
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
python
print("1024,程序员节,冲冲冲!")自然语言是用来表达人脑思维的复杂系统。在这个系统中,词是意义的基本单元。顾名思义,词向量 是用于表示单词意义的向量,并且还可以被认为是单词的特征向量或表示。将单词映射到实向量的技术称为词嵌入。近年来,词嵌入逐渐成为自然语言处理的基础知识。
一、为何独热向量是一个糟糕的选择
在循环神经网络的从零开始实现中,我们使用独热向量来表示词(字符就是单词)。假设词典中不同词的数量(词典大小)为 N N N,每个词对应一个从 0 0 0到 N − 1 N−1 N−1的不同整数(索引)。为了得到索引为 i i i的任意词的独热向量表示,我们创建了一个全为0的长度为 N N N的向量,并将位置 i i i的元素设置为1。这样,每个词都被表示为一个长度为 N N N的向量,可以直接由神经网络使用。
虽然独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的"余弦相似度"。对于向量 x , y ∈ R d \mathbf{x}, \mathbf{y} \in \mathbb{R}^d x,y∈Rd,它们的余弦相似度是它们之间角度的余弦:
x ⊤ y ∥ x ∥ ∥ y ∥ ∈ − 1 , 1 (1) \frac{\mathbf{x}^\top \mathbf{y}}{\|\mathbf{x}\| \|\mathbf{y}\|} \in -1, 1 \tag{1} ∥x∥∥y∥x⊤y∈−1,1(1)
由于任意两个不同词的独热向量之间的余弦相似度为0,所以独热向量不能编码词之间的相似性。
二、自监督的word2vec
word2vec工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。word2vec工具包含两个模型,即跳元模型 (skip-gram)和连续词袋(CBOW)。对于在语义上有意义的表示,它们的训练依赖于条件概率,条件概率可以被看作使用语料库中一些词来预测另一些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。
下面,我们将介绍这两种模式及其训练方法。
三、跳元模型(Skip-Gram)
跳元模型假设一个词可以用来在文本序列中生成其周围的单词。以文本序列"the""man""loves""his""son"为例。假设中心词 选择"loves",并将上下文窗口设置为2,如图1所示,给定中心词"loves",跳元模型考虑生成上下文词 "the""man""him""son"的条件概率:
P ( "the" , "man" , "his" , "son" ∣ "loves" ) (2) P(\textrm{"the"},\textrm{"man"},\textrm{"his"},\textrm{"son"}\mid\textrm{"loves"}) \tag{2} P("the","man","his","son"∣"loves")(2)
假设上下文词是在给定中心词的情况下独立生成的(即条件独立性)。在这种情况下,上述条件概率可以重写为:
P ( "the" ∣ "loves" ) ⋅ P ( "man" ∣ "loves" ) ⋅ P ( "his" ∣ "loves" ) ⋅ P ( "son" ∣ "loves" ) (3) P(\textrm{"the"}\mid\textrm{"loves"})\cdot P(\textrm{"man"}\mid\textrm{"loves"})\cdot P(\textrm{"his"}\mid\textrm{"loves"})\cdot P(\textrm{"son"}\mid\textrm{"loves"}) \tag{3} P("the"∣"loves")⋅P("man"∣"loves")⋅P("his"∣"loves")⋅P("son"∣"loves")(3)
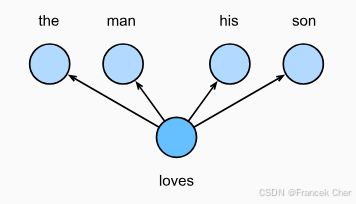
图1 跳元模型考虑了在给定中心词的情况下生成周围上下文词的条件概率
