本文将进一步丰富智能问答系统的功能,接下来的案例中,我们构建一个基于 Streamlit + LangChain + DeepSeek 的智能化数据分析助手,融合两个典型的企业级大模型应用场景:
- PDF 智能问答:支持上传多个 PDF 文档,自动完成内容提取、文本切块、语义向量化,并构建 FAISS 本地检索库,结合大模型进行问答;
- CSV 数据智能分析:通过自然语言指令分析结构化数据,包括统计查询、代码生成与图表绘制;
1、 模块导入与全局设置
python
import streamlit as st
import pandas as pd
import os
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.chat_models import init_chat_model
from langchain_experimental.tools import PythonAstREPLTool
import matplotlib
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
matplotlib.use('Agg')
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
openai_api_key = os.getenv("OPENAI_API_KEY")
openai_api_base = os.getenv("CHAT_API_URL")
# 设置环境变量
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"2、初始化 Embedding、LLM 与 Session
python
# 初始化embeddings
@st.cache_resource
def init_embeddings():
from langchain.embeddings import init_embeddings
return init_embeddings("openai:text-embedding-3-small", openai_api_key=openai_api_key, openai_api_base=openai_api_base) # 可换本地/其他厂商
# 初始化LLM
@st.cache_resource
def init_llm():
return init_chat_model("deepseek-chat", model_provider="deepseek")
# 初始化会话状态
def init_session_state():
if 'pdf_messages' not in st.session_state:
st.session_state.pdf_messages = []
if 'csv_messages' not in st.session_state:
st.session_state.csv_messages = []
if 'df' not in st.session_state:
st.session_state.df = None3、PDF 文档处理逻辑
python
# PDF处理函数
def pdf_read(pdf_doc):
text = ""
for pdf in pdf_doc:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
def get_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_text(text)
return chunks
def vector_store(text_chunks):
embeddings = init_embeddings()
vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)
vector_store.save_local("faiss_db")
def check_database_exists():
return os.path.exists("faiss_db") and os.path.exists("faiss_db/index.faiss")4、PDF 智能问答:RAG + Agent
python
def get_pdf_response(user_question):
if not check_database_exists():
return "❌ 请先上传PDF文件并点击'Submit & Process'按钮来处理文档!"
try:
embeddings = init_embeddings()
llm = init_llm()
new_db = FAISS.load_local("faiss_db", embeddings, allow_dangerous_deserialization=True)
retriever = new_db.as_retriever()
prompt = ChatPromptTemplate.from_messages([
("system", """你是AI助手,请根据提供的上下文回答问题,确保提供所有细节,如果答案不在上下文中,请说"答案不在上下文中",不要提供错误的答案"""),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
retrieval_chain = create_retriever_tool(retriever, "pdf_extractor", "This tool is to give answer to queries from the pdf")
agent = create_tool_calling_agent(llm, [retrieval_chain], prompt)
agent_executor = AgentExecutor(agent=agent, tools=[retrieval_chain], verbose=True)
response = agent_executor.invoke({"input": user_question})
return response['output']
except Exception as e:
return f"❌ 处理问题时出错: {str(e)}"5、CSV 数据分析:代码执行工具 + 可视化
python
def get_csv_response(query: str) -> str:
if st.session_state.df is None:
return "请先上传CSV文件"
llm = init_llm()
locals_dict = {'df': st.session_state.df}
tools = [PythonAstREPLTool(locals=locals_dict)]
system = f"""Given a pandas dataframe `df` answer user's query.
Here's the output of `df.head().to_markdown()` for your reference, you have access to full dataframe as `df`:
```
{st.session_state.df.head().to_markdown()}
```
Give final answer as soon as you have enough data, otherwise generate code using `df` and call required tool.
If user asks you to make a graph, save it as `plot.png`, and output GRAPH:<graph title>.
Example:
```
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plt.hist(df['Age'])
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Age Histogram')
plt.savefig('plot.png')
```output: GRAPH:Age histogram
Query:"""
prompt = ChatPromptTemplate.from_messages([
("system", system),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
return agent_executor.invoke({"input": query})['output']6、✅ 总结(核心功能架构)
| 模块 | 技术组件 | 说明 |
|---|---|---|
| PDF 问答 | FAISS + Retriever Tool | 构成 RAG 检索增强流程 |
| CSV 分析 | PythonAstREPLTool + Pandas | 实现代码生成 + 可视化 |
| LLM | DeepSeek Chat | 统一 Agent 调用 |
| 向量库 | DashScope Embedding + FAISS | 支持中文语义匹配 |
| UI | Streamlit + 自定义 CSS | 提供多 Tab 页面与交互式聊天 |
| 状态管理 | st.session_state |
管理历史、数据、图片等上下文 |
PDF相关功能解说见上篇文章,这里主要对数据分析功能进行说明
- Step 1. CSV 文件上传与 DataFrame 显示。用户上传 .csv 文件后由 pandas.read_csv() 加载为 DataFrame,实时预览数据行列、列名、类型等信息。
- Step 2. 构建代码执行工具 Agent。构建系统提示,注入 DataFrame 的 .head() 输出增强语境理解,使用 PythonAstREPLTool 工具允许模型执行基于 df 的代码分析,通过 create_tool_calling_agent 构建分析 Agent,可执行筛选、分组、聚合等 pandas 操作,图表绘制(保存为 plot.png,关键词识别后渲染)。
- Step 3. 图表识别与自动展示。若模型返回内容中包含 "GRAPH:",则自动读取 plot.png 并展示;支持 plt.hist()、plt.bar() 等可视化命令;会话记录中分类保存文本、图像与表格类型内容。
7、运行结果
7.1 PDF问答
python
> Entering new AgentExecutor chain...
