本文根据 2025 云栖大会演讲整理而成,演讲信息如下
演讲人: 黄鹏程 阿里云智能集团计算平台事业部实时计算Flink版产品负责人
引言
在数据驱动的时代,实时数据处理已成为企业数字化转型的核心能力。阿里云实时计算 Flink 版用了十年时间来进行产品发展,从技术引进到自主创新,已成为实时数据处理的行业标杆。在这次云栖大会上,阿里云发布了实时计算 Flink 的全新升级,不仅在计算和存储层面实现重大突破,更在 AI 时代开辟了实时智能的新篇章。
今天我的演讲主要分为四个部分:首先简单回顾一下产品发展和现在的情况,然后专门讲一下这次云栖大会我们在计算、存储方面的全面升级和创新演进,接着谈谈在 AI 时代如何通过实时和 AI 的结合,让数据更加准确、推理更加快速,获得更新鲜的洞察,最后是产品发展的展望。
十年磨一剑:阿里云实时计算 Flink 版的成长之路
阿里云实时计算 Flink 的发展历程经历了十年的磨砺,可以分为四个关键发展阶段。 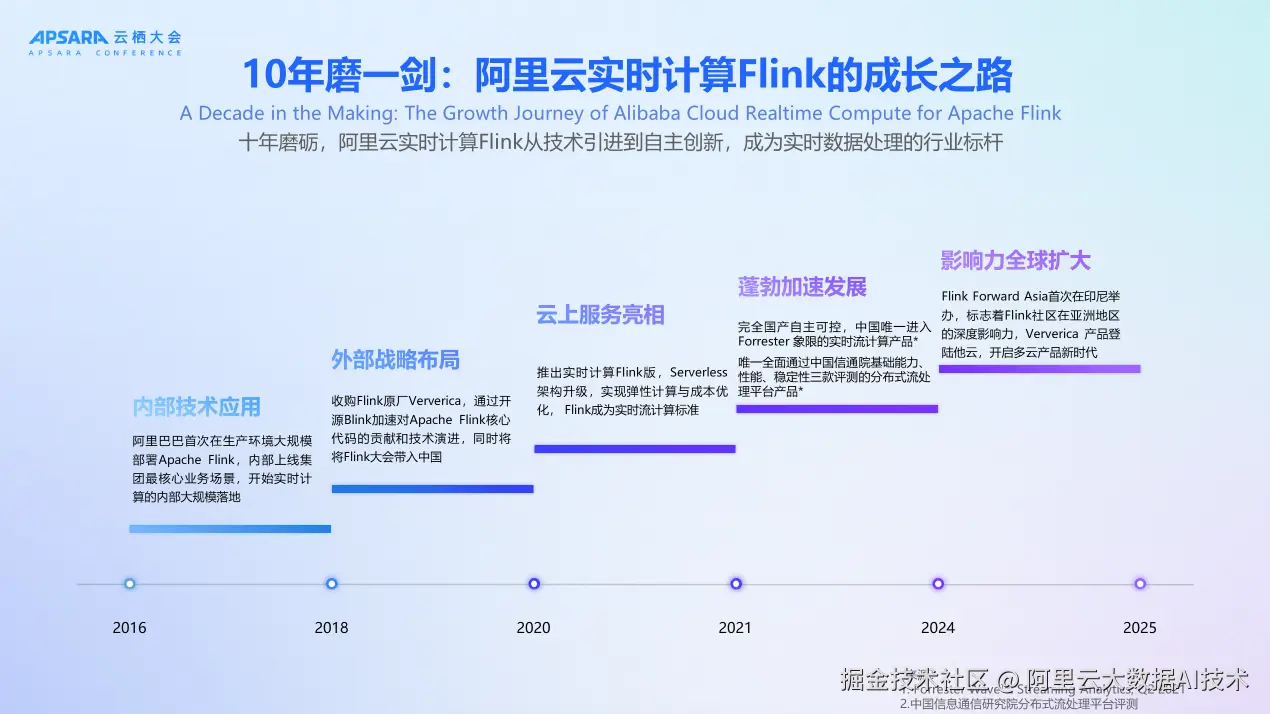
内部技术应用
在早期的内部技术应用阶段,我们首先在阿里巴巴集团内部广泛采用了当时的 Flink 技术。当时我们还专门改过一个版本叫 Blink,了解这个产品的朋友应该都知道这段历史。阿里巴巴首次在生产环境大规模部署 Apache Flink,内部上线了集团最核心的业务场景,开始了实时计算的内部大规模落地。
外部战略布局
到了2016年到2018年左右,我们进入了外部战略布局阶段。我们收购了之前 Apache Flink 的原厂,当时叫 Data Artisans,现在叫 Ververica。通过把中德两边的团队合并,我们把 Blink 贡献给社区,同时作为社区的主导者,一起推动开源社区的发展以及云产品的发展。我们也把 Flink Forward 大会带入了中国。
云上服务亮相
在2020年左右,我们的云上服务正式亮相。2020年推出了实时计算 Flink 版,采用 Serverless 架构升级,实现了弹性计算与成本优化,Flink 成为实时流计算的标准。2021年我们通过了中国信通院的三个评测,包括基础能力、性能、稳定性三项评测,成为完全国产自主可控,中国唯一进入 Forrester 象限的实时流计算产品。
蓬勃加速发展