在跳元模型中,每个词都有两个 d d d维向量表示,用于计算条件概率。更具体地说,对于词典中索引为 i i i的任何词,分别用 v i ∈ R d \mathbf{v}_i\in\mathbb{R}^d vi∈Rd和 u i ∈ R d \mathbf{u}_i\in\mathbb{R}^d ui∈Rd表示其用作中心词 和上下文词 时的两个向量。给定中心词 w c w_c wc(词典中的索引 c c c),生成任何上下文词 w o w_o wo(词典中的索引 o o o)的条件概率可以通过对向量点积的softmax操作来建模:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) (4) P(w_o \mid w_c) = \frac{\text{exp}(\mathbf{u}_o^\top \mathbf{v}c)}{ \sum{i \in \mathcal{V}} \text{exp}(\mathbf{u}i^\top \mathbf{v}c)} \tag{4} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)(4) 其中词表索引集 V = { 0 , 1 , ... , ∣ V ∣ − 1 } \mathcal{V} = \{0, 1, \ldots, |\mathcal{V}|-1\} V={0,1,...,∣V∣−1}。给定长度为 T T T的文本序列,其中时间步 t t t处的词表示为 w ( t ) w^{(t)} w(t)。假设上下文词是在给定任何中心词的情况下独立生成的。对于上下文窗口 m m m,跳元模型的似然函数是在给定任何中心词的情况下生成所有上下文词的概率:
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) (5) \prod{t=1}^{T} \prod{-m \leq j \leq m,\ j \neq 0} P(w^{(t+j)} \mid w^{(t)}) \tag{5} t=1∏T−m≤j≤m, j=0∏P(w(t+j)∣w(t))(5) 其中可以省略小于 1 1 1或大于 T T T的任何时间步。
训练
跳元模型参数是词表中每个词的中心词向量和上下文词向量。在训练中,我们通过最大化似然函数(即极大似然估计)来学习模型参数。这相当于最小化以下损失函数:
− ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w ( t + j ) ∣ w ( t ) ) (6) - \sum_{t=1}^{T} \sum_{-m \leq j \leq m,\ j \neq 0} \text{log}\, P(w^{(t+j)} \mid w^{(t)}) \tag{6} −t=1∑T−m≤j≤m, j=0∑logP(w(t+j)∣w(t))(6)
当使用随机梯度下降来最小化损失时,在每次迭代中可以随机抽样一个较短的子序列来计算该子序列的(随机)梯度,以更新模型参数。为了计算该(随机)梯度,我们需要获得对数条件概率关于中心词向量和上下文词向量的梯度。通常,根据式(4),涉及中心词 w c w_c wc和上下文词 w o w_o wo的对数条件概率为:
log P ( w o ∣ w c ) = u o ⊤ v c − log ( ∑ i ∈ V exp ( u i ⊤ v c ) ) (7) \log P(w_o \mid w_c) =\mathbf{u}_o^\top \mathbf{v}c - \log\left(\sum{i \in \mathcal{V}} \text{exp}(\mathbf{u}_i^\top \mathbf{v}_c)\right) \tag{7} logP(wo∣wc)=uo⊤vc−log(i∈V∑exp(ui⊤vc))(7) 通过微分,我们可以获得其相对于中心词向量 v c \mathbf{v}_c vc的梯度为
∂ log P ( w o ∣ w c ) ∂ v c = u o − ∑ j ∈ V exp ( u j ⊤ v c ) u j ∑ i ∈ V exp ( u i ⊤ v c ) = u o − ∑ j ∈ V ( exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) ) u j = u o − ∑ j ∈ V P ( w j ∣ w c ) u j . (8) \begin{aligned}\frac{\partial \text{log}\, P(w_o \mid w_c)}{\partial \mathbf{v}_c}&= \mathbf{u}o - \frac{\sum{j \in \mathcal{V}} \exp(\mathbf{u}_j^\top \mathbf{v}_c)\mathbf{u}j}{\sum{i \in \mathcal{V}} \exp(\mathbf{u}_i^\top \mathbf{v}_c)}\\&= \mathbf{u}o - \sum{j \in \mathcal{V}} \left(\frac{\text{exp}(\mathbf{u}_j^\top \mathbf{v}c)}{ \sum{i \in \mathcal{V}} \text{exp}(\mathbf{u}_i^\top \mathbf{v}_c)}\right) \mathbf{u}_j\\&= \mathbf{u}o - \sum{j \in \mathcal{V}} P(w_j \mid w_c) \mathbf{u}_j.\end{aligned} \tag{8} ∂vc∂logP(wo∣wc)=uo−∑i∈Vexp(ui⊤vc)∑j∈Vexp(uj⊤vc)uj=uo−j∈V∑(∑i∈Vexp(ui⊤vc)exp(uj⊤vc))uj=uo−j∈V∑P(wj∣wc)uj.(8)
