欢迎来到 OpenSearch!本书旨在为初学者和有经验的用户提供一份关于 OpenSearch 的全面指南。随着 OpenSearch 的采用迅速增长,本书恰逢其时,帮助开发者、工程师、数据科学家和系统管理员利用这一强大的开源搜索与分析引擎,构建稳健的搜索体验,并从数据中获得有洞察力的分析。
在本章中,你将了解 OpenSearch 的来龙去脉、核心特性以及其在真实场景中的用法。你将先认识 OpenSearch 的起源,以及它如何作为一个社区项目逐步发展壮大。随后,你会探索 OpenSearch 的关键能力,例如以特定方式组织信息、处理海量数据、以及为查询返回高度相关的结果。本章还会分享 OpenSearch 在日常情境中的实际应用,如电商商品搜索、计算机系统健康监测,以及为用户推荐有趣内容。你将认识一款用途广泛、功能强大的工具!
本章将涵盖以下主题:
- 认识 OpenSearch 及其演进之路
- 理解 OpenSearch 的核心能力
- 真实世界的案例与用例
- 用 OpenSearch 变革电商搜索
- 借助 OpenSearch 日志分析与可观测性提升运维效率
认识 OpenSearch 及其演进之路
在本节里,我们将回顾搜索引擎的历史,以理解它们在日常生活中的角色。搜索引擎随着万维网的兴起在 1990 年代初进入公众视野。万维网的诞生带来了出版的民主化------人们可以发布并共享信息、观点、科研数据等。超链接让站内与跨站阅读变得交互式。如果你知道该去哪里找,你几乎可以挖掘并学习任何东西!
然而,知道到哪里去寻找某个关键字/字符串或条目并不容易。AltaVista、Ask Jeeves、Yahoo! 和 Google 等网络搜索引擎的目标,是在用户查询时编目并返回网页。它们对网页上的信息进行索引,并用统一资源定位符(URL)列表来响应用户查询。对于一个查询,搜索引擎会依据相关性度量来排序,这些度量综合了关于文档集合的各类信息。
搜索已经成为我们日常生活中不可或缺的一部分。无论是找信息、商品、地点,甚至是人,我们常常依赖应用与网站中的搜索引擎和搜索功能。
无论是在线搜索、查找联系人,还是寻找文件,高效的搜索都至关重要。据估计,2020 年人类每天产生的数据量达到 2.5×10¹⁸(2.5 百京)字节。随着数据体量每年呈指数级增长,开发可扩展的搜索技术已变得至关重要。
让我们看看日常中的几个例子。使用 Google 搜索几乎等同于"上网查一查"。无论你需要快速事实、附近餐馆的位置、前往目的地的路线,还是各种随机问题的答案,Google 都会从其庞大的网页索引中提供相关信息。Google 如此普及,以至于 "Googling" 已成了进行网络搜索的常用动词。搜索在网上购物中同样扮演着重要角色。像 Amazon 这样的电商网站和应用高度依赖搜索功能,帮助用户在海量的商品目录中找到目标。消费者可以按商品名称、类别、品牌、价格区间等进行筛选以缩小范围。搜索结果越相关,用户越可能找到并购买所需商品。Facebook、Instagram 等社交应用也通过搜索把用户和他们想找的人、群组、照片与动态连接起来。借助搜索框,用户可以基于用户名、话题标签或关键字直接访问来自好友与公众人物的内容。相比按时间线浏览,搜索可以更快定位特定帖子、图片与个人主页!无论是在无垠的互联网中,还是在你个人的消息、照片与笔记集合里,你都在用搜索来高效获取相关信息与连接。我们每天使用的诸多搜索创新,已经改变了我们获取知识、与数字世界互动的方式。尽管搜索看似基础设施,其重要性与底层技术却复杂而持续演进。
词法索引、神经网络与排序算法等技术,使得在海量数据库中的强健检索成为可能。词法方法可以通过系统化的元数据标签快速缩小范围,将描述性标签应用于内容以实现高效的分类与检索。更先进的神经模型能够解析文本与语音中的上下文含义,从而支持灵活的自然语言搜索。排序算法还会处理多种信号,基于历史交互确定最优结果顺序。将这些范式结合,现代应用就能在庞大数据集上处理不精确搜索。即便是一条简短的文本或语音查询,也会在几乎瞬时的时间内经历复杂的检索过程。同样的能力也让数据库与内容系统可以摄取新内容,并通过智能索引让其可被发现。随着人们对移动应用、网络服务、商业分析与个性化推荐的依赖不断上升,对复杂搜索的需求也随之增长。幸运的是,机器学习提供了越来越强的工具,帮助我们理解指数膨胀的数据海洋。保持可访问性与相关性,对于实现低延迟且准确的搜索响应的价值至关重要。