到了2024年2025年,我们就更加蓬勃发展了。我们向海外的多云发展,有了更大的影响力。我们把 Flink Forward Asia 大会开到了除中国大陆地区以外的印尼、新加坡这些地方,标志着 Flink 社区在亚洲地区的深度影响力。同时 Ververica 产品登陆其他云平台,开启了多云产品的新时代。 
从产品现状来看,阿里云实时计算 Flink 版采用了两层架构设计。首先是企业级增强引擎 Flash ,这是位置偏下的核心部分,这个自研的向量化引擎在 Nexmark 标准测试中性能是开源 Flink 的 3-4倍,同时提供了自研存储后端优化、SQL 算子优化等能力。企业级能力包括数据摄入、动态的 CEP、弹性扩缩容等功能,重要的是 100% 兼容 Apache Flink 内核,用户从开源版迁移过来也不用修改代码。
第二层是作业开发和运行平台,这就是大家看到的那个 Console 管控平台页面,包含了整个的资源管理、作业的全生命周期管理(从开发、运维、调优到诊断)、Open API、监控告警等可观测性,以及调优诊断功能。左右两边是我们的生态系统,包含了我们可以从哪里读数据,然后可以把数据写到哪里。
产品现状体现出四大核心优势。首先是一站式实时任务开发运维平台 ,这是一个全托管的 Serverless 平台,用户完全不用管下面的集群,提供实时任务开发、调试、部署、管理、诊断调优全流程服务,计费模式灵活支持包年包月或按量付费与混合计费。 
其次是 Serverless 架构,用户以 CU (Compute Unit,即计算资源)为单位进行相关的资源扩缩容,无需预置资源,按需弹性扩缩容,能够降低资源使用成本达30%以上。用户支持动态扩缩容,秒级弹性增减作业资源,保证业务连续性,用户不用为扩展 CU 时的作业重启而担心,作业级别的资源隔离保证业务稳定性。
第三是企业级内核能力,为用户提供极致的性能和丰富的功能。实时计算 Flink 版 100% 兼容 Apache Flink,支持用户平滑迁移,在性能方面 Nexmark 流计算标准测试性能是开源 Flink 的 3-4倍,企业级增强功能能够构建入湖入仓、实时数仓数据湖、CEP动态规则配置等更多业务场景。
最后是全面可观测性,具备高稳定性、高可用的特点,提供丰富的作业监控指标、日志洞察,智能调优与诊断功能,支持同城灾备,全局高可用,故障自动恢复,提供产品级同城灾备能力,99.9%服务可用性保障,能够给企业级实时业务赋能。
