文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F033
架构: vue+flask+neo4j+mysql
亮点:协同过滤推荐算法+知识图谱可视化+智能问答
支持爬取图书数据,数据超过万条,知识图谱节点几万个
0 视频介绍
基于neo4j的 图书问答知识图谱系统vue+flask架构
1 功能和架构说明
功能图
系统简介:本系统是一个基于Vue、Flask、Neo4j、MySQL和爬虫技术构建的图书管理与推荐系统。其核心功能围绕图书数据的爬取、存储、分析和用户交互展开。系统的主要模块包括:

架构图

该系统采用B/S架构,前端使用Vue.js生态系统(包括Vuex用于状态管理、Vue Router用于路由导航)构建用户界面,与Flask后端通过API交互。后端负责业务逻辑处理,利用SQLAlchemy与MySQL数据库进行数据存储,并通过Neo4j构建知识图谱以支持图谱检索。爬虫模块负责从外部来源抓取图书数据,导入MySQL和Neo4j数据库,为系统提供数据支持。
推荐系统基于UserCF和ItemCF算法,分析用户行为和图书特征,提供个性化推荐。数据可视化模块利用ECharts生成多种图表,支持用户进行深入的数据分析。图书问答系统集成了LTP模型,提供智能问答服务。登录和注册功能确保推荐功能仅对授权用户可用,保障系统的安全性和用户体验。
系统架构清晰,技术选型合理,既保证了数据处理的高效性,又提供了丰富的用户交互功能。
系统架构主要分为以下几个部分:用户前端 、后端服务 、数据库 、数据爬取与处理。各部分通过协调工作,实现数据的采集、存储、处理以及展示。具体如下:
1. 用户前端
用户通过浏览器访问系统,前端采用了基于 Vue.js 的技术栈来构建。
- 浏览器:作为用户与系统交互的媒介,用户通过浏览器进行各种操作,如浏览图书、获取推荐等。
- Vue 前端:使用 Vue.js 框架搭建前端界面,包含 HTML、CSS、JavaScript,以及 Vuex(用于状态管理),vue-router(用于路由管理),和 Echarts(用于数据可视化)等组件。前端向后端发送请求并接收响应,展示处理后的数据。
2. 后端服务
后端服务采用 Flask 框架,负责处理前端请求,执行业务逻辑,并与数据库进行交互。
- Flask 后端:使用 Python 编写,借助 Flask 框架处理 HTTP 请求。通过 SQLAlchemy 与 MySQL 进行交互,通过 py2neo 与 Neo4j 进行交互。后端主要负责业务逻辑处理、 数据查询、数据分析以及推荐算法的实现。
3. 数据库
系统使用了两种数据库:关系型数据库 MySQL 和图数据库 Neo4j。
- MySQL:存储从网络爬取的基本数据。数据爬取程序从外部数据源获取数据,并将其存储在 MySQL 中。MySQL 主要用于存储和管理结构化数据。
- Neo4j:存储图谱数据,特别是用户、图书及其关系(如阅读、写、出版等)。通过利用 py2neo 库将 MySQL 中的数据结构化为图节点和关系,再通过图谱生成程序(可能是一个 Python 脚本)将其导入到 Neo4j 中。
4. 数据爬取与处理
数据通过爬虫从外部数据源获取,并存储在 MySQL 数据库中,然后将数据转换为图结构并存储在 Neo4j 中。
- 爬虫:实现数据采集,从网络数据源抓取相关信息。爬取的数据首先存储在 MySQL 数据库中。
- 图谱生成程序:利用 py2neo 将爬取到的结构化数据(如用户、图书、作者、出版社,以及它们之间的关系)从 MySQL 导入到 Neo4j 中。通过构建图谱数据,使得后端能够进行复杂的图查询和推荐计算。
工作流程
- 数据爬取:爬虫程序从外部数据源抓取数据并存储到 MySQL 数据库中。
- 数据处理与导入:图谱生成程序将 MySQL 中的数据转换为图结构并导入到 Neo4j 中,利用 py2neo 与 Neo4j 交互。
- 前后端交互 :
- 用户通过浏览器访问系统,前端用 Vue.js 构建,提供友好的用户界面和交互。
- 前端向 Flask 后端发送请求,获取图书信息或推荐图书。
- 推荐算法:后端在接收请求后,利用 Neo4j 图数据库中的数据和关系进行处理(如推荐计算),并使用 py2neo 库与 Neo4j 交互获取数据结果。
- 数据返回与展示:后端将计算结果返回给前端进行展示,通过 Vue.js 的图表库(如 Echarts)进行数据可视化,让用户得到直观的推荐结果和分析信息。
小结
这套系统通过整合爬虫、关系型数据库、图数据库,以及前后端的协调配合,实现了数据的高效采集、存储、处理、推荐和展示。从用户体验的角度,系统能够提供高度个性化的推荐,并通过图形化的方式呈现数据分析结果。
2 功能介绍
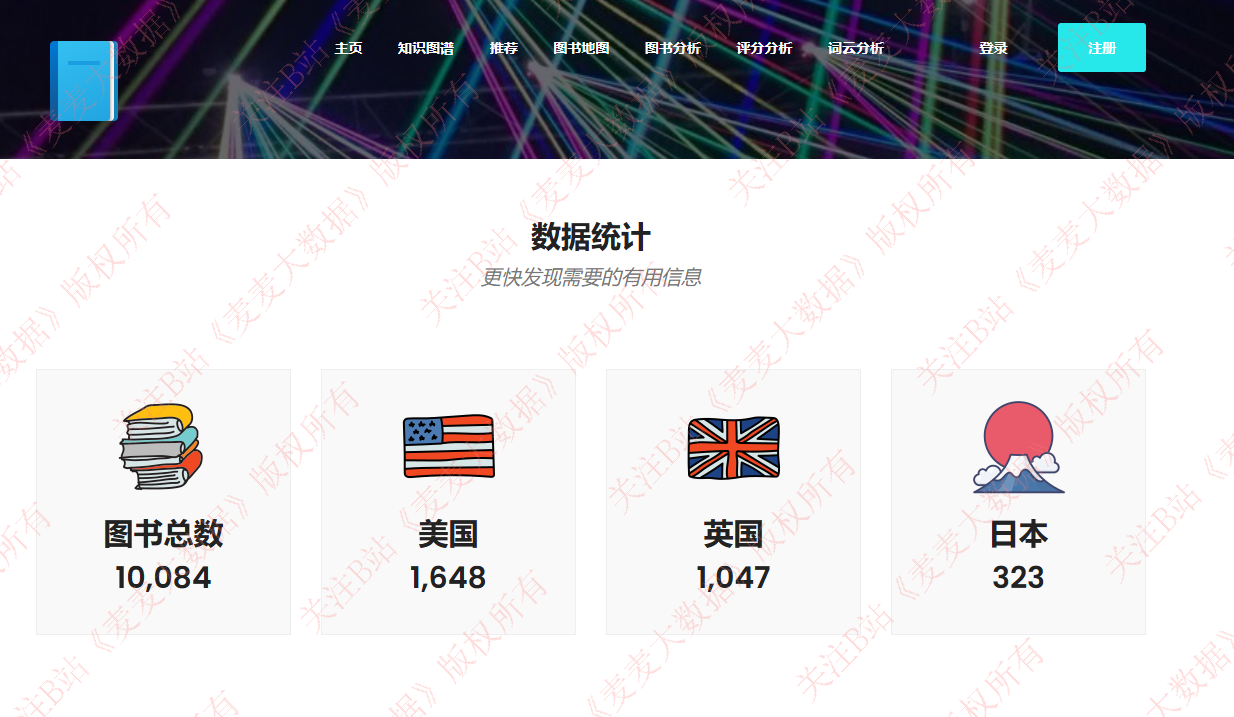
1 系统主页,统计页面
2 知识图谱构造 & 可视化
利用Python 实现知识图谱的构建,同时对构建过程可看进度:

构建完之后来neo4j界面中可以查看:

本文系统实现的知识图谱可视化:

支持模糊搜索,比如搜索法国作家 加缪

3 推荐算法
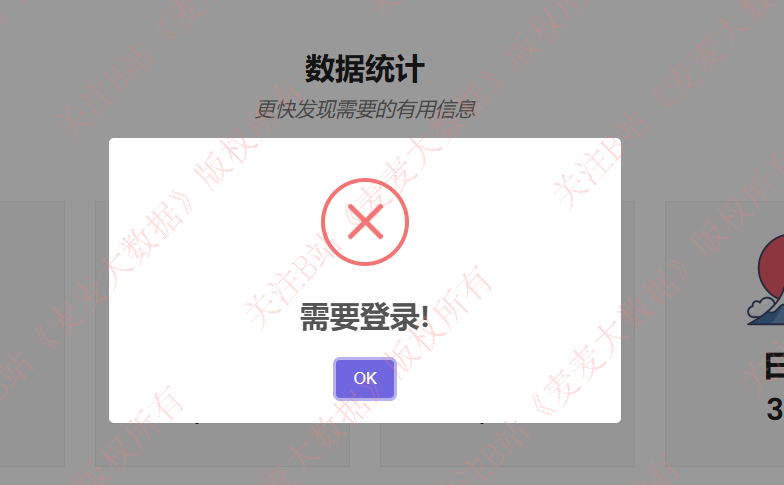
没有登录无法推荐
两种协同过滤推荐算法推荐

点击可以进入图书详情页面(可以查看 名称、作者、系列、图片、装帧、用户给图书的评分)

