假设文档的存在方向旋转,那么会进一步的干扰VLM进行OCR的性能,下面看一个预处理方案,解决文档旋转干扰OCR问题,并进行一些评估,方法较为简单,快速看一下。
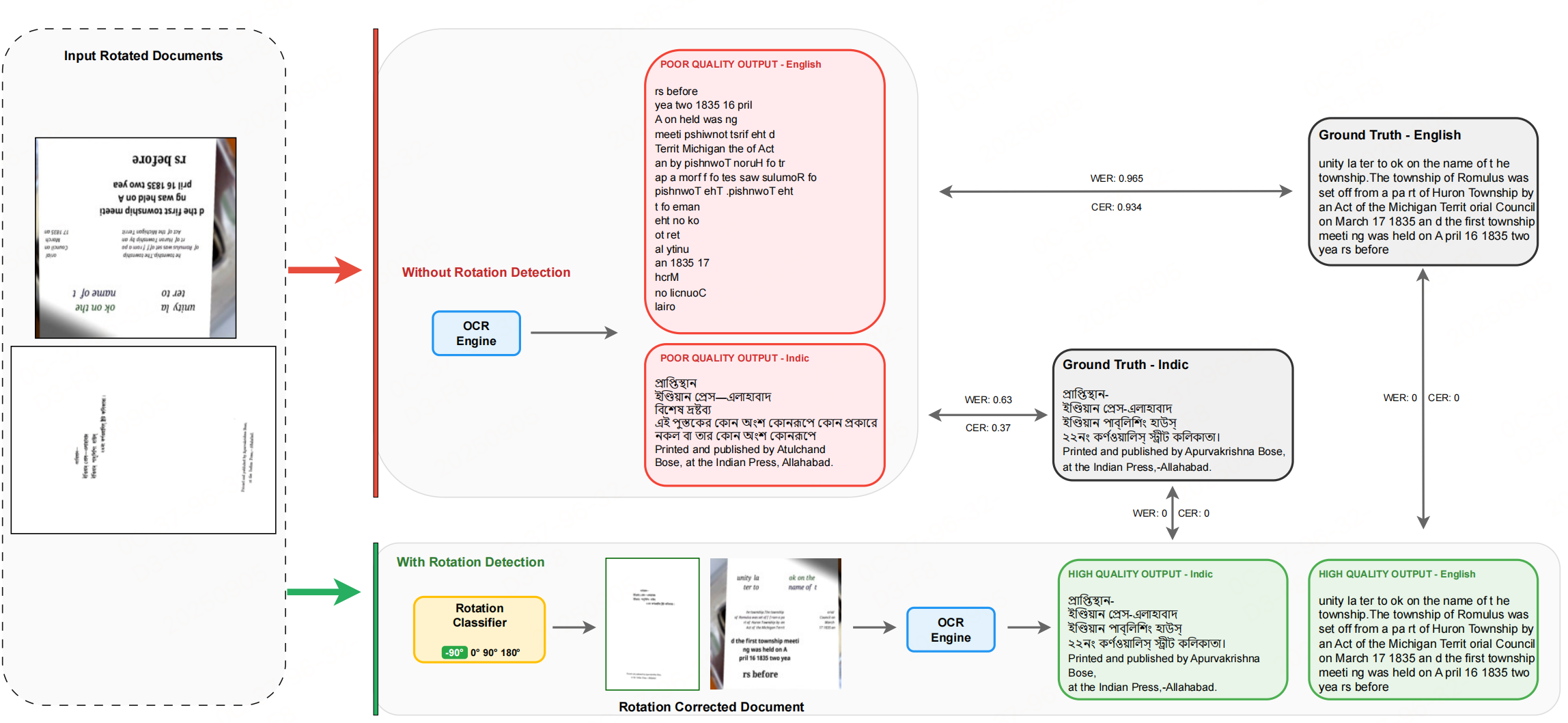
旋转分类任务定义:将文档旋转校正转化为四分类任务,覆盖最常见的四种旋转状态:
- 类别0:-90°(逆时针旋转90°)
- 类别1:0°(正立)
- 类别2:90°(顺时针旋转90°)
- 类别3:180°(倒置)
模型架构
视觉编码器
初始化Phi-3.5-Vision-Instruct的视觉编码器作为 backbone,该编码器基于CLIP ViT-L/14结构,具备强视觉特征提取能力,且参数量适中(整体模型约304M参数)。
动态裁剪策略
为解决单一图像输入难以兼顾"全局布局"和"局部文本细节"的问题,设计了多尺度裁剪方案:
- 预处理步骤:先将输入图像(RGB格式,H×W×3)缩放、填充至"长和宽均能被336整除"的分辨率。
- 裁剪生成:
- 局部裁剪:将图像分割为不重叠的336×336补丁(最多16个),捕捉局部文本特征。
- 全局裁剪:将整图缩放到336×336,保留全局布局信息。
这么做可以通过多视角输入提升模型对文本位置不均、边缘填充过多等复杂场景的鲁棒性。
分类头
既然是一个四分类任务,那么自然有基于特征的分类头。
- 特征聚合:每个裁剪块经编码器输出序列后,提取首个位置的CLS token(全局特征表示,跟bert的分类类似),再对所有裁剪块的CLS token取平均,得到统一的图像表征。
- 多层分类头:采用轻量前馈神经网络,结构为:
- 第一层:线性投影(维度从D→D/2,D为编码器输出维度1024)+ GELU激活 + 20% dropout(防过拟合)。
- 第二层:线性投影(维度从D/2→4),输出四分类logits。
- 损失函数:Softmax交叉熵损失。
数据

训练数据:英文数据集(11K文档图像,含发票、合同等真实场景);11种印度语言数据集(38K图像,源自Wikisource
旋转增强:对训练数据均匀施加四种旋转变换,模拟真实的随机旋转场景。
性能
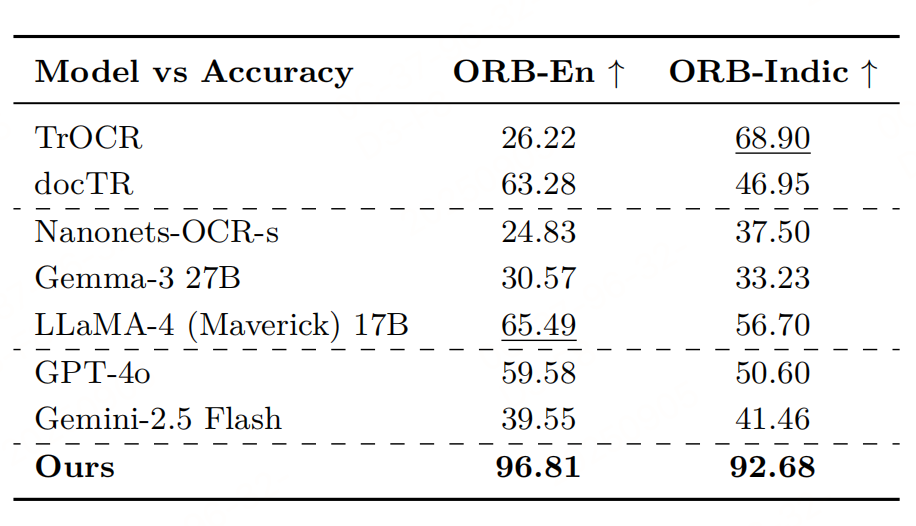
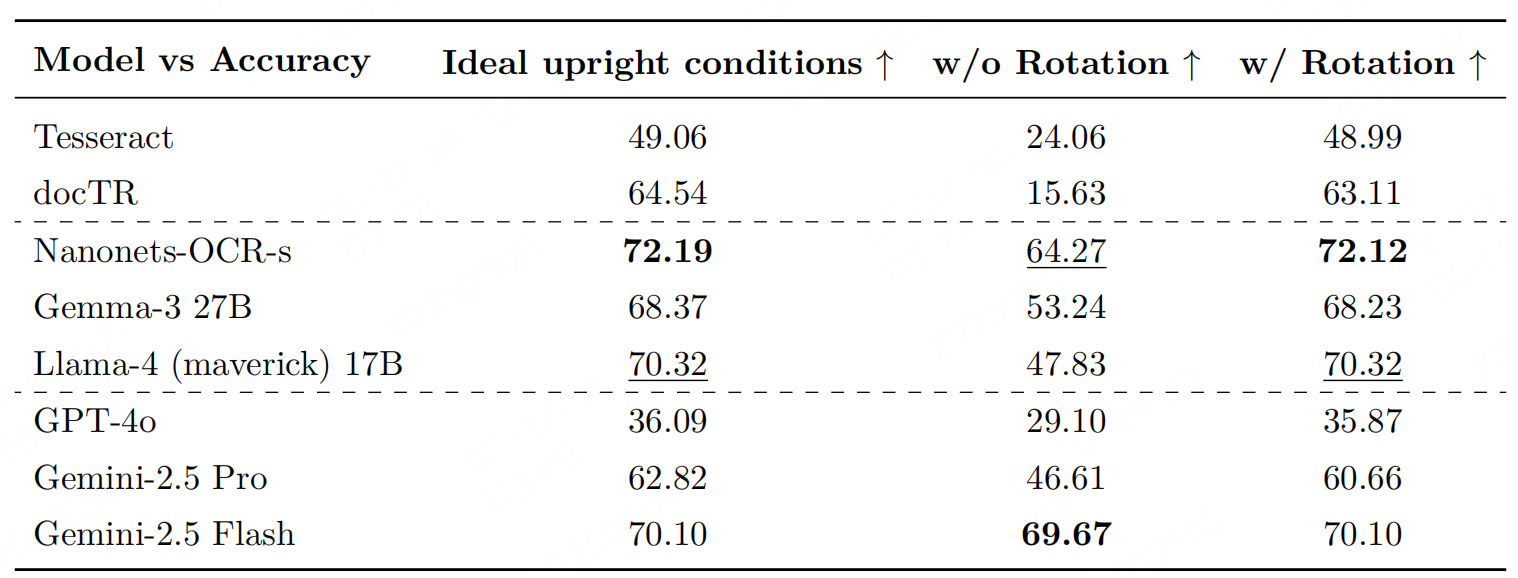
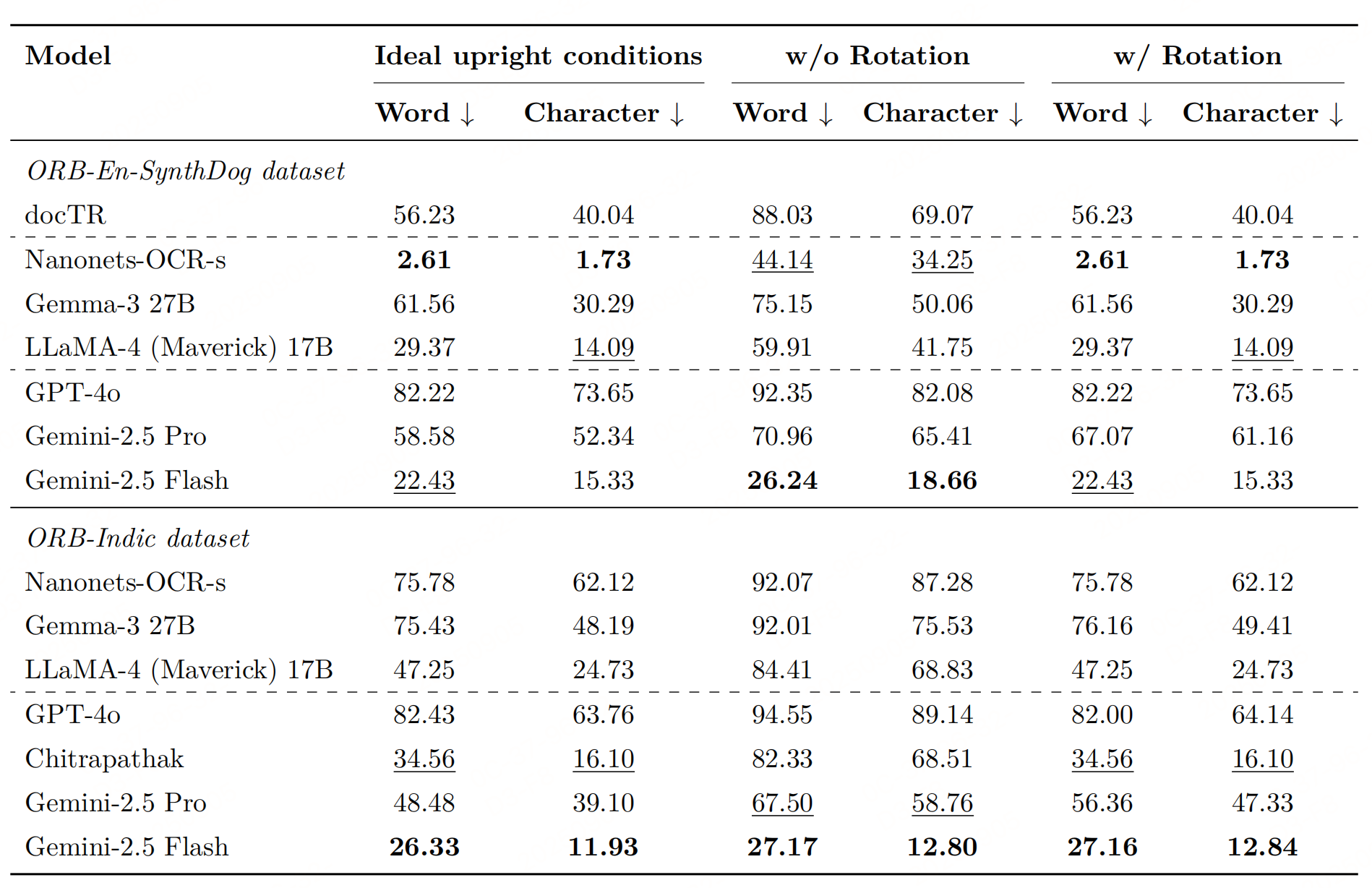
参考文献:Seeing Straight: Document Orientation Detection for Efficient OCR,https://arxiv.org/pdf/2511.04161v1