目标检测技术正以前所未有的速度重塑着我们的世界。从自动驾驶汽车在城市街道上自如穿梭,到智能工厂精准监控生产线,这项技术已成为无数AI应用的核心支柱。
随着Transformer架构和注意力机制的快速发展,2025年的目标检测领域迎来了翻天覆地的变化。
RF-DETR和YOLOv12等新一代模型不断突破极限,在保持实时性能的同时实现了前所未有的精度。本文将带你全面了解当前最优的目标检测模型,并展示如何在不同硬件平台上高效部署这些模型。
模型评选的五大黄金准则
在选择目标检测模型时,我们遵循五个核心标准:
- 实时性能: 模型必须满足实时应用需求,在NVIDIA T4等标准GPU或边缘设备上达到30+ FPS,确保处理视频流和时间敏感任务时无明显延迟。
- 标准基准精度: 在Microsoft COCO等行业标准基准测试中表现优异,IoU 0.50:0.95条件下mAP至少达到45%,保证模型在各种目标尺度和类别上都能可靠检测。
- 模型效率与可扩展性: 架构应提供多种尺寸变体,在参数数量、FLOPs和精度间取得平衡,适应从边缘设备到云端的各种部署环境。
- 领域适应性: 强大的预训练模型应能良好迁移到自定义数据集,在RF100-VL等领域自适应基准测试中表现稳定,展现超越训练数据的泛化能力。
