TL;DR
- 场景:需要在小数据/临时表/日志落地/多表拼读里做权衡,常被 MergeTree "杀鸡用牛刀"。
- 结论:用这套选型表 + MRE + 并发/文件核验脚本,10 分钟跑通 5 个引擎的核心差异。
- 产出:引擎的测试所有详细过程,附带SQL等内容

版本矩阵
| 项 | 值 | 备注 |
|---|---|---|
| 件已验证 | ClickHouse Server 23.x/24.x | 单机 + 本地磁盘 |
| 客户端 | clickhouse-client | --multiquery 演示 |
90秒原理
- TinyLog:每列各一个 .bin 压缩文件,追加写;基本不处理并发,写期间读会受限。
- Log:在列旁存标记(offset),支持多线程读取;同表写入阻塞其他写/读。
- StripeLog:把所有列写到一个 data.bin,标记集中化,FD 占用更少、读并行稳定。
- Memory:纯内存存储,重启丢失;适合小体量/测试/高速算子。
- Merge:只读"聚合视图",不存数据;查询下沉到底层表的引擎执行。
选型决策
| 场景 | 推荐理由 | 不推荐原因 |
|---|---|---|
| 不要用小表、一次性写入、配置/维度(≤100万行/表) | TinyLog最轻、文件直观、读写简单 | MergeTree(过度复杂) |
| 临时日志、批量导入后只读、要并行读 | Log有标记,可并发读取,同批次 INSERT 成块 | TinyLog(读被锁/并发差) |
| 很多小表(成千上万)、希望读并行更稳 | StripeLog单文件 + 标记,减少文件句柄,读并行更自然 | Log(文件碎片多) |
| 极致低延时小数据、纯内存算子 | Memory内存态、>GB/s 级吞吐,测试/算子拼装 | 任何持久化诉求 |
