一、Kuberntes架构
1.宏观架构
- Master node(控制面):集群管理者
- Worker node(数据面):工作节点,运行用户的任务
2.微观架构

3.主要组件
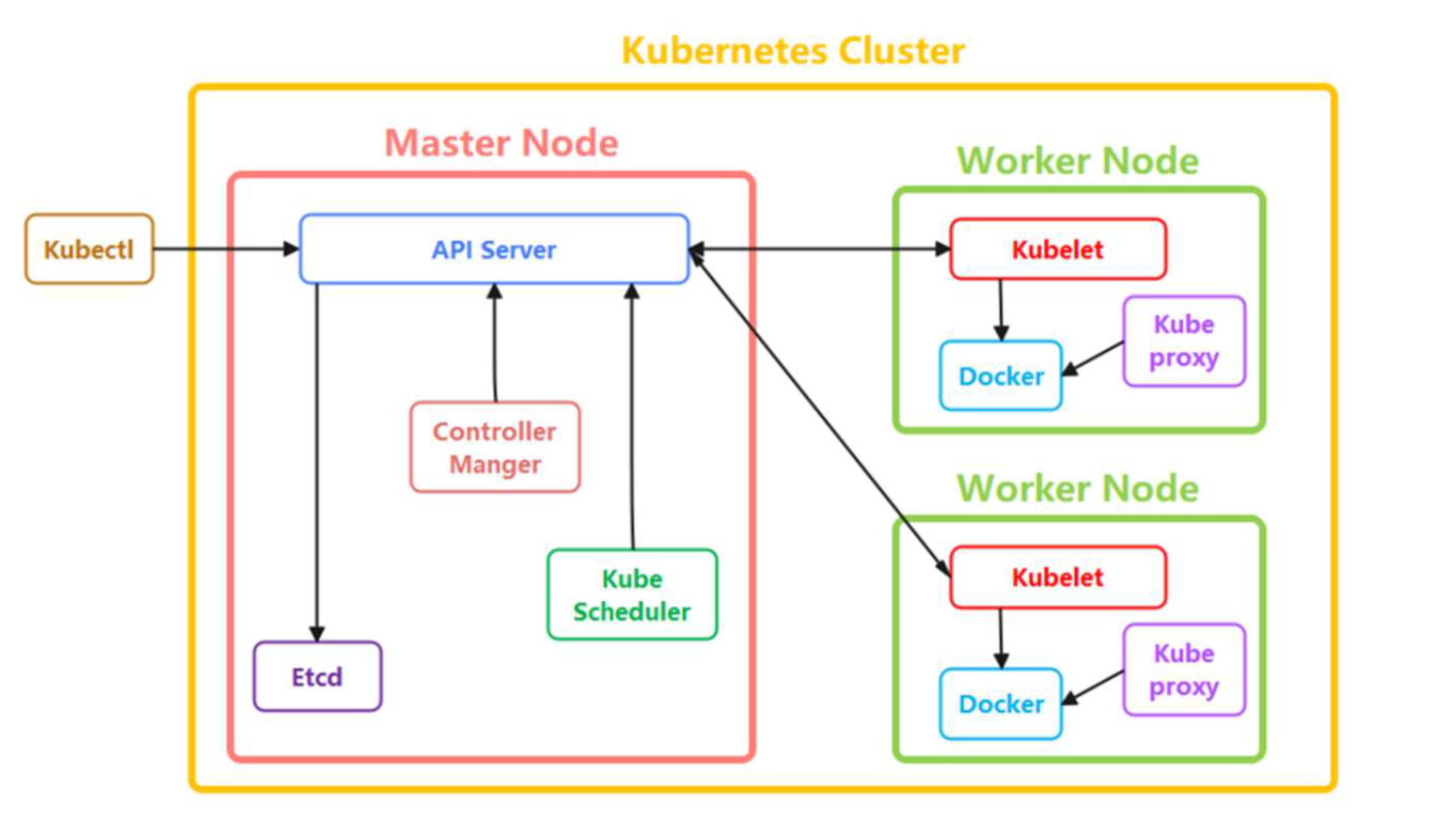
Master node(控制面)组件:
- kube-apiserver:整个 Kubernetes 系统的唯一入口;加上了验证、授权等功能;所有其他组件都只能和它直接通信
- kube-scheduler:负责容器的编排工作,检查节点的资源状态,把 Pod 调度到最适合的节点上运行
- kube-controller-manager:负责维护容器和节点等资源的状态,实现故障检测、服务迁移、应用伸缩等功能
- etcd:采用Raft分布式共识算法;分布式 Key-Value 数据库;持久化存储系统里的各种资源对象和状态;只与 apiserver 有直接联系
Worker node(数据面)组件:
- kubelet :实现状态报告、命令下发、启停容器等功能,负责 Pod 生命周期管理,执行任务并将 Pod 状态报告给 Master 节点
- kube-proxy:是 Node 的网络代理,只负责管理容器的网络通信
- CR ( Container Runtime ):容器和镜像的实际使用者,在 kubelet 的指挥下创建容器,管理 Pod 的生命周期
4.工作流程
-
每个 Node 上kubelet会定期向 kube-apiserver 上报节点状态,kube-apiserver 再存到 etcd 里
-
每个 Node 上的 kube-proxy 实现了 TCP/UDP 反向代理,让容器对外提供稳定的服务
-
kube-scheduler 通过 kube-apiserver 得到当前的节点状态,调度 Pod,然后 kube-apiserver 下发命令给某 个 Node 上的 kubelet,kubelet 调用 container-runtime 启动容器
-
controller-manager 也通过 kube-apiserver 得到实时的节点状态,监控可能的异常情况,再使用相应的手段去调节恢复
5.功能插件
- DNS: 负责为整个集群提供DNS服务
- Ingress Controller:为服务提供外网入口
- MetricsServer:提供资源监控
- Dashboard:提供GUI
二、Kubernetes 集群部署
1.Kubeadm
- Kubernetes 管理员
- Kubeadm 是用容器和镜像来封装 Kubernetes 的各种组件
- 轻松地在集群环境里部署 Kubernetes
2.环境准备
(1)所需服务器
|-----------|--------|---------------|------|------|----------------|
| 角色 | 主机名 | IP | 最小配置 | 建议配置 | 操作系统 |
| Master 节点 | master | 192.168.5.110 | 2C4G | 2C4G | Rockylinux 9.4 |
| Worker 节点 | worker | 192.168.5.120 | 2C2G | 2C4G | Rockylinux 9.4 |
(2)关闭防火墙&&SELinux
# 关闭防火墙,并禁止开机自动运行
systemctl disable --now firewalld
# 设置 SELinux 的执行模式。0 表示关闭 SELinux。
setenforce 0
# 修改 SELinux 配置文件 /etc/selinux/config ,禁用 SELinux
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config(3)关闭交换分区
swapoff -a; sed -i '/swap/d' /etc/fstab(4)配置时钟同步
dnf -y install chrony
# 修改配置文件 /etc/chrony.conf ,添加如下行
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
