深入解析 Python 循环导入问题,解释其根源、对生产环境的影响,以及 Instagram 等企业如何通过静态分析、依赖反转和自动化工具解决循环依赖。
一个 import 语句如何让整个应用宕机 ------ 为什么企业团队花费巨资来解决循环导入
在开发环境里,你的 Django 应用一切顺利。测试全部通过,部署流水线也跑通了。可偏偏就在凌晨三点,生产环境突然崩溃,报出了一个莫名其妙的错误:
javascript
ImportError: cannot import name 'Order' from partially initialized module 'order'
这就是臭名昭著的 循环导入(circular import) 问题。
它和语法错误或类型错误不一样。语法错误会直接报错,类型错误大多数情况也能提前发现,但循环导入往往在开发阶段没问题,等到生产环境一跑才爆炸,导致线上回滚、业务中断,工程团队因此要花掉大量时间排查。
为什么 Python 的导入机制会"坑你"
要搞清楚循环导入,先得明白 Python 的 import 究竟是怎么工作的。
很多人觉得它就是黑盒子,写个 import xxx 就完了。但实际上,Python 的导入顺序是有明确规则的,而正是这些规则埋下了循环导入的雷。
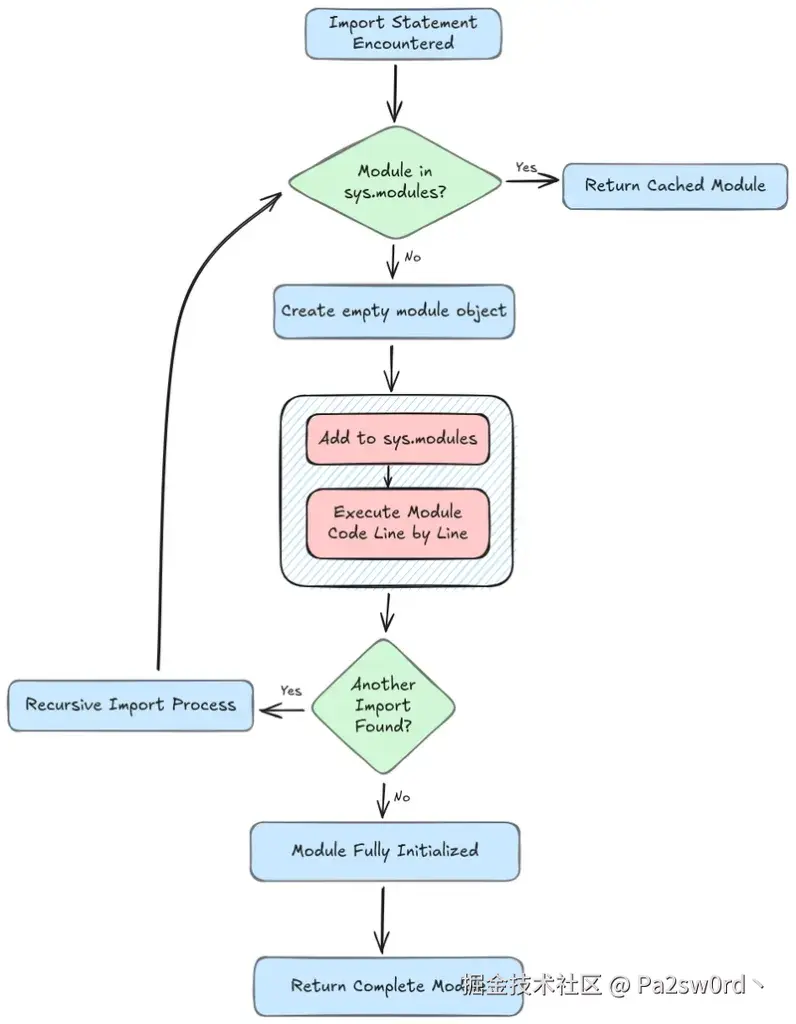
关键细节在这里:Python 在执行模块代码之前,就会先把这个模块注册进 sys.modules。
这么做的本意是防止无限递归导入。但副作用就是会出现"部分初始化模块(partially initialized module)"。当另一个模块在这个时机试图访问它时,就会直接触发循环导入错误。
真实灾难:Instagram 的百万行单体代码危机
Instagram 工程团队曾经遇到过业界最复杂的循环导入问题之一。
他们的后端应用是一个庞大的 Django 单体(monolith),代码量达到了数百万行。规模越大,循环依赖带来的风险就越大,最终在生产环境演变成严重的架构问题。
Benjamin Woodruff(Instagram 的资深工程师)在一次技术分享中详细讲述了他们的应对之路。场景极其夸张:
- 几百名工程师同时开发
- 每天提交上百次代码
- 持续部署频率高达 每 7 分钟一次
- 单日生产环境更新接近 100 次
- 从提交到上线的延迟不到一小时
在这种超高速迭代下,循环导入成了"隐形炸弹"。他们发现,这些问题并不仅仅是导入失败,而是暴露出 系统架构层面上的耦合。
突破口:静态分析
最终,Instagram 找到了转机。他们基于 LibCST(后来开源)构建了一套静态分析系统,可以在短短 26 秒内分析整个数百万行的代码库。
