软考论文系列
【摘要】
2020年6月,我所在集团为加速数字化转型进程,应对传统IT基础设施的诸多挑战,决定启动"新一代私有云数据中心"的建设项目。本人在该项目中荣幸地担任系统架构师,全面负责新数据中心的技术路线选型、整体架构设计以及关键技术方案的制定与落地。传统"计算、存储、网络"三层式架构存在资源竖井、管理复杂、扩展困难及总体拥有成本高昂等问题,已成为制约业务敏捷发展的瓶颈。本文将结合该项目实践,深入论述我们如何运用超融合架构(Hyper-Converged Infrastructure)进行新一代数据中心的设计与应用。在架构设计阶段,我们系统性地分析了超融合架构的核心原理,对比了其与传统及融合架构的优劣,并基于业务负载特性设计了计算、存储、网络及管理等多个层面的具体方案。在实施过程中,我们通过精细化的存储策略定义、高可用的网络拓扑规划和自动化的运维体系建设,成功构建了一个高效、弹性、易于管理的私有云平台。项目上线后,资源交付效率提升了近90%,运维成本降低了约40%。实践证明,超融合架构是构建现代化、软件定义数据中心的理想基石,能够有效提升企业IT支撑能力。
【正文】
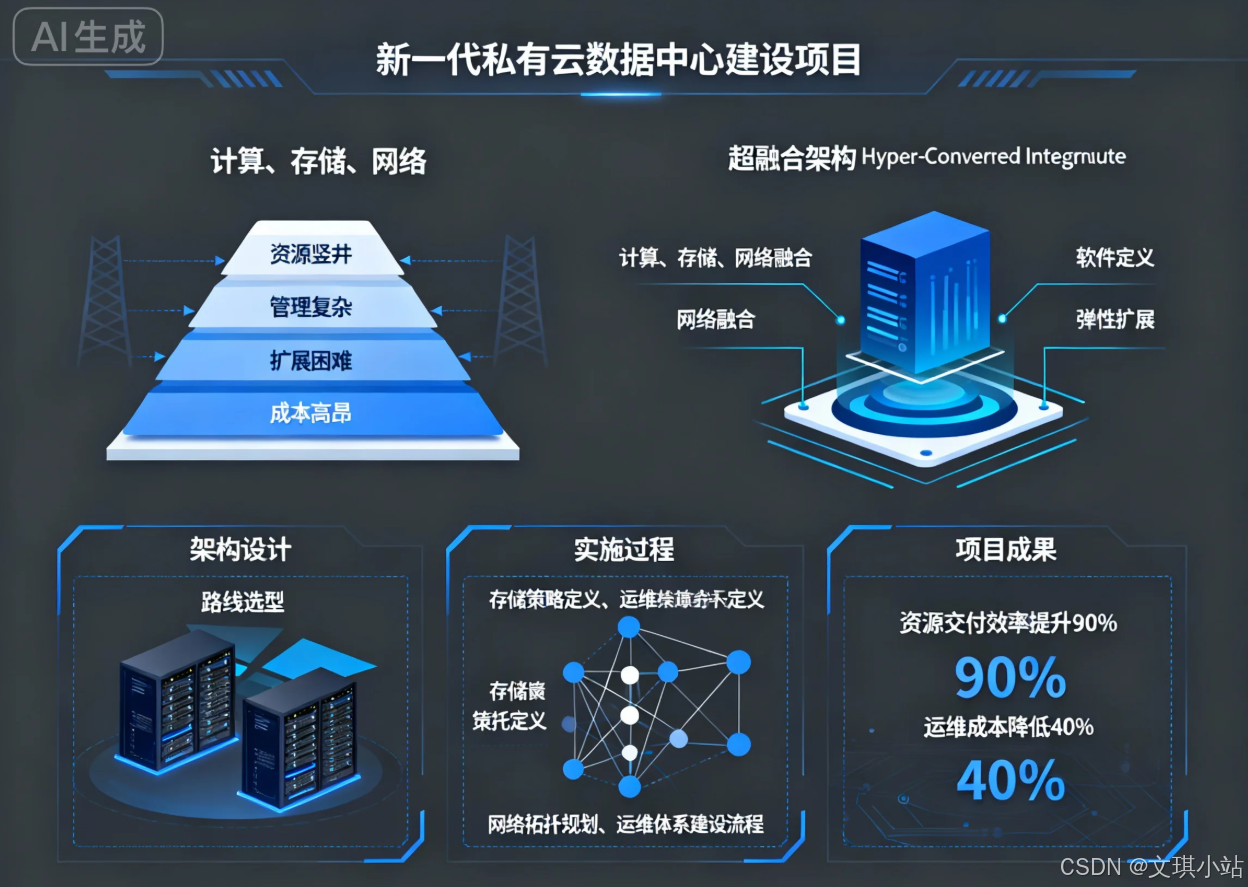
进入信息时代,数字化转型已不再是企业的选择题,而是关乎生存与发展的必答题。企业IT部门的角色也从传统的成本中心,逐步转变为驱动业务创新与增长的价值中心。然而,许多企业仍受困于传统的IT基础设施架构,其以服务器、专用存储阵列(SAN/NAS)和网络设备为核心的三层式物理架构,虽然在过去相当长的时间里支撑了企业的核心业务,但其固有的"竖井式"建设模式、异构设备带来的管理复杂性、以及"烟囱式"扩展带来的高昂成本和性能瓶颈,使其在应对云计算、大数据、人工智能等新兴业务需求时显得力不从心。在这种背景下,我所在的大型制造集团为支撑其智能制造、供应链协同和大数据分析等战略方向,迫切需要构建一个更具敏捷性、弹性和成本效益的新一代IT基础设施平台。
2020年6月,集团正式立项"新一代私有云数据中心"项目,我被任命为该项目的系统架构师,肩负着从零开始规划和设计整个平台技术体系的重任。项目初期,我带领团队对现有数据中心的痛点进行了全面的梳理与剖析。首要问题是资源交付的效率低下,一个新业务系统的上线,需要经历计算、存储、网络等多个部门的协同审批与手动配置,周期往往长达数周,严重拖慢了业务的上线速度。其次是运维管理的复杂性,不同品牌的服务器、存储、交换机拥有各自独立的管理界面和技术栈,运维团队需要掌握多种技能,故障排查与性能优化难度极大,导致运营成本(OpEx)居高不下。再者,系统的扩展性不佳,存储容量的垂直扩展成本高昂且存在性能天花板,而计算资源的横向扩展又常常受限于存储的性能瓶ISU,无法实现资源的线性、均衡增长。面对这些积弊,我们明确了新一代数据中心的架构设计目标:简化管理、弹性伸缩、提高资源利用率并降低总体拥有成本(TCO)。