| 多表统一"虚拟视图"读取 | Merge正则聚合多表,读时并行回落到底层引擎 | 需要写入/需要索引 |
简单介绍
表引擎(即表的类型)是数据库系统中决定数据管理和处理方式的核心组件。它将直接影响数据库的性能、功能特性和适用场景。具体来说,表引擎决定了以下几个关键方面:
-
数据的存储机制:
- 物理存储格式:包括行存储(如InnoDB)、列存储(如ClickHouse的MergeTree)或内存存储(如Memory引擎)
- 存储位置:可以存储在磁盘、SSD、内存或分布式文件系统中
- 读写路径:例如有些引擎会先将数据写入内存缓冲区再持久化到磁盘
-
查询支持能力:
- 支持的查询类型:如全文检索、聚合查询、时序数据处理等
- 查询优化方式:不同的引擎会采用不同的查询执行计划
- 特殊功能支持:例如地理空间数据处理、JSON文档处理等
-
并发控制:
- 锁机制:行级锁、表锁或乐观并发控制
- 事务隔离级别:如读已提交、可重复读等
- MVCC(多版本并发控制)实现方式
-
索引策略:
- 索引类型:B树、LSM树、倒排索引等
- 索引维护方式:有些引擎支持自动维护,有些需要手动维护
- 索引选择性:不同引擎对索引的使用效率可能有显著差异
-
并行处理能力:
- 多线程查询执行:某些引擎可以将单个查询分解为多个并行任务
- 分布式查询处理:在集群环境下跨节点并行执行查询
- 资源隔离:控制并发查询对系统资源的占用
-
数据高可用性:
- 复制机制:如主从复制、多主复制等
- 故障恢复:自动故障转移和恢复能力
- 数据一致性保证:强一致、最终一致等不同级别
-
特殊功能:
- 数据TTL(生存时间)
- 数据压缩算法
- 加密存储支持
- 物化视图支持