这让团队得以 提前检测循环导入,而不是等到生产环境崩溃时才去救火。
更重要的收获是:Instagram 发现循环导入并不是单个模块的问题,而是团队在长期协作中 自然生成的架构模式 。
要解决问题,光靠修修补补不够,必须把"依赖关系分析"提升到架构设计的层面,和数据库建模、接口设计一样对待。
循环导入的剖析:逐步还原出错过程
下面我们通过一个例子,看看 Python 遇到循环导入时究竟发生了什么。代码看起来很简单:
ruby
from order import Order
class User:
def __init__(self, name):
self.name = name
def create_order(self, product):
return Order(self, product)
ruby
from user import User
class Order:
def __init__(self, user, product):
self.user = user
self.product = product
def get_user_name(self):
return self.user.name现在,当你在项目里执行:
arduino
import user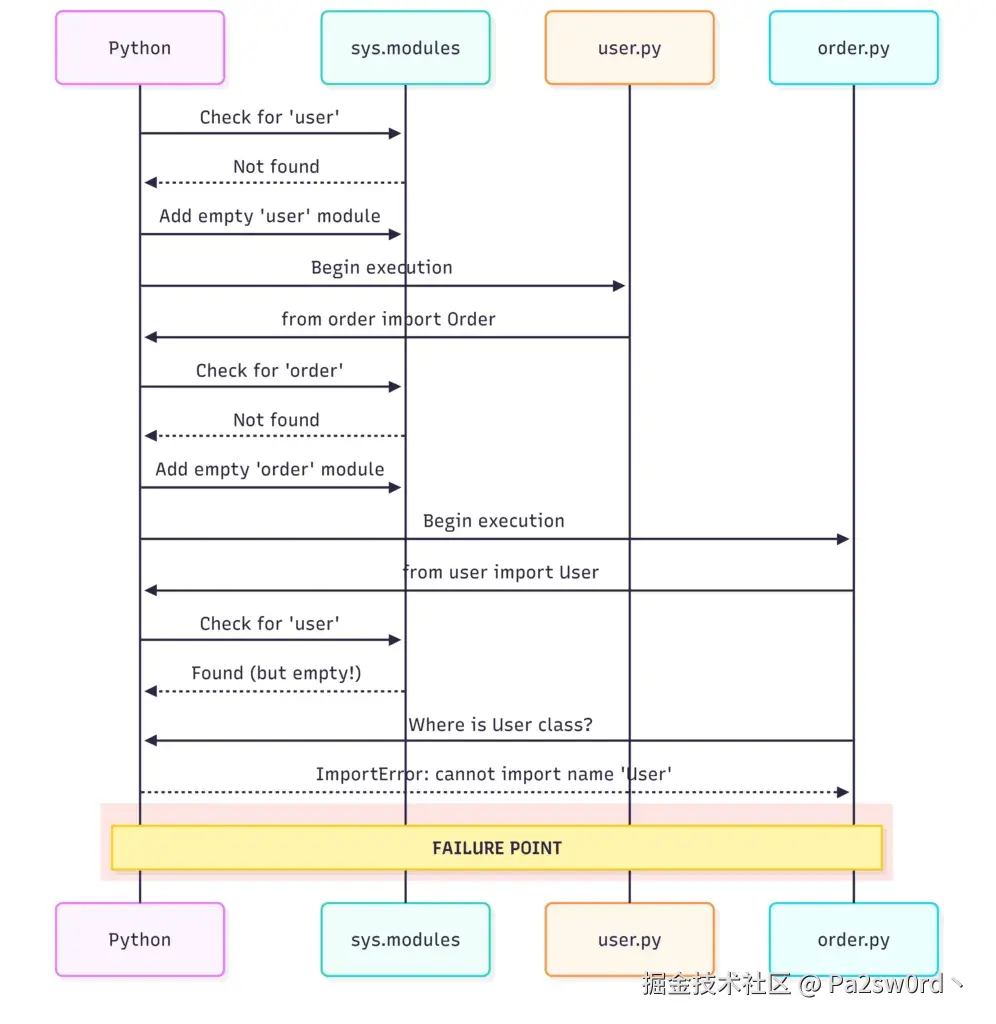
出问题的关键步骤是这样的:
- Python 开始加载
user.py,执行到from order import Order。 - 于是转去加载
order.py。 order.py一上来又写了from user import User,Python 发现user已经在sys.modules里,于是直接去用这个模块。- 但这时候
user.py并没有执行完,User类还没创建出来。 - 结果就是:
order.py想导入User,却只能拿到一个 部分初始化的模块(partially initialized module) ,报错收场。
换句话说,失败发生在 order.py 试图导入 User 的瞬间。模块虽然已经存在于 sys.modules,但还没初始化完成,User 根本还不存在。
👉 到这里,我们完整解释了循环导入在最简单场景下的触发原因。
企业级难题:复杂依赖网络
在真实的应用里,循环导入往往不是两个模块之间的"小打小闹"。
企业级代码库里常常会发展出极其复杂的依赖网络,循环依赖可能跨越多个子系统。
想象这样一个八个模块形成的依赖环:
css
A → B → C → D → E → F → G → H → A在本地看,每个模块的导入似乎都是合理的:
- A 需要调用 B 的功能
- B 又依赖于 C
- ...
