Keepalived 状态检测核心机制简述
1.简述 Keepalived 状态检测的核心机制,至少包含 2 个关键检测对象。
Keepalived 的状态检测核心机制是通过分层检测确保主节点及服务的可用性,当检测到异常时触发主备切换,主要依据两个关键的检测对象节点和服务
节点存活状态:主节点周期性发送 VRRP 通告报文(默认 1 秒一次),备节点监听该报文。若备节点在超时时间(默认 3 秒)内未收到通告,判定主节点网络或节点本身故障,触发备节点升级为主节点。
关键服务状态 :通过配置vrrp_script脚本,定期检测主节点上的核心服务(如 Nginx、LVS、数据库等)是否正常运行(如检查进程是否存在、端口是否监听、接口是否通等)。若脚本返回异常结果,Keepalived 会主动降低主节点优先级,触发备节点接管。
Keepalived 相关核心面试题与解答
2.列举 2 个与 Keepalived 相关的常见面试问题,并给出简洁答案(如 "Keepalived 的 VIP 是什么?作用是?")。
问题:Keepalived 的主要功能是什么?
答案:主要用于实现服务器高可用(HA),通过 VRRP 协议管理虚拟 IP(VIP)实现主备节点自动切换,避免单点故障;同时可结合 LVS 实现负载均衡的高可用。
问题:Keepalived 中 VRRP 协议的作用是什么?
答案:VRRP(虚拟路由冗余协议)用于在多节点间选举主节点,主节点承载服务并持有 VIP,备节点监听主节点状态;当主节点故障时,备节点自动接管 VIP 和服务,保障业务连续性。
问题:Keepalived 主从节点切换的触发条件有哪些?
答案:① 主节点服务器宕机或网络中断(无法发送 VRRP 通告);② 主节点上的关键服务(如 LVS、Nginx)故障(通过脚本检测,非 VRRP 原生功能);③ 手动强制切换(如执行 systemctl stop keepalived)。
Keepalived 主从部署与 VIP 漂移验证
3.在两台 Linux 主机上部署 Keepalived,配置主从节点,实现 VIP 的自动漂移(当主节点宕机时,从节点接管 VIP)。验证状态检测功能:手动停止主节点的 Keepalived 服务,观察从节点是否成功切换并接管服务。
实践:
现在两台主机上下载keepalived服务


下载nginx并设置相关页面




定制keepalived的配置
首先定制网卡
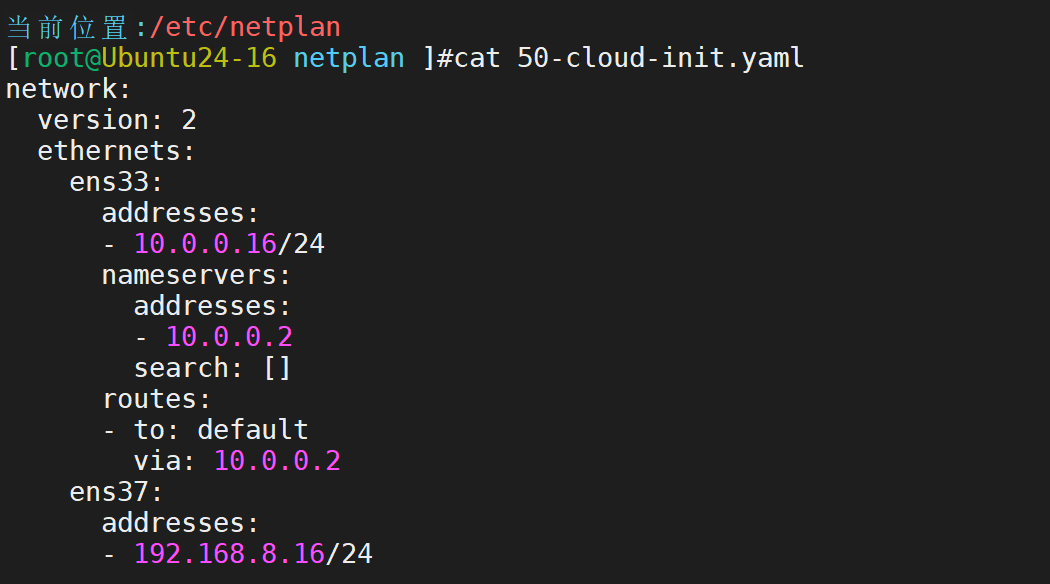
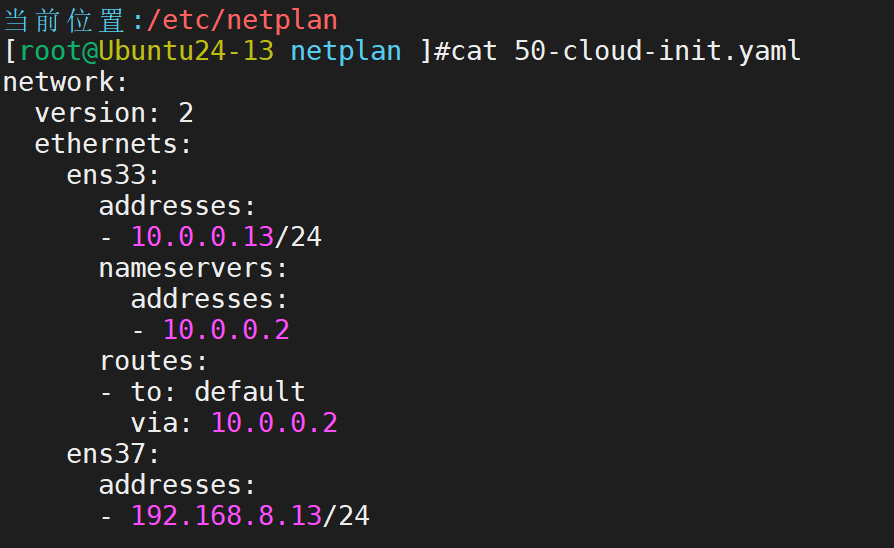
配置好后通过netplan apply命令应用配置
然后配置keepalived相关配置
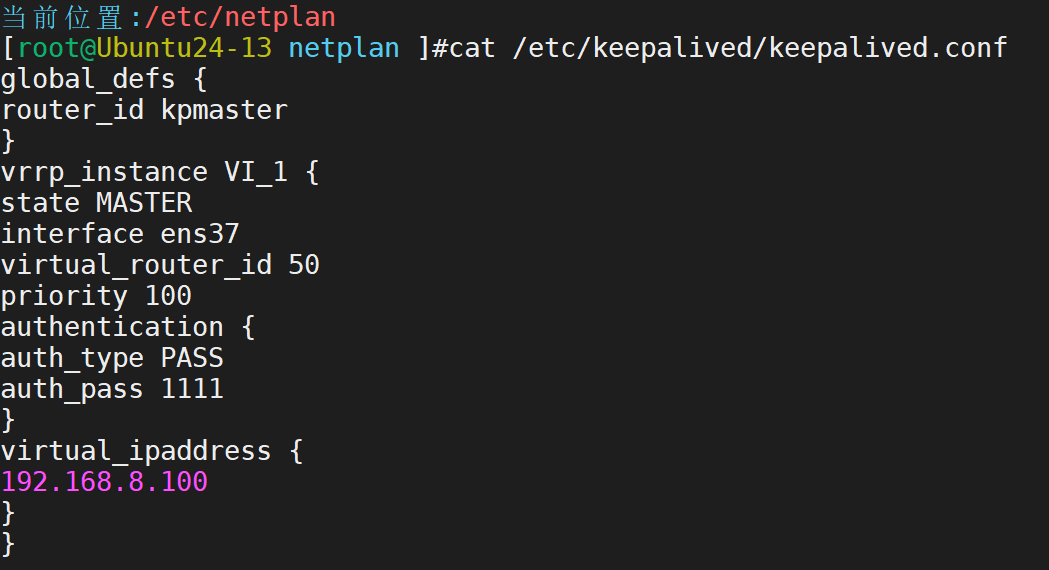
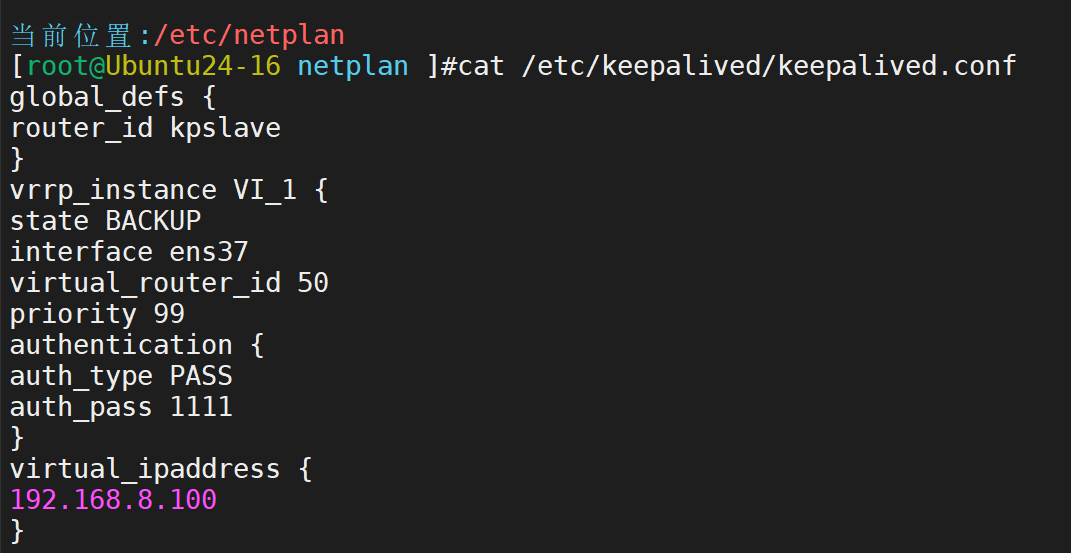
启动服务后,查看情况
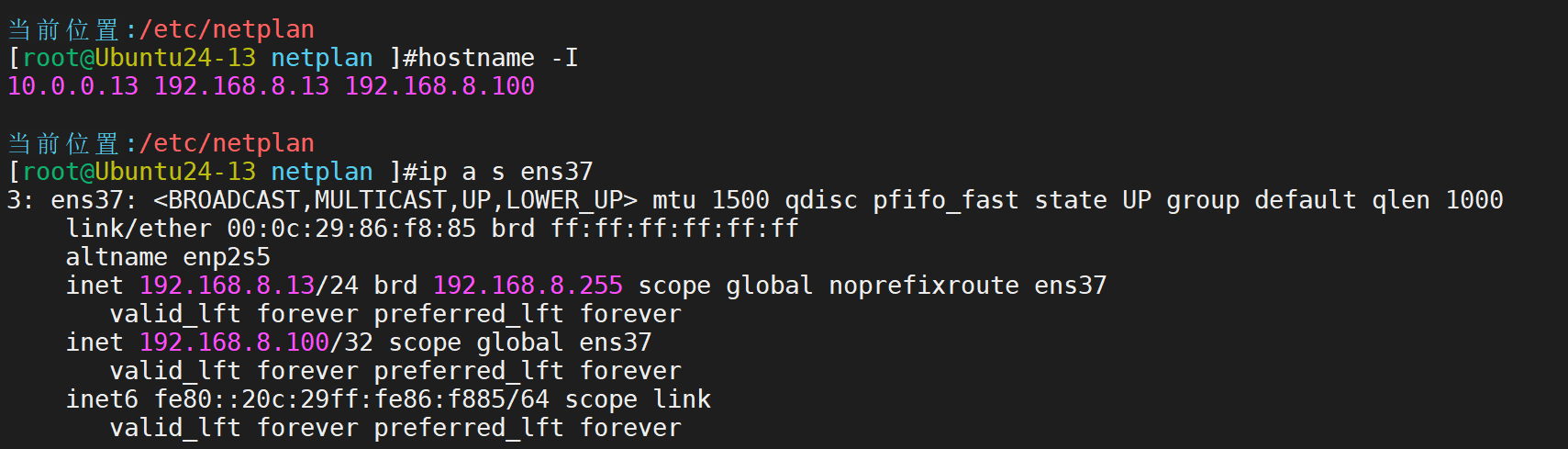
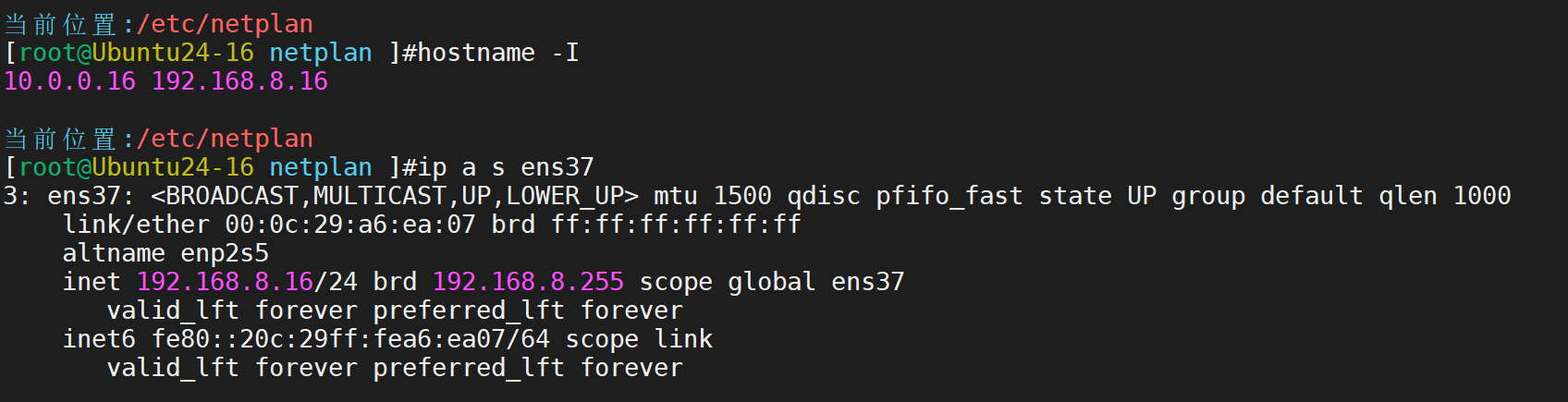
此时192.168.8.13主机是master,16主机是slave。所以VIP在13哪里·
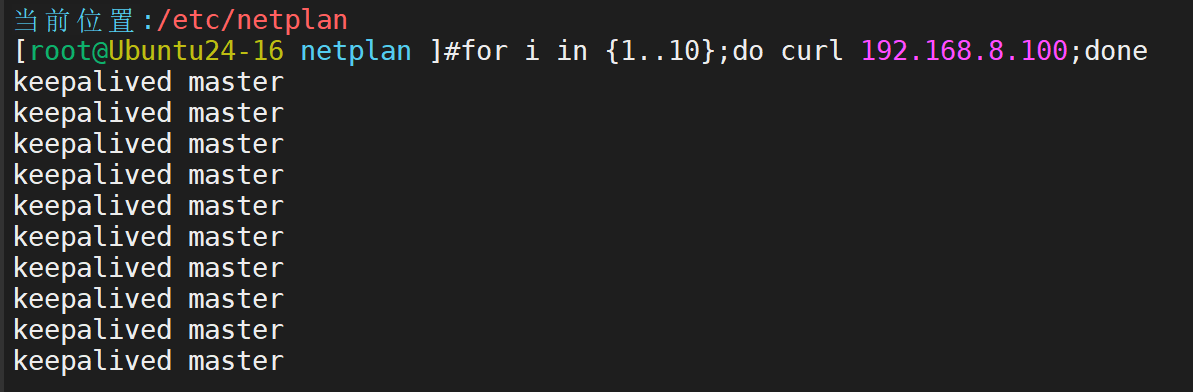
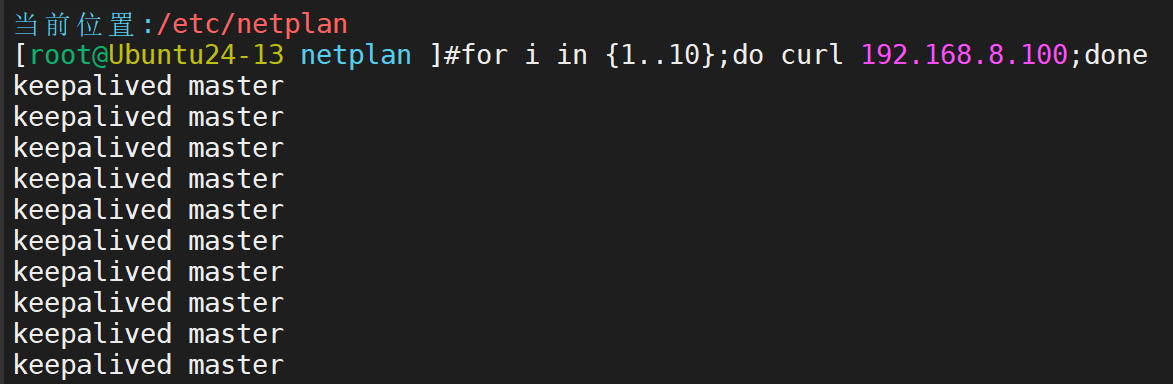
二者pingVIP均为master承接流量。
接下来手动关闭master,来查看漂移状态
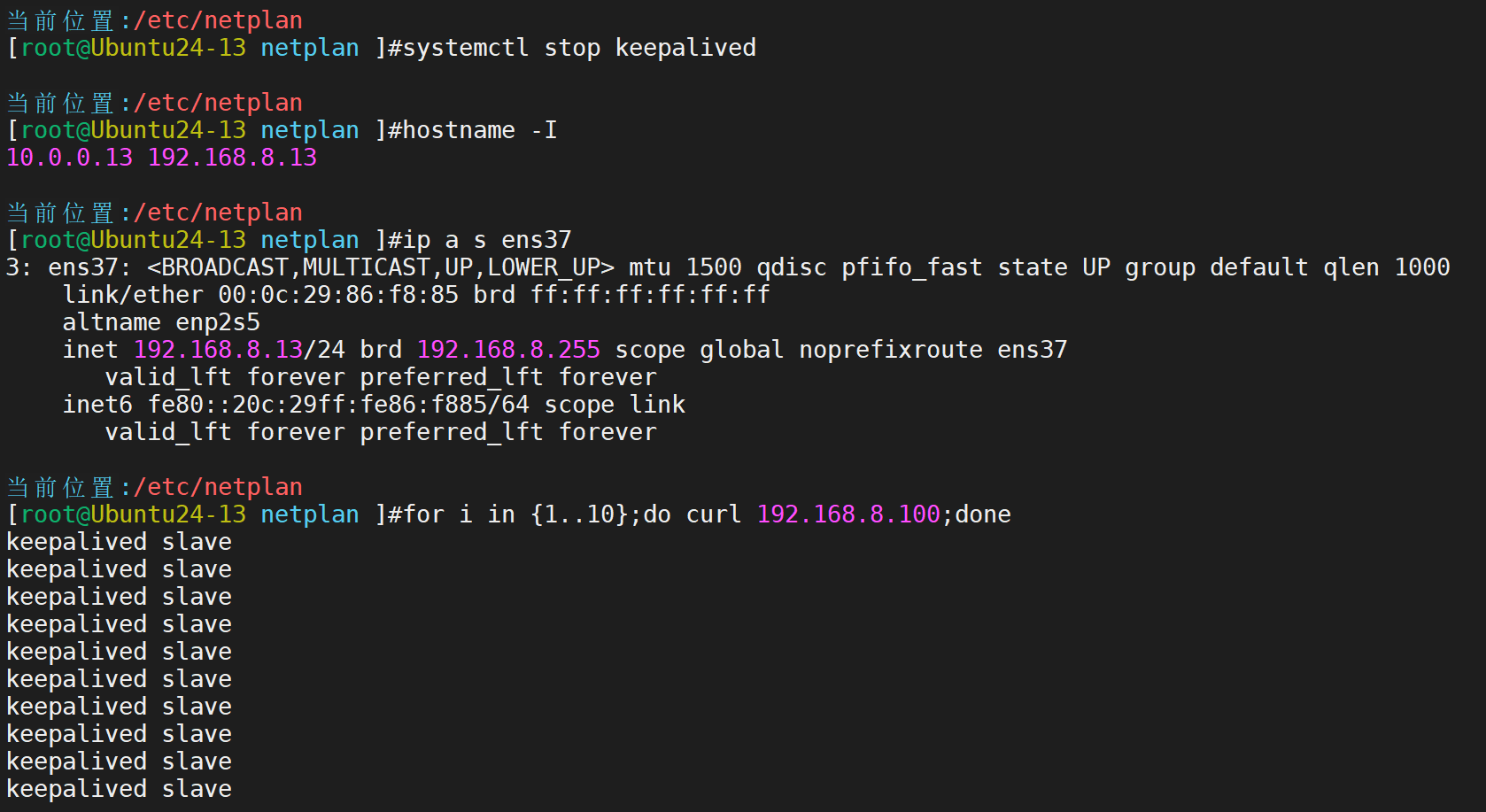
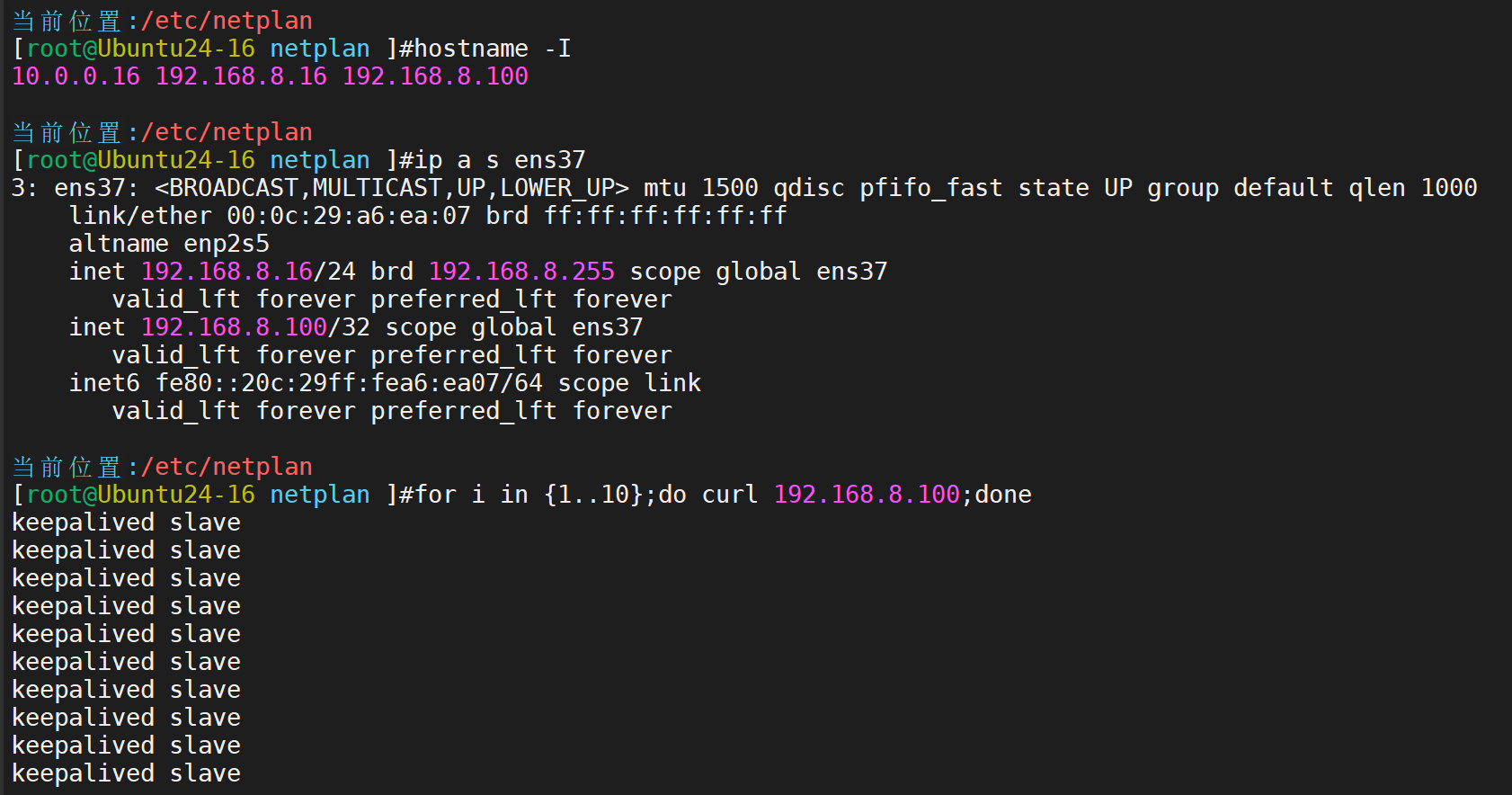
效果如上,展示成功
Ansible 核心工作原理三句话概括
4.用 3 句话概括 Ansible 的工作原理,需包含 "控制节点""被管理节点""通信方式" 3 个核心要素。
- 控制节点是安装 Ansible 的主机,负责编写和存储任务流程,定义对被管理节点的操作逻辑。
- 控制节点与被管理节点通过 SSH 协议建立通信,将任务指令传输到被管理节点。
- 被管理节点接收并执行指令,完成后将结果返回给控制节点,实现集中化的自动化管理。
Ansible 主机清单的作用与分组管理解析
5.解释 Ansible 中 "主机清单" 的作用,以及如何在清单中分组管理不同主机。
主机清单(Inventory)的作用
主机清单是 Ansible 识别 "被管理节点" 的配置文件,用于定义需要管理的主机及相关连接信息,是 Ansible 执行任务时定位目标节点的 "地址簿",确保控制节点知道对哪些主机执行操作
Ansible Playbook 与模块命令的区别及优势
6.简述 Ansible Playbook 与单个模块命令的区别,说明 Playbook 的核心优势。
Ansible Playbook 与单个模块命令的区别
- 结构与形式 :单个模块命令是通过
ansible命令直接调用单个模块(如ping、copy)的单行指令(如ansible web -m ping),仅能执行单一任务;Playbook 是基于 YAML 格式的文件,可包含多个任务、变量、条件判断等,是 "任务集合的脚本化定义"。 - 功能复杂度:单个模块命令仅支持简单的单步操作,无法实现流程控制(如循环、条件判断);Playbook 可串联多个任务,支持变量、模板、角色等,能编排复杂的自动化流程如 "安装软件→配置文件→启动服务" 的完整部署。
Playbook 的核心优势
- 可复用与可追溯:Playbook 以文件形式保存,可重复执行、版本化管理(如纳入 Git),避免重复编写单条命令,适合团队协作。
- 支持复杂流程编排 :通过
tasks串联多步骤操作,结合when(条件)、loop(循环)等语法,可应对 "按环境差异部署""批量处理动态数据" 等复杂场景。 - 幂等性保障:Playbook 中任务默认支持幂等性(多次执行结果一致),避免重复操作导致的资源浪费或错误(如重复安装软件不会重复执行)。
- 可读性与可维护性:YAML 格式清晰易懂,配合注释可直观体现自动化逻辑,便于后期修改和扩展。
Ansible 全流程实践:从环境部署到 Role 应用
7.部署 Ansible 环境:
完成 1 台控制节点、2 台被管理节点的环境配置,确保控制节点能免密登录被管理节点。
基础模块实践:使用ping模块测试主机连通性,用yum模块在被管理节点安装nginx,用service模块启动nginx服务。
Playbook 实践:编写 1 个 Playbook,实现 "在被管理节点安装并启动mysql服务" 的自动化操作。
Role 实践:创建 1 个用于部署tomcat的 Role,包含配置文件、启动脚本等,并用它完成 1 台主机的tomcat部署。
实践
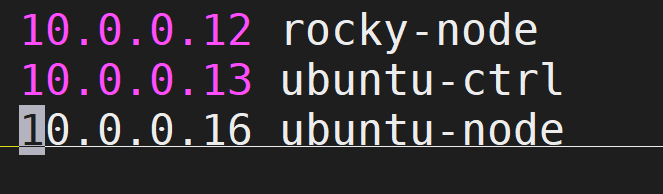
环境准备(所有节点)
vim /etc/hosts
添加内容
创建专用用户
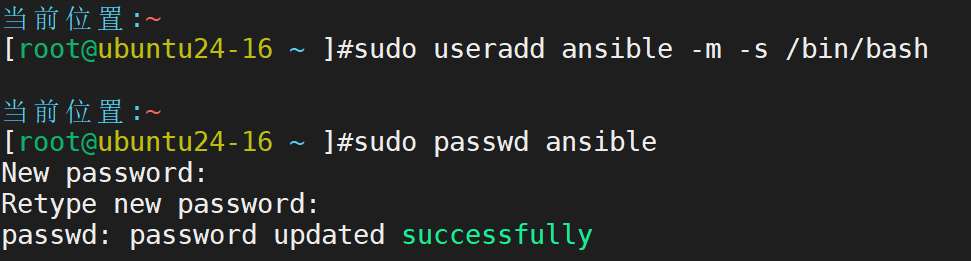
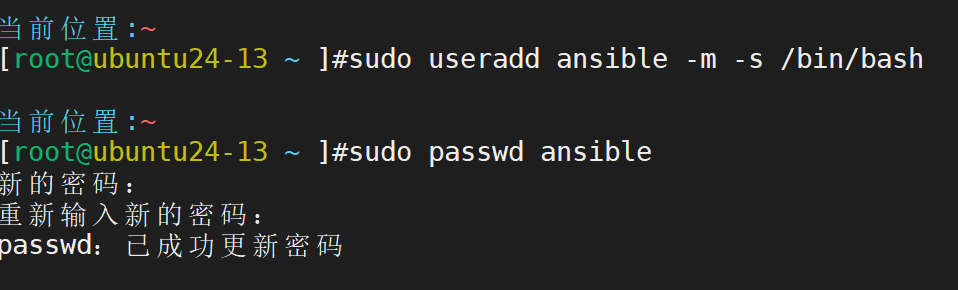
配置控制节点
生成 SSH 密钥
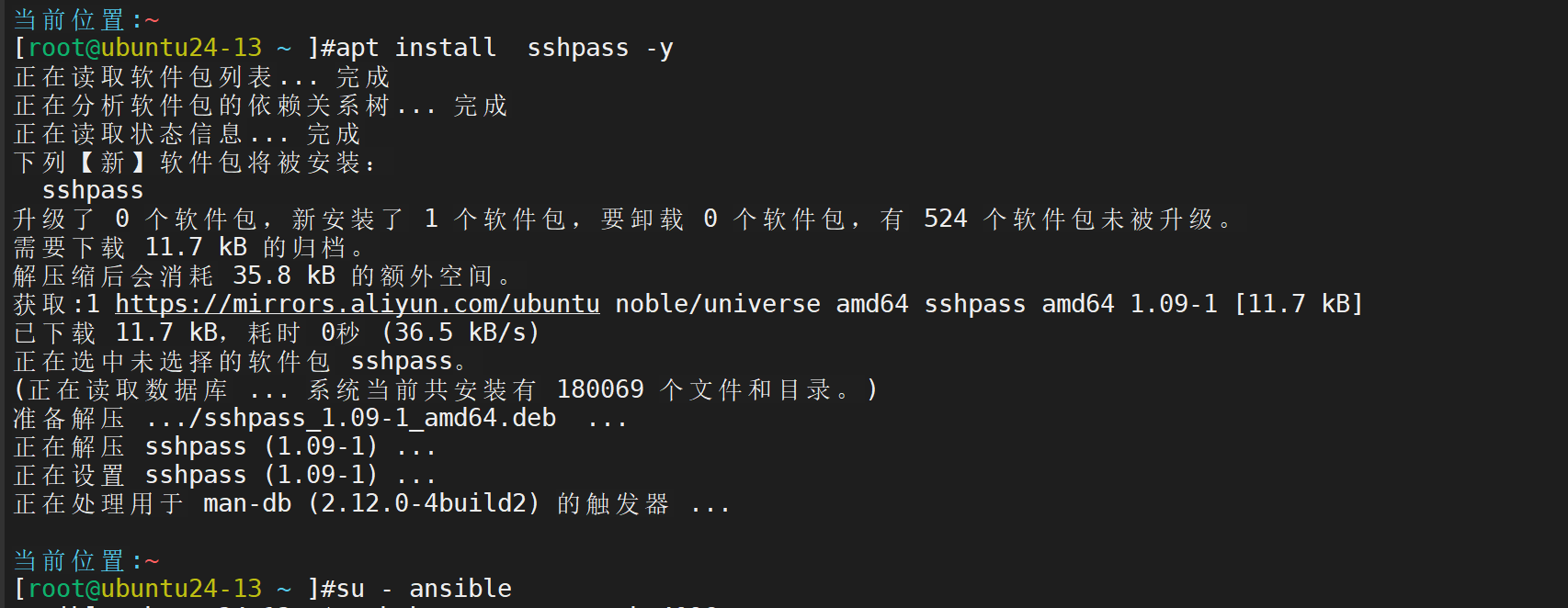