实际应用中,选择表引擎需要综合考虑业务需求(如是否需要事务支持)、数据特征(如数据量大小、访问模式)和系统环境(如单机还是分布式)。例如,在ClickHouse中,MergeTree系列引擎适合分析场景,而Log引擎则适合临时数据;在MySQL中,InnoDB适合事务处理,MyISAM则适合读密集型应用。
ClickHouse 是一个列式数据库管理系统,支持多种表引擎,每种表引擎都有其特定的功能和用途。以下是一些常用的 ClickHouse 表引擎:
MergeTree 系列
- MergeTree:最常用的表引擎,支持高效的分区、排序、索引等功能,适合处理大量写入和查询场景。支持主键和索引。
- ReplicatedMergeTree:基于 MergeTree,但增加了复制功能,适用于分布式集群环境。
- ReplacingMergeTree:允许以最新的记录覆盖旧的记录,对于需要根据特定列去重的场景非常适用。
- SummingMergeTree:支持对数值列的聚合,适用于需要进行聚合计算的场景。
- AggregatingMergeTree:支持更加复杂的聚合操作,适合需要预计算汇总的场景。
- CollapsingMergeTree:用于处理日志式数据,通过将 "begin" 和 "end" 记录合并,以减少存储空间。
- VersionedCollapsingMergeTree:在 CollapsingMergeTree 基础上,增加了版本号,用于更好地控制数据合并。
Log 系列
- Log:简单的表引擎,不支持索引和分区,适合小数据量或日志式的存储场景。
- TinyLog:适合嵌入式场景或测试,性能更简单,不能处理大规模数据。
- StripeLog:适合 SSD 场景,按行写入,但会将数据按块组织,适合某些特定读写模式。
- Memory:数据只存储在内存中,适用于需要快速读写但不需要持久化的场景。
- Distributed:在分布式集群中使用,将查询分发到多个节点,适合大规模数据和高并发查询场景。