支持使用评分控件进行评分
4 可视化分析
分为4个页面
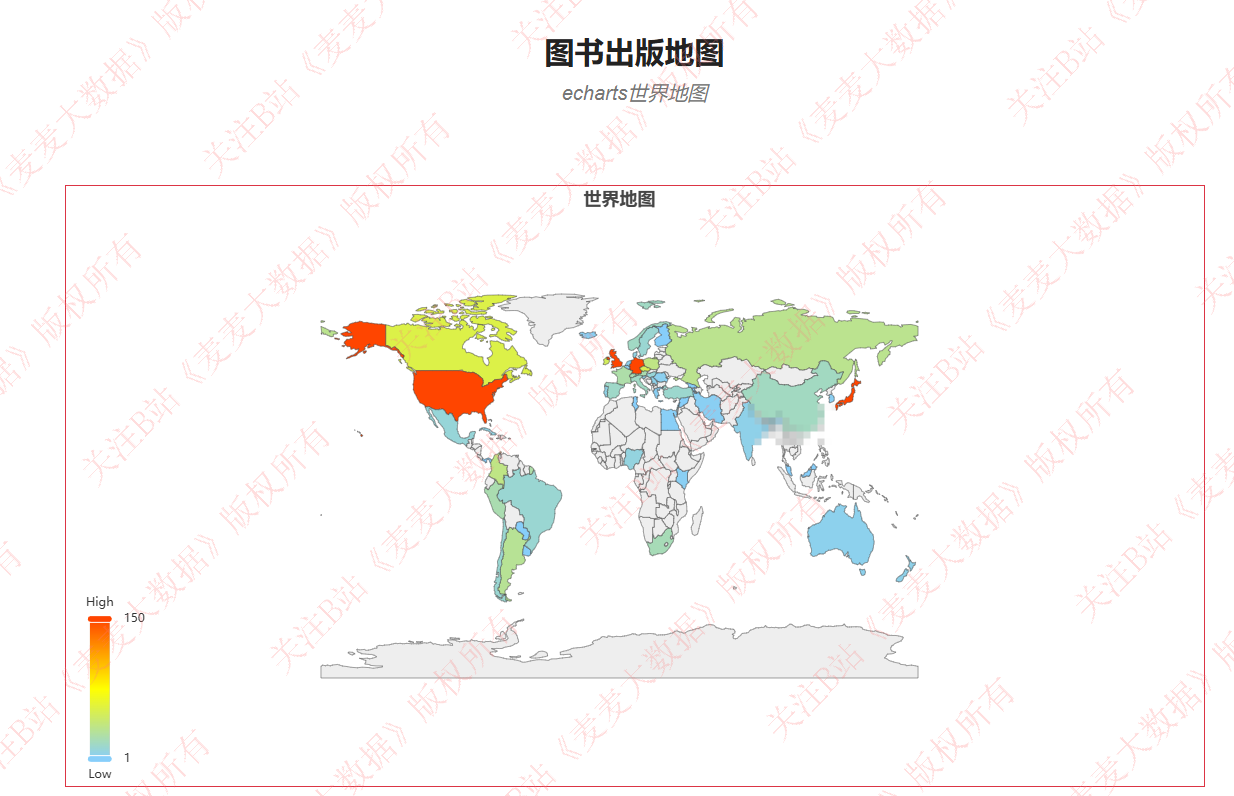
图书出版地图分析
图书分析