# 启动服务
systemctl restart chronyd
systemctl enable chronyd
# 检查状态
chronyc tracking(5)修改内核参数
[root@localhost ~]# cat >>/etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
# net.ipv4.ip_forward = 1 启用了IPv4的IP转发功能,允许服务器作为网络路由器转发数据包。
# net.bridge.bridge-nf-call-iptables = 1 当使用网络桥接技术时,将数据包传递到iptables进行处理。(6)配置hosts本地解析
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.5.110 master
192.168.5.120 worker
EOF(7)安装容器运行时
dnf install -y yum-utils
# 使用 阿里云仓库
dnf config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装 containerd
dnf -y install containerd.io-1.7.25(8)修改 containerd 配置文件
# 创建默认配置文件
cd /etc/containerd
mv config.toml config.toml.orig
containerd config default > /etc/containerd/config.toml
# 修改 Containerd cgroup 配置
sed -i "s#SystemdCgroup\ \=\ false#SystemdCgroup\ \=\ true#g" /etc/containerd/config.toml
# grep -i SystemdCgroup /etc/containerd/config.toml
# SystemdCgroup = true # false 改为 true
# 修改 sandbox 沙箱镜像地址(就是 pause 镜像地址)
sed -i "s#registry.k8s.io#registry.aliyuncs.com/google_containers#g" /etc/containerd/config.toml
# grep -i sandbox_image /etc/containerd/config.toml
# sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.8"
# 修改镜像仓库 从 registry.k8s.io 修改为 阿里云 (9)启动 containerd 服务
systemctl enable --now containerd
systemctl status containerd
ctr version (10)nerdctl命令行工具
# Kubernetes 容器运行时 从 Docker 切换到 Containerd 之后,使用 ctr 或 crictl 命令管理容器和镜像都不方便,今天我们使用一个新的命令行工具 nerdctl
# 下载
# wget https://github.com/containerd/nerdctl/releases/download/v2.0.3/nerdctl-2.0.3-linux-amd64.tar.gz
# 解压
# tar Cxzvvf /usr/local/bin nerdctl-2.0.3-linux-amd64.tar.gz(11)安装kubeadm和k8s组件
# k8s 官方的仓库访问受限,我们使用阿里云的仓库
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/repodata/repomd.xml.key
EOF
dnf install -y kubeadm-1.32.2 kubelet-1.32.2 kubectl-1.32.2
systemctl enable --now kubelet3.Master 节点初始化