Invoking: `pdf_extractor` with `{'query': 'LangChain竞品框架对比'}`
responded: 我来查询一下LangChain竞品框架的对比信息。
显著缩短从Demo到生产的距离。
4.1组件标准化接口:降低集成成本、摆脱厂商锁定
LangChain为"模型---工具---检索---管道"这几类基础构件提供了统一的抽象层,显著
减少在不同厂商接口之间改写代码的工作量。核心在于:
Runnable/LCEL标准化编排:所有链式组件统一实现Runnable接口;在此之上,
LangChainExpressionLanguage(LCEL)用声明式语法把提示词、模型调用、解析
器、检索器等拼装为稳定的"链",并天然支持流式返回、异步与并行,还自动打点
到LangSmith(需要外网,国内不方便),便于调试与回溯。官方也明确给出使
用指引:简单编排用LCEL,涉及分支、循环、多智能体与显式状态时转用
LangGraph。
ToolCalling统一接口:不同模型厂商(OpenAI/Anthropic/Gemini等)对工具调
用的返回结构各不相同。LangChain将其**标准化为ChatModel.bind_tools()+
AIMessage.tool_calls**,开发者只需用@tool装饰器定义函数及其模式
(schema),再绑定到支持工具调用的模型即可跨厂商复用。这样避免了早期需要针
对各家API拆additional_kwargs的脆弱写法。
检索/向量库/文档加载的统一协议:LangChain为Retriever抽象出统一接口;向量
库可一键转为检索器(.as_retriever()),既能对接Faiss、Pinecone等向量库,
也能接入如Kendra、Wikipedia、API搜索等非向量后端;而DocumentLoader提
供上百种数据源适配(本地/云存储/协作平台/社媒等),统一产出
Document{page_content,metadata}以便后续切分、嵌入与检索。
作用:统一的模型/工具/检索/编排抽象让团队可以快速换型(模型或向量
库迁移时仅需少量改动),并把工程精力集中在业务逻辑而非粘合代码上。
4.2复杂应用的编排:从"轻管道"到"有状态多智能体"
LangChain覆盖了从简单链到复杂代理系统的全谱系编排能力:
LCEL适合轻量链路:如"Prompt→LLM→解析器"、"RAG的检索→重写→
险心里有数,加速从Demo到可用产品的迁移。
4.4生产部署与管理:长跑型智能体的托管、伸缩与治理
从"能跑"到"能长跑",关键在运行时与治理能力。LangChain提供LangGraph
Platform作为生产级运行时:
长运行/有状态代理的运行时:提供执行、持久化、监控、扩缩等API;可把用
LangGraph(或其他框架)构建的代理托管成托管端点,并附带面向"助手/代理
UX"的观点化API与集成开发者工作室。
多部署形态:支持本地开发免费运行,生产可选云、混合、自建三种模式,满足
合规/内网/成本等差异化诉求。
作用:把"能工作的多智能体"稳定地跑在生产,并通过平台化能力做好
可观测、扩缩与团队协作;结合LangSmith,可形成"开发---评测---部
署---观测"一体化流水线。
4.5典型落地价值(角色定位小结)
对应用工程师:统一接口+LCEL让原型快、维护稳;检索/工具接入与切换低成本。
对平台/架构团队:LangGraph让复杂代理可控可回放,HITL与状态持久化支撑审计与风
控。
对运维与质量团队:LangSmith把不确定性指标化,持续评测+线上观测锁定问题根因与回
归。
对生产部署:LangGraphPlatform提供可选托管路径与多形态部署,让智能体从实验室走向长
期在线服务。
LangChain通过标准化接口(LCEL/Tool/Retriever/Loader)、分层编排(LCEL↔
LangGraph)、可观测与评测(LangSmith)以及生产运行时(LangGraphPlatform),
把LLM从"强但不稳"的黑盒,变成可复用、可组合、可观测、可运营的工程化能力底
座,显著缩短从Demo到生产的距离。
如果团队更偏向可视化搭建与教学演示,可引入LangFlow作为低/零代码
的可视化编排界面(与LangChain概念一一对应,支持主流LLM/向量库),
用于快速试验与团队协作
五、LangChain的优势
LangChain具有以下优势:
灵活性与扩展性:支持与多种模型、工具和数据源的集成,适应不同的应用场景。
模块化设计:各组件功能独立,开发者可以根据需求选择使用,降低了耦合度。
活跃的社区支持:拥有庞大的开发者社区,提供丰富的资源和支持,促进了生态的
持续发展。
集成LangChain:与LangChain紧密集成,支持所有主要的LLM和向量数据库。
多代理支持:支持多代理的编排和对话管理。
实时测试:提供即时测试环境,支持快速迭代和调试。
适用场景:
快速原型开发和MVP构建。
需要低代码解决方案的开发者。
教育和培训场景中的应用构建。
5.LangGraphStudio:可视化调试与开发环境
功能概述:
可视化代理图:提供可视化的代理图,帮助开发者理解应用结构。
实时交互:支持在代理运行过程中修改结果或逻辑,进行实时调试。
代码编辑器集成:支持在代码编辑器中修改代码,并能够重新运行节点。
适用场景:
开发复杂的代理应用程序。
需要实时调试和交互的开发环境。
教育和培训场景中的应用开发。
6.LangGraphPlatform:生产就绪的托管平台
功能概述:
托管基础设施:提供托管基础设施,用于部署长期运行、有状态的AI代理。
多智能体协作:支持多智能体的协作和任务调度。
持久化上下文管理:支持持久化的上下文管理,确保代理的长期运行。
适用场景:
需要长期运行和高可用性的生产环境。
需要多智能体协作和任务调度的应用。
需要持久化上下文管理的复杂应用。
通过这些工具的协同工作,开发者可以构建、调试、部署和维护复杂的LLM应用,满
足不同场景的需求。
四、LangChain解决的问题与作用
LangChain通过标准化接口(LCEL/Tool/Retriever/Loader)、分层编排(LCEL↔
