文章目录
-
- [LangSmith 介绍](#LangSmith 介绍)
- LangSmith使用
- [Callback 使用](#Callback 使用)
-
- 什么是Callback机制
- [CallBack 使用场景](#CallBack 使用场景)
- 使用Callback机制
LangSmith 介绍
什么是LangSmith
LangSmith 是由 LangChain 团队开发的一款 用于调试、测试、评估和监控 LLM 应用的开发者工具平台,适用于构建基于大型语言模型(LLMs)的复杂应用。它特别适合在使用 LangChain、OpenAI Function calling、Agent、RAG(检索增强生成)等场景中进行调试与监控。它是一个 SaaS 服务平台,由 LangChain 官方运营,服务托管在云端。使用 LangSmith 需要注册账号,并通过云端 API Key 接入。
监控功能介绍
- Trace(调用追踪):记录和可视化每一次 LLM 调用链条(Trace Tree)。记录模型调用的输入、输出、使用的模型名称、参数(如
temperature、top_p 等)、token 使用情况。 - Telemetry(性能指标监控):统计调用性能指标,便于优化性能和成本。例如:平均响应时间、总调用次数、成功/失败次数、Token
使用量(input/output 分别统计) - Dataset / Run Comparison(运行比对与评估):用于自动化评估 LLM 系统的准确性和一致性,用于监控模型版本变更或prompt 改动后的影响
- Tagging & Metadata(标签与元数据):支持给每次调用打标签,比如:哪个用户触发的(user_id)、哪个环境(prod/dev)、哪个版本(v1.2.0),可用于后续查询和聚合分析,便于精细监控和定位问题
- 错误监控(Error Tracing):自动记录错误类型、异常堆栈,支持错误分组分析(如调用某个 retriever的失败率较高),可集成告警系统(Slack, Webhook 等)
