大型语言模型(LLMs)在多元时间序列分类(MTSC)中展现出巨大潜力。为有效将大型语言模型适配于多元时间序列分类任务,生成全面且富有信息量的数据表示至关重要。目前,大多数利用大型语言模型的方法将数值型时间序列编码至模型的潜在空间,旨在与大型语言模型的语义空间对齐,以实现更有效的学习。
尽管这些方法颇具成效,但仍存在三个被忽视的局限性。为弥补这些不足,来自中科大与科大讯飞的研究者提出 TableTime,将多元时间序列分类重构为表格理解任务。在来自 UEA 档案库的10个公开基准数据集上进行的广泛实验,验证了 TableTime 作为多元时间序列分类新范式的巨大潜力。

【论文标题】TableTime: Reformulating Time Series Classification as Training-Free Table Understanding with Large Language Models
【论文地址】https://arxiv.org/abs/2411.15737
【论文源码】https://github.com/realwangjiahao/TableTime
论文背景
MTSC 是时间序列分析中的核心任务,广泛应用于医疗监测、工业检测、人体动作识别等领域。传统方法如动态时间规整(DTW)和基于距离的分类器在处理长度变化的序列时表现良好,但难以捕捉隐藏特征;机器学习方法(如 SVM、随机森林)依赖人工特征且假设数据平稳,限制了其在动态数据上的效果;深度学习方法(如CNN、Transformer)虽减少了特征工程的需求,但严重依赖大量标注数据,且计算成本高。
近年来,LLM 展现出强大的序列建模和推理能力,为时间序列分析提供了新思路。然而,现有 LLM 方法在应用于时间序列时仍存在三大瓶颈:难以融入时间信息与通道特定信息,而这两者均为多元时间序列的关键组成部分;将学习到的表示空间与大型语言模型的语义空间对齐被证明是一项重大挑战;这些方法往往需要针对特定任务进行重新训练,尽管大型语言模型具备泛化能力,但仍无法实现免训练推理。
为此,研究者提出 TableTime------一种基于表格理解、无需训练的 MTSC 框架。将数值型时间序列转换为表格格式,同时保留时间一致性和通道特定信息。为使表格形式的时间序列与 LLM 的语义空间对齐,研究者引入表格编码技术,将表格形式的时间序列转换为文本表示。为实现无需训练的分类,研究者采用表格理解方法,重新构建 MTSC 任务,使大型语言模型无需针对特定任务重新训练即可进行分类。为充分发挥大型语言模型的推理潜力,研究者开发了一种包含邻域辅助增强和多路径推理的提示方法,旨在充分挖掘大型语言模型的推理能力。如图1所示,TableTime 为 MTSC 提供了一种新范式。