既然我们已经了解了搜索的背景,接下来让我们梳理一套典型的搜索架构,以及构建它需要什么。
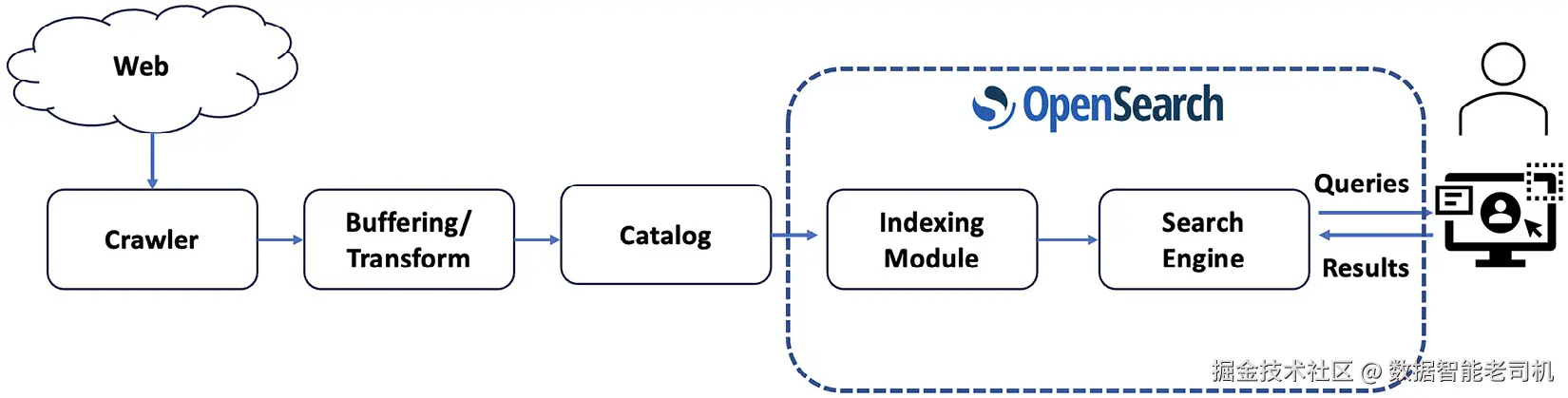
图 1.1:搜索的组件架构
尽管将数据从源头搬运到搜索引擎的架构形态多种多样,但一套典型的搜索架构通常由若干关键组件协同工作,以实现高效的数据摄取、索引与检索。
- 语料库(corpus) :即你希望被搜索的数据集合------你的商品目录、企业文档库,甚至整个万维网。
- 采集代理(collection agent) :负责从语料库中发现并抓取数据。对于以搜索为后端的应用,你可能会编写自定义采集组件;对于 Web 搜索,可以使用 Apache Nutch 或 Googlebot 等爬虫。
- 缓冲/转换(buffer/transform) :对原始数据做处理与规范化,执行过滤、富化或格式转换等任务;常用工具包括 Apache Kafka 或 OpenSearch 项目的 Data Prepper。
- 投递(delivery) :连接搜索引擎并通过 REST API 发送处理后的数据。自定义脚本、Data Prepper 等组件以及爬虫都可以把数据投递到搜索引擎。
- 索引模块(在图 1.1 中为 OpenSearch 内部模块):接收处理后的数据,构建用于快速查询的优化索引。
- 搜索模块:对索引执行用户查询,对结果进行排序,并返回相关结果。
这些组件共同形成一条可扩展、具备容错能力的流水线,把原始数据转化为可行动的搜索结果。
补充性数据存储指用于补充搜索能力与工作负载的其他数据库,如对象存储(S3)、数据仓库(Redshift)、Hadoop(HDFS)等。关键原则是将摄取、存储、索引、元数据与查询功能分离,以实现可扩展性与灵活性。各组件通过 API 与标准化接口通信。OpenSearch 在单一平台中提供索引、存储与搜索能力,而自建的搜索基础设施则可能为架构中的每个部分组合专门化工具。
示例:一套现代电商搜索系统可能使用 OpenSearch 作为核心搜索引擎,将商品目录数据建立索引以支持快速全文检索。图片与视频存储在 S3 中,其元数据与描述符写入 OpenSearch 以便可被搜索。用户行为数据可能通过 Kafka 同时流入 OpenSearch(用于实时个性化)和 Redshift(用于更深入的分析)。搜索 API 层将编排跨系统的查询,例如用 OpenSearch 处理文本检索,同时查询基于用户行为数据构建的推荐服务。该模块化架构允许各组件独立扩展,并可针对不同内容类型与搜索模式进行专门优化。
OpenSearch 的演进
OpenSearch 源自 Elasticsearch------这是一款开源的搜索与分析引擎,最早于 2010 年以 Apache License 2.0 许可发布。Elasticsearch 因其速度与可扩展性,以及对开发者友好的 API 而迅速走红。2021 年 1 月,Amazon Web Services 基于 Apache 许可的 Elasticsearch 7.10.2 版本进行分叉,创建了 OpenSearch 项目。2021 年 7 月,Amazon 使 OpenSearch 1.0 正式可用。OpenSearch 是一个完全开源、由社区驱动的分叉项目。Amazon 的目标是为希望使用并共同推动该引擎能力增长的用户,提供一个自由开放的替代选择。自发布以来,OpenSearch 获得了强劲的采用和活跃的开源社区贡献。该项目聚焦于提供可用于生产的搜索、分析与向量数据库能力,并配套企业级安全、告警与报表等特性。2024 年 9 月,Amazon 与核心会员 SAP、Uber 以及 12 家普通会员共同在 Linux 基金会旗下成立了 OpenSearch Software Foundation (opensearch.org/foundation),为项目的未来发展提供开放治理与供应商中立的基金会。
现在你已经对 OpenSearch 的过去有所了解,接下来就通过探索其核心能力,看看它能带来什么。
理解 OpenSearch 的核心能力
在本节中,你将从构建者(builder)的视角出发,聚焦于项目的各个服务组件,探索 OpenSearch 的核心能力。
OpenSearch Project(github.com/opensearch-...) 是由多个子项目组成的软件套件,包括:
