Markdown 因其简洁、易读易写等特性,已成为当今最流行的轻量级标记语言。在 2014 年之前,由于缺乏明确的规范,各种实现方式差异巨大,同一文档在不同系统上的呈现方式有明显不同。2014 年 CommonMark 规范出现,提出了一套标准、明确的语法规范,并提供了一套全面的测试用于验证 Markdown 的实现是否符合该规范,为 Markdown 的标准化奠定了坚实基础。cmark 作为其参考实现,展现了现代解析器设计的精髓。
Markdown 的简洁语法背后隐藏着复杂而精妙的解析机制。本文将深入探讨 CommonMark 的核心解析策略------两阶段解析机制,从理论层面剖析块结构解析与内联元素处理的设计,并结合 cmark 工程的源码实现,揭示这一架构背后的技术细节。以最终形成对 CommonMark 解析器完整而深刻的理解。
一、CommonMark 解析策略
1. 解析阶段概述
CommonMark 的核心解析策略可以概括为一个精巧的两阶段过程。在第一阶段,解析器专注于构建文档的宏观结构,它逐行扫描文本,识别出段落、标题、列表等块级元素,并构建起一个树状的文档骨架。在第二阶段,解析器会遍历第一阶段生成的块结构,深入每个块的内部,将原始文本解析成具体的内联元素序列,如粗体、斜体、链接和图片等。以下为两阶段解析策略示意:
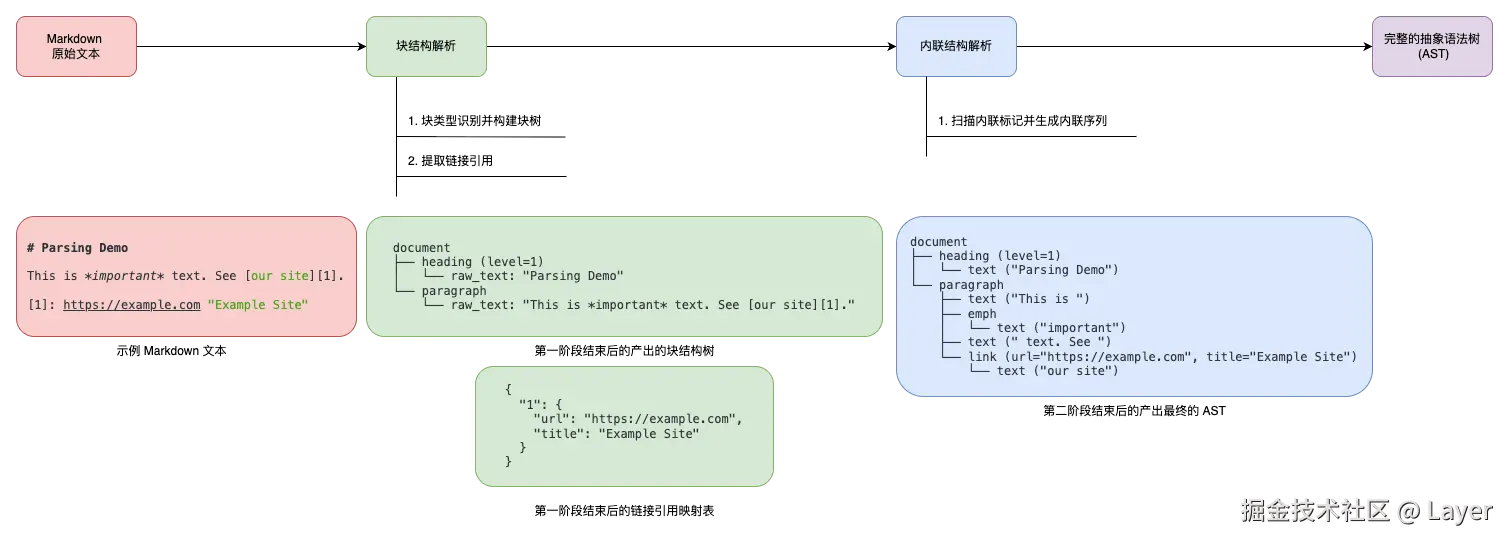
这种两阶段的设计不仅降低了语法的复杂性,也使得整个解析过程更加健壮和可预测。两阶段的关键步骤如下:
- 第一阶段:块结构解析
- 构建文档块结构:
- 逐行消费输入内容(为了确保跨平台兼容性,CommonMark 将换行符
\n、回车符\r、回车+换行 CRLF\r\n都视作行尾) - 将文档划分为不同的块类型,包括标题、段落、列表、块引用、代码块、HTML 块、分割线、链接引用定义等
- 构建块的树状层次结构,标题、段落、代码块是叶子块(不能包含其他块级元素,只能包含 行内元素),列表、块引用是容器块(可以包含其他块级元素)
- 逐行消费输入内容(为了确保跨平台兼容性,CommonMark 将换行符
- 文本分配但不解析:
- 将原始文本内容分配给相应的块,此时不对文本内容进行内联元素解析,保持文本的原始状态
- 链接引用定义处理:
- 识别和解析链接引用定义(如
[label]: url "title"),构建链接引用映射表,为第二阶段的链接解析做准备
- 识别和解析链接引用定义(如
- 构建文档块结构:
- 第二阶段:内联结构解析
- 内联元素解析:
- 处理直接包含原始文本的块(标题和段落)、可以包含其他块的块(列表项、块引用)中的原始文本内容
- 从左到右扫描文本,根据它在当前位置遇到的字符来决定解析为具体的内联元素序列。包括使用第一阶段构建的链接引用映射来解析引用式及其他内联元素类型(普通文本、强调、重强调、链接、图片、行内代码、行内 HTML、硬换行、软换行、自定义内联元素)
- 内联元素解析:
为什么第一阶段要解析链接引用定义?
- 全局性质的处理:链接引用定义具有全局作用域特性
markdown这是一个[示例链接][ref1]。 ... (很多其他内容) ... [ref1]: https://example.com "示例标题"定义可以出现在文档的任何位置、引用可以在定义之前使用、一个定义可以被多次引用。这种全局性质要求在处理任何内联链接之前,先扫描整个文档收集所有定义。在第二阶段解析内联元素时,遇到
[示例链接][ref1]需要知道ref1指向哪个URL。如果不在第一阶段预先解析链接定义,就无法正确解析引用式链接。 2. 性能优化考虑:避免重复扫描。如果在第二阶段才解析链接定义,每次遇到引用链接都需要扫描整个文档。第一阶段预先构建链接映射表,第二阶段只需要查表即可。大大提高了解析效率,特别是对于包含大量链接的文档。
- 流式处理的支持:链接定义是"一旦一行以这种方式被合并到树中,它就可以被丢弃,所以输入可以以流的形式读取。"的例外,因为它们需要被保存到映射表中供后续使用。第一阶段统一处理这些全局信息,使得其他内容可以被流式处理。
2. 文档的块树表示
在处理的每个阶段,文档都表示为一个块树。树的根是一个文档块。文档可以有任意数量的其他块作为子块。这些子块又可以有其他块作为子块。块的最后一个子块通常被认为是开放的,这意味着后续的输入行可以改变其内容。例如,这是一个可能的文档和文档树:
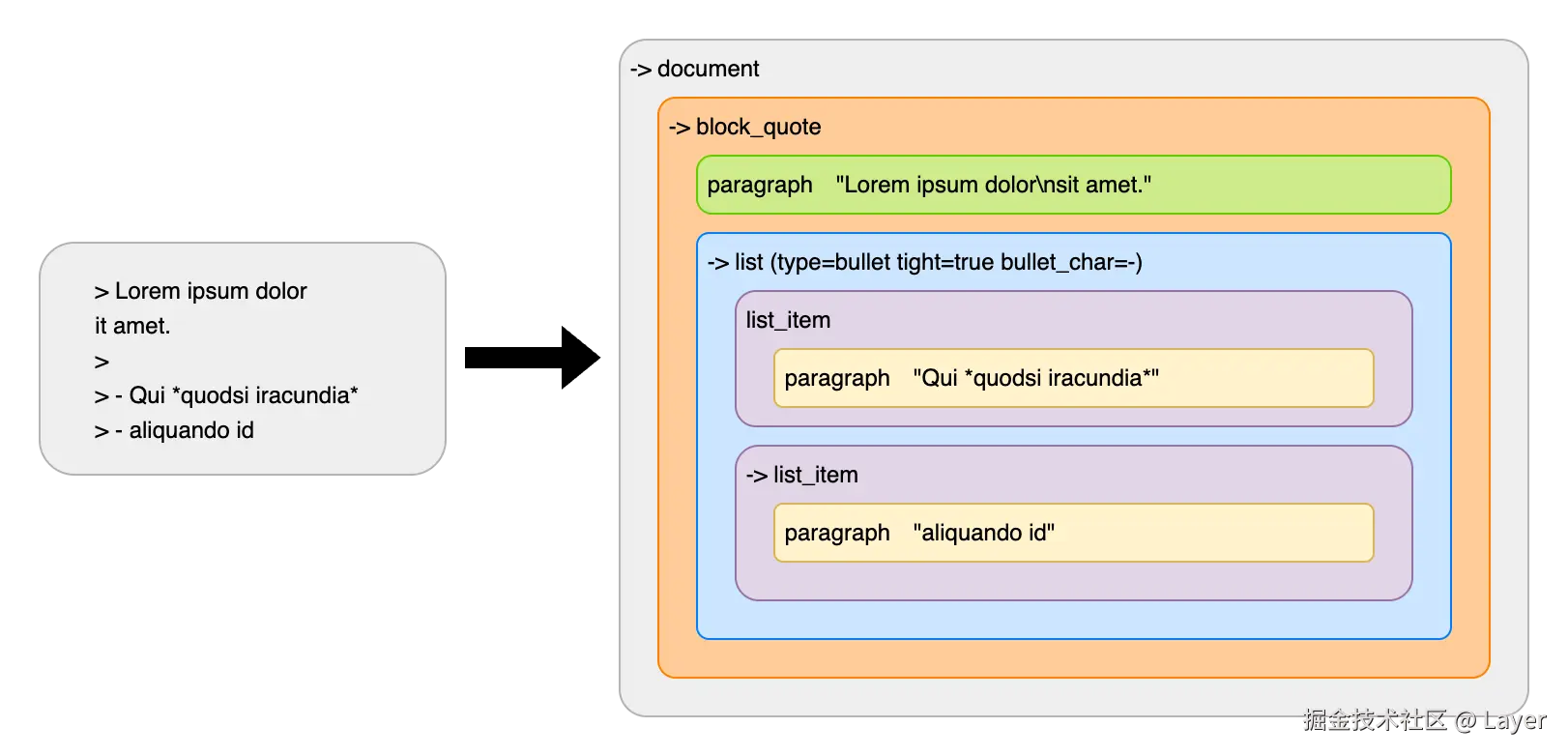
在上述文档树中:
- 符号含义:
->:表示该块是开放状态 ,可以接受后续输入行的修改- 无箭头:表示该块是 关闭状态 ,内容已经确定
document(文档根节点):整个文档的根容器,始终开放,可以添加新的顶级块block_quote(块引用):由>字符标记的块引用,当前开放,可以继续添加内容,包含一个段落和一个列表paragraph(段落):已关闭的段落,包含换行符,表示原本是两行,文本第二行是懒惰延续(Lazy Continuation),被合并到同一段落list(列表):类型属性type=bullet表示无序列表(项目符号列表)、tight=true表示紧凑列表(列表项之间没有空行)、bullet_char=-表示使用-作为项目符号,当前是开放的,可以添加新的列表项ist_item(列表项):有两个列表项,第一个列表项 已关闭,第二个列表项可以继续接受内容
懒惰延续:当一行文本没有提供完整的块延续标记时,但仍然可以被视为现有开放块的延续内容。这个机制使得 Markdown 的编写更加自然和灵活,同时保持了解析的准确性。
markdown> Lorem ipsum dolor sit amet.在这个例子中,第一行
> Lorem ipsum dolor创建了一个块引用和段落,第二行sit amet.没有>标记,但仍然被添加到段落中。
3. 第一阶段:块结构解析
3.1 块结构解析流程概览
处理的每一行都会对这个树产生影响,文档可能又以下一种或多种方式被改变:
-
一个或多个开放块可能被关闭。当新行不满足某些开放块的延续条件时,这些块会被关闭
- 引用块需要
>字符、列表项需要适当的缩进、代码块需要围栏标记或缩进
- 引用块需要
-
一个或多个新块可能作为最后一个开放块的子块被创建。当检测到新的块开始标记时
- 新的块引用(
>)、新的列表项(-,*,+或数字)、新的标题(#或下划线)、新的代码块(围栏或缩进)
- 新的块引用(
-
文本可能被添加到树上剩余的最后(最深)开放块中
- "最后"的指的是经过块匹配检查后仍然保持开放状态的最后一个块,是按照解析顺序确定的最后一个开放块
- 通常情况下,最后的开放块也是最深的,但在某些情况下可能不是绝对最深的
markdown- A paragraph. ---在这个例子中,遇到
---前, "最后"、"最深"的开放块是段落,因为---无法放入段落,导致段落被关闭。解析器的上下文"回溯"了一层, "最后" 的开放块变成了列表项。此时, 列表项是"最后"的,它比刚刚被关闭的段落块要"浅"一层。 -
一旦一行以这种方式被合并到树中,它就可以被丢弃,因此输入可以以流的形式读取
3.2 解析器的逐行处理机制
对于每一行,解析器遵循以下流程:
-
匹配现有结构:检查开放块的匹配条件。从根文档开始,递归遍历到最后的开放块,检查每个块是否满足保持开放的条件(即使某些块不匹配,也不会立即关闭它们,因为可能存在懒惰延续)。只有当外层的块符合条件时,才会继续向内深入,检查更深层的块。如果匹配链条在任何一级中断,并且"懒惰延续"也不适用,那么就进入第二步
-
段落:需要非空行
-
块引用:需要
>字符 -
列表项:需要适当的缩进 因为第二行
包含多行文字。有缩进,所以解析器知道它不是一个新的列表项,而是第一项内容的延续:markdown- 这是一个列表项, 它包含多行文字。 -
代码块:需要围栏标记或缩进 围栏代码块是使用三个反引号或波浪线将代码包裹起来。缩进代码块是任何以四个空格或一个制表符(Tab)开头的行,就会被识别为缩进代码块的一部分:
markdown这是一个普通段落。 def hello(): print("Hello, indented code!") 这也是一个普通段落。在上面的例子中,只要
def hello():和print(...)这两行前面有至少 4 个空格,它们就会被渲染成一个代码块。完全不需要任何反引号。现代 Markdown 用户和解析器更倾向于使用围栏代码块,更明确、功能更强大、更不容易出错。但为了兼容旧的 Markdown 文档,解析器必须同时支持这两种形式。
-
-
关闭旧有结构 :既然新的一行无法融入现有的结构,那就说明旧的结构已经结束了。解析器会执行"关闭"操作。它会从第一个匹配失败的块开始, 关闭该块及其包含的所有内部块。寻找新块开始。在这个阶段,解析器会进行一些"收尾工作"。最重要的一项是,在关闭一个段落块时,它会最后一次检查该段落的内容,看它是否符合链接引用定义(如
[label]: url)的格式。如果是,就将其解析为链接定义,而不是普通段落 -
开启全新结构:在清理完所有过时的旧结构后,解析器会用一个全新的视角来审视当前这行文本,尝试用它来开启一个新的块。解析器会按照一个 固定的优先级列表 ,来判断这行文本属于哪一种新的块类型。这个列表是:分割线 -> ATX 标题 -> 围栏代码块 -> HTML 块 -> Setext 标题 -> 块引用 -> 列表 -> 缩进代码块。如果该行匹配了其中任何一种块类型,解析器就会创建一个对应的新块,并将其添加到文档结构中。如果该行不符合任何已知的块类型特征 ,它将被视为最普通、也是优先级最低的新段落。
3.3 块结构解析复杂示例
markdown
> # 这是一个标题
>
> 这是第一段文字,包含**粗体**和*斜体*。
这行没有 > 标记,是懒惰延续。
>
> - 第一个列表项
这行没有 > 和缩进,但仍是列表项的懒惰延续
> - 第二个列表项
> - 嵌套列表项 1
这行缺少 > 但有缩进,是嵌套项的懒惰延续
> - 嵌套列表项 2
> \`\`\`python
def hello():
print("Hello World")
\`\`\`
>
最后一段没有任何标记,懒惰延续只能"延续"一个当前已经开放的段落。初始状态:
diff
-> document第1行:> # 这是一个标题,正常块引用 + 标题创建:
rust
-> document
-> block_quote
-> heading (level=1)
"这是一个标题"第2行:> 空行,标题关闭
第3行: > 这是第一段文字,包含**粗体**和*斜体*。 正常段落创建:
rust
-> document
-> block_quote
heading (level=1)
"这是一个标题"
-> paragraph
"这是第一段文字,包含**粗体**和*斜体*。"第4行: 这行没有>标记,是懒惰延续。:
-
检查开放块:
document: 匹配block_quote: 不匹配 (缺少>)- 由于常规匹配失败,解析器并不会立即关闭块 ,而是检查是否能启用"懒惰延续"这一特殊规则
-
懒惰延续判断:
-
检查内部:当前最内层的开放块是段落吗?是
-
检查新行:新的一行本身是否开启了一个更高优先级的块(如标题、列表等)?否
-
文本添加到段落(懒惰延续成功)
-
rust
-> document
-> block_quote
heading (level=1)
"这是一个标题"
-> paragraph
"这是第一段文字,包含**粗体**和*斜体*。\n这行没有>标记,是懒惰延续。"第5行:>,空行处理
第6行:> - 第一个列表项,段落关闭,列表创建
rust
-> document
-> block_quote
heading (level=1)