全部回车
配置免密登录被管理节点

测试 SSH 连接

创建 Ansible 清单
mkdir ~/ansible-project && cd ~/ansible-project
vim inventory.ini
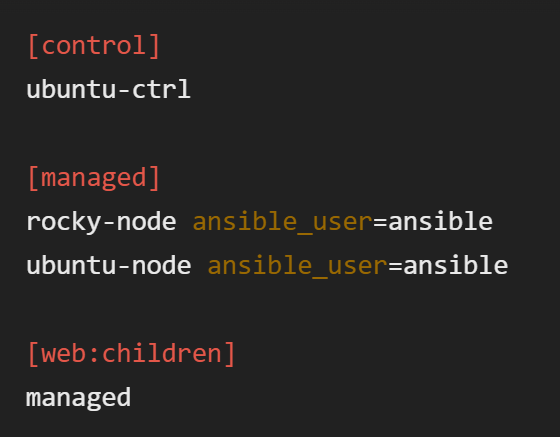
基础模块实践
测试主机连通性
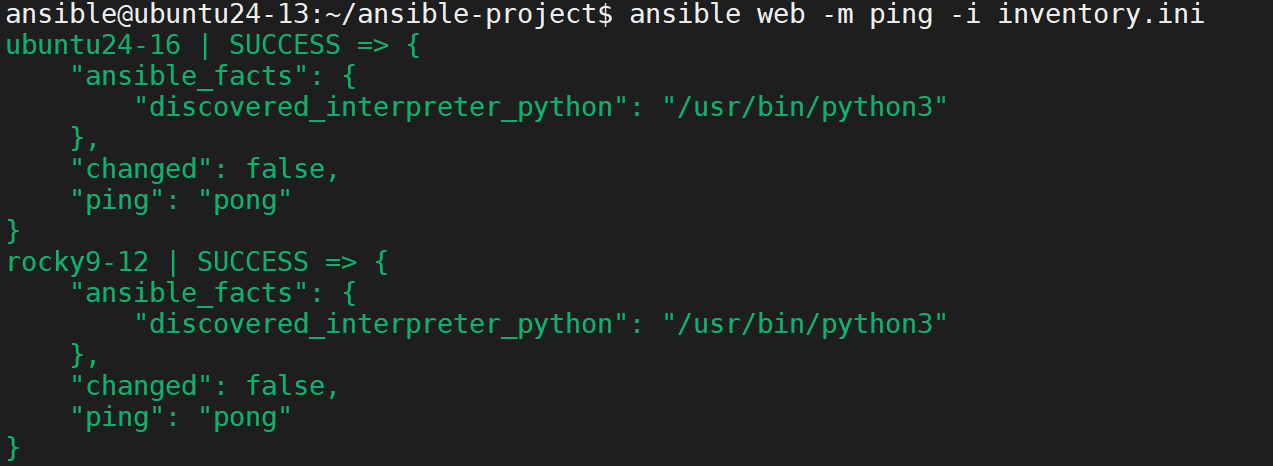
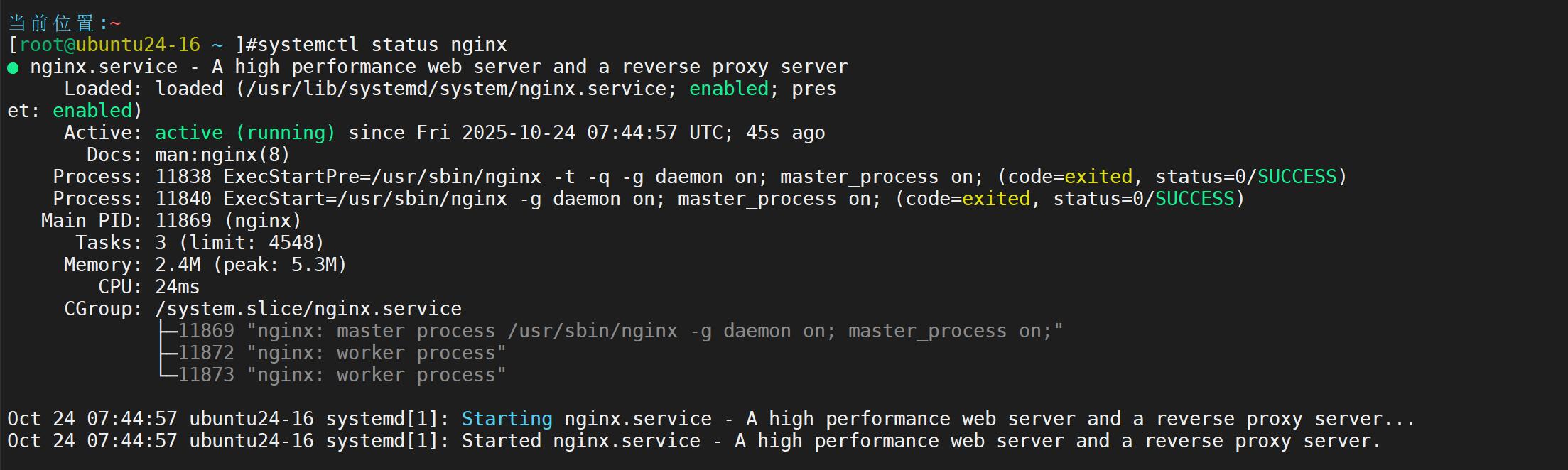
安装 启动Nginx

验证
Playbook 实践(安装 MySQL)
创建 Playbook
vim install_mysql.yml
- name: Install and configure MySQL
hosts: managed
become: yes
vars:
mysql_root_password: "SecurePass123!" # 实际使用时改为强密码
tasks:
- name: Install MySQL (RockyLinux)
yum:
name: mysql-server
state: present
when: ansible_distribution == "Rocky"
- name: Install MySQL (Ubuntu)
apt:
name: mysql-server
state: present
when: ansible_distribution == "Ubuntu"
- name: Start and enable MySQL service
service:
name: mysqld
state: started
enabled: yes
when: ansible_distribution == "Rocky"
- name: Start and enable MySQL service (Ubuntu)
service:
name: mysql
state: started
enabled: yes
when: ansible_distribution == "Ubuntu"
- name: Set root password (初次安装后执行)
shell: |
mysql -e "ALTER USER 'root'@'localhost' IDENTIFIED BY '{{ mysql_root_password }}';"
args:
executable: /bin/bash
ignore_errors: yes # 避免未初始化报错
执行 Playbook

