破晓数据迷雾:从处理海量到创造价值的现代大数据架构全景
引言:数据的价值悖论与架构革命
我们在数据的海洋中溺亡,却在洞察的沙漠中渴死。这个残酷的悖论正困扰着大多数企业------据IDC数据,全球数据总量正以每年23% 的复合增长率膨胀,预计2025年达到175ZB,然而超过80% 的企业数据从未被有效分析,仅有不到15% 的组织能够将数据分析转化为可衡量的商业价值。
问题的根源并非数据本身,而是我们处理数据的架构范式。传统的集中式大数据架构如同试图用19世纪的铁路系统来运营21世纪的航空网络------设计理念的落后导致系统在复杂性面前彻底失效。
本文将深入剖析大数据架构的演进历程,揭示从"数据仓库"到"数据湖",再到"数据网格"和"湖仓一体"的范式转移,并提供构建现代数据价值系统的完整蓝图。
第一章:架构演进史:三代数据系统的兴衰
1.1 数据仓库时代:结构化的代价
第一代数据架构以Teradata、Oracle Exadata为代表,采用ETL-中心化存储-OLAP的三层模式:
sql
复制
下载
-- 经典数据仓库架构示例
CREATE TABLE dw_sales_fact (
date_id INT,
product_id INT,
customer_id INT,
store_id INT,
quantity INT,
amount DECIMAL(10,2)
) DISTRIBUTED BY (date_id);
-- 复杂的ETL管道
EXTRACT FROM operational_systems
TRANSFORM (clean, conform, aggregate)
LOAD INTO data_warehouse
-- 优点:数据一致性强,查询性能优秀
-- 致命缺陷:模式僵化,无法处理半结构化数据,变更周期长达数月这一架构的崩溃始于三个不可逆转的趋势:数据多样性爆炸、实时性需求激增、数据民主化期待。
1.2 数据湖时代:自由的陷阱
2010年代,Hadoop生态系统的崛起催生了数据湖范式------"先存后查"的哲学带来了前所未有的灵活性:
scala
复制
下载
// Spark数据湖处理示例
val rawData = spark.read.parquet("s3://data-lake/raw/")
.withColumn("processing_time", current_timestamp())
// 无模式写入
rawData.write.mode("append")
.partitionBy("year", "month", "day")
.save("s3://data-lake/silver/")
// 优点:成本极低,支持任意数据格式
// 致命缺陷:迅速沦为"数据沼泽"——缺乏治理、难以发现、质量堪忧数据湖的失败揭示了大数据的关键真理:技术上的可能性不等于组织上的可行性。没有治理的数据自由只会导致混乱。
1.3 第三代架构:湖仓一体与数据网格
现代架构的答案不再是非此即彼的选择题,而是"既要又要"的辩证统一:
python
复制
下载
# 湖仓一体化架构示例(Delta Lake + Iceberg)
# 1. 保持数据湖的开放性
df = spark.read.format("json").load("s3://raw-zone/events/")
# 2. 提供数据仓库的能力
# ACID事务支持
spark.sql("""
CREATE TABLE gold.user_behavior
USING iceberg
PARTITIONED BY (date)
TBLPROPERTIES (
'format-version'='2',
'write.delete.mode'='merge-on-read'
)
AS SELECT * FROM silver.events
""")
# 3. 时间旅行与增量处理
# 查询24小时前的数据版本
spark.read.format("iceberg")
.option("snapshot-id", "1234567890123456789")
.load("gold.user_behavior")
# 增量处理新数据
updates = spark.read.format("iceberg")
.option("start-snapshot-id", last_processed_snapshot)
.load("gold.user_behavior")而数据网格则从组织层面解决了根本问题,其四大支柱重新定义了数据所有权:
-
领域导向的数据所有权:数据由产生它的业务团队负责
-
数据即产品:每个数据域必须提供API、文档和SLA
-
自助式数据平台:平台团队提供基础设施而非数据
-
联邦治理:平衡全局标准与本地自主性
yaml
复制
下载
# 数据产品契约示例
apiVersion: datamesh.company.com/v1
kind: DataProduct
metadata:
name: real-time-customer-profile
domain: customer-experience
spec:
owner: customer-data-team@company.com
serviceLevel:
availability: 99.9%
freshness: "60s"
interfaces:
- type: "GraphQL"
endpoint: "https://api.data.company.com/customer-profile"
schema: "customer_profile.graphql"
- type: "Change Data Capture"
stream: "kafka://customer-events"