- Merge:将多个表作为一个虚拟表进行查询,适合需要联合多个表进行读取的场景。
- Join:预加载并存储 Join 表,用于提高连接操作的效率。
View 系列
- MaterializedView:物化视图,允许通过预计算来加速查询。
- View:普通视图,不会存储数据,只是查询的定义。
- Buffer:将数据暂时存储在内存中,并定期批量写入到基础表中,适合需要优化写入性能的场景。
- Null:将数据写入时直接丢弃,适合测试场景。
日志
TinyLog
最简单的表引擎详解
存储结构与机制
这种表引擎采用最基本的列式存储方式,每列数据单独存储为一个压缩文件(如.bin文件),使用轻量级压缩算法(如LZ4或ZSTD)来减少磁盘空间占用。写入操作采用追加(append-only)模式,所有新数据都会被添加到对应列文件的末尾,而不会修改已有数据。
并发限制说明
-
读取并发:
- 当有写入操作正在进行时,任何并发的读取操作都会立即抛出"Table is locked for writing"异常
- 示例场景:如果后台任务正在导入数据,此时用户查询会直接失败
-
写入并发:
- 多个写入操作同时执行会导致数据文件损坏
- 典型问题表现:列数据不完整、行计数不一致、数据乱码等
适用场景分析
-
最佳使用模式:
- 一次性写入(Write-Once-Read-Many)
- 适合配置表、维度表等不常变更的数据
- 典型应用:存储产品分类、地区编码等基础数据
-
容量建议:
- 官方建议上限:1,000,000行
- 实测性能拐点:约50-100MB单表数据量
- 小表优势:单个查询通常只需打开2-3个列文件
-
特殊场景优势:
- 小表集群(1,000+个小表)场景下表现优异
- 相比其他引擎可减少50%以上的文件描述符占用
