文章目录
摘要
本周学习了Swin-Transformer和MAE两篇论文,了解了Swin-Transformer的做法和MAE的做法。
Abstract
This week, I studied two papers: Swin-Transformer and MAE, gaining an understanding of the approaches of both Swin-Transformer and MAE.
1 Swin-Transformer
1.1 相关背景
swin-transformer可以用作视觉任务的骨干网络,在ViT之后,transformer应用于视觉领域是可行的,但是ViT的论文只是在分类任务上进行了实现,对于检测等视觉任务没有进行实现,然后swin-transformer来解决了这些问题。这篇论文想证明transformer可以用于所有视觉任务,不仅仅是分类。在检测、分割上也可以获得很好的结果。
transformer从NLP应用到vision的挑战:1.图片中不同的物体大大小小是不一样的。2.图像的像素太多了。
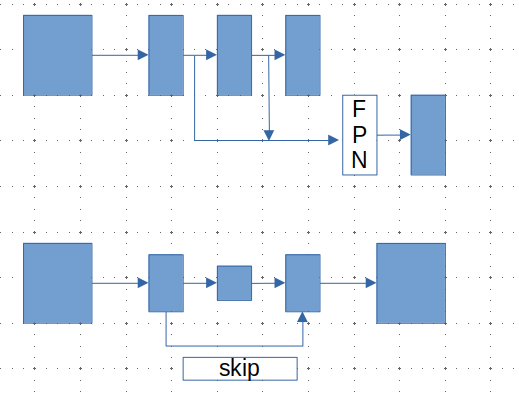
对于检测任务常使用FPN,抓住物体的多尺度特征,处理物体不同尺寸的问题。
对于分割任务常使用UNet,上采样时从之前下采样的特征一起使用,能够将更多的细节还原出来。
ViT在面对检测、分割这些预测密集型任务时,处理的特征都是单一尺寸,而且是像素值少,始终都是处理patch内的像素。复杂度也随着图片的增长而增长。
swin-transformer采用的是在层次化小窗口内计算自注意力,就会跟图片大小成线性增长关系。swin-transformer的多特征是通过不同的patch大小来实现的,第一层是 4 × 4 4 \times 4 4×4的patch大小,第二层是 8 × 8 8 \times 8 8×8的patch大小,第三层为 16 × 16 16 \times 16 16×16的patch大小。每一层都会计算自注意力,不同的patch大小也就可以得到不同尺寸的特征,对于检测和分割这些任务就有了多特征。
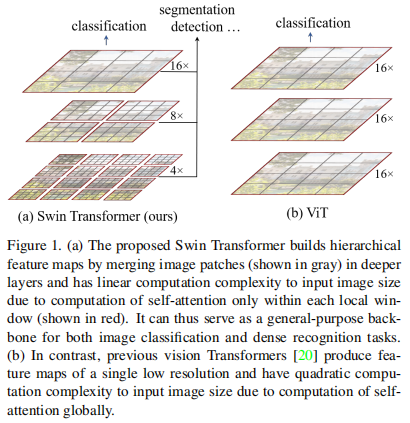
线性计算复杂度通过在图像分区的非重叠窗口内,局部计算自注意力机制实现。每个窗口内的patch数量是固定的,因此复杂度和图像大小呈线性关系。
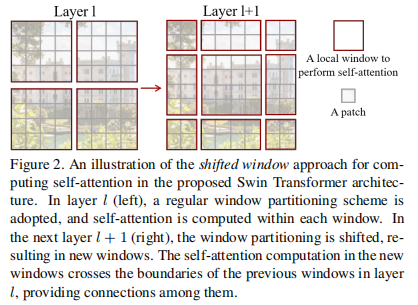
swin-transformer的关键是移动窗口,初始时的patch是在下图的左边中按这个大小去划分,然后计算好注意力之后,会把窗口进行移动,把窗口向右下移动两格,然后再分割成四份就会得到不同的窗口,那么窗口和窗口之间就会有联系了,比如左图左上的一个大方框内的小灰格之间只能相互注意,移动了窗口之后,有一些小灰格被包含到了右图的中间,然后就可以和其他的小灰格产生注意力。
1.2 模型
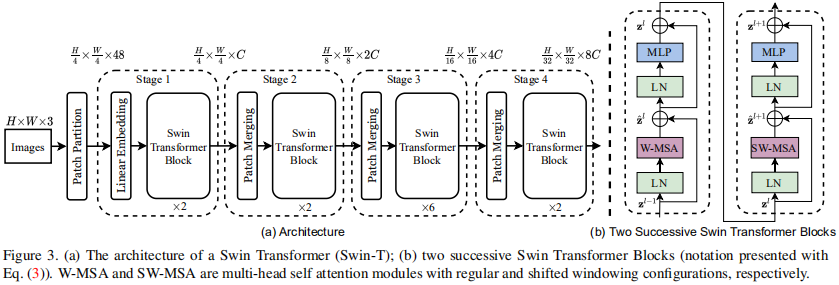