"这是一个标题"
paragraph
"这是第一段文字,包含**粗体**和*斜体*。\n这行没有>标记,是懒惰延续。"
-> list (type=bullet)
-> list_item
-> paragraph
"第一个列表项"第7行:这行没有 > 和缩进,但仍是列表项的懒惰延续:
- 检查开放块:
document:匹配block_quote: 不匹配 (缺少>),- 由于常规匹配失败,解析器并不会立即关闭块 ,要继续检查所有层级,是否能启用"懒惰延续"这一规则
list:不匹配 (缺少>和适当缩进)list_item: 不匹配 (缺少缩进)paragraph:匹配(非空行)
- 懒惰延续判断:
- 检查内部:当前最内层的开放块是段落吗?是
- 检查新行:新的一行本身是否开启了一个更高优先级的块(如标题、列表等)?否
- 文本添加到段落(懒惰延续成功)
rust
-> document
-> block_quote
heading (level=1)
"这是一个标题"
paragraph
"这是第一段文字,包含**粗体**和*斜体*。\n这行没有>标记,是懒惰延续。"
-> list (type=bullet)
-> list_item
-> paragraph
"第一个列表项\n这行没有 > 和缩进,但仍是列表项的懒惰延续"继续处理其他行...
最后一行:最后一段没有任何标记,懒惰延续只能"延续"一个当前已经开放的段落。,这行完全没有任何容器标记,且懒惰延续只能延续一个当前已经开放的段落,最终结果是块引用后面跟着一个完全独立的段落。
swift
document
block_quote
heading (level=1)
"这是一个标题"
paragraph
"这是第一段文字,包含**粗体**和*斜体*。\n这行没有>标记,是懒惰延续。"
list (type=bullet tight=false bullet_char=-)
list_item
paragraph
"第一个列表项\n这行没有>和缩进,但仍是列表项的懒惰延续"
list_item
paragraph
"第二个列表项"
list (type=bullet tight=false bullet_char=-)
list_item
paragraph
"嵌套列表项 1\n这行缺少>但有缩进,是嵌套项的懒惰延续"
list_item
paragraph
"嵌套列表项 2"
code_block (info="python")
"def hello():\n print(\"Hello World\")"
paragraph
"最后一段没有任何标记,懒惰延续只能"延续"一个当前已经开放的段落。"3.4 块结构解析特殊示例
3.4.1 Setext 标题的形成
解析器在读取 Markdown 文档时,是一行一行处理的。当它读到几行连续的文本时,它会暂时将它们视为一个普通的段落。然而,如果这几行文本紧接着的下一行是 === 或 --- 这样的"下划线",解析器就会改变主意。它会意识到前面的那几行文本其实不是一个段落,而是一个 Setext 样式的标题。它会立即将前面的 "这是一个标题" 重新归类为一个 1 级标题。
| 特性 | ATX 标题 (# 样式) |
Setext 标题 (下划线样式) |
|---|---|---|
| 语法 | # 标题内容 |
标题内容 ======== 或 -------- |
| 支持级别 | 6 级(H1 到 H6) | 2 级(H1 和 H2) |
| 多行标题 | 不支持,标题必须在一行内 | 支持,标题文本可以跨越多行 |
| 简洁性 | 非常简洁,级别一目了然 | 视觉上更突出,但语法稍显繁琐 |
| 常见用法 | 在现代 Markdown 编辑中非常普遍,几乎是事实标准 | 在一些纯文本或邮件风格的写作中仍然可见 |
Setext 标题的识别是基于上下文的------只有在文本行后面跟了特定格式的下划线时,它才被确认为标题。
3.4.2 引用链接定义的检测
解析器会一直收集连续的文本行,并将它们暂时放在一个"可能是段落"的缓冲区里。在"关闭"的那一刻,解析器并不会立即将缓冲区里的所有内容都认定为段落。相反,它会从这些行的开头开始检查,看看它们是否符合引用链接定义的格式(即 [label]: url "title")。
如果是有效的链接定义,解析器就会将它们"消费"掉,作为链接定义来处理。这些定义在最终渲染时是不可见的。如果在消费掉所有链接定义后,缓冲区里还有剩余的文本行,那么这些剩余的行才会最终被确认为一个普通段落 。如果所有行都是链接定义,那么就不会形成段落。
考虑下面的 Markdown:
perl
[my-link]: https://example.com "示例"
这是一个段落。解析器的工作流程如下:
- 读到
[my-link]: https://example.com "示例",放入段落缓冲区 - 读到
这是一个段落。,继续放入段落缓冲区 - 到达文档末尾,触发"段落关闭"事件
- 开始检查缓冲区内容:
[my-link]: https://example.com "示例"这是一个链接定义,解析器将其处理掉 (即提取信息并存入内部的引用表,然后将它从缓冲区中移除)- 检查剩余内容: 缓冲区还剩下
这是一个段落。
这是一个段落。不再匹配任何链接定义格式,因此它被最终确认为一个段落
为什么链接引用定义优先?核心是类似链接定义 与 Setext 标题的冲突,考虑以下 Markdown 文本:
markdown[foo]: /url ---如果解析器可以随时随地处理链接定义,那么这段文本就会产生两种完全不同、且都看似合理的解释:
- 链接定义 + 主题分隔线,一个不可见的链接定义,加上一条水平线
- Setext 标题,一个二级标题,其文本是
[foo]: /url为了解决这个冲突,CommonMark 制定了一条简单而优雅的规则:当解析器遇到一连串准备形成段落的文本行时,它必须首先从第一行开始,尝试将这些行解析为链接引用定义。以消除歧义、提高解析效率,且符合直觉。
4. 第二阶段:内联结构解析
4.1 内联结构解析流程概览
在第一阶段解析器的目标是识别文档的宏观结构,构建出一个只包含块级元素的抽象语法树(Abstract Syntax Tree),并且已经收集了文档中所有的链接定义。对于段落或标题,它只是把里面的所有文本视为一个未经处理的原始字符串。
回顾第一阶段示例,阶段一结束时 *quodsi iracundia* 只是一个普通的字符串,解析器还没处理它们。
在第二个阶段,解析器会遍历阶段一创建的 AST:
- 当它访问到一个包含"原始字符串内容"的节点时(段落和标题),它会启动行内解析器
- 行内解析器会扫描这些原始字符串,寻找行内元素的标记,解析为内联元素
- 由于我们已经收集了文档中所有的链接定义,所以我们可以在进行时解析引用链接
以下是示例 AST 解析的结果:
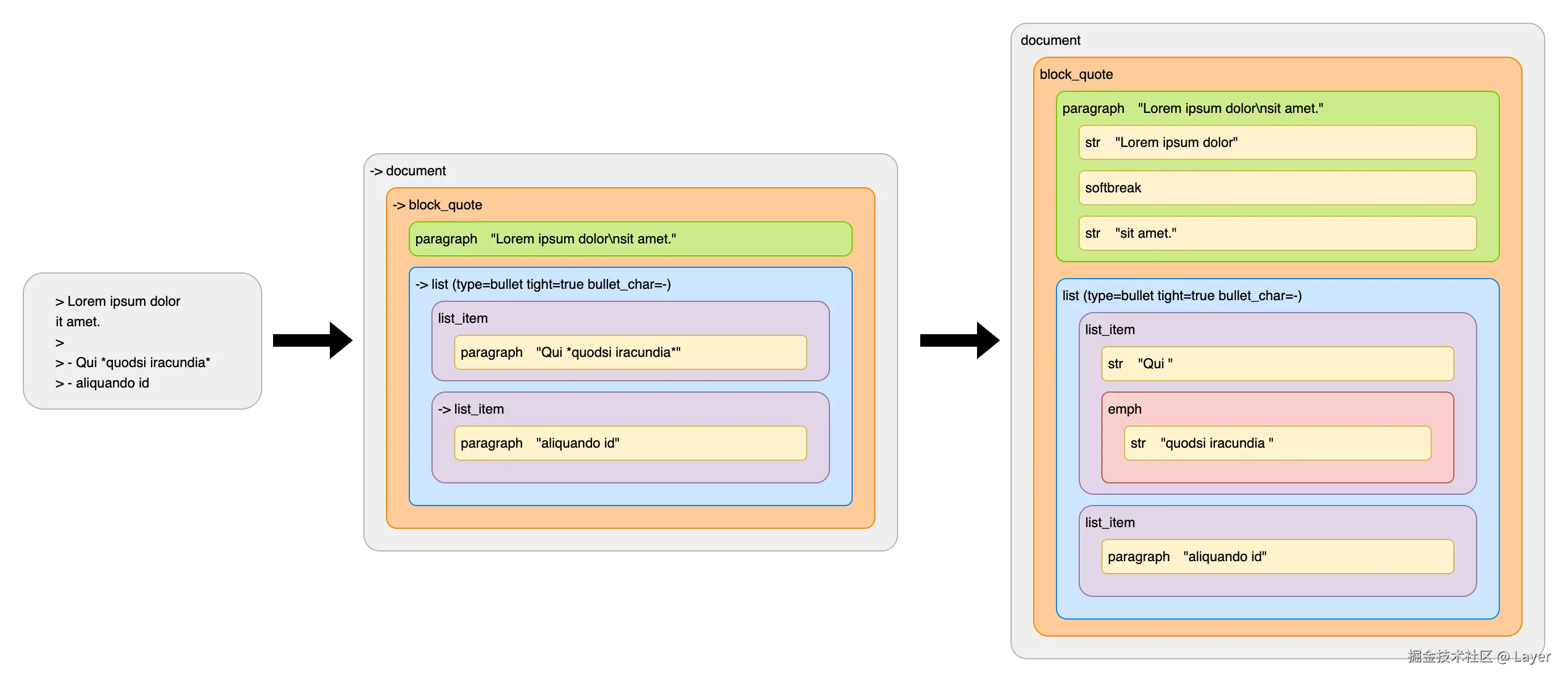
其中第一段中的行结束被解析为软换行,第一个列表项中的星号变成强调。
4.2 解析嵌套强调和链接的算法
需要先处理链接或图片(由
]触发)再处理强调,其核心原因在于两者定界符在解析算法中的角色和处理机制不同:
- 指令的明确性:链接或图片是"确定性"指令,强调是"可能性"标记
- 闭合方括号
]是一个高优先级且行为明确的触发器。当解析器遇到它,会立即执行一个特定任务:回顾与之匹配的开方括号[,并尝试解析为一个完整的链接或图片。这是一个"即时"的、确定的操作。- 相比之下,星号
*是一个 上下文相关的"延迟处理"标记。它本身含义模糊,可能是强调的开始、结束,或者仅仅是一个普通字符。因此,解析器不会立即做出决定,而是将其作为一个"潜在的定界符"暂存起来,等待后续内容来最终确定其身份。- 解析的原子性:链接优先构成"原子单元",再参与后续组合
- 由于链接的解析优先级更高,一旦触发,解析器会优先将
[文本]和(URL "标题")作为一个整体,构成一个不可分割的链接节点 。这个节点在后续的解析流程中,被视为一个原子单元。正是因为这种机制,才使得嵌套关系得以明确:
- 当链接在强调内部时
*[a](/url)*,是先构成[a](/url)这个链接单元 ,然后这个单元再被外部的*包裹,形成强调。- 当强调在链接内部时
[*a*](/url),是先识别出链接,然后对其 内部文本*a*进行递归解析,从而在链接单元的内部生成强调。
4.2.1 括号堆栈和分隔符堆栈机制
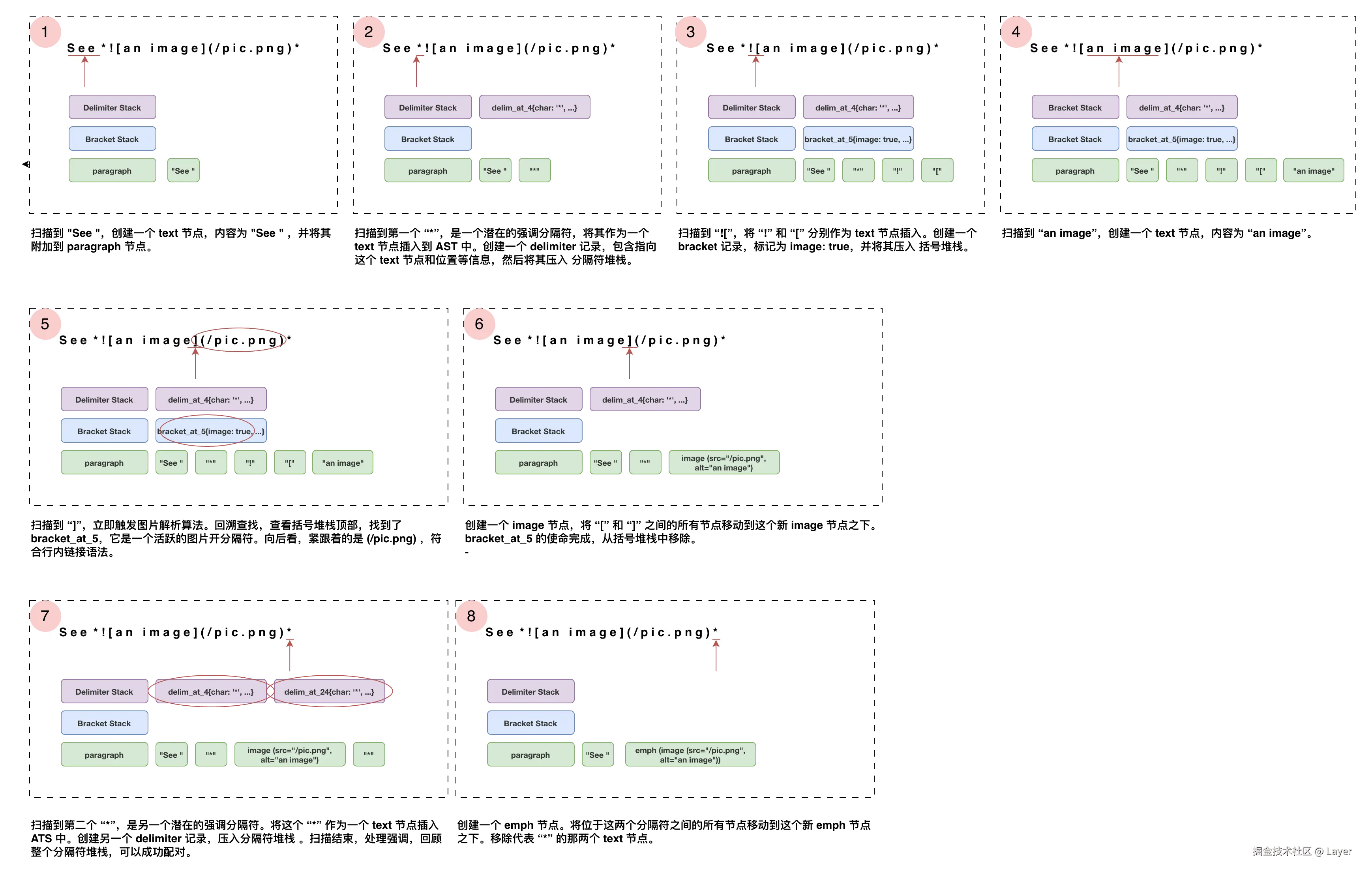
行内解析算法的精髓在于栈的机制,它将链接/图片的解析与强调/重强调的解析分离开来。这两种堆栈分别是括号堆栈(Bracket Stack)和分隔符堆栈(Delimiter Stack)。括号堆栈用于处理链接和图片,分隔符堆用于处理强调。以下是一个简单示例:
整体来看,它遵循一个两阶段的流程:
4.2.1.1 扫描与入栈
当解析器在处理行内内容时,一旦遇到以下两种情况之一:
- 一连串(一个或多个)的
*或_字符 - 一个
[(潜在的链接开始) 或![(潜在的图片开始)
解析器会执行两个操作:
- 插入文本节点:它并不会立即创建"强调"或"链接"节点,而是先将这些符号作为普通文本插入到文档树中
- 压入堆栈:遇到
[或![压入括号堆栈、遇到*或_压入分隔符堆栈。在决定这个字符的最终命运之前,会先为这个字符本身创建一个文本类型的节点。每个堆栈内元素都包含一个指向文本节点的指针,以及关于该分隔符的信息:- 分隔符的类型:
[、![、*、_ - 分隔符的数量:
*的数量是 1,**的数量是 2。 - 分隔符是否活跃:初始时,所有压入堆栈的分隔符都是活跃的。在后续处理中,不满足匹配条件的分隔符会被标记为不活跃,从而在最终处理强调时被忽略
- 分隔符开闭潜力:分隔符是一个潜在的开分隔符(Opener),还是一个潜在的闭分隔符(Closer),或是两者皆可(这取决于分隔符前后的字符)。例如,
*后面紧跟非空白字符,它就是开分隔符;前面紧跟非空白字符,它就是闭分隔符。
- 分隔符的类型:
开分隔符和闭分隔符这套机制是用来判断一个
*或_到底应该开始一段强调,还是结束 一段强调,或者仅仅是一个普通的字符。根据左右字符是空格 、 标点还是其他字符 ,解析器就能决定这个分隔符的"潜力"。 一个分隔符要有潜力成为"开分隔符" ,必须满足以下条件:
- 它的右边不能是空格
- 并且它的左边要么是空格,要么是标点符号
一个分隔符要 有潜力成为"闭分隔符" ,规则正好相反:
- 它的左边不能是空格
- 并且,它的右边要么是空格,要么是标点符号
当一个
*同时满足上述两种潜力时(如a*b中的*),它就被标记为两者皆可,在这种情况下,解析器会根据上下文来决定它最终扮演的角色。
4.2.1.2 触发与处理
当解析器遇到特定的"触发点"时,它会启动第二阶段的处理逻辑:
- 当我们遇到一个
]字符时,我们会调用"查找链接或图片"的过程(详见下文),这个过程会从括号堆栈的顶部开始向后查找,寻找一个与之匹配的、活跃的[或![。如果找到了,解析器就能成功构建一个链接或图片节点。 - 当我们到达输入的末尾时(即一个块级元素的所有行内内容都处理完毕),我们会调用"处理强调"的过程(详见下文),这个过程会检查分隔符堆栈中所有仍然活跃的
*和_分隔符。然后,它会根据匹配规则将它们配对,并把它们之间的文本节点包装成"强调"或"重强调"节点。
这个算法将识别、解释分隔符的含义这两个步骤分开了:
- 扫描阶段:线性扫描文本,遇到特殊符号就先存起来(压入堆栈),不做任何复杂的决策
- 处理阶段:在遇到特定触发点(如
]或文本末尾)时,才回过头来,根据堆栈中记录的完整上下文信息,进行匹配和转换