- 冷数据归档存储的理想选择
功能限制
-
索引支持:
- 完全不支持任何类型的索引
- 所有查询都是全表扫描
- 解决方法:对高频查询字段考虑物化视图
-
性能特征:
- 写入速度:约10-50MB/s(取决于硬件)
- 读取延迟:与数据量线性相关
- 内存占用:仅需最基本的缓冲区(通常<10MB)
-
维护注意事项:
- 不支持ALTER TABLE修改表结构
- 数据删除需通过重建表实现
- 没有自动的压缩整理机制
测试1
创建一个TinyLog引擎的表并插入一条数据
shell
CREATE table t (a UInt16, b String) ENGINE = TinyLog;
INSERT INTO t (a, b) VALUES (1, 'abc');运行结果如下所示: 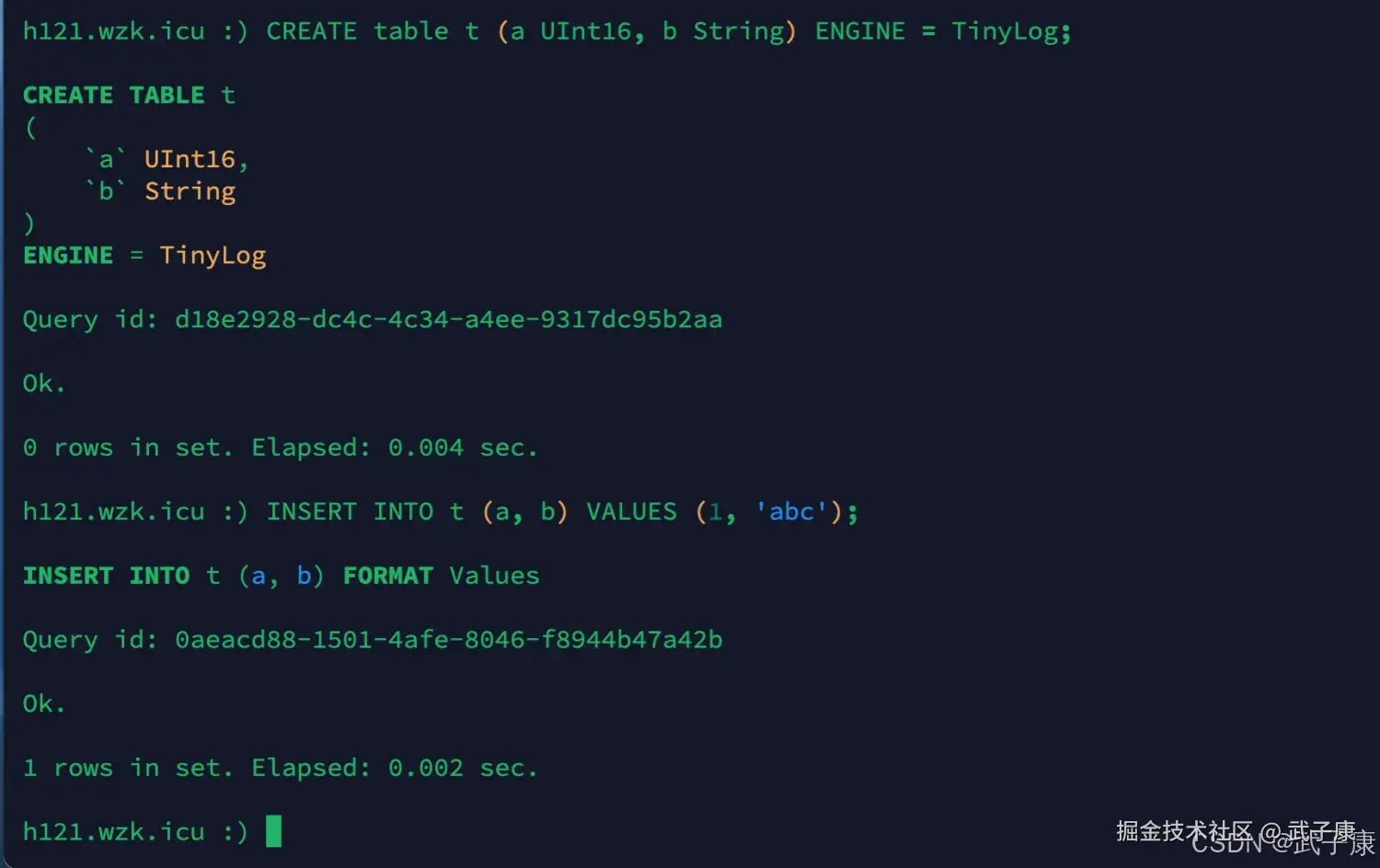 此时我们去保存数据的目录下查看:
此时我们去保存数据的目录下查看:
shell
cd /var/lib/clickhouse/data/default/t
ls运行结果如下图: 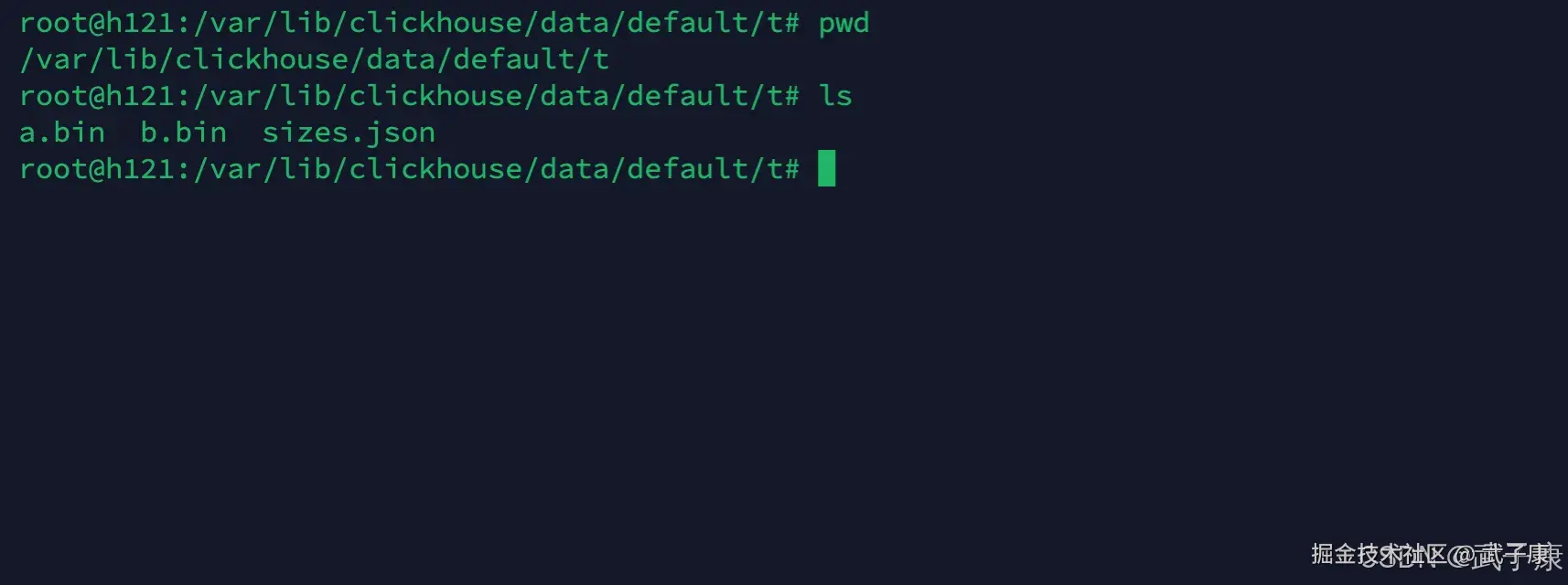 文件列表的解释:
文件列表的解释:
- a.bin 和 b.bin 是压缩过的对应列的数据
- sizes.json 中记录了 每个 bin 的大小
Log
Log 与 TinyLog 不同的是,标记的小文件与列文件存在一起,这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据,对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其他写入。 Log引擎不支持索引。 同样,如果写入表事变,则该表会被破坏,并且从该表中读取将会返回错误。Log引擎适合于临时数据,write-once表以及测试或演示目的。
