NLP之Embedding:Youtu-Embedding的简介、安装和使用方法、案例应用之详细攻略
目录
[T3.1、使用 sentence-transformers](#T3.1、使用 sentence-transformers)
[T3.2、使用 LangChain](#T3.2、使用 LangChain)
[T3.3、使用 LlamaIndex](#T3.3、使用 LlamaIndex)
[信息检索 (Information Retrieval - IR) / 向量检索](#信息检索 (Information Retrieval - IR) / 向量检索)
语义文本相似度 (Semantic Textual Similarity - STS)
检索增强生成 (Retrieval-Augmented Generation - RAG)
Youtu-Embedding的简介
2025年9月底,Youtu-Embedding 是由腾讯优图实验室(Tencent Youtu Lab)开发的一款业界领先的通用文本表示模型。该模型旨在为各种自然语言处理(NLP)任务提供高质量的文本向量表示,其在信息检索(IR)、语义文本相似度(STS)、聚类、重排(Reranking)和分类等多个领域都展现出了顶尖的性能。
项目团队不仅开源了模型权重,还提供了完整的推理代码和创新的训练框架,希望能够帮助社区开发者利用这一工具创造更大的价值。
根据项目页面信息,其发布的第一个版本 Youtu-Embedding-V1 是一个拥有20亿(2B)参数的通用语义表示模型,输出维度为2048,并支持高达8K的序列长度。
Github地址: https://github.com/TencentCloudADP/youtu-embedding
1、特点
Youtu-Embedding 的核心优势和技术特点可以总结为以下四个方面:
****>> 顶尖的性能表现 (State-of-the-Art Performance):****在权威的中文文本嵌入评测基准 CMTEB 上,该模型取得了 77.58 的最高分(截至2025年9月),证明了其强大的文本表示能力。在分类、聚类、成对分类、重排、检索、语义相似度等七个任务类别中均表现出色。
>> ****精心设计的三阶段训练流程 (Sophisticated Three-Stage Training):****项目团队首创了"大语言模型预训练 → 弱监督对齐 → 协同判别式微调"的训练管线。这个流程系统性地将大语言模型(LLM)的广泛知识,提炼并转化为嵌入任务所需的专业判别能力。
>> ****⭐ 创新的微调框架 (Innovative Fine-tuning Framework):****为了解决多任务学习中普遍存在的"负迁移"问题,项目设计了一个独特的协同判别式微调框架(Collaborative-Discriminative Fine-tuning Framework)。该框架通过以下关键创新实现高效的统一表示学习:
- ****统一且可扩展的数据格式:****能够无缝处理来自IR、STS、分类和重排等异构任务的数据,并为未来集成新任务提供了良好的扩展性。
- ****任务差异化的损失函数:****针对不同任务设计了专门的优化目标。例如,为信息检索(IR)任务使用支持多正例、难负例和批内跨设备负采样的 InfoNCE 对比损失;为语义文本相似度(STS)任务采用排序感知的目标(如皮尔逊损失、KL散度损失),直接优化排序一致性。
- 动态单任务采样机制:为了避免混合任务批次带来的梯度干扰,实现了自定义的动态采样器。它确保在单次训练迭代中,所有GPU处理的是同一数据集的非重叠分片,为模型提供纯净、稳定的梯度信号。
****>> 细致的数据工程 (Meticulous Data Engineering):****项目结合了基于大语言模型(LLM)的高质量数据合成技术与高效的难负例挖掘策略,为模型训练提供了最坚实的数据基础。
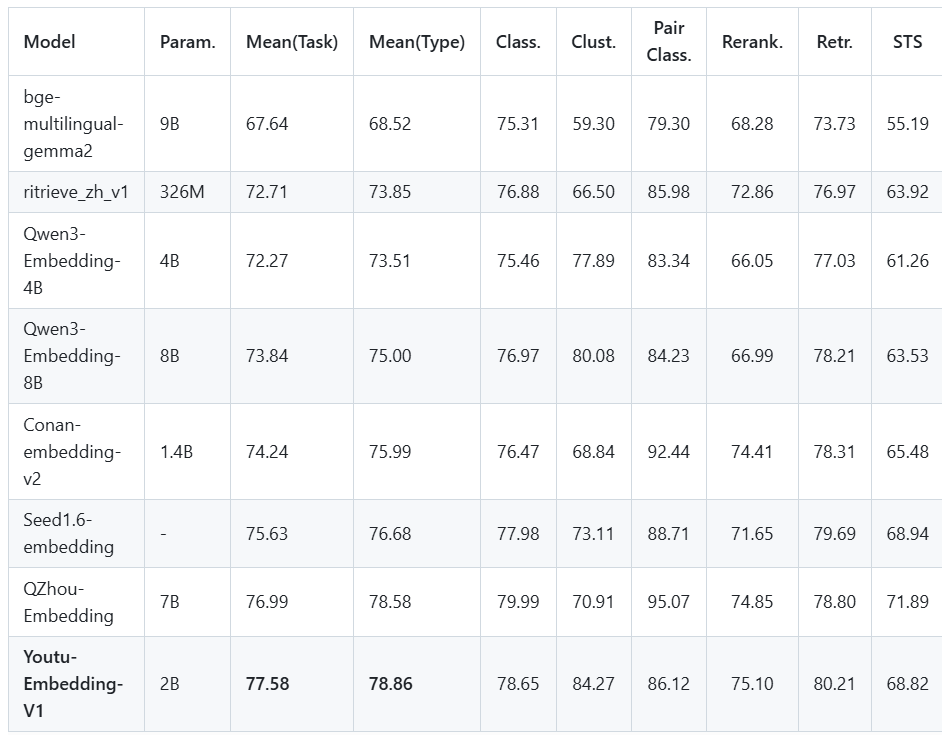