- OpenSearch:一个基于 REST(表述性状态转移)API 的分布式系统;
- OpenSearch Dashboards:图形化用户界面(GUI)前端;
- 约 40 个插件,提供异常检测、细粒度访问控制、告警、SQL 查询、向量存储与检索等高级能力。
分布式数据库
OpenSearch 归属于数据库技术家族。与其他数据库一样,它存储并组织信息以便高效检索。OpenSearch 提供支持 CRUD(创建、读取、更新、删除) 的 REST API,以及一系列管理操作。你通过索引 API 将数据发送到 OpenSearch,通过搜索 API 查询数据;OpenSearch 将数据存放在你创建和管理的 索引(index) 中。
OpenSearch(以及更广义的搜索引擎)最初被设计为 关系型数据库管理系统(RDBMS) 的补充。关系型数据库具备使其可靠、可预测且可组合的一系列重要特性,即 ACID(原子性、一致性、隔离性、持久性):
- 原子性:事务中的操作要么全部成功,要么全部失败
- 一致性:保证读取的一致性
- 隔离性:并发操作互不干扰
- 持久性:一旦成功提交,结果被持久保存
此外,关系型数据库还能通过外键设计数据表示,并执行跨表连接(join)的查询。
为了维持 ACID,关系数据库在扩展到极高并发时可能受限。搜索引擎则通过不保证 ACID 来换取更高的扩展性与更低的查询延迟。OpenSearch 提供最终一致性(eventual consistency),不提供原子操作,也不提供事务 ,并且最适合以 扁平化/反规范化 的形式存储数据。作为取舍,这让 OpenSearch 能横向扩展到 每秒 100,000+ 操作 ,跨越 TB 乃至 PB 级 数据进行处理。常见情况下,服务端平均处理时间为 个位数毫秒 ,p90 延迟约 20--30 ms。
OpenSearch 是 分布式数据库 。你将其以集群方式部署到一组容器或服务器节点上。OpenSearch 节点为索引、存储与查询处理提供所需资源。每个节点可能承担一种或多种职责;其中最重要的是 数据节点(data node) (负责索引、存储、搜索的核心资源)和 集群管理节点(cluster manager node) (维护集群状态)。你将在下一章进一步了解节点类型。
通过放宽 ACID 约束、采用分布式架构以实现水平扩展和并行请求处理,搜索引擎设计者构建出既能容纳更多数据、又能以更高吞吐与更低延迟返回结果的系统。
词法检索(Lexical Search)
OpenSearch 最核心、也最能定义它的首要用例就是 词法检索 。用户带着信息目标而来:想买某个产品、在文档中找信息、或定位一张网页。他们用 词 来表达目标。OpenSearch 让你可以基于用户输入的词来检索结果:
- 在电商网站中,输入框里的词会与商品标题、描述中的词匹配;
- 在大型文档库(Wiki、PDF、Word 等)中,输入的词会与所有文档中的词匹配,从而找回与你意图最契合的内容。
当你为语料库建立索引时,OpenSearch 提供高效的 词匹配 工具。你的语料可能高度结构化(来自其他数据库系统),OpenSearch 为这类结构化元数据提供 精确、整串 匹配;也可能是非结构化文本(PDF、Word 等),OpenSearch 提供将自由文本解析与规范化为 单词项 的工具,以支持逐词匹配。大多数情况下,你都会同时拥有结构化元数据与自由文本。
索引(indices) 及其存储文档的数据结构,是实现高效"词对词"匹配的关键。OpenSearch 的索引持有一个个 搜索文档(search document) ,每个文档代表语料库中的一个可检索项。可类比为:索引 ≈ 关系库的表,文档 ≈ 行,字段 ≈ 列,字段值 ≈ 单元格。
- 若你处理的是来自关系数据库的结构化元数据,可将其导出并写入 OpenSearch。像数据库对单元格进行精确匹配那样,OpenSearch 也能对字段值做精确匹配,并以 低延迟、高吞吐 响应,从而显著减轻数据库压力、把查询时延从秒/分钟级降到毫秒/秒级。
- 若你处理的是自由文本(不论来自完整文档,还是来自关系库的某个字段),OpenSearch 提供 分析(analysis) 工具,将自由文本解析为可匹配的单词,应用自然语言规则,并存储由此产生的词项。此分析会将词还原为核心语义(如 running → run ),即便单词以不同形态出现,也能更好地匹配用户的查询与语料内容。
