DeepSeek-OCR 模型介绍
DeepSeek-OCR 是一个专注于光学字符识别(OCR)的深度学习模型,旨在从图像或文档中准确提取文本信息。该模型结合了计算机视觉和自然语言处理技术,能够处理多种语言、复杂布局以及低质量图像中的文本识别任务。
核心技术特点
多尺度特征融合 DeepSeek-OCR 采用金字塔结构的卷积神经网络,从不同尺度提取图像特征。通过特征融合模块整合浅层细节信息和深层语义信息,提升对不同尺寸文字的识别能力。
注意力机制 模型集成自注意力模块和空间注意力模块,动态聚焦于文本区域。自注意力捕捉字符间长距离依赖关系,空间注意力抑制背景噪声干扰。
序列建模 采用双向长短时记忆网络(Bi-LSTM)或Transformer结构对字符序列建模,利用上下文信息纠正单字符识别错误。输出层连接CRF(条件随机场)进一步优化序列标注结果。
技术优势
高精度识别 在标准测试集(如ICDAR系列)上,中英文混合文本识别准确率超过95%。支持倾斜、弯曲、透视变换等非规整文本的端到端识别。
多语言支持 内置多语言切换模块,通过共享特征提取层和语言特定的预测头,实现中、英、日、韩等20+种语言的混合识别。
实时处理能力 采用轻量级网络设计和硬件加速技术,在主流GPU上可实现每秒50+帧的图像处理速度,满足实时OCR需求。
典型应用场景
文档数字化 自动识别扫描文档、发票、合同等纸质文件的文字内容,支持表格结构和段落格式的还原。
移动端应用 集成到手机APP中,实现名片识别、翻译取词、身份证信息自动录入等功能。