LangGraph)、可观测与评测(LangSmith)以及生产运行时(LangGraphPlatform),把
LLM从"强但不稳"的黑盒,变成可复用、可组合、可观测、可运营的工程化能力底座,
显著缩短从Demo到生产的距离。
4.1组件标准化接口:降低集成成本、摆脱厂商锁定
LangChain为"模型---工具---检索---管道"这几类基础构件提供了统一的抽象层,显著
减少在不同厂商接口之间改写代码的工作量。核心在于:
Runnable/LCEL标准化编排:所有链式组件统一实现Runnable接口;在此之上,
作用:统一的模型/工具/检索/编排抽象让团队可以快速换型(模型或向量
库迁移时仅需少量改动),并把工程精力集中在业务逻辑而非粘合代码上。
4.2复杂应用的编排:从"轻管道"到"有状态多智能体"
LangChain覆盖了从简单链到复杂代理系统的全谱系编排能力:
LCEL适合轻量链路:如"Prompt→LLM→解析器"、"RAG的检索→重写→
生成"等线性或轻分支流程,享受流式、异步、并行与内建追踪。官方建议复杂度
不高时用LCEL,让代码更简洁、性能更稳。
LangGraph处理复杂/长期/多智能体场景:当流程存在显式状态、循环、分支、
回退、多代理协作,或需要持久化与断点续跑、人类在环(HITL)时,使用
LangGraph。它支持耐久执行、全面记忆(短/长时),并能把图状态做检查点,
从而在审核或人工介入后暂停/继续执行------这是生产环境智能体需要的"可控性"。
作用:把简单场景交给LCEL,把复杂有状态场景交给LangGraph,既保证
开发效率,又确保复杂系统在生产中的可控与韧性。4.3可观察性与评估:把"不确定的LLM"变 成"可度量的系统"
LLM天生概率性强、易漂移,LangChain通过LangSmith提供从开发到上线的一
体化可观测与评测:
Tracing&Debugging:对每次调用自动记录输入、输出、耗时、代价、链路拓扑
与工具调用细节;配合LCEL的自动打点,复杂链路也能完整复盘。
Datasets&Evaluations:把真实用户数据或合成样例沉淀为数据集,按"数据集→
目标函数→评测器"运行评测,比较不同Prompt/模型/参数/版本的得分,
定位失败样例并复现;评测既支持通用正确性,也可写自定义evaluator贴合业务
指标。
作用:形成"观测---诊断---改进---再评测"闭环,让团队对质量与回归风
险心里有数,加速从Demo到可用产品的迁移。
4.4生产部署与管理:长跑型智能体的托管、伸缩与治理
从"能跑"到"能长跑",关键在运行时与治理能力。LangChain提供LangGraph
Platform作为生产级运行时:
长运行/有状态代理的运行时:提供执行、持久化、监控、扩缩等API;可把用
LangGraph(或其他框架)构建的代理托管成托管端点,并附带面向"助手/代理
Invoking: `pdf_extractor` with `{'query': '竞品框架 比较 对比 其他框架'}`
responded: 让我继续查询更多关于LangChain竞品框架的对比信息。
险心里有数,加速从Demo到可用产品的迁移。
4.4生产部署与管理:长跑型智能体的托管、伸缩与治理
从"能跑"到"能长跑",关键在运行时与治理能力。LangChain提供LangGraph
Platform作为生产级运行时:
长运行/有状态代理的运行时:提供执行、持久化、监控、扩缩等API;可把用
LangGraph(或其他框架)构建的代理托管成托管端点,并附带面向"助手/代理
UX"的观点化API与集成开发者工作室。
多部署形态:支持本地开发免费运行,生产可选云、混合、自建三种模式,满足
合规/内网/成本等差异化诉求。
作用:把"能工作的多智能体"稳定地跑在生产,并通过平台化能力做好
可观测、扩缩与团队协作;结合LangSmith,可形成"开发---评测---部
署---观测"一体化流水线。
4.5典型落地价值(角色定位小结)
对应用工程师:统一接口+LCEL让原型快、维护稳;检索/工具接入与切换低成本。
对平台/架构团队:LangGraph让复杂代理可控可回放,HITL与状态持久化支撑审计与风
控。
对运维与质量团队:LangSmith把不确定性指标化,持续评测+线上观测锁定问题根因与回
归。
对生产部署:LangGraphPlatform提供可选托管路径与多形态部署,让智能体从实验室走向长
期在线服务。
LangChain通过标准化接口(LCEL/Tool/Retriever/Loader)、分层编排(LCEL↔
LangGraph)、可观测与评测(LangSmith)以及生产运行时(LangGraphPlatform),
把LLM从"强但不稳"的黑盒,变成可复用、可组合、可观测、可运营的工程化能力底
座,显著缩短从Demo到生产的距离。
如果团队更偏向可视化搭建与教学演示,可引入LangFlow作为低/零代码
的可视化编排界面(与LangChain概念一一对应,支持主流LLM/向量库),
用于快速试验与团队协作
五、LangChain的优势
LangChain具有以下优势:
灵活性与扩展性:支持与多种模型、工具和数据源的集成,适应不同的应用场景。
模块化设计:各组件功能独立,开发者可以根据需求选择使用,降低了耦合度。
活跃的社区支持:拥有庞大的开发者社区,提供丰富的资源和支持,促进了生态的
持续发展。
显著缩短从Demo到生产的距离。
4.1组件标准化接口:降低集成成本、摆脱厂商锁定
LangChain为"模型---工具---检索---管道"这几类基础构件提供了统一的抽象层,显著
减少在不同厂商接口之间改写代码的工作量。核心在于:
Runnable/LCEL标准化编排:所有链式组件统一实现Runnable接口;在此之上,
LangChainExpressionLanguage(LCEL)用声明式语法把提示词、模型调用、解析
器、检索器等拼装为稳定的"链",并天然支持流式返回、异步与并行,还自动打点
到LangSmith(需要外网,国内不方便),便于调试与回溯。官方也明确给出使
用指引:简单编排用LCEL,涉及分支、循环、多智能体与显式状态时转用
LangGraph。