- 开发与部署支持: 优先选择拥有强大社区支持、定期更新和生产级部署工具的模型,确保从实验到生产的平滑过渡。
2025年五大顶尖目标检测模型
- RF-DETR:Transformer架构的实时突破
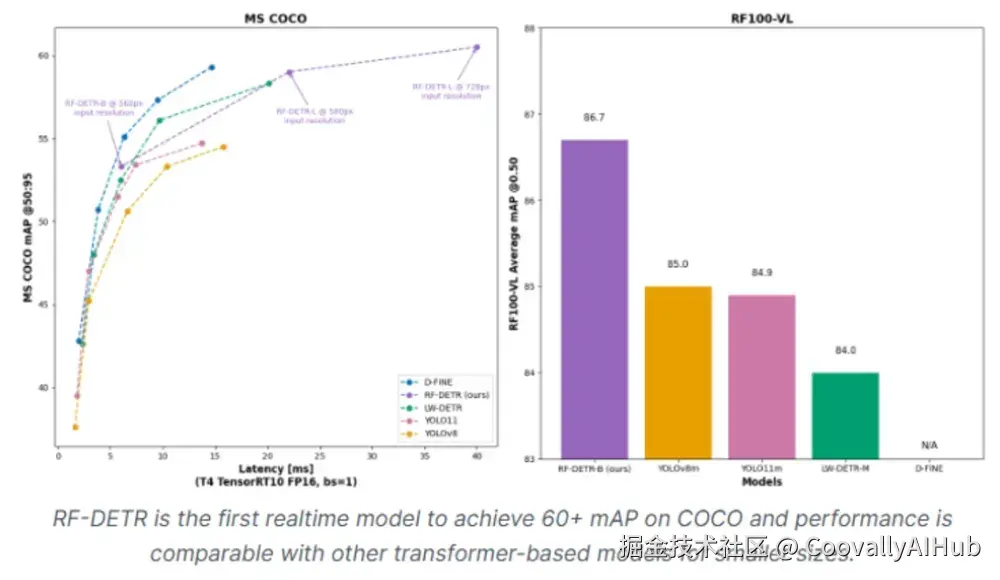
RF-DETR是Roboflow于2025年3月发布的革命性产品,作为首个在RF100-VL领域自适应基准测试中mAP超过60的实时模型,它标志着目标检测技术的重要里程碑。
核心优势:
- 采用DINOv2视觉骨干网络,提供卓越的迁移学习能力
- 真正的端到端架构,消除NMS和锚框等传统组件
- 专为不同领域和数据集规模设计,适用通用检测与专业应用
性能表现:
RF-DETR-M在T4 GPU上实现54.7% mAP,延迟仅4.52ms,在保持实时速度的同时性能优于同类YOLO模型。在RF100-VL基准测试中达到60.6% mAP,展现出色的领域适应性。
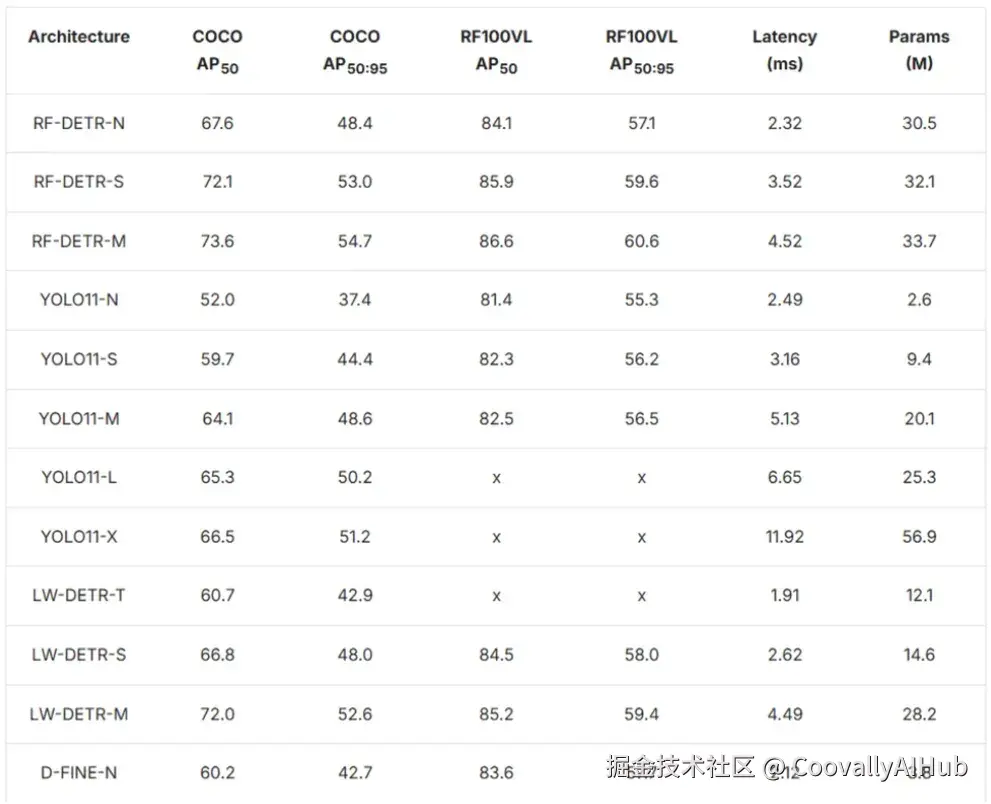
部署优势: 模型体积小巧,可通过Roboflow Inference在边缘设备运行,非常适合需要高精度和实时性能且无云依赖的场景。