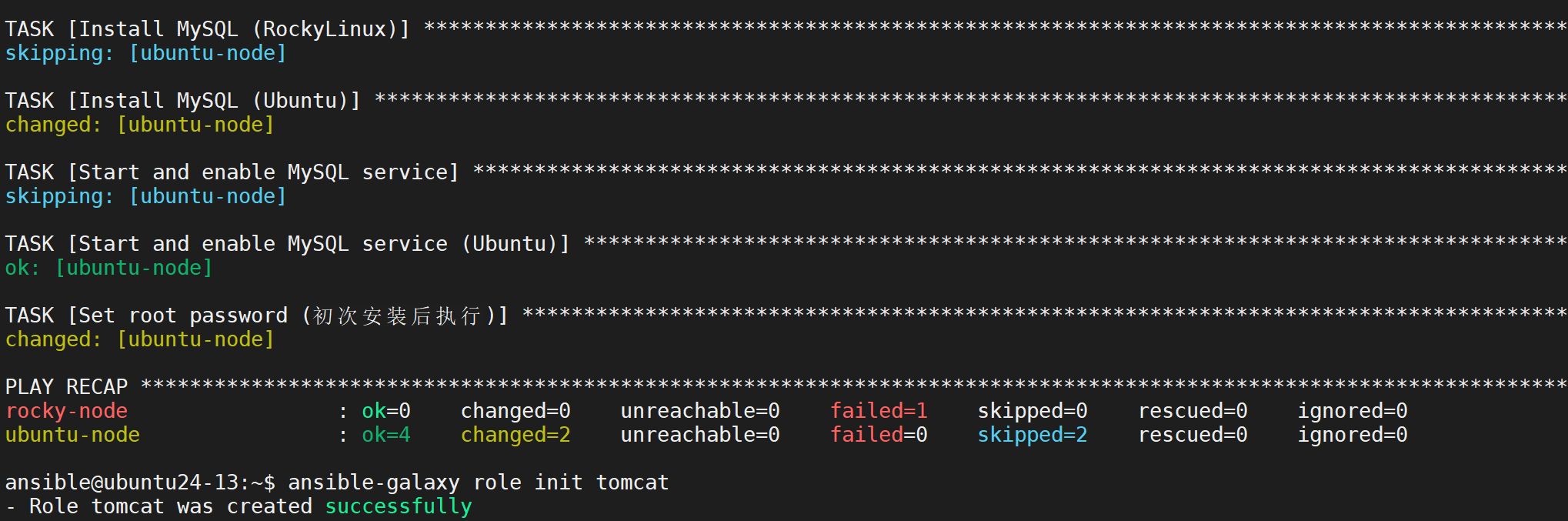
Role 实践(部署 Tomcat)
创建并查看目录结构
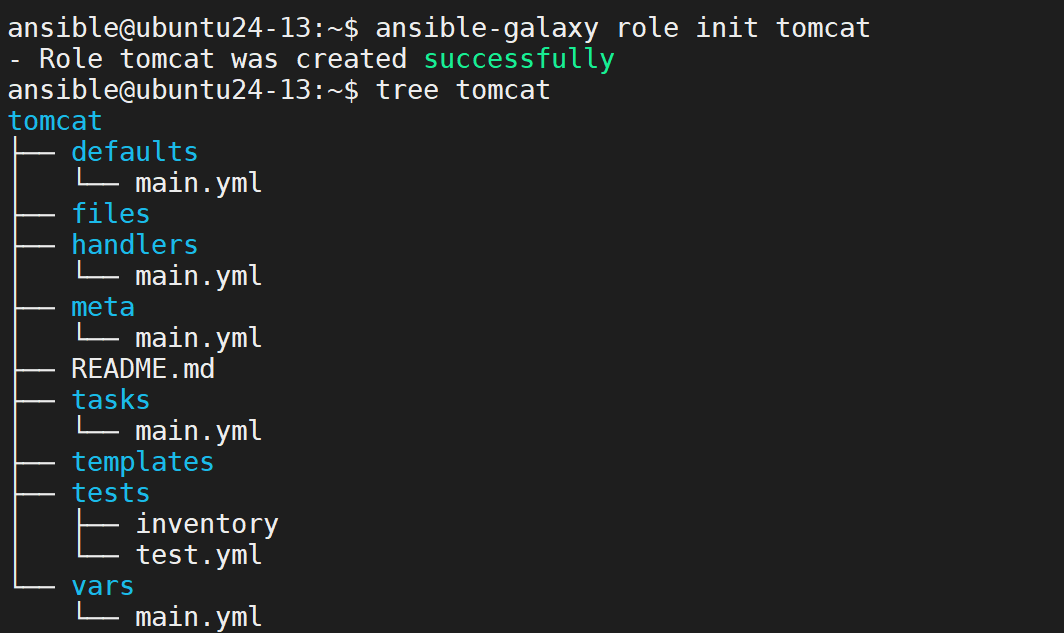
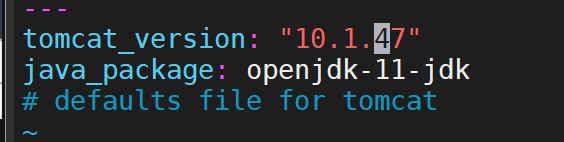
定义变量 tomcat/defaults/main.yml
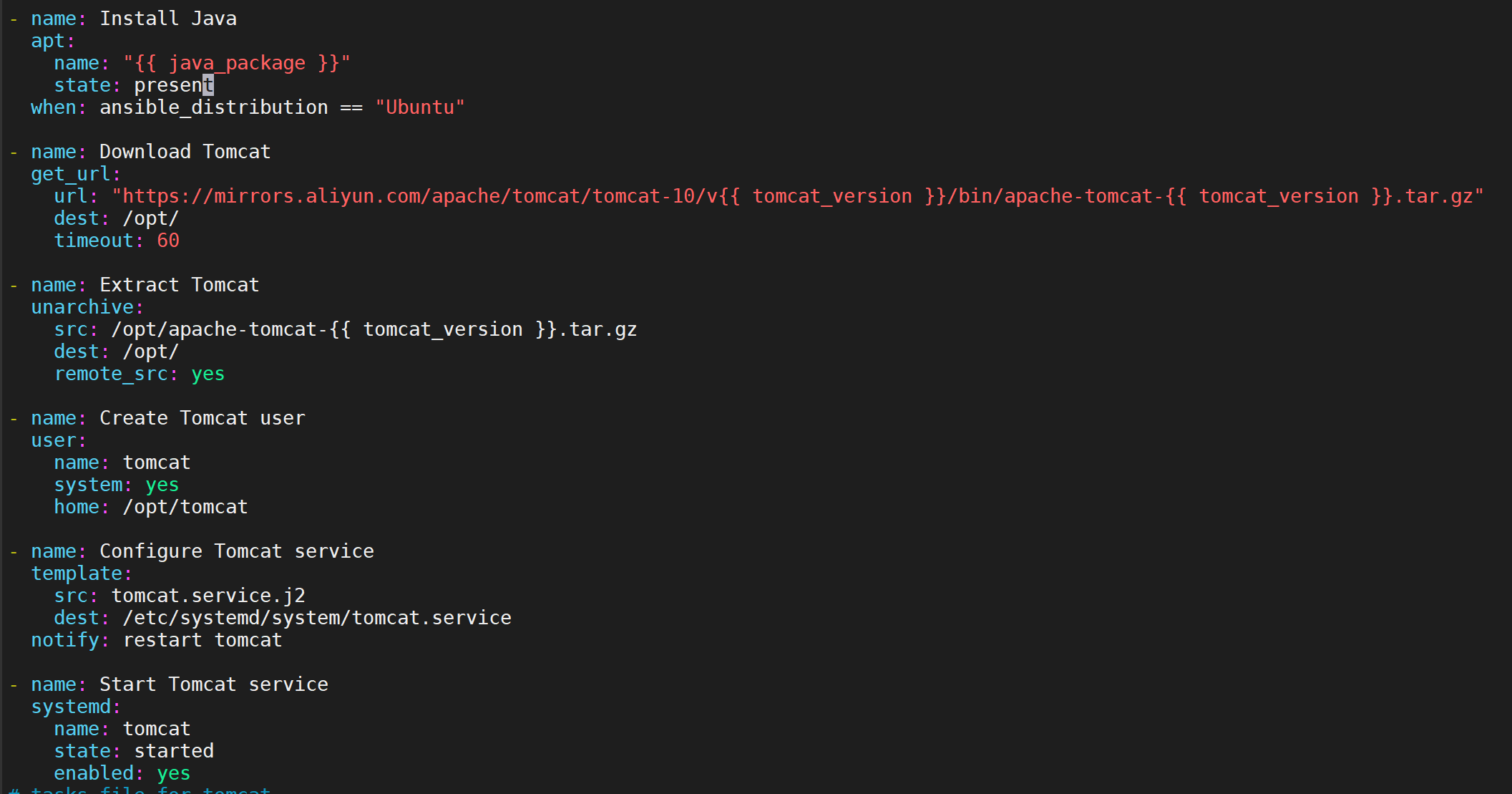
创建任务 tomcat/tasks/main.yml
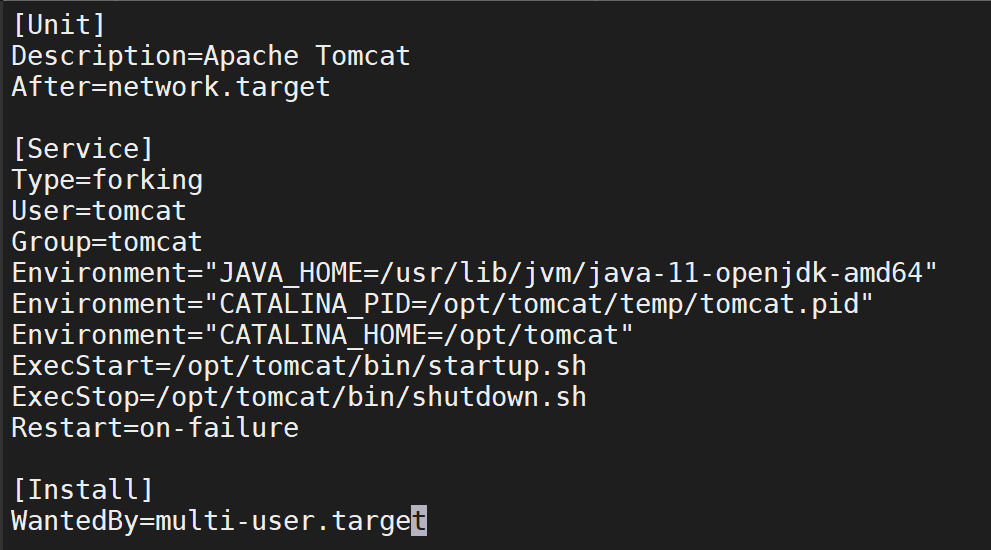
创建服务模板 tomcat/templates/tomcat.service.j2:
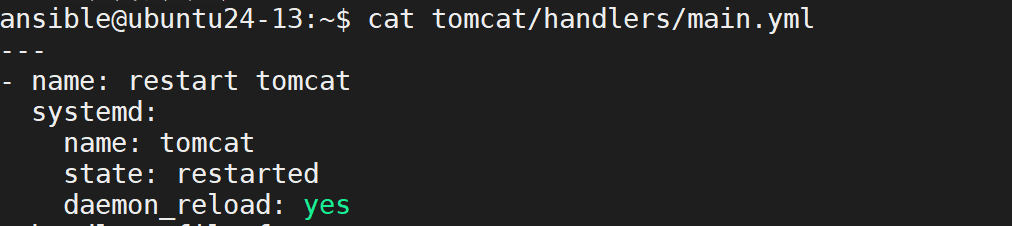
配置 Handlers tomcat/handlers/main.yml
创建 Playbook 调用 Role
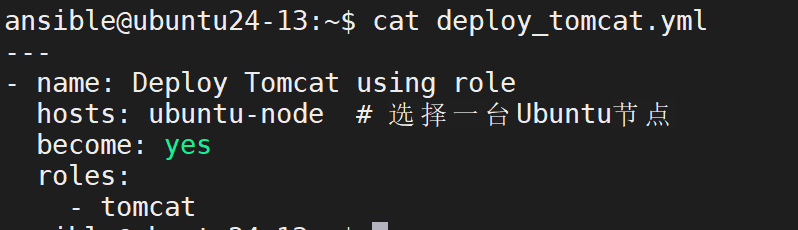
执行部署
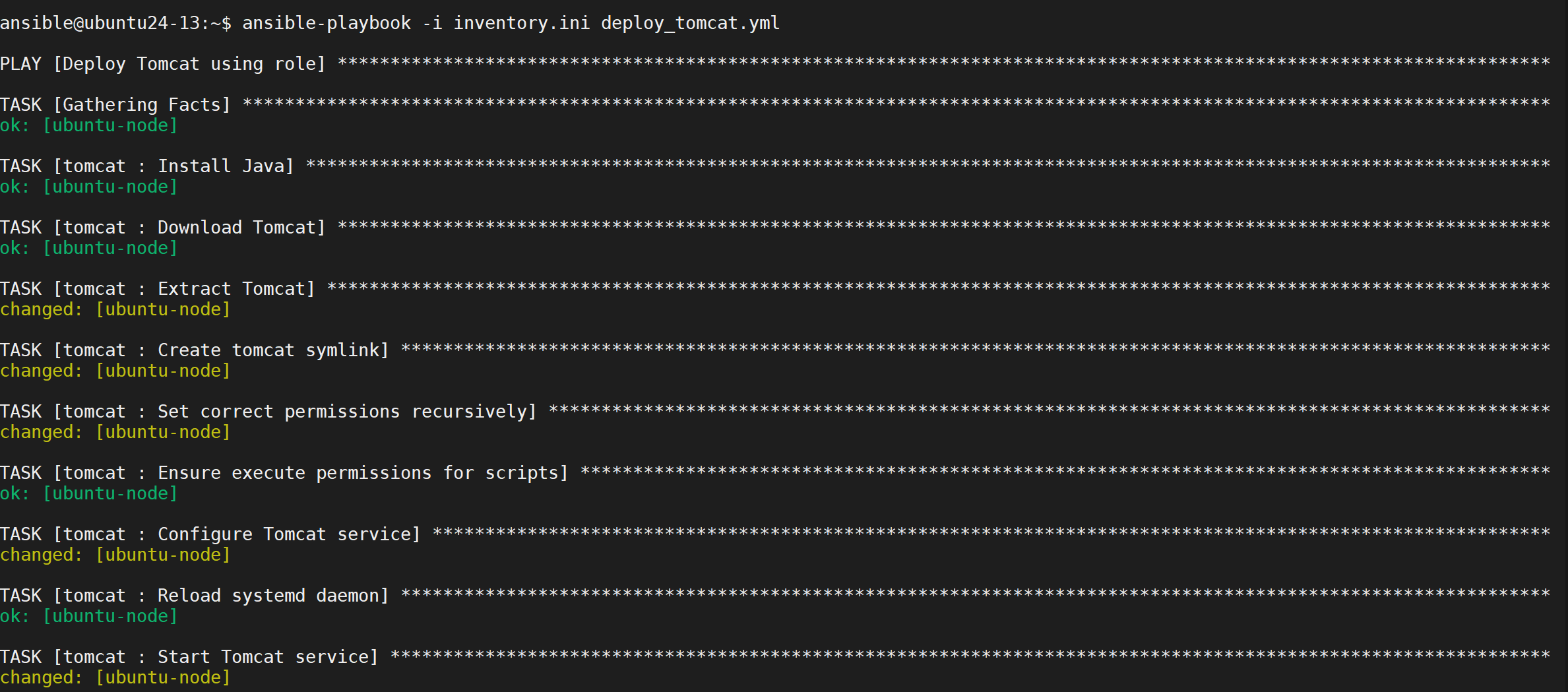