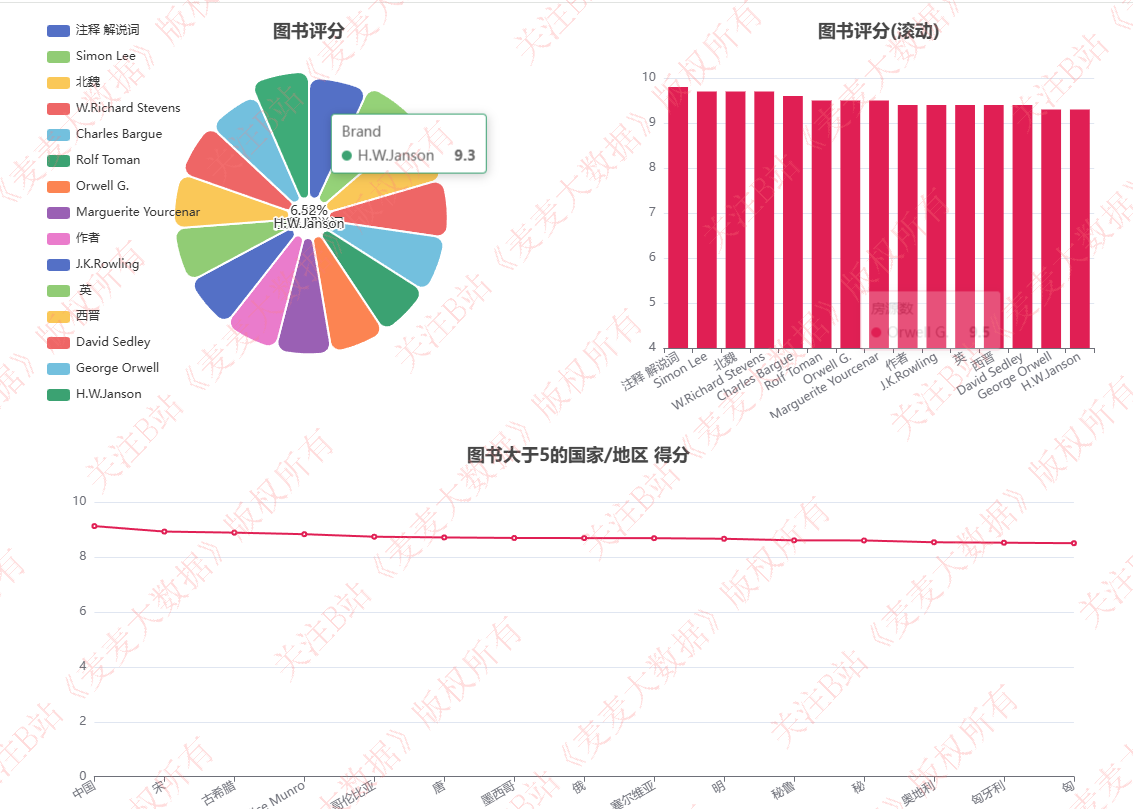
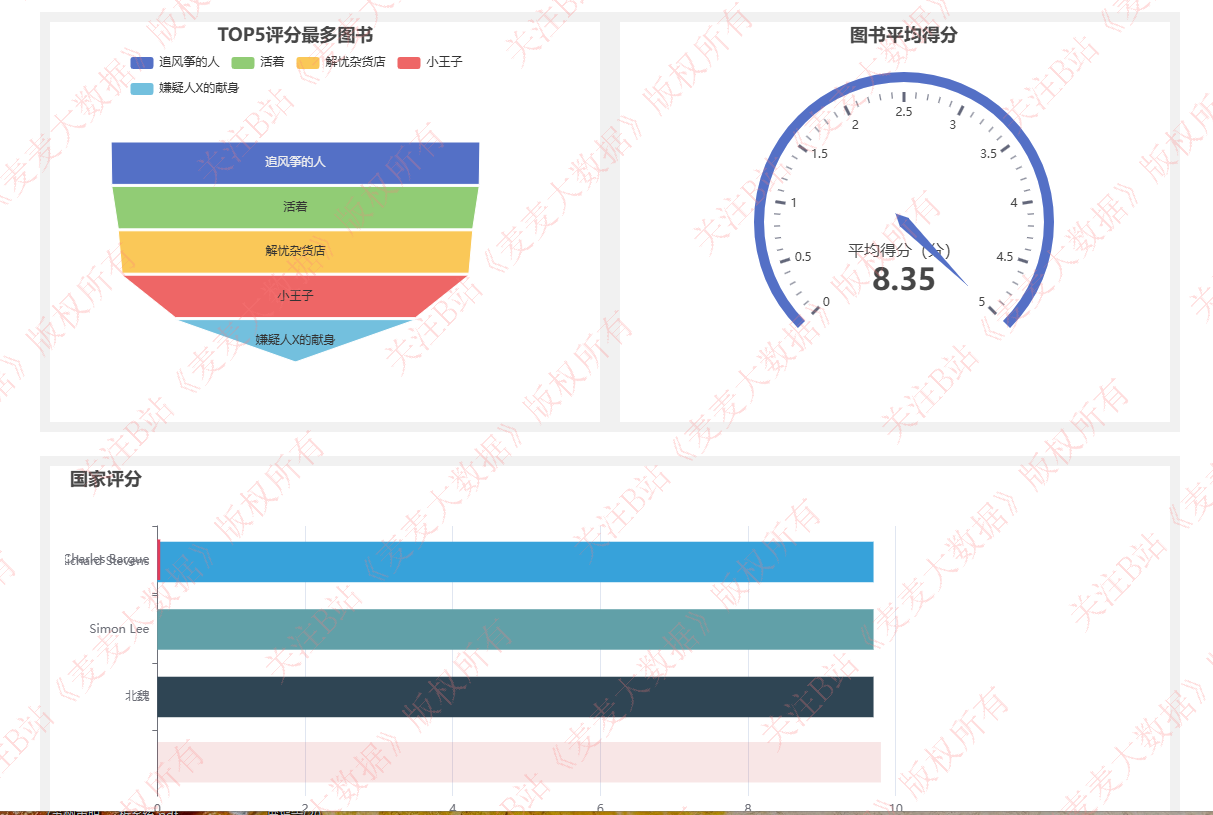
图书评分分析
图书词云分析

