在上一篇文章《领域驱动设计(DDD)领域对象一定要讲究充血模型吗?》中,我已阐明:聚合根的深层价值在于领域信息的表达,而非单纯的一致性守护。但是如果询问GTP等AI大模型,会发现它们总是坚守DDD社区的主流观点,将聚合根的核心职责固化为"维护一致性"。
从可逆计算理论的视角审视,这一认知亟待纠偏。本文将基于此理论,深入揭示一种更具演化能力的全新架构范式。
在领域驱动设计(DDD)的殿堂中,"聚合根作为一致性与事务的边界"几乎是一条不容置疑的金科玉律。它被视为守护领域模型纯洁性、确保数据完整性的最后一道防线。然而,当我们将目光投向那些极度复杂、需要高度演化能力的平台级系统时,这一传统认知可能正是我们需要打破的最大"架构误解"。
本文将基于广义可逆计算(Generalized Reversible Computation)理论的视角,深入剖析这一原则在现代软件工程实践中的局限性。我们将提出一种颠覆性的新范式:将聚合根从"事务囚徒"中解放出来,拆分为职责更清晰的 "数据聚合"与"行为聚合" ,让其回归"领域语言载体"的本质,从而构建出真正能够与业务同频演化、灵活适应未来的软件系统。 需要强调的是,本文并非意在全盘否定传统DDD。对于业务相对稳定、规模可控的系统,传统模型依然高效。我们聚焦的是其在超大规模、平台级SaaS/PaaS 这类对可演化性、可定制性有极致要求的场景下的局限性。
一、 传统原则的裂痕:当"金科玉律"遭遇复杂现实
在实践中,死守"聚合根=一致性边界"的原则,往往会导致四个难以回避的困境,使我们的系统变得脆弱、臃肿且僵化。
1. "不变式"的幻觉:错把策略当真理 传统观点要求聚合根维护其内部的"不变式"(Invariants)。但我们往往错误地将大量易变的业务策略误认为永恒不变的真理,并将其硬编码进聚合根:
"VIP客户下单可透支10000元"------ 这是市场策略,随时可能调整。"新用户首单享受8折优惠"------ 这是营销活动,生命周期短暂且多变。
诚然,优秀的设计师会尝试使用策略模式剥离这些规则,但聚合根依然是那个"决策执行者",其方法签名依然与这些多变的业务流程耦合。而我们追求的是,聚合根完全不关心 这些上层策略。真正需要聚合根誓死守护的核心不变式 其实极少,只有 订单总价 >= 0 或 库存数量 >= 0 这类结构性约束。
2. "上帝聚合"的陷阱:行为与数据的过度捆绑 为了封装所有行为,聚合根被迫承担了本不属于它的职责,迅速膨胀为无所不能的"上帝聚合"。一个Account(账户)聚合根可能同时包含了计息、冻结、风控、费用计算、对账等几十个方法,严重违反了单一职责原则 和开放-封闭原则。
3. 不变式维护的粒度误区:不必要的"问题扩大化" 传统方法强迫我们将大量不相关的规则校验逻辑揉在一个宏大的方法中,导致代码逻辑复杂、高度耦合,难以修改和测试。而一个具体的不变式通常只涉及聚合根内部的一小部分属性。
4. "事务边界"的枷锁:牺牲架构弹性 将事务边界与聚合根操作绑定,在批量处理 (如银行月末计息)和长流程(如贷款审批)场景下,会成为性能瓶颈和架构枷锁,限制了我们自由调配事务策略的能力。
让我们通过一个具体的 Order(订单)聚合根例子来感受这些问题:
Before: 一个典型的"上帝聚合"
这是一个传统的、与MyBatis等持久化框架结合紧密的聚合根。它的行为与数据强耦合,并且直接依赖外部服务。
java
// 传统的Order聚合根,通常也是一个JPA Entity或MyBatis POJO
public class Order {
private Long id;
private List<OrderItem> items;
private Long customerId; // 经常只存ID
private BigDecimal totalPrice;
private OrderStatus status;
// ... 可能还有几十个属性
// 一个巨大的、混合了所有逻辑的方法,依赖外部注入的服务
public void placeOrder(CustomerRepository customerRepo, PromotionService promotionSvc, InventoryService inventorySvc) {
// 1. 校验订单状态
if (this.status != OrderStatus.DRAFT) {