这种机制优雅地解决了各种复杂的嵌套问题,例如 [a link with *emphasis*](/url) 和 *emphasis with a [link](/url)*,确保了解析的准确性和一致性。
4.2.2 查找链接或图片过程
当解析器在行内扫描时遇到一个闭合方括号 ] ,会立即触发该的算法以判断它是否能与之前遇到的 [ 或 ![ 构成一个合法的链接或图片。该算法严格遵循以下步骤:
-
回溯查找匹配的开分隔符 :从分隔符堆栈的顶部(即最新添加的那个分隔符)开始,向后(即向旧的方向)遍历堆栈,寻找一个开分隔符,这个开分隔符必须是
[或![如果在堆栈中没有找到匹配的开分隔符,或者找到的开分隔符是"不活跃"状态(意味着它已被之前的某个解析过程消耗或禁用),则匹配失败。当前的]被视为一个普通的文本字符。任何找到的"不活跃"开分隔符也会被从堆栈中移除 -
前瞻解析链接语法 :如果成功找到了一个活跃的开分隔符,解析器会进入前瞻 (Lookahead) 阶段,检查紧跟在
]后面的文本,判断其是否符合以下四种标准链接/图片语法之一:- 行内链接/图片 :
[text](url "title") - 引用链接/图片 :
[text][label] - 紧凑引用链接/图片 :
[text][] - 快捷引用链接/图片 :
[text]
如果在
]之后没有发现任何上述合法语法(例如其后是普通字符或文本末尾),则匹配失败。即使找到了活跃的开分隔符,这个[ ... ]组合也无法构成链接。该开分隔符会从堆栈中移除,而当前的]依然被视为普通文本 - 行内链接/图片 :
-
重构抽象语法树(AST):只有当 步骤 1 和 步骤 2 全部成功时,解析器才会最终确认这是一个合法的链接/图片,并执行一系列关键的 AST 重构操作:
- 创建链接/图片节点:创建一个新的链接或图片节点,所有在 AST 中位于开分隔符
[和闭分隔符]之间的节点,都会被移动到这个新节点之下,成为其子节点。这些内容正式构成了链接的显示文本 - 处理内部的强调:对刚刚成为链接或者图片子节点的这些行内元素, 递归地调用处理强调过程,匹配到的
[开分隔符被设为"堆栈底部"。这意味着强调的匹配范围被严格限制在[和]之间,绝不会"越界"与链接外部的*或_发生匹配,从而完美地解析[a *b* c](/url)这样的内嵌格式 - 移除开分隔符:完成上述操作后,这个
[或![开分隔符的使命已经完成,将它从分隔符堆栈中移除 - 禁用嵌套链接:如果创建的是一个链接,解析器会执行一个额外的重要操作:将堆栈中所有位于当前这个
[开分隔符之前的、其他的[分隔符全部设置为"不活跃"这是 CommonMark 规范中"链接不能嵌套"规则的实现方式。一旦[link [text...这样的结构出现,当内部的]匹配成功后,外部的[就会被禁用,从而无法再形成链接。例如,在[a [b](/url_b) c](/url_a)中,[b]会成功解析为链接,但外部的[a ... c]则会失败
- 创建链接/图片节点:创建一个新的链接或图片节点,所有在 AST 中位于开分隔符
4.2.3 处理强调过程
处理强调过程的核心职责是遍历分隔符堆栈,将所有待定的 * 和 _ 分隔符,根据严格的匹配规则,最终解释为强调、重强调或回退为普通文本。这个过程在两种情况下被调用:
- 当一个块(如段落)的所有行内内容扫描完毕后,对该块关联的整个分隔符堆栈进行一次总调用
- 当一个链接或图片被成功解析后,对其内部的文本内容进行一次递归调用 ,以处理如
[*text with emphasis*](/url)这样的内嵌格式
该算法通过一个巧妙的主循环实现:
-
带边界的堆栈扫描:该循环依赖于几个关键的指针来管理其扫描范围和状态
stack_bottom设定处理边界- 此参数为分隔符堆栈设定了一个不可逾越的处理下限
- 全局调用时:当处理整个块时,
stack_bottom为 NULL ,意味着算法需要处理从栈顶到栈底的所有分隔符 - 递归调用时:当处理链接文本时,
stack_bottom会指向该链接的[开分隔符。这确保了处理过程仅在这个下限之上的堆栈部分进行,从而隔离链接内外的强调匹配。例如它能防止[a *b]和c*中的两个*错误地匹配
current_position主迭代器- 这是一个在堆栈中向前(从栈底向栈顶)移动的指针,作为主循环的迭代器,依次访问每个潜在的分隔符
openers_bottom动态的搜索下限- 算法为
*和_这两种分隔符类型,分别维护一个独立的开分隔符搜索下限指针,用于性能优化 - 记录了对于某个类型的分隔符,我们已经确认在此指针之下不存在可用的开分隔符了,初始时他们都等于
stack_bottom - 当后续搜索匹配的开分隔符时,无需再徒劳地扫描这部分堆栈,从而避免了大量的重复搜索
- 算法为
-
寻找并构建强调的双层循环 :从
stack_bottom之上的第一个分隔符开始循环,直至处理完所有潜在的闭分隔符- 找到下一个闭分隔符(主循环):
current_position指针在堆栈中前进,直到找到第一个(即最靠近文本开头的)潜在的闭分隔符 - 寻找匹配的开分隔符(内部循环):找到一个闭分隔符后,算法会从该位置向后(向栈底方向)搜索,寻找一个与之匹配的开分隔符 其匹配条件是:
- 分隔符类型必须相同(
*对*,_对_) - 搜索范围不能越过
stack_bottom和该分隔符类型的openers_bottom
- 找到下一个闭分隔符(主循环):
-
情况 1:找到匹配的开分隔符:如果找到匹配,算法将执行以下操作来构建强调节点
- 判断强度 :根据开闭分隔符的长度决定是普通强调还是重强调。如果开闭分隔符的长度都大于等于2,则它们可以形成重强调,否则,它们只能消耗1个字符形成普通强调
- 重构 AST :在抽象语法树中创建一个普通强调或者重强调节点。这个新节点会"包裹"住 AST 中所有位于开分隔符和闭分隔符之间的行内节点
- 移除中间分隔符:所有位于这对开闭分隔符和闭分隔符之间的分隔符条目,因为被"跨越"而失去了配对资格,将从分隔符堆栈中被彻底移除
- 消耗并清理开闭分隔符:
- 从开闭分隔符和闭分隔符对应的文本节点中,移除被消耗的字符
- 如果一个分隔符的所有字符都被消耗(例如
*节点在形成普通强调后变空),则其对应的文本节点将从 AST 中删除,其堆栈条目也将被移除 - 如果闭分隔符所在的堆栈条目被移除,
current_position指针会回退到前一个元素,以便在下一次循环中能正确前进
-
情况 2:未找到匹配的开分隔符:如果对于当前的闭分隔符,在合法范围内找不到匹配的开分隔符
- 更新
openers_bottom:对于当前这种分隔符类型,在current_position(包含)之前的位置上,不存在任何可用的开分隔符了。因此,将该类型的openers_bottom更新为current_position的前一个位置,极大地缩减了后续的搜索范围 - 移除无用的闭分隔符:如果这个闭分隔符本身不具备成为开分隔符的潜力,那么它现在既无法闭合也无法开放,因此可以从分隔符堆栈中安全地移除
- 继续前进:
current_position指针移动到堆栈中的下一个元素,继续主循环
- 更新
-
最终清理 :主循环结束后,所有能成功匹配的强调都已被处理并构建为 AST 节点。此时,堆栈中(
stack_bottom之上)可能还剩下一些未能配对的分隔符。这些都无法构成强调,只能被解释为普通的*或_字符
4.3 内联结构解析复杂示例 1
输入 Markdown 文本:Welcome to our [special *about [Company B][b_ref]* page](http://example.com/special).
以及文档末尾的引用定义: [b_ref]: http://example.com/b "The Official Website of Company B"
- 描与入栈:解析器从左到右扫描文本
- 遇到在 special 前的
[,将其作为"链接开分隔符"压入括号堆 - 遇到在 about 前的
*,将其作为"强调开分隔符"压入分隔符堆栈 - 遇到在 Company B 前的
[,再次将其作为"链接开分隔符"压入括号堆栈
- 遇到在 special 前的
- 处理内部链接:解析器遇到 Company B 后的
],触发链接处理逻辑- 它在括号堆栈中从后向前查找,找到与之最接近的开分隔符,即 Company B 前的
[ - 接着,解析器向前扫描,识别出
[b_ref]语法,并在文档的引用定义中成功找到了b_ref
- 它在括号堆栈中从后向前查找,找到与之最接近的开分隔符,即 Company B 前的
- 匹配成功:立即创建一个链接节点,其文本是
Company B,链接地址是http://example.com/b- 将这对已成功匹配的
[和]从括号堆栈中彻底移除 - 由于链接不能包含其他链接规则,解析器设置一个临时状态,括号堆栈中更早的、在
special前的[被临时标记为不活跃
- 将这对已成功匹配的
- 处理失败的外部链接:解析器继续前进,遇到
page后的],再次触发链接处理逻辑- 它在括号堆栈中回溯,找到了在
special前开分隔符[,但由于上一步设置的"不活跃"状态,这个[被忽略 - 由于找不到活跃的开分隔符,此次匹配失败。这个
]和它对应的[被降级为普通的文本字符
- 它在括号堆栈中回溯,找到了在
- 处理强调:在整个块级内容解析即将结束时,启动 强调处理逻辑
- 它找到了
about前的*和b_ref]后的* - 匹配成功,创建一个强调节点包裹
about [Company B]
- 它找到了
在此示例中:
- 链接解析的即时性与高优先级:遇到
]时立即尝试匹配 - 链接嵌套的禁止:通过将内部链接之外的
[标记为不活跃,阻止链接的嵌套 - 强调处理的延迟性:强调的匹配发生在链接解析全部完成之后
4.4 内联结构解析复杂示例 2
输入 Markdown 文本: _Part 1 __Part 2 *Part 3__ Part 4* Part 5_
- 扫描与入栈:解析器扫描整个字符串,将所有
_和*分隔符的信息压入分隔符堆栈 - 启动强调处理:从后向前(从左到右)遍历分隔符堆栈,寻找闭分隔符
- 找到第一个可作为闭分隔符的
__,在Part 3之后- 从它开始,向堆栈前回溯,寻找一个匹配的开分隔符
__,找到了Part 2前的__ - 匹配成功,创建一个重强调节点,包裹
Part 2 *Part 3 - 移除已用和无效的分隔符,将这对配对的
__从堆栈中移除。同时位于它们之间的*因被跨越而失效,也被从堆栈中移除
- 从它开始,向堆栈前回溯,寻找一个匹配的开分隔符
- 继续遍历,找到下一个可作为闭分隔符的
*,在Part 4之后- 从它开始,向堆栈前回溯,寻找匹配的开分隔符
* - 匹配失败,搜索无法找到任何活跃的
*开分隔符 - 既然从当前
*的位置无法向前找到任何匹配,解析器就记录下这个失败的位置,并设置一个"动态搜索下限",告诉后续的回溯搜索不必再看得比这个位置更早位置的*了,减少后续的无效搜索 - 这个无法匹配的
*本身也被从堆栈中移除,并降级为普通文本
- 从它开始,向堆栈前回溯,寻找匹配的开分隔符
- 继续遍历,找到最后的
_,在Part 5之后- 从它开始,向堆栈前回溯,寻找匹配的开分隔符
_ - 它成功找到了位于最开始的
_,在 Part 1 前 - 匹配成功,创建一个普通强调节点,包裹从
Part 1到Part 5的所有内容
- 从它开始,向堆栈前回溯,寻找匹配的开分隔符
在此示例中:
- 由内而外的匹配:解析器优先匹配最内层、最先闭合的有效分隔符对
- 分隔符的消耗:成功配对会消耗掉配对的分隔符以及它们之间的所有其他分隔符
- 动态的搜索下限:通过在失败的搜索后动态收缩后续搜索的范围,减交复杂度从而提升性能
二、cmark 工程与代码解析
1. 项目结构
cmark 的核心目录结构清晰明了:
bash