(1)生成初始化的配置文件
kubeadm config print init-defaults > kubeadm-config.yaml(2)修改配置文件
# 默认生成的kubeadm初始化配置文件 kubeadm-config.yaml 需要修改以下内容:
localAPIEndpoint:
advertiseAddress: 192.168.5.110 # 修改为 master节点IP地址,如果使用公有云,配置虚机的内网地址
bindPort: 6443
... ...
imageRepository: registry.aliyuncs.com/google_containers # 修改为阿里云镜像仓库
kind: ClusterConfiguration
kubernetesVersion: 1.32.2 # # 需要安装的 k8s 版本号
networking:
dnsDomain: cluster.local
serviceSubnet: 192.168.111.0/24 #(真实机的网段,即网络的网段)
podSubnet: 172.17.0.0/16 # 添加 pod 网络 CIDR 地址(容器的网段)(3)下载集群初始化所需镜像
# 查看 Kubernetes 初始化需要用到的镜像
[root@master-01 ~]# kubeadm config --config=kubeadm-config.yaml images list
# 下载初始化需要用的镜像
[root@master-01 ~]# kubeadm config --config=kubeadm-config.yaml images pull
# 查看下载后的镜像 使用 ctr 命令
[root@master-01 ~]# ctr -n k8s.io image list (4)集群初始化
kubeadm init --config=kubeadm-config.yaml
# 配置 kubectl 的认证文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 验证集群
[root@master-01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 2m21s v1.32.2(5)Worker 节点加入集群
注:在worker节点执行命令
kubeadm join 192.168.5.110:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:9feaeaba353c4ca994ce329e4bb65600c93a37a28acfd90f64b5a2fb9226fb97注:在master节点查看
[root@localhost ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
worker NotReady <none> 55s v1.32.2
master NotReady control-plane 6m45s v1.32.24.安装网络插件
注:在 master 节点执行,实现跨节点的网络容器之间的通信
# 我们使用 Calico 网络插件,calico 用到的镜像在 hub.docker.com 上,国内需要配置加速器,或者导入离线镜像
# 导入镜像, ctr 是 containerd 的客户端命令(每个节点都要导),压缩包从资源仓库下载
ctr -n k8s.io image import calico-3.29.2.image
# 下载 calico YAML 文件
curl https://raw.githubusercontent.com/projectcalico/calico/v3.29.2/manifests/calico.yaml -O
# 安装 calico 插件 (只在master节点上执行)
kubectl create -f calico.yaml 最终结果:
[root@localhost ~]# kubectl get pods -A -w
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-77969b7d87-75wvq 1/1 Running 0 37s