为了达成这些目标,我们对业界主流的基础设施架构演进路线进行了深入的考察与评估。融合架构(Converged Infrastructure)通过将计算、存储、网络设备进行预集成和预验证,在一定程度上简化了部署,但其本质上仍是分离组件的物理集成,并未从根本上解决管理孤岛和软件定义能力不足的问题。而超融合架构(Hyper-Converged Infrastructure, HCI)则代表了更为彻底的变革。它以软件定义为核心,在标准化的x86服务器硬件之上,通过虚拟化技术将计算(CPU/内存)和存储(本地磁盘)资源池化,并以分布式软件的形式提供企业级的存储服务,所有功能均通过统一的软件平台进行管理。这种架构将数据中心的核心能力从专用硬件中解耦出来,实现了计算与存储在同一物理节点上的深度融合。其核心架构特征包括:软件定义一切,通过软件定义存储(SDS)和软件定义网络(SDN)实现资源的灵活调度与自动化管理;分布式架构,所有节点共同组成一个无共享的集群,数据和负载被分散到所有节点,天然具备高可用性和无单点故障的能力;基于商用硬件,摆脱了对昂贵专用存储设备的依赖,显著降低了初始投入(CapEx);以及积木式的横向扩展能力,通过简单地增加节点即可同步、线性地扩展计算和存储资源,实现了性能和容量的可预测增长。经过审慎的论证和多款产品的POC测试,我们认为超融合架构高度契合我们项目的设计目标,并最终选定了基于VMware vSAN的解决方案,主要考虑到其与我们现有成熟的vSphere虚拟化技术栈能够无缝集成,可最大程度地保护现有投资并降低团队的学习曲线。
在确定了技术路线后,我便着手进行详细的系统架构设计。这不仅是选择一个产品,更是要构建一套完整、可靠、高效的运行体系。我的设计工作主要围绕以下几个维度展开。在物理与逻辑架构层面,我们规划了"管理集群"与"业务集群"分离的部署模式。管理集群规模较小,专门用于运行vCenter Server、vRealize Operations等核心管理组件,确保管理平面的稳定与安全。业务集群则根据应用的重要性划分为"生产环境集群"和"开发测试集群",实现了资源的物理隔离和差异化的服务等级保障。在计算资源设计上,我们基于对现有业务负载的性能基线分析,标准化了计算节点的硬件配置,并利用vSphere DRS(分布式资源调度)和HA(高可用)功能,实现了虚拟机的自动化负载均衡与故障自愈,确保了计算层的高可用性与资源利用效率。