例如,字符串 "the quick brown fox jumped over the lazy dog " 的英文分析结果为:quick brown fox jump over lazi dog 。若用户查询 "jumping foxes "(分析为 jump fox )、"the fox's laziness "(fox lazi )、"Lazy Foxes and Dogs "(lazi fox dog),OpenSearch 的英文分析器会让源文与查询项实现对应匹配(第 4 章将深入介绍文本分析)。
随之而来的关键问题是:匹配更多文本也意味着可能匹配到语义更远的文本,OpenSearch 如何确保"好匹配"?
所谓 相关性(relevance) ,是搜索结果与触发该结果的查询之间的匹配程度。OpenSearch 使用一种打分函数 TF/IDF(更准确地说是 Okapi BM25) 来为每个匹配文本打分,并按分值排序。BM25 的核心思想是:将某个词在语料中"常见程度"的度量,与其在文档中出现的次数相结合;稀有词 通常信息量更大、区分力更强,因而得分更高;常见词 信息量小,得分较低;而 停用词 (如 a、an、the)通常直接过滤。BM25 排序长期是搜索引擎的主流。近年,随着自然语言处理进步,利用 大语言模型(LLM) 生成 向量嵌入(embeddings) 的新评分方法崛起。
基于向量嵌入的语义检索(Semantic Search)
语义检索 在更高层次上实现"意对意"的匹配。近五年里,Transformer 架构推动了文本生成、聊天机器人、AI 助手与智能体的突破。诸如 BERT 这类 LLM 能将自然语言映射为向量(多维空间中的点)。
如 Amazon Titan Text Embeddings 、Anthropic Claude 等模型(也有编码图像/视频/音频的模型)会把输入转成一串浮点数(常见维度 384、768、1536 等)。嵌入模型让"语义相近"的词/文本在向量空间中彼此接近,"语义相远"的彼此远离(例如 dog 接近 puppy ,远离 skyscraper)。
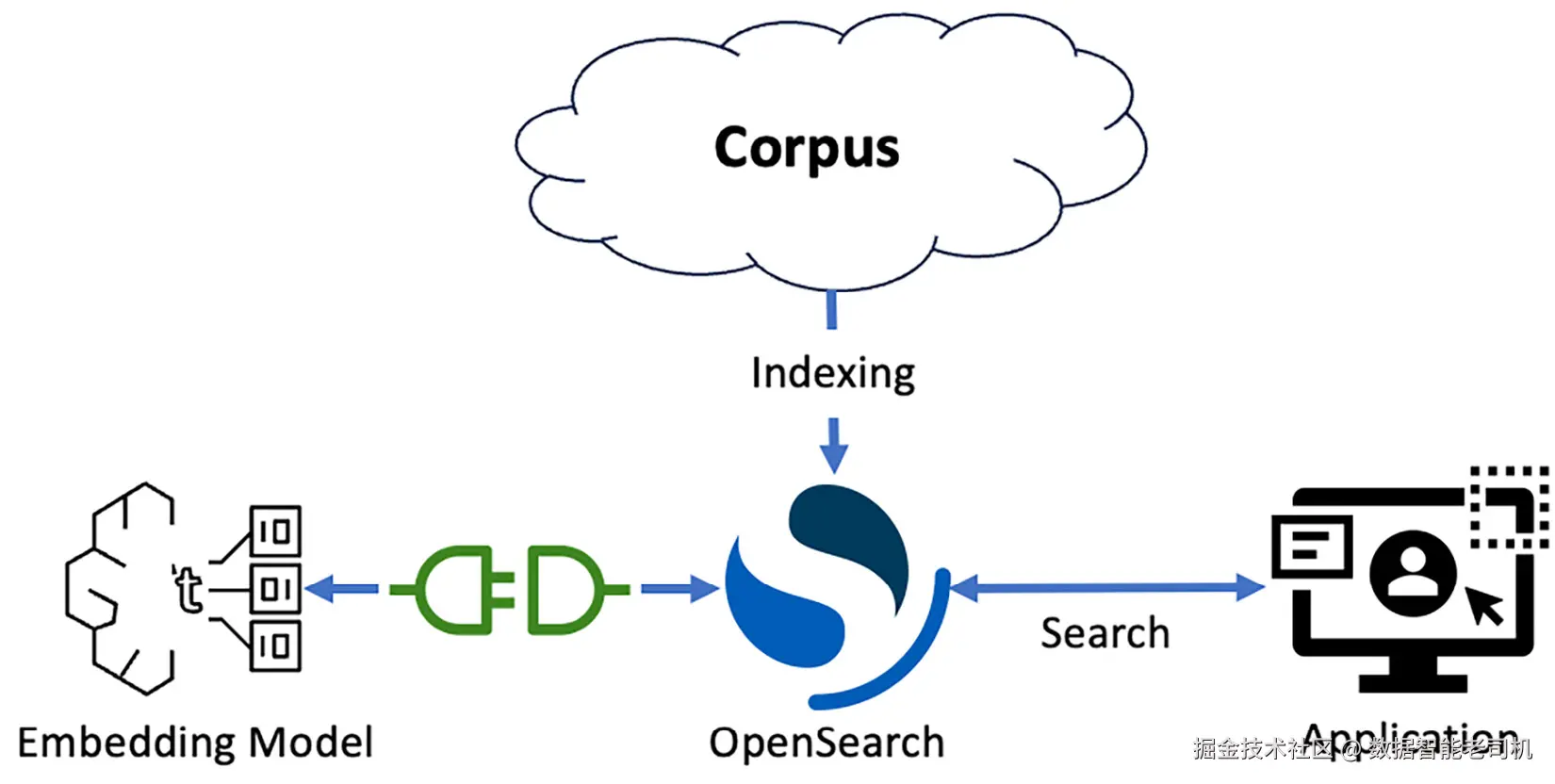
如 图 1.2 所示,要做语义检索,首先需为每个文档生成嵌入。这可以在 OpenSearch 之外的"文档转换"流程中完成,或用 OpenSearch 的 Connector 框架 自动生成。OpenSearch 将每个嵌入随文档一起存入 kNN 索引 。查询时,你为查询生成嵌入(或让 Connector 框架代劳),然后使用 最近邻查询 按向量距离为文档打分。因为向量保留了词语的大量语义信息,匹配结果通常高度相关。在标准基准上,语义检索相较 BM25 可提升约 10--20% 的相关性。
OpenSearch 的 K-Nearest Neighbor(KNN)插件 提供了存储、匹配、打分向量嵌入的引擎与算法:
- 文档较少时可用 精确 KNN(与所有向量匹配,代价随规模急剧上升);
- 海量文档时采用 近似 KNN,以启发式算法减少比对数量,降低延迟、以少量准确率为代价换取性能。
KNN 插件支持三类存储与查询引擎:NMSLib 、FAISS 、Lucene 向量引擎。它们提供两类常用算法:
- HNSW(层次化可导航小世界图) :由 Lucene、NMSLib、FAISS 支持;通过多层图从粗到细地搜索邻居,逐层细化,最终在叶层命中近邻。
- IVF(倒排文件) :索引时进行聚类,选取质心;查询时只检索与查询向量最近的若干簇。可配合 产品量化(PQ) 压缩存储字节数,以空间/延迟换取一定精度损失。
OpenSearch 最新的语义检索技术还包括 稀疏向量 (参见 opensearch.org/docs/latest...)。稀疏向量通过分词器减少总词项数,并为每个词项赋权;与稠密向量不同,稀疏向量与原始词项保持更紧密的对应关系,同时通过权重具备一定泛化能力。
Neural 插件 简化了索引与查询阶段添加向量嵌入的流程:既可使用部署在集群内、带 ml 角色 的自定义模型,也可对接第三方模型托管服务。做语义检索时,通常会部署一个或多个 专用 ml 节点 以降低对其他节点的影响。OpenSearch 还能连接 Amazon Bedrock、Amazon SageMaker、Cohere、OpenAI 等托管服务。
那么,词法检索与语义检索哪个更好?
