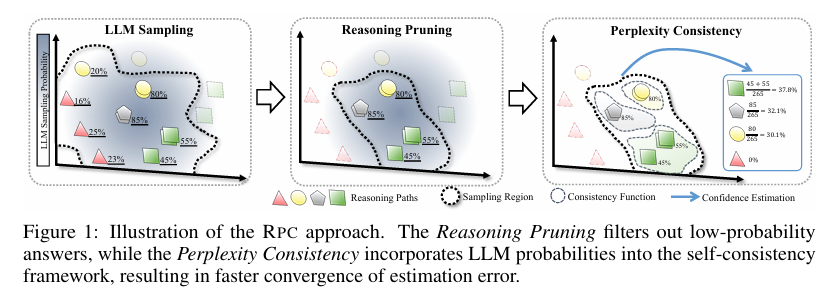
摘要 :测试时缩放(Test-time scaling)旨在通过增加计算资源来提升大型语言模型(LLMs)的推理性能。该领域内一种普遍采用的方法是基于采样的测试时缩放方法,这类方法通过在推理过程中为给定输入生成多条推理路径来增强推理能力。然而,尽管该方法在实际应用中取得了成功,但其理论基础仍有待深入探索。在本文中,我们从置信度估计的角度出发,为分析基于采样的测试时缩放方法提供了首个理论框架。基于该框架,我们分析了两种主流范式:自洽性(self-consistency)和困惑度(perplexity),并揭示了它们的主要局限性:自洽性存在较高的估计误差,而困惑度则表现出显著的建模误差,且估计误差收敛性可能下降。为解决这些局限性,我们引入了RPC这一混合方法,该方法通过两个关键组件------困惑度一致性(Perplexity Consistency)和推理剪枝(Reasoning Pruning)------来利用我们的理论洞见。困惑度一致性结合了自洽性和困惑度的优势,将估计误差的收敛速率从线性提升至指数级,同时保持了模型误差。推理剪枝则通过消除低概率推理路径来防止性能下降。在七个基准数据集上的理论分析和实证结果均表明,RPC在减少推理误差方面具有巨大潜力。值得注意的是,RPC在实现与自洽性相当的推理性能的同时,不仅提高了置信度的可靠性,还将采样成本降低了50%。代码和相关资源可在Github获取。Huggingface链接:Paper page,论文链接:2510.15444
研究背景和目的
研究背景 :
近年来,大型语言模型(LLMs)在问题解决、规划、决策等多个领域展现了卓越的推理能力。然而,为了进一步提升这些模型的推理性能,研究者和实践者常常采用测试时扩展方法(test-time scaling methods),即在推理阶段增加计算资源。
其中,基于采样的测试时扩展方法尤为流行,这类方法通过为给定输入生成多个推理路径来增强推理效果。尽管这些方法在实际应用中取得了显著成功,但其理论基础仍显薄弱,尤其是关于采样推理路径的置信度估计机制及其对推理性能的影响尚不充分。
研究目的 :
本研究旨在填补这一理论空白,通过构建一个基于置信度估计视角的理论框架,深入分析基于采样的测试时扩展方法。
具体目标包括:
- 分析现有方法的局限性:揭示自洽性方法(self-consistency)和困惑度方法(perplexity)在置信度估计上的关键不足。
- 提出改进方法:设计一种新的混合方法,即推理剪枝困惑度一致性(RPC),以克服现有方法的局限,提升推理性能和置信度可靠性。
- 验证方法的有效性:通过理论分析和实证研究,证明RPC方法在减少推理错误、提升推理性能和置信度可靠性方面的优势。
研究方法
理论框架构建 :
本研究首先构建了一个理论框架,将LLM推理错误分解为估计错误(Estimation Error)和模型错误(Model Error)两部分。
估计错误源于对采样推理路径置信度的不准确估计,而模型错误则反映了LLM本身推理能力的局限性。通过这一框架,研究能够系统地分析不同置信度估计方法对推理性能的影响。
现有方法分析:
- 自洽性方法:该方法通过比较多个采样推理路径的答案一致性来估计置信度,使用蒙特卡洛估计。然而,其估计错误仅随采样量线性下降,导致在有限采样预算下性能不佳。
- 困惑度方法:该方法直接利用LLM内部概率来估计置信度,理论上可实现指数级收敛速率。但实际应用中,当LLM内部概率较低时,其收敛优势会显著退化,且模型错误通常较大。