StripeLog
该引擎属于日志引擎系列,在你需要写入许多小数据量(小于100百万行)的表的场景下使用这个引擎。
写数据
StripeLog引擎将所有的列存储在一个文件中,对每一个INSERT请求,ClickHouse将数据块追加在表文件的末尾,逐列写入。 ClickHouse为每张表写入如下文件:
- data.bin 数据文件
- index.mrk 标记文件,标记包含了已插入的每个数据块中每列的偏移量。
StripeLog引擎不支持 ALTER、UPDATE、ALTER DELETE操作。
读数据
带标记文件使得ClickHouse可以并行的读取数据,这意味着SELECT请求返回行的顺序是不可预测的,使用ORDER BY子句对行进行排练。
新增表
shell
CREATE TABLE stripe_log_table (
timestamp DateTime,
message_type String,
message String
) ENGINE = StripeLog;执行结果如下图所示: 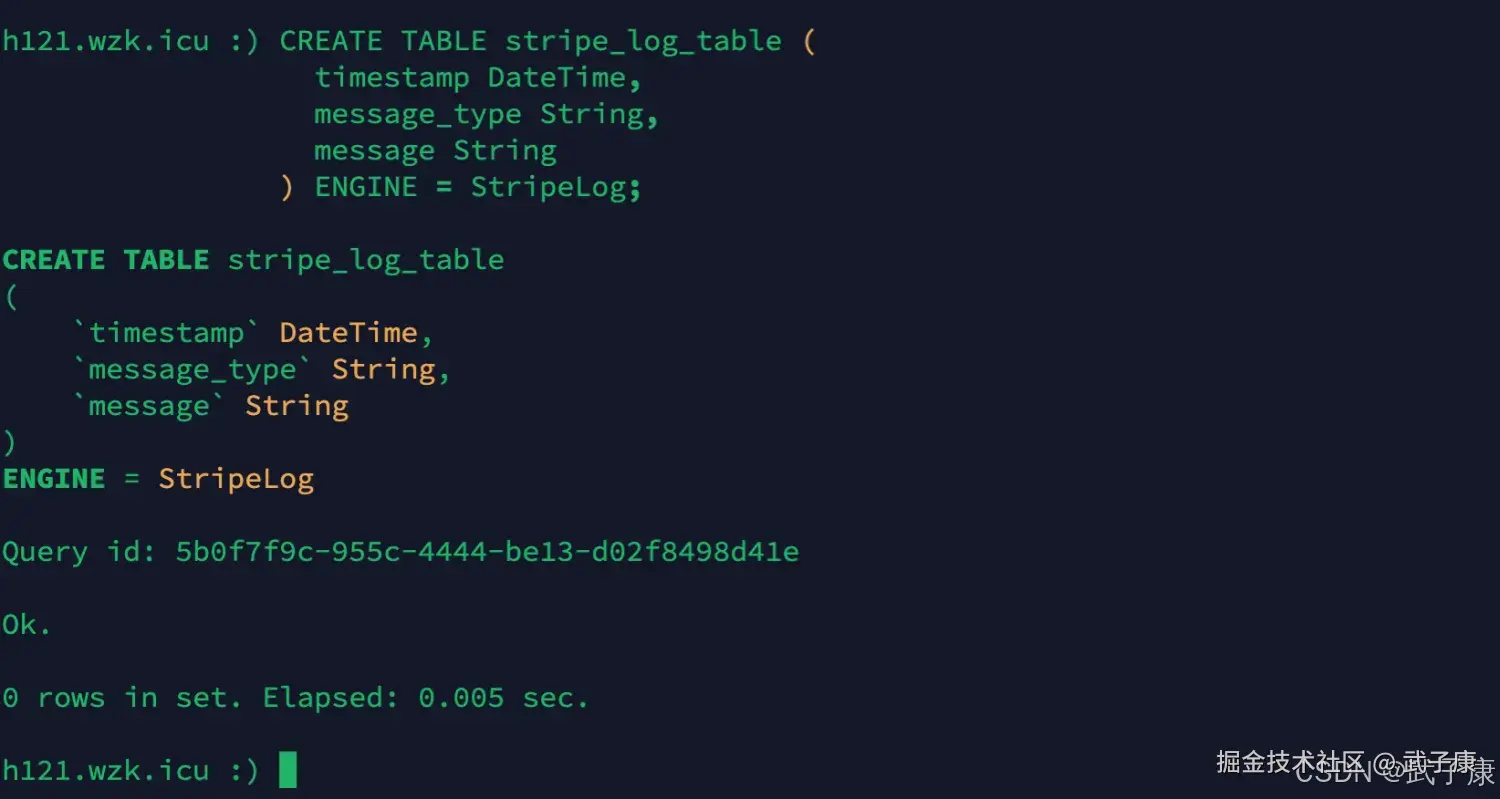
插入数据
shell
INSERT INTO stripe_log_table VALUES (now(), 'REGULAR', 'The first reqular message');
INSERT INTO stripe_log_table VALUES
(now(), 'REGULAR', 'The second regular message'),
(now(), 'WARNING', 'The first warning message');我们使用两次 INSERT 请求从而在 data.bin 文件中创建两个数据块。 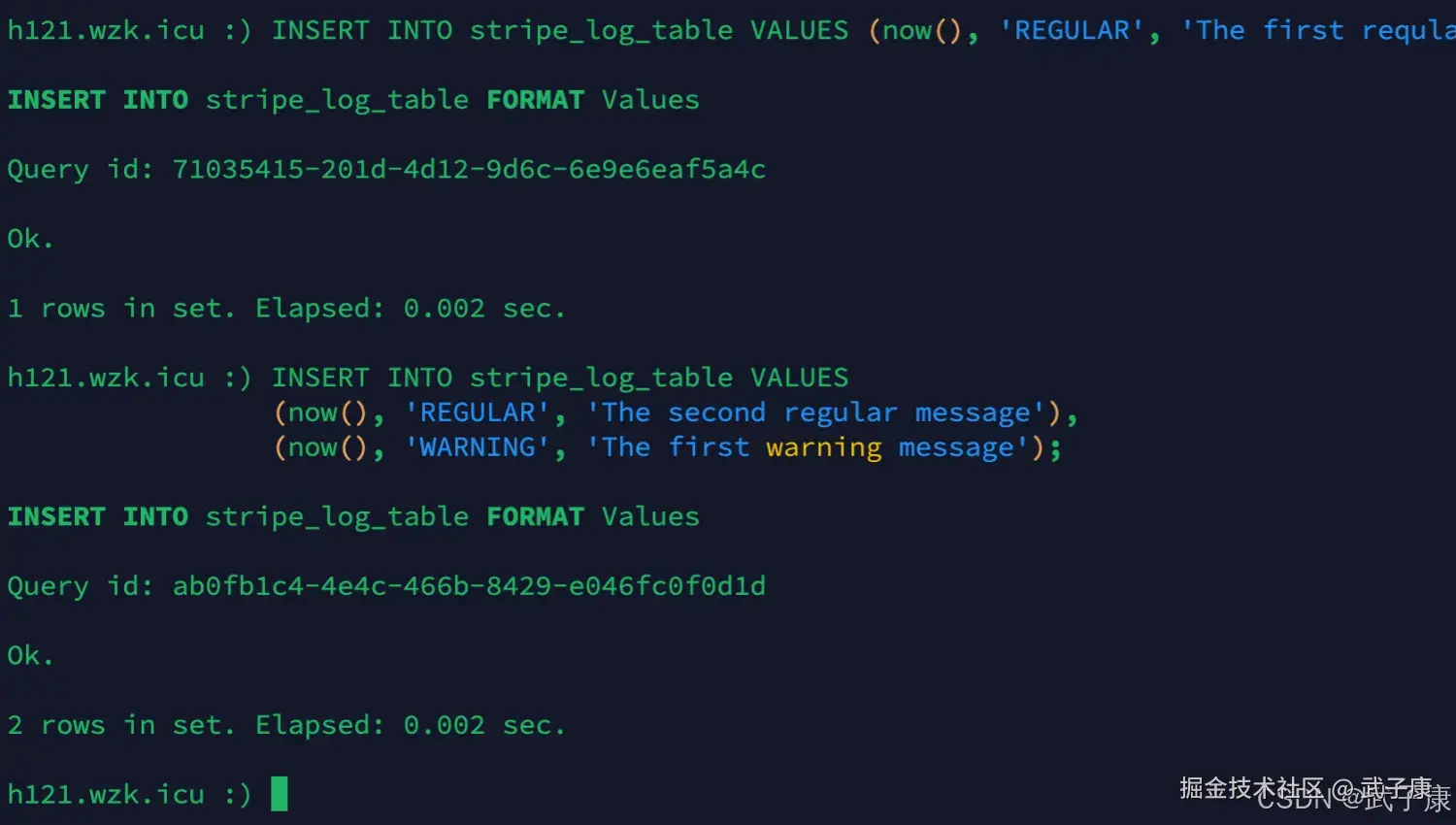