ToolCalling统一接口:不同模型厂商(OpenAI/Anthropic/Gemini等)对工具调
用的返回结构各不相同。LangChain将其**标准化为ChatModel.bind_tools()+
AIMessage.tool_calls**,开发者只需用@tool装饰器定义函数及其模式
(schema),再绑定到支持工具调用的模型即可跨厂商复用。这样避免了早期需要针
对各家API拆additional_kwargs的脆弱写法。
检索/向量库/文档加载的统一协议:LangChain为Retriever抽象出统一接口;向量
库可一键转为检索器(.as_retriever()),既能对接Faiss、Pinecone等向量库,
也能接入如Kendra、Wikipedia、API搜索等非向量后端;而DocumentLoader提
供上百种数据源适配(本地/云存储/协作平台/社媒等),统一产出
Document{page_content,metadata}以便后续切分、嵌入与检索。
作用:统一的模型/工具/检索/编排抽象让团队可以快速换型(模型或向量
库迁移时仅需少量改动),并把工程精力集中在业务逻辑而非粘合代码上。
4.2复杂应用的编排:从"轻管道"到"有状态多智能体"
LangChain覆盖了从简单链到复杂代理系统的全谱系编排能力:
LCEL适合轻量链路:如"Prompt→LLM→解析器"、"RAG的检索→重写→
调试、部署到可视化编排的全方位工具。以下是对LangChain核心生态系统中主要组件
的详细介绍:
1.LangChain:LLM应用的基础框架功能概述:
模块化构建:提供Prompt模板、工具调用、记忆管理、检索增强生成(RAG)
等模块,帮助开发者构建复杂的LLM应用。
多模型支持:支持与OpenAI、Anthropic、HuggingFace等多种大型语言模型的集
成。
丰富的集成:提供与数据库、API、文件系统等外部资源的集成,扩展应用的能力。
适用场景:
快速原型开发。
构建线性流程的LLM应用。
需要灵活集成多种工具和资源的应用。
2.LangGraph:复杂工作流的编排引擎
功能概述:
状态管理:维护应用的当前状态,支持持久化和流式处理。
多智能体协作:支持多代理的协作和通信,适用于复杂的任务分配和执行。可与
LangChain兼容开发使用。
流程控制:支持循环、条件判断等复杂的流程控制。
适用场景:
构建复杂的多智能体系统。
需要动态决策和状态管理的应用。
需要高可扩展性和可靠性的生产环境。
3.LangSmith:开发和生产的可观察性平台
功能概述:
追踪与调试:提供对LLM应用的追踪和调试功能,帮助开发者识别和解决问题。
性能评估:评估模型和链的性能,提供优化建议。
框架无关性:支持与多种LLM框架的集成,不仅限于LangChain。
适用场景:
开发阶段的调试和优化。
生产环境中的监控和评估。
需要高可靠性和可维护性的应用。
4.LangFlow:低代码的可视化应用构建工具
功能概述:
拖拽式界面:通过可视化界面,用户可以拖拽组件,快速构建AI应用。可对比
Dify,相比之下,LangFlow完全开源,更加灵活。
集成LangChain:与LangChain紧密集成,支持所有主要的LLM和向量数据库。
多代理支持:支持多代理的编排和对话管理。
实时测试:提供即时测试环境,支持快速迭代和调试。
适用场景:
快速原型开发和MVP构建。
需要低代码解决方案的开发者。
教育和培训场景中的应用构建。
5.LangGraphStudio:可视化调试与开发环境
集成LangChain:与LangChain紧密集成,支持所有主要的LLM和向量数据库。
多代理支持:支持多代理的编排和对话管理。
实时测试:提供即时测试环境,支持快速迭代和调试。
适用场景:
快速原型开发和MVP构建。
需要低代码解决方案的开发者。
教育和培训场景中的应用构建。
5.LangGraphStudio:可视化调试与开发环境
功能概述:
可视化代理图:提供可视化的代理图,帮助开发者理解应用结构。
实时交互:支持在代理运行过程中修改结果或逻辑,进行实时调试。
代码编辑器集成:支持在代码编辑器中修改代码,并能够重新运行节点。
适用场景:
开发复杂的代理应用程序。
需要实时调试和交互的开发环境。
教育和培训场景中的应用开发。
6.LangGraphPlatform:生产就绪的托管平台
功能概述:
托管基础设施:提供托管基础设施,用于部署长期运行、有状态的AI代理。
多智能体协作:支持多智能体的协作和任务调度。
持久化上下文管理:支持持久化的上下文管理,确保代理的长期运行。
适用场景:
需要长期运行和高可用性的生产环境。
需要多智能体协作和任务调度的应用。
需要持久化上下文管理的复杂应用。
通过这些工具的协同工作,开发者可以构建、调试、部署和维护复杂的LLM应用,满
足不同场景的需求。
四、LangChain解决的问题与作用
LangChain通过标准化接口(LCEL/Tool/Retriever/Loader)、分层编排(LCEL↔
LangGraph)、可观测与评测(LangSmith)以及生产运行时(LangGraphPlatform),把
LLM从"强但不稳"的黑盒,变成可复用、可组合、可观测、可运营的工程化能力底座,
显著缩短从Demo到生产的距离。
4.1组件标准化接口:降低集成成本、摆脱厂商锁定
LangChain为"模型---工具---检索---管道"这几类基础构件提供了统一的抽象层,显著
减少在不同厂商接口之间改写代码的工作量。核心在于:
Runnable/LCEL标准化编排:所有链式组件统一实现Runnable接口;在此之上,
Invoking: `pdf_extractor` with `{'query': 'Dify LLamaIndex AutoGen Haystack 框架'}`
responded: 让我查询更多关于其他框架的信息。
一、前言
在当今AI应用开发领域,大型语言模型(LLM)已成为核心技术之一。然而,如
何将LLM与外部数据源、工具和API有效集成,构建高效、可扩展的智能应用,仍然
是开发者面临的挑战。为此,LangChain应运而生,提供了一个灵活、模块化的框架,帮
助开发者构建复杂的LLM应用。