throw new IllegalStateException("...");
}
// 2. 加载关联对象,产生多次DB交互
Customer customer = customerRepo.findById(this.customerId);
// 3. 检查客户信用(策略)
if (customer.isVip() && this.totalPrice > customer.getCreditLimit() + 10000) {
throw new CreditExceededException("...");
}
// 4. 应用促销和优惠券(策略)
BigDecimal finalPrice = promotionSvc.apply(this);
this.totalPrice = finalPrice;
// 5. 检查库存 (外部RPC调用)
inventorySvc.checkStock(this.items);
// 6. ...更多风控、积分等逻辑
// 7. 最终修改状态
this.status = OrderStatus.PENDING_PAYMENT;
// 在Service层保存this对象
}
// ... 其他几十个类似的大方法
}问题分析:
placeOrder方法极其臃肿,职责混杂,包含了校验、风控、营销、库存等一系列不相关的逻辑。- 强依赖多个外部服务(
customerRepo,promotionSvc,inventorySvc),使得聚合根与外部环境紧密耦合。 - 难以进行单元测试,必须模拟所有外部依赖。
- 任何一步逻辑的修改(比如改变风控规则)都可能影响整个方法,违反开闭原则。
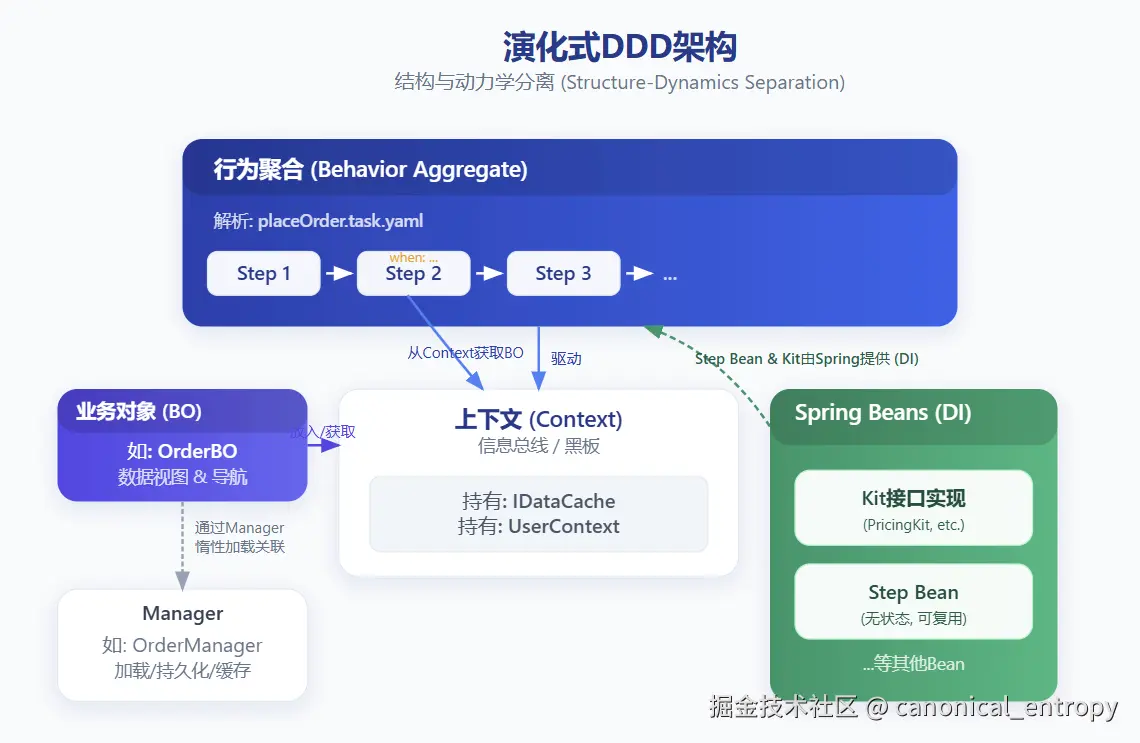
二、 范式转移:从"对象网络"到"信息空间 + 流程编排"
要打破这些桎梏,我们需要的不是修修补补,而是一次范式转移:放弃构建固化的"对象网络",转向生成一个可演化的"结构化信息空间 ",并在此之上进行"流程编排"。
为此,我们引入一套新的核心概念模型,将原有的聚合根职责进行精细化拆分:
核心概念模型
-
数据聚合 (Data Aggregate)
- 职责:成为领域语言最廉价、最直观的载体,构建一张统一的"信息访问地图"。它封装了底层数据实体,并提供了加载关联对象的能力。
- 特征 :仅承载领域结构性数据与最小核心结构不变式(例如:金额不能为负)。它不主动参与任何策略决策,但通过
Manager和Cache机制,高效地为上层逻辑提供完整的、富含业务语义的信息视图。order.getCustomer().getCreditLimit()这样的代码本身就是一句清晰的领域表达。
-
行为聚合 (Behavior Aggregate / Orchestrator)
- 职责:通过流程编排器,将原先聚合根的大方法拆分为一条有序的"步骤链"。
- 特征 :不直接承载领域状态,而是通过编排多个
步骤(Step)来完成业务操作。它可以被动态组合和扩展,以适应不同的业务需求(如租户定制)。
-
流程步骤 (Step)
- 职责:保证一个局部不变式或执行一个单一的业务变换。
- 特征 :输入为共享的
上下文(Context),输出是对聚合数据的局部变换或校验结果。每个Step职责单一,易于单元测试和替换。
-
Kit 接口
- 职责:抽象并封装外部可变的能力,如定价策略、库存检查、风险评分等。
- 特征:通过依赖倒置,将易变的策略从稳定的流程中解耦出去,支持通过表达式、规则引擎或远程服务等多种方式实现。
-
上下文 (Context / Blackboard)
- 职责:在流程执行期间,作为共享的数据载体,传递数据聚合实例、IDataCache引用以及其他辅助信息。
- 特征:避免了方法参数爆炸,并允许在不破坏接口签名的情况下轻松扩展流程所需的信息(如tracingId、幂等键)。
这种**"结构(数据)"与"动力学(流程)"的彻底分离**,是新范式成功的关键。
这种做法类似于函数式编程中的 ADT(代数数据类型)+ 纯函数 模式:
- 数据聚合 ≈ ADT:一个纯粹的、透明的数据结构
- 业务步骤 ≈ 纯函数:一个个接收数据、执行单一职责、内部无状态的逻辑单元
After: 重构后的"下单"流程