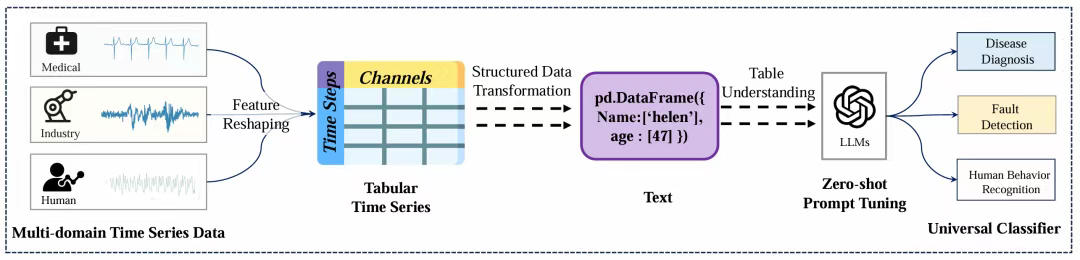
图1:TableTime的核心思想:在以数据为中心的范式下,将时间序列转换为表格表示形式以实现通用分类
论文方法
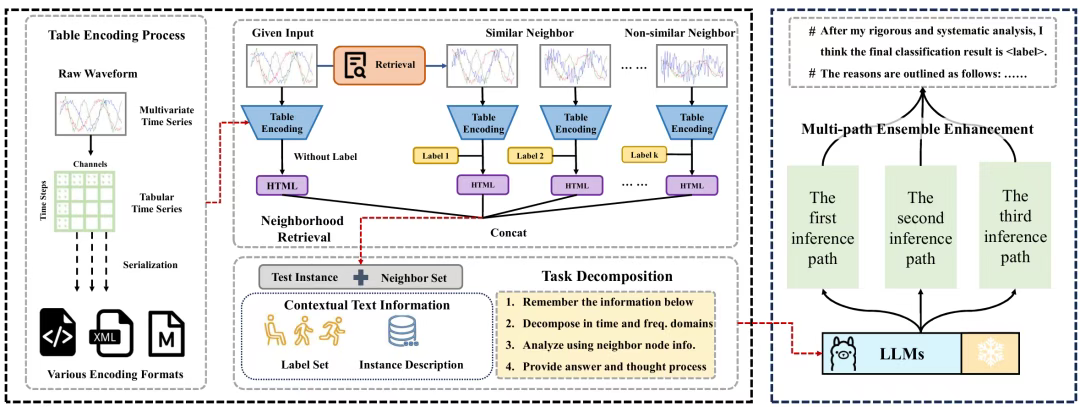
图2:TableTime示意图
TableTime 的整体流程包含四个关键步骤:近邻检索:从训练集中识别与测试样本相关的近邻样本表格编码:将原始数值时间序列转换为表格格式提示工程:设计包含上下文文本、近邻知识和任务分解的综合性提示零样本推理:基于提示信息进行分类,无需任务特定训练
01上下文信息建模
(1)表格重构策略
TableTime 提出表格编码技术,将多元时间序列转换为表格形式:行对应时间步:保留时间维度的一致性;列对应通道:维持各传感器/特征的独立性;表格序列化:通过 DFLoader、MarkDown 等方法将表格转换为文本。
这种表示方法的优势在于:同时保留时间依赖关系和通道特异性信息;支持元数据或领域知识的集成;增强模型的可解释性和兼容性。
(2)上下文文本信息
为解决 LLM 缺乏任务特定知识的问题,TableTime 设计了结构化的领域上下文模板:任务定义:明确说明在特定领域中的分类任务数据集描述:解释数据集特征包括数据长度等属性类别定义:详细说明每个标签的含义通道信息:描述每个通道在数据集中的物理意义
02近邻辅助推理机制
(1)近邻检索策略
仅使用正样本:应用相似度度量算法,从训练数据集中为每个测试样本找出𝑘个最近邻。
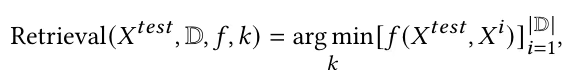
进行对比增强:将负样本纳入模型的推理过程。首先使用K均值聚类等算法对训练数据集进行聚类。然后,从不包含测试样本的簇中选择负样本,以确保这些样本具有足够的差异性。通过引入这些负样本,TableTime 利用对比学习帮助大型语言模型(LLMs)更好地区分不同类别并优化其决策边界。
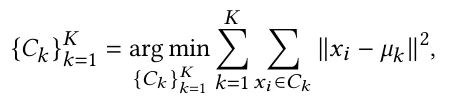
上下文文本信息与邻域信息在增强大型语言模型推理能力方面起到互补作用。上下文邻域通过从训练数据中识别样本,提供特定于任务且数据驱动的上下文,通过模式和特征对齐直接指导分类决策。相比之下,上下文文本描述则利用大型语言模型广泛且预训练的语义理解能力,建立任务规则和逻辑框架,为模型提供预热。通过结合基于邻域的上下文信息的精确性与领域上下文的泛化能力,TableTime 实现了稳健且准确的分类。
