WordNet

| 对比项 | 普通字典 | WordNet |
|---|---|---|
| 建立方式 | 人类写作者为读者编写 | 语言学家为计算机编写 |
| 内容结构 | 每个词独立定义、例句 | 每个词义(Synset)之间有网络关系 |
| 主要用途 | 查含义、拼写 | 计算机进行语义推理、相似度计算 |
| 数据形式 | 文本 | 图结构(词义节点 + 语义边) |
Problems with WordNet

One-hot

Problem of similarity

WordNet 方式失败,因此要"学习向量"而非人工列举。
Distributional semantics:

word vector

word vector=word embedding =word representation
"分布式"意思是------词义被分布在多个维度上,不是集中在某一个维度。
-
每一维都反映一部分语义(可能与语法、语境、主题有关)。
-
例如,"banking"的第 7 维可能反映"金融性",第 19 维可能反映"机构性",等等。
因此,语义信息是**分布式编码(distributed encoding)**的。
Word2vec

核心概念
Word2Vec 是 Mikolov 等人在 2013 年提出的一个框架,用来从大量文本中学习词向量(word vectors) 。
它的目标是:
让语义相似的单词拥有相似的向量表示。
主要思想(Idea)
-
We have a large corpus of text
→ 我们有一个巨大的文本语料库(corpus),比如所有维基百科文章。
这就是模型的训练数据。
-
Every word is represented by a vector
→ 语料库中每个词都有一个可学习的向量(embedding)。
这些向量最开始是随机的,模型训练后会逐渐学到语义信息。
-
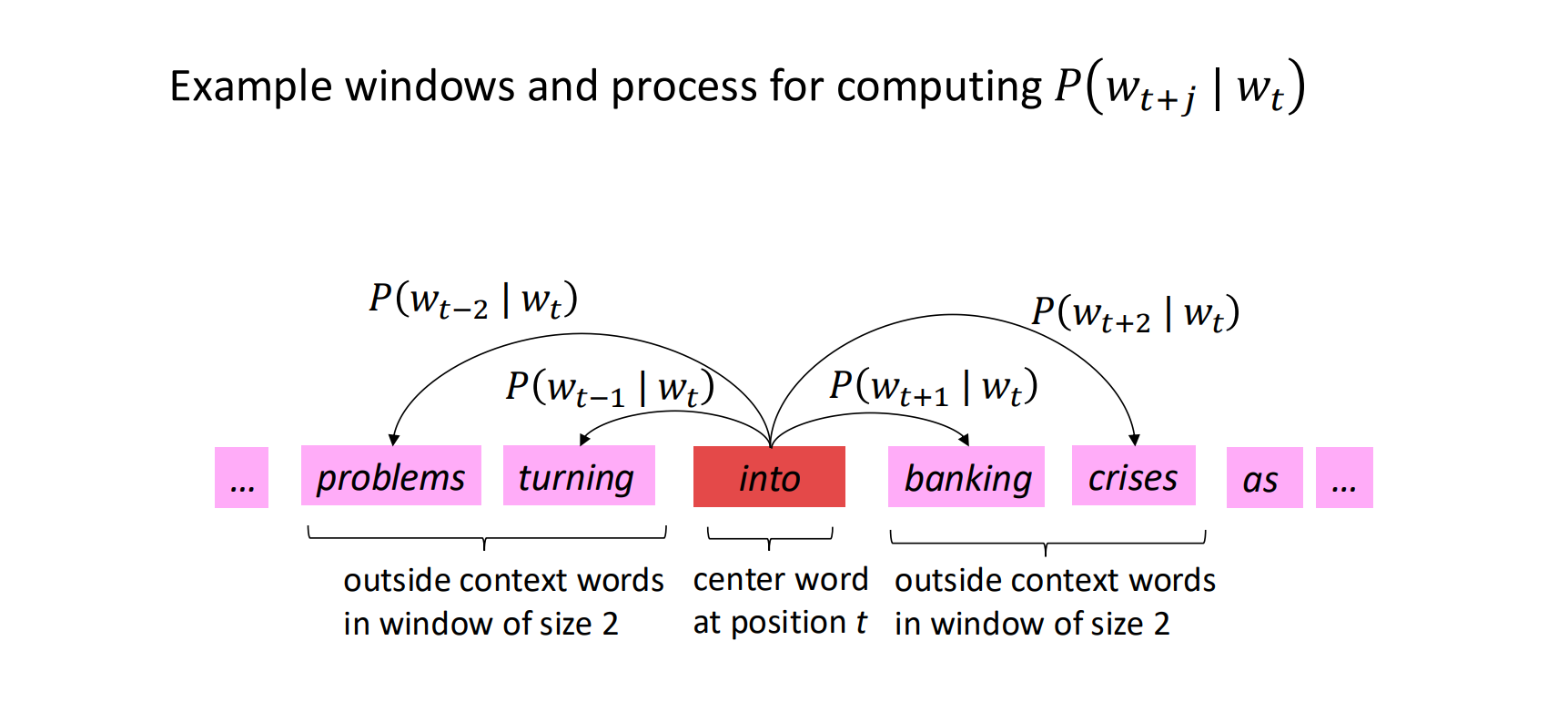
Go through each position t in the text
→ 在语料的每个位置 t,取出当前的中心词(center word)记为 c = w(t),
