我整理好的1000+面试题,请看
大模型面试题总结-CSDN博客
或者
https://gitee.com/lilitom/ai_interview_questions/blob/master/README.md
最好将URL复制到浏览器中打开,不然可能无法直接打开
好了,我们今天针对上面的问题,
大模型训练需要设置温度系数吗?
那肯定是不需要的,当然,面试官会总推理的环节出发先问你推理这块需不需要设置温度系数,然后再过度到问你训练环节需不需要。其实在训练中,温度系数为1,可以理解为不需要设置。
我们直接打开千问3的源码看一看,https://github.com/huggingface/transformers/blob/52c5c6582bdef8bd0f0a9238c9d6703137a10583/src/transformers/models/qwen3/modeling_qwen3.py#L197
也即:
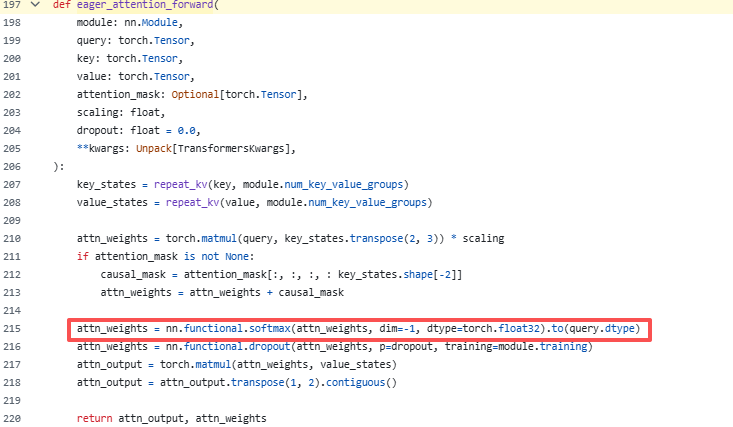
看到是没有温度的。
具体softmax是怎么算的可以看下面(对此知道的可以不用看了):
LLMs 几乎总是出于实际原因输出未缩放的 logits(原始分数),而不是直接输出概率。这只是意味着输出可以是负无穷到正无穷之间的任何值,而不是像概率那样在0到1之间,并且原始分数与其重要性成正比:例如,值100比值3重要得多。为了获得实际概率,这些原始分数随后使用 softmax 函数进行指数化和归一化:
其中下一个 token i 的概率 P(token_i) 是指数化的原始分数,归一化后除以所有不同可用 token 的所有指数化原始分数的总和。具体而言,在"I went to the park and saw a..."的例子中,我们可以计算 P(dog) 为:
指数化有几个实际用途:
-
指数化保证正值:由于概率必须是非负的且总和为1,指数化确保 softmax 函数的所有输出都是正值。
-
指数化增强差异:指数函数增长迅速,这意味着即使 logits 的微小差异也可能导致最终概率的显著差异。例如,如果一个 logit 比其他 logit 稍大,其指数化值将主导分母中的总和,导致该类别获得高得多的概率。例如,e^4 ≈ 54.6,而 e^4.1 ≈ 60.3。