K8s 集群环境搭建 - yaml 版本(一)
文章目录
- [K8s 集群环境搭建 - yaml 版本(一)](#K8s 集群环境搭建 - yaml 版本(一))
- [一、k8s 集群架构](#一、k8s 集群架构)
- 二、环境规划
-
- [1. 集群类型](#1. 集群类型)
- 2.环境准备
- [3. k8s 集群搭建](#3. k8s 集群搭建)
- [三、k8s 命令](#三、k8s 命令)
-
- [1. 操作 NameSpace](#1. 操作 NameSpace)
- [2. 操作 Pod](#2. 操作 Pod)
- [3. 操作 Deployment](#3. 操作 Deployment)
- [4. 操作 Service](#4. 操作 Service)
- [5. 操作 Ingress](#5. 操作 Ingress)
- [6. 操作 ConfigMap](#6. 操作 ConfigMap)
- [7. 操作 Secret](#7. 操作 Secret)
- [四、安装 harbor](#四、安装 harbor)
- [五、配置 StorageClass](#五、配置 StorageClass)
-
- [1. 集成 Minio](#1. 集成 Minio)
- [2. 集成 NFS](#2. 集成 NFS)
一、k8s 集群架构
-
工作方式:
- N Master Node + N Worker Node:N主节点+N工作节点; N>=1,我们这里采用
1主节点 + 2工作节点的方式。
- N Master Node + N Worker Node:N主节点+N工作节点; N>=1,我们这里采用
-
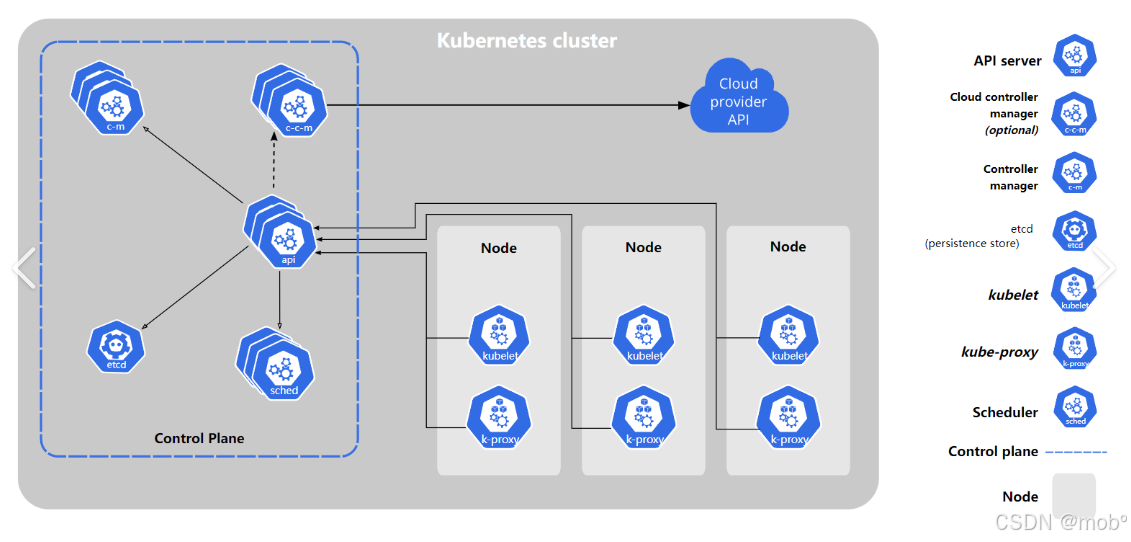
组织架构图:
-
Control Plane(控制平面):是集群的 "大脑",
负责决策和管理整个集群的状态。它由多个核心组件组成,每个组件各司其职又相互协作。- 作用:
- 维护集群的期望状态。
- 处理用户提交的配置。
- 做出调度决策。
- 监控并自动恢复异常。
- 作用:
-
Control Plane(控制平面)组件包含:
-
kube-apiserver:所有操作的统一入口,提供 RESTful API。- 唯一与 etcd 直接交互的组件。
- 提供认证、授权、准入控制机制。
- 支持资源的增删改查和监听。
- 可水平扩展以提高性能。
- 工作流程。
- 接收客户端请求。
- 验证请求合法性。
- 读取 / 更新 etcd 中的数据。
- 返回响应。
-
etcd:集群的数据库,存储所有集群状态信息。- 高可用的键值存储系统,基于 Raft 协议保证一致性,存储包括:配置信息、Pod 状态、Service 信息等。
-
kube-scheduler:负责 Pod 的调度决策。- 工作流程:预选 (Predicate):筛选出满足 Pod 基本要求的节点、优选 (Priority):对候选节点打分排序、绑定 (Bind):将 Pod 分配给得分最高的节点。
-
调度的考量因素有:资源需求(CPU、内存、GPU 等)、节点亲和性与反亲和性、Pod 亲和性与反亲和性、污点与容忍度、数据局部性、优先级与抢占。
-
kube-controller-manager:运行各种控制器进程,维持集群状态。- 主要控制器:
- 节点控制器:监控节点健康状态。
- 副本控制器:维持 Pod 副本数量。
- 端点控制器:管理 Service 与 Pod 的映射关系。
- 服务账号控制器:管理服务账号和令牌。
- 命名空间控制器:处理命名空间的生命周期。
- 垃圾回收控制器:清理依赖资源。
- 主要控制器:
-
cloud-controller-manager (可选):与云服务提供商集成。
-
-
Control Plane(控制平面)组件间协作流程,以创建一个 Deployment 为例:
- kubectl apply -f deployment.yaml 发送请求到 kube-apiserver
- API Server 将配置存入 etcd
- Deployment 控制器发现新资源,创建 ReplicaSet
- ReplicaSet 控制器创建相应数量的 Pod
- Scheduler 为每个 Pod 选择合适的节点
- 目标节点的 kubelet 接收到 Pod 配置并启动容器
- 所有状态变更通过 API Server 更新到 etcd
-
Node 组件包含:
kubelet:是运行在每个节点上的代理程序,负责让 Worker Node 与控制平面进行通信,主要是与 API Server 通信。它从 API Server 接收关于 Pod 的定义,并与容器运行时交互,以在 Pod 上运行相关容器,还承担着对运行容器的 Pod 进行资源监控、健康检查的职责。kube-proxy:是一个网络代理,运行在控制面和 Worker 节点上,职责是动态更新和维护节点上的所有网络规则,抽象了 Pod 的网络细节,并将连接请求转发到 Pod 中的容器,通过 Service API 对象实现用户定义的转发规则。
二、环境规划
1. 集群类型
-
Kubernetes 集群大致分为两类:一主多从和多主多从。
-
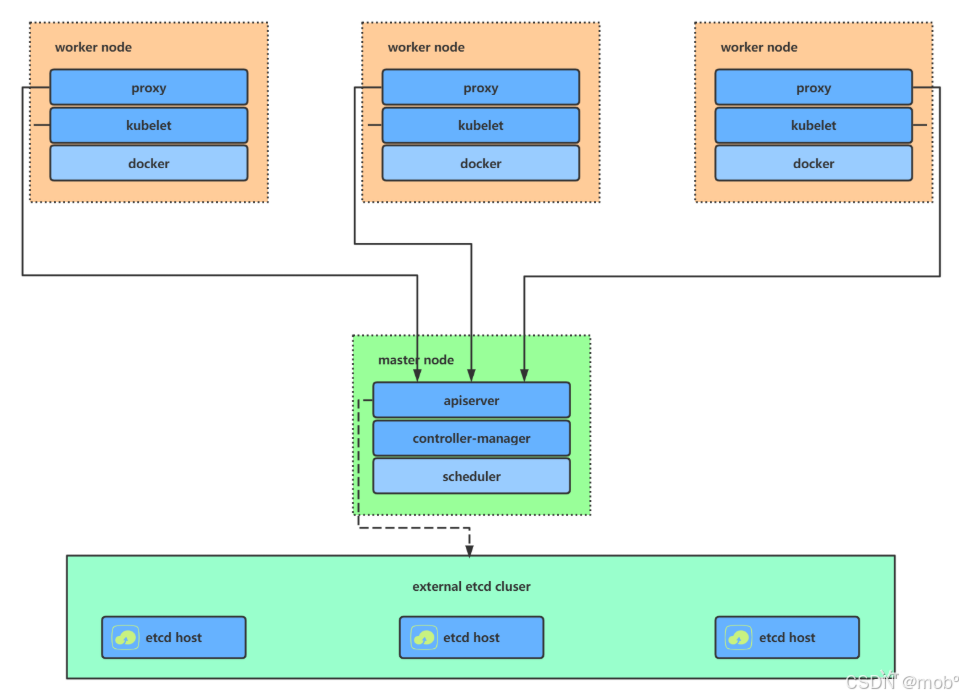
一主多从(单 master ):一个 Master 节点和多台 Node 节点,搭建简单,但是有单机故障风险,适合用于测试环境。
-
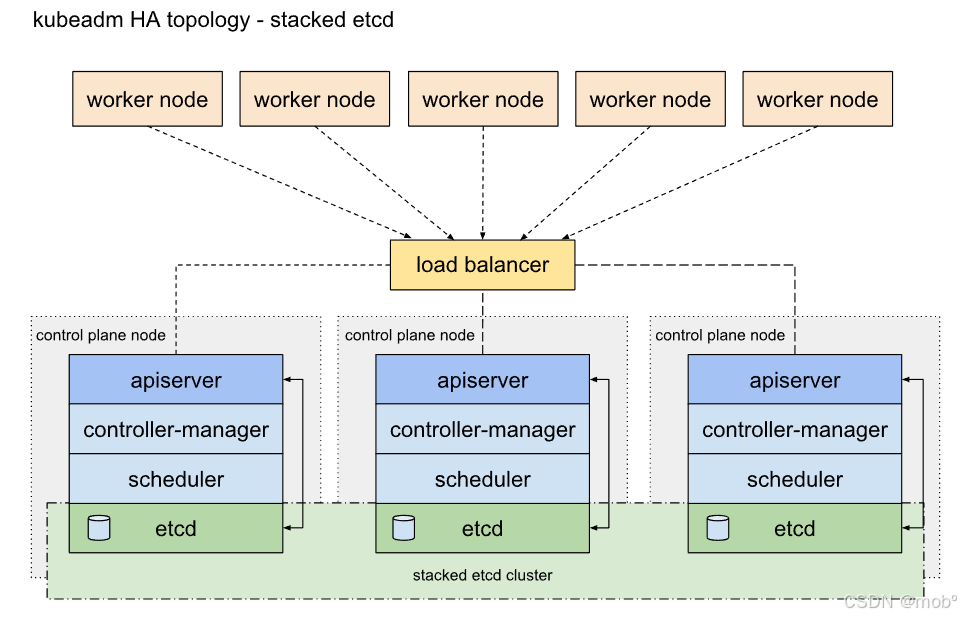
多主多从(高可用):多台 Master 节点和多台 Node 节点,搭建麻烦,安全性高,适合用于生产环境。
-
-
本次搭建是一主两从类型的集群。
2.环境准备
-
Kubernetes 有多种部署方式,目前主流的方式有 kubeadm 、minikube 、二进制包。本次我们采用的是 kubeadm 安装的方式。