2、模型性能
截至2025年9月28日的CMTEB基准测试结果表明,Youtu-Embedding-V1(2B参数)在当时展现出卓越的性能,在七个任务类别中均表现领先,以77.58的平均任务得分和78.86的平均类型得分位居榜首,尤其在聚类(84.27)和重排序(75.10)任务中优势明显,同时在检索(80.21)和语义文本相似度(68.82)等关键任务上也取得最佳成绩,显著优于同期的QZhou-Embedding、Seed1.6-embedding和Conan-embedding-v2等模型,实现了当时的最高整体平均分,彰显了其在该时间节点上全面且领先的中文多任务语义理解能力------但需强调,这一领先地位反映的是截至该日期的模型竞争力,技术演进将持续推动性能边界,卓越仅属于当下。
Youtu-Embedding的安装和使用方法
项目提供了多种灵活的使用方式,包括官方API、本地部署以及与流行框架(LangChain, LlamaIndex)的集成。
1、安装与使用
T1、使用官方API
安装
这是最便捷的使用方式,适合快速集成和线上应用。
安装SDK:pip install --upgrade tencentcloud-sdk-python
使用方法
关于认证和接入点的详细信息,请参考腾讯云官方API文档。
具体的SDK使用方法,可以参考仓库中的示例脚本:usage/tencent_cloud_api.py。
T2、本地自托管推理
在本地运行模型可以获得完全的控制权,适合离线使用、定制化或数据隐私要求高的场景。
步骤1:环境准备
# 克隆仓库
git clone https://github.com/TencentCloudADP/youtu-embedding.git
cd youtu-embedding
# 创建并激活虚拟环境 (以Linux/macOS为例)
python -m venv youtu-env
source youtu-env/bin/activate
# Windows用户请使用: youtu-env\Scripts\activate
# 安装依赖
pip install -U pip
pip install "transformers==4.51.3" torch numpy scipy scikit-learn huggingface_hub步骤2:获取模型权重(二选一)
选项A: 从Hugging Face下载到本地文件夹
huggingface-cli download tencent/Youtu-Embedding --local-dir ./youtu-model
选项B: 克隆模型仓库
git clone https://huggingface.co/tencent/Youtu-Embedding ./Youtu-Embedding
步骤3:运行预置的测试脚本
仓库提供了针对不同环境的测试脚本,可以直接运行。
CUDA 系统: python test_transformers_online_cuda.py
macOS (Apple Silicon with MPS): python test_transformers_online_macos.py
纯本地 (使用已下载到本地的模型): python test_transformers_local.py
示例输出:
Loading checkpoint shards: 100%|███████████████████████████████| 2/2 [00:00<00:00, 28.64it/s]
Model loaded: ./Youtu-Embedding
Device: mps
================================================================================
🔍 Query: What's the weather like?
