目录
推算出EXT2文件系统的i_block最多能存储的数据块的个数
[inode bitmap](#inode bitmap)
[block bitmap](#block bitmap)
[Group Descriptors](#Group Descriptors)
[★Super Block](#★Super Block)
[3.问题: 文件的增删改查,系统做了什么?](#3.问题: 文件的增删改查,系统做了什么?)
1.知识回顾
2.EXT2文件系统
上篇文章讲了i_block数组的三个级别的索引
推算出EXT2文件系统的i_block最多能存储的数据块的个数
-
i_block0~i_block12→13个数据块
-
i_block13,假设其指向存储数据块号的表能存N个元素→N*1==N个数据块
-
i_block14,假设指针表能存储M个指针,每个指针又指向能存储P个元素的存储数据块号的表→M*P个数据块
所以最多能存储13+N+M*P 个数据块,假设每个数据块的大小为K,得出EXT2允许一个文件的最大的大小为**(13+N+M*P)*K**
每个数据块的大小是可以手动设置的
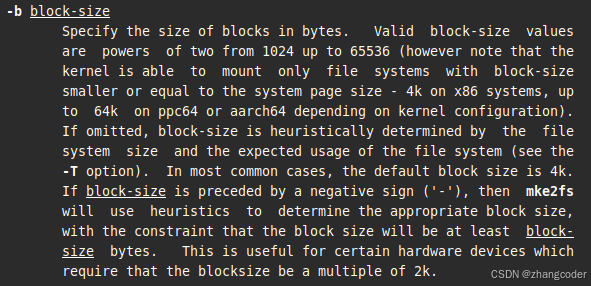
具体每个数据块的大小可以使用-b选项设置,但注意: 每个数据块的大小必须是2的次方数,例如1024字节、2048字节、4096字节......
8号手册中mke2fs中-b选项的说明: 手册中明确指出每个数据块的大小必须是2的次方数
inode bitmap
inode bitmap记录哪些inode已经使用,哪些inode没有使用,即将比特位的位置和inode编号映射起来,那么可以快速查询哪些inode编号没有用过,从而分配给文件使用
block bitmap
从inode bitmap同理可得block bitmap的作用,这里再赘述
删除一个文件需不需要将存储文件内容的数据块都清空呢?
答: 没有必要,为了提高EXT2文件系统的工作效率,只需要修改inode bitmap和block bitmap,将该文件对应的位置都清空即可
除此之外,如果用户误删文件,可以使用恢复软件,恢复软件可以通过读Linux日志来得出被删除文件的inode编号,之后恢复inode bitmap,接着在inode table找到inode结构体,再找到blocks数组,然后修改block bitmap,由于被删除文件的数据块没有清空,那么恢复软件可以通过读文件块来恢复用户误删的文件
"分区"满的含义
分别设想inode编号和数据块用完的情况
一个分区所用的inode的总数是固定的,这个在格式化时就已经确定
1.如果inode编号用完了,但数据块还有,那么剩下的这些数据块是能存储文件内容的,虽然不能新建文件,但是可以对现有文件增加文件内容
2.如果数据块用完了,而inode编号还有,那么剩下的这些inode编号是不能分配给新建文件的
3.如果inode编号和数据块都恰好用完,那么显然分区是不能存储文件的
在https://unix.stackexchange.com/questions/26598/how-can-i-increase-the-number-of-inodes-in-an-ext4-filesystem中被采纳回答的评论也提到了:

Group Descriptors
组描述符Group Descriptor,缩写是GDT(注意全局描述符表Global Descriptior Table的缩写也是GDT),其记录每个块组的信息
每个块组(block group)都有组描述符,存储inode表的指针、数据块的指针、inode和数据块分配位图的指针
★Super Block
超级块Super Block: 存储文件系统的基本信息,包含的是整个分区的使用情况,例如一共有多少个组、每个组的大小、每个组inode的数量、每个组的block数量、每个组的起始inode
、文件系统的类型与名称等等,注: 超级块的所有信息将在下一篇的实验中讲
不是每个块组都有超级块,这个也在下一篇的实验中讲
由此得知: 超级块很重要,如果超级块损坏了,会影响所有组的边界,进而导致磁盘的所有分区无法识别,因此必须备份超级块,这样在某些情况下可以修复文件系统
超级块的分类
主超级块
即0号块组的超级块,紧邻着启动块
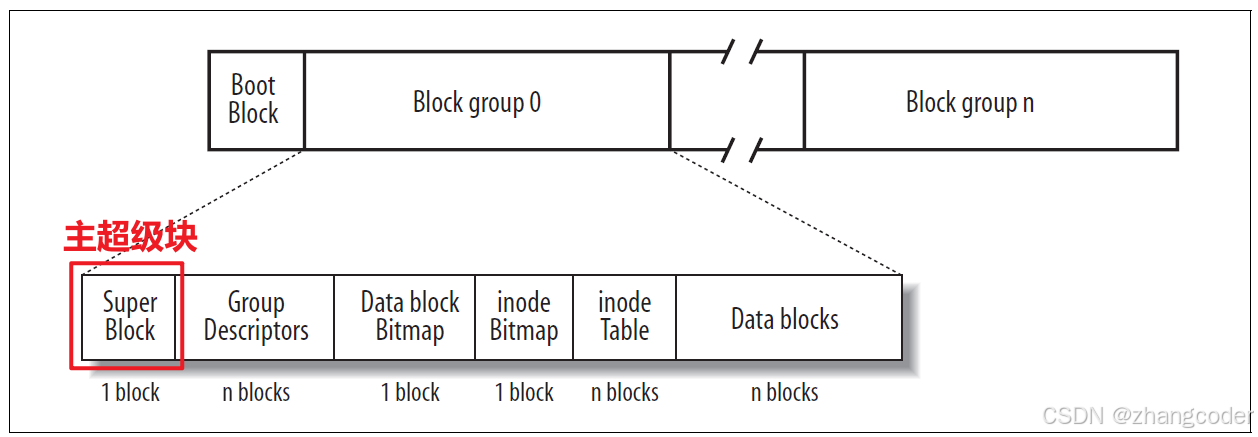
备份超级块
分布在文件系统的各个块组(Block group)中,但不是每个块组都有备份的超级块,这个会在下一篇文章的实验中说明
结论
每一个分区在被使用之前,都必须提前先将部分文件系统的属性信息提前设置进对应的分区中,方便后续使用这个分区或者分组,这叫先描述再组织