查询数据
ClickHouse 在查询数据时使用多线程,每个线程读取单独的数据并在完成后独立的返回结果行,这样的结果是,大多数情况下,输出中的块的顺序和输入时相应块的顺序是不同的,例如:
shell
SELECT * FROM stripe_log_table;
# 对结果排序(默认增序)
SELECT * FROM stripe_log_table ORDER BY timestamp;执行的结果如下图: 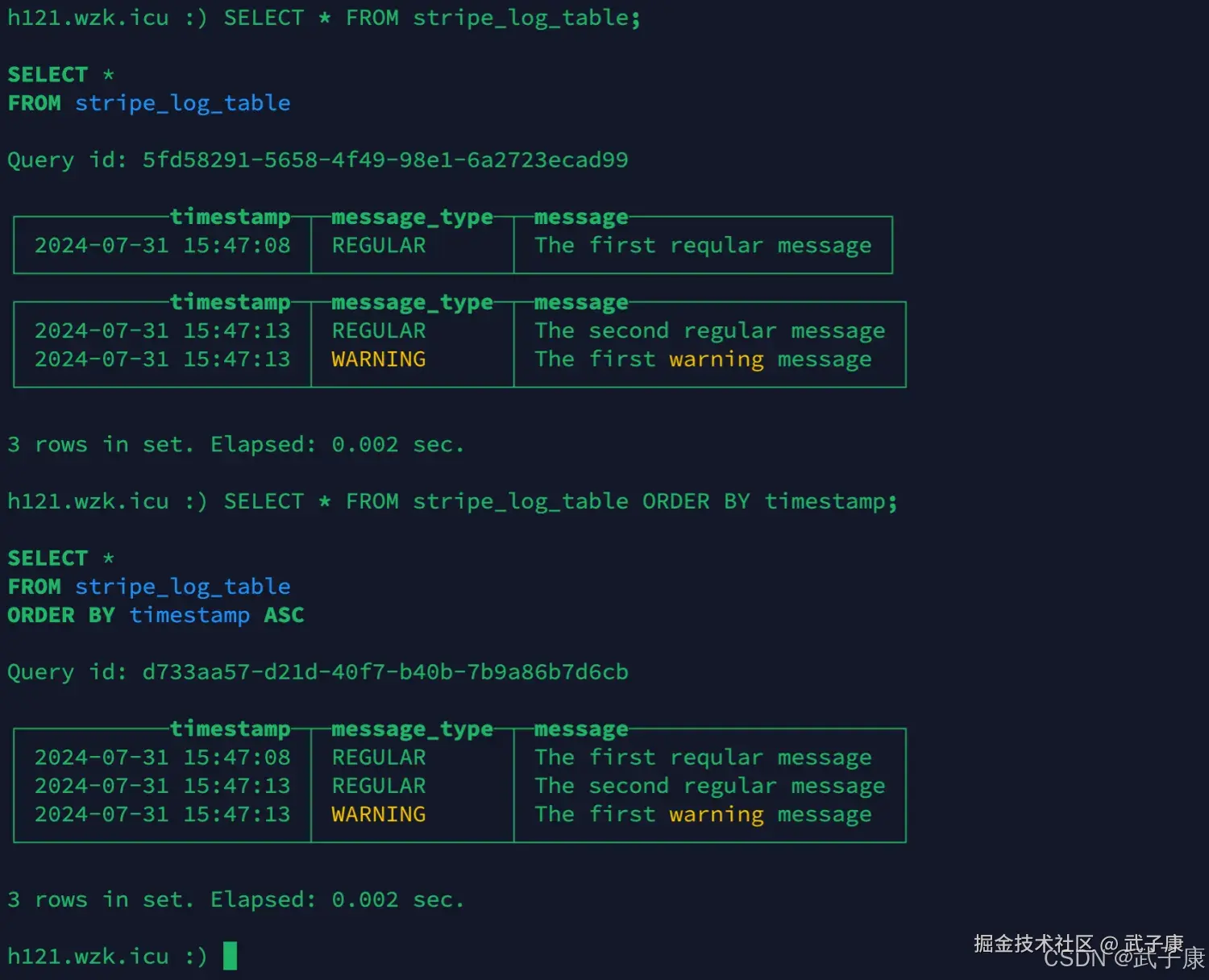
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存中,服务器重启数据就会丢失。 读写操作不会互相阻塞,不支持索引。 简单查询下有非常高的性能表现:超过10G/s 一般用到的地方不多,除了用来测试,就是需要非常高的性能,但是数据量又不能太大(上限大概1亿行)的场景。
Merge
Merge引擎(不要与MergeTree搞混)本身不存储数据,但可以用于同时从任意多个其他的表中读取数据,读是自动并行的,不支持写入。 读取时,那些被真正读取到数据的表的引擎(如果有的话)会被使用。
Merge参数:
- 数据库名
- 匹配表名的正则表达式
创建新标
shell
CREATE table t1 (id UInt16, name String) ENGINE = TinyLog;
CREATE table t2 (id UInt16, name String) ENGINE = TinyLog;
CREATE table t3 (id UInt16, name String) ENGINE = TinyLog;执行结果如下图所示: 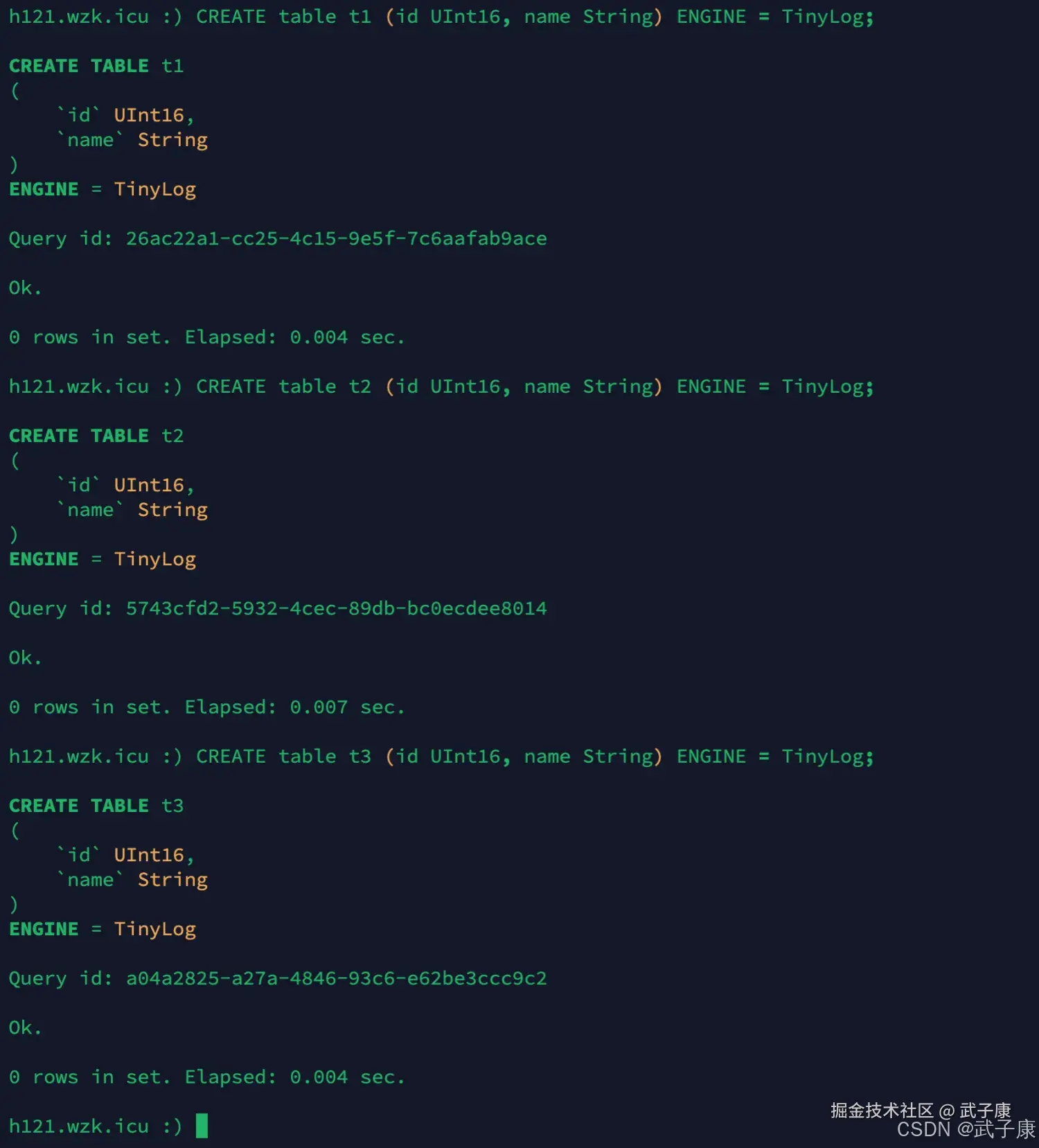