- minikube:一个用于快速搭建单节点的 Kubernetes 工具。
- kubeadm:一个用于快速搭建Kubernetes 集群的工具(可以用于生产环境)。
- 二进制包:从官网上下载每个组件的二进制包,依次去安装(建议生产环境使用)。
-
三台云服务器:
需要选择相同地域的服务器,如上海。不同地域的云服务器内网不互通,而 k8s 集群中,master 连接 woker 默认采用的内网连接,比如连接 master 连接 woker 的 10250 端口,通过此端口获取节点状态,下发容器操作指令等。角色 IP地址 操作系统 配置 hostname Master 192.168.245.20 veLinux 2.0 CentOS Compatible 64 bit 8核CPU,16G内存,40G硬盘 k8s-master Node1 192.168.245.19 veLinux 2.0 CentOS Compatible 64 bit 8核CPU,16G内存,40G硬盘 k8s-node1 Node2 192.168.0.2 veLinux 2.0 CentOS Compatible 64 bit 4核CPU,8G内存,40G硬盘 k8s-node2 -
配置 k8s 集群的安全组。首先需要知道 k8s 集群中哪些端口提供。并且由谁提供。(其中一些端口视情况而定)
节点角色 端口号 协议 方向 作用说明 必要性 Master 节点 6443 TCP 入站(Worker 访问) Kubernetes API Server 端口,所有集群组件(kubelet、kube-proxy 等)通过此端口与 Master 通信 必须开放 2379-2380 TCP 入站(Master 内部 / 集群) etcd 数据库端口(2379 用于客户端通信,2380 用于集群节点间数据同步) 必须开放(单 Master 至少开放 2379) 10250 TCP 入站(Worker 访问) kubelet 端口(Master 节点自身的 kubelet,用于节点状态上报) 必须开放 10251 TCP 入站(内部) kube-scheduler 端口(调度器组件通信) 必须开放 10252 TCP 入站(内部) kube-controller-manager 端口(控制器管理器通信) 必须开放 10259 TCP 入站(内部) kube-scheduler 安全端口(HTTPS 通信) 必须开放 10260 TCP 入站(内部) kube-controller-manager 安全端口(HTTPS 通信) 必须开放 Worker 节点 10250 TCP 入站(Master 访问) kubelet 端口,Master 通过此端口管理节点和 Pod(如调度、健康检查) 必须开放 30000-32767 TCP 入站(外部访问) NodePort 类型 Service 暴露的端口范围,用于外部访问集群内服务(如应用端口) 按需开放(根据业务需求) 10255 TCP 入站(可选) kubelet 只读端口(已过时,建议关闭,或仅用于调试) 不推荐开放 10256 TCP 入站(可选) kube-proxy 健康检查端口 必须开放 所有节点通用 8472 UDP 网络插件(如 Flannel)的 VXLAN 通信端口(Calico 可能使用 4789) 必须开放(根据网络插件) -
版本说明:
k8s 选择的版本是 1.24.9。k8s 1.24 版本之后正式移除了内置的 dockershim 组件。dockershim 是过去 Kubernetes 用于直接对接 Docker 引擎的桥接模块,由于 Docker 本身不原生支持 Kubernetes 的 CRI(容器运行时接口),需要通过 dockershim 进行协议转换。- 移除后,Kubernetes 不再直接支持 Docker 作为容器运行时 ------ 但这并不意味着完全不能用 Docker,而是需要额外的兼容层。但需要通过 cri-dockerd 工具(Docker 官方提供的 CRI 兼容层),实现 Docker 与 Kubernetes CRI 的对接。
- 我这里也并有选择 cri-docker,而是采用了containerd。也是官方推荐的使用方式。
- 选择的 containerd 版本为:
containerd.io-1.6.15 - Kubernetes 1.24.9 对 containerd.io(containerd 的官方包名)有明确的版本要求,需要满足 1.4.12+ 及以上版本,但建议使用更稳定的 1.5.x 或 1.6.x 版本(不建议使用过高版本如 1.7.x,可能存在兼容性风险)。根据 Kubernetes 官方文档,1.24 版本兼容的 containerd 最低版本为 1.4.12,推荐使用:1.5.x 系列(如 1.5.16+,稳定性经过验证),1.6.x 系列(如 1.6.15+,支持更多新特性)
3. k8s 集群搭建
-
安装 k8s 之前需要将 swap 关闭。通过 free -m 可查看,需要 total、used、free 都是0。需要执行如下命令:
java# 将 SELinux 设置为 permissive 模式(相当于将其禁用) sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab -
配置国内源,这里选择的阿里云:
javacat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF -
安装 kubeadm kubectl kubelet (可以指定版本)
javayum -y install kubeadm-1.24.9 kubectl-1.24.9 kubelet-1.24.9 -
安装 containerd