- YOLOv12:注意力机制的完美融合
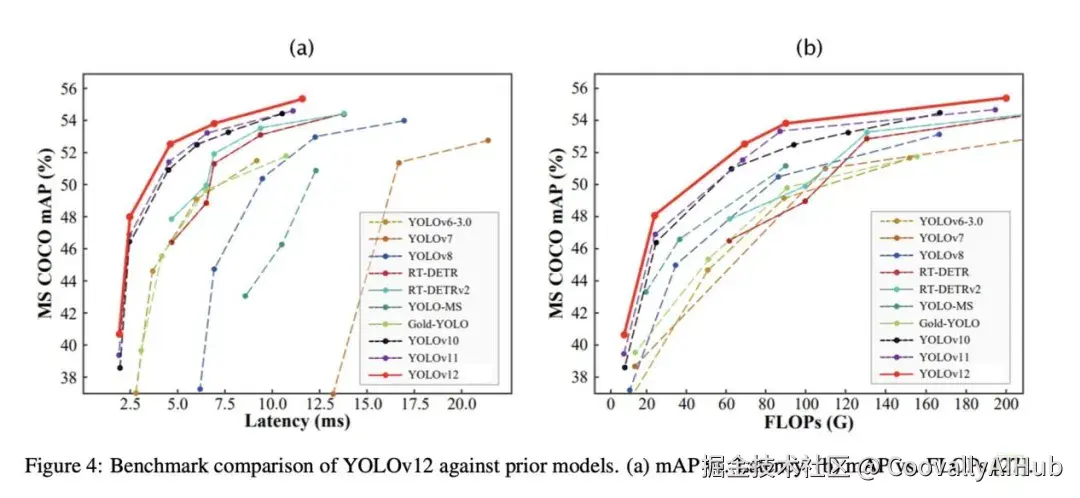
YOLOv12于2025年2月发布,通过引入以注意力为中心的架构,成为YOLO系列的重要进化。它在保持YOLO传统实时速度的同时,集成了高效的注意力机制来捕获全局上下文。
创新亮点:
- 区域注意力模块(A²):通过划分特征图优化注意力计算效率
- 残差高效层聚合网络(R-ELAN):通过块级残差连接增强训练稳定性
- FlashAttention集成:减少内存瓶颈,提升推理效率
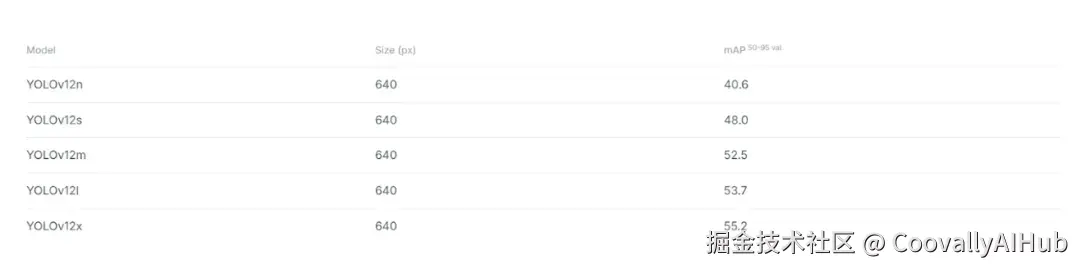
性能阶梯:
- YOLOv12-N: 40.6% mAP,延迟1.64ms
- YOLOv12-M: 52.5% mAP,延迟4.86ms
- YOLOv12-X: 55.2% mAP,YOLO系列精度新高
虽然YOLOv12-N比YOLOv10-N慢9%,但对于检测质量至关重要的应用,精度提升完全值得这一微小代价。
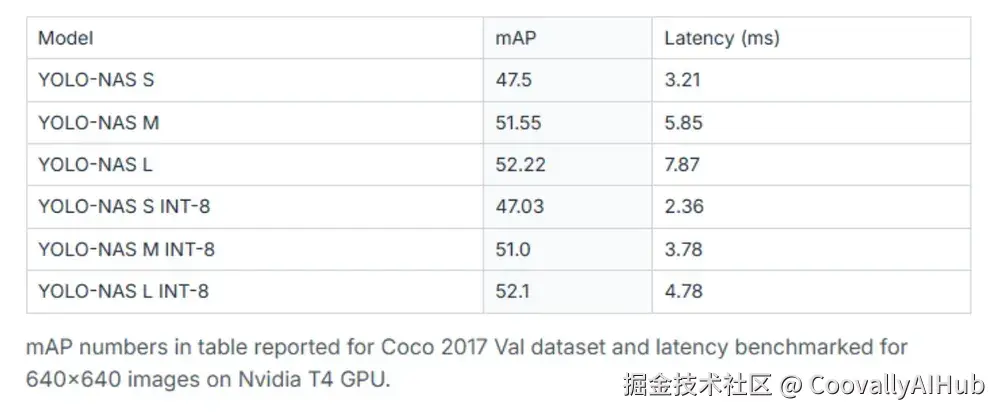
- YOLO-NAS:神经架构搜索的智慧结晶