3.问题: 文件的增删改查,系统做了什么?
新建文件
新建文件在表面上是在某一个路径下新建
但其内部操作比较复杂: 一个存储设备可能分成了很多分区,而且文件不能跨分区存储,
因为每个分区可以有自己的文件系统,而文件系统中的inode和文件数据块是存储在同一个文件系统内的,也就存储在同一个分区中,因此不能跨文件系统存储
1.在将文件存储到设备中需要指定设备上的某一个分区
2.需要为新的文件分配inode,但一个文件系统的inode编号是有限的,因此需要先确保inode编号是否充足
确保inode编号是否充足需要查组描述符,Linux内核的/fs/ext2.h中是这样写的:
cpp
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap block */
__le32 bg_inode_table; /* Inodes table block */
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
};其中bg_free_inodes_count表示空闲的inode编号的个数
如果组描述符中inode还多着,那么就分配指定分区中的inode
3.查inode bitmap,找最近没有使用的inode编号
ext2_group_desc结构体中有bg_inode_bitmap
4.在inode table中找到对应的inode结构体,填写文件属性
5.分析block bitmap,找对应的data block,写入文件内容
删除文件
本文上方说明过:删除一个文件不需要将存储文件内容的数据块都清空,即不需要清空存储文件内容的数据块
1.找到删除文件对应的inode 分析文件属性
2.根据所处目录找到文件存储的分区
3.根据inode所处的范围确定是哪个分组的,再索引block bitmap清空文件对应的块号,即从1置为0
3.再索引inode bitmap,将对应的比特位从1置为0
结论
因为删除文件即将这个文件和对应的数据块解除绑定,可能在新建其他文件或修改其他文件时会用到删除文件对应的数据块,那么++文件系统认为该删除的文件的数据块的空间被腾出来了删除,即允许被覆盖++
查找文件
查找一个目录中的某个文件的前提是: 这个目录是可读的,如果找到某个文件和其inode的映射关系,就可以读取文件内容
例如cat test.txt: 拿到inode找到对应的分区,根据inode确定分组,拿inode到inode bitmap确认是0还是1,是1再拿inode table对应的结构体数据,找到对应的data block
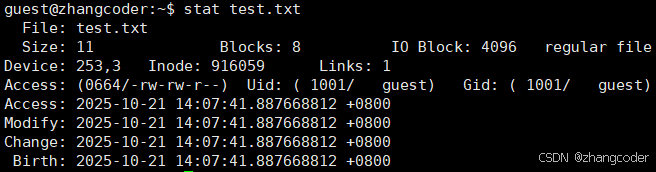
使用stat命令查看文件的元数据
例如:
bash
stat test.txt可以查到该文件的inode编号
修改文件
和上面类似,不再赘述
4.如何知道一个文件的inode编号
删除、查找、修改文件需要指定文件的inode编号,但使用者从来没关心过inode,用的是文件名
5.如何理解目录?
由于Linux的"一切皆文件"的设计思想,那么目录也是文件 ,文件=内容+属性,因此目录有自己的inode,有自己的属性,有自己的数据块......
目录的数据块的内容
目录的数据块存放++该目录下文件的文件名和对应文件的inode的映射关系++,即key-value结构
由于key-value结构的特殊性,之前在map中讲过,key一定是唯一的,那么同一个目录下不能有同名文件
Linux内核的/fs/ext2/ext2.h中给出了存储文件名的结构体:
cpp
/*
* Structure of a directory entry
*/
struct ext2_dir_entry {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__le16 name_len; /* Name length */
char name[]; /* File name, up to EXT2_NAME_LEN */
};
/*
* The new version of the directory entry. Since EXT2 structures are
* stored in intel byte order, and the name_len field could never be
* bigger than 255 chars, it's safe to reclaim the extra byte for the
* file_type field.