各有所长。许多场景下,精确匹配 + BM25 的效果与稠密向量的语义检索相当甚至更好。比如你要买 "Eastman 1/2 inch FIP x 3/8 inch OD Compression Quarter Turn Angle Stop Valve, Brass Plumbing Fitting, Chrome, 10733LF" ,直接搜 "Eastman 10733LF" 就不需要(也不希望)语义泛化。
但如果查询是 "适合全家观看且情节有趣的电影" ,稠密向量的语义检索更合适。稀疏向量 因保留与源词更紧密的映射,能在更多情形下取得成功。OpenSearch 还通过 Neural 插件提供 混合检索(hybrid search) (opensearch.org/docs/latest...):同时运行 BM25 与向量检索,并对分数归一与融合,在标准基准上可带来约 14--17% 的准确率提升。
日志分析(Log Analytics)
到目前为止,我们主要讨论了 OpenSearch 在"搜索你的数据、找到相关结果"方面的能力。OpenSearch 还擅长存储与分析 时序数据 。约有一半用例是"纯搜索",另一半是 存储/搜索/分析 trace、日志、指标 数据,用于 DevOps、安防监控、应用与基础设施监测 等。
OpenSearch 的监控能力源自其核心搜索能力。构建者在实现搜索体验时,发展出了用于 分面(faceted)搜索 的 UI 与 API:比如在 Amazon 上搜索 "golf shirt" 时,页面会基于匹配到的文档统计品牌、价格区间、颜色、尺码等分面;你可以点击分面为查询增加过滤条件。
本质上,分面就是对某字段各取值的计数 。OpenSearch 将值聚合成桶并统计文档数。发送日志到 OpenSearch 前,通常先把原始日志行(往往是一条字符串)解析为结构化的 JSON 字段。例如来自 NASA 1995 年 7 月航天飞机发射 期间的(已脱敏)Apache httpd 日志行:
arduino
192.168.81.55 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245小贴士:在下一代 Packt Reader 中可以使用 "AI 代码讲解" 与 "一键复制" 功能......(略)
将其转换以便写入 OpenSearch,可解析为如下 JSON(并可用 IP 做地理信息富化等):
json
{
"host": "192.168.81.55",
"client": "-",
"user": "-",
"timestamp": "[01/Jul/1995:00:00:01 -0400]",
"request": "GET /history/apollo/ HTTP 1.0",
"status_code": 200,
"bytes": 6245
}有了结构化字段,配合 过滤 与 聚合 就能发挥巨大价值。随着技术成熟,人们为聚合加入了数学能力(求和、平均、标准差、最小/最大等)。再结合字段过滤,聚合就能用来监控关键指标。若你有上百上千台 Web 服务器,把它们的访问日志都写入 OpenSearch,随后你可以运行查询来回答:
- 最常被访问的资源是什么?
- 从 7 月 1 日 0:00 至 10:00,按 5 分钟间隔累计,服务器共发送了多少字节?
- 主机 192.168.81.55 访问了网站多少次?
时序数据的价值与其时效性高度相关。 监控基础设施可用性时,你需要尽快获知异常;若监控延迟 15 分钟,故障响应就会滞后 15 分钟。OpenSearch 支持 近实时(near real-time) 更新,能以极小延迟摄取 百万级/分 的日志并快速可检索与可视化。
OpenSearch Dashboards (github.com/opensearch-...)是 OpenSearch 项目的一部分,也是开源的数据可视化工具:
- 提供管理功能与基于插件的告警、异常检测、可观测性、安全分析方案;
- 便于构建可视化与仪表板,并近实时监控软硬件系统。
下图展示了一个基于 Apache Web 日志的监控面板,你可以看到饼图、仪表、面积图、直方图等可视化形式。
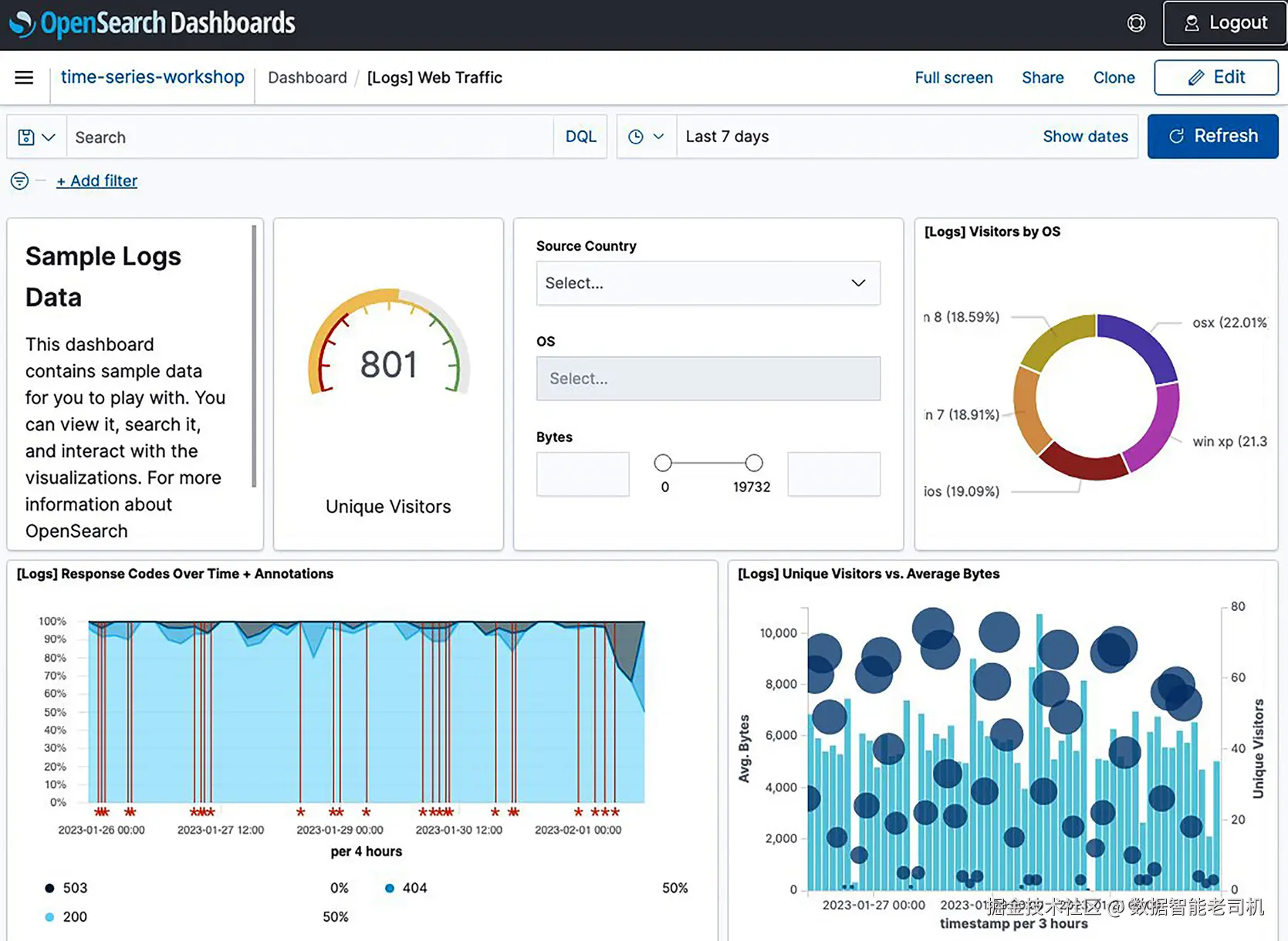
图 1.3:用于日志分析的 OpenSearch Dashboard
小贴士:需要更高清的图片?可在 Packt Reader 或 PDF/ePub 中查看......(略)
借助 OpenSearch + OpenSearch Dashboards ,你可以获得一整套 搜索、分析、可视化 数据的能力。OpenSearch 既能帮你从日志中挖掘关键信息、找到想买的产品,也能确保你的应用正常、安全地运行。接下来我们将转向一些 真实世界的案例,看看人们如何用 OpenSearch 解决上述问题,乃至更多。
真实世界的案例与用例