javawget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo sudo yum install -y containerd.io-1.6.15 -
修改 containerd 配置。
-
初始化 containerd 配置
javasudo containerd config default > /etc/containerd/config.toml -
修改 sandbox_image 和 SystemCgroup 配置:sudo vim /etc/containerd/config.toml
javaregistry.aliyuncs.com/google_containers/pause:3.9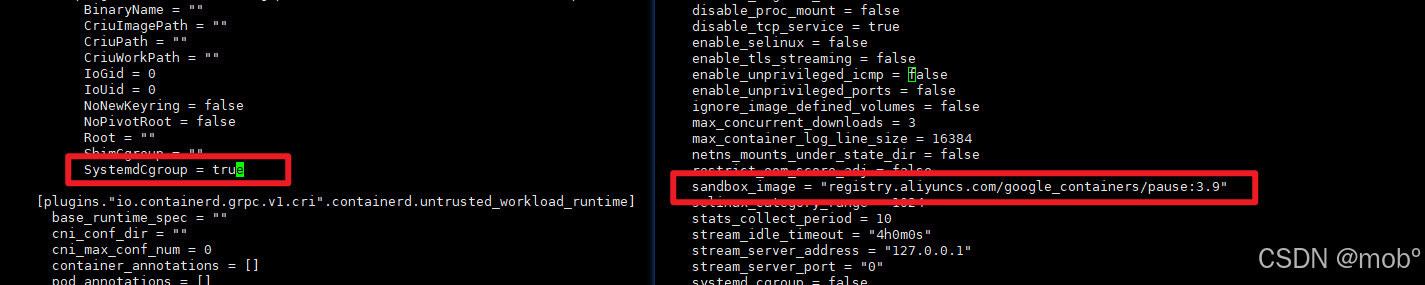
-
重启 containerd 使配置生效:
javasudo systemctl restart containerd
-
-
加载ipvs模块:
java# 加载ipvs模块 modprobe br_netfilter modprobe -- ip_vs modprobe -- ip_vs_sh modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- nf_conntrack_ipv4 # 验证ip_vs模块 lsmod |grep ip_vs ip_vs_wrr 12697 0 ip_vs_rr 12600 0 ip_vs_sh 12688 0 ip_vs 145458 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 139264 2 ip_vs,nf_conntrack_ipv4 libcrc32c 12644 3 xfs,ip_vs,nf_conntrack # 内核文件 cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward=1 vm.max_map_count=262144 EOF # 生效并验证内核优化 sysctl -p /etc/sysctl.d/k8s.conf -
修改 crictl下载镜像 默认端点:
javacat > /etc/crictl.yaml <<EOF runtime-endpoint: unix:///var/run/containerd/containerd.sock image-endpoint: unix:///var/run/containerd/containerd.sock timeout: 0 debug: false pull-image-on-create: false EOF- 验证 运行crictl images list命令,不再报错 即可。
-
初始化 master 节点:
javakubeadm init \ --apiserver-advertise-address=192.168.245.20 \ --control-plane-endpoint=k8s-master \ --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \ --kubernetes-version v1.24.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16 -
成功初始化:通过下图进行操作。woker 和 master 节点也可通过下图进行加入集群。
javamkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config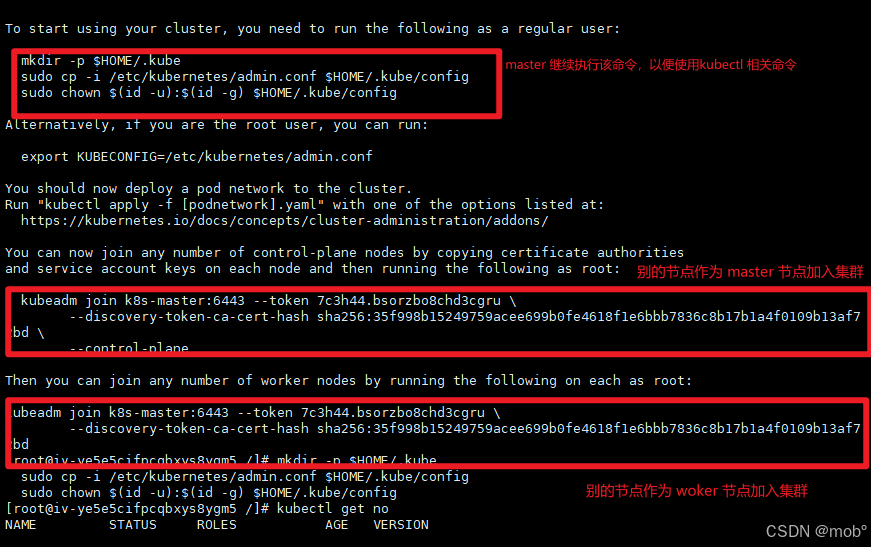
-
如果令牌过期了,可重新获取令牌:
javakubeadm token create --print-join-command -
在 /opt 下载calico的yaml配置文件
javacurl -O https://raw.githubusercontent.com/projectcalico/calico/v3.26.4/manifests/calico.yaml sed -i 's/docker.io/swr.cn-north-4.myhuaweicloud.com\/ddn-k8s\/docker.io/g' calico.yaml -
构建镜像:
javakubectl apply -f calico.yaml -
可通过命令查看pod启动情况:一个 master 和两个 woker
javakubectl get pod -A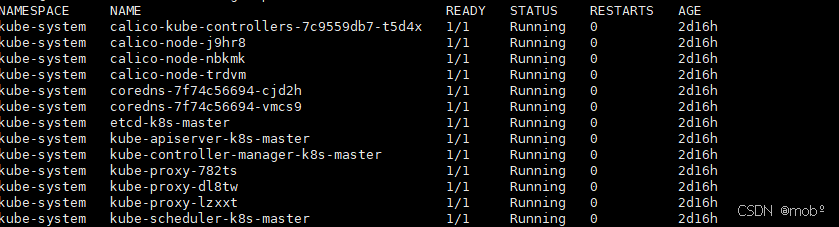
-
如果pod启动失败,可通过命令查看日志。
javakubectl describe po [pod name] -n [namespace]
三、k8s 命令
1. 操作 NameSpace
-
获取所有 NameSpace
javakubectl get ns -
获取所有 NameSpace 的 pod
javakubectl get pods -A -
获取默认 NameSpace【default】的 pod
javakubectl get pods -
获取指定 NameSpace 的 pods
javakubectl get pod -n [NameSpace] -
删除指定 NameSpace(默认 default 不可删除)
javakubectl delete ns [NameSpace] -
创建 NameSpace
javakubectl create ns [NameSpace]
2. 操作 Pod
-
查看 pod (默认 NameSpace 为 default 下的 pod)
javakubectl get pods -
查看 pod 详细信息
