目录
[一、 核心创新与架构](#一、 核心创新与架构)
[1. 多分辨率联合训练](#1. 多分辨率联合训练)
写在前面
LTXVideo是基于Transformer的潜在扩散模型(Latent Diffusion Model),通过整合视频变分自编码器(Video-VAE)和去噪Transformer的功能,实现了高效且高质量的视频生成。
LTXVideo是现在开源模型中速度数一数二的(可能是最快的),它的高速来自于高压缩比,关于压缩比可以看这篇文章,那LTXVideo除了高压缩比还有什么创新呢?LTXVideo的论文说了什么呢?下面我来简单解读一下。
论文地址:https://arxiv.org/abs/2501.00103
项目地址:https://github.com/Lightricks/LTX-Video
一、 核心创新与架构
LTX-Video的核心创新在于整体化设计,将Video-VAE和去噪Transformer深度融合,而非传统方法中独立处理两者。关键设计包括:
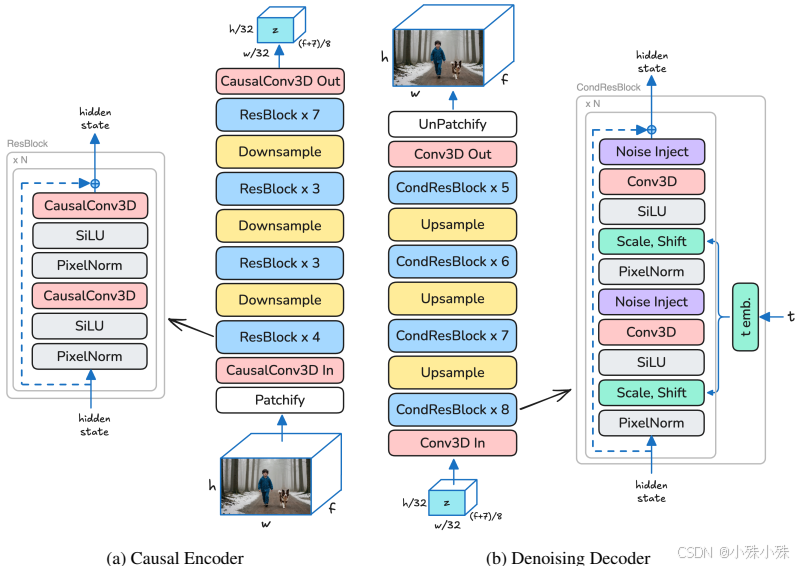
1.高压缩率Video-VAE
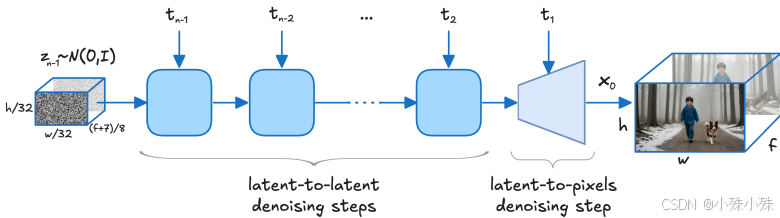
通过将图像块化(patchifying)操作从Transformer输入端移至VAE输入端,实现了1:192的压缩率(空间下采样32×32,时间下采样8帧/标记)。这种高压缩率显著减少了计算量,使Transformer能在压缩后的潜在空间中高效执行全时空自注意力(见图2)。
2.共享去噪目标
VAE解码器不仅负责潜在空间到像素空间的转换,还承担最终去噪步骤,直接在像素空间生成干净结果。这一设计避免了传统方法中高频细节丢失的问题,同时无需额外的上采样模块(见图4)。
二、关键技术改进
1.Video-VAE的优化
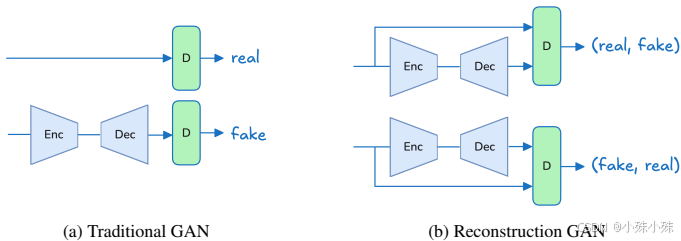
(1)重建GAN(rGAN):
传统GAN判别器需区分真实与生成样本,而rGAN通过对比输入与重建样本的成对数据,简化判别任务(见图5)。实验表明,rGAN显著提升了重建质量和训练稳定性。
(2)多层噪声注入:
借鉴StyleGAN,在VAE解码器的多层中注入噪声,增强高频细节的多样性生成能力。
(3)视频离散小波变换(DWT)损失:
通过3D DWT计算输入与重建视频的多频段L1距离,弥补传统像素损失的不足。
2.Transformer的增强