YOLO-NAS由Deci AI开发,通过神经架构搜索技术在目标检测领域实现突破。该架构在3,800 GPU小时内探索了10^14个潜在架构,最终找到了最优设计。
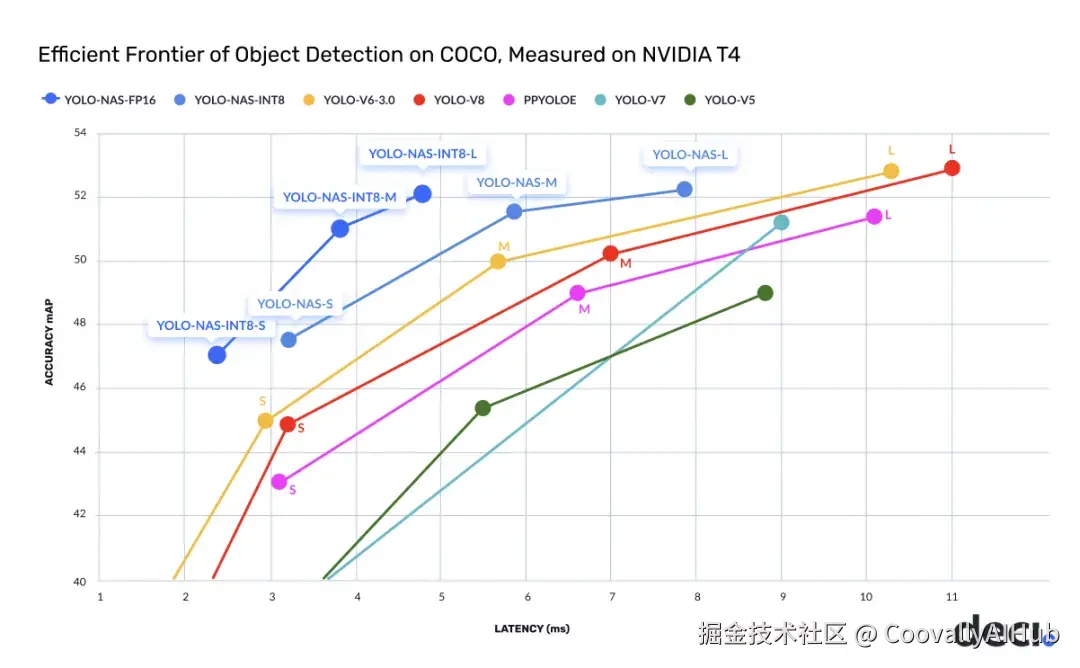
量化友好特性:
YOLO-NAS最大亮点在于其量化友好架构,大多数模型在INT8量化时精度显著下降,而YOLO-NAS专门设计的量化感知块最大限度地减少了精度损失。
训练优势:
结合Objects365预训练、COCO伪标签图像和知识蒸馏技术,有效解决类别不平衡问题,提高对代表性不足类别的检测精度。
性能提升: 相比YOLOv7提升20.5%,比YOLOv5提升11%,比YOLOv8提升1.75%,成为生产部署的理想选择。
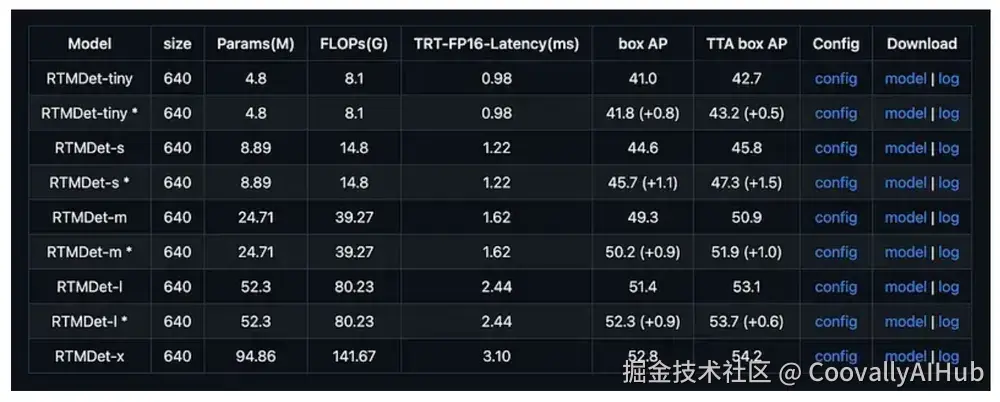
- RTMDet:极速推理的新标杆
RTMDet由OpenMMLab开发,在NVIDIA 3090 GPU上实现了300+ FPS的惊人速度,同时在COCO数据集上保持52.8% AP,为高通量检测场景设立新标准。
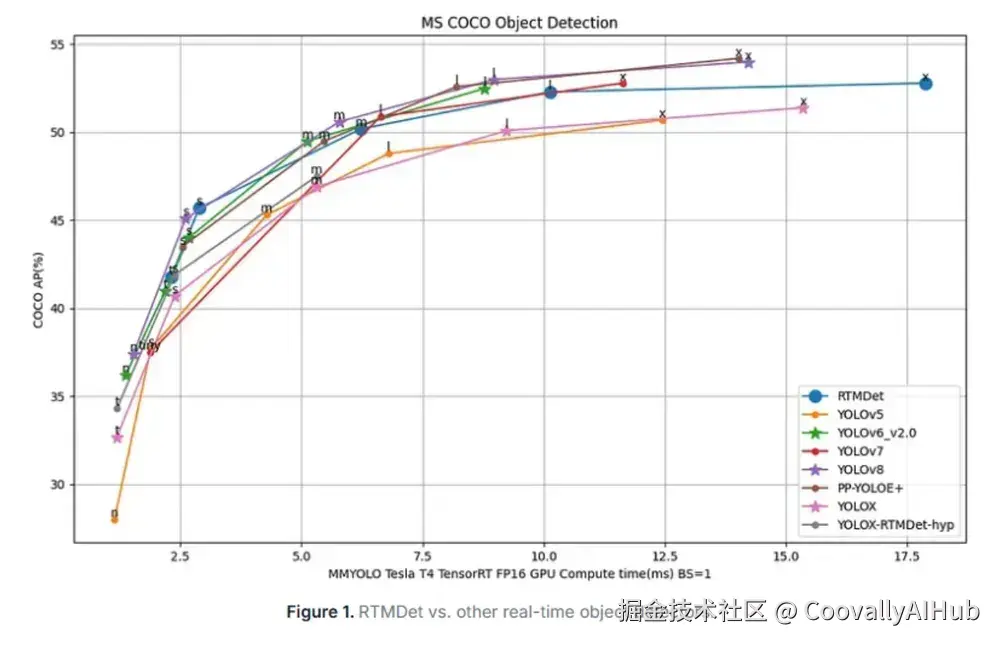
速度秘籍:
- 为并行处理优化的轻量级骨干网络
- 动态标签分配提高训练效率
- 共享卷积层减少计算开销