并找出它前后一定范围内的上下文词(context words) o = w(t±1), w(t±2)...。
这称为滑动窗口(context window)。
-
Use similarity to calculate probability
→ 模型计算"在给定中心词 c 的情况下,上下文词 o 出现的概率",
用到的就是它们的词向量相似度(通常用点积)。
数学上写成: P(o∣c)=euoTvc∑w∈VeuwTvcP(o|c) = \frac{e^{u_o^T v_c}}{\sum_{w \in V} e^{u_w^T v_c}} P(o∣c)=∑w∈VeuwTvceuoTvc
(softmax 形式)
-
Keep adjusting word vectors to maximize this probability
→ 不断调整这些词向量,使得真实上下文词出现的概率最大。
换句话说,模型学习到:
-
"banking" 的上下文常出现 "finance, loan, money";
-
"apple" 的上下文常出现 "fruit, tree, eat";
因此它们的向量就会靠近这些语义邻居。
-
右侧图解释
右边的图展示的是 Skip-gram 模型结构(Word2Vec 的两种形式之一):
-
输入层:当前中心词 w(t)(例如 "banking")。
-
投影层(projection):把输入词映射成向量表示(embedding)。
-
输出层:预测它周围的上下文词 w(t−2)、w(t−1)、w(t+1)、w(t+2)。
也就是说,Skip-gram 的任务是:
给定中心词 → 预测上下文。
另一种相反的模型叫 CBOW(Continuous Bag of Words),是:
给定上下文 → 预测中心词。
Word2vec:objective function
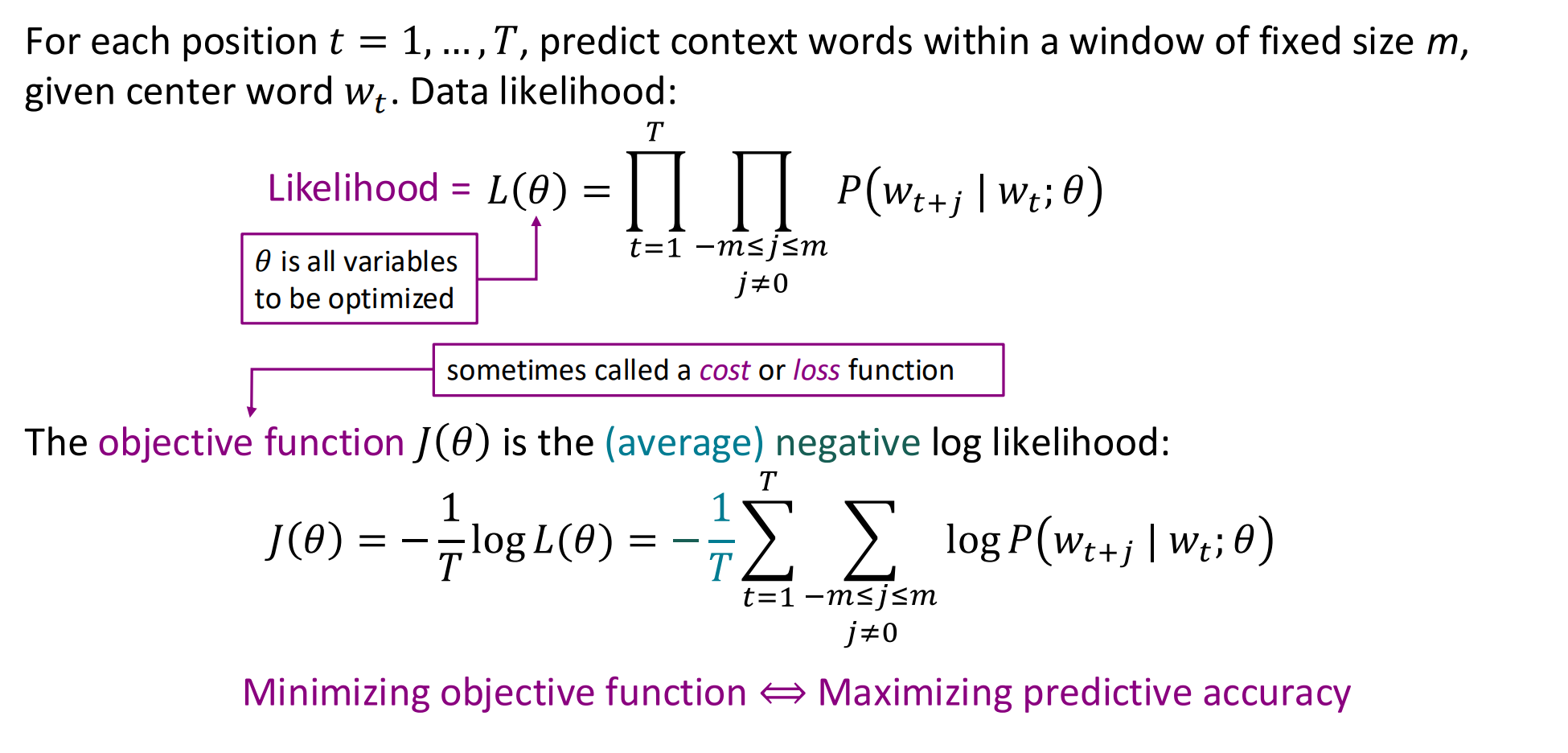
下标
在 Word2Vec 中:
-
下标在 v 上的词是中心词;
-
下标在 u 上的词是上下文词。
换句话说:
vcv_cvc→ "谁在预测别人",
uou_ouo → "谁被预测出来"。
预测函数