以下示例精准地模拟了Nop平台的设计哲学:与Spring深度集成,通过外部化配置实现声明式、可演化的业务流程。
如果直接使用Nop平台会更加简单,可以通过元编程减少更多胶水代码。在不使用Nop平台的情况下,5000行代码大概可以实现一个精简版本。
1. 声明式的流程定义 (YAML配置)
yaml
# === placeOrder.task.yaml (流程定义) ===
# 流程定义被外部化,清晰、可读、易于修改
name: placeOrder
steps:
# 每个step都有明确的name和bean属性,bean指向Spring容器中的Bean ID
- name: creditValidation
bean: validateCreditStep
# 'when' 条件控制步骤是否执行,表达式可以直接访问上下文中的对象和属性
- name: couponApplication
bean: applyCouponStep
# 只有当订单的顾客有关联的优惠券时,此步骤才执行
when: "order.customer.coupons.size() > 0"
- name: promotionApplication
bean: applyPromotionStep
- name: stockChecking
bean: checkStockStep
- name: statusFinalization
bean: finalizeStatusStep2. 业务对象与步骤实现 (Java代码)
java
// 1. 业务对象(BO),封装数据和关联加载逻辑
public class OrderBO {
private final Order data; // 持有底层的POJO/Entity
private final OrderManagerImpl manager;
private final IDataCache cache;
public OrderBO(Order data, OrderManagerImpl manager, IDataCache cache) {
this.data = data;
this.manager = manager;
this.cache = cache;
}
// Getter直接代理到底层data对象
public BigDecimal getTotalPrice() { return data.getTotalPrice(); }
public void setTotalPrice(BigDecimal price) { data.setTotalPrice(price); }
// 关键:关联对象的加载是惰性的,并通过Manager和Cache
public CustomerBO getCustomer() {
// manager负责通过customerId加载,并利用cache避免重复DB查询
return manager.getCustomerOfOrder(this.data, this.cache);
}
}
// 2. 单一职责的步骤,全部实现为可复用的Spring Bean
@Component("validateCreditStep") // 注册为Spring Bean,ID与YAML中对应
public class ValidateCreditStep implements IStep {
public void execute(Context ctx) {
// 直接从上下文获取BO
OrderBO order = (OrderBO) ctx.getAttribute("order");
CustomerBO customer = order.getCustomer(); // 惰性加载
if (customer.isVip() && order.getTotalPrice().compareTo(customer.getCreditLimit().add(new BigDecimal(10000))) > 0) {
throw new CreditExceededException("...");
}
}
}
@Component("applyPromotionStep")
public class ApplyPromotionStep implements IStep {