quality:
metrics:
- name: "completeness"
threshold: ">99%"
alertChannel: "slack#data-quality"
costAllocation:
model: "consumer-pays"
transparency: "per-query-breakdown"第二章:现代大数据技术栈全景
2.1 存储层演进:从HDFS到云原生表格式
传统HDFS的局限性催生了新一代存储方案:
| 方案 | 核心技术 | 优势 | 适用场景 |
|---|---|---|---|
| 云对象存储 | S3, ADLS, GCS | 无限扩展、极致成本、存算分离 | 原始数据存储、归档 |
| 表格式层 | Apache Iceberg, Delta Lake, Hudi | ACID事务、时间旅行、模式演化 | 生产数据层、增量处理 |
| 缓存层 | Alluxio, Redis | 亚秒级访问、热点数据加速 | 特征存储、实时查询 |
sql
复制
下载
-- Iceberg高级特性示例
-- 1. 隐藏分区(无需了解物理分区结构)
CREATE TABLE sales (
id BIGINT,
sale_time TIMESTAMP,
product STRING,
amount DECIMAL(10,2)
) PARTITIONED BY (
days(sale_time), -- 自动按天分区
bucket(10, id) -- 哈希分桶
);
-- 2. 模式演化(不重写数据)
ALTER TABLE sales ADD COLUMN discount DECIMAL(5,2);
ALTER TABLE sales RENAME COLUMN amount TO total_amount;
-- 3. 性能优化(数据剪枝)
-- 自动跳过不相关的数据文件
SELECT * FROM sales
WHERE sale_time BETWEEN '2024-01-01' AND '2024-01-31'
AND product = 'premium_product';2.2 计算引擎选择矩阵
不同的工作负载需要专门优化的计算引擎:
python
复制
下载
# 计算引擎选择框架
def select_compute_engine(requirements):
"""根据需求推荐最佳计算引擎"""
engines = {
"批处理": {
"spark": {
"吞吐量": "极高",
"延迟": "分钟级",
"成本效率": "高",
"最佳场景": ["ETL管道", "历史分析", "模型训练"]
},
"presto": {
"吞吐量": "高",
"延迟": "秒到分钟级",
"成本效率": "中",
"最佳场景": ["交互式查询", "ad-hoc分析"]
}
},
"流处理": {
"flink": {
"吞吐量": "极高",
"延迟": "毫秒级",
"状态管理": "优秀",
"最佳场景": ["实时风控", "CEP", "实时ETL"]
},
"spark_streaming": {
"吞吐量": "高",
"延迟": "秒级",
"状态管理": "良好",
"最佳场景": ["微批处理", "近实时分析"]
}
},
"混合负载": {
"starrocks": {
"吞吐量": "极高",
"延迟": "亚秒级",
"并发能力": "优秀",
"最佳场景": ["高并发BI", "实时报表"]
}
}
}
# 基于决策树推荐
if requirements["latency"] == "subsecond":
return "starrocks" if requirements["concurrency"] > 100 else "presto"
elif requirements["latency"] == "realtime":
return "flink" if requirements["exactly_once"] else "spark_streaming"
else:
return "spark"2.3 实时架构的实践模式
现代业务对实时性的需求催生了多种架构模式:
java
复制
下载
// Lambda架构 -> Kappa架构的演进
// 旧模式:维护两套逻辑(批+流)
public class LambdaArchitecture {
// 批处理层(T+1)
Dataset<Row> batchView = spark.sql(
"SELECT user_id, SUM(amount) FROM sales GROUP BY user_id"
);
// 速度层(实时)
DataStream<Tuple2<String, Double>> realtimeView = kafkaStream
.keyBy(event -> event.userId)
.timeWindow(Time.minutes(5))
.aggregate(new SumAggregate());
// 需要合并两套结果
public double getTotal(String userId) {
return batchView.get(userId) + realtimeView.get(userId);
}
}
// 新模式:统一的流处理(Kappa架构)
public class KappaArchitecture {
public DataStream<UserProfile> buildUnifiedPipeline() {
return env.addSource(kafkaSource)