假设在ImageNet数据集上来进行训练,那么第一个Image就是 224 × 224 × 3 224 \times 224 \times 3 224×224×3,然后经过patch分块,每个patch大小是 4 × 4 4 \times 4 4×4,图片大小就变为 56 × 56 × 48 56 \times 56 \times 48 56×56×48,(48是 4 × 4 × 3 4 \times 4 \times 3 4×4×3,3是通道数)。接下来是Linear Embedding(全连接层),将 56 × 56 × 48 56 \times 56 \times 48 56×56×48大小的图片投射到 ( H 4 × W 4 ) × C (\frac{H}{4}\times \frac{W}{4})\times C (4H×4W)×C的维度,所以就变成了 56 × 56 × 96 56 \times 56 \times 96 56×56×96大小的张量,在swin-T中c是超参数96。然后把前面的 56 × 56 56 \times 56 56×56拉直变成 3136 3136 3136,最后的输入向量大小就是 3136 × 96 3136\times 96 3136×96,Swin Transformer Block是改进自注意力模块,对输入的维度没有改变。
Patch Merging层,借助一个 1 × 1 1\times 1 1×1的卷积核,把图像的通道数降低。
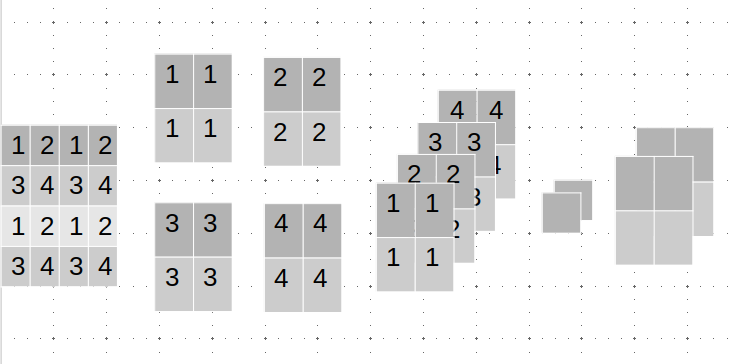
上图是patch merging操作的流程图,对单通道的图片进行操作,最后的通道数翻倍,大小减半,所以 56 × 56 × 96 56 \times 56 \times 96 56×56×96的输入变成了 28 × 28 × 192 28\times 28 \times 192 28×28×192的输出。
1.3 自注意力模块

Swin Transformer 相比于 Transformer block (例如 ViT),将 标准多头自注意力模块 (MSA) 替换为 基于移位窗口的多头自注意力模块 (W-MSA / SW-MSA) 且保持其他部分不变 。如上图所示,一个 Swin Transformer block 由一个 基于移位窗口的 MSA 模块 构成,且后接一个夹有 GeLU 非线性在中间的 2 层 MLP。LayerNorm (LN) 层被应用于每个 MSA 模块和每个 MLP 前,且一个 残差连接 被应用于每个模块后。
1.4 计算

原本的划分里面,每个patch的大小不一样,如果是对小的patch填充0,就会出现9个窗口,计算复杂度就提高了,所以作者对窗口进行了循环移位,这样就可以保持还是4个窗口,计算复杂度就下降了。
移位之后,由于移位之后的像素在原始图像上差距很远,不应该直接相互计算注意力,应该加入掩码。对于这些窗口,将patch拉直,拉直成一个一个的向量,然后把向量转置之后,和原向量进行相乘,然后得到的一个矩阵,矩阵的左下和右上是不同图片之间的自注意力,然后与 0 − 100 − 100 0 \begin{bmatrix}0 & -100 \\ -100 & 0 \end{bmatrix} 0−100−1000相加就会将不同图片的注意力mask。
2 MAE
MAE是在ViT和BERT的基础上实现的,思想类似BERT,盖住图片的一些块,然后重构这些块。使用VIT-H模型在中型数据集上也达到了大数据集的效果。
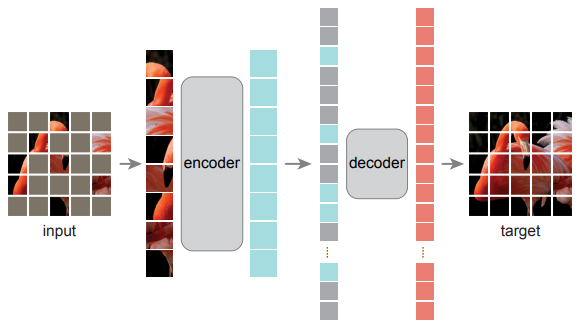
示意图如上,将图片的一些块盖住,然后经过编码器得到特征,然后和上盖住的像素块的位置信息,传入解码器,重构出原本的信息。编码器和解码器是不对称的,编码器看到的只是没被盖住的块,解码器需要重构盖住的块,盖住的块是比较多的,大概75%或者更多。