使用场景总结
| 场景 | LangSmith 帮助点 |
|---|---|
| Chain 调试 | 可视化各步骤输入输出、耗时、调用顺序 |
| RAG 应用监控 | 监控 Retriever/LLM 效果、错误情况、响应质量 |
| Prompt 优化与 A/B Test | 比较不同 prompt 的性能与效果 |
| 模型版本对比 | 运行历史版本对比评估 |
| 用户行为分析 | 利用 tagging 分析调用频率、失败率、使用行为 |
LangSmith使用
创建项目获取 API Key
登录https://smith.langchain.com/,并创建账号。
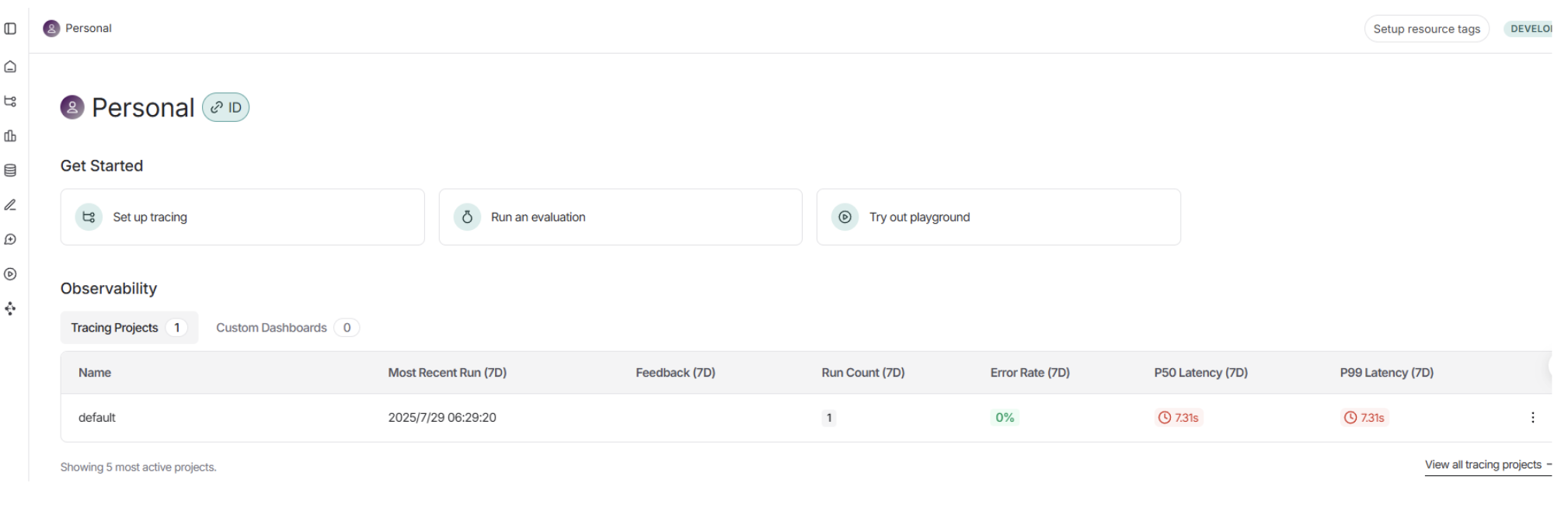
系统中默认存在一个项目,我们新建一个项目。
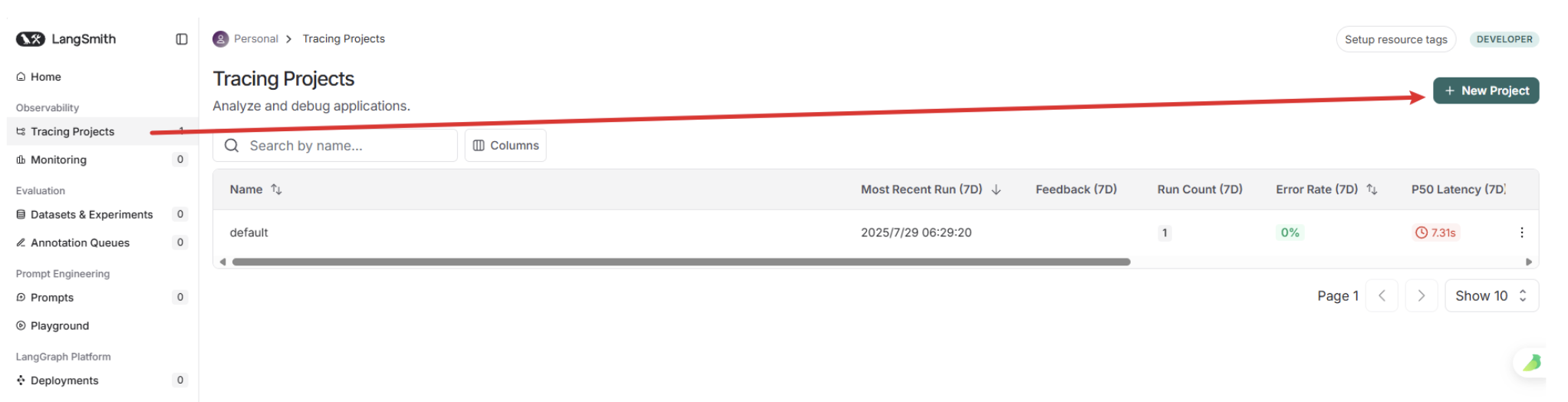
LangSmith支持LangChain项目和非LangChain项目,并且分别提供了将LangSmith接入到应用的方法,点击Generate API Key,生成API Key。
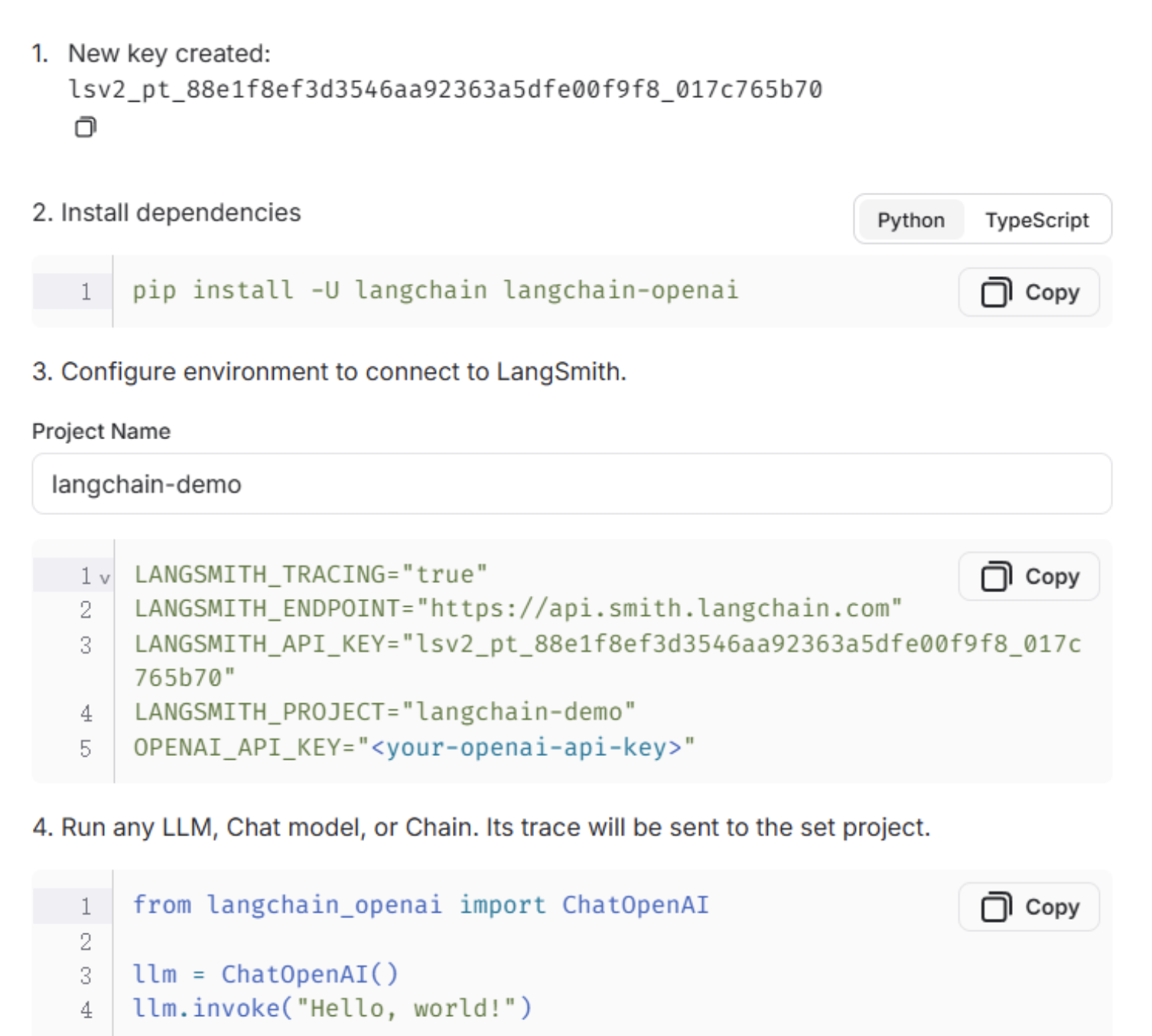
复制环境变量配置
复制上方的配置,放到项目的.env 文件中
python
LANGSMITH_TRACING="true"
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="XXXXXXXXXXXXXXXXXXX"
LANGSMITH_PROJECT="langchain-demo"使用验证
通过一个最简单的示例进行测试:
python
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama.llms import ChatOllama
# 读取env配置
dotenv.load_dotenv()
# 构建 prompt 模板
template = """
使用中文回答下面的问题:
问题: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:8b", reasoning=False)
# 创建 Chain
chain = prompt | model
# 打印结果
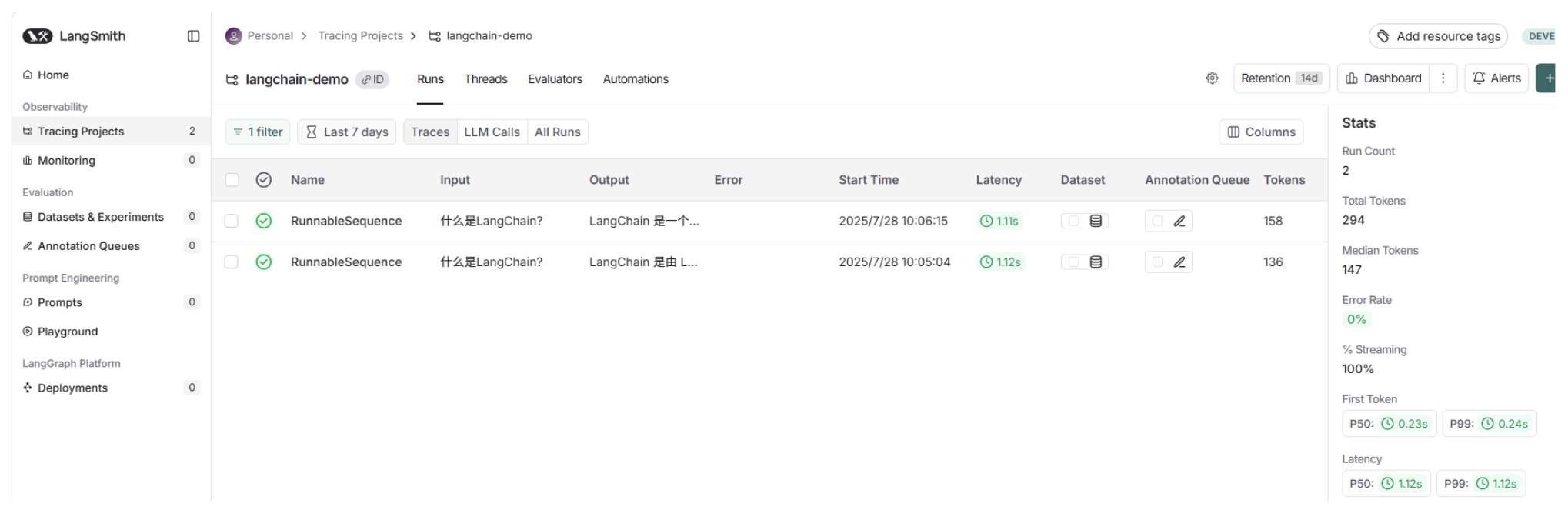
print(chain.invoke({"question": "什么是LangChain?"}))执行完成之后,在Tracing Projects页面就可以看到langchain-demo项目被成功创建
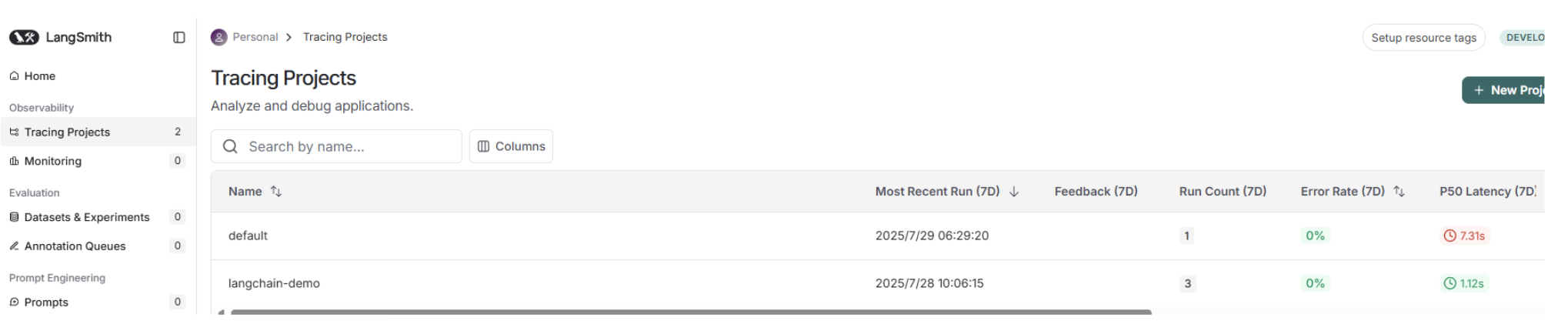
点击进入项目,就可以看到刚刚那一次的调用过程,包括输入、输出、发起时间、总耗时等信息
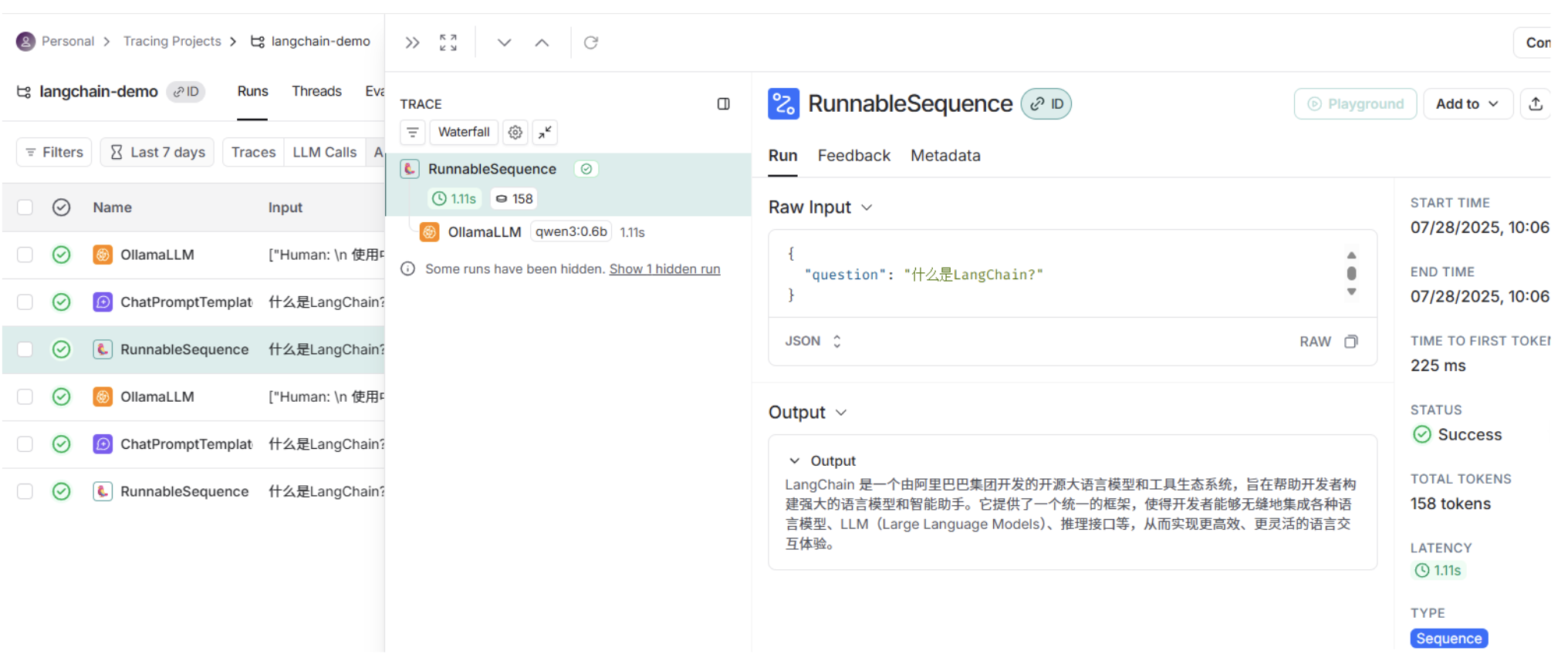
点击All Runs可以查看各个组件的执行过程,包括Prompt生成、LLM响应、输出解析器处理等各环节的详细执行信息
Callback 使用
什么是Callback机制
除了使用LangSmith之外,LangChain还提供了一种回调机制,可以在 LLM 应用程序的各种阶段执行特定的钩子方法。通过这些钩子方法,我们可以轻松地进行日志输出、异常监控等任务,Callback支持以下事件的钩子方法:
| Event 事件 | 触发时机 | 关联钩子方法 |
|---|---|---|
| Chat model start | 聊天模型启动 | on_chat_model_start |
| LLM start LLM | LLM模型启动 | on_llm_start |
| LLM new token LLM | LLM生成新的 token 时触发,仅在启用流式输出(streaming)模式下生效 | on_llm_new_token |
| LLM ends | LLM 或聊天模型完成运行时 | on_llm_end |
| LLM errors | LLM 或聊天模型出错 | on_llm_error |