cmark/
├── README.md # 项目介绍
├── CMakeLists.txt # 项目构建配置文件
├── man/ # 帮助手册
├── src/ # 核心源码目录
├── test/ # CommonMark 规范符合性测试
├── api_test/ # API 使用示例与测试
├── wrappers/ # 其他语言的封装示例
└── build/ # 编译产物目录src/ 是整个项目的核心,所有 Markdown 的解析、AST 的构建和管理、以及最终渲染成不同格式的代码都在这里。
根据 src/CMakeLists.txt 文件,我们可以将 cmark 的核心源文件分为几个功能组:
- 公共 API 与入口:
main.c:cmark 命令行工具的入口。它解析命令行参数,然后调用cmark.c中定义的公共 API 来完成工作cmark.c:定义了库的公共 API,例如cmark_parse_document()和cmark_render_html()。这些是外部程序调用libcmark功能的入口点,负责协调解析器和渲染器的工作
- 数据结构:
node.c:定义了cmark_node结构体和操作 AST 的所有函数(创建、链接、遍历)buffer.c:实现了一个动态字符串缓冲区cmark_strbuf,用于在库中高效、安全地拼接和管理字符串references.c:专门处理链接引用定义(例如[id]: url)。在第一阶段收集它们,以供第二阶段的链接元素使用
- 解析器:
blocks.c:第一阶段解析。逐行扫描,识别段落、标题、列表等块级结构,构建初步的 AST。inlines.c:第二阶段解析。遍历块节点,解析其内部的强调、链接、代码等内联元素。scanners.c:高度优化的底层扫描器,用于快速定位特殊字符(*、[、_等)。它由 re2c(Regular Expressions to Code) 工具从scanners.re生成,是 cmark 高性能的关键之一
- 渲染器:
html.c:将 AST 渲染成 HTMLlatex.c:将 AST 渲染成 LaTeXman.c:将 AST 渲染成 man 手册xml.c:将 AST 渲染成 XML 格式commonmark.c:将 AST 逆向渲染回格式规范的 Markdown 文本
2. 公共 API 与入口
2.1 man1:用户命令
描述了所有用户可以在命令行中直接运行的可执行程序。cmark 程序读取 CommonMark 格式的纯文本,并将其转换为 HTML、groff man 手册页:
| 选项 | 作用 |
|---|---|
--to FORMAT |
指定输出格式。FORMAT 可以是:html (默认)、man、 xml、 latex、commonmark |
--width WIDTH |
指定输出的换行宽度。设置为 0 表示不自动换行。此选项目前只对 commonmark, latex, 和 man 渲染器有效。 |
--hardbreaks |
将源文件中的软换行(段落内的普通回车)渲染为硬换行 |
--nobreaks |
将软换行渲染为空格 |
--sourcepos |
在输出的元素中包含源文件位置属性(例如 data-sourcepos),标明其在源文件中的行号和列号 |
--validate-utf8 |
在解析前验证输入是否为合法的 UTF-8 编码,并将非法序列替换为 Unicode 替换字符(U+FFFD) |
--smart |
启用智能标点:直引号("、 ')会根据位置转换为弯引号 (""、'')、-- 会被渲染为 en-dash (--)、--- 会被渲染为 em-dash(---)、... 会被渲染为省略号(...) |
--safe |
启用安全模式(默认行为):原始 HTML 会被替换为占位符注释、危险 URL(以 javascript:, vbscript:, file:, 或 data: 开头的链接)会被替换为空字符串 |
--unsafe |
禁用安全模式,允许渲染原始 HTML 和危险 URL。此选项会覆盖默认的 --safe 行为 |
--help |
打印用法信息 |
--version |
打印版本号 |
- 通过字符串管道 (
|) 快速转换字符串:
bash
echo "Hello, **world**! This is `cmark`." | cmark
# <p>Hello, <strong>world</strong>! This is <code>cmark</code>.</p>- 转换文件为其他格式并保存到输出文件:
bash
cmark --to xml document.md > output.xml2.2 man3:库函数
man3 目录存放的是 libcmark 这个库所提供的所有公开 C 语言函数的说明文档,清晰地展示 cmark 库的 三大核心功能模块:解析、 AST 操作和渲染:
-
直接将 Markdown 字符串转换为 HTML 字符串
char *cmark_markdown_to_html(const char *text, size_t len, int options) -
一次性将 Markdown 文本转换为 AST:
- 将内存中的一整块字符串 buffer 解析成一个 AST
cmark_node *cmark_parse_document(const char *buffer, size_t len, int options) - 从一个文件指针 f 中读取并解析内容
cmark_node *cmark_parse_file(FILE *f, int options)
- 将内存中的一整块字符串 buffer 解析成一个 AST
-
流式将 Markdown 文本转换为 AST:
- 创建一个新的解析器
cmark_parser *cmark_parser_new(int options) - 向解析器提供一块数据
void cmark_parser_feed(cmark_parser *parser, const char *buffer, size_t len) - 结束解析,并返回最终的 AST 根节点
cmark_node *cmark_parser_finish(cmark_parser *parser) - 释放解析器对象
void cmark_parser_free(cmark_parser *parser)
- 创建一个新的解析器
-
AST 节点 API,包括创建与销毁、树状遍历、迭代器、属性访问、树结构修改等
-
将一个 AST转换为最终的输出字符串:
char *cmark_render_html(cmark_node *root, int options)
char *cmark_render_xml(cmark_node *root, int options)char *cmark_render_man(cmark_node *root, int options, int width)char *cmark_render_latex(cmark_node *root, int options, int width)char *cmark_render_commonmark(cmark_node *root, int options, int width)
3. 数据结构
3.1 cmark_node
cmark_node 是一个通用节点,可以代表 Markdown 文档中的无论是块级还是内联级的任何元素。所有这些节点通过指针链接在一起,形成一棵树。cmark_node 的定义如下:
c
struct cmark_node {
cmark_mem *mem;
struct cmark_node *next;
struct cmark_node *prev;
struct cmark_node *parent;
struct cmark_node *first_child;
struct cmark_node *last_child;
void *user_data;
unsigned char *data;
bufsize_t len;
int start_line;
int start_column;
int end_line;
int end_column;
uint16_t type;
uint16_t flags;
union {
cmark_list list;
cmark_code code;
cmark_heading heading;
cmark_link link;
cmark_custom custom;
int html_block_type;
} as;
};-
树结构指针:允许从任何节点出发,向上、向下、或在同级进行高效遍历
next、prev:指向兄弟节点,使得所有子节点形成一个双向链表,方便在同一层级遍历parent:指向父节点first_child、last_child:指向第一个和最后一个子节点。如果一个节点没有子节点,指针为 NULL
-
节点类型与元数据:
type:一个uint16_t整数,实际是cmark.h定义的cmark_node_type枚举值。标识这个节点是段落CMARK_NODE_PARAGRAPH、标题CMARK_NODE_HEADING、文本CMARK_NODE_TEXT还是其他类型flags:用于存储节点的状态位,例如CMARK_NODE__OPEN表示这个块节点尚未闭合、CMARK_NODE__LAST_LINE_BLANK表示节点的最后一行是空白行start_line、start_column、end_line、end_column:记录了该节点在原始 Markdown 文本中对应的起止位置,可实现源码映射等功能
-
内容存储:
data和len这两个成员一起定义了节点所持有的原始文本内容- 在块解析结束时,对于像段落这样的块节点,
data指向的是它包含的未经处理的内联文本 - 在内联解析之后,对于像文本节点这样的叶子节点,
data指向的是它所代表的纯文本 - 对于其他节点,这部分可能不被使用
- 在块解析结束时,对于像段落这样的块节点,
-
特定类型的数据:
cmark_node是一个通用结构,但不同类型的节点需要存储不同的信息,union允许多个成员共享同一块内存,根据节点的type,程序会访问union中对应的成员- 如果
type是CMARK_NODE_LIST,程序会通过node->as.list来访问列表的特定属性 - 如果
type是CMARK_NODE_LINK,程序会通过node->as.link来访问 URL 和标题 - 如果
type是CMARK_NODE_HEADING,程序会通过node->as.heading来访问标题的级别
- 如果
-
用户数据:
user_data:一个void*指针,允许库的使用者将任何自定义数据附加到 AST 的节点上,而无需修改库的源码。是一个灵活的扩展机制
3.2 cmark_strbuf
在 Markdown 解析过程中,需要大量地拼接、修改和累积文本,例如:
- 收集一个段落的所有行
- 构建一个链接的 URL 或标题
- 在渲染阶段(如生成 HTML)拼接标签和内容
在 C 语言中,处理字符串通常很繁琐,因为你需要手动管理内存:分配、重新分配、释放。 buffer.c 将所有这些繁琐的操作封装了起来,为上层解析器(如 blocks.c 和 inlines.c)提供了一套简单、高效、安全的字符串操作接口。它的核心作用是提供一个动态字符串缓冲区 的功能。可以把它理解为一个"智能"的、会自动扩容的字符串。核心数据结构是 cmark_strbuf:
c
typedef struct {
cmark_mem *mem;
unsigned char *ptr;
