📚 论文信息
-
标题 :Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
-
作者:Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova
-
单位:Google Research、succinctly.ai、University of Cambridge
-
会议:ICML 2023
-
🔗 GitHub 项目
一、问题背景:视觉与语言的"割裂"
当前的视觉-语言理解(Vision-Language Understanding)研究,大多基于图像与文本分开处理的范式。 但现实中,我们接触到的文本和视觉往往是交织在一起的,例如👇
-
📄 含表格和图片的文档
-
📊 图示和信息图
-
📱 UI 界面
-
🌐 网页内容
现有方法多依赖 OCR 管线 或 特定领域工程 来拆解这种混合信息,例如:
-
文档理解依赖外部 OCR;
-
UI 理解依赖平台特定 metadata;
-
图表理解依赖图结构提取。
👉 这导致模型难以泛化,工程复杂、跨域能力弱,也难以构建统一的视觉语言理解框架。
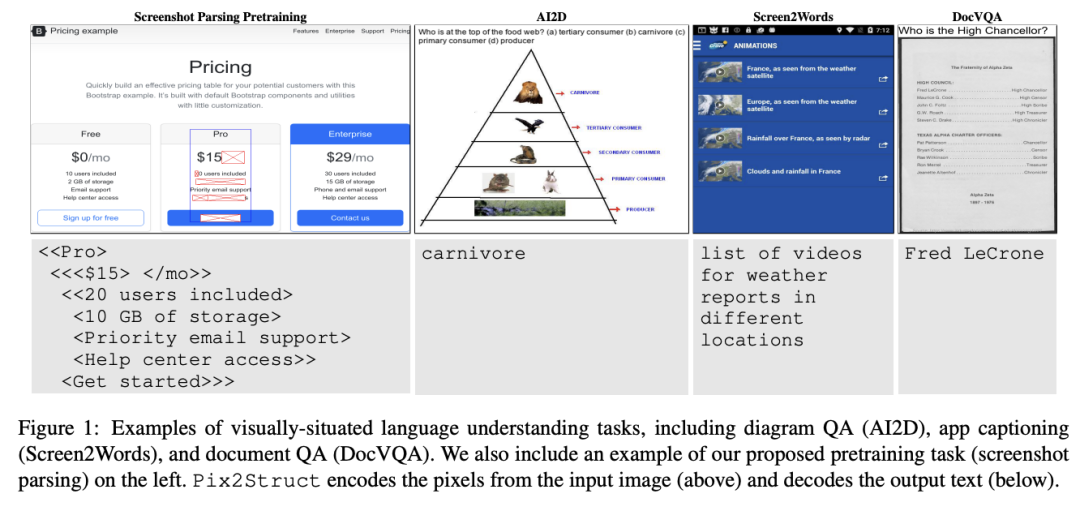
二、方法创新:Pix2Struct = 截图 + HTML 解析
论文提出的 Pix2Struct 旨在彻底简化这一过程。 其核心思想是:
"只用像素输入 + 预训练解析网页结构,就能学到通用视觉语言能力。"
✳️ 核心技术路径
- 截图解析预训练(Screenshot Parsing)
-
从网页抓取 截图 + HTML;
-
通过模型输入像素截图,输出 HTML 简化结构(类似图像转标记语言);
-
自监督学习网页的布局与内容关系。
-
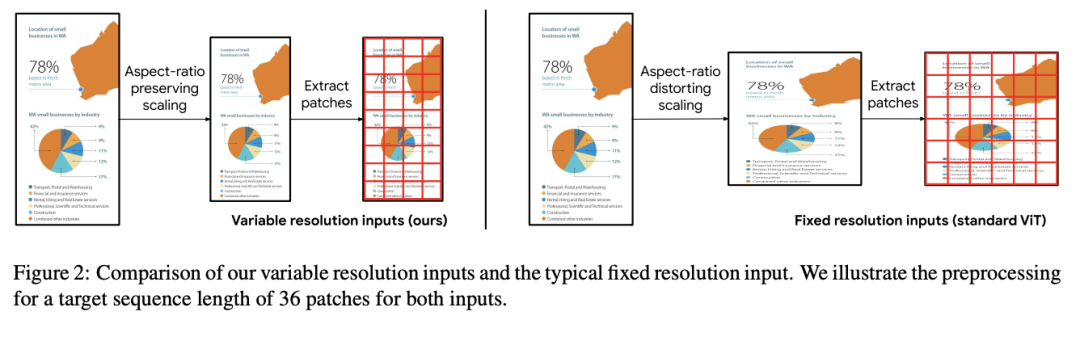
可变分辨率输入
-
-
改进 ViT 输入,支持灵活分辨率和长宽比;
-
避免 OCR 模型常见的失真问题。
-
-
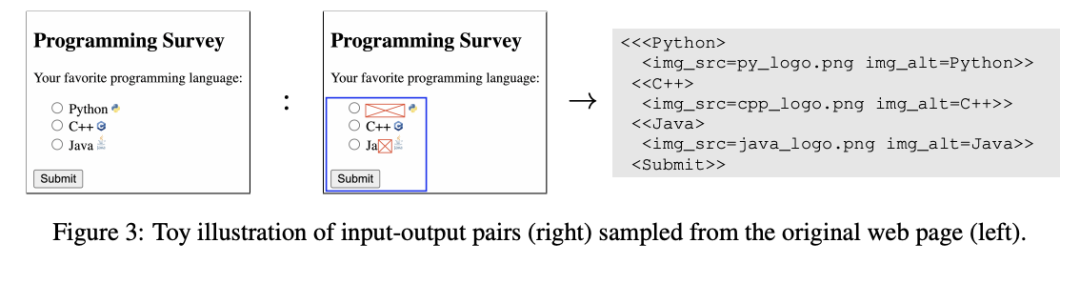
文本直接渲染到图像上
-
-