| Chain start | 链开始执行(实际上就是每个可运行组件开始执行) | on_chain_start |
| Chain end | 链结束执行(实际上就是每个可运行组件结束执行) | on_chain_end |
| Chain error | 链执行出错 | on_chain_error |
| Tool start | 工具开始执行 | on_tool_start |
| Tool end | 工具结束执行 | on_tool_end |
| Tool error | 工具执行出错 | on_tool_error |
| Agent action | agent开始执行 | on_agent_action |
| Agent finish | agent结束执行 | on_agent_finish |
| Retriever start | 检索器开始执行 | on_retriever_start |
| Retriever end | 检索器结束执行 | on_retriever_end |
| Retriever error | 检索器执行出错 | on_retriever_error |
| Text | 每次模型输出一段文本时,就会调用这个方法 | on_text |
| Retry | 当某个组件(比如 LLM 调用或链)发生失败并触发重试机制时 | on_retry |
CallBack 使用场景
在实际开发中,LangSmith 更适合在开发调试阶段使用,而在生产环境下,出于数据隐私和安全考量,我们通常不会将敏感数据上传到LangSmith平台。这时,Callback 机制就能将执行信息接入到本地或自定义的监控系统,实现同样的可观测性。
使用Callback机制
使用Callback机制,需要使用到Callback handler,即回调处理器,那些各个生命周期的钩子方法,就定义在回调处理器中,回调处理器支持同步和异步,同步回调处理器继承BaseCallbackHandler类,异步回调处理器继承AsyncCallbackHandler类。
BaseCallbackHandler类可以重写的钩子方法 如下:
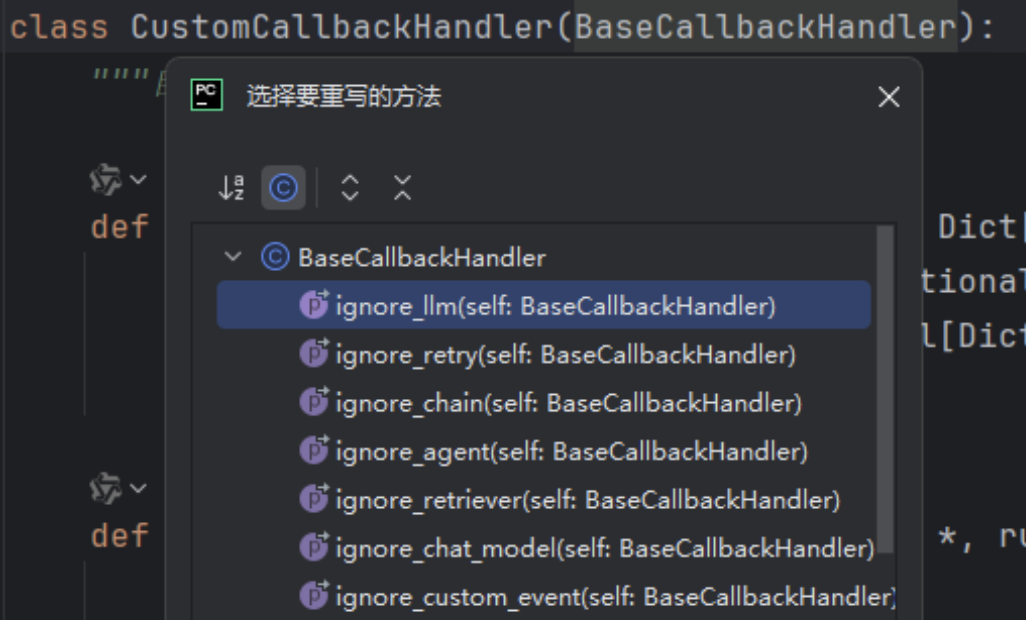
那么,如何使自定义的CallbackHandler生效呢?可以在调用可执行组件的invoke()方法中,除了传递输入参数外,再传递config配置参数,config配置参数可以传递各种配置信息,其中,callbacks属性用来传递回调处理器,callbacks属性接收一个数组,数组里面包含自定义的CallbackHandler对象,代码示例如下:
python
from uuid import UUID
import dotenv
from typing import Dict, Any, Optional, List
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain_core.outputs import LLMResult
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableConfig
from langchain_ollama.llms import ChatOllama
class CustomCallbackHandler(BaseCallbackHandler):
"""自定义回调处理类"""
def on_chat_model_start(self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], *, run_id: UUID,
parent_run_id: Optional[UUID] = None, tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None, **kwargs: Any) -> Any:
print("======聊天模型结束执行======")
def on_llm_end(self, response: LLMResult, *, run_id: UUID, parent_run_id: Optional[UUID] = None,