.keyBy(event -> event.userId)
// 1. 实时处理
.process(new RealTimeProcessor())
// 2. 保存到支持更新的存储
.addSink(new IcebergSink("user_profiles"));
}
// 历史重处理只需改变数据源
public void reprocessHistory() {
env.addSource(historicalSource) // 从Iceberg读取
.keyBy(event -> event.userId)
.process(new RealTimeProcessor())
.addSink(new IcebergSink("user_profiles"));
}
}2.4 机器学习与大数据的深度融合
特征平台成为连接大数据与AI的关键桥梁:
python
复制
下载
# 现代化特征平台架构
class FeaturePlatform:
"""统一特征计算、存储、服务的平台"""
def __init__(self):
self.feature_store = FeastFeatureStore()
self.compute_engine = SparkComputeEngine()
self.serving_layer = RedisServingLayer()
def create_feature_view(self, feature_def):
"""定义特征视图"""
# 离线特征批计算
batch_features = self.compute_engine.compute_batch_features(
source_tables=feature_def.sources,
transformations=feature_def.transformations,
schedule=feature_def.schedule
)
# 在线特征服务
online_features = self.feature_store.create_online_store(
batch_features,
serving_config={
"latency_sla": "50ms p99",
"freshness": "1分钟"
}
)
# 注册特征元数据
self.feature_store.register_feature_view(
name=feature_def.name,
entities=feature_def.entities,
features=feature_def.feature_schema,
batch_source=batch_features,
online_source=online_features,
ttl=feature_def.ttl
)
return FeatureViewMetadata(
name=feature_def.name,
serving_endpoint=f"redis://features/{feature_def.name}",
monitoring_dashboard=self.create_monitoring(feature_def)
)
def get_training_data(self, entity_df, feature_refs):
"""获取训练数据(保证离在线一致性)"""
# 获取时间点一致的快照
training_df = self.feature_store.get_historical_features(
entity_df=entity_df,
feature_refs=feature_refs,
timestamp_col="event_timestamp"
)
# 自动验证数据质量
quality_report = self.validate_training_data(training_df)
if not quality_report.passed:
raise DataQualityError(
f"训练数据质量不达标: {quality_report.issues}"
)
return TrainingDataset(
data=training_df,
metadata={
"feature_definitions": feature_refs,
"snapshot_time": datetime.now(),
"quality_metrics": quality_report.metrics
}
)第三章:生产级大数据架构蓝图
3.1 分层架构设计
现代数据平台通常采用多层架构,平衡灵活性与治理:
sql
复制
下载
-- 典型的分层设计(以零售行业为例)
-- L0: 原始数据层 (Bronze)
CREATE TABLE bronze.website_events (
raw_data JSON,
source_system STRING,
ingested_at TIMESTAMP
) USING DELTA
LOCATION 's3://data-lake/bronze/events/';
-- L1: 清洗整合层 (Silver)
CREATE TABLE silver.user_sessions
USING ICEBERG
PARTITIONED BY (date)
AS
SELECT
user_id,
session_id,
MIN(event_time) as session_start,
MAX(event_time) as session_end,
COUNT(*) as event_count,
ARRAY_AGG(event_type) as event_sequence
FROM bronze.website_events