在 Word2Vec 的上下文里,这个 xix_ixi 其实具体对应的是每个词的相似度分数(score)
max" 表示会放大最大值的影响;
"soft" 表示仍然给较小的值留一点概率
Optimize value of parameters to minimize loss
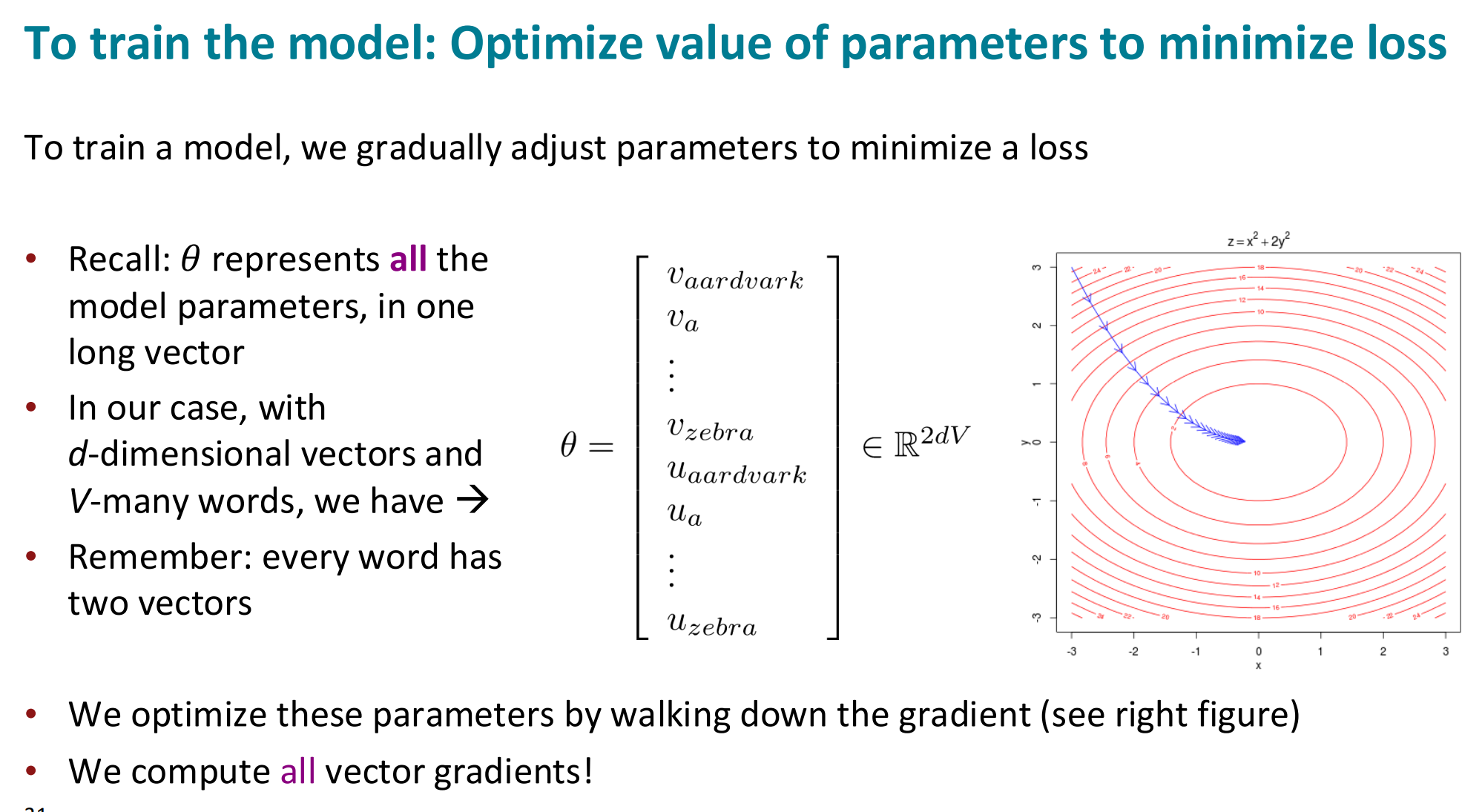