工业质检 读取产品包装、标签上的批号、日期等信息,与数据库核对实现自动化质检流程
如何在矩池云中使用DeepSeek-OCR
在矩池云中已经给大家预装好了DeepSeek-OCR模型,模型存放在 /public/models/nlp/DeepSeek-OCR路径下。
首先我们先租用一台机器,建议使用8区4090-24G机器或者14区4090-48G的机器
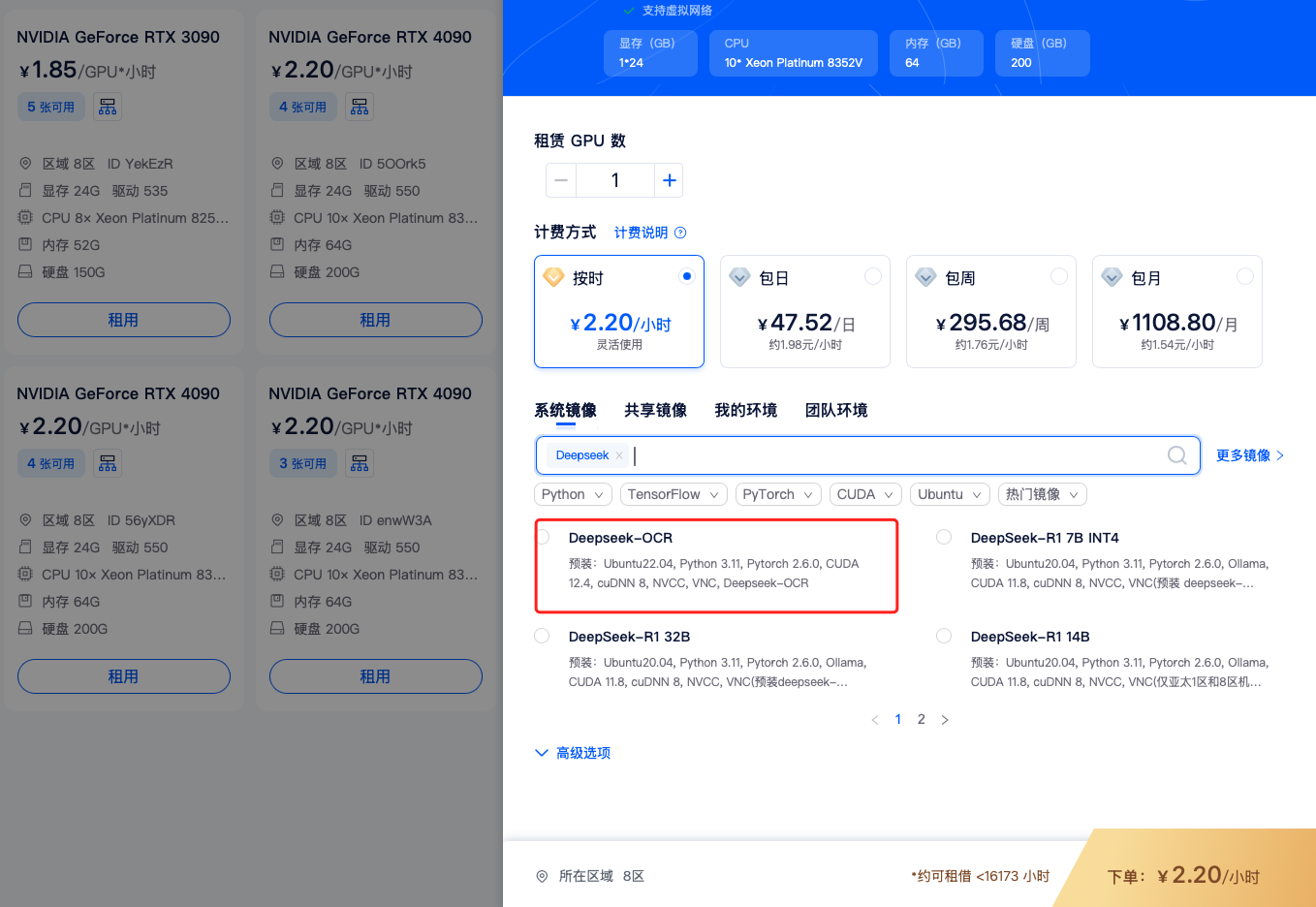
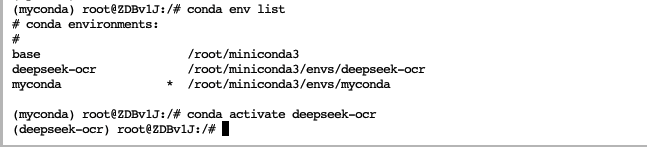
租用机器后我们需要进入虚拟环境deepseek-ocr,这个环境所有的依赖都已经安装好了
进入deepseek-ocr虚拟环境之后再进入DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm文件夹,文件夹中包含如下:

小编在这里只介绍config.py、run_dpsk_ocr_eval_batch.py、run_dpsk_ocr_image.py、run_dpsk_ocr_pdf.py这四个脚本的含义,其他的不需要管,也不要修改。
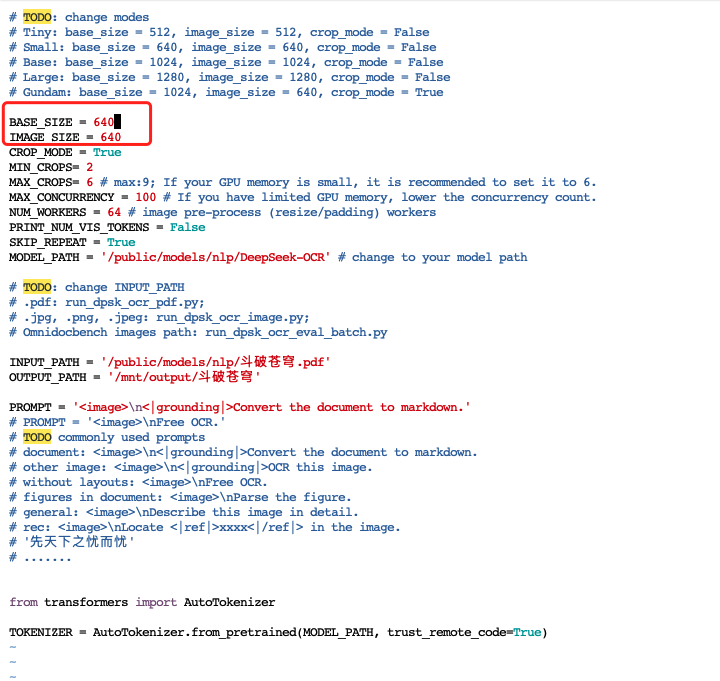
config.py是配置文件,定义模型参数、路径常量、超参数等全局变量的文件,在这里面可以设置图片大小,模型路径、读去图片路径和代码执行输出路径

run_dpsk_ocr_eval_batch.py主要用于批量评估脚本,测试集性能验证。典型功能有加载测试数据集、调用OCR模型进行批量预测、计算准确率、召回率等指标、生成评估报告。