WHERE event_time >= CURRENT_DATE - INTERVAL 30 DAYS
GROUP BY user_id, session_id;
-- L2: 业务聚合层 (Gold)
CREATE MATERIALIZED VIEW gold.daily_metrics
REFRESH EVERY 1 HOUR
AS
SELECT
date,
COUNT(DISTINCT user_id) as dau,
SUM(session_duration) as total_engagement,
AVG(event_count) as avg_events_per_session
FROM silver.user_sessions
GROUP BY date;
-- L3: 应用层 (Platinum)
CREATE VIEW app.realtime_dashboard AS
SELECT
current_dau,
yesterday_dau,
growth_rate,
CASE
WHEN growth_rate < -0.1 THEN 'alert'
WHEN growth_rate > 0.2 THEN 'success'
ELSE 'normal'
END as status
FROM (
SELECT
today.dau as current_dau,
yesterday.dau as yesterday_dau,
(today.dau - yesterday.dau) / yesterday.dau as growth_rate
FROM gold.daily_metrics today
JOIN gold.daily_metrics yesterday
ON today.date = CURRENT_DATE
AND yesterday.date = CURRENT_DATE - 1
);3.2 数据质量与可观测性
数据质量不是一次性的检查,而是持续的过程:
python
复制
下载
# 数据质量即代码框架
class DataQualityFramework:
"""声明式的数据质量管理系统"""
def __init__(self):
self.expectation_store = ExpectationStore()
self.validation_engine = GreatExpectationsEngine()
self.observability_dashboard = GrafanaDashboard()
def define_data_contract(self, table_name, contract_spec):
"""定义数据契约"""
expectations = []
# 1. 完整性检查
for column in contract_spec.required_columns:
expectations.append({
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {"column": column},
"meta": {"severity": "critical"}
})
# 2. 准确性检查
if contract_spec.value_constraints:
for col, constraints in contract_spec.value_constraints.items():
if "min" in constraints:
expectations.append({
"expectation_type": "expect_column_values_to_be_between",
"kwargs": {
"column": col,
"min_value": constraints["min"],
"max_value": constraints.get("max", None)
}
})
# 3. 一致性检查
if contract_spec.referential_integrity:
for fk in contract_spec.referential_integrity:
expectations.append({
"expectation_type": "expect_column_pair_values_to_be_equal",
"kwargs": {
"column_A": fk["source"],
"column_B": fk["target"]
}
})
# 4. 时效性检查
expectations.append({
"expectation_type": "expect_table_row_count_to_be_between",
"kwargs": {
"min_value": contract_spec.min_rows_per_update,
"max_value": contract_spec.max_rows_per_update
},
"meta": {"freshness_check": True}
})
# 保存并调度
suite = self.expectation_store.save_expectation_suite(
table_name, expectations
)
# 创建监控
self.create_quality_monitoring(
table_name, suite,
schedule=contract_spec.check_frequency
)
return DataContract(
table=table_name,
expectations=len(expectations),