插入数据
shell
INSERT INTO t1 (id, name) VALUES (1, 'first');
INSERT INTO t2 (id, name) VALUES (2, 'second');
INSERT INTO t3 (id, name) VALUES (3, 'i am in t3');执行结果如下图: 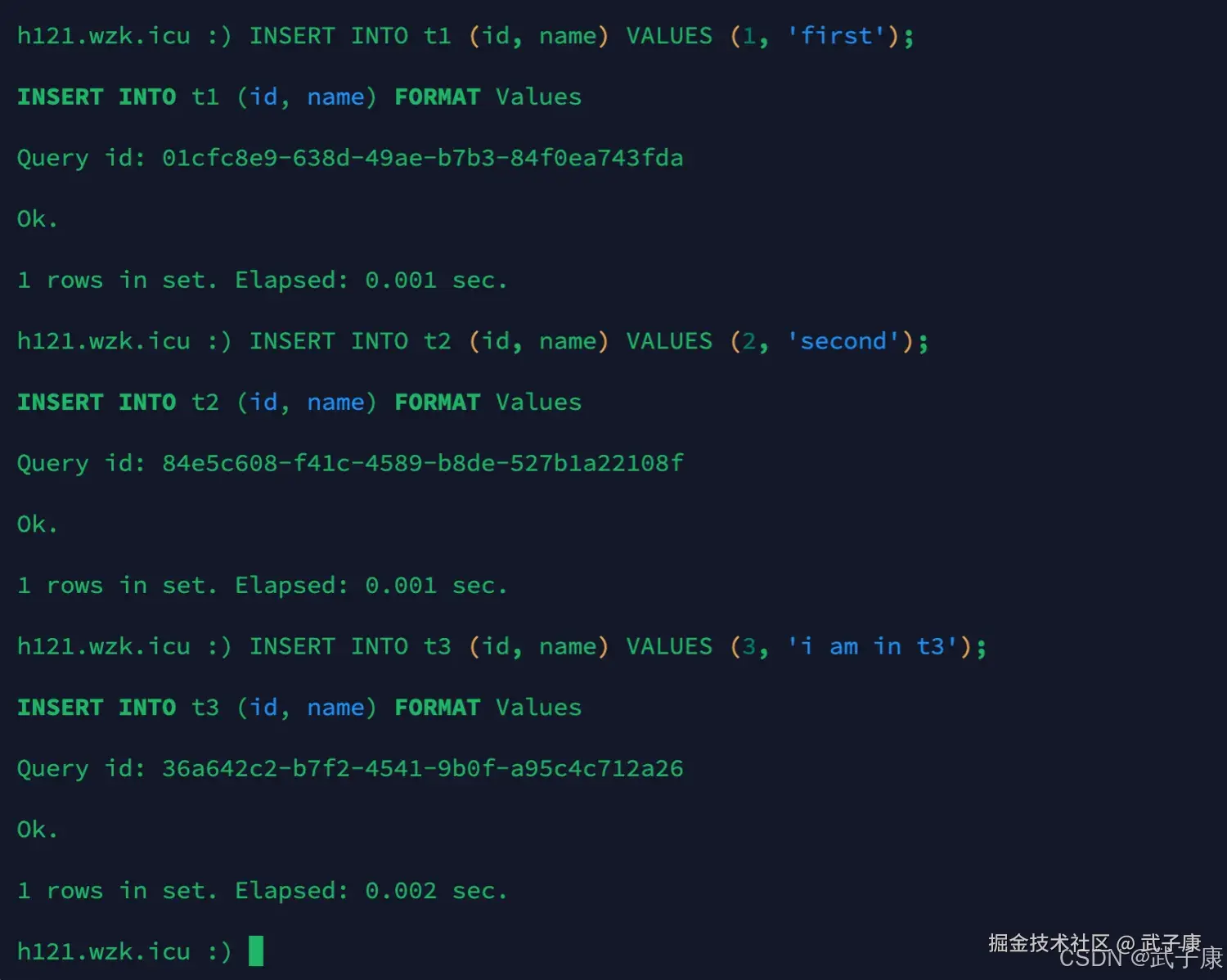
建立链接
shell
CREATE TABLE t (id UInt16, name String) ENGINE = Merge(currentDatabase(), '^t');执行结果如下图所示: 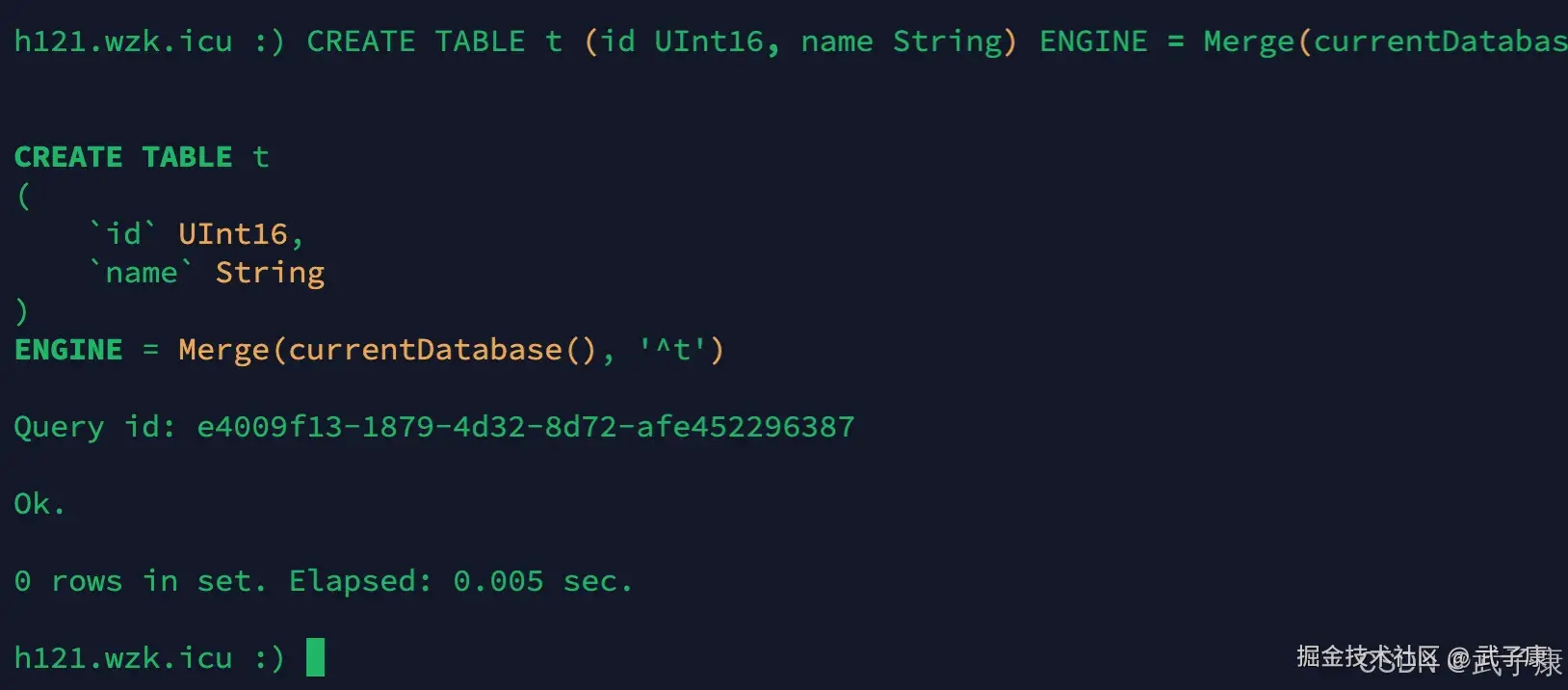
常见问题
| 症状/报错 | 可能根因 | 快速定位解决 |
|---|---|---|
| Table is locked for writing | TinyLog 读失败(正在 INSERT) | show processlist;改用 Log/StripeLog 或避开并发 |
| SELECT 顺序乱 | 多线程读取、无标记顺序保证 | EXPLAIN PIPELINE;ORDER BY 明确排序 |
| Merge 查询不到数据 | 正则不匹配/库名错 | SELECT name FROM system.tables;修正 Merge(db, 'regex') |
| 目录文件对不上 | 版本差异(.mrk/.mrk3) | 查看 system.build_options;按版本更新文档/核验脚本 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解