2.1 自编码器
先把图片分割成patch,随机的采样某些块,剩下的块盖住,然后把可见的块拿出来,输入编码器。将input image切分为不重叠的patches之后,执行linear projection,再加上positional embeddings (the sine-cosine version) ,然后送入transformer blocks。
2.2 解码器
同样使用ViT,将mask tokens和encoded visible patches作为输入,加上位置编码 (the sine-cosine version) 。decoder的最后一层是linear projection,输出通道数量和一个patch内的pixel数量相同(方便重构),然后再reshape,重构image。损失函数使用MSE,损失函数只对masked patches计算(和BERT相同)。同时作者也尝试了normalization的方式,即计算一个patch内像素值的均值和标准差,然后对patch执行normalization,此时encoder的重构任务发生了一些变化,需要重构normalized pixel values,实验表明这种方式效果更好一点
MAE中decoder的设计并不重要,因为预训练结束之后,只保留encoder,decoder只需要完成预训练时的图像重构任务。但是作者也表示decoder决定了latent representations的语义级别(While in BERT the decoder can be trivial (an MLP) , we found that for images, the decoder design plays a key role in determining the semantic level of the learned latent representations)。
2.3 MAE的优势
(1)Scalable:encoder只操作可见patches,把mask tokens给本身参数就不多的decoder去运算,大大降低了计算量,尤其当mask的比例很高的时候,大大减少了预训练时间,让MAE可以很轻松的scale到更大的模型上(enabling us to easily scale MAE to large models),并且通过实验发现随着模型增大,效果越来越好
(2)高容量且泛华性能好(very high-capacity models that generalize well):使用MAE预训练方法,可以训练很大的model,比如ViT-Large/Huge,当把预训练好的ViT-Huge迁移到下游任务时,模型表现非常好,甚至超过了使用监督预训练的相同模型(achieves better results than its supervised pre-training counterparts),这说明MAE预训练学习到的表示可以很好的泛化到下游任务(these pre-trained representations generalize well to various downstream task)
总结
本周学习了Swin-Transformer和MAE两篇论文,从论文中也体会到transformer架构在CV和NLP领域统一的形势,大家都想提出一个骨干网络,可以解决CV和NLP的问题,然后应用到多模态上。