
在 Python 开发中,处理表格数据是非常常见的任务,而 Pandas 是最常用的数据处理和分析库。开发者经常需要将 Pandas DataFrame 导出到 Excel,以便进行报告、团队协作或进一步的数据分析。虽然 Pandas 提供了 to_excel 方法进行基本导出,但如果需要创建格式丰富和含图表的专业 Excel 报表,则需要借助专业Excel库。
本教程介绍如何在Python中使用Spire.XLS for Python库将单个或多个 Pandas DataFrame 写入到 Excel,并实现灵活的格式化与可视化设置。
为什么使用 Spire.XLS 导出 Pandas DataFrame 到 Excel
虽然 Pandas 提供了基本的 Excel 导出功能,但它主要用于数据输出而非 Excel 文件处理,对格式设置、样式应用和图表生成等高级功能的支持有限。相比之下,Spire.XLS 是一个专为 Excel 文件创建与操作而设计的专业库,能够提供更灵活、更全面的控制。使用 Spire.XLS,开发者可以:
- 将多个 DataFrame 组织到同一个工作簿的不同工作表中。
- 自定义标题、字体、颜色和单元格格式,生成专业布局。
- 自动调整列宽和行高,提高可读性。
- 添加图表、公式和其他 Excel 功能,而无需安装微软Excel或其他库。
pip install pandas spire.xls这些库允许你将 DataFrame 导出到 Excel,并自定义格式、插入图表和生成结构化布局。
将单个 Pandas DataFrame 导出到 Excel 并设置格式
导出单个 DataFrame 到 Excel 是最常见的场景。使用 Spire.XLS,不仅可以导出 DataFrame,还可以格式化标题、设置单元格样式,并添加图表,让你的报表看起来更加专业。
具体实现步骤如下:
步骤 1:创建示例 DataFrame
首先,需要创建一个 DataFrame。以下是一个示例DataFrame,你可以将其替换为自己的数据。
import pandas as pd
from spire.xls import *
# 创建一个示例 DataFrame
df = pd.DataFrame({
'姓名': ['张伟', '李娜', '王强'], # 员工姓名
'部门': ['人事部', '财务部', '技术部'], # 部门
'月薪': [8000, 9500, 12000] # 月薪
})Pandas DataFrame 导出到 Excel 的准备工作
在导出 Pandas DataFrame 到 Excel 之前,请确保已安装pandas与Spire.XLS库:
import pandas as pd
from spire.xls import *
# 创建一个示例 DataFrame
df = pd.DataFrame({
'姓名': ['张伟', '李娜', '王强'], # 员工姓名
'部门': ['人事部', '财务部', '技术部'], # 部门
'月薪': [8000, 9500, 12000] # 月薪
})步骤 2:创建工作簿并访问第一个工作表
接下来,创建一个新的 Excel 工作簿,并获取第一个工作表。给工作表命名为 "员工信息",便于理解和管理。
# 创建新工作簿
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "员工信息" # 给工作表命名步骤 3:写入列标题并格式化
将列标题写入 Excel 第一行,并加粗字体,同时设置浅灰色背景,使表格整洁、易于阅读。
# 写入列标题
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True # 设置标题加粗
cell.Style.Color = Color.get_LightGray() # 设置浅灰色背景步骤 4:写入数据行
将 DataFrame 中的每一行数据写入 Excel。对于数字数据,使用 NumberValue 属性,让 Excel 能够识别并用于计算和绘图;对于文本数据,则使用 Text 属性。
# 写入数据行
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value # 数字使用 NumberValue