**kwargs: Any) -> Any:
print("======聊天模型结束执行======")
def on_chain_start(self, serialized: Dict[str, Any], inputs: Dict[str, Any], *, run_id: UUID,
parent_run_id: Optional[UUID] = None, tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None, **kwargs: Any) -> Any:
print(f"开始执行当前组件{kwargs['name']},run_id: {run_id}, 入参:{inputs}")
def on_chain_end(self, outputs: Dict[str, Any], *, run_id: UUID, parent_run_id: Optional[UUID] = None,
**kwargs: Any) -> Any:
print(f"结束执行当前组件,run_id: {run_id}, 执行结果:{outputs}, {kwargs}")
# 读取env配置
dotenv.load_dotenv()
# 构建 prompt 模板
template = """
使用中文回答下面的问题:
问题: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:0.6b", reasoning=False)
# 创建 Chain
chain = prompt | model
# 设置回调处理类
config = RunnableConfig(callbacks=[CustomCallbackHandler()])
# 打印结果
chain.invoke({"question": "什么是LangChain?"}, config)在示例中,创建了一个CustomCallbackHandler类,继承了BaseCallbackHandler,分别重写了on_chain_start、on_llm_end、on_chain_start、on_chain_end,在聊天模型开始执行和结束执行进行了信息输出,在on_chain_start、on_chain_end打印了当前链执行的组件名称、运行id、输入参数、输出结果。
执行结果如下,通过输出结果可以清晰地看到每一个组件的输入和输出结果,以及LLM何时开始执行、结束执行,若需监控异常情况,可重写 on_chain_error 方法。
python
开始执行当前组件RunnableSequence,run_id: e3ff2574-b6a4-4ad5-a06a-fa8495ddc0ad, 入参:{'question': '什么是LangChain?'}
开始执行当前组件ChatPromptTemplate,run_id: 3dabdc63-c815-4d93-9830-634b0784383d, 入参:{'question': '什么是LangChain?'}
结束执行当前组件,run_id: 3dabdc63-c815-4d93-9830-634b0784383d, 执行结果:messages=[HumanMessage(content='\n 使用中文回答下面的问题:\n 问题: 什么是LangChain?\n ', additional_kwargs={}, response_metadata={})], {'tags': ['seq:step:1']}
======聊天模型结束执行======
结束执行当前组件,run_id: e3ff2574-b6a4-4ad5-a06a-fa8495ddc0ad, 执行结果:LangChain 是由 LangChain 公司开发的一个开源平台,用于构建和管理大型语言模型的应用程序。它提供了一个易于使用和可扩展的框架,帮助开发者实现各种自动化任务,包括但不限于数据处理、知识管理、任务执行等。LangChain 结合了多种语言模型和人工智能技术,使用户能够快速创建和管理复杂的应用程序,从而提高开发效率和用户体验。, {'tags': []}