作为一个大模型开发者,在选择合适的框架时,应根据具体的应用需求、团队的技术
栈以及项目的复杂度等因素进行综合考虑。LangChain、LlamaIndex和GoogleADK
(AgentDevelopmentKit)等不同的开发框架各有优势,理解它们的特点和适用场景,
有助于做出更合适的选择。
1.LangChain
特点:提供与LLM的集成、工具调用、记忆管理、流程控制等功能,支持多种
数据源和模型的接入。
优势:模块化设计,灵活性高,适用于构建复杂的LLM应用。
适用场景:需要高度自定义和灵活性的应用,如智能客服、文档分析等。
2.LlamaIndex
特点:专注于检索增强生成(RAG)任务,提供数据加载、索引构建、查询引擎
等功能。
优势:在处理大规模数据集和高效信息检索方面表现出色。
适用场景:需要高效信息检索和问答功能的应用,如知识库构建、搜索引擎等。
3.GoogleADK
特点:提供模块化、多智能体系统的构建能力,支持结构化和动态的工作流编排。
优势:适用于构建复杂的多智能体系统,支持多种代理的协作和任务调度。
适用场景:需要多智能体协作和复杂任务调度的应用,如自动化流程、智能助手
等。
二、LangChain的背景与诞生
LangChain由HarrisonChase于2021年提出,并于2022年作为开源项目正式发
布。其初衷是简化大型语言模型(LLM)与外部数据源、工具和API的集成,推动
LLM应用的快速开发。
2022年:功能扩展与生态起步2022年,LangChain发布了第一个版本,提供了
基础的提示词(Prompt)管理功能,并支持将工具(Tool)与语言模型结合,支持
调用外部API。同时,新增了对外部数据源的支持,包括SQL数据库、NoSQL
数据库、文件系统等,使得开发者能够将LLM与各种数据源无缝集成。
调试、部署到可视化编排的全方位工具。以下是对LangChain核心生态系统中主要组件
的详细介绍:
1.LangChain:LLM应用的基础框架功能概述:
模块化构建:提供Prompt模板、工具调用、记忆管理、检索增强生成(RAG)
等模块,帮助开发者构建复杂的LLM应用。
多模型支持:支持与OpenAI、Anthropic、HuggingFace等多种大型语言模型的集
成。
丰富的集成:提供与数据库、API、文件系统等外部资源的集成,扩展应用的能力。
适用场景:
快速原型开发。
构建线性流程的LLM应用。
需要灵活集成多种工具和资源的应用。
2.LangGraph:复杂工作流的编排引擎
功能概述:
状态管理:维护应用的当前状态,支持持久化和流式处理。
多智能体协作:支持多代理的协作和通信,适用于复杂的任务分配和执行。可与
LangChain兼容开发使用。
流程控制:支持循环、条件判断等复杂的流程控制。
适用场景:
构建复杂的多智能体系统。
需要动态决策和状态管理的应用。
需要高可扩展性和可靠性的生产环境。
3.LangSmith:开发和生产的可观察性平台
功能概述:
追踪与调试:提供对LLM应用的追踪和调试功能,帮助开发者识别和解决问题。
性能评估:评估模型和链的性能,提供优化建议。
框架无关性:支持与多种LLM框架的集成,不仅限于LangChain。
适用场景:
开发阶段的调试和优化。
生产环境中的监控和评估。
需要高可靠性和可维护性的应用。
4.LangFlow:低代码的可视化应用构建工具
功能概述:
拖拽式界面:通过可视化界面,用户可以拖拽组件,快速构建AI应用。可对比
Dify,相比之下,LangFlow完全开源,更加灵活。
集成LangChain:与LangChain紧密集成,支持所有主要的LLM和向量数据库。
多代理支持:支持多代理的编排和对话管理。
实时测试:提供即时测试环境,支持快速迭代和调试。
适用场景:
快速原型开发和MVP构建。
需要低代码解决方案的开发者。
教育和培训场景中的应用构建。
5.LangGraphStudio:可视化调试与开发环境
LLM应用的快速开发。
2022年:功能扩展与生态起步2022年,LangChain发布了第一个版本,提供了
基础的提示词(Prompt)管理功能,并支持将工具(Tool)与语言模型结合,支持
调用外部API。同时,新增了对外部数据源的支持,包括SQL数据库、NoSQL
数据库、文件系统等,使得开发者能够将LLM与各种数据源无缝集成。
2023年:快速发展与生态构建2023年,LangChain进入快速发展阶段,推出了
多个关键功能模块,包括链(Chain)、记忆(Memory)、工具与代理(Tool&
Agent)、检索增强生成(RAG)支持、流水线功能等,进一步增强了框架的灵活
性和功能性。同时,LangChain加强了社区建设,吸引了大量开发者参与,生态系
统逐步完善。
2024年:稳定版本发布与企业化进程2024年1月8日,LangChain发布了第
一个稳定版本(0.1.0),标志着框架进入成熟阶段。同年2月,LangChain发布
了LangSmith,这是一个闭源的可观察性和评估平台,旨在帮助开发者跟踪、评估
并迭代LLM应用。此外,LangChain宣布完成了由SequoiaCapital领投的2500
万美元A轮融资。
2025年:多智能体系统与长期部署能力2025年5月14日,LangChain推出了
LangGraph平台,提供了托管基础设施,用于部署长期运行、有状态的AI代理。
该平台支持多智能体协作、动态任务调度和持久化上下文管理,适用于复杂的工作
流和多步骤任务。此外,LangChain继续扩展其生态系统,推出了多个新功能和工
具,进一步提升了框架的能力和适用范围。
三、LangChain的核心生态系统 在构建智能应用的过程中,LangChain提供了一个强大的生态 系统,涵盖了从开发、
调试、部署到可视化编排的全方位工具。以下是对LangChain核心生态系统中主要组件
的详细介绍:
1.LangChain:LLM应用的基础框架功能概述:
模块化构建:提供Prompt模板、工具调用、记忆管理、检索增强生成(RAG)
等模块,帮助开发者构建复杂的LLM应用。
多模型支持:支持与OpenAI、Anthropic、HuggingFace等多种大型语言模型的集
成。
显著缩短从Demo到生产的距离。