全面升级:计算与存储的创新演进
实时计算 Flink 版这次云栖大会的发布一共分了两个部分:计算和存储的全面升级。
计算升级:增量计算技术革新
Flink 从流计算起家,后来也开始慢慢做批计算,我们也提出了流批一体的概念。现在用户在更精细化的场景下,希望在一定的时效性和一定成本之间取得比较完美的平衡。
传统的流计算和批计算各有优劣。流计算能够提供秒级时效性,但成本较高;批计算成本较低,但时效性差,通常是小时级或天级。用户在精细化场景下,需要在时效性和成本之间找到完美平衡。阿里云实时计算 Flink 版推出的增量计算技术,正是为了解决这一痛点。 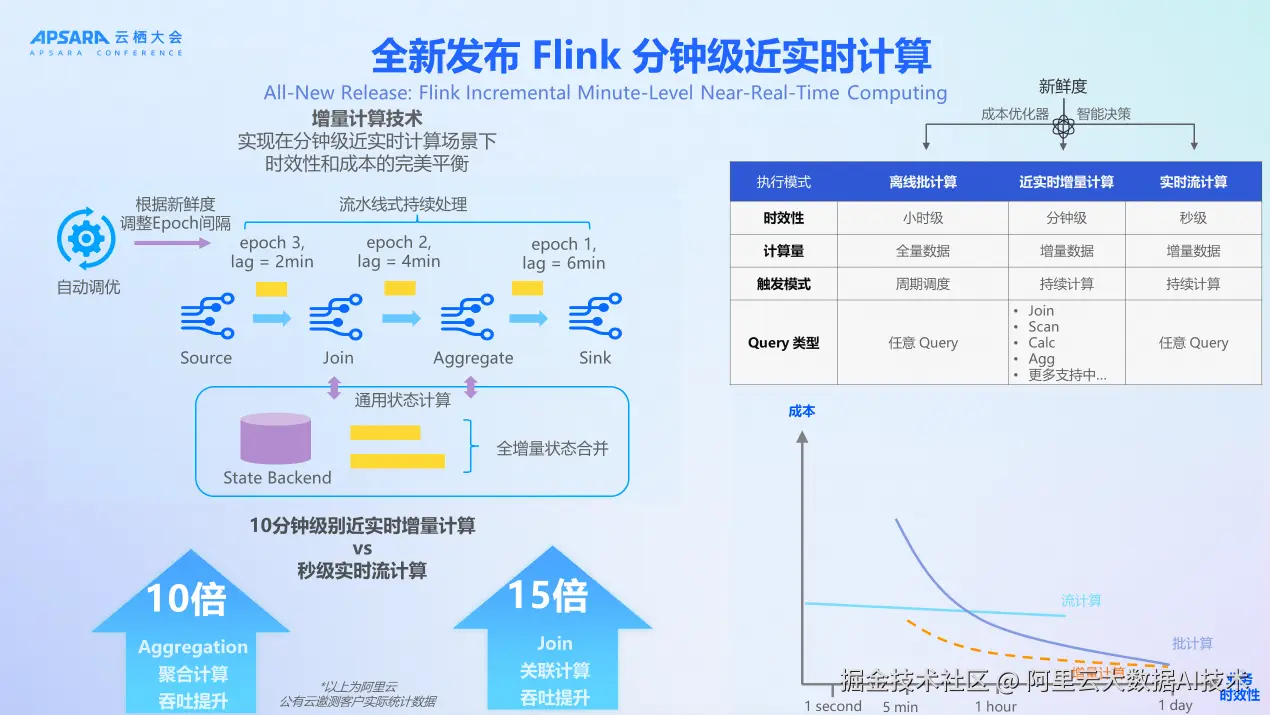
增量计算的核心思想是是通过 Epoch(微批次) 将连续的数据流划分为有限的数据集合,每个 Epoch 由框架定时触发,并通过 Epoch Marker 标识边界。该方案引入 DamStage 作为执行计划的最小并行单元,由"只进不出"的 Dam 算子(如聚合、连接等)构成,确保数据处理仅在 Epoch 边界处向下游输出。方案通过 AutoPilot 自动调优机制,根据业务对数据新鲜度(Freshness)的要求和dataLag (统计数据从在作业上游创建,到被作业处理完成下游可见的延迟),动态计算 Epoch 大小并调度资源。 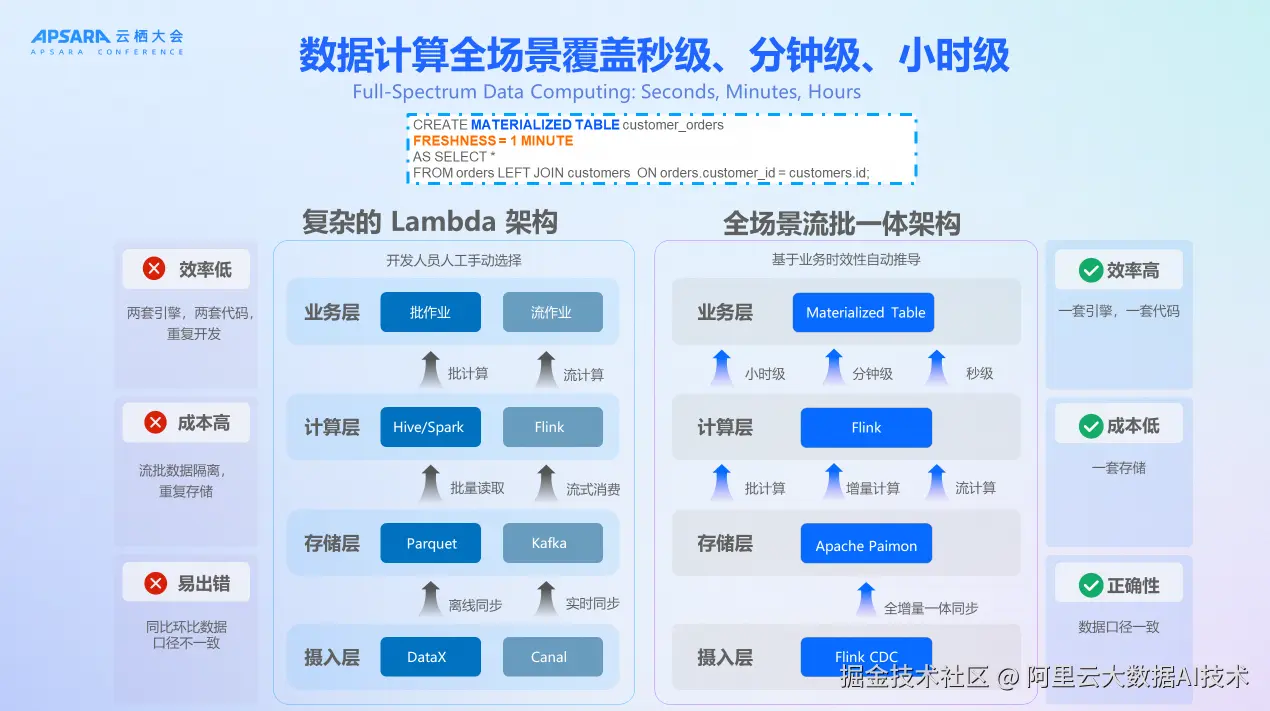
根据阿里云公有云实际统计数据,增量计算在性能方面表现优异。在聚合计算方面,分钟级、十分钟级的增量计算与秒级(Record by Record)处理相比,吞吐能够提升10倍左右。在 Join(关联计算)方面,吞吐能够提升15倍左右。增量计算能够在用户的成本和一定时效性上取得比较好的平衡。**如果业务不需要秒级,但希望比天级或半天级都要好,增量计算是很好的选择。**在分钟级的时候,增量计算已经很好地优于流计算。
传统的 Lambda 架构存在批处理和流处理割裂的问题,有批处理作业和实时作业,存储、计算都是割裂的。阿里云推出的 UniFlow 统一计算架构通过 Materialized Table 概念,实现了流批一体。通过声明式语法把秒级、分钟级以及天级的计算统一到一起,用户只用调整 Freshness,就能得到不同新鲜度的数据。这个架构基于 Apache Paimon 湖存储,使用 Flink CDC 做数据接入。整体架构更加统一、优雅,成本、效率和正确性都能得到很好的平衡和保证。开发人员不再需要人工手动选择,而是基于业务时效性自动推导,实现了数据计算全场景覆盖秒级、分钟级、小时级。