validation_schedule=contract_spec.check_frequency,
dashboard_url=self.observability_dashboard.create_dashboard(
table_name, contract_spec
)
)
def run_validation(self, table_name, data_batch):
"""执行数据验证"""
results = self.validation_engine.validate(
data_batch,
self.expectation_store.load_suite(table_name)
)
# 记录结果
validation_record = {
"table": table_name,
"batch_id": data_batch.batch_id,
"timestamp": datetime.now(),
"success": results.success,
"results": results.to_json_dict()
}
# 实时告警
if not results.success:
critical_failures = [
r for r in results.results
if not r.success and r.expectation_config.meta.get("severity") == "critical"
]
if critical_failures:
self.send_alert(
level="critical",
message=f"数据质量严重异常: {table_name}",
details={
"failures": critical_failures,
"batch_size": data_batch.data.shape[0],
"impact_assessment": self.assess_impact(table_name)
}
)
# 更新可观测性
self.observability_dashboard.update_metrics(
table_name, validation_record
)
return validation_record3.3 成本优化策略
大数据成本优化的五个关键维度:
python
复制
下载
# 大数据成本优化框架
class CostOptimizationFramework:
"""端到端的成本优化系统"""
def analyze_cost_drivers(self, time_range='30d'):
"""分析成本构成与驱动因素"""
cost_data = self.collector.get_cost_data(time_range)
analysis = {
"存储成本": {
"total": cost_data.storage_cost,
"breakdown": {
"hot_storage": self.analyze_hot_storage(cost_data),
"cold_storage": self.analyze_cold_storage(cost_data),
"redundancy": self.analyze_redundancy_cost(cost_data)
},
"优化机会": self.identify_storage_optimizations(cost_data)
},
"计算成本": {
"total": cost_data.compute_cost,
"breakdown": {
"批处理": self.analyze_batch_compute(cost_data),
"流处理": self.analyze_stream_compute(cost_data),
"交互查询": self.analyze_query_compute(cost_data)
},
"优化机会": self.identify_compute_optimizations(cost_data)
},
"数据传输": {
"total": cost_data.transfer_cost,
"优化机会": self.identify_transfer_optimizations(cost_data)
},
"闲置资源": {
"total": cost_data.idle_cost,
"详情": self.identify_idle_resources(cost_data),
"回收潜力": self.calculate_reclaim_potential(cost_data)
}
}
return CostAnalysisReport(
total_cost=sum(category["total"] for category in analysis.values()),
breakdown=analysis,
recommendations=self.generate_recommendations(analysis),
estimated_savings=self.estimate_savings_potential(analysis)
)
def implement_optimizations(self, recommendations):
"""实施成本优化措施"""
results = []
for rec in recommendations:
if rec.category == "storage_optimization":
result = self.optimize_storage(rec)
elif rec.category == "compute_rightsizing":