// Kit/Service等依赖由Spring自动注入,Step本身保持无状态
@Autowired
PricingKit pricingKit;
public void execute(Context ctx) {
OrderBO order = (OrderBO) ctx.getAttribute("order");
BigDecimal newPrice = pricingKit.applyPromotions(order);
order.setTotalPrice(newPrice);
}
}
// ... 其他步骤同样实现为Spring Bean ...3. 框架驱动的行为聚合 (流程编排器)
java
// 开发者完全无需关心流程的执行细节。框架在背后完成了所有魔法。
public class FrameworkEngine {
// (伪代码)
public void executeBizAction(String bizAction, Context ctx) {
// 1. 定位并解析对应的 "placeOrder.task.yaml" 文件。
FlowDefinition flowDef = loadFlowDefinition(bizAction);
// 2. 遍历Steps定义。
for (StepDefinition stepDef : flowDef.getSteps()) {
// 3. 检查 'when' 条件,如果存在且为false,则跳过此步骤。
if (stepDef.hasWhenCondition() && !evaluateWhenCondition(stepDef.getWhen(), ctx)) {
continue;
}
// 4. 从Spring容器中通过bean属性获取step bean实例。
IStep stepInstance = springContext.getBean(stepDef.getBean(), IStep.class);
// 5. 执行步骤。
stepInstance.execute(ctx);
if(ctx.isEnd())
break;
}
// 6. 流程结束后,统一处理持久化。
}
}这套设计的核心优势:
- 极致的声明式:业务流程完全以数据(YAML)的形式存在,业务可读性强。
- 与Spring无缝融合 :充分利用了Spring强大的DI能力,
Step就是一个普通的@Component。 - 职责分离彻底:数据导航、业务能力、流程编排各司其职
- 动态与灵活 :通过
when条件实现动态流程,易于调整和扩展 - 无状态设计:业务步骤保持无状态,易于测试和复用
三、 新范式解锁的核心能力
这种架构变革带来了传统模型难以企及的优势:
1. 拉取式信息流(Pull-based Information Flow) 业务逻辑(Step)通过BO的方法(order.getCustomer().isVip())按需从这张"信息地图"上拉取数据 。这种模式使得组件间彻底解耦,逻辑调整只需修改局部Step或YAML,无需改变整个调用链路。
2. 差量编程(Delta Programming):实现真正的无侵入式扩展 系统的演化不再通过修改源码。当需要定制逻辑时,我们只需提供一个"差量模型(Delta Model) ",声明式地描述对基础模型(数据或行为Step)的修改或替换。这好比为你的架构提供了一个类似Docker镜像叠加的扩展机制 :基础模型是main分支,而每个租户的定制就是一个feature层,系统通过合并这些"差量"来动态生成最终的业务逻辑。这是构建可深度定制PaaS/SaaS平台的关键。
3. 声明式事务管理(Declarative Transaction Management) 事务边界与聚合根解耦,由上层服务(如行为聚合)根据场景声明式地定义。这使得我们能够灵活实现:
- 单笔业务的原子性 :在流程末尾统一
flush()变更。 - 微批处理(Micro-batching) :在批量任务中,每处理N个聚合后调用一次
flush(),兼顾性能与数据一致性。
4. 自由的流程组合(Composable Flow) 基于上下文(Context)的黑板模式,打破了传统方法固定参数签名的限制,使得业务步骤(Step)可以像乐高积木一样被任意组合、替换和重用。
四、 一致性分层:我们到底在守护什么?