4.1组件标准化接口:降低集成成本、摆脱厂商锁定
LangChain为"模型---工具---检索---管道"这几类基础构件提供了统一的抽象层,显著
减少在不同厂商接口之间改写代码的工作量。核心在于:
Runnable/LCEL标准化编排:所有链式组件统一实现Runnable接口;在此之上,
LangChainExpressionLanguage(LCEL)用声明式语法把提示词、模型调用、解析
器、检索器等拼装为稳定的"链",并天然支持流式返回、异步与并行,还自动打点
到LangSmith(需要外网,国内不方便),便于调试与回溯。官方也明确给出使
用指引:简单编排用LCEL,涉及分支、循环、多智能体与显式状态时转用
LangGraph。
ToolCalling统一接口:不同模型厂商(OpenAI/Anthropic/Gemini等)对工具调
用的返回结构各不相同。LangChain将其**标准化为ChatModel.bind_tools()+
AIMessage.tool_calls**,开发者只需用@tool装饰器定义函数及其模式
(schema),再绑定到支持工具调用的模型即可跨厂商复用。这样避免了早期需要针
对各家API拆additional_kwargs的脆弱写法。
检索/向量库/文档加载的统一协议:LangChain为Retriever抽象出统一接口;向量
库可一键转为检索器(.as_retriever()),既能对接Faiss、Pinecone等向量库,
也能接入如Kendra、Wikipedia、API搜索等非向量后端;而DocumentLoader提
供上百种数据源适配(本地/云存储/协作平台/社媒等),统一产出
Document{page_content,metadata}以便后续切分、嵌入与检索。
作用:统一的模型/工具/检索/编排抽象让团队可以快速换型(模型或向量
库迁移时仅需少量改动),并把工程精力集中在业务逻辑而非粘合代码上。
4.2复杂应用的编排:从"轻管道"到"有状态多智能体"
LangChain覆盖了从简单链到复杂代理系统的全谱系编排能力:
LCEL适合轻量链路:如"Prompt→LLM→解析器"、"RAG的检索→重写→根据查询到的信息,我来为您总结LangChain与竞品框架的对比:
## LangChain竞品框架对比
### 主要竞品框架概览
#### 1. **LlamaIndex**
- **特点**:专注于检索增强生成(RAG)任务,提供数据加载、索引构建、查询引擎等功能
- **优势**:在处理大规模数据集和高效信息检索方面表现出色
- **适用场景**:需要高效信息检索和问答功能的应用,如知识库构建、搜索引擎等
#### 2. **Google ADK (Agent Development Kit)**
- **特点**:提供模块化、多智能体系统的构建能力,支持结构化和动态的工作流编排
- **优势**:适用于构建复杂的多智能体系统,支持多种代理的协作和任务调度
- **适用场景**:需要多智能体协作和复杂任务调度的应用,如自动化流程、智能助手等
#### 3. **Dify**
- **特点**:低代码平台,提供可视化界面构建AI应用
- **对比**:与LangFlow相比,Dify是部分闭源的,而LangFlow完全开源,更加灵活
### LangChain的独特优势
#### 1. **完整的生态系统**
LangChain提供了一个完整的生态系统,包括:
- **LangChain**:基础框架,提供模块化构建能力
- **LangGraph**:复杂工作流编排引擎,支持状态管理和多智能体协作
- **LangSmith**:可观察性平台,提供追踪、调试和性能评估
- **LangFlow**:低代码可视化应用构建工具,完全开源
- **LangGraph Studio**:可视化调试与开发环境
- **LangGraph Platform**:生产就绪的托管平台
#### 2. **标准化接口**
- **Runnable/LCEL标准化编排**:所有链式组件统一实现Runnable接口,支持流式返回、异步与并行
- **Tool Calling统一接口**:将不同模型厂商的工具调用标准化,实现跨厂商复用
- **检索/向量库/文档加载的统一协议**:提供统一的Retriever接口,支持多种向量库和数据源
#### 3. **分层编排能力**
- **LCEL**:适合轻量链路,如简单的"Prompt→LLM→解析器"流程
- **LangGraph**:处理复杂/长期/多智能体场景,支持显式状态、循环、分支、回退等
#### 4. **从Demo到生产的完整支持**
- **开发阶段**:统一接口+LCEL让原型开发快速、维护稳定
- **调试评测**:LangSmith提供完整的可观测与评测能力
- **生产部署**:LangGraph Platform提供托管、伸缩与治理能力
- **多部署形态**:支持本地、云、混合、自建等多种部署模式
### 框架选择建议
选择框架时应考虑以下因素:
1. **如果需要快速原型开发和灵活集成**:选择LangChain
2. **如果专注于RAG和信息检索**:选择LlamaIndex
3. **如果需要复杂的多智能体协作**:LangChain的LangGraph或Google ADK
4. **如果需要低代码可视化开发**:LangFlow(开源)或Dify
5. **如果需要完整的生产级解决方案**:LangChain生态系统提供最全面的支持
### 总结
LangChain的核心优势在于其完整的生态系统和标准化的接口设计,能够显著缩短从Demo到生产的距离。它不仅提供了基础的框架能力,还通过LangGraph、LangSmith、LangFlow等工具覆盖 了开发、调试、部署、监控的全生命周期,特别适合需要构建复杂、可扩展的企业级LLM应用的团队。
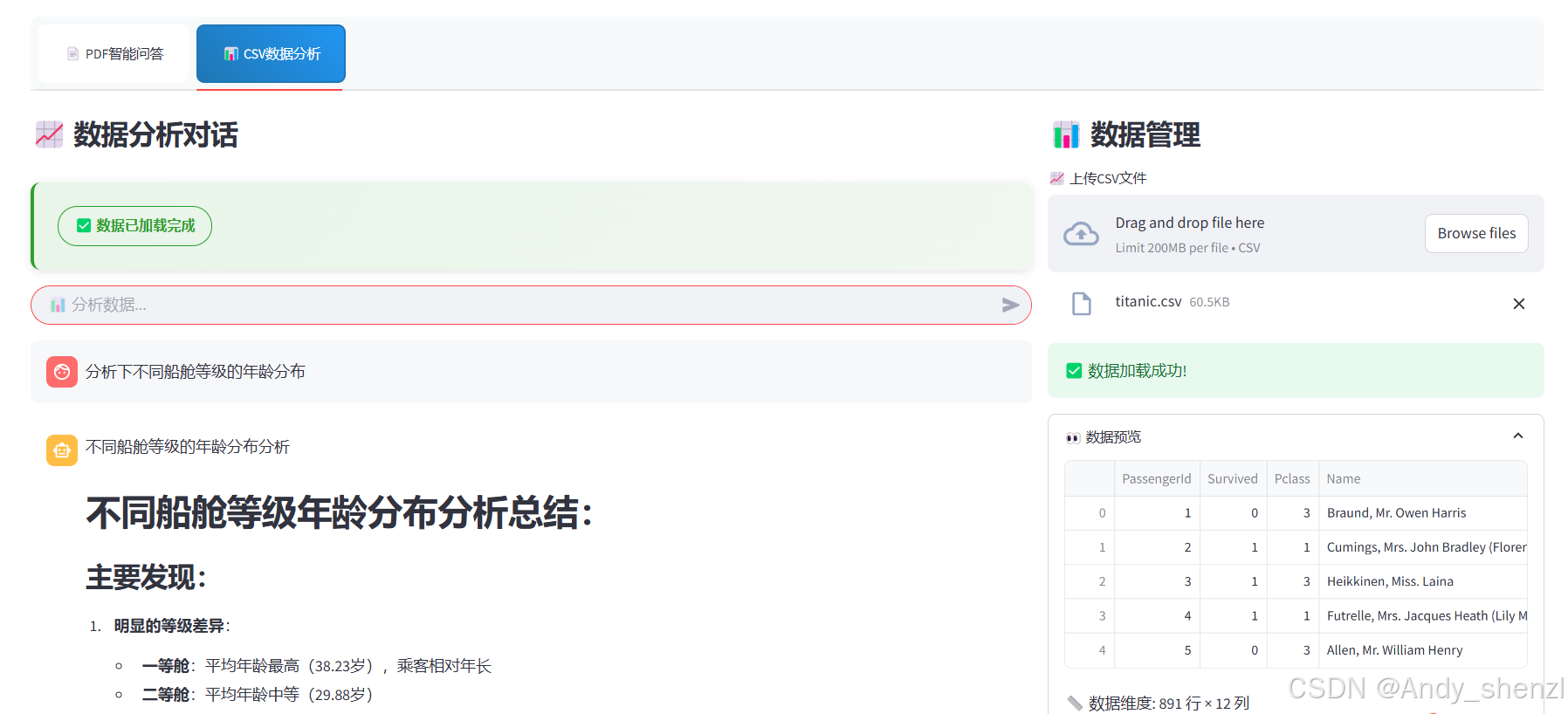
> Finished chain.7.2 数据分析
基于titanic数据集进行测试
python
> Entering new AgentExecutor chain...