在本节中,我们将探讨 OpenSearch 在各行各业的多样化落地,展示其在不同场景中的适配性。从重塑电商平台的商品搜索,到为医疗环境提供关键洞察,OpenSearch 都证明了自己的通用性。更进一步,我们还将讨论 语义搜索 相关的用例:OpenSearch 利用自然语言处理(NLP)理解用户查询意图,返回高度相关的结果。比如,查询 formal attire for a beach wedding (海边婚礼的正式服饰),系统会给出适合温暖天气且满足正式场合的定制化结果,从而通过上下文准确性显著提升用户体验。最后,我们将以 日志分析 的关键作用作结:OpenSearch 能让组织实时处理与分析海量日志数据,便于主动发现与解决问题。其强大的搜索与聚合能力,帮助用户从日志中挖掘用于故障排查、性能监控与安全分析的洞察;配合成熟的可视化工具,团队可以把握系统行为与性能趋势,从而提升整体运维效率与可靠性。我们都爱购物,因此电商常被视为搜索的"显学";但在我们身边,还有大量依赖搜索与日志分析变体的应用。下面进入若干典型场景:
电商(E-commerce)
- 商品搜索:按关键字、类别、品牌、价格区间等帮助用户找到目标商品
- 商品推荐:基于历史购买、浏览记录、购物车等进行推荐
媒体 / 文娱(Media / Entertainment)
- 媒体检索:按标题、艺人、类型、发行日期等搜索电影、剧集、音乐、图书等
- 个性化内容推荐:基于过往互动、点赞与偏好,推荐新的剧集、电影、音乐、图书等
旅游与酒店(Travel & Hospitality)
- 旅行搜索:按目的地、日期区间、预算、设施等搜索航班、酒店、民宿等
- 个性化目的地推荐:基于历史行程、浏览记录、常驻位置与收藏地点提供出行建议
银行 / 金融(Banking / Finance)
- 交易搜索:按关键字、商户名、日期范围、金额等查找历史交易
- 对账与个性化洞察:分析消费模式,为每位用户提供预算、账单与储蓄目标的定制化洞察
医疗(Healthcare)
- 健康档案搜索:在个人健康档案中检索化验结果、用药、免疫接种、报告等
新闻 / 资讯(News / Information)
- 新闻检索:按关键字、实体、类别、日期范围等查找文章
- 个性化新闻推荐:基于阅读历史与兴趣偏好推荐文章与话题
求职 / 职业(Jobs / Careers)
- 职位搜索:按职位名称、关键字、地点、公司与薪资范围搜索在招岗位
- 个性化职位推荐:基于浏览记录、技能、经验与偏好推荐岗位机会
社交媒体(Social Media)
- 内容搜索:通过关键字、话题标签与提及,搜索平台上的帖子、用户与页面
- 个性化信息流、Percolator 用例与社媒监控:策划用户的信息流,呈现其常互动的人与话题的内容
零售银行(Retail Banking)
- 账户搜索:便捷定位并访问账户与交易
- 个性化洞察:分析账户交易,提供消费习惯、预算与长期目标的建议
制造业(Manufacturing)
- 零部件搜索:按部件号、关键字与规格快速查找库存部件
- 个性化部件推荐:基于历史订单中选择的部件,推荐替代或互补部件
地理空间分析(Geo-spatial Analysis)
- 地点搜索:搜索地址、兴趣点、空间坐标等
- 个性化地点推荐:根据过往到访地点与偏好推荐可去之处
采矿(Mining)
- 地质数据搜索:在地质调查数据集中检索潜在矿产地
- 个性化洞察:分析调查数据与地质图,标示更可能存在矿藏的区域
天文学(Astronomy)
- 天体搜索:在星表与数据库中检索恒星、星系、星云等
- 个性化星空图:基于观测位置、设备与兴趣生成标注目标的夜空图
房地产(Real Estate)
- 基于地理位置的搜索与推荐:推荐性价比房源;通过 Percolator 做房源提醒
连锁快餐与配送(QSR & Delivery)
- 定位与匹配:定位配送骑手、同邮编客户与附近餐厅
对话式搜索(Conversational Search)
- 文档 / 聊天 / 地理对话搜索:如叫车、查找最近医院、图片搜索等的对话式体验
OpenSearch 用于日志分析(Log Analytics)
日志在各行业的故障排查、取证与可用性保障中至关重要。全球组织以多样方式使用 OpenSearch:
- Company X 在全球范围管理设备日志(此前为本地化 Elasticsearch);
- Company Y 专注基础设施监控;
- Company Z 为开发者每天处理 50 TB 的流媒体平台日志。
集中式日志帮助 Company A 通过历史数据调查税务欺诈;Company B 在 100 TB/日 规模上将可观测性标准化到 Amazon OpenSearch Service。除此之外,常见应用还包括 安全威胁狩猎、供应链可视化、订单追踪、微服务应用监控 等。OpenSearch 的核心价值在于:在海量数据上实现 实时分析 ------在 PB 级 存储下仍维持 低延迟查询 ,为 安全、运维与业务指标 提供关键洞察,助力复杂数据系统保持健康与安全。