新范式并非放弃一致性,而是将其从"大一统"的聚合方法中解放出来,进行更精细的分层管理:
| 层级 | 一致性关注点 | 守护机制 |
|---|---|---|
| 微服务边界 | 跨多个聚合的业务流程最终正确性 | Saga模式 / 领域事件 / 流程引擎 |
| 行为聚合(管线) | 一次业务操作中所有不变式的原子性提交 | 有序的步骤序列 + 最终统一Flush |
| 数据聚合 | 核心结构性不变式(非负、存在性、合法状态迁移) | 内部校验 + 最终结构验证Step |
| 步骤 (Step) | 单一不变式或单一转换的正确执行 | 独立的、可测试的执行单元 |
| 策略/Kit | 可变业务政策的正确应用 | 接口与可插拔的具体实现 |
核心准则 :只有"落库后绝对不能容忍错误"的约束,才属于数据聚合需要守护的强一致不变式。策略的正确性固然重要,但其变化不应迫使核心数据模型频繁改动。
五、 聚合根职责的再定义:两种范式的根本差异
| 对比维度 | 传统DDD范式 | 升级后的演化式DDD范式 |
|---|---|---|
| 理论基础 | 面向对象范式 (Object-Oriented Paradigm) | 可逆计算理论 (Reversible Computation) |
| 核心职责 | 行为容器,一致性与事务的守护者 | 领域语言载体,统一的信息访问地图 |
| 架构隐喻 | 精心设计的对象网络 | 可逆变换生成的结构化信息空间 |
| 数据与行为 | 行为与数据必须合一(封装) | 结构(数据+关联)与动力学(流程)分离 |
| 信息流 | 推送模式(为方法准备专用DTO) | 拉取模式(逻辑按需从信息空间拉取数据) |
| 扩展机制 | 继承、组合(侵入式,需改源码) | 差量编程(非侵入式,通过差量叠加扩展) |
| 事务边界 | 与聚合根操作/UoW强绑定 | 与聚合根解耦 ,由上层服务声明式定义 |
| 组合方式 | 依赖固定的方法签名 | 类似黑板模式,通过通用上下文实现自由组合 |
六、 CQRS架构下的范式融合与聚合根的再诠释
CQRS(Command Query Responsibility Segregation)将系统明确划分为命令端和查询端,这引发了一个深刻的思考:难道在纯查询的场景下,DDD和聚合根就毫无用武之地了吗?
答案显然是否定的。而这正揭示了聚合根概念在架构设计中更深层次、更本质的价值。
1. CQRS对传统聚合根概念的冲击与澄清
在标准的CQRS架构中:
- 命令端 :其核心职责是处理写操作,确保业务规则和一致性。在这里,传统DDD的聚合根严格存在于命令侧。它的职责是在处理命令时,维护聚合内部的业务规则和强一致性。但正如本文所剖析的,它常常会演变为"上帝聚合",成为性能和复杂度的瓶颈。
- 查询端 :其核心职责是高效地返回数据,不涉及业务逻辑的变更。在这里,传统意义上那个作为"一致性守护者"的聚合根确实不应存在。查询端不需要维护不变式,也不需要封装复杂的修改行为,它通常使用为查询特化的数据模型(如DTO、视图模型)。
这一清晰的划分使得"聚合根维护一致性"这一职责的边界变得明确,但也侧面引出了一个更深层次的问题:如果查询端完全摒弃了聚合根的概念,那么我们是否也同时失去了在查询端表达领域语义的能力?
