本文档参考DeepSeek-OCR LLM部分(DeepSeek-3B-MoE)前向推理流程解读。
网络结构高清大图,请在点击下载获取。
1. 采用64个专家模块(mlp),每个token推理激活6个专家模块。
2. prefill产生首token运行时流程
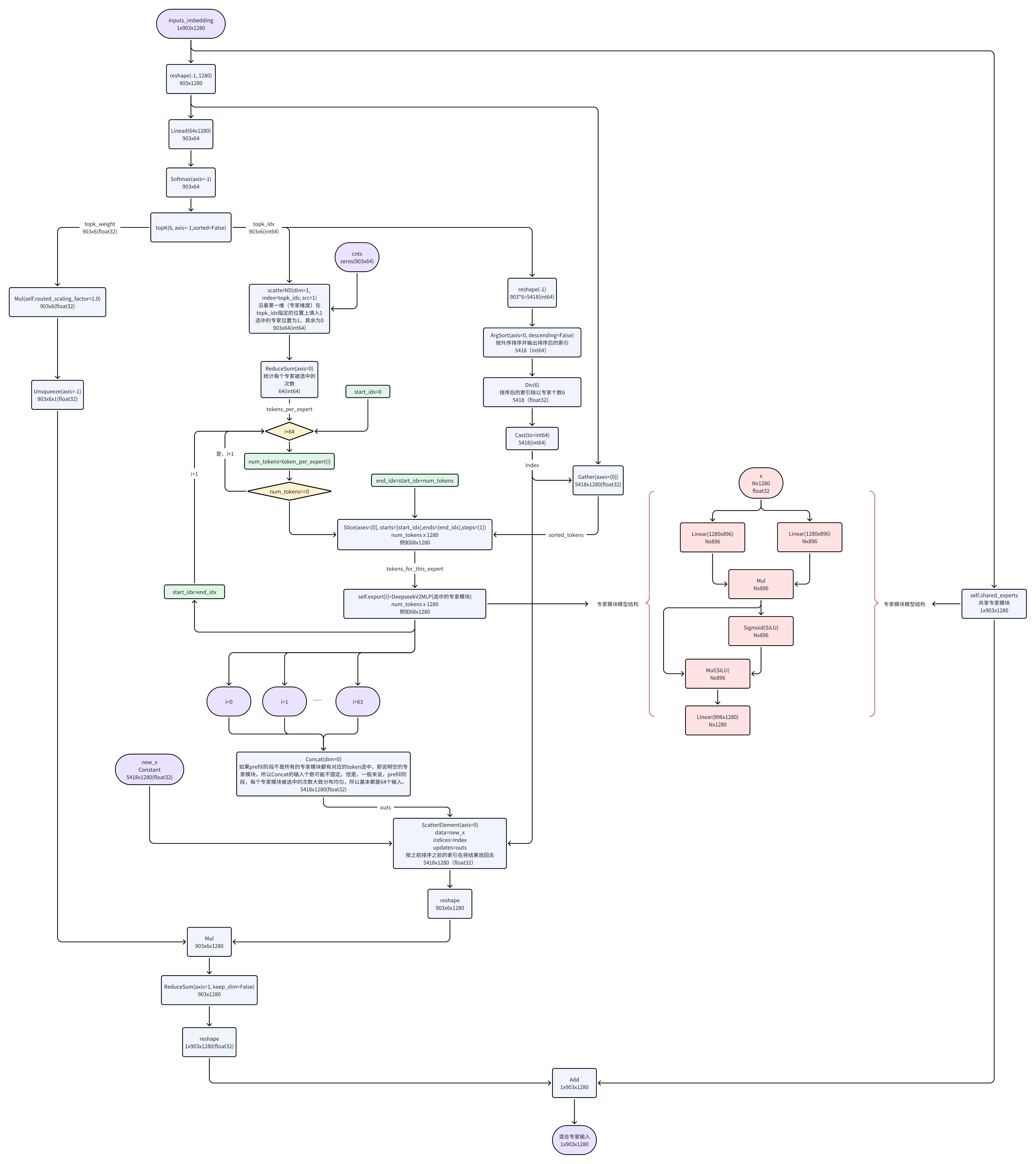
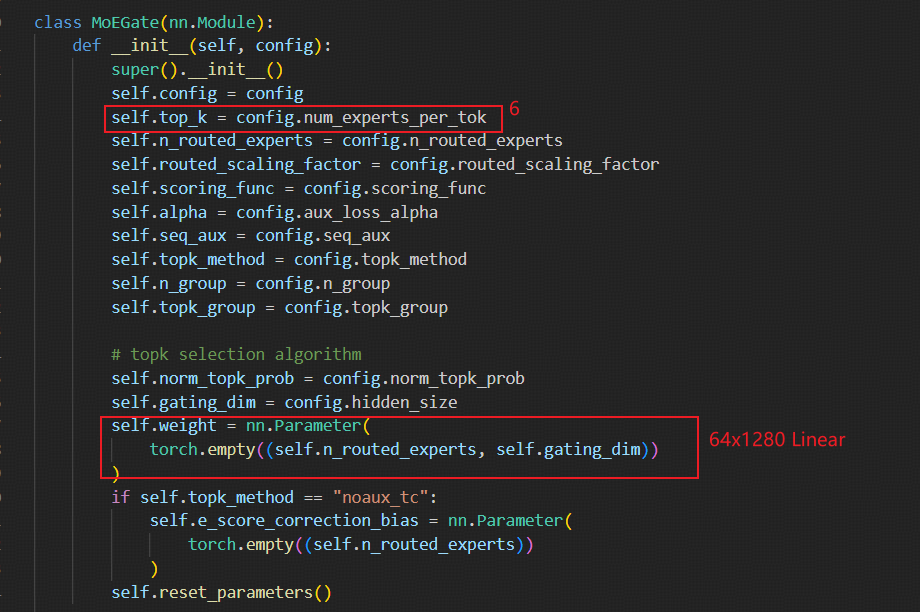
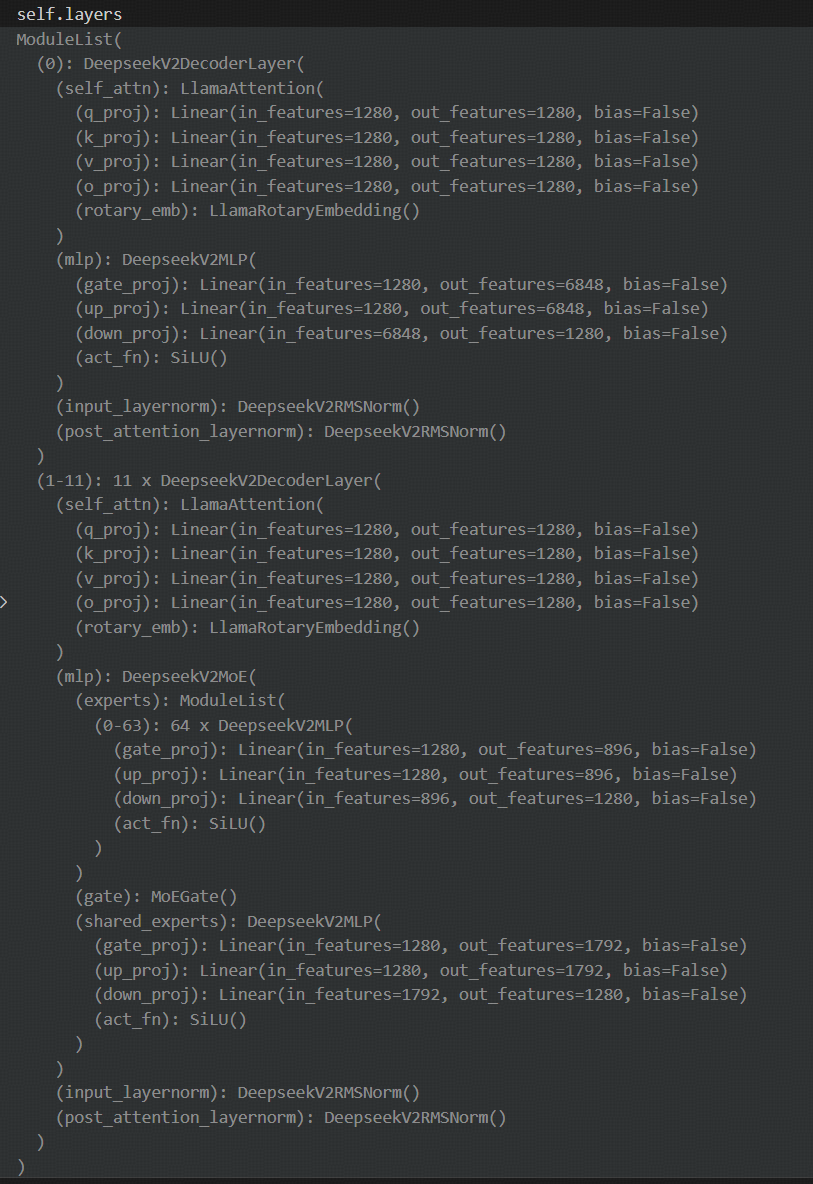
从流程图中可以明显看出,混合专家模块其实主要针对每个block的transformer模块中的计算量最大的Feed Forward(前馈网络,实际就是全连接+act)做选择,64个混合专家在903个输入token中每个token都被选择6个,即计算903x6次专家计算(Feed