bufsize_t asize, size;
} cmark_strbuf;其中:
cmark_mem *mem:一个指向内存分配器的指针。cmark 实现了一个可插拔的内存分配机制,允许使用者提供自己的malloc、realloc、free函数。这个指针确保了缓冲区的内存操作都通过统一的分配器进行,便于内存管理和调试unsigned char *ptr: 指向实际存储字符串数据的内存块bufsize_t size:当前缓冲区中存储内容的实际大小,即字符串的长度bufsize_t asize: 已分配的内存空间的总大小,asize 总是大于或等于 size
当我们需要向缓冲区添加内容时,如果 size 即将超过 asize, buffer.c 中的函数会自动调用 realloc 通过 mem 分配器来扩大 ptr 指向的内存块,增加 asize 的值,然后再把新内容放进去。这就避免了手动检查容量和重新分配内存的麻烦。
buffer.h 中声明的其他函数,主要可以分为以下几类:
- 初始化与销毁
cmark_strbuf_init():初始化一个cmark_strbuf结构体。它会为一个新的缓冲区分配初始内存,并将size和asize设置为适当的初始值cmark_strbuf_free():释放ptr指向的内存,并将缓冲区重置回初始状态。这是为了防止内存泄漏cmark_strbuf_detach():这是一个所有权转移函数。它返回ptr指针,但 不会释放它 ,同时将buf结构体本身重置。调用者在拿到这个返回的字符串指针后,就有责任在未来手动free()它 。这在需要将缓冲区内容传递给其他模块长期使用时非常有用
- 扩容逻辑
cmark_strbuf_grow():当其他函数如putc、put发现当前容量不足时,就会调用grow。 其策略通常是按需分配,但会多分配一些,以减少频繁调用realloc带来的性能开销
- 数据添加操作(这些函数内部都会检查容量,如果需要就会调用
cmark_strbuf_grow(),然后使用memcpy或直接赋值将数据拷贝到ptr指向的内存中,并更新size)cmark_strbuf_putc(buf, c):向缓冲区末尾添加 一个字符ccmark_strbuf_put(buf, data, len):向缓冲区末尾添加一段指定长度 len 的二进制数据datacmark_strbuf_puts(buf, string):向缓冲区末尾添加一个以\0结尾的 C 字符串string
- 字符串处理工具
cmark_strbuf_trim():移除缓冲区内容开头和结尾的空白字符cmark_strbuf_rtrim():只移除结尾的空白字符cmark_strbuf_normalize_whitespace():将连续的空白字符(空格、换行、制表符)替换为单个空格cmark_strbuf_unescape():解析 Markdown 中的转义字符,例如将\*转换为*
3.3 cmark_reference_map
references 模块是 cmark 中一个职责非常专一的子系统,它专门负责管理 Markdown 文档中的链接引用定义。Markdown 允许先在文末或文中任何地方集中定义链接,然后在需要的地方通过一个标签来引用它们:
markdown
This is a paragraph with a [link to CommonMark][cm] and another
[link to GitHub][gh].
[cm]: https://commonmark.org "CommonMark Spec"
[gh]: https://github.com这就给解析器带来了挑战:
- 收集:在解析文档时,必须先识别并存储所有的链接定义(
[cm]: ...和[gh]: ...) - 查找 : 在解析到
[link to CommonMark][cm]这样的文本时,必须能通过标签cm快速地查找到之前存储的 URL 和标题
references 模块就是为了解决这个问题而存在的,references 模块定义了两个核心的数据结构:
struct cmark_reference代表一个单独的链接引用定义unsigned char *label;规范化后的标签 (key),例如 "cm"unsigned char *url;链接的 URLunsigned char *title;链接的可选标题struct cmark_reference *next;一个指向下一个 reference 的指针,用于将所有收集到的引用串成一个简单的链表unsigned int age;一个整数,记录这个引用被创建的顺序。用于在有多个相同标签的定义时,确定哪一个优先unsigned int size;内部使用的字段,用于资源限制检查
struct cmark_reference_map代表整个链接引用定义的集合,是管理所有cmark_reference的容器cmark_mem *mem;内存分配器指针,用于所有内存操作cmark_reference *refs;这是一个无序链表的头指针。在块级解析阶段,所有新创建的cmark_reference都会被简单地插入到这个链表的头部cmark_reference **sorted;这是一个指针数组 ,在第一次查找时被创建。它存储了指向所有cmark_reference节点的指针,并且按 label 排序好,是实现快速查找的关键unsigned int size;记录集合中唯一的引用定义的数量unsigned int ref_size;、unsigned int max_ref_size;用于资源限制
references 模块的工作流程清晰地分为两个阶段,完美契合 cmark 的两阶段解析模型:
-
阶段一:收集,在块级解析 blocks.c 中,当识别出一行是链接引用定义时,它会调用
cmark_reference_create()- 调用
normalize_reference()函数处理标签,将标签转换为小写、折叠连续的内部空白为一个空格、移除首尾的空白 - 创建一个新的
cmark_reference结构体,并填入规范化后的标签、URL 和标题 - 将这个新节点 直接插入到
map->refs链表的头部,不关心是否有重复,也不做任何排序
- 调用
-
阶段二:查找,在内联解析 inlines.c 中,当遇到一个引用式链接时,它会调用
cmark_reference_lookup()-
首次查找的预处理,首先检查
map->sorted数组是否已经被创建,如果是第一次查找则调用sort_references() -
sort_references()创建一个足够大的指针数组sorted,并遍历map->refs无序链表,将每个节点的地址存入数组,调用 C 标准库的qsort(),使用一个自定义的比较函数refcmp对sorted数组进行排序。首先比较规范化后的label,如果label相同,则比较age,再次遍历已排序的数组,利用其有序性,只保留每个label、age最小的,丢弃所有后续的重复定义,将这个排好序且去重的数组的地址存入map->sorted,供后续使用 -
对待查找的
label执行与创建时完全相同的normalize_reference()操作,调用 C 标准库的bsearch(),在已排序的map->sorted 数组上进行高效的二分查找,如果找到,返回匹配的cmark_reference指针;否则返回 NULL
-
references 模块在块解析阶段只管收集,用最快的 O(1) 链表头插法,不进行任何多余处理。在真正需要查找时,才付出一次性的 O(n log n) 排序代价,换来后续所有查找都享有 O(log n) 的高速性能。这种设计完美地平衡了两个阶段的不同需求,避免了在块解析阶段为可能永远不会发生的查找操作付出不必要的计算开销,是 cmark 高性能的设计之一。
4. 解析器
4.1 cmark_parser
parser.h 是一个 内部头文件 ,它的作用是为 cmark 库内部的几个关键 C 文件(主要是 blocks.c、 inlines.c、cmark.c)提供 cmark_parser 结构体的统一定义。cmark_parser 是一个状态机 ,封装了单次 Markdown 解析任务所需的所有状态和数据。每次解析调用 cmark_parser_new() 都会创建一个全新的实例,代表一次独立的解析过程。每一次独立的、从头开始的 Markdown 文档解析任务,都必须调用一次 cmark_parser_new() 来创建一个全新的 cmark_parser 实例。cmark_parser 的定义如下:
c
struct cmark_parser {
struct cmark_mem *mem;
struct cmark_reference_map *refmap;
struct cmark_node *root;
struct cmark_node *current;
int line_number;
bufsize_t offset;
bufsize_t column;
bufsize_t first_nonspace;
bufsize_t first_nonspace_column;
bufsize_t thematic_break_kill_pos;
int indent;
bool blank;
bool partially_consumed_tab;
cmark_strbuf curline;
bufsize_t last_line_length;
cmark_strbuf linebuf;
cmark_strbuf content;
int options;
bool last_buffer_ended_with_cr;
unsigned int total_size;
};下面是其所有成员的详细分类解析:
-
核心对象与 AST 树指针:
struct cmark_mem *mem:内存分配器,指向一个包含calloc、realloc、free函数指针的结构体,解析过程中所有内存操作都通过它,实现了内存管理的抽象化。默认的cmark_mem是通过一个定义在cmark.c中的全局变量DEFAULT_MEM_ALLOCATOR来实现的,是对标准 C 库中的内存管理函数做了一层安全的封装struct cmark_reference_map *refmap:链接引用表,专门负责存储和查询 Markdown 文档中的链接引用定义,如[label]: url "title"。当解析器在文中遇到[text][label]时,会在此查找label对应的数据。refmap的所有相关逻辑都封装在references.h和references.c这两个文件中,采用了一种"延迟排序 + 二分查找"的策略struct cmark_node *root:AST 根节点,始终指向CMARK_NODE_DOCUMENT类型的根节点,是最终生成的抽象语法树的入口,在一次完整的解析过程中,parser->root指针一旦被设定,就永远不会再改变struct cmark_node *current:当前活动节点,指向当前正在构建的、最深层的开放节点。只在块级解析阶段被使用和修改,整个blocks.c的逻辑都围绕着current指针在 AST 上的移动来构建文档的"骨架":- 当进入一个新的嵌套块时下移:
current = new_child_node - 当一个块被闭合时上移 :
current = current->parent - 当添加新的同级块时作为父节点 :
add_child(current, new_node) - 当检查行延续性时作为上下文 :
check_open_blocks(parser, current, ...)