javakubectl get pod -owide -
查看指定 NameSpace 下的 pod
javakubectl get pod -n [NameSpace] -
查看 pod 的启动情况:
javakubectl describe pod [podName] -
通过配置文件的方式创建 pod
javakubectl apply -f [xx.yaml] -
删除通过配置文件创建的 pod
javakubectl delete -f [xx.yaml] -
直接删除 pod
javakubectl delete pod [podName] -n [namespace] -
强制删除 pod
javakubectl delete pod <pod-name> -n <namespace> --grace-period=0 --force -
查看 pod 的运行日志
javakubectl logs [podName] -
进入 pod
javakubectl exec -it [podName] -- /bin/bash
3. 操作 Deployment
-
使 Pod 拥有多副本、自愈、扩缩容等能力。
-
创建 Deployment 并指定容器
javakubectl create deployment [deployName] --image=[imageName] -
查看 deployment
javakubectl get [deployName] -
创建 deployment 并指定副本
javakubectl create deployment [deployName] --image=[imageName] --replicas=[count] -
删除 deployment
javakubectl delete deploy [deployName] -
对 deployment 进行扩缩容
javakubectl scale deploy/[deployName] --replicas=[count] -
也可修改配置文件,从而修改 deployment
javakubectl edit deploy [deployName] -
对 deployment 中某个镜像进行滚动更新
javakubectl set image deploy/[deployName] nginx=nginx:1.16.1 --record -
滚动更新过程,查看整个过程
javakubectl get pod -w -
查看 deployment 历史版本记录
javakubectl rollout history deployment/[deployName] -
查看某个历史详情
javakubectl rollout history deployment/[deployName] --revision=[version] -
回滚到上个版本
javakubectl rollout undo deployment/[deployName] -
回滚到指定版本
javakubectl rollout undo deployment/[deployName] --to-revision=[version]
4. 操作 Service
-
Pod 的服务发现与负载均衡。
-
默认暴露方式为 ClusterIP:只能在集群内访问。
-
NodePort:也可集群外访问,即任意一台集群内机器的IP 都可以在外用来访问服务。
-
设置 Service 服务端口,映射 Deployment 端口,默认 type=ClusterIP,也可指定 type=NodePort
javakubectl expose deploy [deployName] --port=[servicePort] --target-port=[deployPort] --type=ClusterIP -
该配置对应 yaml 写法为:
yamlapiVersion: v1 kind: Service metadata: labels: app: [deployName] name: [deployMent] spec: selector: app: my-dep ports: - port: 8000 protocal: TCP targetPort: 80 -
其中 label 为标签,可通过命令查看 pod 所属标签
javakubectl get pod --show-labels
-
获取 service
javakuebctl get svc
5. 操作 Ingress
-
Service 的统一网关入口
-
创建 ingress
javakubectl apply -f xxx.yaml -
获取 ingress
javakubectl get ingress / kubectl get ing -
修改 ingress
javakubectl edit ing [ingressName]
6. 操作 ConfigMap
-
查看所有 ConfigMap,默认 namespace 为 default
javakubectl get configmaps -n [namespace] // 简写 kubectl get cm -n [namespace] -
查看 ConfigMap 的详细信息(包括数据内容)
javakubectl describe configmap [configmap名称] # 示例 kubectl describe cm app-config -
以 YAML/JSON 格式查看完整定义
java# YAML 格式(常用) kubectl get configmap [configmap名称] -o yaml # JSON 格式 kubectl get configmap [configmap名称] -o json -
查看其他命名空间的 ConfigMap