存储架构的设计是超融合架构的核心与难点。作为架构师,我设计的关键在于如何利用vSAN的软件定义能力,为不同业务提供差异化的存储服务。我们采用了全闪存的节点配置以满足生产业务对高性能的需求,并通过精细化的"存储策略"(Storage Policy Based Management, SPBM)进行资源调配。例如,对于核心数据库等关键应用,我制定了"FTT=1, RAID-1(Mirroring)"的策略,即允许一个节点故障,数据采用镜像方式存放两份,以保障最高的数据冗余度和读写性能。对于文件服务器等容量需求大但性能要求次之的应用,则采用"FTT=1, RAID-5(Erasure Coding)"的策略,通过纠删码技术在保证数据冗余的同时,极大地节省了存储空间。这种基于策略的自动化管理,使得存储资源的分配从繁琐的LUN划分和Masking操作,转变为简单的策略选择,极大地提升了敏捷性。在网络架构设计上,为支撑vSAN节点间大量的数据同步、vMotion以及业务流量,我们采用了25GbE的Leaf-Spine(叶脊)网络拓扑,为东西向流量提供了高带宽、低延迟的无阻塞通道。每个HCI节点配置四块物理网卡,通过vSphere Distributed Switch进行绑定和流量整形,将管理、vMotion、vSAN和业务流量通过不同的VLAN和虚拟网卡进行隔离,确保了各类流量互不干扰,并实现了网络层面的高可用。
项目最终历时八个月完成了部署、数据迁移和上线割接。新一代私有云平台的建成,为集团的IT能力带来了革命性的提升。从最终的运行效果来看,我们完全达成了预设的架构目标。首先,资源交付实现了自动化,通过与云管平台的集成,业务部门申请虚拟机资源从过去以周为单位的流程,缩短至十几分钟内即可自助完成。其次,运维效率大幅提高,统一的vCenter管理界面纳管了计算、存储、网络(部分通过NSX)资源,运维团队从过去"救火队"的角色,转变为平台的运营者,工作重心更多地放在了性能优化与容量规划上。据统计,整体运维人力投入减少了约40%。最后,总体拥有成本显著降低,基于标准x86服务器的模式不仅降低了初期的硬件采购成本,其简化的运维和更优的电能、空间效率也持续降低了运营成本。当然,在实施过程中我们也遇到了挑战,例如网络配置的细节对vSAN性能影响巨大,需要网络和虚拟化团队紧密协作;同时,团队成员也需要从传统的"专才"向具备计算、存储、网络综合知识的"通才"转变。作为架构师,我不仅设计了技术蓝图,也通过组织培训和制定标准操作流程,推动了团队的技能转型。
总结本次项目经验,我认为超融合架构的成功应用,关键在于从系统工程的视角进行全局设计。它不仅仅是技术的堆叠,更是对传统IT组织架构、运维流程和技术理念的一次重塑。作为系统架构师,必须超越单一产品的特性,深入理解其背后的分布式系统原理,并将其与企业的业务需求、运维能力和发展战略相结合,才能设计出真正行之有效的解决方案。展望未来,我们计划在此私有云平台的基础上,进一步集成容器技术(如vSphere with Tanzu),构建云原生应用平台,并探索与公有云的混合连接,打造一个统一、开放、智能的混合云架构,为集团的持续创新提供更加强大的数字引擎。
更多文章,请移步WX,搜索同名:文琪小站