验证成功(令人愉快的绿色!!!)
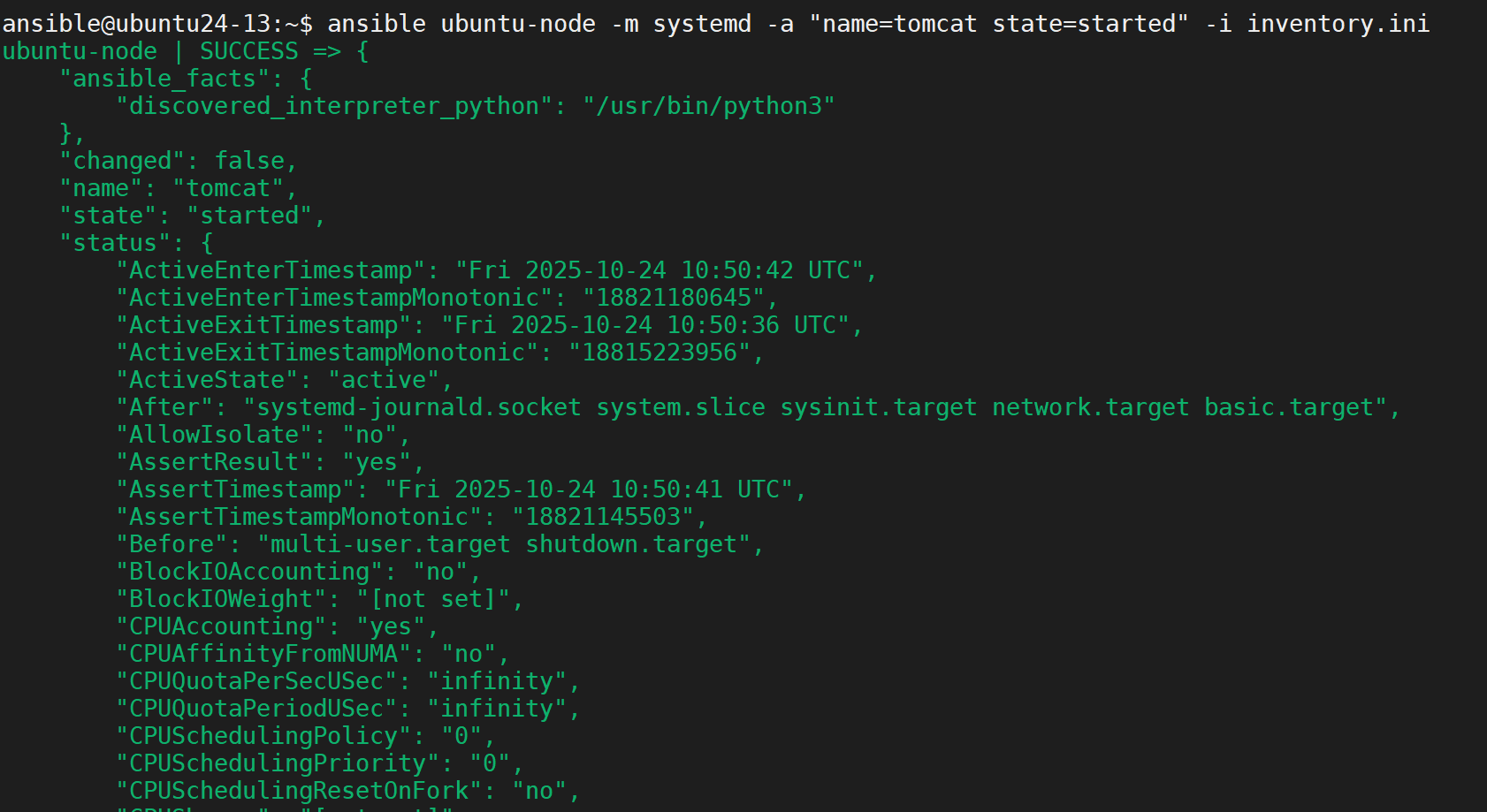
完成,测试

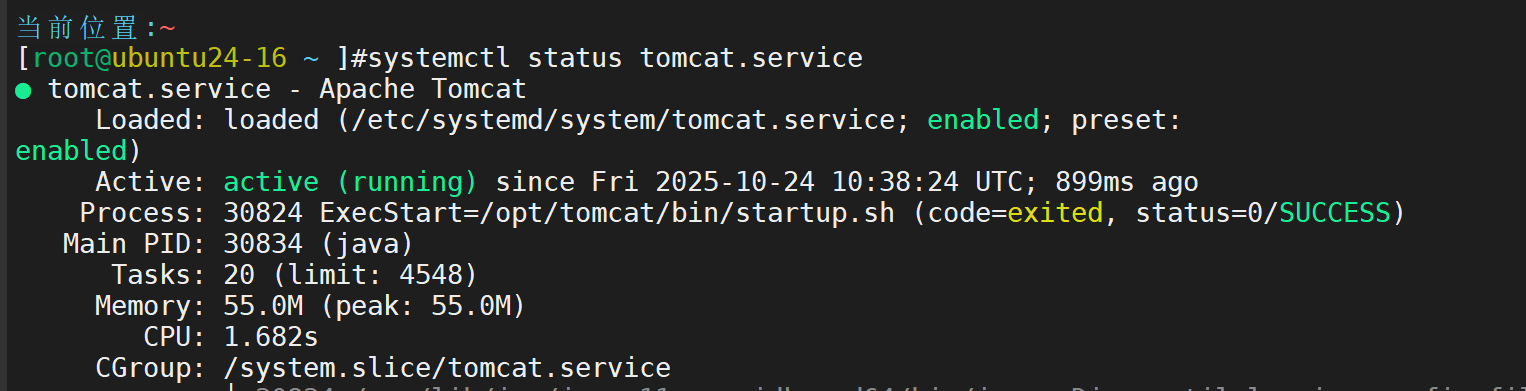
Zabbix 核心组件及其作用详解
8.简述 Zabbix 的核心组件(如 Server、Agent 等)及各自的作用。
Zabbix 的核心组件及各自作用
- Zabbix Server:核心组件,负责接收 Agent/Proxy 发送的监控数据,处理告警逻辑(触发条件、通知方式),存储数据到数据库,并协调整个监控系统的工作。
- Zabbix Agent:部署在被监控主机上的轻量进程,主动或被动收集主机的监控数据(如 CPU 使用率、磁盘空间等),并发送给 Server 或 Proxy。
- Zabbix Proxy:分布式监控的中间组件,用于减轻 Server 压力。可在远程区域收集多个 Agent 的数据,汇总后转发给 Server,适用于大规模或跨机房监控场景。
- 数据库:存储所有监控数据(历史指标、配置信息、告警记录等),支持 MySQL、PostgreSQL、Oracle 等主流数据库。
- Zabbix Web Interface:基于 Web 的可视化界面,供用户配置监控项、查看监控图表、管理告警规则等,是用户与 Zabbix 交互的主要入口。
Zabbix 监控项、触发器与告警的关联逻辑
9.解释 Zabbix "监控项""触发器""告警" 三者的关联逻辑,用 1 个简单场景描述(如 "CPU 使用率过高")。
一、三者关联逻辑
监控项 是数据采集源头,负责获取被监控对象的具体指标;触发器 是条件判断规则,基于监控项的采集数据判断是否触发异常;告警是异常响应动作,当触发器满足触发条件时,自动执行预设的通知或处理操作。三者形成 "数据采集→条件判断→动作响应" 的闭环,实现从 "发现异常" 到 "通知处理" 的自动化监控。
二、简单场景描述(CPU 使用率过高)
-
监控项:采集 CPU 使用率数据在 Zabbix 中为目标服务器创建 "CPU 使用率(%)" 监控项,配置采集规则(如每隔 1 分钟采集 1 次),该监控项会持续获取服务器的实时 CPU 使用率,并将数据传输到 Zabbix Server 存储。
-
触发器:判断 CPU 是否过高基于上述监控项,创建触发器,设定判断条件(如 "监控项采集的 CPU 使用率连续 2 次≥80%")。当监控项采集到的数据满足该条件(例如连续两次测得 82%、85%),触发器会从 "正常" 状态切换为 "异常" 状态,标记 "CPU 使用率过高" 的潜在问题。
-
告警:触发异常通知提前配置告警规则:当上述触发器切换为 "异常" 时,Zabbix 自动执行告警动作 ------ 比如向管理员的邮箱发送通知(内容含 "服务器 XX 的 CPU 使用率达 85%,触发告警"),同时在 Zabbix Web 界面高亮显示该告警;直到监控项采集的 CPU 使用率回落(如降至 70%),触发器恢复 "正常",告警才会自动解除。
Zabbix 两种监控方式对比与场景分析
10.列举 Zabbix 支持的 2 种监控方式,并说明适用场景。
1. Agent 监控(主动 / 被动模式)
核心原理:在被监控主机上部署 Zabbix Agent 程序,Agent 与 Zabbix Server 通信 ------ 被动模式下,Server 主动向 Agent 发起请求获取监控数据;主动模式下,Agent 主动将采集到的数据推送给 Server。
适用场景:适合有操作系统的设备,如 Linux/Windows 服务器、物理机、虚拟机等。这类设备可正常安装 Agent 程序,能精准采集系统级指标(CPU、内存、磁盘、进程状态等)和应用级指标。
2. SNMP 监控
核心原理:基于 SNMP(简单网络管理协议),无需在被监控设备上安装 Agent,而是通过设备自带的 SNMP 服务,Zabbix Server 向设备发送 SNMP 请求,获取设备的预设监控数据。
适用场景:适合无操作系统或无法安装 Agent 的网络设备、硬件设备,如路由器、交换机、防火墙、打印机、UPS 电源、IoT 传感器等。这类设备通常原生支持 SNMP 协议,可通过配置 SNMP 共同体名实现数据采集。
Zabbix 监控环境部署与 Grafana 可视化实战
11.部署 Zabbix 环境:
完成 Zabbix Server 和 1 台 Zabbix Agent 的安装与配置,确保 Server 能正常识别 Agent。
基础监控实践:在 Zabbix 中为 Agent 主机添加 "内存使用率""磁盘空间" 2 个监控项,并配置对应的触发器(如内存使用率 > 80% 触发告警)。
告警实践:配置 Zabbix 的微信告警或钉钉告警,当触发器触发时,能收到对应的告警消息。
可视化实践:使用 Grafana 连接 Zabbix 数据源,创建 1 个包含 "CPU 使用率""网络流量" 的监控仪表盘。
实践
Zabbix Server的安装与配置
软件源定制:更新软件源之后apt updata
获取最新版本的zabbix软件源


更新后进行安装
安装数据库apt install mysql-server 然后对数据库进行配置
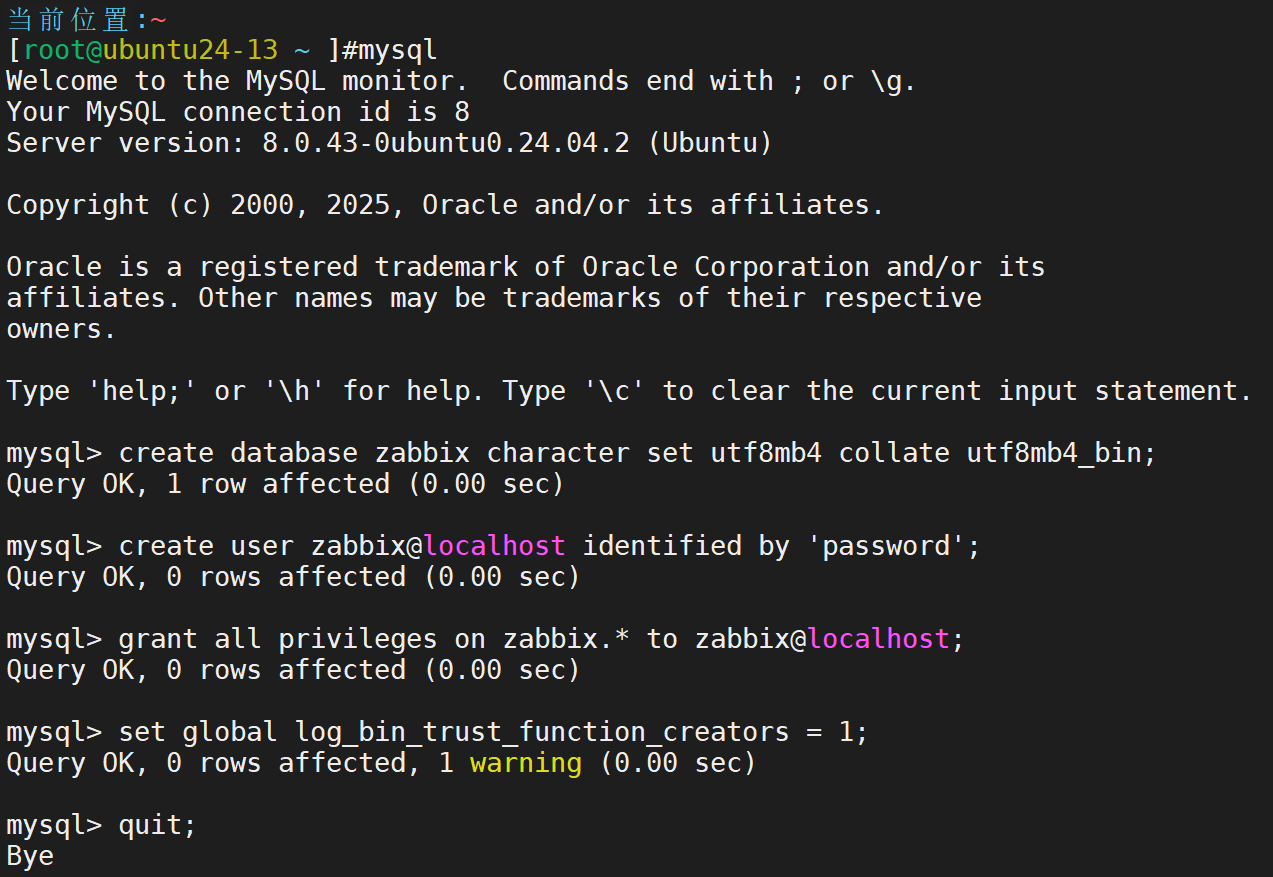
使用默认的sql文件,创建zabbix的数据库环境
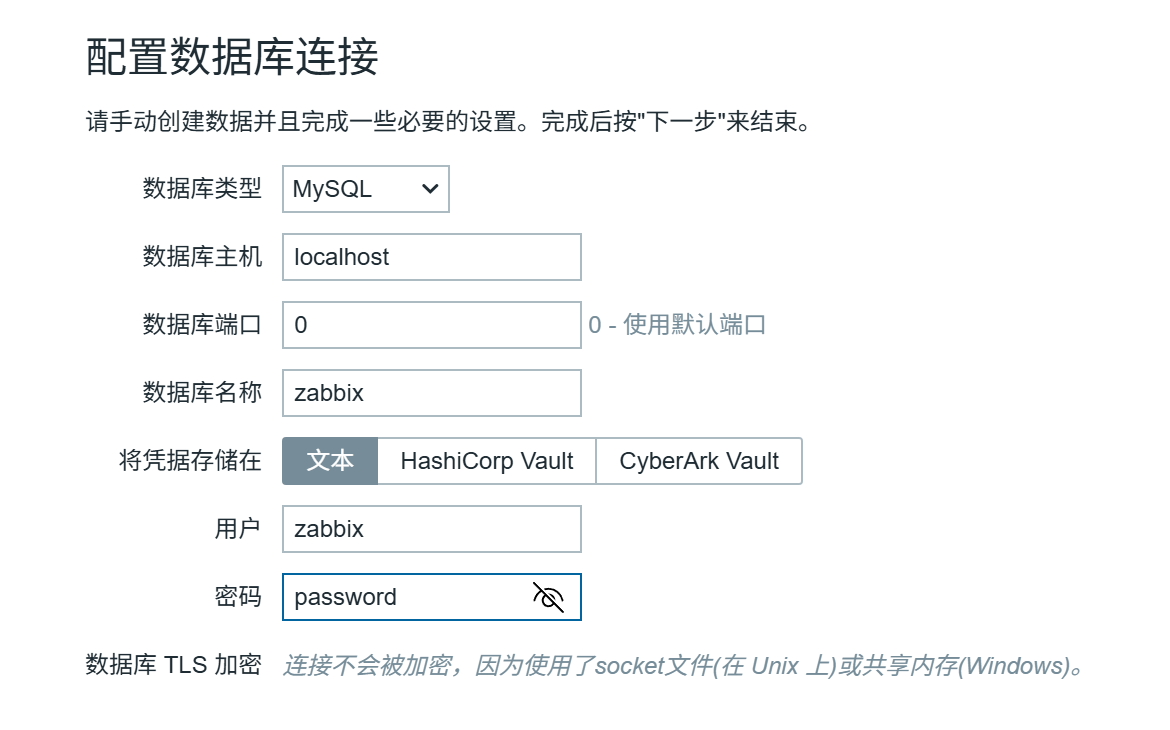
注意,我们为了方便演示刚才密码设置为password