存储升级:Fluss 流存储创新
传统 Flink + Kafka 架构在实时计算场景下存在诸多限制。传统 Kafka 存在 IO 开销大的问题,如果 Record 是 JSON 格式有100列,Flink 处理时需要把所有 Record 都消费出来,即使只用其中10列,这就造成了很大的浪费。同时伸缩性差,Kafka 的伸缩性与实时计算伸缩性完全独立,很难做统一伸缩。在延迟方面,基于 Kafka 一般是分钟级,做秒级运维成本很高,异常概率高。架构也比较复杂,流存储和湖存储割裂,运维复杂。 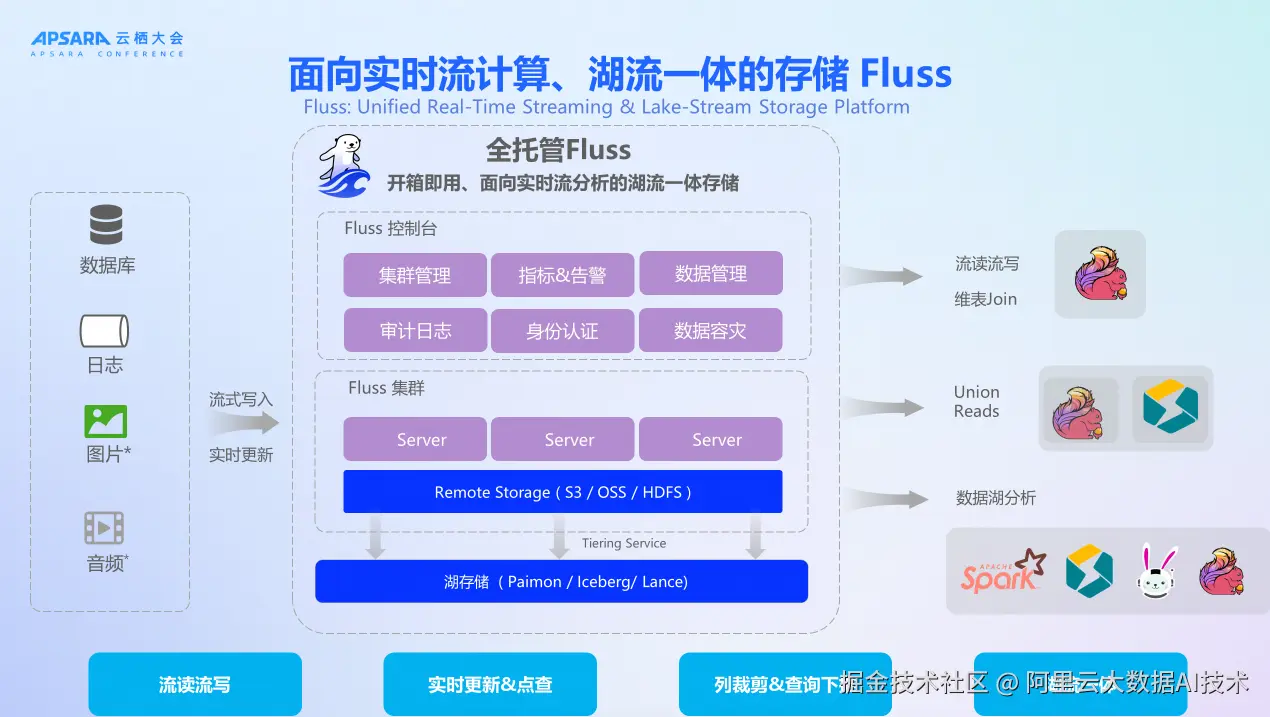
流存储 Fluss 版是阿里云推出的面向实时流的、面向湖流一体的流存储,计划今年开始全网公测(目前邀测阶段) ,其背后的开源项目 Apache Fluss (incubating) 现已在 Apache 社区孵化。这个产品专门面向过去 Flink + Kafka 客户场景,解决 Kafka 架构限制导致的实时方面开销和能力不足。 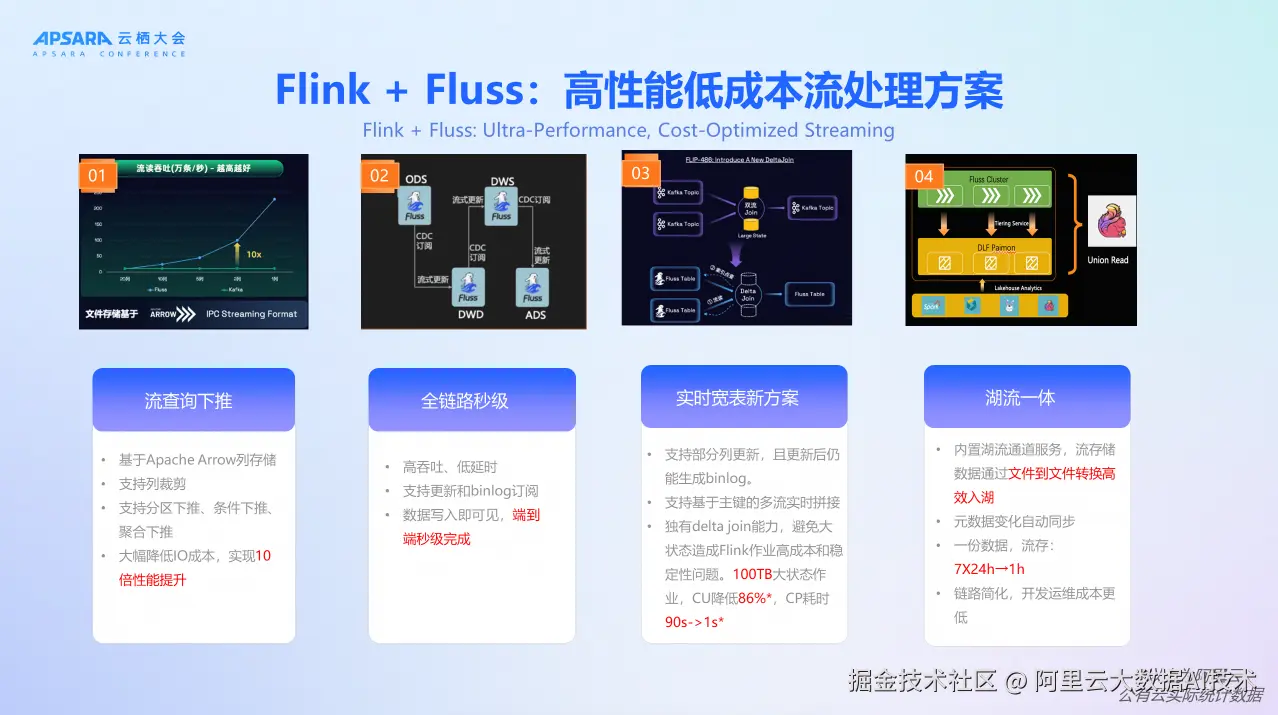
Fluss 解决方案具有四大核心优势。首先是流查询下推和裁剪 ,Fluss 支持直接只取需要的部分数据,不需要全部取过来,基于 Apache Arrow 列存储,支持列裁剪、分区下推、条件下推、聚合下推,大幅降低 IO 成本,实现10倍性能提升,整体 IO 成本和性能显著优化。
其次是全托管伸缩性,Fluss 面向流设计,可以与 Flink 计算做更好的伸缩性配合。与 Flink 计算引擎协同伸缩,采用 Serverless 架构,自动资源部署、运维、监控,根据业务负载自动调整资源。
第三是秒级数据延迟,流存储 Fluss 版采用云原生架构,设计之初就考虑稳定性和低延迟性,能做到秒级。支持更新和 binlog 订阅,数据写入即可见,端到端秒级完成,相比传统方案异常概率更低,运维成本更低。