- 利用GPU并行性的优化推理流程
型号全覆盖:
从RTMDet-Tiny(1020+ FPS,40.5% AP) RTMDet-Extra-Large(52.8% AP),满足不同场景需求,即使大型变体也保持200+ FPS帧率。
应用场景:高速视频处理、快速移动目标实时跟踪、制造业质量控制、自主机器人等需要最大吞吐量的场景。
- YOLO-World:零样本检测的游戏规则改变者
YOLO-World由腾讯AI实验室推出,代表了目标检测的根本性变革------通过开放词汇能力,无需重新训练即可检测新类别目标。
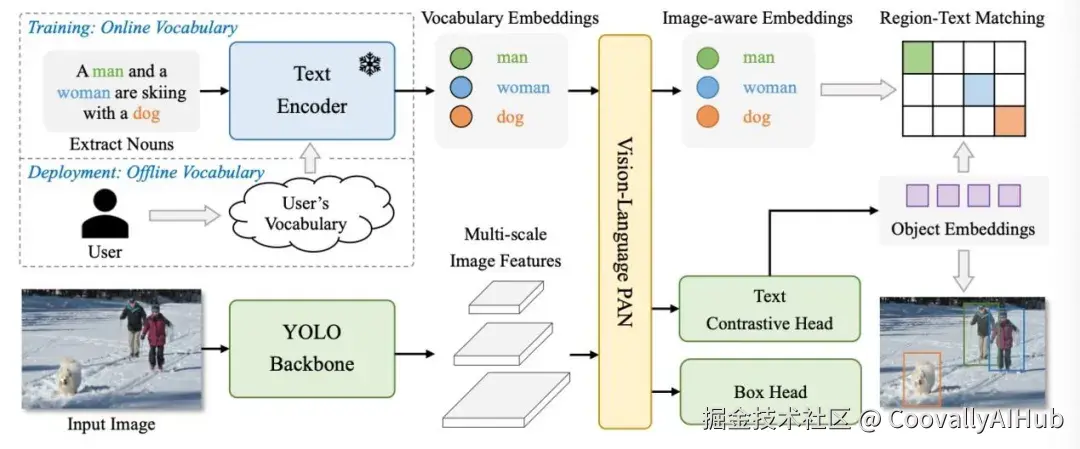
技术突破:
- 基于YOLOv8骨干网络,集成RepVL-PAN和区域-文本对比学习
- 保持CNN架构速度优势,实现Transformer模型的零样本能力
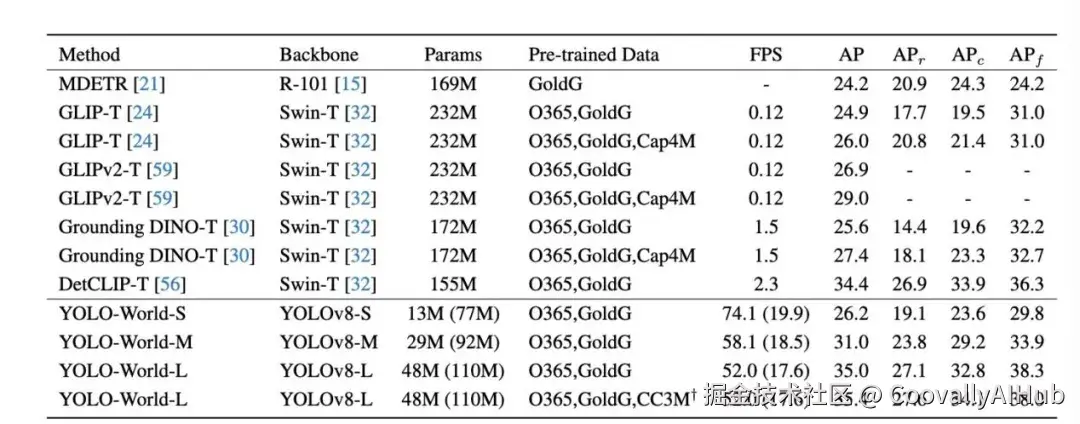
- 在LVIS数据集上实现35.4 AP,速度比竞争零样本检测器快约20倍
核心价值: 彻底改变传统检测流程,只需文本描述即可检测训练期间从未见过的目标,极大降低了自定义检测应用的门槛。
实战指南:如何选择最适合的模型?