注意,式(8)中的计算需要词典中以 w c w_c wc为中心词的所有词的条件概率。其他词向量的梯度可以以相同的方式获得。
对词典中索引为 i i i的词进行训练后,得到 v i \mathbf{v}_i vi(作为中心词)和 u i \mathbf{u}_i ui(作为上下文词)两个词向量。在自然语言处理应用中,跳元模型的中心词向量通常用作词表示。
四、连续词袋(CBOW)模型
连续词袋 (CBOW)模型类似于跳元模型。与跳元模型的主要区别在于,连续词袋模型假设中心词是基于其在文本序列中的周围上下文词生成的。例如,在文本序列"the""man""loves""his""son"中,在"loves"为中心词且上下文窗口为2的情况下,连续词袋模型考虑基于上下文词"the""man""him""son"(如 :numref:fig_cbow所示)生成中心词"loves"的条件概率,即:
P ( "loves" ∣ "the" , "man" , "his" , "son" ) (9) P(\textrm{"loves"}\mid\textrm{"the"},\textrm{"man"},\textrm{"his"},\textrm{"son"}) \tag{9} P("loves"∣"the","man","his","son")(9)
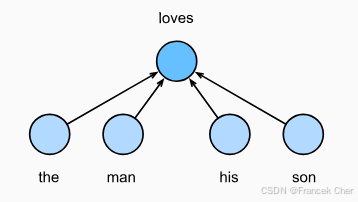
图2 连续词袋模型考虑了给定周围上下文词生成中心词条件概率
由于连续词袋模型中存在多个上下文词,因此在计算条件概率时对这些上下文词向量进行平均。具体地说,对于字典中索引 i i i的任意词,分别用 v i ∈ R d \mathbf{v}i\in\mathbb{R}^d vi∈Rd和 u i ∈ R d \mathbf{u}i\in\mathbb{R}^d ui∈Rd表示用作上下文 词和中心 词的两个向量(符号与跳元模型中相反)。给定上下文词 w o 1 , ... , w o 2 m w{o_1}, \ldots, w{o_{2m}} wo1,...,wo2m(在词表中索引是 o 1 , ... , o 2 m o_1, \ldots, o_{2m} o1,...,o2m)生成任意中心词 w c w_c wc(在词表中索引是 c c c)的条件概率可以由以下公式建模:
P ( w c ∣ w o 1 , ... , w o 2 m ) = exp ( 1 2 m u c ⊤ ( v o 1 + ... , + v o 2 m ) ) ∑ i ∈ V exp ( 1 2 m u i ⊤ ( v o 1 + ... , + v o 2 m ) ) (10) P(w_c \mid w_{o_1}, \ldots, w_{o_{2m}}) = \frac{\text{exp}\left(\frac{1}{2m}\mathbf{u}c^\top (\mathbf{v}{o_1} + \ldots, + \mathbf{v}{o{2m}}) \right)}{ \sum_{i \in \mathcal{V}} \text{exp}\left(\frac{1}{2m}\mathbf{u}i^\top (\mathbf{v}{o_1} + \ldots, + \mathbf{v}{o{2m}}) \right)} \tag{10} P(wc∣wo1,...,wo2m)=∑i∈Vexp(2m1ui⊤(vo1+...,+vo2m))exp(2m1uc⊤(vo1+...,+vo2m))(10) 为了简洁起见,我们设为 W o = { w o 1 , ... , w o 2 m } \mathcal{W}o= \{w{o_1}, \ldots, w_{o_{2m}}\} Wo={wo1,...,wo2m}和 v ˉ o = ( v o 1 + ... , + v o 2 m ) / ( 2 m ) \bar{\mathbf{v}}o = \left(\mathbf{v}{o_1} + \ldots, + \mathbf{v}{o{2m}} \right)/(2m) vˉo=(vo1+...,+vo2m)/(2m)。那么式(10)可以简化为:
P ( w c ∣ W o ) = exp ( u c ⊤ v ˉ o ) ∑ i ∈ V exp ( u i ⊤ v ˉ o ) (11) P(w_c \mid \mathcal{W}_o) = \frac{\exp\left(\mathbf{u}_c^\top \bar{\mathbf{v}}o\right)}{\sum{i \in \mathcal{V}} \exp\left(\mathbf{u}_i^\top \bar{\mathbf{v}}_o\right)} \tag{11} P(wc∣Wo)=∑i∈Vexp(ui⊤vˉo)exp(uc⊤vˉo)(11)
给定长度为 T T T的文本序列,其中时间步 t t t处的词表示为 w ( t ) w^{(t)} w(t)。对于上下文窗口 m m m,连续词袋模型的似然函数是在给定其上下文词的情况下生成所有中心词的概率:
∏ t = 1 T P ( w ( t ) ∣ w ( t − m ) , ... , w ( t − 1 ) , w ( t + 1 ) , ... , w ( t + m ) ) (12) \prod_{t=1}^{T} P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}) \tag{12} t=1∏TP(w(t)∣w(t−m),...,w(t−1),w(t+1),...,w(t+m))(12)
训练
训练连续词袋模型与训练跳元模型几乎是一样的。连续词袋模型的最大似然估计等价于最小化以下损失函数:
− ∑ t = 1 T log P ( w ( t ) ∣ w ( t − m ) , ... , w ( t − 1 ) , w ( t + 1 ) , ... , w ( t + m ) ) (13) -\sum_{t=1}^T \text{log}\, P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}) \tag{13} −t=1∑TlogP(w(t)∣w(t−m),...,w(t−1),w(t+1),...,w(t+m))(13) 请注意,
log P ( w c ∣ W o ) = u c ⊤ v ˉ o − log ( ∑ i ∈ V exp ( u i ⊤ v ˉ o ) ) (14) \log\,P(w_c \mid \mathcal{W}_o) = \mathbf{u}_c^\top \bar{\mathbf{v}}o - \log\,\left(\sum{i \in \mathcal{V}} \exp\left(\mathbf{u}_i^\top \bar{\mathbf{v}}o\right)\right) \tag{14} logP(wc∣Wo)=uc⊤vˉo−log(i∈V∑exp(ui⊤vˉo))(14) 通过微分,我们可以获得其关于任意上下文词向量 v o i \mathbf{v}{o_i} voi( i = 1 , ... , 2 m i = 1, \ldots, 2m i=1,...,2m)的梯度,如下:
∂ log P ( w c ∣ W o ) ∂ v o i = 1 2 m ( u c − ∑ j ∈ V exp ( u j ⊤ v ˉ o ) u j ∑ i ∈ V exp ( u i ⊤ v ˉ o ) ) = 1 2 m ( u c − ∑ j ∈ V P ( w j ∣ W o ) u j ) (15) \frac{\partial \log\, P(w_c \mid \mathcal{W}o)}{\partial \mathbf{v}{o_i}} = \frac{1}{2m} \left(\mathbf{u}c - \sum{j \in \mathcal{V}} \frac{\exp(\mathbf{u}_j^\top \bar{\mathbf{v}}_o)\mathbf{u}j}{ \sum{i \in \mathcal{V}} \text{exp}(\mathbf{u}_i^\top \bar{\mathbf{v}}_o)} \right) = \frac{1}{2m}\left(\mathbf{u}c - \sum{j \in \mathcal{V}} P(w_j \mid \mathcal{W}_o) \mathbf{u}_j \right) \tag{15} ∂voi∂logP(wc∣Wo)=2m1 uc−j∈V∑∑i∈Vexp(ui⊤vˉo)exp(uj⊤vˉo)uj =2m1 uc−j∈V∑P(wj∣Wo)uj (15)
其他词向量的梯度可以以相同的方式获得。与跳元模型不同,连续词袋模型通常使用上下文词向量作为词表示。
小结
- 词向量是用于表示单词意义的向量,也可以看作词的特征向量。将词映射到实向量的技术称为词嵌入。
- word2vec工具包含跳元模型和连续词袋模型。
- 跳元模型假设一个单词可用于在文本序列中,生成其周围的单词;而连续词袋模型假设基于上下文词来生成中心单词。