03多路径集成增强
多路径推理利用多种不同的推理路径生成多样化的输出集合,从而捕捉到更广泛范围的特征表示。通过聚合这些结果,该方法减轻了任何单一推理路径中潜在的偏差,提高了预测的鲁棒性和准确性。这使得多路径推理特别适合本文任务,因为它能有效处理多元时间序列数据的复杂性。多路径集成增强策略可形式化表述如下:
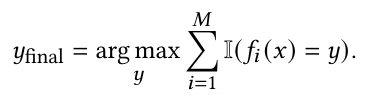
每个分类器都是一个LLM。我们可以使用不同的参数进行集成,或者集成来自不同LLM的结果。通过使用不同模型生成多个结果,并通过投票机制进行聚合,确保最终分类反映了模型最为自信且一致的推理。
04零样本推理提示设计
(1)任务分解机制
传统的提示词往往缺乏大型语言模型(LLMs)有效处理复杂任务所需的结构化指导。这种明确指令的缺失迫使LLMs独立解释任务,这可能导致错误、不一致或无关的推理。没有逐步的框架,模型可能会忽略问题的关键方面或关注不太相关的细节。
为了应对这些挑战,研究者引入了任务分解方法,该方法将复杂的时间序列分类任务分解为一系列更小、更易管理的步骤,使模型能够更有效地进行推理。这种逐步的过程确保LLMs逐渐收敛到更准确的分类结果,提高了决策质量和可解释性。
(2)结构化提示模板
在 TableTime 中,结构化的提示词对于实现零样本推理至关重要。上下文文本信息为 LLM 提供了专业知识,使其能够预热并更好地理解任务。邻居信息通过将测试样本与训练集中相似的标记示例相关联,提供了关键的上下文。任务分解则指导 LLM 进行逐步推理。

图3:TableTime的提示词模板
05总结与讨论
(1)与基于 LLM 的模型的关系
LLM 在序列建模任务中展现出了巨大的优势。然而,LLM 中庞大的参数量使得训练变得非常困难。因此,如何高效地利用 LLM 成为了一个亟待解决的问题。
现有的方法要么是从零开始在 LLM 的潜在空间中学习时间序列的嵌入,要么是从外部模型映射以与 LLM 对齐。尽管这些方法有效,但它们无法以无损的方式表示原始时间序列。相比之下,TableTime 能够完全编码原始时间序列,并实现零样本分类。
(2)与传统模型的关系
基于距离的方法是传统但有效且高度可解释的方法。然而,基于距离的方法对噪声和异常值敏感,且难以识别局部模式。它们还缺乏有效表示序列特征的能力,无法充分挖掘序列中的潜在结构信息。