================================================================================
🥇 BEST MATCH
Score: 0.4465 | ⚡ Moderately Relevant
Visual: [█████████████░░░░░░░░░░░░░░░░░] 44.7%
Content: "The weather is lovely today."
🥈 2nd BEST
Score: 0.3124 | ⚡ Moderately Relevant
Visual: [█████████░░░░░░░░░░░░░░░░░░░░░] 31.2%
Content: "It's so sunny outside!"
...
================================================================================
Raw scores: [[0.4465198516845703, 0.31240472197532654, 0.03040437400341034, 0.06884326785802841]]T3、与其他框架集成
T3.1、使用 sentence-transformers
安装: pip install sentence-transformers==5.1.0
代码示例
python
from sentence_transformers import SentenceTransformer
# model_id 可以是 "tencent/Youtu-Embedding" 或本地模型路径
model = SentenceTransformer("model_id")
queries = ["What's the weather like?"]
passages = [
'The weather is lovely today.',
"It's so sunny outside!",
'He drove to the stadium.'
]
queries_embeddings = model.encode_query(queries)
passages_embeddings = model.encode_document(passages)
similarities = model.similarity(queries_embeddings, passages_embeddings)
print(similarities)T3.2、使用 LangChain
安装: pip install langchain==0.3.27 langchain-community==0.3.29 langchain-huggingface==0.3.1 sentence-transformers==5.1.0 faiss-cpu==1.11.0
使用: 可轻松将模型集成到 RAG(检索增强生成)等应用中。详细示例请参见仓库文件 usage/langchain_embedding.py。
T3.3、使用 LlamaIndex
安装: pip install llama-index==0.14.2 llama-index-embeddings-huggingface==0.6.1 sentence-transformers==5.1.0 llama-index-vector-stores-faiss==0.5.1
**使用:**非常适合将模型集成到 LlamaIndex 的搜索和检索系统中。详细示例请参见仓库文件 usage/llamaindex_embedding.py。
2、如何训练
项目开源了其训练框架,代码位于 training/ 目录。
安装:
python
git clone https://github.com/TencentCloudADP/youtu-embedding.git
cd training/CoDiEmb
pip install -r requirements.txt开始训练:
python
cd scripts
bash train_youtuemb.shYoutu-Embedding的案例应用
虽然项目文档没有提供具体的商业落地案例,但它明确指出了模型的适用场景和任务类型,这些即是其核心的应用案例。
信息检索 (Information Retrieval - IR) / 向量检索
这是模型的核心应用之一。通过将查询(Query)和文档库(Documents)中的文本转换为高质量的向量,可以快速、准确地在大规模数据中找到与查询最相关的文档。这在搜索引擎、问答系统、知识库检索等场景中至关重要。
语义文本相似度 (Semantic Textual Similarity - STS)
模型能够精确计算两个文本片段在语义上的相似程度。这可用于文本去重、意图识别、对话系统中的相似问题匹配等。
文本聚类 (Clustering)
将文本转换为向量后,可以使用K-Means等聚类算法对海量文本进行无监督分类,从而发现文本中的主题分布、进行用户画像分析或舆情热点发现。
文本重排 (Reranking)
在搜索引擎或推荐系统中,可以先用一个快速但可能不太精确的方法(如关键词匹配)召回一个候选集,然后使用 Youtu-Embedding 对这个候选集进行更精确的语义相关性排序,从而提升最终结果的质量。
文本分类 (Classification)
生成的文本向量可以作为特征输入到分类器(如SVM、逻辑回归或简单的神经网络)中,用于情感分析、新闻分类、垃圾邮件检测等任务。
检索增强生成 (Retrieval-Augmented Generation - RAG)
项目提供了与 LangChain 和 LlamaIndex 的集成示例,这表明 Youtu-Embedding 是构建 RAG 应用的理想选择。在 RAG 流程中,它负责"检索"步骤,即根据用户问题从知识库中精确地召回相关信息片段,然后将这些信息提供给大语言模型以生成更准确、更具事实性的答案。