- 精度优先场景: RF-DETR是当前精度最高的实时检测器,特别适合处理遮挡、复杂场景和领域转移,在精度关键应用中表现卓越。
- 速度敏感场景: RTMDet提供无与伦比的推理速度,适合视频监控、高速质检等需要处理大量视频流的场景。
- 灵活检测需求: YOLO-World和GroundingDINO为零样本检测提供强大支持,适合类别频繁变化或缺乏标注数据的场景。
- 边缘部署场景: YOLO-NAS的量化友好特性使其在边缘设备上表现优异,平衡速度与精度。
- 平衡型选择: YOLOv12在YOLO系列的易用性与先进注意力机制间取得良好平衡,适合大多数常规应用。
未来展望
2025年的目标检测领域呈现出多元化发展态势。Transformer-based模型如RF-DETR在精度和领域适应性上表现卓越;YOLO系列通过集成注意力机制保持其竞争力;零样本检测技术正逐渐成熟,有望彻底改变传统检测流程。
随着Roboflow Inference、Ultralytics等部署框架的不断完善,从研究到生产的过渡变得更加便捷。无论你的应用场景是自动驾驶、工业检测还是智能安防,总有一款模型能够满足特定需求。
在选择模型时,建议结合实际应用场景、硬件限制和精度要求进行全面评估,必要时进行基准测试,确保选择最适合的解决方案。