result = self.rightsize_compute(rec)
elif rec.category == "query_optimization":
result = self.optimize_queries(rec)
elif rec.category == "scheduling_optimization":
result = self.optimize_scheduling(rec)
results.append({
"recommendation": rec.description,
"implementation_status": result.status,
"actual_savings": result.savings,
"validation": self.validate_optimization(rec, result)
})
return OptimizationResults(
implementations=results,
total_validated_savings=sum(r["actual_savings"] for r in results),
roi=self.calculate_roi(results)
)第四章:行业实践案例
4.1 电商实时推荐系统架构
scala
复制
下载
// 电商实时推荐系统架构
object ECommerceRecommendation {
// 1. 实时特征计算
val userBehaviorFeatures = kafkaStream
.filter(_.eventType == "view" || _.eventType == "purchase")
.keyBy(_.userId)
.timeWindow(Time.minutes(30), Time.seconds(5))
.aggregate(new UserSessionAggregator())
.map(session => extractRealTimeFeatures(session))
// 2. 模型服务调用
val recommendations = userBehaviorFeatures
.map(features => {
// 调用多个模型服务
val cfRec = collaborativeFilteringModel.predict(features)
val cbRec = contentBasedModel.predict(features)
val nnRec = neuralNetworkModel.predict(features)
// 集成学习
EnsembleRecommendation(cfRec, cbRec, nnRec)
})
.map(recs => applyBusinessRules(recs)) // 业务规则过滤
.map(recs => diversify(recs)) // 多样性保证
.map(recs => applyFreshness(recs)) // 新鲜度调整
// 3. 结果存储与提供
recommendations
.addSink(new RedisSink("realtime_recommendations")) // 实时API查询
.addSink(new KafkaSink("recommendation_events")) // 下游消费
.addSink(new ElasticsearchSink("recommendation_logs")) // 分析记录
// 4. 反馈循环
val feedbackLoop = kafkaStream
.filter(_.eventType == "click" || _.eventType == "purchase")
.keyBy(_.recommendationId)
.process(new FeedbackProcessor())
.addSink(new ModelTrainingPipeline()) // 实时模型更新
}4.2 金融风控实时决策系统
python
复制
下载
# 金融实时风控决策系统
class RealTimeRiskDecisionSystem:
def __init__(self):
self.rules_engine = DroolsRulesEngine()
self.ml_models = RiskMLModels()
self.graph_analyzer = NetworkGraphAnalyzer()
self.decision_explain = ExplainableAI()
async def assess_transaction_risk(self, transaction):
"""评估交易风险"""
# 并行获取多维度数据
customer_profile, historical_patterns, external_signals = await asyncio.gather(
self.get_customer_profile(transaction.customer_id),
self.get_historical_patterns(transaction),
self.get_external_risk_signals(transaction)
)
# 多模型风险评估
risk_scores = {}
# 1. 规则引擎评估
rule_based_score = self.rules_engine.evaluate({
"transaction": transaction,
"customer": customer_profile,
"rules": self.load_rules("fraud_detection")