- 当进入一个新的嵌套块时下移:
-
行处理与位置状态:
int line_number:当前处理的行号,从 1 开始,当一个块级节点开始时,解析器会读取当前的parser->line_number和parser->column,并将它们存入该节点的start_line和start_column成员中。当这个节点被闭合时,解析器会再次读取当前的parser->line_number和parser->last_line_length,并将它们存入节点的end_line和end_column成员中cmark_strbuf curline:当前行字符串缓冲区,存储着当前正在被S_process_line函数处理的、未经修改的line_number所指向的那一行的的文本内容,包含指向数据的指针ptr和长度sizebufsize_t offset:行内字节偏移,记录解析器在当前行缓冲区curline中已经处理到了哪个字节位置bufsize_t column:行内逻辑列号,与offset不同,它考虑了制表符(Tab)的宽度。一个 Tab 字符(1字节)可能使 column 增加 1-4 列。offset是给程序看的,用于在内存层面进行高效操作。column是为了匹配规范 ,用于在逻辑层面进行语法判断。两者协同工作,才能精确地解析既包含空格又包含制表符的复杂缩进bufsize_t first_nonspace、bufsize_t first_nonspace_column:预先计算并缓存当前行curline第一个非空白字符的位置字节偏移量、逻辑列号,在块级解析中,几乎所有类型的块级元素识别,都始于检查行首的特征,这是个重要的性能优化,是一个典型的空间换时间的优化案例。在块级解析中,几乎所有类型的块级元素识别,都始于检查行首的特征:ATX 标题(检查行首忽略缩进后是不是#)、块引用(检查行首忽略缩进后是不是>)、列表项(检查行首忽略缩进后是不是*、+、-或1)、围栏代码块(检查行首忽略缩紧后是不是围栏代码块)、Setext 标题(需要检查这一行是不是完全由-或=组成)int indent:记录当前行curline在第一个非空白字符出现之前的总缩进量,以"空格"为单位。在块级解析中主要用于区分和处理列表与代码块:根据 CommonMark 规范 4 个空格或一个等效的制表符的缩进构成一级代码块缩进、延续列表项内容和区分段落与子列表bool blank:空白行标志,如果当前行只包含空白字符,则为true。据 CommonMark 规范,一个"空白行"是指 只包含零个或多个空格或制表符的行。用于在块级解析状态机中驱动关键的状态转换,如当parser->blank为true时,解析器就知道它遇到了一个分隔符。这通常会触发闭合当前开放的节点、一个列表是"松散"(loose)还是"紧凑"(tight)取决于其列表项之间是否有空白行bool partially_consumed_tab:Tab 部分消耗标志,一个用于处理复杂缩进的边缘情况的标志。当为了满足一个 k 列的缩进,而消耗了一个能提供 n > k 列宽度的 Tab 字符时,作为一个信号,通知后续的内容添加逻辑,需要在实际内容前补上 n - k 个虚拟的空格 ,以确保最终存入节点的内容在逻辑上是正确对齐的bufsize_t last_line_length:记录解析器刚刚处理完的上一行的有效内容长度,解决在处理第 N 行时,需要获取第 N-1 行结束位置信息的时间差问题,用于在闭合节点时,精确设置节点的end_columnmarkdownHello world, this is a paragraph. A new paragraph.-
解析器处理第 1 行,开启一个段落节点。
start_line=1、start_column=1 -
解析器处理第 2 行,发现它可以"懒延续",于是将
this is a paragraph.添加到该段落的内容中 -
解析器处理第 3 行,发现这是一个空白行
parser->blank = true -
空白行是一个明确的块分隔符。这个信号告诉解析器前面那个段落到此结束了。于是解析器调用
finalize()函数来闭合段落节点 -
在
finalize函数内部确定结束位置:-
end_line:节点是在第 3 行被闭合的,但它的内容实际上结束于第 2 行。所以end_line被设置为parser->line_number - 1,也就是 3 - 1 = 2 -
end_column:我们需要第 2 行的结束列号。但在处理第 3 行的这个时刻,parser->curline里存的是第 3 行的内容,关于第 2 行的精确列信息已经丢失了 -
在处理完第 2 行、进入第 3 行之前,解析器已经将第 2 行的有效长度存入了
parser->last_line_length -
finalize函数可以直接使用这个被特意保存下来的值b->end_column = parser->last_line_length,也就是 21
-
-
-
内容聚合与缓冲区:
-
cmark_strbuf linebuf:处理流式输入的行拼接缓冲区,cmark 的一个核心特性是支持流式解析。可以通过多次调用cmark_parser_feed()函数,一块一块地把数据喂给解析器,而不是一次性提供整个文档。这就会带来一个问题一个完整的文本行可能会被分割在两次feed调用之间。它负责处理跨越多次 feed 调用的数据片段,将它们拼接起来,然后再交给curline处理cmark_parser_feed(parser, "Hello\nWor", 9);、cmark_parser_feed(parser, "ld\n", 3);-
第一次调用 : 解析器接收到 "Hello\nWor"
-
它能找到一个完整的行 "Hello\n" ,于是把它交给
curline处理 -
这个片段的末尾没有换行符
\n,解析器无法确定这一行是否已经结束 -
解析器会把这个不完整的片段 "Wor" 暂存到
linebuf缓冲区中
-
-
第二次调用 : 解析器接收到 "ld\n"
-
解析器会检查
linebuf是否为空。它发现 linebuf 中已经有内容 -
会把新接收到的数据 "ld\n" 追加到
linebuf的末尾,linebuf中的内容变成了 "World\n" -
解析器再次扫描
linebuf,发现它现在包含了一个完整的行 -
解析器从
linebuf中取出 "World\n" ,把它交给 curline 进行处理,并清空linebuf
-
-
-
cmark_strbuf content:节点内容缓冲区,在块级解析阶段收集属于同一个块级节点(如段落、标题)的所有文本行内容。当解析器准备开始处理一个新的、可以包含文本内容的块级节点时,content缓冲区通常会被清空。在处理后续的每一行时,如果这一行被判断为属于当前块,比如一个段落的第二行、第三行,那么这一行的有效文本内容(经过缩进处理、标记消耗等)会被追加到content缓冲区中。当这个块级节点最终被闭合时,content缓冲区里就包含了这个节点全部的、原始的、多行文本内容。提高内存分配效率、简化对"懒延续"等复杂规则的处理、方便对完整的块内容进行最终处理(resolve_reference_link_definitions函数就是对content里的内容进行操作以抽取出链接引用定义)
-
-
配置与其他状态
-
int options解析选项,从cmark_parser_new传入的选项位掩码,解析过程中的某些行为会据此调整CMARK_OPT_DEFAULT:进行标准的 CommonMark 解析和渲染,不开启任何额外的开关CMARK_OPT_SOURCEPOS:开启源码映射,为 AST 中的所有块级节点记录它们在原始 Markdown 文本中的起止位置,这些信息会被填充到cmark_node结构体的start_line、start_column、end_line、end_column字段中,用于需要实现滚动同步、实时预览、错误高亮等功能的编辑器或工具CMARK_OPT_HARDBREAKS:将软换行渲染为硬换行CMARK_OPT_UNSAFE:禁用安全过滤,允许不安全的 HTML 和链接。危险的原始 HTML 比如<script>、<style>等标签会被替换为占位符注释<!-- raw HTML omitted -->。危险的链接比如javascript:、vbscript:、file:协议的链接,以及某些data:协议的链接,其 URL 会被替换为空字符串CMARK_OPT_SMART:开启智能标点转换,在内联解析阶段,它会将一些 ASCII 标点自动转换为更美观的印刷体符号。如"直引号 转换为"和"弯引号CMARK_OPT_NOBREAKS:将软换行渲染为空格CMARK_OPT_VALIDATE_UTF8:校验输入是否为有效的 UTF-8 。在解析前,会检查输入字符串的 UTF-8 编码。如果发现无效的字节序列,会将其替换为 Unicode 的替换字符CMARK_OPT_SAFE已废弃,早期版本中用于开启安全模式,目前安全模式已是默认行为,保留以保持旧版本的 API 兼容性CMARK_OPT_NORMALIZE:已废弃,现在没有任何效果
-
bufsize_t thematic_break_kill_pos:在单行处理中,记录一个导致水平分割线解析失败的关键字符位置,以避免在同一行内进行后续的、注定会失败的重复检查。可能会在两个地方发生水平分割线检查:检查是否是独立的水平分割线、检查 Setext 标题的下划线。将多次昂贵的字符串扫描操作,变成了一次扫描和多次廉价的整数比较 -
bool last_buffer_ended_with_cr在不同的操作系统中,换行符有不同的表示方法,在 Windows 中使用 CRLF(Carriage Return + Line Feed)\r\n。用于正确处理\r\n换行符被分割在流式处理中两个输入块边界的边缘情况mark_parser_feed(parser, "Hello\r", 6);、cmark_parser_feed(parser, "\nWorld", 6);-
第一次调用 : 解析器接收到 "Hello\r"
- 看到了
\r,但它无法确定这到底是一个独立的 CR 换行,还是一个 CRLF 换行的一半,但是输入已经结束了 - 先把 "Hello" 处理掉,然后设置
parser->last_buffer_ended_with_cr = true;,并结束这次 feed 调用
- 看到了
-
第二次调用 : 解析器接收到 "\nWorld"
-
在处理这个新数据块的最开始 ,检查
last_buffer_ended_with_cr标志是true,且新数据块的第一个字符正好是\n。 -
上一个数据块结尾的
\r和这个数据块开头的\n共同构成了一个完整的\r\n换行符,解析器把这个\n忽略,因为它已经被作为\r\n的一部分处理了 -
将
last_buffer_ended_with_cr重置为false,并从W开始处理 "World"
-
-
-
unsigned int total_size,记录已经送入解析器的总字节数,这是一个简单的累加器,每当cmark_parser_feed函数被调用时,它传入的len参数值就会被累加到total_size上。一个预留的、用于监控和资源限制的钩子。它让库的维护者或高级用户可以在需要时,通过parser实例获取到目前为止处理的总输入量,从而实现自定义的资源消耗检查
-
4.2 scanners
4.2.1 re2c
re2c 是一个免费、开源的自由软件工具,它的全称是 "regex to C",即正则表达式到 C。它的核心功能是:读取一个包含正则表达式和 C/C++ 代码块的特殊源文件,通常以 .re 为扩展名,并生成一个高度优化的、基于 goto 的 C/C++ 词法分析器(Lexical Analyzer) 或扫描器(Scanner)。与经典的 lex 或 flex 工具类似,但 re2c 在设计上更注重生成速度极快且内存占用小的代码。
开发者首先创建一个 .re 文件。这个文件不是纯 C 代码,而是一种混合语言:
- C/C++ 代码:你可以像在普通
.c文件里一样写 C 代码 re2c块:使用特殊的注释/*!re2c ... */来包裹re2c的规则- 规则:在
re2c块中,你用一种类似正则表达式的语法来定义要匹配的模式,以及匹配成功后要执行的 C 代码
一个scanners.re 的简化版的例子:
c
// scanners.re
#include <stdio.h>
int lex(const char *YYCURSOR) {
const char *YYMARKER; // re2c 需要的内部标记
/*!re2c
re2c:define:YYCTYPE = char; // 定义字符类型
re2c:yyfill:enable = 0; // 禁用缓冲区填充(cmark自己管理)
"foo" { printf("Found foo\\n"); return 1; }
"bar" { printf("Found bar\\n"); return 1; }
* { printf("Unknown\\n"); return 0; }
*/
}在上述代码中:
lex函数:我们定义的 C 函数,它的工作是接收一个字符串作为输入,然后分析这个字符串的开头是什么YYCURSOR:这是一个特殊的指针,由re2c规定,指向当前正要被分析的字符。lex函数通过这个参数接收输入字符串/*!re2c ... */块:re2c工具在处理这个文件时,会忽略所有的 C 代码,只关心这个块里的内容,并用 goto 状态机来替换
在命令行中运行 re2c,明确输入文件和输出文件:
bash
re2c -o scanners.c scanners.rere2c 会解析 scanners.re 文件,并将 /*!re2c ... */ 块转换成一个复杂的、由 goto 和标签构成的 C 语言有限状态机,以下是简化的输出内容:
c
// scanners.c (自动生成)
#include <stdio.h>
int lex(const char *YYCURSOR) {
const char *YYMARKER;
yych: // 当前字符
// ... 大量的 goto 和标签 ...