最后是湖仓一体能力,数据先流入本地盘(Fluss 集群),再通过 Tiered Storage 以 Paimon 格式流到湖存储。以 Paimon 格式存储,支持多种分析引擎,内置湖流通道服务,流存储数据通过文件到文件转换高效入湖,元数据变化自动同步,一份数据,流存储保留 1 小时内数据即可,其余数据可归档到数据湖中,从而简化链路,开发运维成本更低。Serverless Spark、StarRocks、Flink 都可以做进一步分析,提供统一的数仓搭建能力,降低用户复杂度。
Flink + Fluss 组合形成了高性能低成本的流处理方案。除了前面提到的优势外,还有实时宽表新方案。支持部分列更新,且更新后仍能生成 binlog,支持基于主键的多流实时拼接,即独有 delta join 能力(注:阿里云上实时计算 Flink 版+流存储 Fluss 版现已支持 Delta join,无需依赖 Apache Flink 2.1),避免大状态造成 Flink 作业高成本和稳定性问题。淘天集团应用 Flink+Fluss 方案后,成功减免 100TB+ 的大状态作业,CU 降低86%,CP 耗时从90秒降低到1秒。 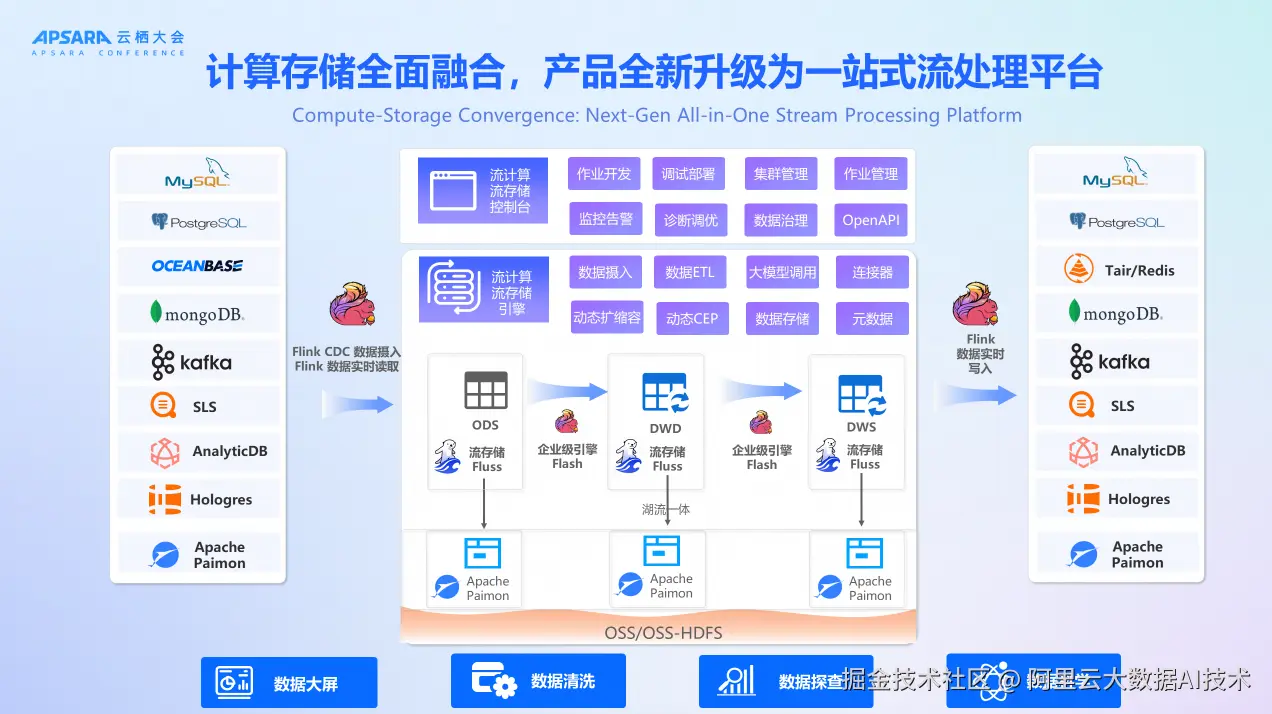
通过计算存储的全面融合,实时计算 Flink 版产品全新升级为一站式流处理平台。产品集成了 Flink CDC 数据摄入、Flink 数据实时读取、流存储 Fluss、湖流一体等能力。在控制台层面提供作业开发、监控告警、集群管理、数据治理、调试部署、诊断调优、作业管理、OpenAPI 等功能。引擎层面包括流计算流存储引擎,支持数据摄入、动态扩缩容、大模型调用、数据存储、数据ETL、动态CEP、连接器、元数据等能力。
AI 时代的实时智能:Flink 与大模型融合
现状挑战与机遇
现在很多用户都面临挑战:数据总量越来越大,数据种类越来越多样化,数据来源越来越多样化。但是 AI 模型的训练、推断、应用还主要靠离线数据和批处理数据,这就导致 AI 模型新鲜度非常差,准确性就会越差,最终效果非常差。
在 AI 时代,企业面临新的数据处理挑战。数据爆炸式增长带来了数据总量、种类、来源的指数级增长。模型滞后问题严重,AI 模型主要依赖离线数据,新鲜度差。准确性下降,数据新鲜度差导致模型准确性降低。同时业务对实时 AI 推理的需求日益迫切。
解决方案:实时 + AI 全链路能力
阿里云实时计算 Flink 版专门为实时计算开发了从数据到智能的全链路能力,包括数据接入、特征工程、模型推断、模型部署、整个模型管理的全链路能力。 