在 Word2Vec 里,参数 θ 就是所有词的中心向量和上下文向量的集合。
Gradient descent
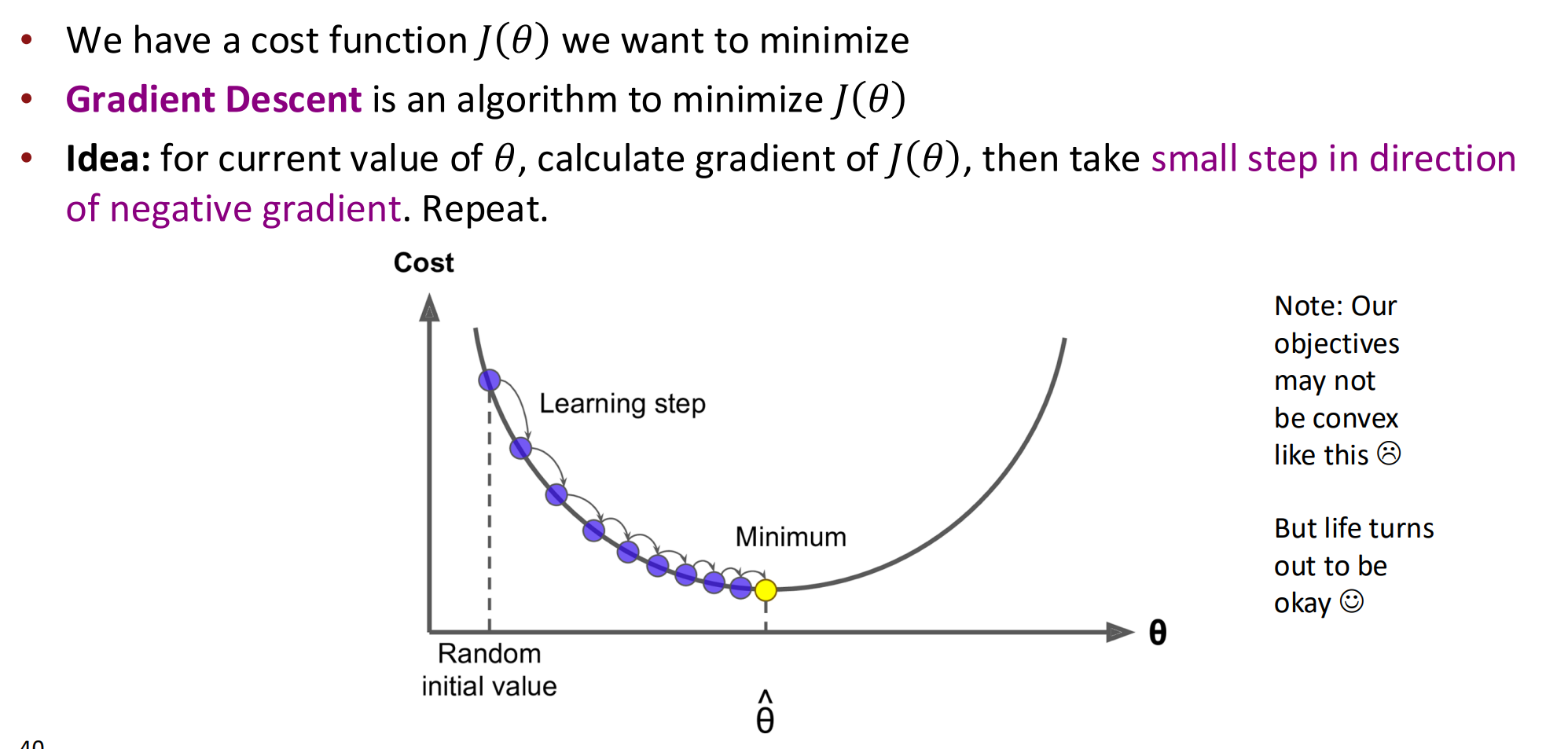

Stochastic Gradient Descent

-
在 Batch GD 中,偏导数是全体样本平均梯度。
-
在 SGD 中,偏导数是单一样本的梯度,因此每次都能更新参数