检测效果
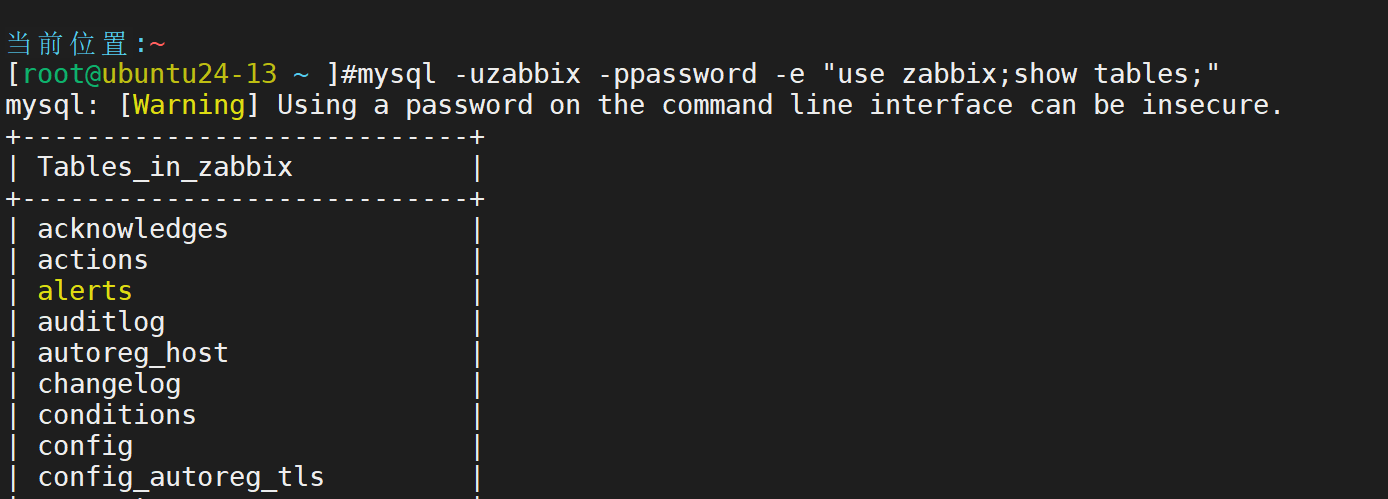
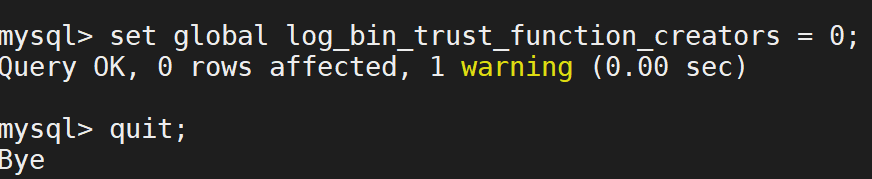
然后进入数据库中,将刚才为了导入数据库文件能力的 属性移除
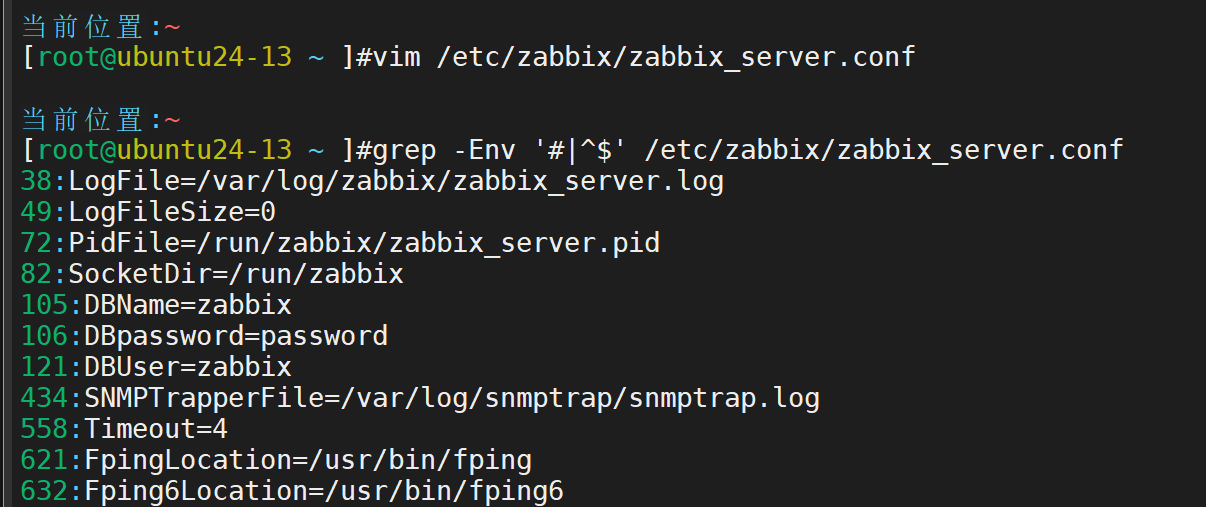
为Zabbix server配置数据库
vim /etc/zabbix/zabbix_server.conf DBPassword=password
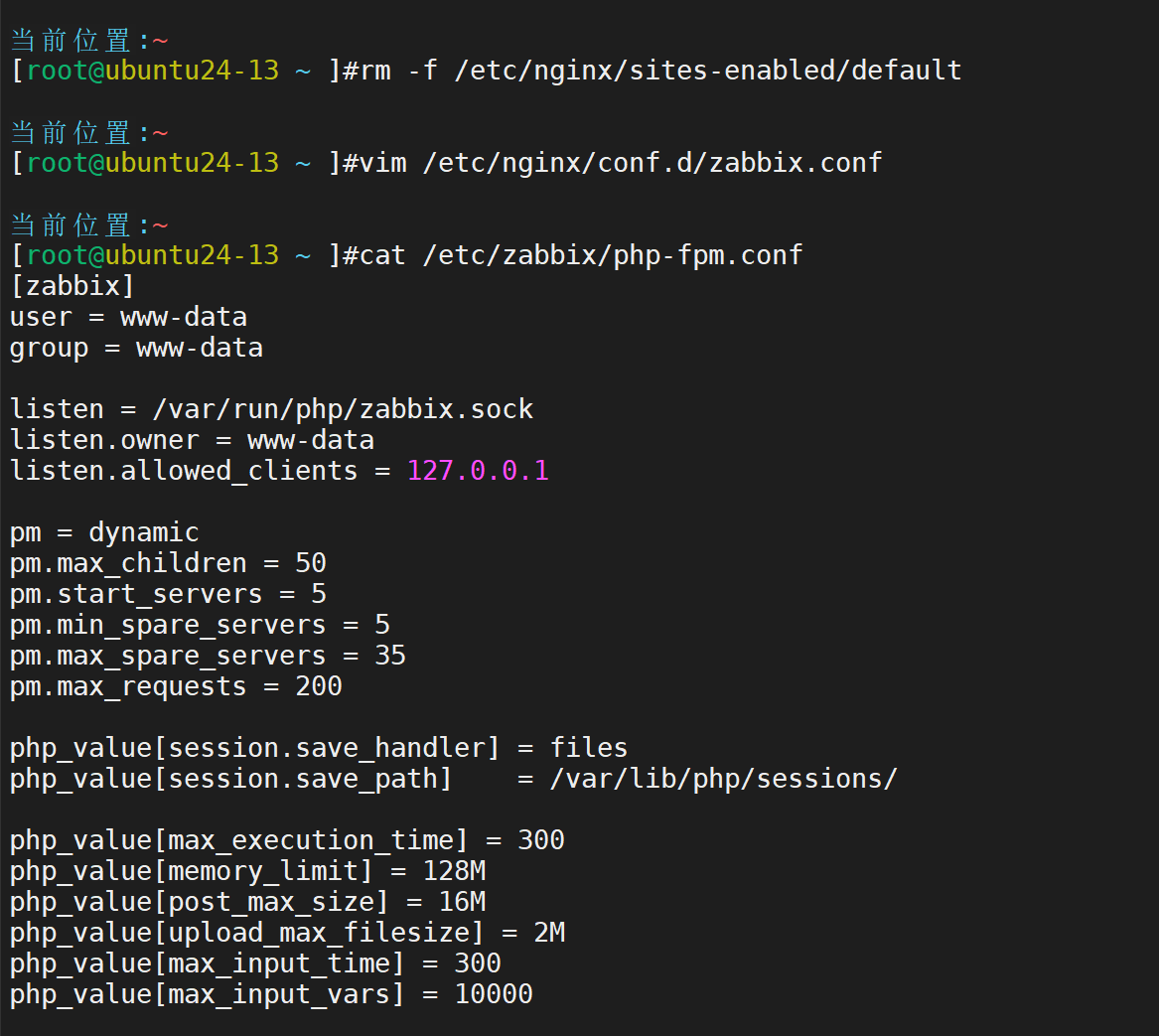
然后配置前端 Nginx环境和PHP环境
删除出事的nginx首页画面。
在/etc/nginx/conf.d/zabbix.conf 中添加 listen 80
然后在/etc/zabbix/php-fpm.conf文件最后一行添加默认时区
php_valuedate.timezone = Asia/Shanghai
重启服务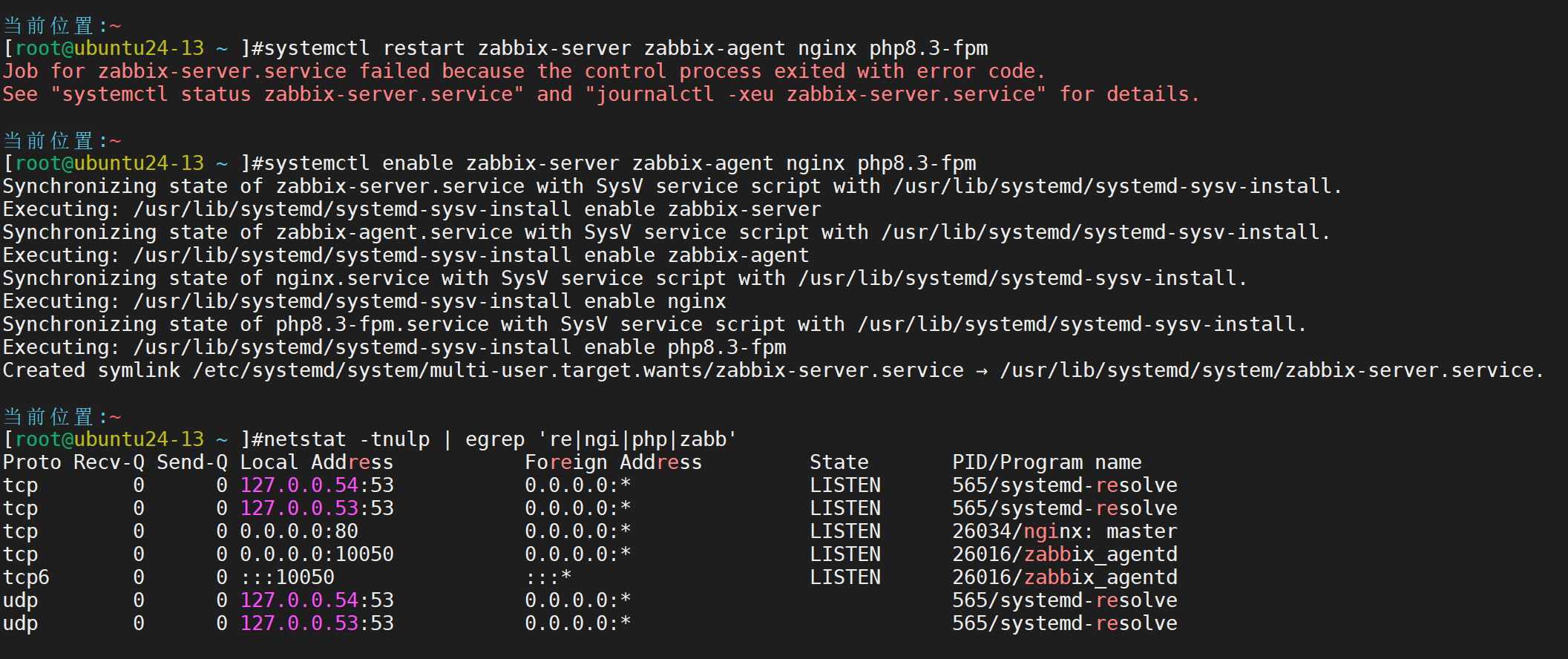
浏览器查看
接下来在浏览器上进行操作
点击下一步
下一步,设置密码
设置主机名称
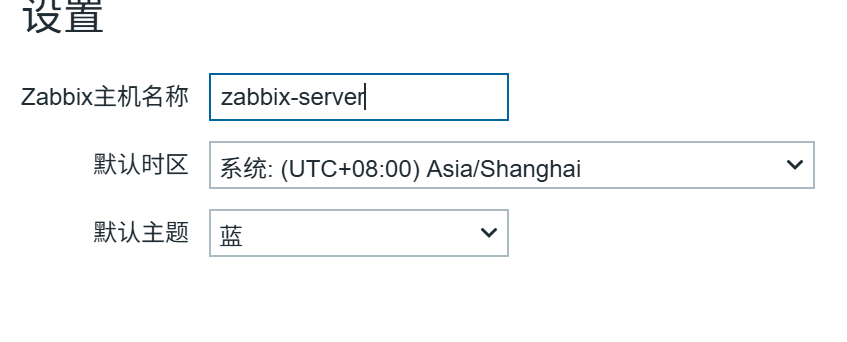
无异议,选择下一步