本节我们概览了 OpenSearch 的真实应用:既可深入 语义搜索 获得定制化结果,也可利用 日志分析 主动化解问题。接下来,我们将更深入地剖析一个最受欢迎的用例------电商搜索------它已被 OpenSearch 深刻改造,并仍在持续演进。
用 OpenSearch 变革电商搜索
在节奏飞快的线上购物世界里,搜索功能的有效性常常决定一个平台的成败。凭借强大的检索能力,OpenSearch 正在重塑电商版图,使平台能够向用户提供高度相关、个性化的搜索结果。下面就来看几个 OpenSearch 改造商品搜索的典型用例:
- 更强的商品发现(Enhanced product discovery) :OpenSearch 通过直观而准确的搜索体验,强化电商平台的商品发现能力。用户只需输入诸如 blue jeans for men 或 summer dresses under $50 之类的查询,就能获得与其偏好高度匹配的定制化结果。
- 容错拼写与同义词匹配提升精确度 :OpenSearch 将拼写容错 与同义词匹配 融入电商搜索。例如用户想搜 blue floral dress 却误输入为 bloo floral dres ,OpenSearch 的拼写容错会自动更正,仍然返回准确结果。
此外,同义词匹配会扩展检索范围:如把 dress 的同义词 garment / apparel 纳入匹配,用户即便搜索 floral outfit 也能得到相关结果。最终,这既提升用户满意度,也能提高平台转化率,带动销量增长。 - 分面搜索与筛选(Faceted search & filtering) :借助 OpenSearch,平台可实现按尺码、颜色、价格区间、品牌等属性的分面筛选,帮助用户快速收敛范围,精准找到目标商品。
- 动态商品运营(Dynamic merchandising) :平台可依据实时数据与业务规则对列表进行加权或降权 :如按库存、销售表现、季节趋势、促销活动等调整曝光。在节日季,零售商可优先展示高毛利或契合热门礼品品类的商品。
- 实时库存管理(Real-time inventory) :OpenSearch 让商品数据得以及时索引与更新,确保搜索结果实时反映可售状态,避免缺货商品出现在结果中,降低用户挫败感。
- 个性化购物体验(Personalization) :结合机器学习与用户画像,OpenSearch 能理解用户偏好与行为,为其优先展示与推荐契合兴趣的商品,提升满意度与忠诚度。
总体而言,OpenSearch 让电商平台打造快速、准确、个性化 的搜索体验,增强用户参与,提升转化并最终推动营收增长。传统关键词检索 作为基础已沿用数十年,但也有局限:关键词常常含糊 、缺少上下文,易导致无关结果与不佳体验,也错失个性化推荐的机会。
这正是向量检索 "锦上添花"的地方。通过在关键词检索之上引入向量表示 ,OpenSearch 克服了关键词方法的不足:把商品与用户查询都映射为高维向量,实现语义理解 与上下文感知匹配 。即使查询中没有精确关键词 ,仍能返回与用户偏好高度一致的结果。简言之:关键词检索 是基础,向量检索 在其上叠加语义与上下文。两者结合,使 OpenSearch 能提供更快、更准、更个性化的体验,提升参与度与转化率,助力电商平台成功。
变革性的搜索:Iva 的时尚之旅
Iva 要为生日派对寻找理想礼服。她先在搜索框中用传统关键词输入 blue cocktail dress。平台仅凭关键词匹配,返回了大量结果:各种深浅的蓝色礼服、鸡尾酒会礼服,甚至还有不相关的鞋包配饰。选择太多让 Iva 不知所措,难以收敛。
不气馁的她改用同义词 拓展范围,输入 navy party gown ,希望探索相近色调。支持同义词匹配的平台智能理解了她的意图,呈现了一组更聚焦的海军蓝礼服。无关结果减少,让 Iva 更有信心继续筛选。
深入之后,Iva 体会到筛选与聚合 的重要性。她利用筛选器指定裙长、领型、面料 等偏好,快速剔除不合条件的款式;同时通过聚合对比价格、评分、流行度,更理性地排序与取舍。
转折点出现在她体验到语义搜索 的威力:被平台对自然语言的理解吸引,她输入 elegant evening gown with lace detail and A-line silhouette (优雅、带蕾丝细节、A 字版型的晚礼服)。平台精准理解并呈现与描述高度匹配 的精选礼服。Iva 意识到,语义搜索彻底升级了她的购物体验,让她发现真正契合自己风格的款式。
Iva 的旅程展示了搜索技术的演进及其对网购体验的深刻影响:从传统关键词 到高级语义 ,每一步都在增强她找到"那一件"的能力------这正是搜索创新在时尚领域的变革力量。除搜索外,OpenSearch 还提供全栈可观测性能力,帮助应用提升运维效率。
以 OpenSearch 的日志分析与可观测性最大化运维效率
在当今数字化环境中,企业高度依赖数据驱动的洞察 来优化运营并提供卓越的客户体验。借助强大的日志分析 与可观测性能力,OpenSearch 为企业释放数据价值、达成卓越运营提供了一套完整方案:
- 实时监控与告警 :聚合并分析来自服务器、应用、网络设备等多源日志,实时洞察系统健康与性能。OpenSearch 帮助识别异常与瓶颈,在影响业务前主动处置。实时告警让相关方迅速响应,降低风险,保障连续服务。