javakubectl get cm -n [namespace] # 示例:查看 kube-system 命名空间的 ConfigMap kubectl get cm -n kube-system -
过滤查看特定标签的 ConfigMap
javakubectl get cm -l [标签键=标签值] # 示例:查看标签为 app=nginx 的 ConfigMap kubectl get cm -l app=nginx
7. 操作 Secret
-
查看命名空间下的所有 Secret(快速列表)
javakubectl get secrets -n [nameSpace] -
查看指定 Secret 的详细信息(包含编码后的内容)
javakubectl describe secret mysql-secret -n [nameSpace] -
查看 Secret 中编码后的具体值(需解码),Secret 的值存储为 base64 编码,若需查看明文(谨慎操作!),可使用以下命令解码:查看所有键的明文
java# 以 YAML 格式输出并解码所有值 kubectl get secret mysql-secret -n [nameSpace] -o yaml | grep -v '^ apiVersion\|^ kind\|^ metadata' | awk '{print $0}' | base64 -d -
查看指定键的明文(推荐,更安全):
java# 查看 root-password 的明文 kubectl get secret mysql-secret -n [nameSpace] -o jsonpath='{.data.root-password}' | base64 -d && echo
四、安装 harbor
-
使用Harbor 私有镜像仓库。Harbor 是基于 Docker 容器运行的,它的安装和运行依赖于 Docker 环境。同时,还需要安装 Docker Compose,用于管理 Harbor 的多个容器组件。 为什么需要私有镜像仓库?
- 提高镜像下载速度。
- 节省网络带宽。
- 确保镜像安全性。
- 便于管理公司内部的容器镜像。
-
从 Docker 20.10.3 版本开始,Docker 已经内置了 Compose 功能(通过 docker compose 命令),无需单独安装。你可以直接验证:
docker compose version。安装 docker -
下载 harbor:
javawget https://github.com/goharbor/harbor/releases/download/v2.11.1/harbor-offline-installer-v2.11.1.tgz -
解压安装包:
javatar xvf harbor-offline-installer-v2.8.3.tgz -
进入 harbor 后复制配置文件:
javacd harbor cp harbor.yml.tmpl harbor.yml -
配置 host 映射 vim /etc/hosts
java14.103.138.45 mortal.harbor.com -
编辑 harbor.yml:
javahostname: mortal.harbor.com # 修改 https 相关配置(使用 https) https: port: 443 certificate: /data/cert/mortal.harbor.com.crt private_key: /data/cert/mortal.harbor.com.key # 修改管理员密码(建议修改) harbor_admin_password: Harbor131413 # 修改数据存储路径(可选) data_volume: /data/harbor # 修改数据库密码(建议修改) database: password: root123 -
启用 HTTPS,需要生成 SSL 证书:
java# 创建证书目录 mkdir -p /data/cert cd /data/cert # 生成私钥 openssl genrsa -out ca.key 4096 # 生成证书 openssl req -x509 -new -nodes -sha512 -days 3650 \ -subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=mortal.harbor.com" \ -key ca.key \ -out ca.crt # 生成服务器证书 openssl genrsa -out mortal.harbor.com.key 4096 openssl req -sha512 -new \ -subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=mortal.harbor.com" \ -key mortal.harbor.com.key \ -out mortal.harbor.com.csr # 生成 x509 v3 扩展文件 cat > v3.ext <<-EOF authorityKeyIdentifier=keyid,issuer basicConstraints=CA:FALSE keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment extendedKeyUsage = serverAuth subjectAltName = @alt_names [alt_names] DNS.1=mortal.harbor.com DNS.2=harbor DNS.3=hostname EOF # 使用 v3.ext 文件为域名生成证书 openssl x509 -req -sha512 -days 3650 \ -extfile v3.ext \ -CA ca.crt -CAkey ca.key -CAcreateserial \ -in mortal.harbor.com.csr \ -out mortal.harbor.com.crt -