- 最后 H 又反过来导入了 A
单独看没问题,但组合在一起,就形成了一个完整的循环。
这种情况在大型代码库里非常常见:
- 功能越堆越多
- 业务逻辑越来越复杂
- 每个团队只顾着在本地范围内解决问题
- 最终整个系统形成了一张"无法维持"的全局依赖网
结果就是:模块之间高度耦合,系统架构变得脆弱,一旦某个环节出问题,就可能引发连锁反应。
检测策略:从人工审查到自动化分析
在小项目里,循环导入有时候还能靠人工代码审查发现,但在大型代码库中,这几乎不可能。要想可靠地发现问题,就必须依赖自动化工具和系统化方法。
图论方法
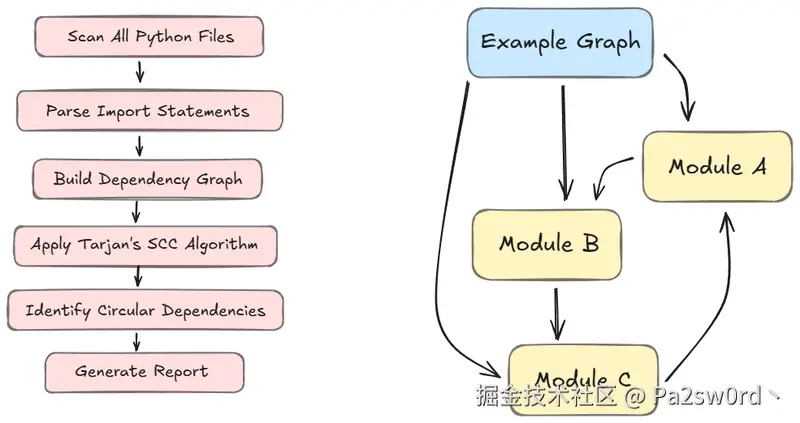
最稳妥的检测方式,是把代码库看作一张有向图:
- 节点 代表模块
- 边 代表导入关系
循环导入就对应于图中的 强连通分量(Strongly Connected Components, SCCs) 。
只要能在依赖图里找到 SCC,就能定位到循环依赖。
运行时检测
有些循环导入不会在静态代码层面暴露出来,因为它们是通过动态导入或条件导入产生的。
这种情况下,就需要在运行时进行检测。
例如,我们可以写一个自定义的导入跟踪器:
python
class CircularImportDetector:
def __init__(self):
self.import_stack = []
self.original_import = __builtins__.__import__
__builtins__.__import__ = self.tracked_import
def tracked_import(self, name, *args, **kwargs):
if name in self.import_stack:
cycle_start = self.import_stack.index(name)
cycle = self.import_stack[cycle_start:] + [name]
raise CircularImportError(f"Cycle: {' → '.join(cycle)}")
self.import_stack.append(name)
try:
return self.original_import(name, *args, **kwargs)
finally:
self.import_stack.pop()这个类会替换 Python 内置的 __import__,在每次导入时记录调用栈。一旦发现某个模块被重复导入,就能直接报错并给出完整的循环链路。
这种方法特别适合定位那些"偶尔才出现"的循环依赖问题,比如只在某些配置、条件分支下才触发的情况。
架构解决方案:打破循环
发现循环导入只是第一步,更关键的是如何解决它。
常见的几种方法可以帮助我们从架构层面打破循环依赖。
1. 依赖倒置原则(Dependency Inversion Principle)
最有效的办法之一,就是通过抽象来消除直接依赖。
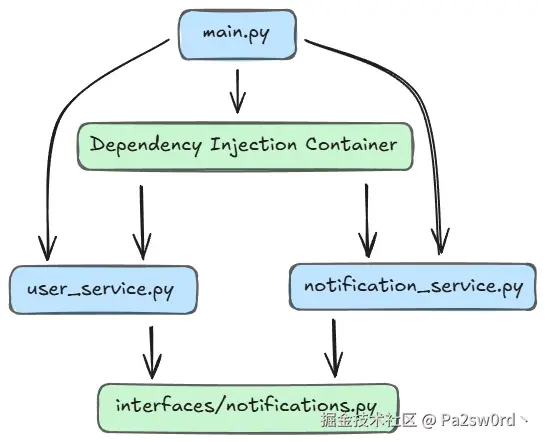
重构前(存在循环依赖):
python
# user_service.py
from notification_service import send_welcome_email # 直接依赖
class UserService:
def create_user(self, data):
user = User.create(data)
send_welcome_email(user) # 潜在循环依赖
return user
# notification_service.py
from user_service import UserService # 导致循环!def send_welcome_email(user):
user_service = UserService()
profile = user_service.get_profile(user.id)这里,user_service 和 notification_service 相互依赖,形成循环。
重构后(解耦):
python
# interfaces/notifications.py
from abc import ABC, abstractmethod