if ((yych = *YYCURSOR) == 'b') goto yy4;
if (yych == 'f') goto yy5;
goto yy2;
yy2:
++YYCURSOR;
yy3:
{ printf("Unknown\n"); return 0; }
yy4:
// ... 更多 goto ...
{ printf("Found bar\n"); return 1; }
yy5:
// ... 更多 goto ...
{ printf("Found foo\n"); return 1; }
}这个生成的状态机在逻辑上等同于你手写的 if/else 或 switch,但它的结构经过了 re2c 的算法优化,执行效率通常更高。最后,像编译其他普通 C 文件一样,编译这个生成的 scanners.c 文件,并将其链接到最终程序中:
- 极高的性能 :
re2c生成的代码是为速度而生的。它通过构造一个确定性有限自动机,使得在扫描输入时,每个字符只需要进行一次检查,时间复杂度是严格的 O(n),其中 n 是输入字符串的长度。它大量使用goto,这里是生成最高效状态机的关键,因为它直接对应了状态之间的跳转。 - 灵活性和控制力 :与
lex/flex不同,re2c不会生成一个完整的、包含main函数的程序。它只生成一个可以被你自由调用的函数体。它不强制使用任何特定的 I/O 或缓冲区管理方案。你可以自己决定如何读取和管理输入数据。 - 内存占用小:生成的状态机非常紧凑,适合用于内存受限的嵌入式系统或对性能要求极高的底层库。
4.2.2 scanners
scanners 模块由 scanners.h 、 scanners.c 和 scanners.re 三个文件组成,其核心职责是提供一系列高度优化的函数,用于在字符串的任意位置快速地扫描和匹配特定的 Markdown 语法模式。scanners.re 是 scanners 模块的真正"源码",是 re2c 工具的输入文件。
可以将文件内容分为三大部分来解析:
-
全局定义区:定义可复用的模式和全局配置
c/*!re2c re2c:define:YYCTYPE = "unsigned char"; re2c:define:YYCURSOR = p; re2c:define:YYMARKER = marker; re2c:define:YYCTXMARKER = marker; re2c:yyfill:enable = 0; // 基本字符类型 spacechar = [ \t\v\f\r\n]; reg_char = [^\\\\()\\x00-\\x20]; // 非特殊字符 escaped_char = [\\\\][!\"#$%&\'()*+,./:;<=>?@[\\\\\\]^_`{|}~-]; // 转义字符 // HTML 相关模式 tagname = [A-Za-z][A-Za-z0-9-]*; // HTML 标签名 blocktagname = 'address'|'article'|...|'ul'; // 所有块级 HTML 标签名 attribute = ...; // HTML 属性 opentag = tagname attribute* spacechar* [/]? [>]; // 开标签 closetag = [/] tagname spacechar* [>]; // 闭标签 htmltag = opentag | closetag; // 完整的 HTML 标签 htmlcomment = ...; // HTML 注释 processinginstruction = ...; // XML 处理指令 declaration = ...; // DTD 声明 cdata = ...; // CDATA 块 // 链接相关模式 in_parens_nosp = ...; // 括号内的非空白内容 in_double_quotes = [\"] (escaped_char|[^\"\\x00])* [\"]; // 双引号内容 in_single_quotes = [\'] (escaped_char|[^\'\\x00])* [\']; // 单引号内容 in_parens = [(] (escaped_char|[^)\\x00])* [)]; // 括号内容 scheme = [A-Za-z][A-Za-z0-9.+-]{1,31}; // URL 协议 */- 配置 : 设置了
re2c的基本工作参数,如用p作为光标,禁用yyfill等 - 原子模式 : 定义了像
spacechar、escaped_char这样的最基本的字符组合 - 组合模式 : 通过组合原子模式,构建出更复杂的、有实际意义的模式。如
htmltag是由opentag和closetag组成的,而opentag又是tagname和attribute的组合。这种分层定义使得复杂的正则表达式变得结构化,易于管理
- 配置 : 设置了
-
块级扫描函数:用于在 blocks.c 中识别块级元素的函数
_scan_atx_heading_start:识别 ATX 标题,[#]{1,6} ([ \t]+|[\\r\\n]),匹配 1-6 个#号,其后必须跟至少一个空格/制表符,或者直接是行尾_scan_setext_heading_line:识别 Setext 标题下划线,[=]+ [ \t]* [\\r\\n]和[-]+ [ \t]* [\\r\\n],匹配一行是否完全由=或-组成允许行尾有空格。根据匹配的是=还是-,分别返回 1 或 2 ,代表一级或二级标题_scan_open_code_fence、_scan_close_code_fence:识别围栏代码块,匹配至少 3 个连续的反单引号或波浪号_scan_html_block_start、_scan_html_block_start_7:识别 HTML 块的开始,包含7种规则,对应 CommonMark 规范中定义的7种 HTML 块的起始条件_scan_html_block_end_1到_scan_html_block_end_5:为不同类型的 HTML 块识别其结束标志
-
内联扫描函数:用于在 inlines.c 中识别内联元素的函数
_scan_schemescheme [:],识别 URL 协议模式,匹配一个合法的 URL 协议加上后面的冒号_scan_autolink_uri、_scan_autolink_email,识别自动链接,当 inlines.c 遇到<时,会调用这两个函数来判断它是否构成一个完整的 URI 自动链接<http://a.b>或 Email 自动链接<a@b.c>_scan_html_tag,识别行内 HTML 标签,当 inlines.c 遇到<时,调用此函数来匹配一个完整的 HTML 标签,开标签或闭标签_scan_link_title: 识别链接标题,在解析[text](url "title")时,用于快速匹配并提取被引号或括号包围的 title 部分_scan_dangerous_url检查不安全的 URL,'javascript:' | 'vbscript:' | 'file:' | 'data:',在解析出链接的 URL 后,调用此函数进行安全检查_scan_spacechars扫描连续空白,[ \t\v\f\r\n]+一个简单的工具函数,用于快速跳过一串连续的空白字符
cmark 只在处理模式复杂、性能敏感的语法时才动用 re2c 这个工具,而对于模式简单、固定的语法,则直接使用更直观、更灵活的 C 代码进行判断。
块级元素哪些没有使用 scanners.c ?
-
块引用:在 blocks.c 中,通过
if (parser->curline.ptr[parser->offset] == '>')直接判断,模式简单 -
列表项:在 blocks.c 中,通过一个手写的
is_list_marker函数,用switch和if判断*,+,-或数字加.,模式简单 -
缩进代码块:在 blocks.c 中,通过
if (parser->indent >= 4)判断,基于状态而不是基于字符模式匹配 -
水平分割线:在 blocks.c 中,通过一个手写的循环来判断一行中只有
*、-、_三种字符,且总数不少于 3 个。需要与 Setext 标题的-下划线规则进行区分,手写代码能更清晰地控制这种 上下文相关的判断逻辑
内联元素哪些没有使用 scanners.c ?