在 TableTime 中,研究者保留了基于距离的方法的优势,并利用 LLM 来实现对原始时间序列的理解。与集成学习方法相比,TableTime 通过整合同一 LLM 在不同参数设置下生成的结果来获得最终结果。研究者没有采用多个模型,而是引入了多路径集成策略,该策略可以增强模型的鲁棒性,并使最终结果更加准确。
实验结果
01分类结果分析
TableTime 在多个数据集上表现出卓越性能,尤其在训练样本较少的任务中优势明显。在 AF 和 SWJ 等小型数据集上,TableTime 大幅领先其他基线方法,验证了其强大的零样本推理能力。consistently outperforms Time-LLM 和 Time-FFM 证明表格理解范式能更有效释放 LLM 的推理潜力。
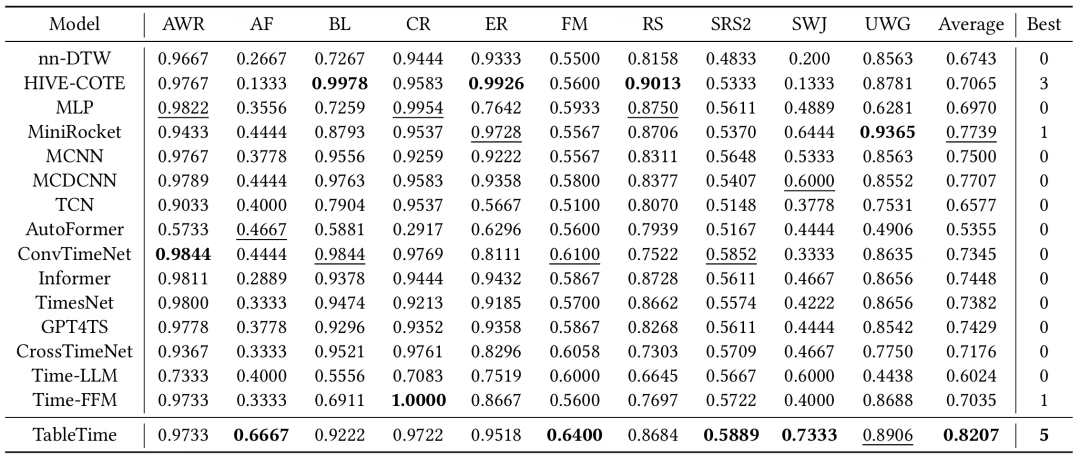
表1:TableTime与基线模型在十个数据集上的多元时间序列分类性能
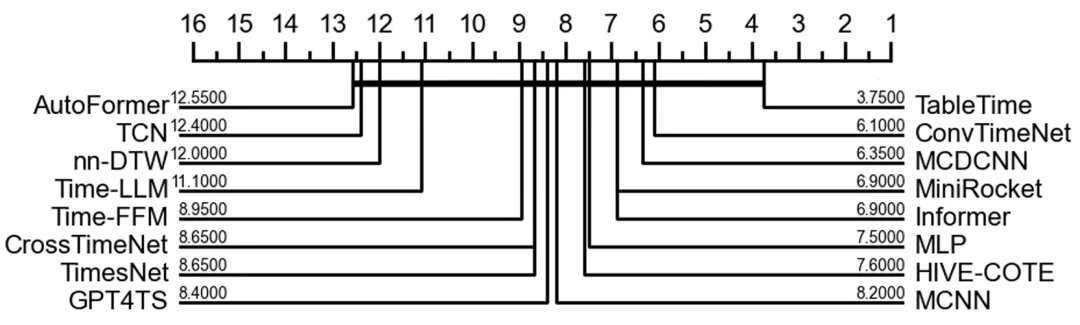
图4:TableTime与基线模型平均排名的临界差异图。
02上下文信息建模分析
消融实验证明时空信息对模型性能至关重要:时间信息比通道信息更为关键,印证了时间序列建模中时序特征的核心地位,同时去除时间和通道信息会导致性能显著下降。
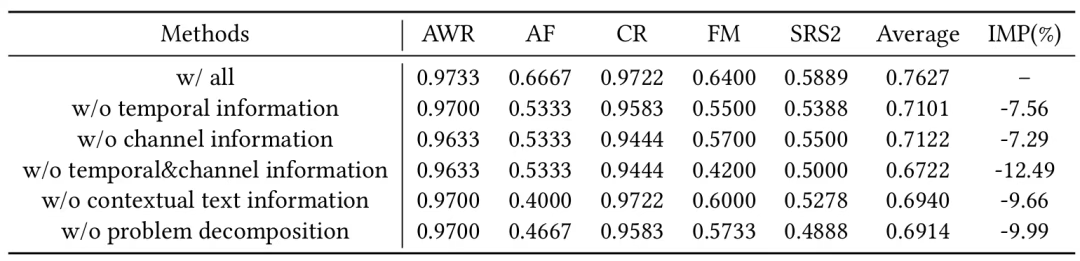
表2:五个关键模块的消融实验结果
03深度性能评估
近邻一致性分析揭示 TableTime 的鲁棒性:即使检索到不一致的近邻,分类准确率仍保持在50%以上;FM 数据集达60.0%,SRS2 数据集达58.3%。证明模型能通过 LLM 推理实现可靠预测,而非简单模仿近邻标签。
总结
本研究着重强调了显式建模原始时间序列数据中时间信息与通道特定信息的至关重要性。总结来看,TableTime 引入了以下策略:(1)利用表格形式统一时间序列格式,推动从以模型为中心的方法向以数据为中心的方法转变;(2)以文本格式表示时间序列,便于与大型语言模型的语义空间无缝对齐;(3)设计一个知识-任务双驱动的推理框架------TableTime,整合上下文信息与专家级推理指导,以增强大型语言模型的推理能力,并实现免训练分类。
尽管该模型具有诸多优势,但研究者认为仍存在若干局限性,需进一步深入研究。首先,探索在所提框架内高效编码表格形式时间序列的方法至关重要。如前所述,某些编码技术可能会阻碍大型语言模型的可解释性。其次,最近邻检索过程存在优化空间。除了直接在原始时间序列数据上执行检索外,另一种方法可先将原始数据嵌入,再进行最近邻检索。这种方法能够更全面地探索特征,从而获得更深入的洞察。