class NotificationSender(ABC):
@abstractmethod
def send_welcome_email(self, user):
pass
ruby
# user_service.py
from interfaces.notifications import NotificationSender
class UserService:
def __init__(self, notification_sender: NotificationSender):
self.notification_sender = notification_sender
def create_user(self, data):
user = User.create(data)
self.notification_sender.send_welcome_email(user)
return user通过依赖倒置,我们引入了一个抽象接口,模块之间不再直接依赖,循环自然消除。
2. 事件驱动架构(Event-Driven Architecture)
另一种思路是彻底避免直接导入,用事件总线来解耦模块。
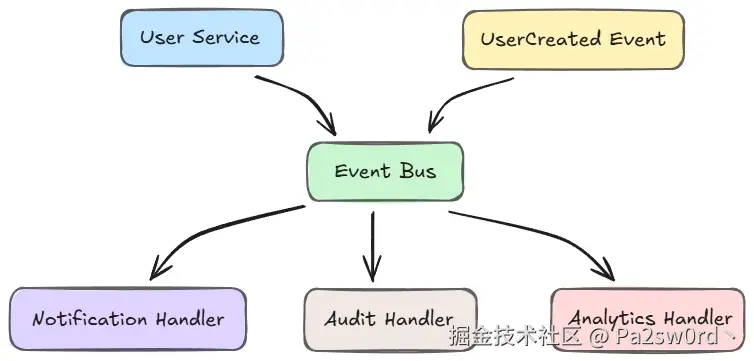
当用户创建时,UserService 只负责发出一个"用户创建"事件,由消息系统或事件处理器来决定是否发送欢迎邮件。
这种模式能彻底消除模块之间的硬依赖,特别适合大型分布式系统。
3. 延迟导入(Import Timing Strategies)
有时候,循环依赖无法完全避免。这时可以通过"延迟导入"来缓解问题。
python
def process_user_data(user_data):
# 只有在需要时才导入
from .heavy_processor import ComplexProcessor
processor = ComplexProcessor()
return processor.process(user_data)这样,模块不会在加载时立即触发导入,而是等到函数调用时才进行。
4. TYPE_CHECKING 模式
Instagram 团队还推广了一种 TYPE_CHECKING 模式,用于处理类型注解导致的循环依赖:
python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from circular_dependency import CircularType
def process_item(item: 'CircularType') -> bool:
# 运行时不需要真正导入
return item.is_valid()在运行时,Python 不会导入 CircularType,从而避免循环。但静态类型检查工具依然能识别类型。
Instagram 甚至写了 lint 规则,自动合并和规范化这些 TYPE_CHECKING 块。
生产落地:CI/CD 集成 (Production Implementation: CI/CD Integration)
在企业级项目中,循环导入问题的解决不仅仅在于编写正确的代码,更关键的是将其集成到 持续集成(CI)和持续交付(CD) 流程中,以实现自动化检测和防护。
1. 静态分析集成
在 CI 流程中,可以集成静态分析工具来检测循环依赖:
- pycycle:用于检测 Python 模块之间的循环导入
- pylint:结合插件可识别循环依赖
- 自定义脚本:通过项目依赖图检测强连通分量(SCC)
这样,一旦新提交引入循环依赖,CI 流程就会报错并阻止合并。
yaml
# GitHub Actions 示例
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install dependencies
run: pip install pycycle
- name: Check circular imports
run: pycycle path/to/your/project性能监控
跟踪生产中与导入相关的指标:

高级检测:超越简单的循环
传递依赖分析
简单的循环导入检测会遗漏复杂的传递关系。考虑以下依赖链:
继续阅读全文: Python 循环导入详解:为什么会导致生产环境崩溃及企业级解决方案****