kube-system calico-node-l7xxv 1/1 Running 0 37s
kube-system calico-node-zdtq9 1/1 Running 0 37s
kube-system coredns-6766b7b6bb-c8ldf 1/1 Running 0 20m
kube-system coredns-6766b7b6bb-vhfqf 1/1 Running 0 20m
kube-system etcd-master 1/1 Running 0 20m
kube-system kube-apiserver-master 1/1 Running 0 20m
kube-system kube-controller-manager-master 1/1 Running 0 20m
kube-system kube-proxy-q6fg8 1/1 Running 0 20m
kube-system kube-proxy-t8gsz 1/1 Running 0 14m
kube-system kube-scheduler-master 1/1 Running 0 20m
# 此时集群初始化完毕
[root@localhost ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
worker Ready <none> 15m v1.32.2
master Ready control-plane 21m v1.32.2
# 控制面组件状态显示 Healthy
[root@localhost ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy ok 5.常见故障处理
(1)镜像拉取失败
- 如果 Pod 状态显示
ImagePullBackOff,表示容器所有的节点 镜像拉取失败,需要到对应节点上手动拉取镜像或者导入离线镜像即可

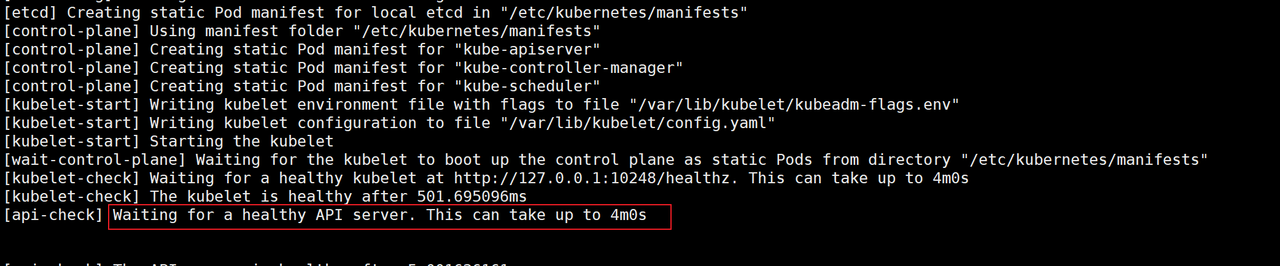
(2)Master 节点初始化失败
- 在 master 节点初始化过程中,常见的故障是 卡在如下界面,此处是正在等待 kube-apiserver 启动成功,如果apiserver启动失败,这里会一直等待,直到4分钟超时会有报错。
- 排错的时候需要查看 messages 日志定位具体原因,在初始化的过程中建议打开一个shell 终端运行
tail -f /var/log/messages命令,注意观察报错信息
(3)Worker 节点加入集群失败
- Worker 节点在加入集群过程中需要成功运行 kubelet 服务,再连接 kube-apiserver,任何一步失败都无法加入集群
- 因此在执行 kubeadm join 时也需要打开一个shell 终端运行
tail -f /var/log/messages命令,观察日志中的报错信息

(4)重置集群
-
如果找到了报错原因,需要重新初始化集群或是worker节点重新加入集群, 都需要先执行
kubeadm init或是kubeadm join[root@localhost ~]# kubeadm reset
[reset] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[reset] Use 'kubeadm init phase upload-config --config your-config.yaml' to re-upload it.
W1114 20:55:10.703433 38960 preflight.go:56] [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]:
(5)重新生成 join 命令
-
初始化时生成的 kubeadm join 命令,有效期是 24 小时,超时后命令中的token 就失效了,如果 24小时后有节点加入集群, 我们需要执行以下命令,重新生成可用的 token
kubeadm token create --print-join-command