任务中的问题(如 VQA)直接绘制在图片上方;
-
模型通过单一视觉通道理解所有信息,避免多模态对齐难题。
📌 Pix2Struct 是一种 视觉编码 + 文本解码 架构。 与 T5 的"文本到文本"类似,它是 "像素到文本"的通用框架。
三、实验结果:跨 4 大领域,9 项任务
论文在四个视觉语言领域的九个基准上进行了系统测试:
领域 任务示例 数据集 Illustrations 图表/示意图问答 ChartQA, AI2D UI 组件识别、界面描述 RefExp, Widget Captioning Natural Images 图像问答、文字识别 TextCaps, OCR-VQA Documents 文档问答 DocVQA, InfographicVQA 1. 对比 Donut 与 GIT2
-
Pix2Struct 在 9 个基准中 8 个优于 Donut,
-
并在 6 个任务上创下单模型 SOTA;
-
相比 GIT2(12.9B 图文对),Pix2Struct 预训练数据更小,但跨域迁移更强。
2. UI 与插图任务表现尤为突出
-
RefExp(UI组件定位)超过 UIBert;
-
Widget Captioning CIDEr 从 127.4 提升至 136.7;
-
Screen2Words 从 64.3 提升到 109.4。
3. 文档与信息图任务表现
-
DocVQA ANLS 提升 9 分;
-
InfographicVQA 从 11.6 提升到 40。 👉 说明其对长宽比极端的图像也具有较强鲁棒性。
四、优势与局限
✅ 优势
-
统一像素输入,跨领域泛化能力强;
-
训练目标简洁,自监督高效;
-
可变分辨率机制适配真实场景;
-
超越 OCR 管线,在 6/9 基准任务上达 SOTA。
⚠️ 局限
-
语义理解深度与专用文本模型仍有差距;
-
高分辨率训练成本高;
-
对特定领域结构(如 PDF 元数据)不加利用时略有性能损失;
-
暂不具备生成能力,仅限理解类任务。
📝 一句话总结 : Pix2Struct 用"截图+像素解析"打破多模态割裂, 是迈向 通用视觉语言理解 的重要一步。
-