5 智能问答
代码介绍:该代码实现了一个基于LTP的图书知识问答系统,主要功能包括:1. 使用spaCy进行自然语言处理,提取问题中的实体(如作者、书名等);2. 从知识库中检索相关信息并生成答案。代码支持多种问题类型,包括作者查询和主题查询,适用于图书推荐和知识问答场景。
截图:


流程图:

代码:
python
import spacy
from spacy import displacy
from spacy.util import minibatch, compounding
# 加载LTP模型
nlp = spacy.load("zh_core_web_sm")
def book_question_processing(question, book_data):
"""
处理图书相关问题并返回答案
"""
# 分析问题
doc = nlp(question)
entities = [(ent.text, ent.label_) for ent in doc.ents]
# 提取关键信息(作者、书名、主题等)
for entity in entities:
if entity[1] == "作者":
author = entity[0]
elif entity[1] == "书名":
book_name = entity[0]
# 从知识库中检索答案
if "作者" in locals():
return f"{book_name} 的作者是 {author}"
elif "书名" in locals():
return f"{book_name} 的主题是 {book_data[book_name]['主题']}"
# 示例问题生成
questions = [
"谁是《1984》的作者?",
"《平凡的世界》主要讲述什么?"
]
# 知识库示例数据
book_data = {
"1984": {"作者": "乔治·奥威尔", "主题": "反乌托邦"},
"平凡的世界": {"作者": "路遥", "主题": "成长与奋斗"}
}
# 处理问题并输出答案
for q in questions:
print(f"问题:{q}")
print(f"答案:{book_question_processing(q, book_data)}\n")6 登录与注册
支持登录与注册