Invoking: `python_repl_ast` with `{'query': 'import pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# 设置中文字体\nplt.rcParams["font.family"] = ["SimHei"]\nplt.rcParams["axes.unicode_minus"] = False\n\n# 查看数据基本信息\nprint("数据基本信息:")\nprint(f"数据集大小: {df.shape}")\nprint(f"船舱等级分布:")\nprint(df[\'Pclass\'].value_counts())\nprint(f"\\n年龄列缺失值数量: {df[\'Age\'].isnull().sum()}")\nprint(f"年龄描述性统计:")\nprint(df[\'Age\'].describe())'}`
responded: 我来分析不同船舱等级的年龄分布。首先让我查看一下数据的基本情况,然后生成相应的图表。
ModuleNotFoundError: No module named 'seaborn'
Invoking: `python_repl_ast` with `{'query': 'import pandas as pd\nimport matplotlib.pyplot as plt\n\n# 设置中文字体\nplt.rcParams["font.family"] = ["SimHei"]\nplt.rcParams["axes.unicode_minus"] = False\n\n# 查看数据基本信息\nprint("数据基本信息:")\nprint(f"数据集大小: {df.shape}")\nprint(f"船舱等级分布:")\nprint(df[\'Pclass\'].value_counts())\nprint(f"\\n年龄列缺失值数量: {df[\'Age\'].isnull().sum()}")\nprint(f"年龄描述性统计:")\nprint(df[\'Age\'].describe())'}`
responded: 让我使用matplotlib来创建图表:
数据基本信息:
数据集大小: (891, 12)
船舱等级分布:
Pclass
3 491
1 216
2 184
Name: count, dtype: int64
年龄列缺失值数量: 177
年龄描述性统计:
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
Invoking: `python_repl_ast` with `{'query': '# 按船舱等级分组查看年龄统计\nprint("\\n不同船舱等级的年龄统计:")\nage_by_class = df.groupby(\'Pclass\')[\'Age\'].describe()\nprint(age_by_class)'}`
不同船舱等级的年龄统计:
count mean std min 25% 50% 75% max
Pclass
1 186.0 38.233441 14.802856 0.92 27.0 37.0 49.0 80.0
2 173.0 29.877630 14.001077 0.67 23.0 29.0 36.0 70.0
3 355.0 25.140620 12.495398 0.42 18.0 24.0 32.0 74.0
Invoking: `python_repl_ast` with `{'query': "# 创建箱线图显示不同船舱等级的年龄分布\nplt.figure(figsize=(10, 6))\n\n# 按船舱等级分组数据\nclass1_ages = df[df['Pclass'] == 1]['Age'].dropna()\nclass2_ages = df[df['Pclass'] == 2]['Age'].dropna()\nclass3_ages = df[df['Pclass'] == 3]['Age'].dropna()\n\n# 创建箱线图\ndata = [class1_ages, class2_ages, class3_ages]\nlabels = ['一等舱', '二等舱', '三等舱']\nplt.boxplot(data, labels=labels)\n\nplt.xlabel('船舱等级')\nplt.ylabel('年龄')\nplt.title('不同 船舱等级的年龄分布箱线图')\nplt.grid(True, alpha=0.3)\n\nplt.savefig('plot.png', dpi=300, bbox_inches='tight')\nplt.show()"}`
responded: 现在让我创建箱线图来可视化不同船舱等级的年龄分布:
<string>:1: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