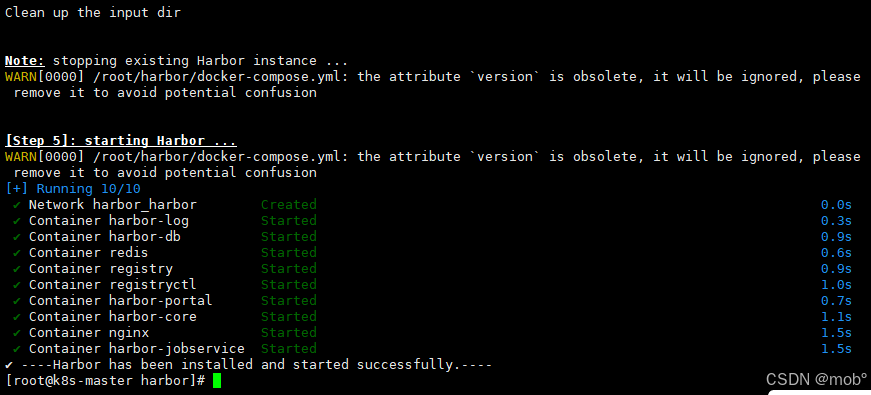
安装 Harbor:
java./install.sh- harbor(v2.10) 对部分组件做了调整,主要变化如下:
- 必须设置有效的主机名:不能使用 localhost 或 127.0.0.1,因为 Harbor 需要被外部客户端访问(如其他服务器、开发机等)
- 正确配置方式:在 harbor.yml 中设置为服务器的实际 IP 地址(如 192.168.1.100)或可解析的域名(如 harbor.example.com)。
- --with-trivy:仍支持此参数,若需要启用漏洞扫描功能,安装时需显式指定(因为 Trivy 不再默认安装)。`./install.sh --with-trivy # 启用漏洞扫描
--with-notary和--with-chartmuseum:这两个参数已被移除,因为对应的组件(Notary 镜像签名、ChartMuseum Helm 仓库)已被弃用。镜像签名功能:Harbor 新版本推荐使用内置的 Cosign 替代 Notary,Helm 仓库功能:Harbor 已原生支持 Helm Chart 管理,无需依赖 ChartMuseum。
- harbor(v2.10) 对部分组件做了调整,主要变化如下:
-
安装成功:
-
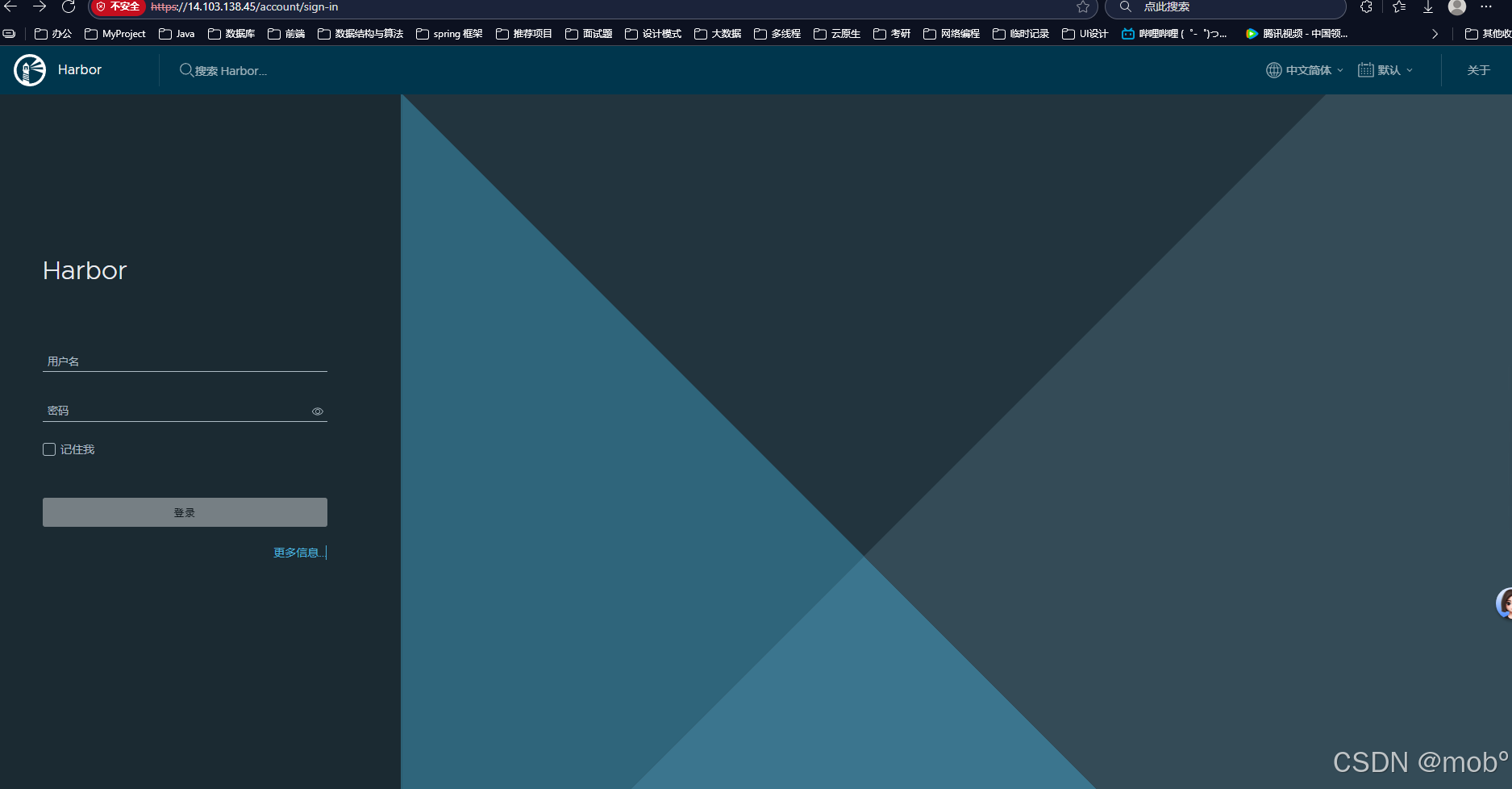
访问:https://ip/account/sign-in:
-
这时候还需要再docker 上配置 harbor 的 SSL 证书,不然 docker push 推送镜像会报错如下错误:
javadocker pull nginx:latest # 标记镜像 docker tag nginx:latest mortal.harbor.com/library/nginx:v1 -
尝试推送镜像至 harbor,报如下错误:
javadocker push mortal.harbor.com/library/nginx:v1
-
配置 SSL 证书:
java# 创建 Harbor 域名对应的证书目录(域名需与 Harbor 配置一致) sudo mkdir -p /etc/docker/certs.d/mortal.harbor.com # 复制 ca.crt cp ca.crt /etc/docker/certs.d/mortal.harbor.com/ -
重启 docker
java# 重启 Docker systemctl restart docker # 重启所有容器 docker restart $(docker ps -aq) -
登录 harbor:
javadocker login mortal.harbor.com -
再次推送:成功
javadocker push mortal.harbor.com/library/nginx:v1
-
如果修改了 harbor.yml 配置文件,可通过如下命令生效:
java# 执行 prepare 脚本,根据 harbor.yml 生成新配置 sudo ./prepare # 停止当前运行的 Harbor 服务 sudo docker compose down # 启动 Harbor 服务(加载新配置) sudo docker compose up -d -
好需要配置 k8s 能够从 Harbor 行拉取镜像。主要配置 用户密码 和 ca.crt。
-
配置 Harbor 的用户密码用于 k8s 拉取镜像。
-
创建 secret:记住 secret 名称为:harbor-creds 。 在编写 yaml 文件拉取镜像时需要用到
javakubectl create secret docker-registry harbor-creds \ --docker-server=mortal.harbor.com \ --docker-username=admin \ --docker-password=Harbor131413 \ --namespace=mortal-system -
使用:
javaimagePullSecrets: - name: harbor-creds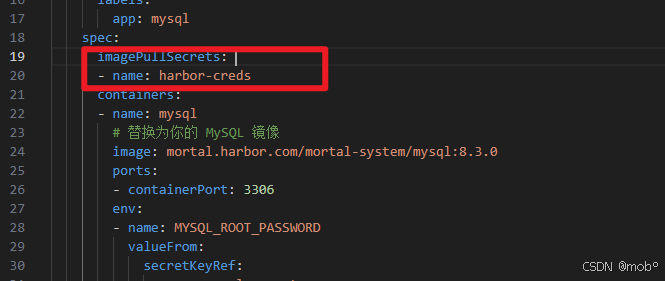
-
也可查看写创建的 secret:

-
-
我们的 image 地址写的是 Harbor 的地址,且用的域名。在 k8s 创建 pod 时,可能会分配给 worker 节点进行创建并启动,所以需要再 k8s 集群所有节点上都需要设置 Harbor 域名的映射(/etc/hosts)。
-
配置 ca.crt 证书,我们的k8s 版本是 1.24+,使用的是 containerd,所以需要所有k8s节点都改它的配置信息。
-
在上述安装 Harbor 的时候,我们创建了 ca.crt 证书,我们需要将它给引用到 containerd 的配置中。
-
查看 ca.crt 位置:
javafind / -name "ca.crt" | grep -i harbor -
复制到我们新建的文件夹中,方便后续引用:
javasudo mkdir -p /etc/containerd/certs.d/mortal.harbor.com/ cp /etc/docker/certs.d/mortal.harbor.com/ca.crt /etc/containerd/certs.d/mortal.harbor.com/ -
containerd 配置中引用:
javavi /etc/containerd/config.tomljava[plugins."io.containerd.grpc.v1.cri".registry.configs."mortal.harbor.com"] [plugins."io.containerd.grpc.v1.cri".registry.configs."mortal.harbor.com".tls] ca_file = "/etc/containerd/certs.d/mortal.harbor.com//ca.crt" -
效果如下:
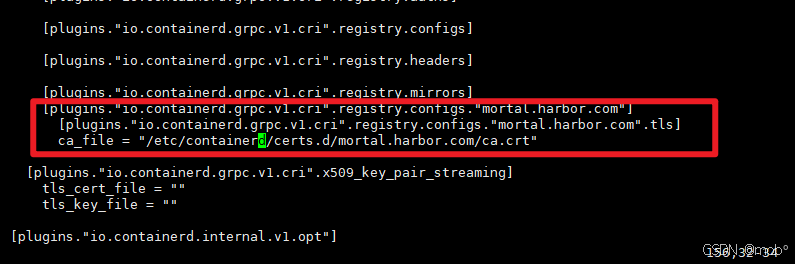
-
重启 containerd:
javasystemctl restart containerd -
上述 所有 k8s 节点都需要配置。
-
五、配置 StorageClass
- k8s 集群默认是没有 PV 的,需要我们自己编写 PV 配置文件,可以采用本地存储或者DFS。我这里采用 DFS 和 Minio 的结合使用。 DFS 提供 数据库、日志存储。 Minio 提供 文件存储。两种存储区别如下:
| 对比维度 | MinIO | NFS(Network File System) |
|---|---|---|
| 存储类型 | 「对象存储」(Object Storage) | 「文件存储」(File Storage) |
| 核心协议 | 兼容 S3 API(HTTP/HTTPS) | NFS 协议(基于 TCP/UDP) |
| 数据组织方式 | 以「对象」为单位(Key-Value 结构,包含数据 + 元信息) | 以「文件 / 目录」为单位(树形目录结构,如 /data/logs/2024.log) |
| 访问方式 | 通过 API 调用(如 putObject/getObject) | 像本地磁盘一样挂载(mount -t nfs),支持 POSIX 语义(如文件锁、权限控制) |
| 适用数据 | 非结构化数据(图片、日志、备份、视频等) | 结构化 / 半结构化数据(配置文件、应用日志、共享代码等需目录管理的数据) |
| K8s 集成方式 | 需通过 CSI 驱动(如 ch.ctrox.csi.s3-driver)模拟文件系统挂载,或直接通过 API 访问 | 需通过 nfs-client-provisioner 提供动态 PVC,支持直接挂载为文件系统 |
1. 集成 Minio
-
使用 Minio 作为存储分为如下步骤:
-
下载集成 Minio 所需的驱动并部署。
-
编写 PVC,测试 Minio 是否可用。
-
在 Kubernetes 中,CSI 提供了一种标准的方式,用于与第三方存储供应商(如 NFS、AWS EFS、Ceph、GlusterFS、Minio 等)对接,实现存储卷的创建、挂载、卸载等操作。所以我们需要先安装 CSI。其中的镜像需要改成国内的,不然可能无法下载。或者安装这里的 CSI 应该也可以,未亲测
-
provisioner.yaml:
javaregistry.cn-hangzhou.aliyuncs.com/google_containers/csi-provisioner:v3.5.0 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ctrox/csi-s3:v1.2.0-rc.2 -
attacher.yaml:
javaimage: registry.cn-hangzhou.aliyuncs.com/google_containers/csi-attacher:v4.3.0 -
csi-s3.yaml:
javaregistry.cn-hangzhou.aliyuncs.com/google_containers/csi-node-driver-registrar:v2.8.0 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ctrox/csi-s3:v1.2.0-rc.2
-
-
安装之后查看启动情况:kubectl get pod -A
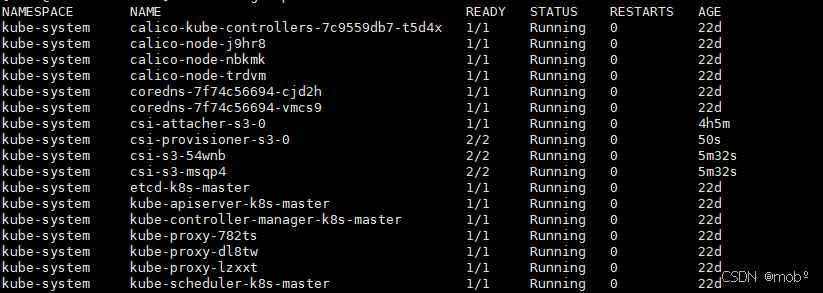
-
创建一个 Secret,存储 MinIO 集群的访问信息(用于 CSI 驱动连接 MinIO)。minio-secret.yaml,并进行部署:kubectl apply -f minio-secret.yaml
java# minio-secret.yaml apiVersion: v1 kind: Secret metadata: name: minio-secret # Namespace depends on the configuration in the storageclass.yaml namespace: mortal-system stringData: # minio 的用户名密码 accessKeyID: root secretAccessKey: root13141314 # For AWS set it to "https://s3.<region>.amazonaws.com" endpoint: http://192.168.245.20:9000 # If not on S3, set it to "" region: "" -
创建 PV:minio-storageclass.yaml,并进行部署:kubectl apply -f minio-storageclass.yaml。