- 强调、加粗:在 inlines.c 中,当遇到
*或_时,进入一个复杂的、手写的定界符处理逻辑,*和_的解析是高度上下文相关的 - 行内代码:遇到反单引号,向后扫描寻找与之匹配的、相同数量的反单引号,模式简单
- 链接和图片:遇到
[或![时,进入一个专门的、手写的parse_link函数,链接的解析是一个 多步骤的、程序化的过程而不是一个单一的模式 - 反斜杠转义:遇到
\时,检查下一个字符是否是可转义的标点,模式简单
scanners 是 cmark 能够实现高性能解析的关键因素之一。通过 re2c 生成的状态机,可以实现严格的 O(n) 时间复杂度的扫描。它将" 如何识别 一个语法模式"的底层复杂性,与" 识别出模式后该做什么 "的上层解析逻辑完全分离开来。这使得 blocks.c 和 inlines.c 的代码可以更专注于状态管理和 AST 构建,而无需关心具体的字符匹配细节。
4.3 blocks
blocks.c 是 cmark 的 块级解析器,它的核心职责是逐行读取 Markdown 文本,识别并构建出文档的各种块级元素组成的抽象语法树。blocks.c 的本质是一个基于行的、自上而下的状态机:
- 基于行:它的基本处理单元是"行",它一次处理一行文本,然后根据这一行的内容来更新解析器的状态
- 状态机:解析器的状态由
cmark_parser结构体中的一系列字段来表示,其中最重要的状态就是parser->current指针,它指向当前开放的、正在处理的块级节点 - 自上而下:它从文档的根节点开始,随着一行的内容,可能会进入更深的嵌套结构,也可能会从深层结构中回溯出来
blocks.c 的所有逻辑都围绕着一个核心函数展开 S_process_line() ,这里的 S_ 前缀代表 static,当外部调用 cmark_parser_feed() 时,数据被送入 linebuf 拼接成行,然后每一行都会被交给 S_process_line() 来处理。S_process_line() 的工作流程可以概括为以下几个步骤:
-
初始化行状态 :接收一行文本,计算并缓存这行的关键信息,存入
cmark_parser结构体中:parser->offset = 0;光标移动到行首parser->column = 0;逻辑列号归零- 计算
parser->indent缩进量和parser->first_nonspace第一个非空白字符位置 - 设置
parser->blank是否为空白行
-
闭合旧结构 :解析器从
parser->current指针指向的当前节点开始, 向上回溯 到根节点,在回溯的路径上,它会检查每一个开放的块级容器是否可以在当前行延续。如针对块引用,当前行是否有>标记?针对列表项,当前行是否有足够的缩进?针对代码块当前行是否是围栏代码块的结束标记?如果某个容器不能延续,解析器就会调用finalize()函数将这个容器以及它内部所有开放的子节点闭合。parser->current指针也会随之上移到被闭合节点的父节点 -
开启新结构 :寻找新的块起始标记,经过上一步的"闭合"操作后,
parser->current指向了当前上下文中最深的、仍然开放的容器。现在解析器在当前行的当前偏移量parser->offset处,开始寻找新的块级元素标记。它会按一定的优先级顺序进行检查,是链接引用定义吗?是块引用标记>吗?是 ATX 标题标记#吗?是围栏代码块标记吗(调用scan_open_code_fence)?是 HTML 块标记吗(调用scan_html_block_start)?是 Setext 标题下划线吗(调用scan_setext_heading_line)?是水平分割线吗?是列表标记吗?如果匹配成功,解析器会创建一个对应类型的新节点,将新节点添加为parser->current的子节点。如果新节点本身也是一个容器,则更新parser->current指向这个新节点,更新parser->offset -
处理段落内容 :如果所有模式都匹配失败,解析器会认为这一行是普通段落的内容,它会检查
parser->current指向的节点是否是一个可以"懒延续"的段落,如果是,它就会简单地将这行文本追加到段落中。如果不是,比如当前在一个 list 节点下但还未创建 paragraph,它会先创建一个新的 paragraph 节点,将parser->current指向它,然后再把文本添加进去。所有被判定为普通文本行的内容,都会通过add_line()函数,被追加到parser->content这个临时字符串缓冲区中。针对 Setext 标题,解析器会将当前这个 paragraph 节点的类型,升级为 heading 节点。 -
S_process_line结束,解析器准备好处理下一行,重复整个过程 。当cmark_parser_finish()被调用时,块级解析阶段正式结束。首先,它会调用finalize(parser->root, parser->line_number),确保从根节点开始所有还开放的块都被彻底闭合。然后,它会将所有节点的字符串内容(之前暂存在parser->content缓冲区中的)进行最后的整理,并设置到node->literal字段中。 至此,一个只包含块级元素 的 AST 树就构建完成了。这棵树的叶子节点通常是 paragraph 或 heading ,它们内部的 literal 字段包含了大块的、未经内联解析的原始文本。这个 AST 就是 blocks.c 工作的最终产物,它将被移交给下一阶段------ inlines.c ------进行深加工。
blocks.c 是一个精巧的、基于行扫描和状态机的解析器。它通过 parser->current 指针在 AST 上的移动 ,以及对每一行文本的延续/新建判断,高效而准确地将一维的文本流,转换成了二维的、具有嵌套结构的文档骨架。它是整个 cmark 库中最复杂,也最核心的算法所在。
4.4 inlines
inlines.c 是 cmark 的内联解析器。它的核心职责是遍历由 blocks.c 构建好的 AST"骨架",找到其中包含纯文本的块级节点,如段落、标题,然后将这些纯文本深加工,解析出其中包含的各种内联语法如强调、链接、行内代码等,并用相应的内联节点来替换原来的纯文本节点。
内联解析不是在块级解析的同时进行的,而是在块级解析完全结束之后才开始。它由 cmark_parser_finish()函数中的 process_inlines() 调用来启动:
c
// cmark.c
cmark_node *cmark_parser_finish(cmark_parser *parser) {
// 1. 闭合所有还开放的块
finalize(parser->root, parser->line_number);
// 2. 启动内联解析
process_inlines(parser->root, parser->refmap, parser->mem, parser->options);
// 3. 返回最终的、完整的 AST
return parser->root;
}与 blocks.c 的基于行不同, inlines.c 的工作模式是基于字符和基于节点的:
-
树遍历 :内联解析器首先会使用一个迭代器
cmark_iter来对 blocks.c 生成的 AST 进行一次深度优先遍历,它会访问树中的每一个节点。在遍历过程中,它会寻找那些可以包含内联元素并且其内容尚未被解析的块级节点。主要是CMARK_NODE_PARAGRAPH段落、CMARK_NODE_HEADING标题,这些节点的 literal 字段中存储着块级解析阶段收集到的原始文本 -
逐字符扫描 :一旦找到一个目标节点,内联解析器就开始逐个字符地扫描其 literal 字段中的文本内容。这个扫描过程由一个核心的
while循环驱动,循环中有一个巨大的 switch 语句,根据当前遇到的字符*,_,[,!,<,\等,来决定下一步的动作 -
定界符栈 :当解析器遇到一个
*或_时,它不仅仅是简单地寻找配对。它会创建一个"定界符"对象,记录下这个*的位置、它是左定界符还是右定界符、它可以打开<strong>还是<em>等信息。然后,它将这个定界符对象 压入一个栈中 。当遇到一个"右定界符"时,它会从栈顶开始 向后查找 ,寻找一个与之匹配的、可以配对的"左定界符"。如果找到了配对,它就会处理这对定界符之间的所有文本,将它们包裹在一个新的 strong 或 emph 节点中。这个基于栈的复杂机制,是 cmark 能够正确处理复杂嵌套和交错规则的关键
对于每一个需要处理的文本块, inlines.c 的主函数 S_parse_inlines 会执行以下流程:
-
初始化 :创建一个
cmark_inline_parser状态机,包含输入字符串的指针、当前位置、定界符栈等 -
主扫描循环:
while ((c = S_peek_char(inline_parser)) != 0)只要没到字符串末尾,就一直循环switch (c):- case \n:处理软换行或硬换行
- case `:调用 S_handle_backticks 处理行内代码
- case \:调用 S_handle_backslash 处理转义字符。
- case &:调用 S_handle_entity 处理 HTML 实体,如
& - case <:调用 scanners.c 中的函数,判断是 HTML 标签还是自动链接
- case [:这是一个链接文本的开始,压入定界符栈
- case !:检查后面是否是 [ ,如果是,则可能是图片
- case ]:这是一个链接文本的结束。触发 S_handle_close_bracket ,它会从定界符栈中寻找匹配的 [ ,并尝试解析链接的 URL 和标题部分
- case * / _:调用 S_handle_delim ,这是最复杂的部分。它会判断定界符的类型,并将其压入定界符栈。
- default:如果不是任何特殊字符,就将其作为普通文本处理,累加到一个 text 节点中。
-
后处理:当整个字符串扫描完毕后,定界符栈中可能还剩下一些未配对的定界符,比如只有一个 *。process_emphasis 函数会被调用,对整个定界符栈进行最后一次清算,尝试匹配所有可能的强调和加粗组合
-
构建子树:在上述过程中,新创建的内联节点(text , emph , link 等)会被链接成一个子链表 。当一个段落的所有内联元素都解析完毕后,这个新生成的内联节点子链表,会替换掉原来那个只包含一个纯文本节点的子节点
5. 渲染器
5.1 将 ATS 转换为 HTML
HTML 渲染器不会手动地去写 node->next 、node->child 这样的代码来手动遍历树。它使用 cmark 库自身提供的强大工具 cmark_iter。cmark_iter 是一个树的迭代器 。一旦创建就能以一种预定的、深度优先的顺序,精确地走遍 AST 的每一个节点。cmark_iter 的工作模式是深度优先遍历,并且在遍历过程中会产生事件。
迭代器在访问每个节点时,会产生两种核心事件:
CMARK_EVENT_ENTER:当迭代器第一次进入一个节点时(在访问其子节点之前)触发CMARK_EVENT_EXIT:当迭代器完成了对一个节点及其所有子节点的访问,准备离开这个节点时触发
HTML 渲染器的主循环就是一个 while 循环,不断地从迭代器获取下一个事件然后工作:
- 收到 ENTER 事件:根据当前节点的类型
cmark_node_type,输出它对应的 HTML 开标签 ,例如进入一个CMARK_NODE_STRONG节点,就输出<strong>,如果进入一个CMARK_NODE_LIST节点,就根据列表类型输出<ul>或<ol> - 收到 EXIT 事件:根据当前节点的类型,输出它对应的 HTML 闭标签。例如离开一个
CMARK_NODE_STRONG节点,就输出</strong>,如果离开一个CMARK_NODE_LIST节点,就输出</ul>或</ol>
这个流程在 cmark.3 手册页中有非常经典的代码示例:
c
#include "cmark.h"
void usage_example(cmark_node *root) {
cmark_event_type ev_type;
// 1. 创建一个指向 AST 根节点的迭代器
cmark_iter *iter = cmark_iter_new(root);
// 2. 循环推进迭代器,直到收到完成事件
while ((ev_type = cmark_iter_next(iter)) != CMARK_EVENT_DONE) {
// 3. 获取当前事件指向的节点
cmark_node *cur = cmark_iter_get_node(iter);
// 4. 根据事件类型和节点类型,执行操作
switch (ev_type) {
case CMARK_EVENT_ENTER:
printf("Entering node type: %s\\n", cmark_node_get_type_string(cur));
break;
case CMARK_EVENT_EXIT:
printf("Exiting node type: %s\\n", cmark_node_get_type_string(cur));
break;
default:
break;
}
}
// 5. 释放迭代器
cmark_iter_free(iter);
}当然,不是所有节点都这么简单:
-
叶子节点对于像
CMARK_NODE_TEXT、CMARK_NODE_CODE、CMARK_NODE_HTML_INLINE这样的叶子节点且每天子节点,渲染器在收到 ENTER 事件时,会直接输出它们的内容- 对于 TEXT 节点,内容会被进行 HTML 转义,例如,
&变成&,<变成<,以防止 XSS 攻击 - 对于
HTML_INLINE或HTML_BLOCK,如果不在安全模式下,其内容 原样输出
- 对于 TEXT 节点,内容会被进行 HTML 转义,例如,
-
带属性的节点 : 对于像
CMARK_NODE_LINK或图片CMARK_NODE_IMAGE这样的节点,在处理 ENTER 事件时,渲染器会:- 从节点中提取额外信息,如
cmark_node_get_url()和cmark_node_get_title() - 使用这些信息来构建一个带有属性的完整开标签,例如
<a href="URL" title="TITLE">
- 从节点中提取额外信息,如
示例
**Hello**的渲染流程:AST为paragraph -> strong -> text("Hello"):
- 渲染器创建一个指向 paragraph 根节点的迭代器
- while 循环开始 :
cmark_iter_next()-> 返回 ENTER , 节点是 paragraph,输出<p>cmark_iter_next()-> 返回 ENTER , 节点是 strong,输出<strong>cmark_iter_next()-> 返回 ENTER , 节点是 text,这是叶子节点,直接输出其内容Hellocmark_iter_next()-> 返回 EXIT , 节点是 strong,输出</strong>cmark_iter_next()-> 返回 EXIT , 节点是 paragraph,输出</p>cmark_iter_next()-> 返回 DONE- 循环结束 。最终输出的字符串是
<p><strong>Hello</strong></p>
总结来说,TO HTML 的核心逻辑就是一个优雅的、状态驱动的 AST 遍历过程。它通过响应迭代器产生的 ENTER 和 EXIT 事件,机械地、确定性地将结构化的节点树,转换为线性的 HTML 标签字符串。
6. 语法扩展的局限
cmark 本身是一个严格的 CommonMark 规范实现,它没有提供一套简单、公开的 API 来让开发者自定义新的 Markdown 语法。但是它的一个重要分支 cmark-gfm(GitHub Flavored Markdown),被设计成了一个可扩展的架构,这个可扩展架构的核心就是插件系统(Plugin System),它允许开发者编写自己的代码,来 Hook 到 cmark 的核心解析流程中,从而识别和处理新的块级和行内语法。其改造可以总结为以下几个核心机制:
- 引入插件注册表 ,维护了一个所有可用语法扩展的列表
cmark_find_syntax_extension(const char *name),允许解析器根据名字来查找并获取一个已注册的扩展 - 任何一个语法扩展都必须实现结构体
cmark_syntax_extension,它里面包含了一系列的函数指针,相当于告诉 cmark 内核如何识别与解析、AST 节点操作和如何渲染 - 在核心解析流程中设置 Hook ,在关键决策点(如
blocks.c和inlines.c)安插了 Hook- 块级解析:当解析器处理新的一行时,它不再仅仅检查是否是
>或###。它会额外地去问所有附加的扩展是否认识这行开头的语法,如果有扩展认领了,那么解析的控制权就暂时交给了该扩展的解析函数 - 行内解析:当行内解析器扫描文本时,它会维护一个包含所有扩展触发字符的"速查表"。当遇到一个字符时,它不仅会检查是否是
[或*,还会检查它是否是某个扩展的触发字符
- 块级解析:当解析器处理新的一行时,它不再仅仅检查是否是
- 使解析器可配置 ,允许开发者使用
cmark_parser_attach_syntax_extension(cmark_parser *parser, cmark_syntax_extension *extension)在运行时将一个或多个语法扩展附加到一个特定的解析器实例上
通过这套机制, cmark-gfm 将一个原本封闭的解析流程,变成了一个开放的、可插拔的平台。
cmark-gfm 的插件系统是另一个话题,并非本文探讨的重点。我们在此提及主要是为了凸显 cmark 核心库在设计上的权衡:它为了追求对 CommonMark 规范的极致忠诚与性能,选择性地牺牲了开箱即用的扩展能力。对于 cmark-gfm 扩展开发感兴趣的读者,最好的学习起点是直接阅读其 src/extensions/ 目录下的源码,尤其是 strikethrough.c(删除线)等实现清晰的范例。
三、总结
对 cmark 策略源码的深入探索,不仅让我们理解了 Markdown 解析的具体实现,更揭示了一个优秀项目从宏观的架构设计到微观的算法实现,cmark 其核心设计可以总结为以 AST 为核心两阶段解析策略,确保确定与无歧义。cmark 不仅仅是一个 Markdown 解析器,它更是一个关于如何将一份详尽的自然语言规范,转化为精确、健壮且高效的计算机代码的经典范例。对于任何希望构建语言解析器或处理结构化文本的开发者来说,cmark 的源码都是一本不可多得的教科书。