Invoking: `python_repl_ast` with `{'query': "# 创建直方图显示不同船舱等级的年龄分布\nplt.figure(figsize=(12, 8))\n\n# 创建子图\nfig, axes = plt.subplots(1, 3, figsize=(15, 5))\n\n# 一等舱年龄分布\naxes[0].hist(class1_ages, bins=20, alpha=0.7, color='blue', edgecolor='black')\naxes[0].set_title('一等舱年龄分布')\naxes[0].set_xlabel('年龄')\naxes[0].set_ylabel('频数')\naxes[0].grid(True, alpha=0.3)\n\n# 二等舱年龄分布\naxes[1].hist(class2_ages, bins=20, alpha=0.7, color='green', edgecolor='black')\naxes[1].set_title('二等舱年龄分布')\naxes[1].set_xlabel('年龄')\naxes[1].set_ylabel('频数')\naxes[1].grid(True, alpha=0.3)\n\n# 三等舱年龄分布\naxes[2].hist(class3_ages, bins=20, alpha=0.7, color='red', edgecolor='black')\naxes[2].set_title('三 等舱年龄分布')\naxes[2].set_xlabel('年龄')\naxes[2].set_ylabel('频数')\naxes[2].grid(True, alpha=0.3)\n\nplt.tight_layout()\nplt.savefig('plot.png', dpi=300, bbox_inches='tight')\nplt.show()"}`
responded: 现在让我再创建一个直方图来更详细地展示分布:
<string>:1: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
Invoking: `python_repl_ast` with `{'query': '# 计算各船舱等级的年龄统计指标\nprint("\\n=== 不同船舱等级年龄分布分析 ===")\nprint(f"\\n一等舱 (Pclass=1):")\nprint(f" 平均年龄: {class1_ages.mean():.2f} 岁")\nprint(f" 年龄中位数: {class1_ages.median():.2f} 岁")\nprint(f" 年龄标准差: {class1_ages.std():.2f} 岁")\nprint(f" 最小年龄: {class1_ages.min():.2f} 岁")\nprint(f" 最大年龄: {class1_ages.max():.2f} 岁")\n\nprint(f"\\n二等舱 (Pclass=2):")\nprint(f" 平均年龄: {class2_ages.mean():.2f} 岁")\nprint(f" 年龄中位数: {class2_ages.median():.2f} 岁")\nprint(f" 年龄标准差: {class2_ages.std():.2f} 岁")\nprint(f" 最小年龄: {class2_ages.min():.2f} 岁")\nprint(f" 最大年龄: {class2_ages.max():.2f} 岁")\n\nprint(f"\\n三等舱 (Pclass=3):")\nprint(f" 平均年龄: {class3_ages.mean():.2f} 岁")\nprint(f" 年龄中位数: {class3_ages.median():.2f} 岁")\nprint(f" 年龄标准差: {class3_ages.std():.2f} 岁")\nprint(f" 最 小年龄: {class3_ages.min():.2f} 岁")\nprint(f" 最大年龄: {class3_ages.max():.2f} 岁")'}`
responded: 让我再计算一些关键的统计指标:
=== 不同船舱等级年龄分布分析 ===
一等舱 (Pclass=1):
平均年龄: 38.23 岁
年龄中位数: 37.00 岁
年龄标准差: 14.80 岁
最小年龄: 0.92 岁
最大年龄: 80.00 岁
二等舱 (Pclass=2):
平均年龄: 29.88 岁
年龄中位数: 29.00 岁
年龄标准差: 14.00 岁
最小年龄: 0.67 岁
最大年龄: 70.00 岁
三等舱 (Pclass=3):
平均年龄: 25.14 岁
年龄中位数: 24.00 岁
年龄标准差: 12.50 岁
最小年龄: 0.42 岁
最大年龄: 74.00 岁
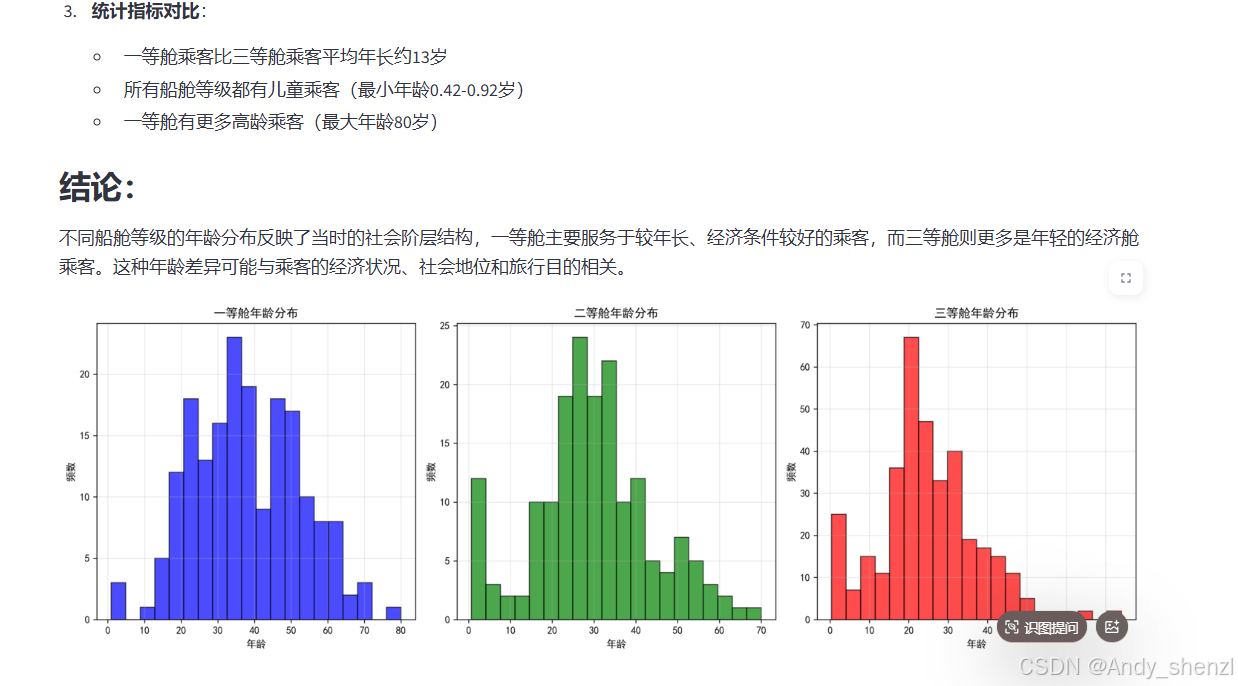
GRAPH:不同船舱等级的年龄分布分析
## 不同船舱等级年龄分布分析总结:
### 主要发现:
1. **明显的等级差异**:
- **一等舱**:平均年龄最高(38.23岁),乘客相对年长
- **二等舱**:平均年龄中等(29.88岁)
- **三等舱**:平均年龄最低(25.14岁),乘客相对年轻
2. **年龄分布特征**:
- 一等舱:年龄范围广(0.92-80岁),中老年人比例较高
- 二等舱:年龄分布相对集中,以青壮年为主
- 三等舱:年龄分布最集中,年轻人占主导
3. **统计指标对比**:
- 一等舱乘客比三等舱乘客平均年长约13岁
- 所有船舱等级都有儿童乘客(最小年龄0.42-0.92岁)
- 一等舱有更多高龄乘客(最大年龄80岁)
### 结论:
不同船舱等级的年龄分布反映了当时的社会阶层结构,一等舱主要服务于较年长、经济条件较好的乘客,而三等舱则更多是年轻的经济舱乘客。这种年龄差异可能与乘客的经济状况、社会地位和旅行目的相关。
> Finished chain.