创建成功

进行登录,用默认名称和密码
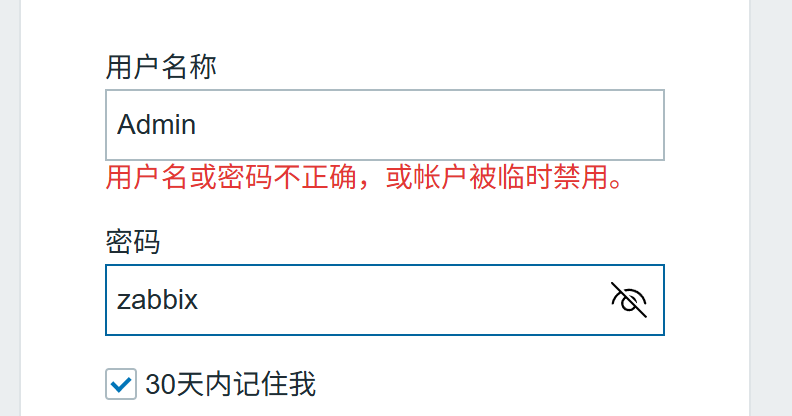
登陆成功
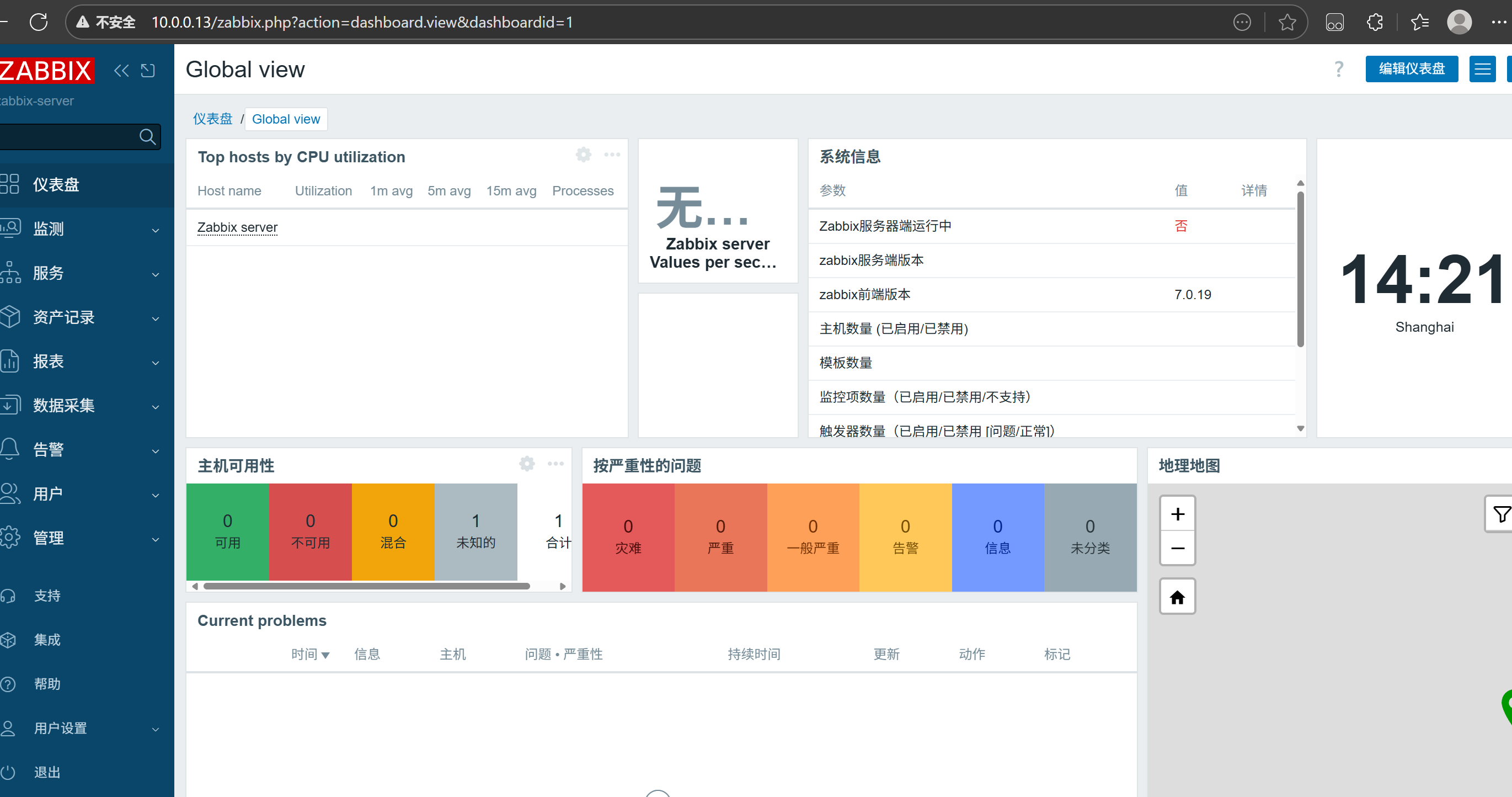
接下来进行安装监控客户端
配置软件源
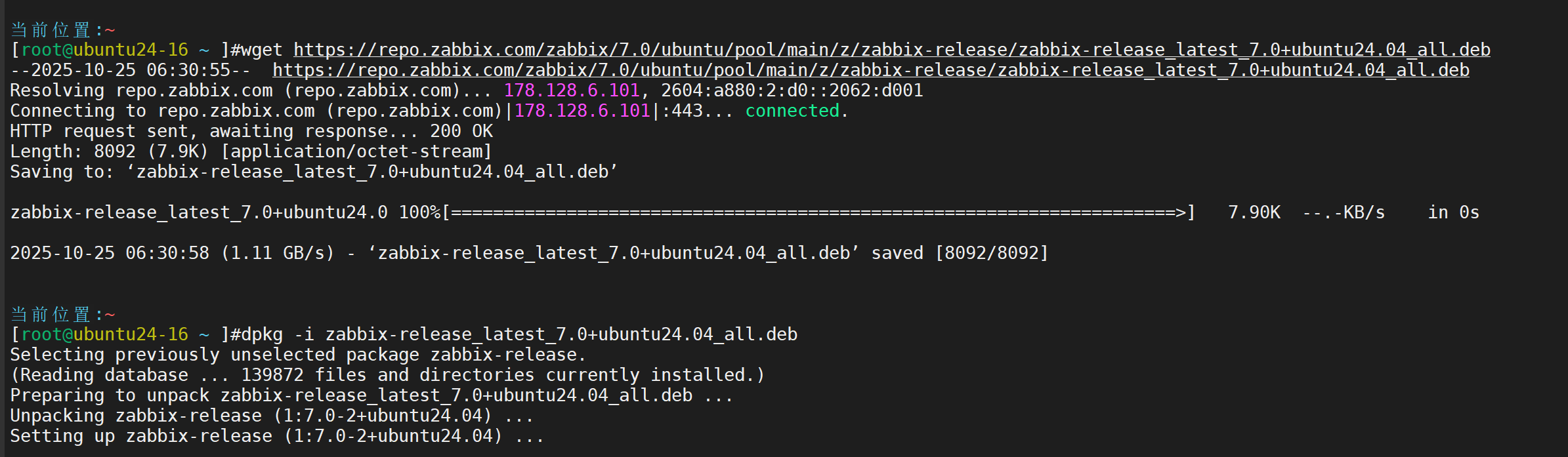
安装
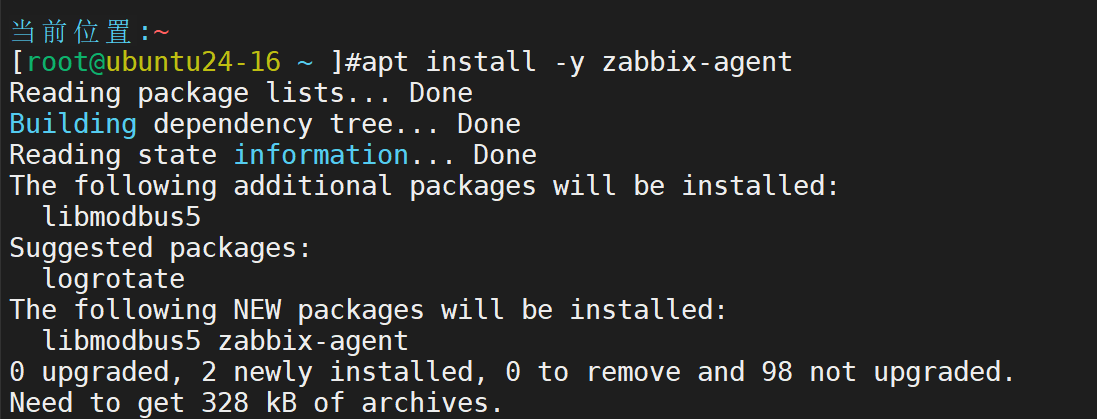
定制配置
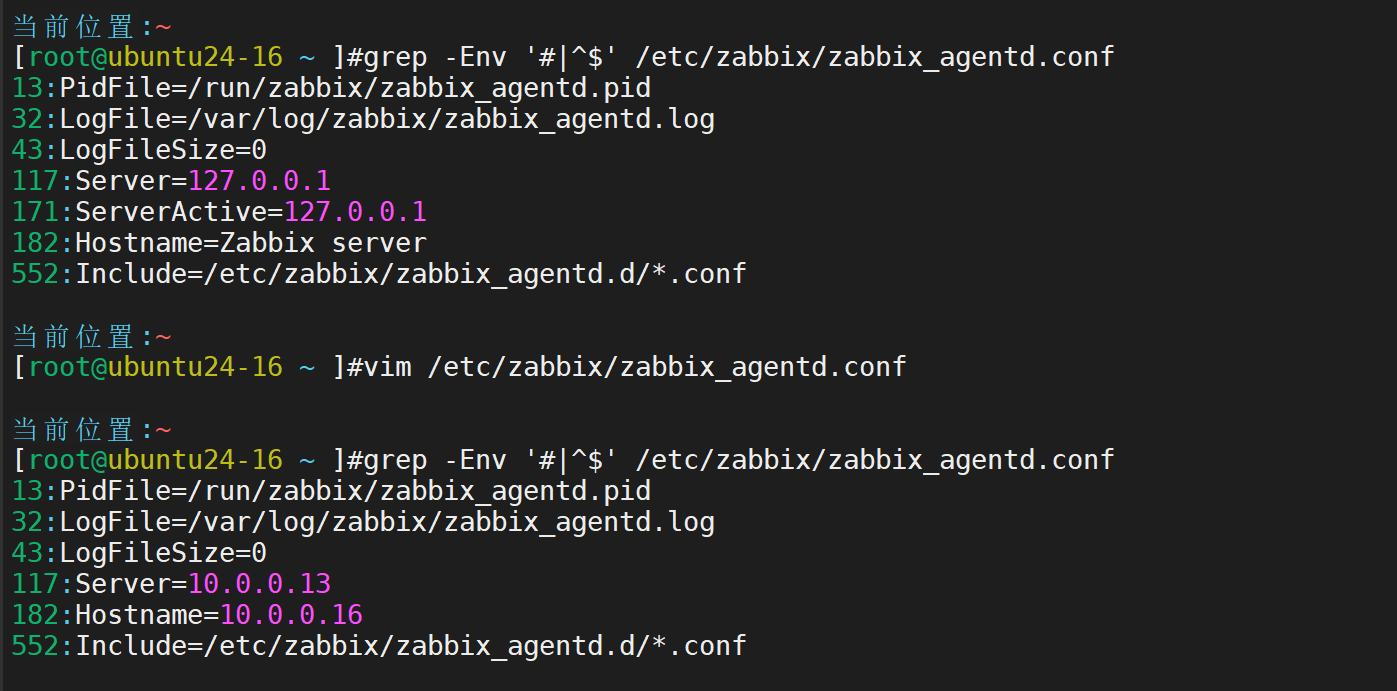
设置开机自启动,并检查端口
仪表盘进行资源创建
点击数据采集下的主机群组
创建主机
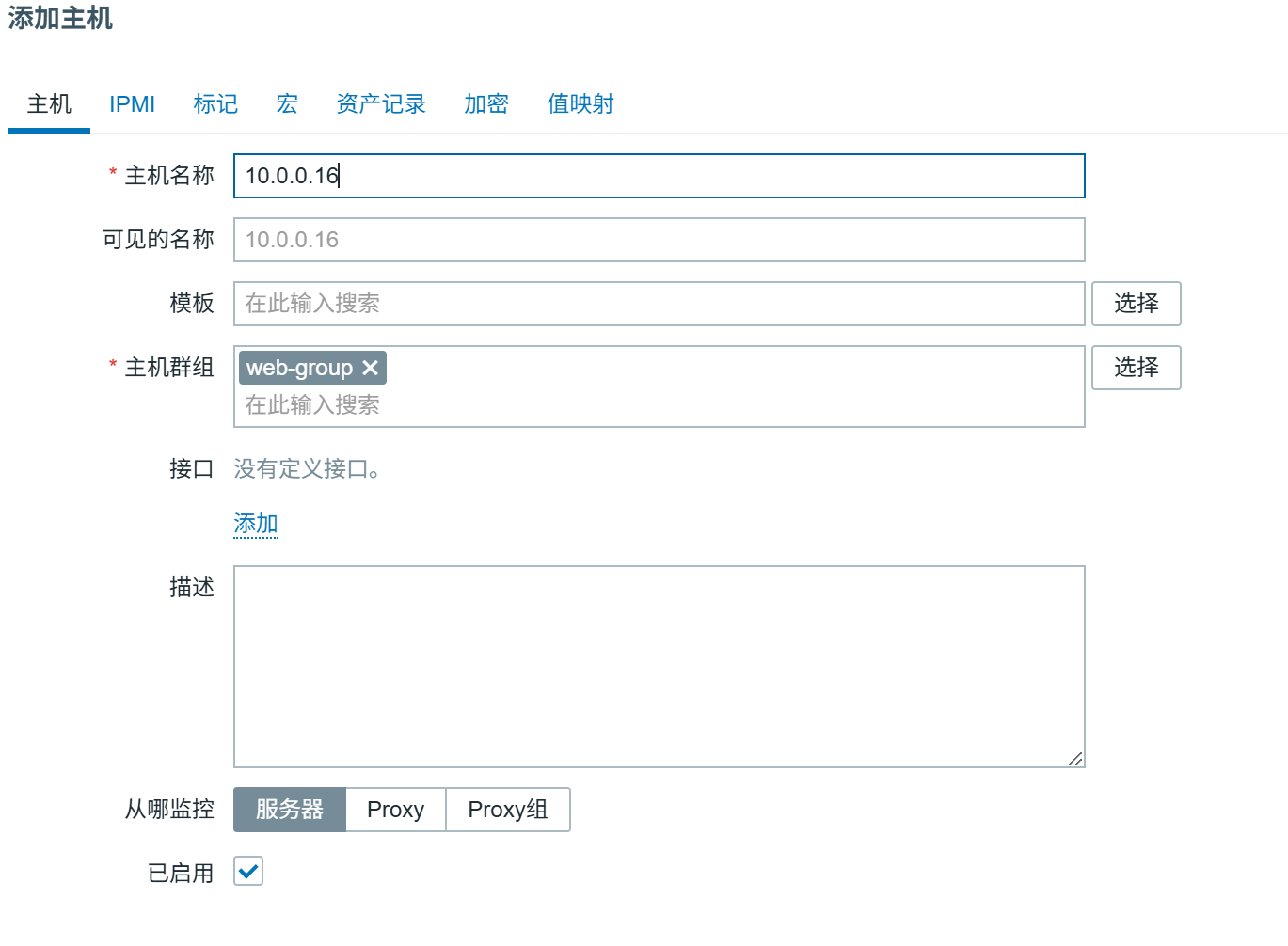
添加后刷新稍等后,变绿
在 Zabbix 中为 Agent 主机添加 "内存使用率""磁盘空间" 2 个监控项,并配置对应的触发器(如内存使用率 > 80% 触发告警)。
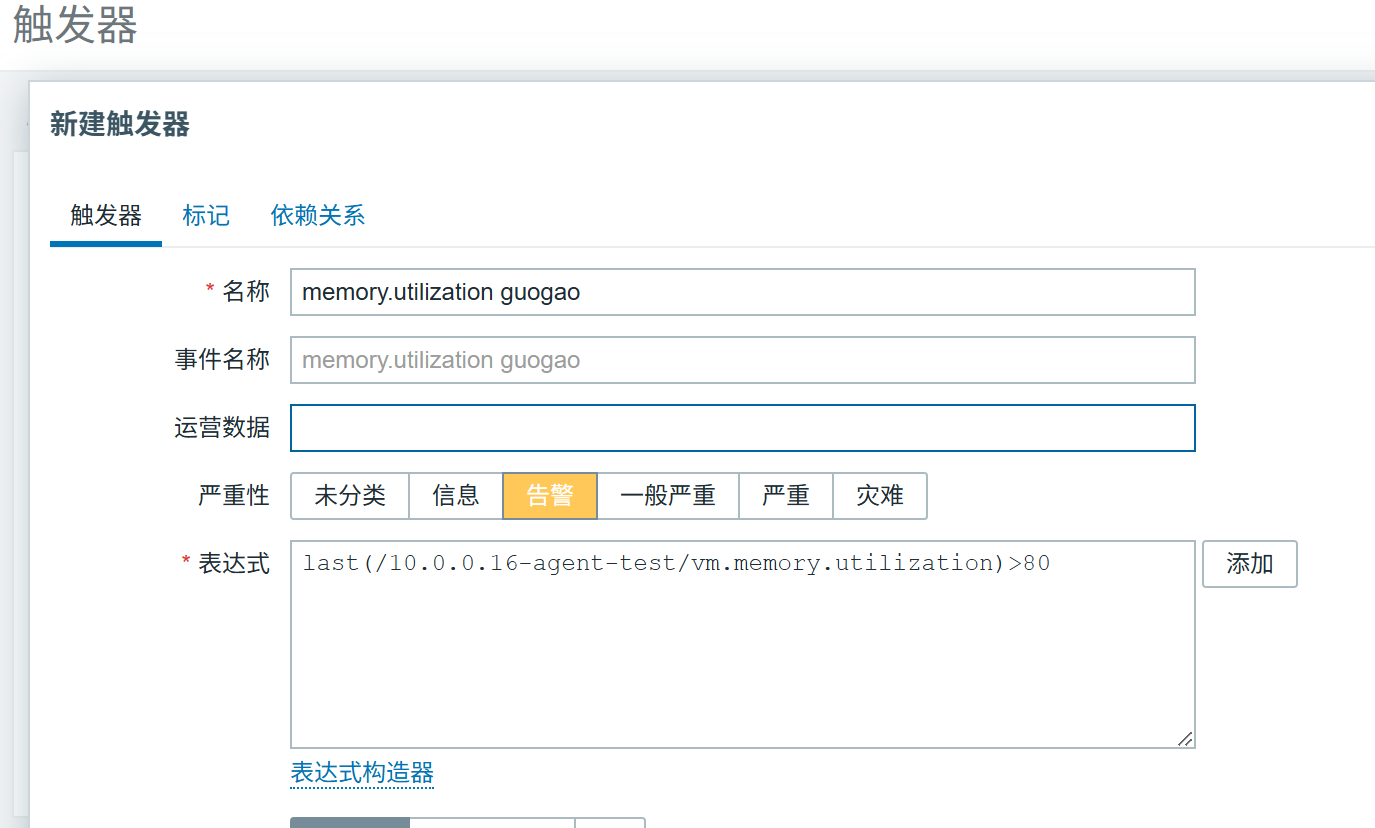
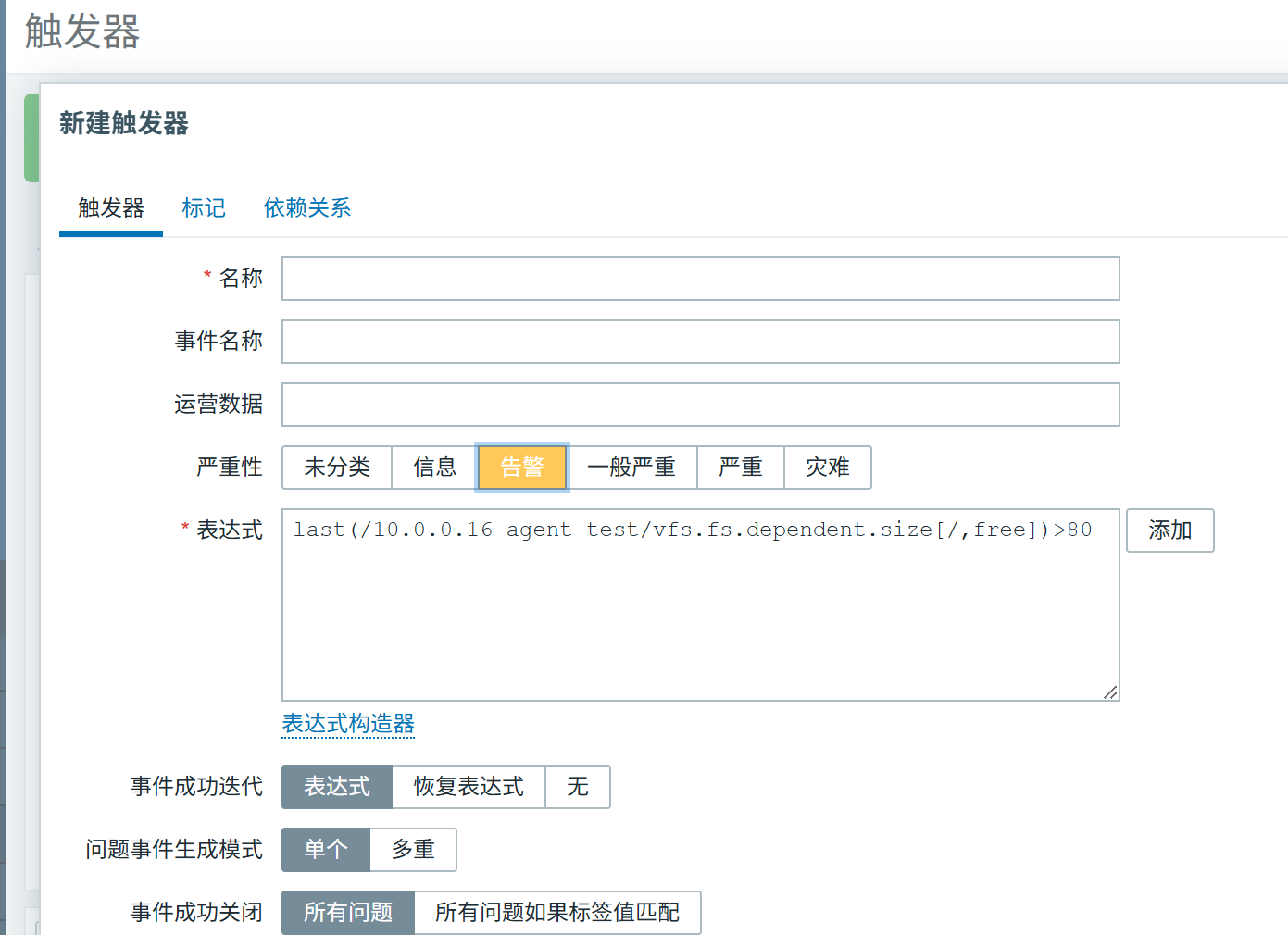

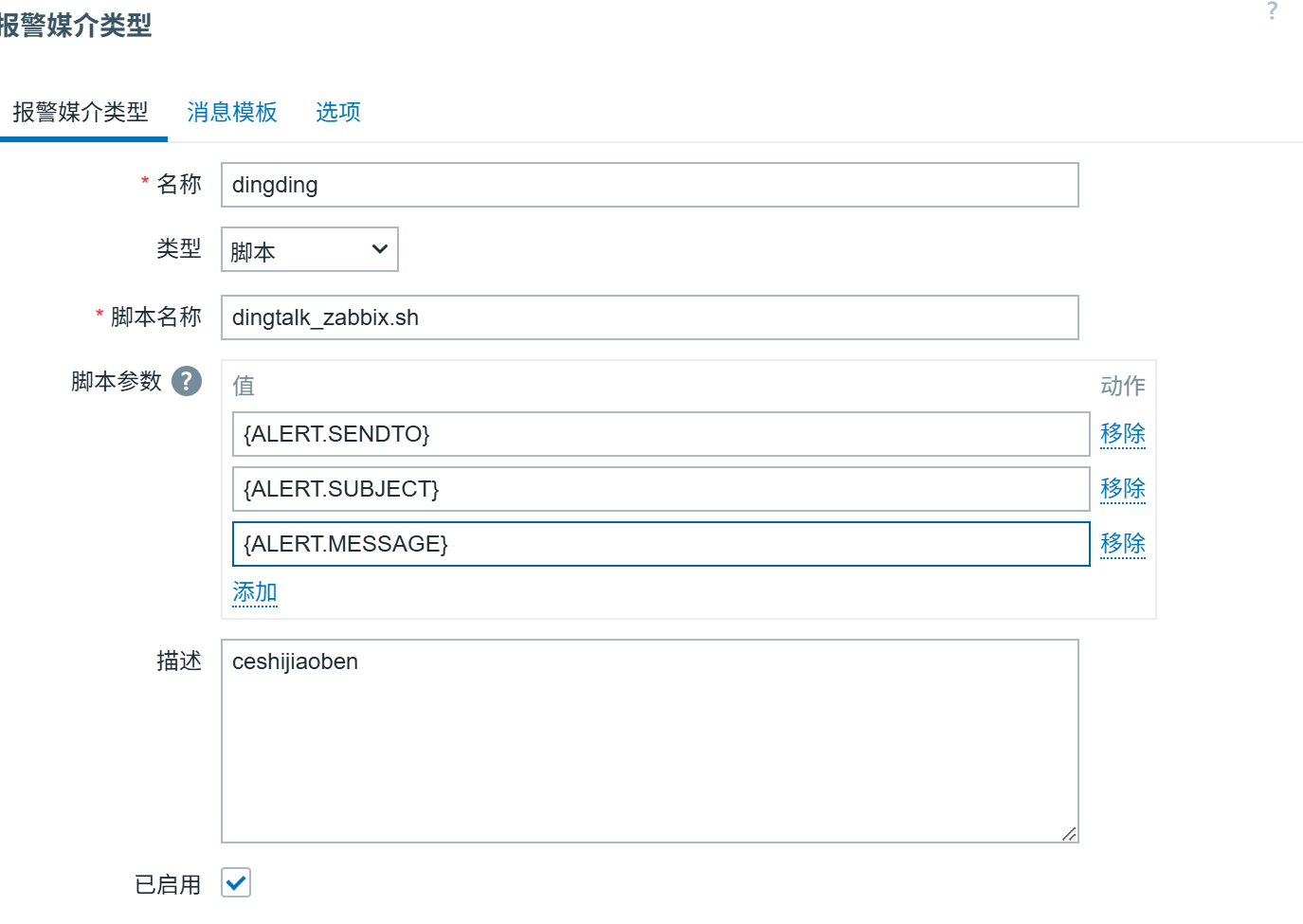
告警实践:配置 Zabbix 的钉钉告警,当触发器触发时,能收到对应的告警消息。
首先我们与要在钉钉上创建一个企业
然后创建一个群组,添加自定义机器人
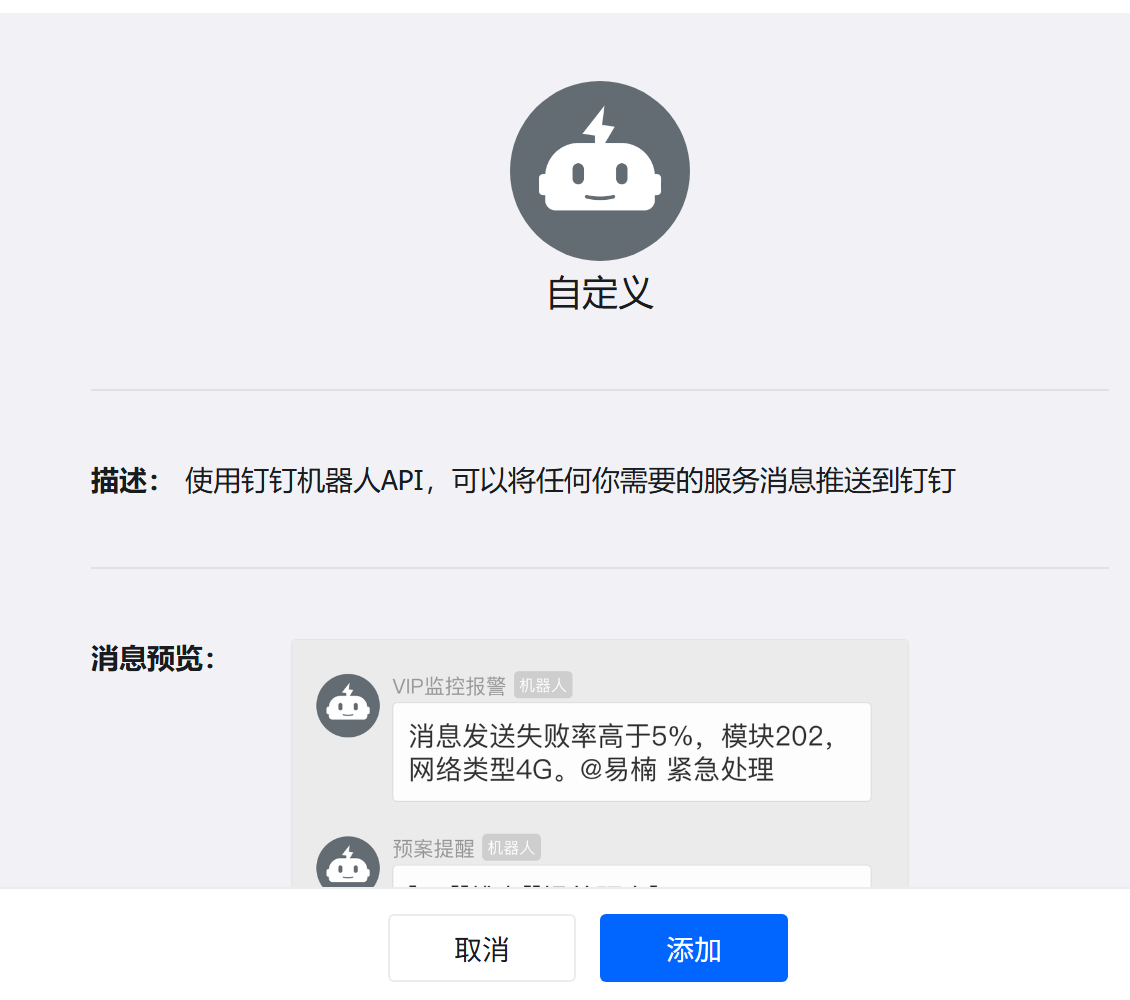
添加好后,会有一个Webhook
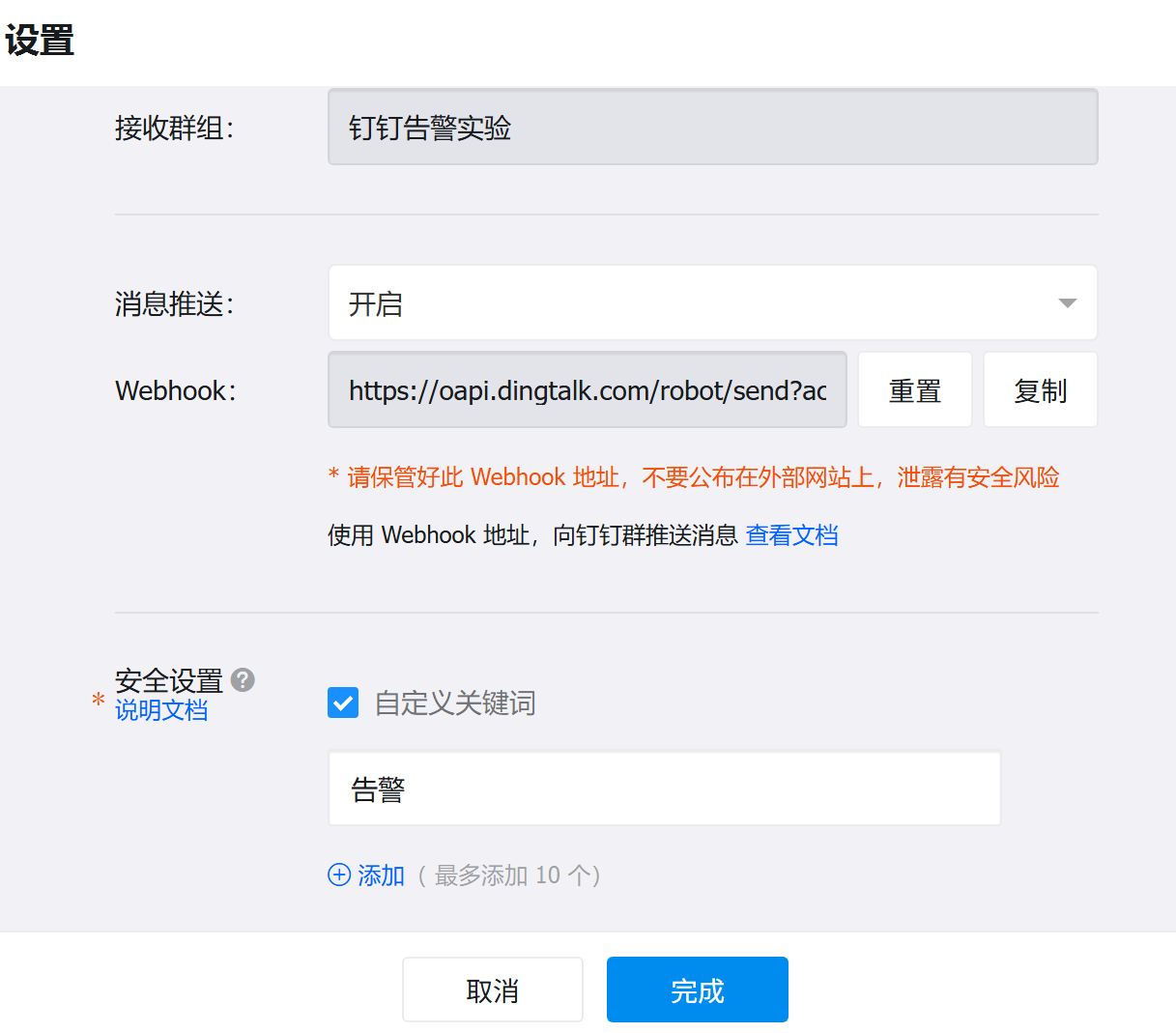
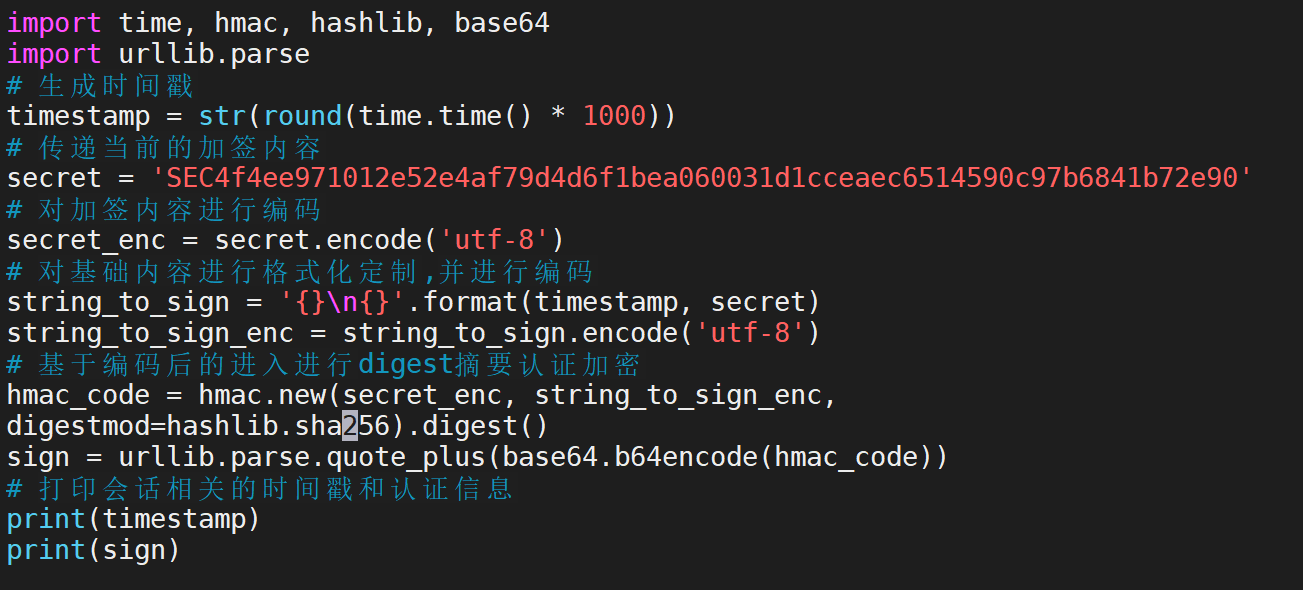
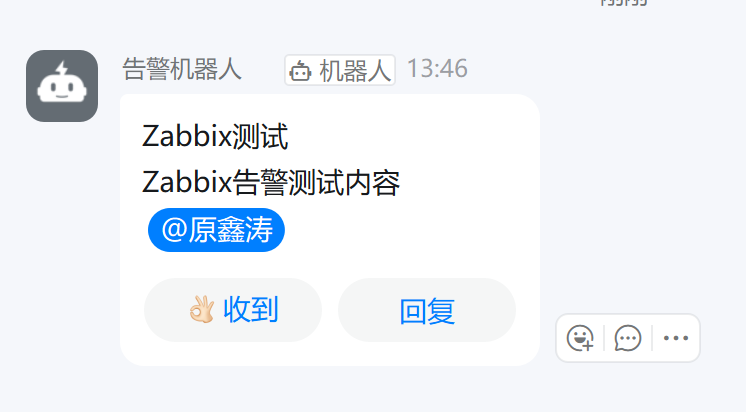
先用Webhook在虚拟机中进行测试(两个花括号中间换成机器人的webhook码)