else:
cell.Text = str(value) # 文本使用 Text步骤 5:应用边框并自动调整列宽
为数据区域添加外部和内部边框,并让列宽自动适应内容长度,使 Excel 表格更加美观、像专业报表。
# 应用边框并自动调整列宽
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # 外边框
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # 内边框
usedRange.AutoFitColumns() # 自动调整列宽步骤 6:添加图表以可视化数据
图表能够帮助快速理解数据趋势。在本示例中,我们创建一个柱状图,用于比较各员工月薪。
# 添加图表
chart = sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered # 设置柱状图
chart.DataRange = sheet.Range["A1:C4"] # 图表数据范围
chart.SeriesDataFromRange = False
chart.LeftColumn = 5 # 图表左侧位置
chart.TopRow = 1 # 图表上方位置
chart.RightColumn = 10 # 图表右侧位置
chart.BottomRow = 16 # 图表底部位置
chart.ChartTitle = "员工月薪对比" # 图表标题
chart.ChartTitleArea.Font.Size = 12
chart.ChartTitleArea.Font.IsBold = True步骤 7:保存工作簿
最后,将工作簿保存到指定位置。
# 保存 Excel 文件
workbook.SaveToFile("员工信息报表.xlsx", ExcelVersion.Version2016)
workbook.Dispose()输出结果:
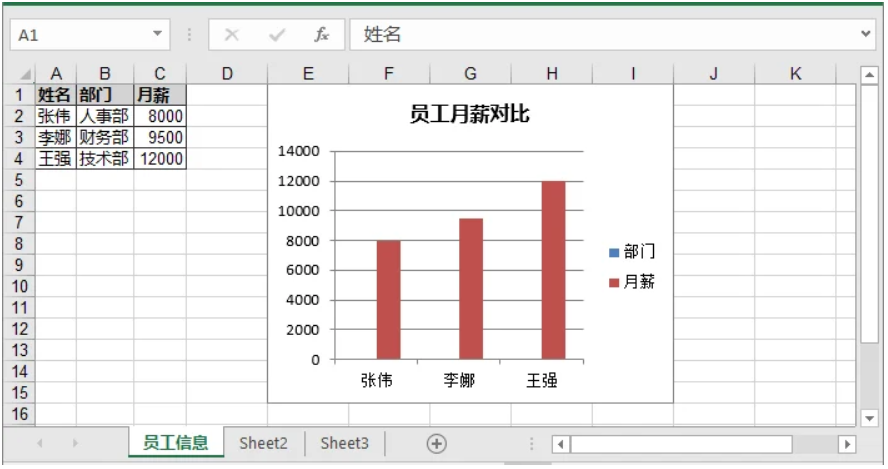
Excel文件生成后,你可以对其进行进一步处理,例如将其转换为 PDF,方便分享:
workbook.SaveToFile("员工信息报表.pdf", FileFormat.PDF)将多个 Pandas DataFrame 导出到同一个 Excel 文件
在生成 Excel 报表时,经常需要将多个数据集放在不同的工作表中。使用 Spire.XLS,每个 DataFrame 可以写入独立工作表,使相关数据清晰有序,便于分析。
具体实现步骤如下:
步骤 1:创建多个示例 DataFrame
在导出前,创建两个 DataFrame:一个包含员工信息,另一个包含产品信息。每个 DataFrame 对应一个工作表。
import pandas as pd
from spire.xls import *
# 示例 DataFrame
df1 = pd.DataFrame({'姓名': ['张伟', '李娜'], '年龄': [28, 32]})
df2 = pd.DataFrame({'产品': ['笔记本电脑', '手机'], '价格': [7500, 3200]})
# 将 DataFrame 与对应工作表名绑定
dataframes = [
(df1, "员工信息"),
(df2, "产品信息")
]这里 dataframes 是一个元组列表,将每个 DataFrame 与其对应的工作表名称关联起来。
步骤 2:创建新工作簿
创建一个新的工作簿,用于存放DataFrame数据。新工作簿默认包含三个工作表。
# 创建新工作簿
workbook = Workbook()步骤 3:循环写入每个 DataFrame到单独的Excel表格
使用循环遍历列表中的 DataFrame,将每个数据集写入单独的工作表。同时为数据区域添加边框。
for i, (df, sheet_name) in enumerate(dataframes):
if i < workbook.Worksheets.Count:
sheet = workbook.Worksheets[i]
else:
sheet = workbook.Worksheets.Add()
sheet.Name = sheet_name