2. 查询端:"数据聚合"作为领域语义载体的复兴
这正是本文核心论点------将聚合的"数据结构"与"行为逻辑"分离 ------的价值所在。在查询端,我们虽然摒弃了作为"行为容器"的聚合根,但可以且应该复兴其作为 "领域语言载体" 的本质,即本文所定义的数据聚合。
-
何为查询端的"数据聚合"? 它不是一个承载行为和执行事务的实体,而是一个富含领域语义的、结构化的数据投影 。它的唯一职责是提供一个面向领域的、便捷的信息访问地图。在代码层面,它实现了与命令端聚合根相同的接口,用于描述领域对象的结构与关系,但其底层实现已针对查询场景进行彻底优化。
-
性能问题的解决之道:统一的接口,差异化的实现 通过
order.getCustomer().getAddress()进行深层次导航是表达领域逻辑的理想方式,但其传统的ORM实现常导致N+1查询问题。 本文所倡导的Manager与IDataCache机制,结合批量加载器 ,正是为此而生。更重要的是,因为业务代码依赖的是"数据聚合"的接口,而非具体实现,我们可以在查询端注入一个完全不同的、高度优化的实现。- 批量加载:在一个请求周期内,框架可以拦截所有对关联数据的访问,将其合并为一次高效的批量查询。
- 实现切换 :以Nop平台为例,其ORM底层可以灵活切换
Driver实现。对于复杂查询,可以切换到使用定制SQL或NoSQL的驱动,通过一次查询完成所有数据的加载与组装,从而在保持上层领域代码纯净的同时,彻底解决性能瓶颈。
3. 统一的领域语义,差异化的架构实现
因此,在CQRS架构下,我们可以这样实践本文的范式:
- 命令端 :采用行为聚合 范式。通过
Orchestrator和Step来编排一个写操作。这些Step消费和修改的是数据聚合(作为状态载体)的状态,并在流程末尾统一持久化。 - 查询端 :直接使用数据聚合。利用其强大的、声明式的关联定义,由框架提供高度优化的实现,构建出完全符合领域Ubiquitous Language的查询模型。
结论
CQRS的提出,非但没有否定DDD的价值,反而通过职责的物理分离 ,让我们更清晰地看到了聚合概念的两面性,并与本文的范式革新高度契合,相辅相成:
- 在命令端,"行为聚合"(流程编排) 超越了传统的聚合根,更灵活地管理了复杂性。
- 在查询端,"数据聚合"(领域语义载体) 摆脱了行为枷锁和性能桎梏,纯粹地服务于领域信息的表达与传递。
它告诉我们,无论架构如何演变,DDD的核心------通过领域模型来捕获和表达业务复杂性------永远不会过时。聚合的核心价值,远不止于维护一致性,它更是我们与业务专家沟通的通用语言在代码中的直接体现,而实现这一价值的关键,恰恰在于将"结构"与"行为"解耦。
七、 工程实践:并发、迁移与风险控制
行为的发现性与统一调用模型 (Behavior Discoverability & Unified Invocation Model)
一个核心的实践问题是:当数据与行为分离后,开发者如何直观地发现并调用与特定业务对象相关的操作?传统的面向对象方法通过查看类的方法列表来解决,而我们的新范式通过一个模型驱动的动态组装机制来提供更强大的解决方案。在Nop平台中,这个模型是这样实现的:
-
统一的REST API入口 : 平台提供一个标准的RESTful API入口,其格式为
/r/{bizObjName}__{bizAction}。这个URL结构本身就是一种强有力的"可发现"机制。{bizObjName}:业务对象的唯一标识名,如CmsArticle、OmsOrder等。{bizAction}:在该业务对象上执行的具体动作名,如publish、cancel、refund等。
-
动态的行为组装与分派 (Dynamic Behavior Assembly & Dispatch) 框架并非通过一个庞大的
switch来分派逻辑。恰恰相反,它在运行时或启动时动态地组装一个业务对象的全部行为:-
行为切片 (Behavior Slices) :框架会自动扫描所有与
OmsOrder相关的"行为切片"。这些切片可以来自基础平台、行业解决方案包、甚至特定租户的定制模块,形式可以是Java类(BizModel)或XDSL模型文件(.xbiz)。 -
叠加与覆盖 (Overlay & Override) :框架将收集到的所有行为切片,按照预设的优先级 进行"叠加"。这就像一个为业务逻辑设计的"PhotoShop图层 ":高优先级的定义(如租户定制的
refund行为)会自动覆盖低优先级的同名行为(如平台基础的refund行为),而XBiz模型文件中的定义拥有最高优先级。 -
生成动态分派器 :叠加完成后,框架会在内存中为每个