在 AI Function 函数方面,提供强大的 AI Function 函数支持在 SQL 流处理中直接调用大语言模型服务。支持 Chat Model 实时调用,实现文本理解,兼容 OpenAI API,各种模型可无缝接入,全面支持阿里云百炼、Platform for AI(PAI)等大模型服务。
在向量化处理方面,支持 Embedding Model 调用,实现文本向量化,提供毫秒级流数据相似性搜索,与 Apache Flink SQL 生态系统无缝集成,让非结构化与结构化数据综合分析成为可能。内置 Milvus 连接器,支持高性能写入向量数据。
在非结构化数据处理方面,提供丰富的上游生态,对数据库实时变化、对象存储文件变化实时捕捉。内置提供多种数据、文本函数方便数据切分,支持结构化与非结构化数据综合分析。
这些能力覆盖实时情感分析、智能推荐、异常检测、语义搜索、智能客服等多样化 AI 场景。基于实时 + AI 能力,可支持多样化的智能场景,包括实时情感分析(社交媒体、客户反馈的实时情感监控)、智能推荐(基于用户实时行为的个性化推荐)、异常检测(业务指标、系统性能的实时异常识别)、语义搜索(基于向量相似性的智能搜索)、智能客服(结合实时上下文的对话机器人)等。
实际应用案例:AI 风控革新
传统 AI 风控存在严重问题。基于一小时以前或半天以前的数据进行风控,信用卡盗刷过了半天才发现,已经盗刷了几十次,造成很大损失。延迟发现、误报率高、响应滞后等问题突出,无法实时阻断可疑交易。
实时 AI 风控解决方案通过整合多元数据源来解决这些问题。数据源包括登录流量、购买流量、支付流量、系统交互流量、物流信息流量等各种行为流量。
处理流程是:全部接入实时计算,用实时计算做特征工程,直接用实时计算结果喂给 AI 模型,实现分钟级乃至秒级的实时风控。具体来说,所有数据流实时接入计算平台,使用实时计算进行特征提取和工程,直接将实时特征输入 AI 模型,实现分钟级乃至秒级的风控决策。
技术优势体现在 Flash 增强引擎上。自研的向量化增强引擎在做向量化、模型推断时,比传统模型有更强的性能、更低的延迟、更低的计算成本,相比传统方案延迟更低,成本控制更好,资源利用率更高。