RPC方法设计 :
基于理论分析,研究提出了RPC方法,该方法包含两个关键组件:
- 困惑度一致性(Perplexity Consistency, PC):将LLM内部概率融入自洽性框架,以加速估计错误的指数级下降,同时保持较低的模型错误。
- 推理剪枝(Reasoning Pruning, RP):通过建模LLM内部概率分布,自动移除低概率推理路径,防止估计错误收敛速率的退化。
实证研究设计:
- 数据集:研究在七个基准数据集上进行了实验,包括四个数学推理数据集(MATH、MathOdyssey、OlympiadBench、AIME)和三个代码生成数据集(HumanEval、MBPP、APPS)。
- 模型选择:使用了InternLM2-Math-Plus 1.8B和7B模型,以及DeepSeekMath-RL7B模型进行数学推理实验;使用Deepseek-Coder 33B模型进行代码生成实验。
- 评估指标:主要评估指标为推理准确性和预期校准误差(Expected Calibration Error, ECE),以衡量推理性能和置信度可靠性。
研究结果
理论分析结果:
- RPC方法通过结合困惑度一致性和推理剪枝,成功实现了估计错误的快速下降,同时保持了较低的模型错误。理论证明显示,RPC方法在特定条件下可将估计错误的收敛速率从线性提升至指数级。
实证研究结果:
- 数学推理任务:在四个数学推理数据集上,RPC方法显著减少了达到自洽性方法最佳性能所需的采样量(至少减少50%),同时保持了相同的推理性能水平。在相同采样预算下,RPC方法平均提升了1.29%的推理准确性。
- 代码生成任务:在三个代码生成数据集上,RPC方法同样展现了最佳性能,进一步验证了其跨领域的有效性。
- 置信度可靠性:RPC方法提供了更接近真实值的置信度估计,ECE值显著低于其他比较方法,表明其置信度估计更为可靠。
研究局限
尽管本研究在理论分析和实证研究方面均取得了显著成果,但仍存在一些局限性:
- 理论框架的普适性:虽然理论框架适用于分析基于采样的测试时扩展方法,但本研究仅聚焦于两种典型方法(自洽性和困惑度)及其混合方法(RPC),未来可进一步拓展至其他先进方法。
- 后验方法的局限性:RPC方法作为一种后验方法,仅依赖于采样推理路径进行答案选择,无需修改LLM架构或训练过程。尽管这一设计使其易于使用,但与涉及模型训练的方法相比,性能提升较为有限。
- 方法设计的简化:当前RPC方法的设计相对简单,存在较大的改进空间。例如,困惑度一致性组件可扩展至包含其他概率度量,推理剪枝模块也可通过引入更先进的技术来提升效果。
未来研究方向
针对本研究的局限性和当前领域的空白,未来研究可从以下几个方向展开:
- 深化理论分析:进一步拓展理论框架,分析更多类型的测试时扩展方法,并探索不同方法之间的协同作用。同时,研究如何将理论框架应用于LLM的训练阶段,以提升模型本身的推理能力。
- 探索高级采样策略:基于理论分析结果,设计更有效的采样策略,以生成更多样化的推理路径。这有助于进一步提升推理性能和置信度可靠性。
- 开发任务特定方法:尽管RPC方法在多个推理任务中均展现了良好性能,但针对不同任务(如数学推理、代码生成、逻辑推理等)开发特定方法仍具有潜力。通过考虑不同任务中推理函数g(·)的特性,可设计出更具针对性的方法以提升性能。
- 结合外部知识源:探索如何将外部知识源(如知识图谱、领域特定数据库等)融入LLM推理过程,以进一步提升推理性能和置信度。这有助于解决LLM在处理复杂或专业领域问题时可能面临的局限性。