javakind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: minio-sc provisioner: ch.ctrox.csi.s3-driver parameters: mounter: geesefs # you can set mount options here, for example limit memory cache size (recommended) options: "--memory-limit 1000 --dir-mode 0777 --file-mode 0666" # to use an existing bucket, specify it here: #bucket: some-existing-bucket csi.storage.k8s.io/provisioner-secret-name: minio-secret csi.storage.k8s.io/provisioner-secret-namespace: mortal-system csi.storage.k8s.io/controller-publish-secret-name: minio-secret csi.storage.k8s.io/controller-publish-secret-namespace: mortal-system csi.storage.k8s.io/node-stage-secret-name: minio-secret csi.storage.k8s.io/node-stage-secret-namespace: mortal-system csi.storage.k8s.io/node-publish-secret-name: minio-secret csi.storage.k8s.io/node-publish-secret-namespace: mortal-system -
查看部署的 PV:

-
后续编写 pvc 时,volumeClaimTemplates 中的 storageClassName 需要写上述的 minio-sc 。比如编写一个 test.yaml
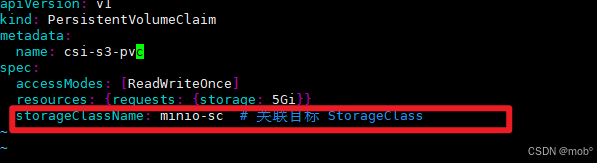
-
部署后:kubectl apply -f test.yaml,在查看 pvc 是否是 bound 状态:kubect get pvc

-
在申请完 PVC 之后就会创建对应的 PV 进行绑定,删除 PVC 之后,与之绑定的 PV 也会删除。
2. 集成 NFS
-
k8s 集成 NFS 步骤如下:
- 安装 NFS。
- 安装 nfs-client-provisioner。
- 测试。
-
k8s 集群中的所有节点(mater 和 worker)安装 NFS。
javasudo yum install nfs-utils -y -
master 节点 新建共享目录:
javasudo mkdir /nfs_share sudo chmod 777 /nfs_share -
配置 NFS 权限:vim /etc/exports,添加如下内容:
java/nfs_share *(rw,sync,no_root_squash) -
使配置生效:
javasudo exportfs -a -
master 启动 nfs 服务:
javasudo systemctl start nfs-server sudo systemctl enable nfs-server -
所有 Worker 节点启动 rpcbind
javasudo systemctl start rpcbind sudo systemctl enable rpcbind -
所有 Worker 节点挂载 Master
javasudo mount 192.168.245.20:/nfs_share /mnt -
Master 安装 nfs-client-provisioner。先进行下载:
javawget https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/refs/tags/v4.0.2/deploy/deployment.yaml wget https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/refs/tags/v4.0.2/deploy/class.yaml wget https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/refs/tags/v4.0.2/deploy/rbac.yaml -
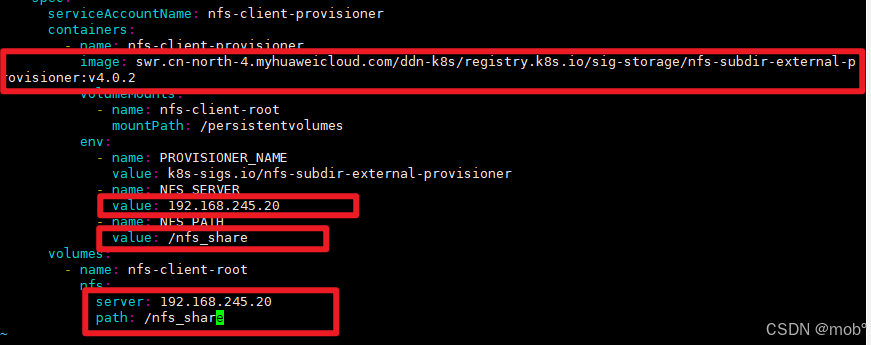
修改 deployment.yaml
-
image:替换为国内镜像。
javaswr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2 -
ip 替换为 安装了 NFS 服务的IP地址。我这里是直接在 Master 节点安装的,所以直接用的 Master 节点的内网IP。
-
path 替换为需要共享的目录。
-
-
安装:
javakubectl apply -f rbac.yaml kubectl apply -f deployment.yaml kubectl apply -f class.yaml -
新建 PVC 进行测试:test.yaml。其中 storageClassName 需要和 上面的 class.yaml 的 name 一致。
javaapiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-nfs-pvc namespace: mortal-system spec: accessModes: - ReadWriteMany # NFS 支持多节点读写 storageClassName: managed-nfs-storage resources: requests: storage: 1Gi -
部署并测试查看 PVC 是否为 bound 状态。
javakubectl apply -f test.yaml
-
如果 NFS 布置在别的服务器上,需要配置安全组,开放端口:111 和 2049