# 写入标题并设置字体加粗和背景颜色
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
sheet.Columns[colIndex - 1].ColumnWidth = 15
# 写入数据行
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# 添加边框
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black())
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black())步骤 4:保存工作簿
将Excel文件保存到指定位置。
workbook.SaveToFile("员工与产品信息.xlsx", ExcelVersion.Version2016)
workbook.Dispose()生成结果:
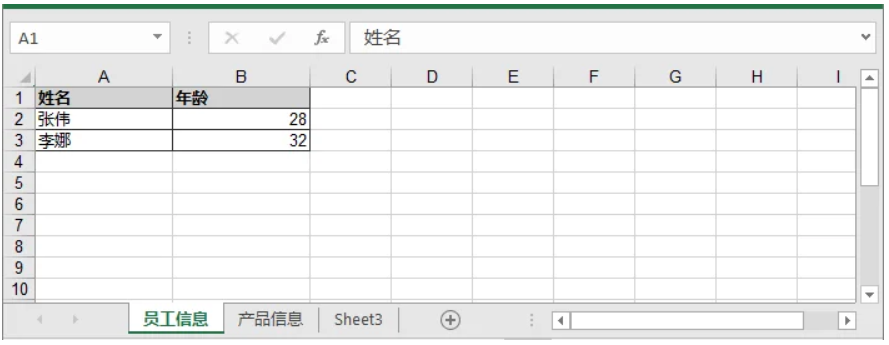
将 Pandas DataFrame 写入现有 Excel 文件
在实际工作中,有时并不希望新建 Excel 文件,而是需要将新的数据写入已有的工作簿。使用Spire.XLS,可以轻松实现这一需求:只需加载现有工作簿,添加新的工作表或访问目标工作表,然后按照与新建工作簿相同的逻辑写入 DataFrame 数据。
以下代码展示了如何将一个Pandas DataFrame写入到现有Excel表格:
import pandas as pd
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("员工与产品信息.xlsx")
new_df = pd.DataFrame({
'区域': ['华北', '华南', '华东', '西南'],
'销售额': [120000, 150000, 130000, 110000]
})
new_sheet = workbook.Worksheets.Add("区域销售")
# 写入标题
for colIndex, colName in enumerate(new_df.columns, start=1):
cell = new_sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
new_sheet.Columns[colIndex - 1].ColumnWidth = 15
# 写入数据
for rowIndex, row in enumerate(new_df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = new_sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# 保存
workbook.SaveToFile("员工产品区域信息.xlsx", ExcelVersion.Version2016)
workbook.Dispose()生成结果:
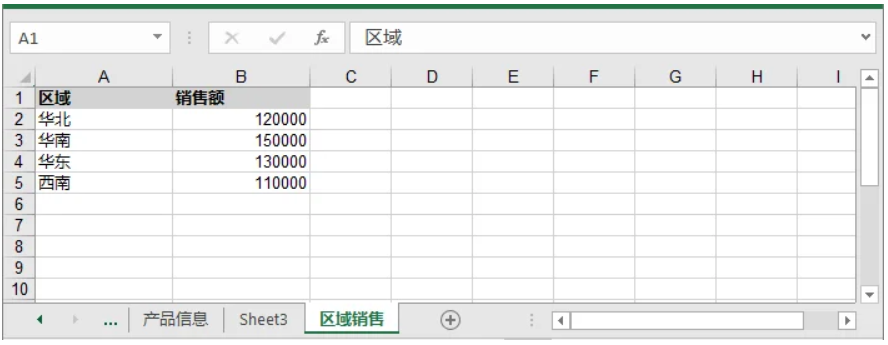
导出 Pandas DataFrame 到 Excel的自定义选项
除了基础导出外,还可以对导出过程进行自定义,以满足特定报表需求。例如,可以选择导出特定列,或者决定是否包含DataFrame索引,从而让 Excel 文件更加整洁、易读。
1. 选择特定列
在实际场景中,很多时候并不需要导出 DataFrame 中的所有列。通过只导出需要的列,可以让 Excel 报表内容更加简洁,同时避免无关信息干扰阅读。
下面示例演示如何只导出姓名和部门两列:
import pandas as pd
from spire.xls import *
# 创建示例 DataFrame
df = pd.DataFrame({
'姓名': ['张伟', '李娜', '王强'],
'部门': ['人事部', '财务部', '技术部'],
'月薪': [8000, 9500, 12000]
})
# 指定需要导出的列
columns_to_export = ['姓名', '部门']
# 创建新的工作簿并获取第一个工作表
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 写入标题行