*/
struct ext2_dir_entry_2 {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[]; /* File name, up to EXT2_NAME_LEN */
};结论: 一个目录包含很多目录项结构体(ext2_dir_entry,新版是ext2_dir_entry_2),而目录项结构体存储着文件名
回顾目录的rwx权限
之前在OS9.【Linux】基本权限(下)文章提到过目录的rwx权限
- 如果目录没有可执行权限, 则无法cd到目录中→不让更新当前所处目录cwd软链接,无进入的权限(注: 切换目录并没有访问目录中的文件)
进入一个目录的本质: 进程修改自己的cwd软链接
如果目录没有可读权限, 则无法用ls等命令查看目录中的文件内容→无法找到目标文件的inode
可写权限w: 如果目录没有可写权限, 则无法在目录中创建、更改或删除文件→就算能创建文件名和inode的映射关系,但不能写到目录文件
一个文件是否能被删除,不由文件本身决定,而由其所处的目录决定
目录的inode编号怎么找?
上面提到了目录也是文件,那么目录有自己的inode编号,只有先获取到了目录自己的inode编号才能访问目录中的文件
使用递归,大目录里面有小目录,因此找目录的inode需找上一级的目录的inode
那么向上一直找,最终会找到根目录/,根目录inode编号是确定的
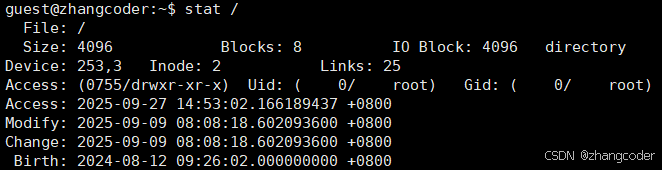
我服务器上根目录的inode编号:
我Linux mint电脑上的根目录的inode编号:
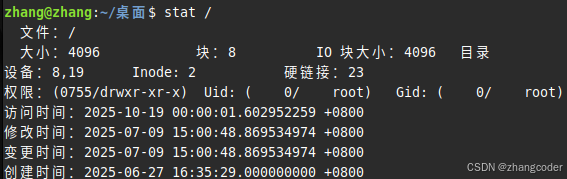
我ext2文件系统、单分区U盘上的根目录的inode编号:
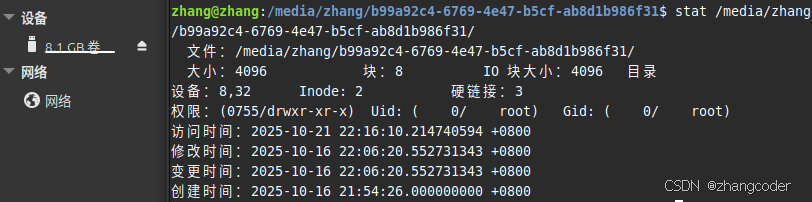
结论: EXT类文件系统的根目录的inode编号是固定的,为2
用相对路径访问文件时底层的处理方法
使用相对路径可以简化命令,例如cat ./myfile/test.txt
当前目录中的文件可以不写绝对路径,但系统底层是需要完整的路径的,即绝对路径,上面讲过了
EXT2文件系统解决文件访问过慢的问题
系统底层访问文件是从根目录开始的,设想一下如果文件路径过长,那么会导致文件访问速度过慢的问题
EXT2文件系统解决方法: 使用缓存
在Louis-Dominique Dubeau所著的Analysis of the Ext2fs structure文章中有提到
Linux ext2fs manager caches access to the inodes and blocks bitmaps. This cache is a list of buffers ordered from the most recently used to the last recently used buffer. Managers should use the same kind of bitmap caching or other similar method of improving access time to disk.
可以看到使用了LRU(the L ast R ecently Used)缓存算法
可以看看https://baike.baidu.com/item/dentry/6715475对目录项缓存的描述
目录项缓存(dcache)通过dentry_hashtable哈希表和dentry_unused链表维护,属于slab缓存机制,保存在全局变量dentry_cache中 2 4。该缓存减少了文件路径遍历层级,加速文件查找过程 5-6。dentry_operations结构定义d_revalidate、d_hash等操作方法,其父子关系通过d_parent和d_child指针实现层级遍历 1-2。
5.参考资料
1.NMU大学的课程笔记https://euclid.nmu.edu/~rappleto/Classes/CS426/Notes/FileSystems/EXT2/
1.EXT2文件系统作者的论文Design and Implementation of the Second Extended Filesystem
- 张书宁老师的《文件系统技术内幕:大数据时代海量数据存储之道》
3.高剑林老师的《Linux内核探秘 深入解析文件系统和设备驱动的架构与设计》