一、背景
在深度学习推理任务中,图像输入需要与模型训练时的数值范围保持一致。
而使用 OpenCV 读取图像时,像素默认是 uint8 类型,取值范围 [0, 255]。
然而,模型往往要求输入为:
- [0, 1](归一化)或 [-1, 1](标准化后输入)
若预处理方式不合理,就会带来额外的内存读写、临时矩阵创建甚至性能瓶颈。
在一次算法优化的任务中,我需要将整个推理项目的速度尽可能优化到极致(前处理,推理,后处理),将自己对于其中图像归一化 的迭代优化思考的过程记录下来,温故而知新。
二、图像归一化改进:从两步法到一次到位
下面展示三种实现方式的演变,从最常见的旧写法,到错误的"优化",再到最终高效版本。
第一代:传统两步法(正确但低效)
cpp
cv::Mat f32;
rgb.convertTo(f32, CV_32F, 1.f / 255.f);
f32 = f32 * 2.f - 1.f;逻辑:
- 先把像素范围 通过除法
[0,255] → [0,1],再通过乘法和减法共三次 计算线性变换为[-1,1]。
数学表达:
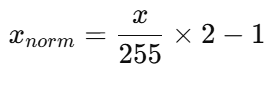
问题:
-
两次完整图像遍历;
-
每次遍历触发一次内存读写;
-
对大图或多分块(图像分块推理)场景,性能损耗显著。
第二代:自认为"优化"的错误写法
cpp
cv::Mat f32;
rgb.convertTo(f32, CV_32F);
f32 = (f32 - 127.5f) / 127.5f;初衷:
想把利用减法 和除法两次计算压缩成一行,结果反而更慢。
原因:
-
(f32 - 127.5f)创建一个新的临时矩阵; -
/ 127.5f再创建第二个临时矩阵; -
共两次全图遍历,且无法使用 OpenCV 内部 SIMD 加速。
⚠️ 注意:
在 Python (NumPy) 中这是广播操作,一次遍历;
但在 C++/OpenCV 中,每个算术运算都会生成新矩阵。
第三代:最终版 ------ 一次到位的高效归一化
cpp
cv::Mat f32;
rgb.convertTo(f32, CV_32F, 1.0 / 127.5, -1.0); // f32 = rgb * (1/127.5) + (-1)原理:
convertTo() 内部支持同时执行线性变换:
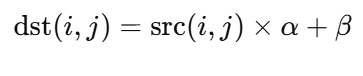
代入参数:
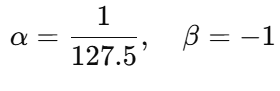
即:
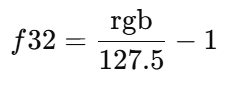
优势:
-
一次遍历完成;
-
内部启用 SIMD + 多线程优化;
-
无临时矩阵,无额外内存拷贝;
三、性能测试验证
测试程序如下:
cpp
#include <opencv2/opencv.hpp>
#include <chrono>
#include <iostream>
using namespace std;
int main() {
cv::Mat rgb = cv::imread("test.jpg");
int N = 50;
auto run = [&](auto func, const string& name) {
auto t0 = chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) func();
auto t1 = chrono::high_resolution_clock::now();
double ms = chrono::duration<double, milli>(t1 - t0).count();
cout << name << ": " << ms / N << " ms" << endl;
};
run([&] {
cv::Mat f32;
rgb.convertTo(f32, CV_32F, 1.f / 255.f);
f32 = f32 * 2.f - 1.f;
}, "第一代:两步法");
run([&] {
cv::Mat f32;
rgb.convertTo(f32, CV_32F);
f32 = (f32 - 127.5f) / 127.5f;
}, "第二代:错误优化");
run([&] {
cv::Mat f32;
rgb.convertTo(f32, CV_32F, 1.0 / 127.5, -1.0);
}, "第三代:一次到位");
return 0;
}测试环境:
-
Intel i7-12700H
-
OpenCV 4.8
-
输入图像:3840×2160 (4K)
测试结果
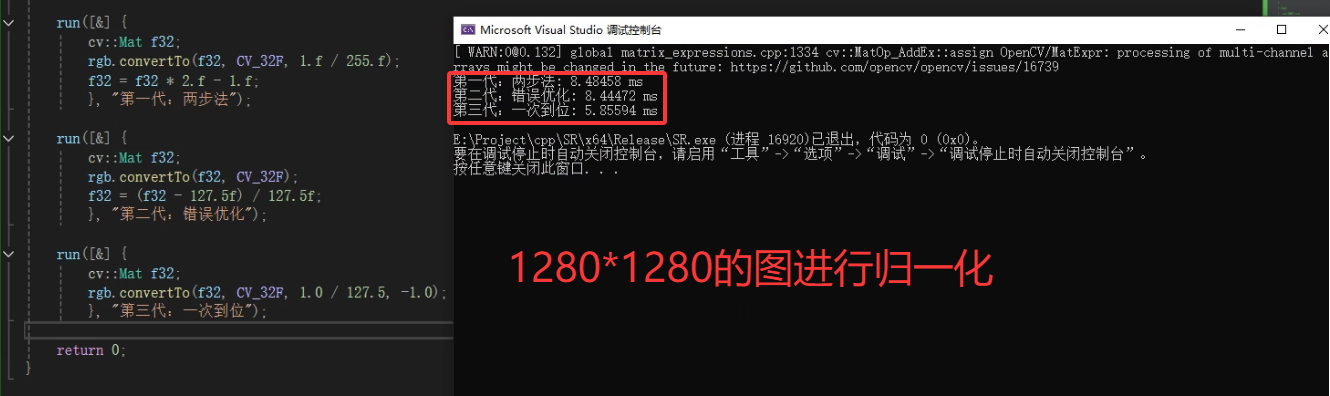
重复运行过很多次,确实是第三种优化方式更快。
四、总结
| 写法 | 遍历次数 | SIMD 优化 | 是否创建临时矩阵 | 性能 |
|---|---|---|---|---|
/255 + *2-1 |
2 | ✅ | 否 | 中等 |
(x - 127.5)/127.5 |
2 | ❌ | 是 | 中等 |
convertTo(..., 1/127.5, -1) |
1 | ✅ | 否 | 最优 🔥 |
✅ 结论:
建议使用
rgb.convertTo(f32, CV_32F, 1.0 / 127.5, -1.0);一步完成归一化。
对大图、超分辨率切片推理等场景,能显著节省 CPU 资源。