会有如图结果
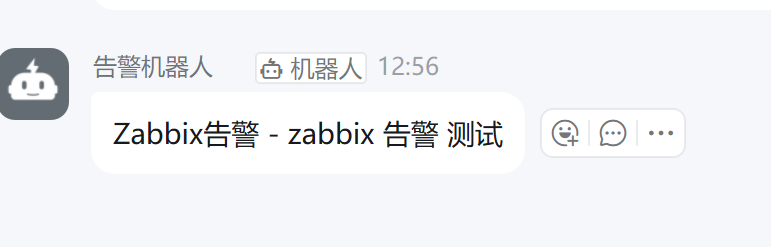
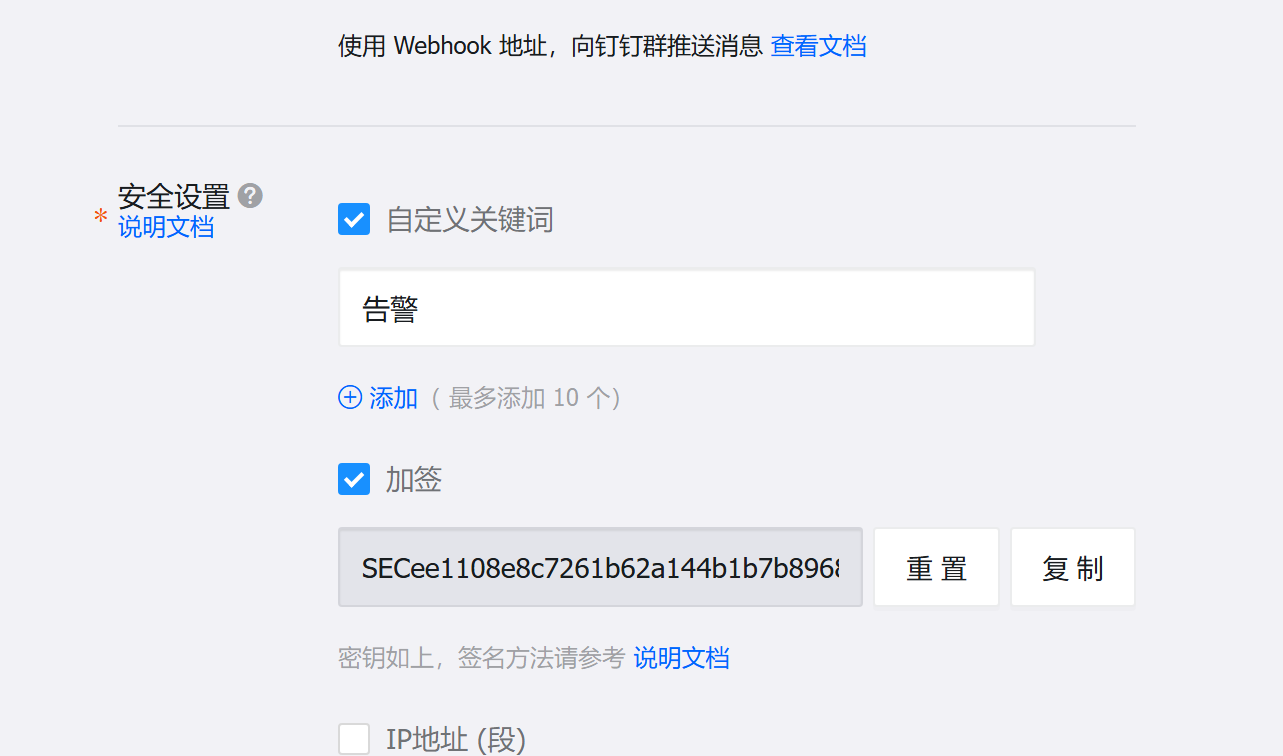

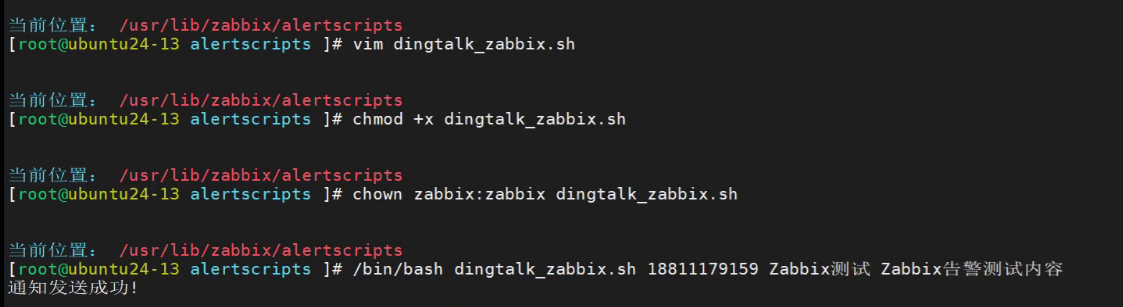
然后接入zabbix,在

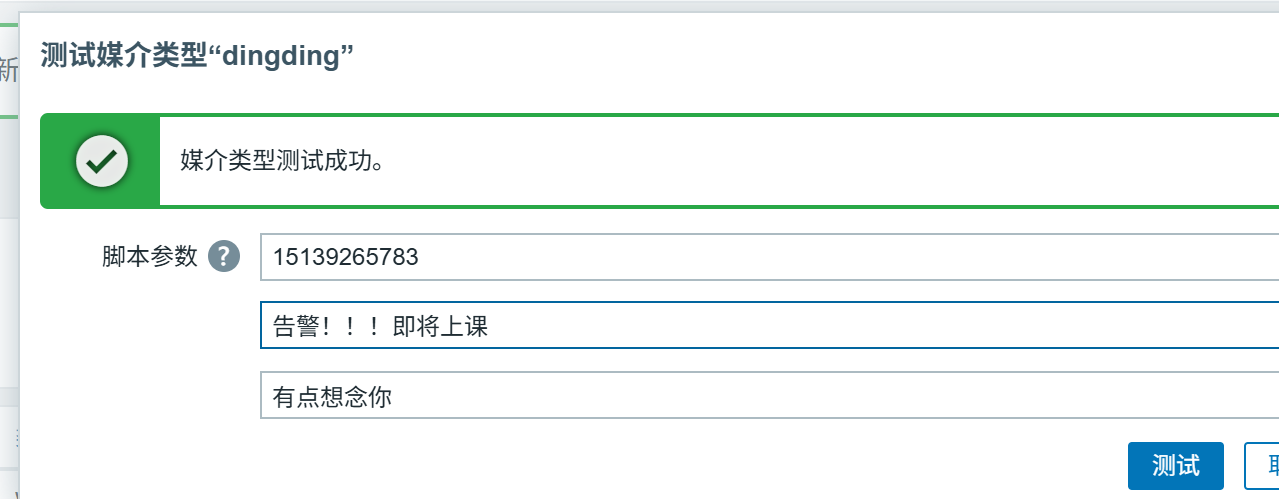
点击测试
可视化实践:使用 Grafana 连接 Zabbix 数据源,创建 1 个包含 "CPU 使用率""网络流量" 的监控仪表盘。
先安装一下需要使用的软件

在安装提前下载好的Grafana

systemctl enable --now grafana-server.service
使用10.0.0.13:3000进行连接
下载插件
启动systemctl restart grafana-server.service
然后
进入后启动
然后进行添加数据源