阿里云在 Apache Flink 社区发起了事件驱动型 AI 多智能体框架 Flink Agents,可以支持事件驱动型 AI 智能体、AI 编程、Chat BI、Deep Research 等多种应用场景。这个框架能够处理购买、评论、点击等各种用户触发和系统触发的指标事件,支持会话型 AI 智能体和事件驱动型 AI 智能体。 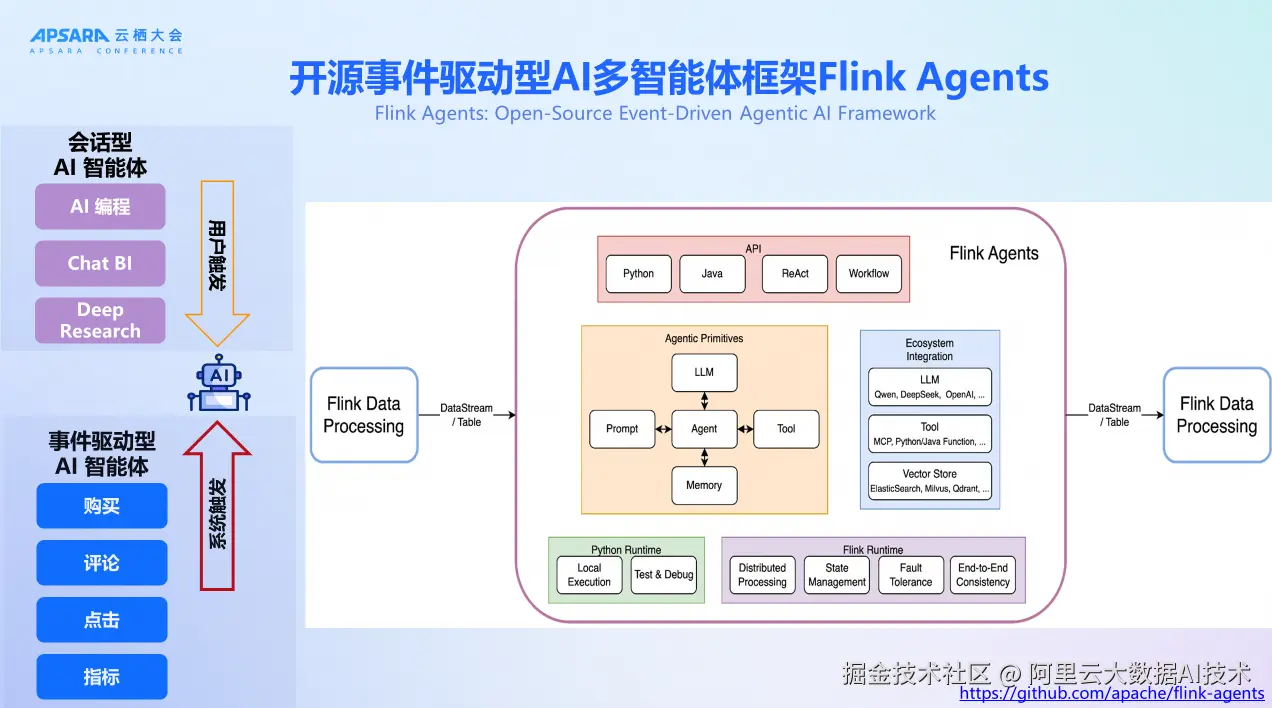
在典型应用场景方面,以直播评论的实时智能情感分析为例。通过 Flink SQL AI 大模型调用,结合外部大语言模型服务和 Fluss 湖流一体存储,可以进行情感分析、话题变化风险追踪、潜在商机挖掘等分析。同时用 Flink SQL 进行结构化数据增强,将结果写入向量数据库。具体的 SQL 语句示例展示了如何通过 ML_PREDICT 函数调用 AI 模型进行实时情感分析。 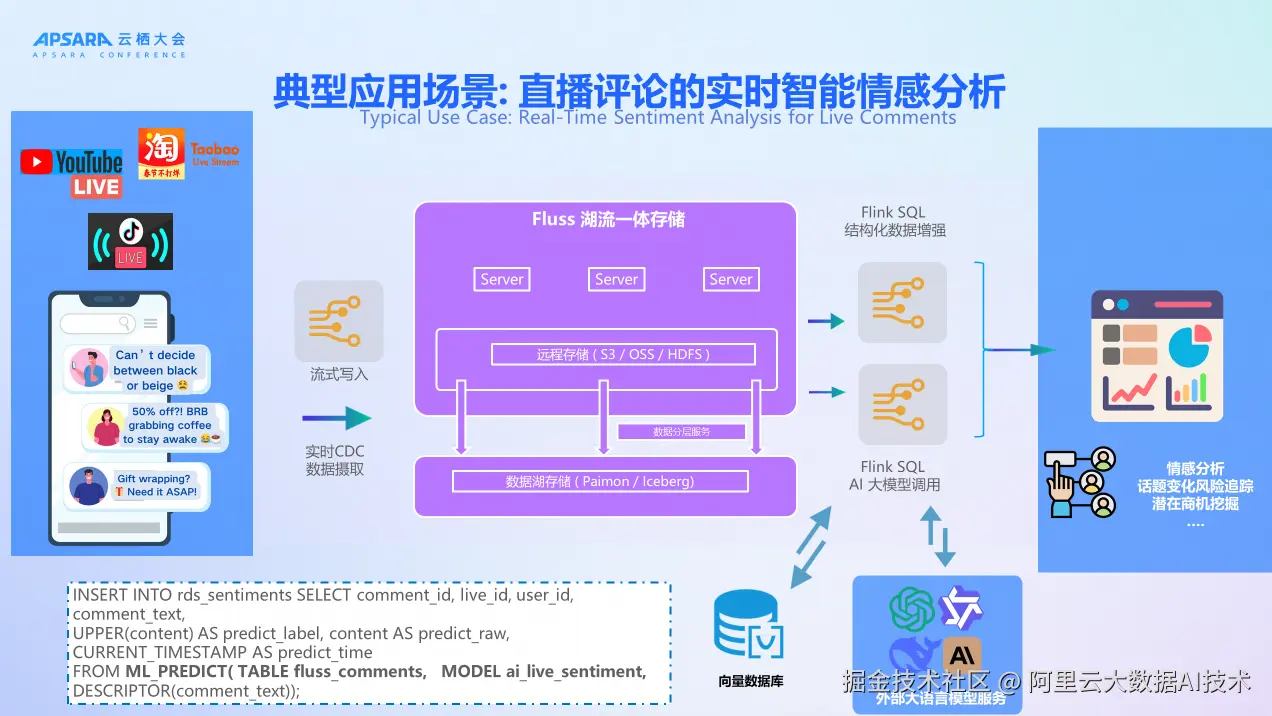
产业落地案例:某头部车企客户之声
在某头部车企的客户之声实时市场舆情分析项目中,VOC(Voice of Customer)应用场景涵盖高层战略、产品介绍、试乘试驾、售后维修、召回、APP使用、论坛、车友会、会员体系、线上线下活动、权益使用等各种场景下,使用大模型进行语音和文字数据的结构化打标和处理工作,提供情感分析、信息提取、VOC标注、标签挖掘能力,用于舆情监控、活动介绍、售后维修等场景。 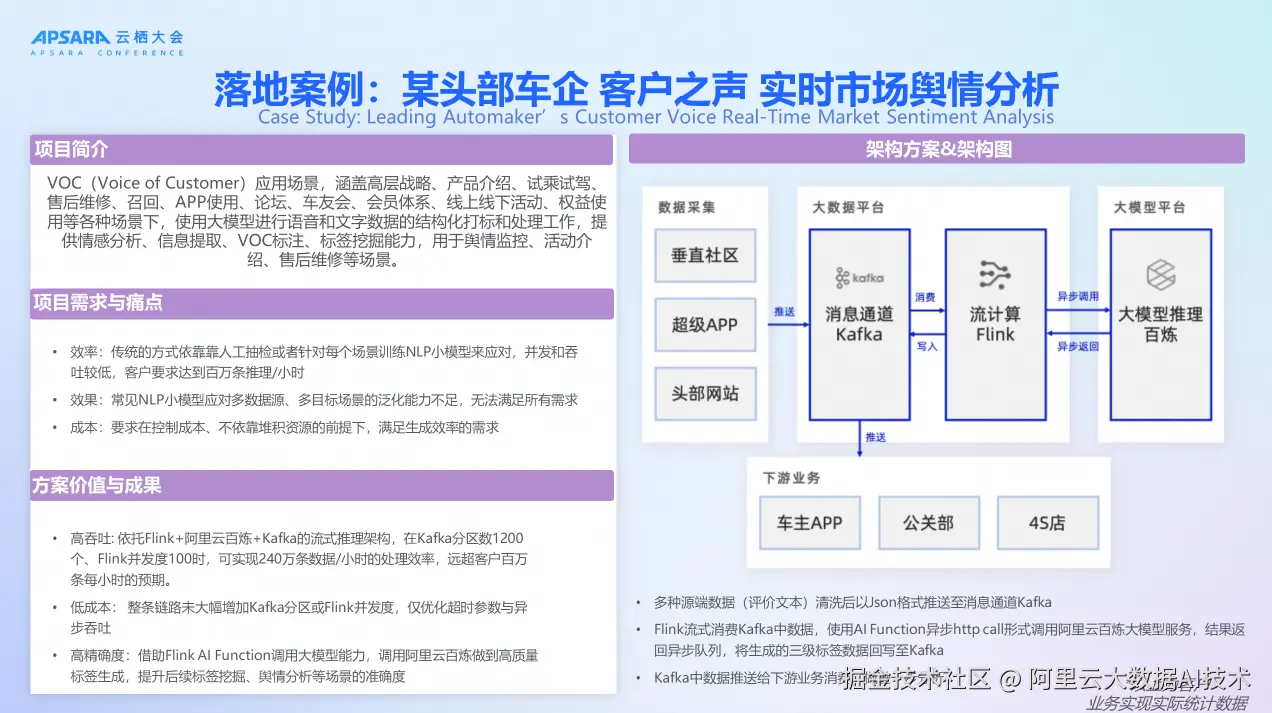
项目需求与痛点包括:效率方面,传统的方式依靠人工抽检或者针对每个场景训练 NLP 小模型来应对,并发和吞吐较低,客户要求达到百万条推理每小时;效果方面,常见 NLP 小模型应对多数据源、多目标场景的泛化能力不足,无法满足所有需求;成本方面,要求在控制成本、不依靠堆积资源的前提下,满足生成效率的需求。
架构方案采用多种源端数据(评价文本)清洗后以 Json 格式推送至消息通道 Kafka,Flink 流式消费 Kafka 中数据,使用 AI Function 异步 http call 形式调用阿里云百炼大模型服务,结果返回异步队列,将生成的三级标签数据回写至 Kafka,Kafka 中数据推送给下游业务消费,做进一步分析。