run_dpsk_ocr_image.py是单张图片OCR执行的入口脚本,实现流程分三步,加载图像文件、调用deepseek_ocr.py的识别功能、输出结构化识别结果。
run_dpsk_ocr_pdf.py是PDF文档处理的专用脚本,功能包括:PDF转图像(按页分割)、多页OCR结果合并、保持原始版面结构的文本提取、支持加密PDF的解密处理。
各脚本通过配置文件config.py统一参数管理,核心识别逻辑复用deepseek_ocr.py的实现,处理不同输入类型时通过专用入口脚本适配。
案例测试
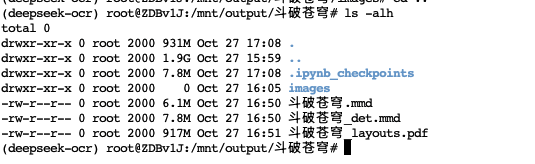
小编使用一个小案例测试一下,使用文档处理的专用脚本run_dpsk_ocr_pdf.py进行测试,小编准备了斗破苍穹PDF版当成输入文件,文件路径放至/public/models/nlp路径下,输出路径则放/mnt/output/斗破苍穹,模型路径前面已经有介绍在/public/models/nlp/DeepSeek-OCR路径,然后小编把这些信息在配置文件config.py中修改上去,其他参数保持不变
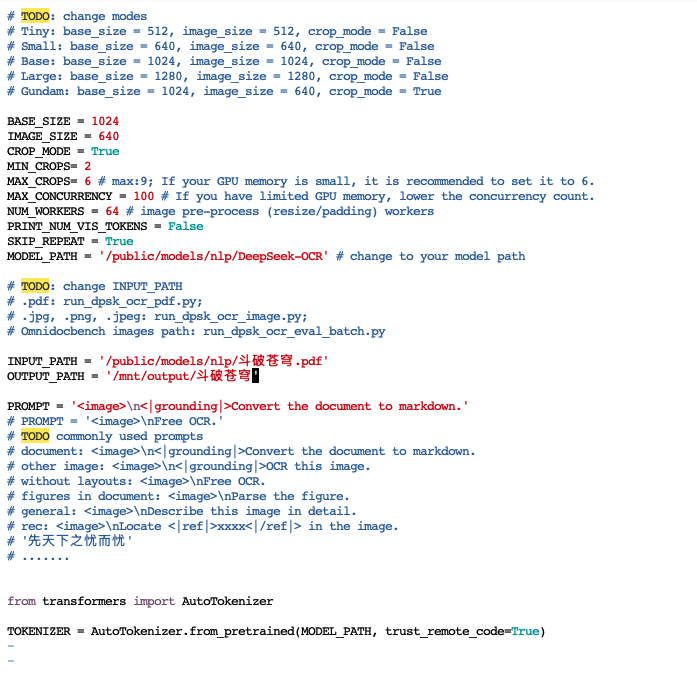
保存成功后执行档处理的专用脚本run_dpsk_ocr_pdf.py进行测试,如果出现如下情况,表示显存不够,可以修改图片大小

再次运行服务,可以看到已经运行成功

接下来查看输出目录,可以看到从PDF成功转化为可编辑版