- 根因分析与故障排查 :当问题出现时,OpenSearch 通过将日志与系统指标、错误信息、性能指示相关联,帮助快速定位根因(无论是软件缺陷、基础设施故障还是网络瓶颈),针对性修复,缩短停机时间、提升可靠性。
- 容量规划与资源优化 :利用历史日志预测趋势 ,进行容量与资源的前瞻性规划。动态伸缩、避免过度或不足配置,优化利用率以匹配变化的负载,兼顾性能与成本。
- 安全监测与威胁检测 :超越性能层面的监控,扩展到安全分析 :从日志中识别可疑活动、未授权访问与异常行为,实时告警并联动响应流程,降低数据泄露、财务损失与品牌风险。
- 合规性 :在金融、医疗等强监管行业,OpenSearch 的日志分析能力帮助企业证明合规 ,追踪敏感数据访问并生成审计线索。集中化日志与严格的访问控制保证完整性、机密性与可用性,降低合规风险与处罚成本。
OpenSearch 提供的日志分析与可观测性解决方案,使组织能够获取关键洞察 、优化性能并精简运营流程,从而在整个技术栈上提升效率与决策质量。下一节,你将通过面向所有人的"playground"站点进行一次快速上手的体验。
你好,OpenSearch
在技术书籍里,尤其是讲编程语言的书中,历来有一个传统:通过编译并运行一小段在控制台打印 "Hello world" 的代码来起步。我们也想为 OpenSearch 提供一个类似的例子,但由于 OpenSearch 是一个分布式系统,搭建过程相对复杂,"简单例子"就不再那么简单。于是,我们鼓励你访问 playground.opensearch.org/ ,在那里通过连接 OpenSearch Dashboards 来体验它自身以及 OpenSearch 的部分能力。
当你连接到 playground 时,你将与 OpenSearch Dashboards 交互。先来运行一条查询。你会在屏幕右上角看到 Dev Tools 链接。点击它,然后关闭 "Welcome to the Console" 欢迎对话框。你会看到两个面板(见图 1.4)。
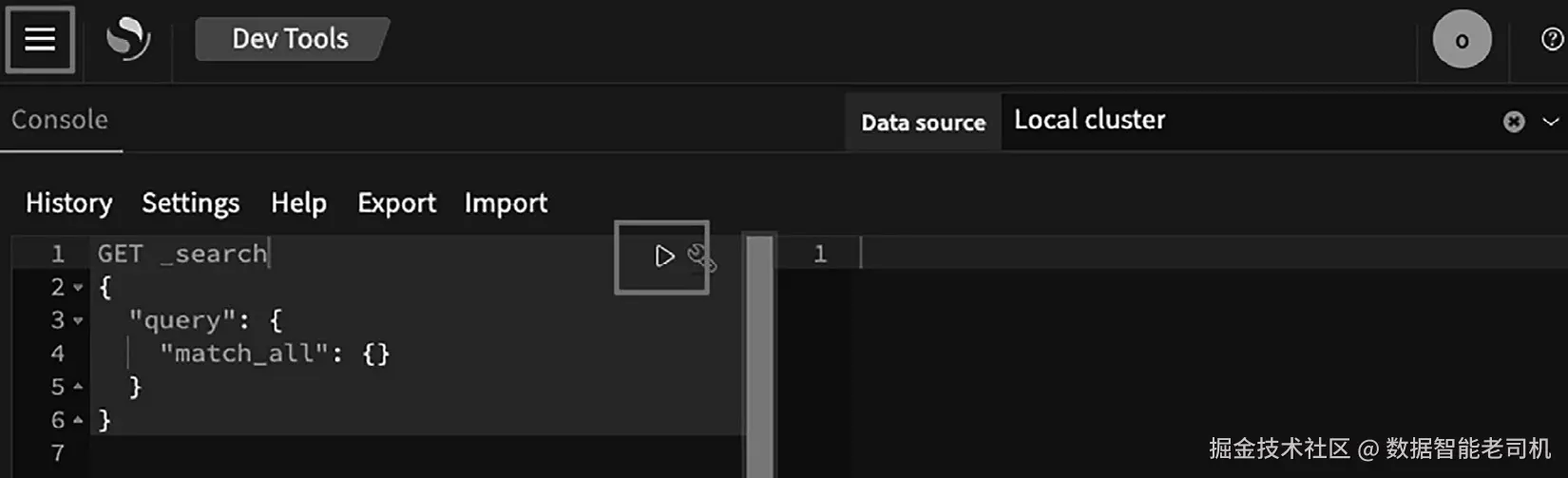
图 1.4:OpenSearch playground
你在左侧面板 输入并执行命令;右侧面板展示来自 OpenSearch 的响应。左侧面板中已预置了一条查询:
sql
GET _search
{
"query": {
"match_all": { }
}
}把光标放在这段代码中的任意位置,点击右指向的三角形按钮(见图 1.4)来执行查询。你会在右侧面板看到 OpenSearch 的响应。可以先随意滚动看看,目前不必纠结每个字段的含义。
运行过查询之后,再去看一个仪表板。OpenSearch playground 预装了 OpenSearch 的样例数据(logs、flights、e-commerce )以及相应的仪表板。点击屏幕左上角的三横线图标打开左侧导航 (见图 1.4),找到并点击 Dashboards 链接,你会看到可用仪表板的列表。点击 eCommerce Revenue Dashboard。浏览这些可视化,感受一下 OpenSearch 在日志数据上的可视化与分析能力。
Hello OpenSearch! 至此,你已经体验了一个基础的"搜索"示例和一个基础的"日志"示例。随着阅读的深入,你将逐步掌握为自己的数据设计查询与构建仪表板的技能。
总结
本章我们概览了开源搜索与分析引擎 OpenSearch 的核心能力与真实应用。首先介绍了它的起源与从 Elasticsearch 演进而来。OpenSearch 是一个分布式数据库系统,擅长词法文本检索 ,通过词形还原(lemmatization)与 BM25 等相关性算法,实现对相关结果的高速召回。同时,OpenSearch 还支持前沿的语义搜索 :利用向量嵌入 与近邻检索算法,实现更具语境与含义导向的匹配。
我们还强调了 OpenSearch 在日志分析与可观测性 方面的能力。它能够实时 摄取、存储与分析海量日志数据,在应用监控、事件响应、安全分析与合规审计等跨行业场景中价值巨大。章节中详细展示了 OpenSearch 如何以拼写容错、同义词匹配、分面导航、个性化推荐等特性,重塑电商搜索体验;通过一个贴近现实的购物场景,演示了包含语义搜索在内的高级技术如何显著改善用户体验。
此外,我们讨论了 OpenSearch 如何通过实时监控、根因分析、容量规划、安全监测与合规等能力,提升运维效率。整章穿插了医疗、金融、社交媒体、制造业等多行业的实例,说明 OpenSearch 如何帮助组织释放数据洞察、优化性能,并在搜索与数据分析的驱动下做出更优决策。
接下来,在本书的后续章节中,我们将回到 Iva 的购物旅程,并看到更多展示 OpenSearch 广度与深度的实例。准备好继续探索 OpenSearch 的奥秘,见证它在各行业中的深远影响吧!现在,让我们进入第 2 章,一起学习 OpenSearch 的基础知识与搭建流程。