for colIndex, colName in enumerate(columns_to_export, start=1):
sheet.Range[1, colIndex].Text = colName
# 写入数据行
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=1):
sheet.Range[rowIndex, colIndex].Text = value
# 保存 Excel 文件
workbook.SaveToFile("选择列.xlsx")
workbook.Dispose()2. 包含或排除DataFrame索引
默认情况下,DataFrame 的索引不会导出到 Excel。但在一些报表中,行号或索引对数据分析非常重要。此时,可以手动将索引写入工作表,使每一行都有明确标识。
下面示例展示如何在导出特定列的同时包含索引:
# 写入索引标题
sheet.Range[1, 1].Text = "索引"
# 写入索引数值(数字)
for rowIndex, idx in enumerate(df.index, start=2):
sheet.Range[rowIndex, 1].NumberValue = idx
# 写入其他列标题,从第二列开始
for colIndex, colName in enumerate(columns_to_export, start=2):
sheet.Range[1, colIndex].Text = colName
# 写入数据行
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=2):
if isinstance(value, (int, float)):
sheet.Range[rowIndex, colIndex].NumberValue = value
else:
sheet.Range[rowIndex, colIndex].Text = str(value)
# 保存 Excel 文件
workbook.SaveToFile("包含索引.xlsx", ExcelVersion.Version2016)
workbook.Dispose()总结
本文介绍了在 Python 中使用 Spire.XLS 将 Pandas DataFrame 导出到 Excel 的多种方法。通过示例可以看到,除了基础的数据导出外,还可以实现标题样式设置、数据格式化、向现有工作簿写入数据,以及选择特定列或包含索引等操作。这些方法让数据分析和报表生成过程更加灵活,使开发者能够更好地控制导出内容和展示效果,以适应不同的应用场景和业务需求。
常见问题解答(FAQs)
问:如何在 Python 中将 Pandas DataFrame 导出到 Excel?
答: 可以使用 Spire.XLS 或类似库将 DataFrame 写入 Excel 文件。这样不仅可以导出数据,还可以自定义表头样式、单元格格式以及添加图表等,使报表更专业。
问:是否可以在同一个 Excel 文件中导出多个 DataFrame?
答: 可以。通过**Spire.XLS**,可以将多个 DataFrame 写入同一个工作簿的不同工作表中,从而将相关数据整合在一个文件里,便于管理和分析。
问:如何在导出的 Excel 中设置标题和单元格样式?
答: 可以将表头字体加粗、设置背景颜色,调整列宽和行高,数字使用 NumberValue 属性保存,以便 Excel 识别和计算。这些设置能让 Excel 报表看起来更规范、易读。
问:能在导出的 Excel 文件中添加图表吗?
答: 可以。Spire.XLS 支持柱状图、折线图等多种图表类型,图表可以直接绑定 DataFrame 的数据,帮助快速展示数据趋势或对比分析。
问:导出 Excel 文件是否必须安装 Microsoft Excel?
答: 不需要。Spire.XLS 可以在 Python 中独立创建和格式化 Excel 文件,无需依赖 Excel 软件本身。
问:可以选择导出 DataFrame 的部分列或包含索引吗?
答: 可以。导出时可以指定需要的列,也可以选择是否包含索引,从而生成更简洁、针对性更强的报表。