Forward),但如果是稠密模型则需要做903x64次FeedForward,计算量巨大。同时,在DeepSeek-3B-MoE中存在一个共享专家(Feed Forward)用于均衡信息。共享专家模块的全连接层维度更大,可以参考下面的ModuleList块,存在1280x6848的权重。而每个混合专家只有1280x896的权重,但64个混合专家权重会更多,所以混合专家模块MoE的主要目的是以空间换时间,更大内存的占用换取推理时更快的速度。
在DeepSeek-OCR中的3B-MoE模型的block为11(从1~11,第0个block为稠密模型),即11次稠密模型与11次混合专家带来的计算量的减少是巨大的。当然在其它模型算法中(比如Qwen 30B A3B模型中采用了128个专家模块,每次激活8个专家模块)。
另外,在prefill阶段,因为一般输入token数量大部分会大于64(本例中为903),所以基本上每个专家模块都会被不同的token所选中,所以大部分混合专家都会被激活。但是也不排除有特例,在prefill阶段存在没有被任何token选中的,那此时concat的输入个数就不固定了,但输出维度是一定的。
3. decode阶段解码时的MoE混合专家模块流程。
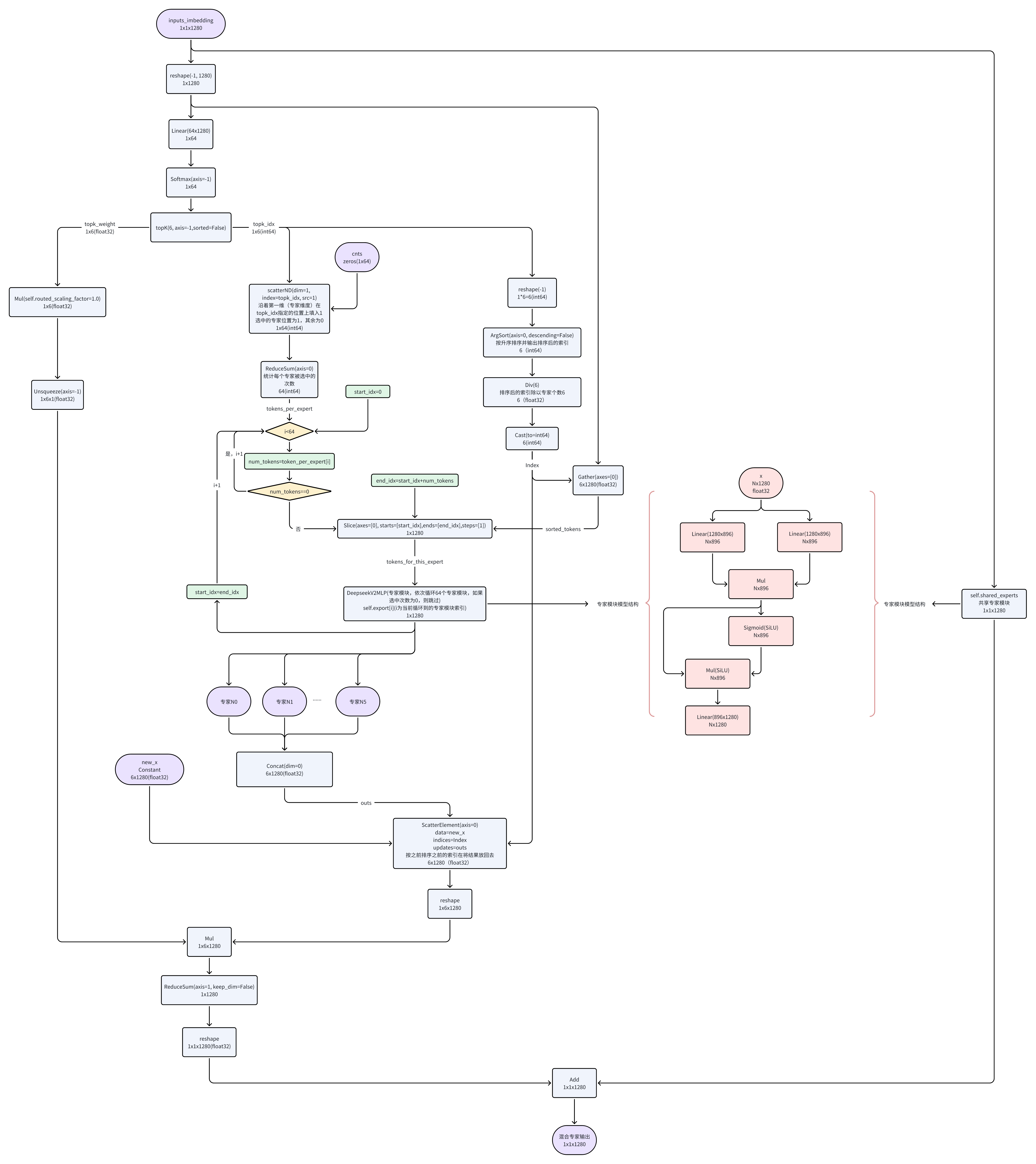
与prefill阶段类似,只不过prefill阶段903个token,在decode阶段每次只有一个token输入,即1x1x1280。另外,由于decode阶段每次输入一个token,所以混合专家每次只有6个被选中激活,即concat的输入个数固定为6个。