方案价值与成果显著:高吞吐方面,依托实时计算 Flink 版+阿里云百炼+Kafka 的流式推理架构,在 Kafka 分区数1200个、Flink 并发度100时,可实现240万条数据每小时的处理效率,远超客户百万条每小时的预期;低成本方面,整条链路未大幅增加 Kafka 分区或 Flink 并发度,仅优化超时参数与异步吞吐;高精确度方面,借助 Flink AI Function 调用大模型能力,调用阿里云百炼做到高质量标签生成,提升后续标签挖掘、舆情分析等场景的准确度。
产品发展展望
 在产品未来发展的展望中,我们将持续深化AI与流计算的融合,重点打造更强大的实时Agent平台,并拓展更多AI应用场景,尤其是实时视频流理解。针对社区、工厂或工地等场景,我们正构建高效方案,实现对海量摄像头数据的持续监控与智能分析,准确捕捉画面中发生的动态事件,该功能预计将在不久后上线。同时,云原生能力的增强也是核心方向之一,通过优化存储与计算的Serverless 架构,进一步提升资源利用率和弹性伸缩能力,以支持更广泛的业务需求。此外,我们还将持续推进流批一体架构的完善,覆盖分钟级、秒级乃至小时级和天级的处理需求,帮助用户在统一的计算与存储体系下释放更多场景价值。
在产品未来发展的展望中,我们将持续深化AI与流计算的融合,重点打造更强大的实时Agent平台,并拓展更多AI应用场景,尤其是实时视频流理解。针对社区、工厂或工地等场景,我们正构建高效方案,实现对海量摄像头数据的持续监控与智能分析,准确捕捉画面中发生的动态事件,该功能预计将在不久后上线。同时,云原生能力的增强也是核心方向之一,通过优化存储与计算的Serverless 架构,进一步提升资源利用率和弹性伸缩能力,以支持更广泛的业务需求。此外,我们还将持续推进流批一体架构的完善,覆盖分钟级、秒级乃至小时级和天级的处理需求,帮助用户在统一的计算与存储体系下释放更多场景价值。
总结
阿里云实时计算 Flink 版的全新升级,标志着流处理技术进入了新的发展阶段。通过增量计算技术实现时效性和成本的完美平衡,通过 Fluss 流存储构建湖流一体架构,通过 AI Function 开启实时智能新纪元。
在 AI 时代,实时数据处理不再只是基础设施,而是驱动智能化转型的核心引擎。阿里云实时计算 Flink 版正在帮助企业构建面向未来的实时智能平台,让数据的价值得以实时释放,让 AI 的能力得以实时展现。
实时即未来,这不仅是技术趋势,更是数字化转型的必然选择。随着阿里云实时计算 Flink 版的持续演进,我们有理由相信,一个更加智能、更加实时的数据处理时代正在到来。