})
risk_scores["rule_based"] = rule_based_score
# 2. 机器学习模型评估
ml_features = self.build_ml_features(
transaction, customer_profile, historical_patterns
)
for model_name, model in self.ml_models.items():
score = model.predict(ml_features)
risk_scores[model_name] = score
# 3. 图分析评估
if self.requires_graph_analysis(transaction):
network_score = self.graph_analyzer.analyze_network_risk(
transaction.customer_id,
transaction.counterparty_id,
historical_patterns
)
risk_scores["network_based"] = network_score
# 4. 集成决策
final_risk_score = self.ensemble_risk_scores(risk_scores)
decision = self.make_decision(final_risk_score, transaction.amount)
# 5. 可解释性报告
explanation = self.decision_explain.generate_explanation({
"scores": risk_scores,
"final_score": final_risk_score,
"decision": decision,
"key_factors": self.identify_key_factors(risk_scores)
})
return RiskAssessment(
transaction_id=transaction.id,
risk_score=final_risk_score,
decision=decision,
confidence=self.calculate_confidence(risk_scores),
explanation=explanation,
required_actions=self.determine_actions(decision, final_risk_score)
)
def ensemble_risk_scores(self, scores):
"""集成多个风险分数"""
# 加权平均(权重可动态调整)
weights = self.get_dynamic_weights(scores)
weighted_sum = 0
total_weight = 0
for model, score in scores.items():
weight = weights.get(model, 1.0)
weighted_sum += score * weight
total_weight += weight
# 应用校准
calibrated_score = self.calibrate_score(weighted_sum / total_weight)
return calibrated_score第五章:未来趋势与战略建议
5.1 大数据技术的未来趋势
-
AI原生化:大数据系统将深度集成机器学习能力
-
智能数据发现与自动标注
-
自适应查询优化
-
预测性数据治理
-
-
实时化普及:批处理与流处理的界限彻底消失
-
统一的计算框架
-
亚秒级决策支持
-
持续学习系统
-
-
数据网格成熟:组织变革推动架构演进
-
企业内部数据市场
-
数据产品经济体系
-
联邦治理标准化
-
-
绿色计算:可持续发展成为核心考量
-
碳感知调度
-
能效优化的硬件
-
可持续的数据中心
-
5.2 战略实施建议
图表
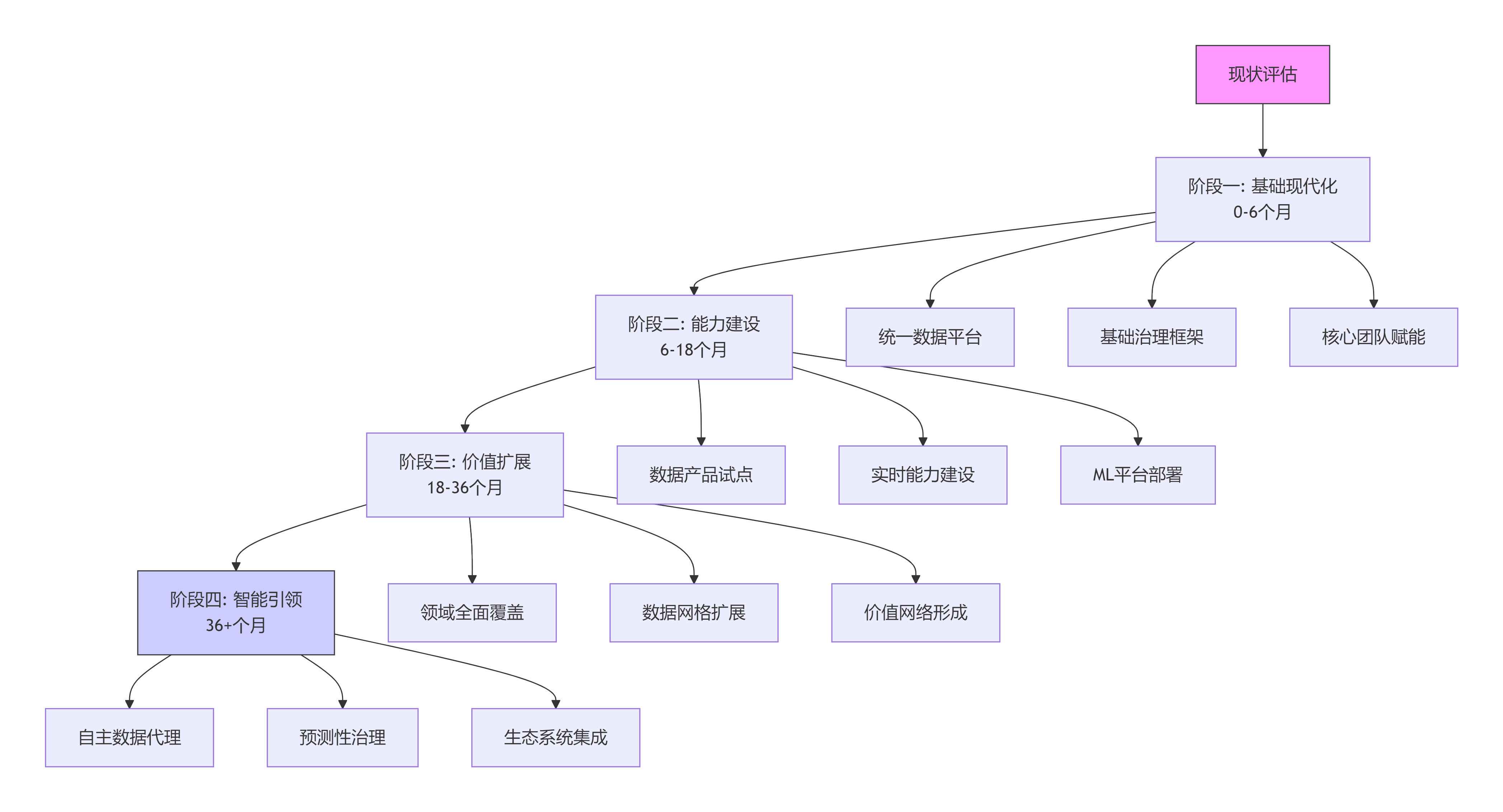
代码
下载
全屏
现状评估
阶段一: 基础现代化
0-6个月
阶段二: 能力建设
6-18个月
阶段三: 价值扩展
18-36个月
阶段四: 智能引领
36+个月
统一数据平台
基础治理框架
核心团队赋能
数据产品试点
实时能力建设
ML平台部署
领域全面覆盖
数据网格扩展
价值网络形成
自主数据代理
预测性治理
生态系统集成
5.3 关键成功因素
-
业务对齐优先:从业务价值出发,而非技术先进性
-
组织变革同步:技术架构与组织架构协同演进
-
渐进式演进:小步快跑,持续交付价值
-
数据文化培育:让数据驱动成为组织DNA
-
生态思维:构建而非购买,整合而非孤立
结语:从技术执行到价值创造
大数据技术的发展正经历着从技术执行 到价值创造的根本性转变。成功不再属于那些拥有最庞大Hadoop集群的组织,而是属于那些能够最有效地将数据转化为洞察、将洞察转化为行动、将行动转化为价值的组织。
未来的数据领导者需要具备三重能力:技术深度 以理解系统原理,业务广度 以识别价值机会,组织智慧 以推动变革落地。数据系统不再只是IT基础设施,而是企业的数字神经系统------感知环境变化、处理复杂信息、协调组织响应。
当我们回望这场持续数十年的大数据革命时,或许会发现真正的转折点并非某项技术的突破,而是我们认知的转变:从"如何存储和处理更多数据"到"如何让数据创造更多价值"。
数据本身不是终点,价值才是。架构本身不是目的,赋能才是。技术本身不是答案,洞见才是。
现在,是时候重新思考你的大数据战略了------不是基于过去的技术限制,而是面向未来的价值可能。