropaqation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() # 梯度值清零,在反向传播之前先清除之前的梯度
loss.backward() # 反向传播,计算得到每个参数的梯度值w
optimizer.step() # 根据梯度更新权重w参数
loss_value = loss.item() # 从tensor数据中提取数据出来,tensor获取损失值
if batch_size_num % 200 == 0: # 判断遍历包的个数是否整除于200,用于将训练到的包的个数打印出来,整除200目的是节省资源
print(f"loss:{loss_value:>7f} [number: {batch_size_num}]") # 打印损失值及其对应的值,损失值最大宽度为7,右对齐
batch_size_num += 1 # 每遍历一个包增加一次,以达到显示出来遍历的包的个数
def test(dataloader,model,loss_fn): # 输入参数打包的图片、训练好的模型、以及损失值
size = len(dataloader.dataset) # 返回测试数据集的样本总数
num_batches = len(dataloader) # 返回当前dataloader配置下的批次数
model.eval() # 表示此为模型测试,w就不能再更新。
test_loss,correct = 0, 0 # 设置总损失值初始化为0,正确预测结果初始化为0
with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算
for x,y in dataloader: # 遍历测试集中的每个包的每个图片及其对应的标签
x,y = x.to(device),y.to(device) # 将其传入gpu
pred = model.forward(x) # 图片数据进行前向传播
test_loss += loss_fn(pred,y).item() # test_loss是会自动累加每一个批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # pred.argmax(1) == y用于判断预测结果最大值对用的标签是否与真实值相同,然后将判断结果的bool值转变为浮点数并求和
a = (pred.argmax(1) == y) # dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches # 总损失值除以打包的批次数,返回测试的每一个包的损失值的均值,能来衡量模型测试的好坏。
correct /= size # 平均的正确率
print(f"Test result: \n Accuracy:{(100 * correct)}%, Avg loss:{test_loss}") # 打印测试集测试结果
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(),lr=0.001) # 创建一个优化器,SGD为随机梯度下降算法,学习率或者叫步长为0.0045
epochs = 8 # 设置训练的轮数为8轮,因为模型中设置了权重值的更新,所以重复训练会更新模型的权值
for i in range(epochs):
print(f"Epoch {i+1}\n--------------------")
train(train_dataloader,model,loss_fn,optimizer)
print('Done!!')
test(test_dataloader,model,loss_fn) # 导入测试集进行测试运行结果:

一、数据增强
1、什么是数据增强
数据增强(data augmentation)是指通过对原始训练数据进行一系列变换和扩充,生成新的训练样本,以增加训练数据的多样性和数量,从而提升深度学习模型的泛化能力和鲁棒性。
2、目的
模拟真实世界中的不同情况和变化,使模型对各种情况都能准确识别和预测。