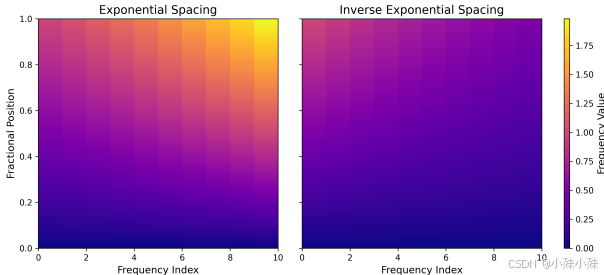
(1)旋转位置嵌入(RoPE):
替换绝对位置编码,采用归一化分数坐标的RoPE(见图7),提升时空一致性。实验显示指数频率间距优于逆指数间距(见图8)。

(2)查询-键归一化(QK Norm):
对查询(Q)和键(K)张量应用RMSNorm,防止注意力logits数值爆炸。在2B参数量下,注意力权重熵值提升0.7,避免过度聚焦局部区域。
三、训练与数据策略
1.多分辨率联合训练
(1)动态令牌丢弃:
训练时随机丢弃0%-20%的令牌,强制模型学习鲁棒表征。例如,在512×384视频中丢弃15%令牌后,生成质量仅下降3%(FID变化)。
(2)图像-视频统一训练:
将图像视为单帧视频,共享同一潜在空间。这使得模型能从LAION-5B等图像数据集中学习丰富概念,提升文本对齐能力。
2.数据增强与过滤
(1)美学评分模型:
基于Siamese网络对视频帧进行美学排序(见图11),过滤低分样本(如模糊或低对比度画面)。在200万视频数据集中,过滤后保留率62%。
(2)运动显著性检测:
剔除静态占比>80%的视频(如访谈片段),确保训练集动态内容丰富。
四、性能与实验结果
1.速度与质量
在NVIDIA H100 GPU上,LTX-Video仅需2秒生成5秒768×512分辨率视频(24fps),速度快于实时播放,且优于同类规模的模型(如MovieGen、CogVideoX等)。表1对比了模型规格,LTX-Video在压缩率和计算效率上显著领先。
2.用户评测
针对文本到视频和图像到视频任务,LTX-Video在视觉质量、运动保真度和提示一致性上均优于竞品(见图15)。

五、局限性与社会影响
1.局限性:对模糊提示的敏感性;目前仅支持短视频生成(≤10秒);未广泛测试领域特定任务(如多视角合成)。
2.社会价值:开源模型降低硬件门槛(支持消费级GPU);高效设计减少能耗,推动可持续AI发展;提供使用指南以防范生成内容的滥用风险。
六、总结
LTX-Video通过三阶段协同设计(高压缩编码→潜在扩散→像素级精修)重新定义了视频生成范式。其技术组合(如rGAN、RoPE、QKNorm)不仅提升效率,更开辟了端到端视频生成的新路径。开源实现将加速行业应用,如广告快速制作或教育内容生成。
LTX-Video就介绍到这里!
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583