IBizObject生成一个高效的行为分派映射表 (例如Map<String, IBizAction>)。当invoke方法调用时,仅需一次 O(1) 复杂度的查表即可执行对应的逻辑(如一个TaskFlow流程)。
-
这个模型的颠覆性优势在于:
- 实现了真正的无侵入式扩展 :当需要为订单增加新行为,或为特定租户修改现有行为时,我们无需修改任何已有的Java代码。只需增加一个新的"差量"模型文件,系统就会自动发现并"织入"新逻辑。
- 完美支撑了差量编程:它正是文章核心思想"差量编程"的落地实现。每个切片就是一个"差量(Delta)",描述了对基础模型的增量修改。
- 消除了僵化的分派逻辑 :彻底告别了需要手动维护的
switch-case,让行为的注册与发现变得自动化和声明化。
事务与并发策略
- 写入原子性 :一条业务流程(如
placeOrder)的执行对应一次事务提交。所有变更先在IDataCache中累积,最后统一flush,减少数据库锁持有时间。 - 乐观并发 :在
flush前检查并增加version版本号。若发生冲突,可安全地重放整个行为管线(要求步骤设计为幂等或纯粹的变换)。
迁移路径建议(增量演进)
- 分类:盘点现有聚合方法,标记出"结构性不变式"与"策略/流程逻辑"。
- 提取 :将策略代码提取到
Kit接口(Spring Bean)。 - 切分 :将大方法内部逻辑切分为独立的
Step对象(Spring Bean)。 - 配置化 :创建
task.yaml文件,将Step的调用顺序配置化。 - 替换:引入框架的统一调用入口,替换旧的服务层大方法。
- 扩展 :通过"差量编程"为特定租户或场景注入或替换
步骤。
常见陷阱与规避
| 陷阱 | 规避策略 |
|---|---|
| 过度拆分步骤 | 一个步骤应具备清晰的领域可命名性,避免微碎粒度。 |
| 上帝Kit接口 | 按能力域拆分Kit,如PricingKit, InventoryKit, RiskKit。 |
| 重试不幂等 | 将变化的输入(如当前时间)捕获到Context中,保证重试时输入不变。 |
| 性能退化 | 对拉取式深链访问,使用**批加载器(Batch Loader)**机制。它能将单个请求周期内所有对同类关联数据的访问合并成一次批量查询(如IN (?)),有效解决N+1查询问题。此机制可内聚在Manager层。 |
结论:让聚合根走出事务的囚笼,成为语言的使能者
让我们再次审视开篇的问题:聚合根最重要的职责是什么?
-
传统DDD回答 :维护一致性边界。这个答案让聚合根成为了一个行为的容器,一个事务的囚徒,一个在复杂性面前步履蹒跚的巨人。
-
新范式回答 :成为领域语言的载体 。这个答案让
数据聚合成为一张信息地图,一个自由的表达者;让行为聚合成为一个灵活的编排者,一个架构的赋能者。
DDD 的原始模型(2003 年提出)诞生于单体、事务性、业务相对稳定的年代,面对云原生、多租户、高定制化的新时代,需要新的抽象层次。
聚合根的首要职责,或许从来就不是"维护一致性",而是"表达领域语义"。一致性只是实现语义正确性的一种手段,而非目的本身。
聚合根的核心使命,不应是确保"下单"在一个事务内完成,而应是让order.customer.creditLimit这样的业务表达在代码中自然、无成本地存在。当我们基于可逆计算 的思想,通过差量编程 和拉取式信息流解放了聚合根,我们就为构建真正能够与业务同频演化、灵活适应未来的软件系统,打开了一扇全新的大门。
这不仅是技术的突破,更是软件设计哲学的一次深刻跃迁。
参考资料
- 可逆计算:下一代软件构造理论:对可逆计算理论的概要介绍,阐述了其基本原理、核心公式,以及与图灵机、Lambda演算这两种传统计算世界观的区别,定位为第三条通向图灵完备的技术路线。
- DDD本质论之理论篇: 结合(广义)可逆计算理论,从哲学、数学到工程层面,系统性地剖析了DDD(领域驱动设计)的技术内核,认为其有效性背后存在着数学必然性。
- DDD本质论之实践篇:作为理论篇的续篇,重点介绍了Nop平台如何将可逆计算理论应用于DDD的工程实践,将DDD的战略与战术设计有效地落实到代码和架构中,从而降低实践门槛。
- DDD本质认知的演进:从实践框架到构造理论: 通过AI辅助的思想实验,对比了传统的DDD概念框架与《DDD本质论》中从第一性原理(空间、时间、坐标系、差量)出发的推导路径,揭示了后者更深刻的内在逻辑。
- 广义可逆计算: 一个软件构造范式的正名与阐释:为"广义可逆计算"(GRC)正名,阐释了其核心思想------以"差量"(Delta)为第一类公民,系统性地管理软件构造过程中的可逆性与不可逆性,旨在解决"复杂性"这一核心工程难题。