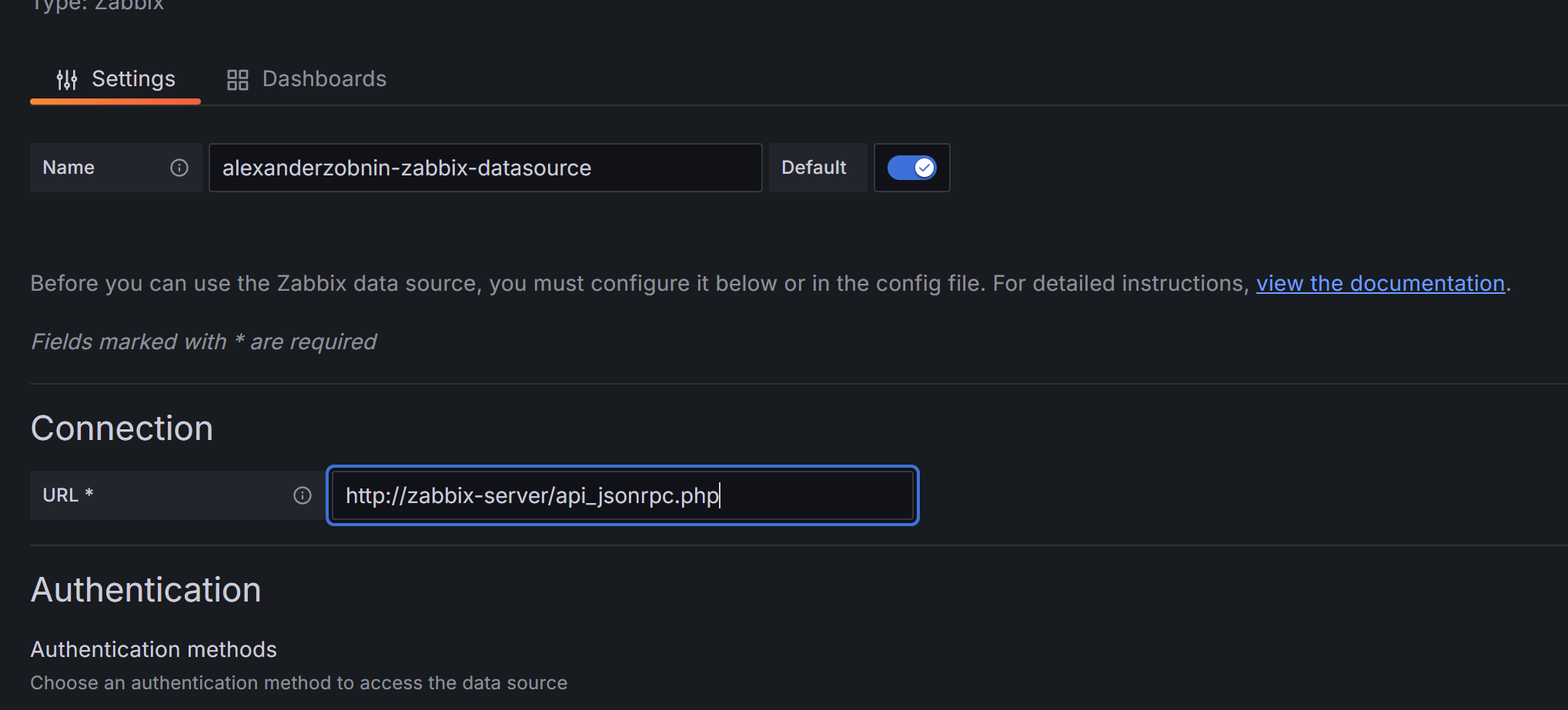
输入用户名和密码
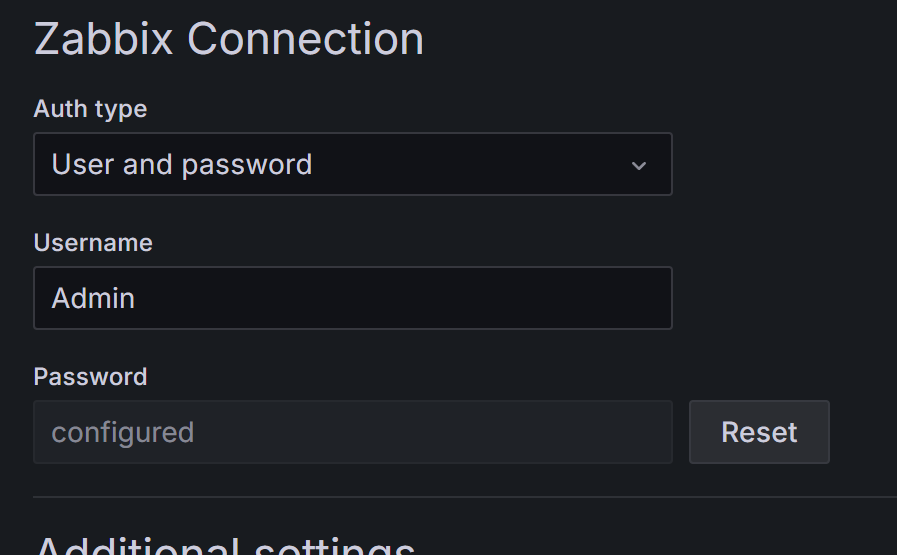
点击save
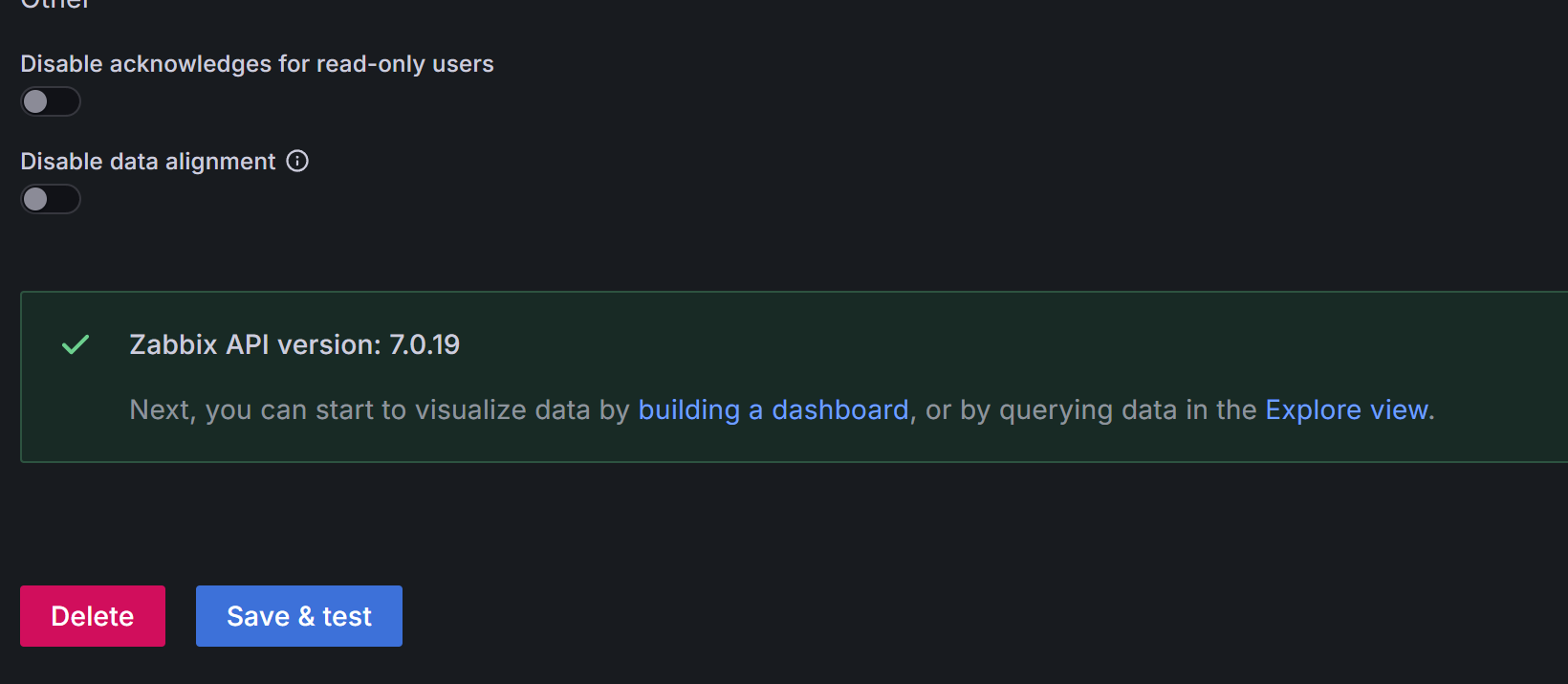
回上方模板库,全部inport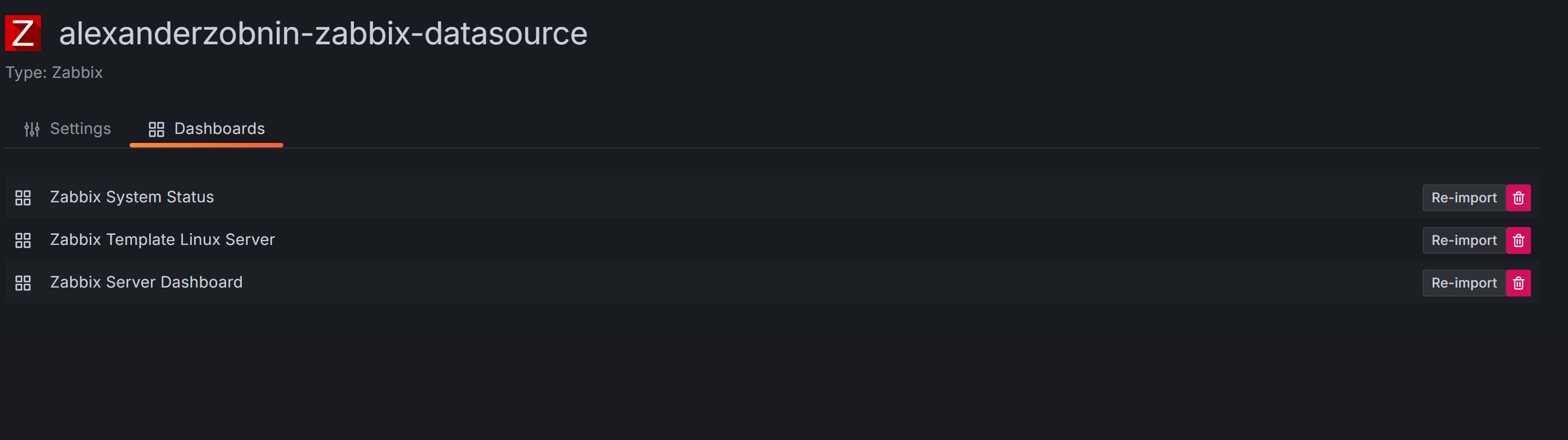
进第二个,右边三个点进行编辑
进行设置
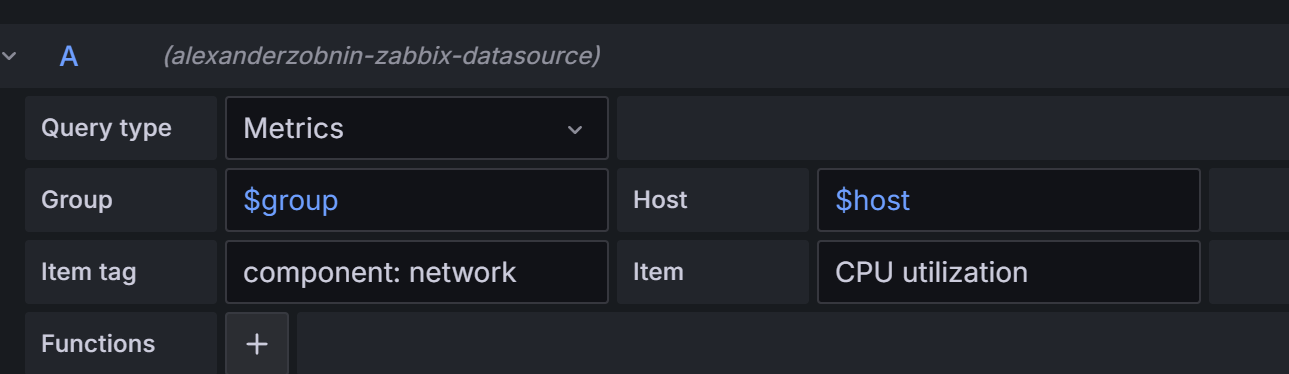
CPU使用率
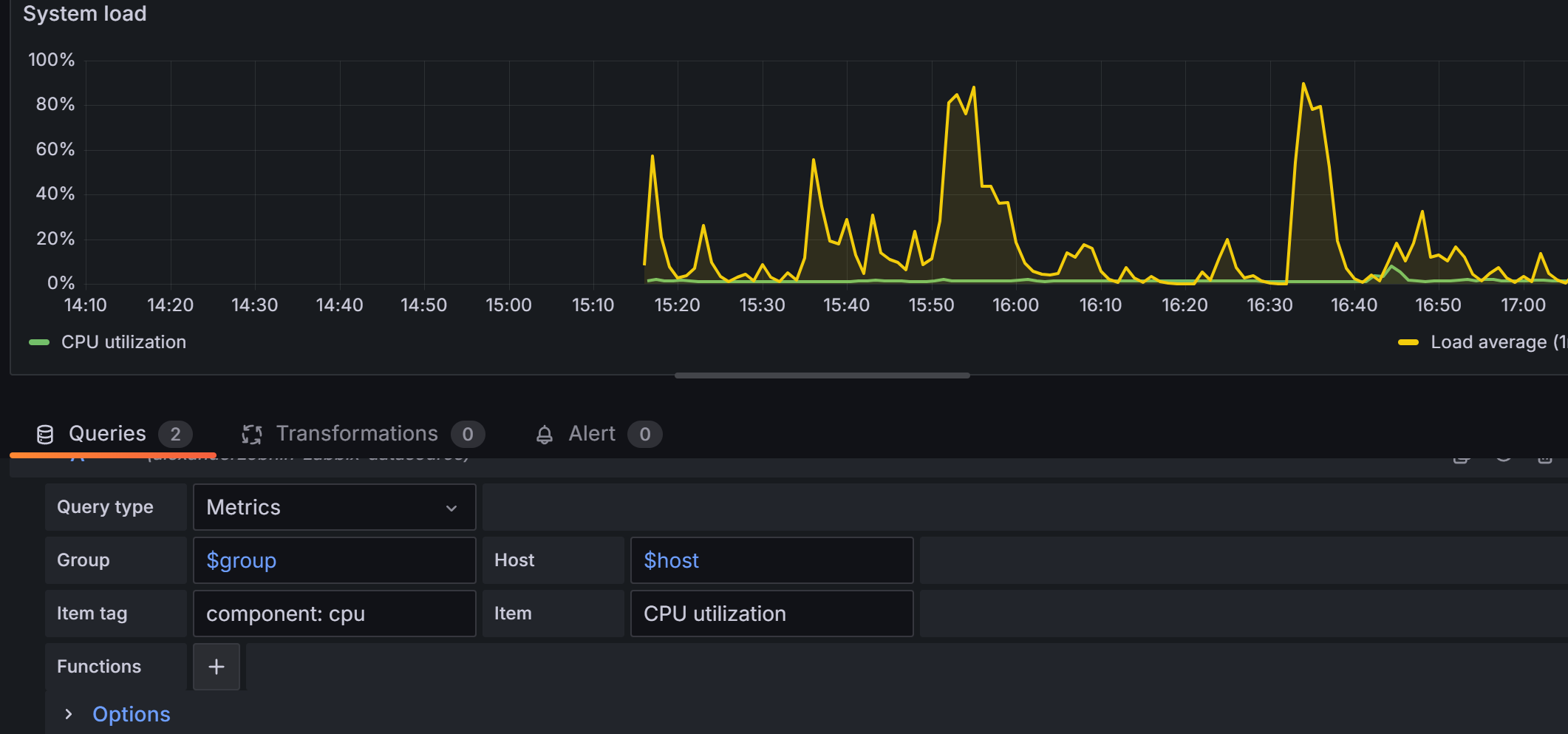
再添加一些其他的
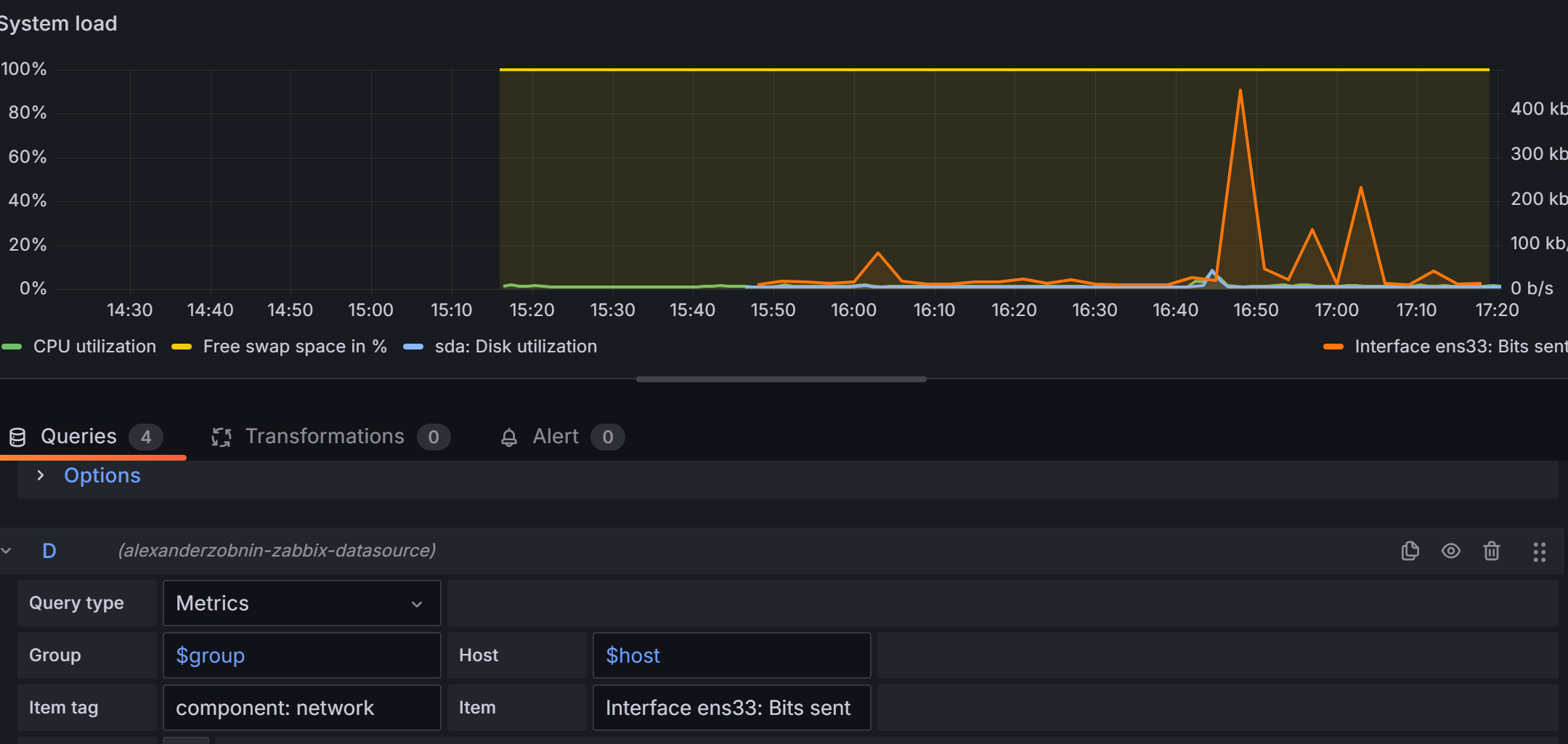
网速
KVM 虚拟化环境搭建与虚拟机管理实战
12.KVM 实践:在 1 台 Linux 主机上安装 KVM 环境,创建 1 台基于 CentOS 的虚拟机,并完成虚拟机的启动、关机、重启操作。
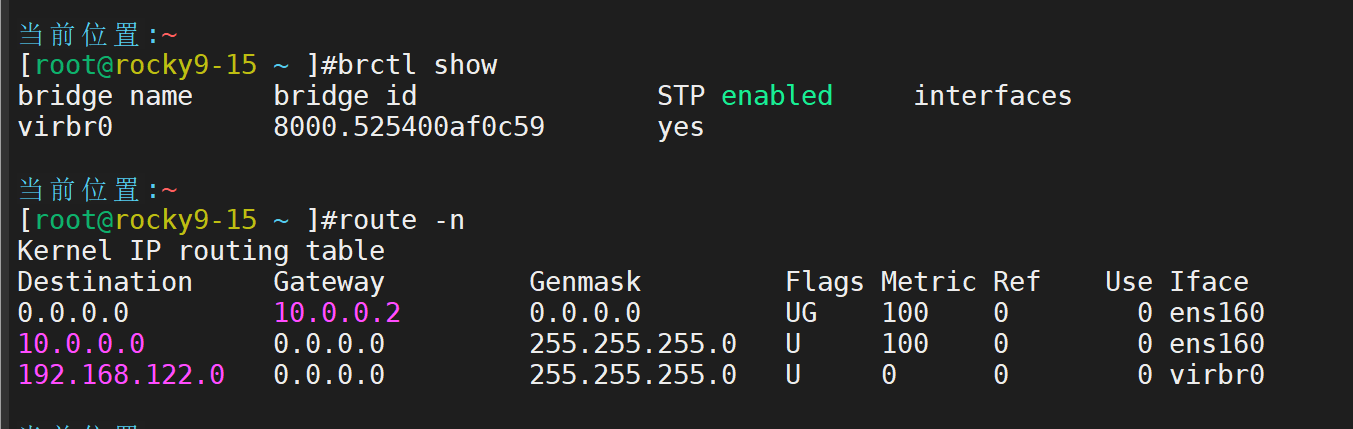
存储与网络管理:为 KVM 虚拟机添加 1 块新的虚拟磁盘,并用桥接模式配置虚拟机的网络,确保虚拟机能访问外网。
首先要在我们的虚拟机处理器栏勾选虚拟化引擎·(必须关机状态下操作)
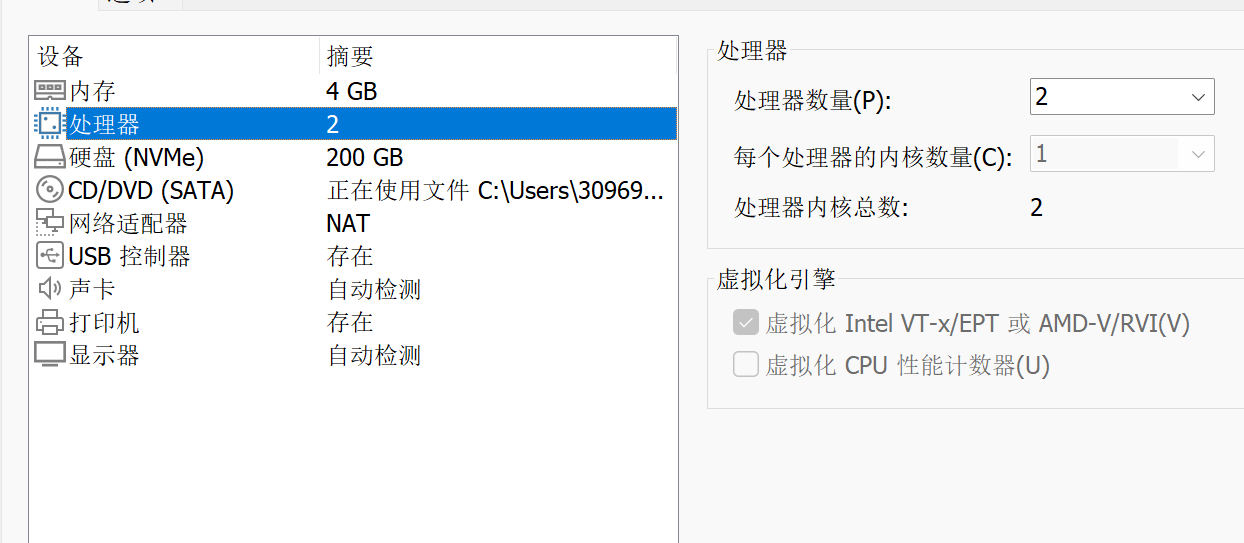
确保确实支持

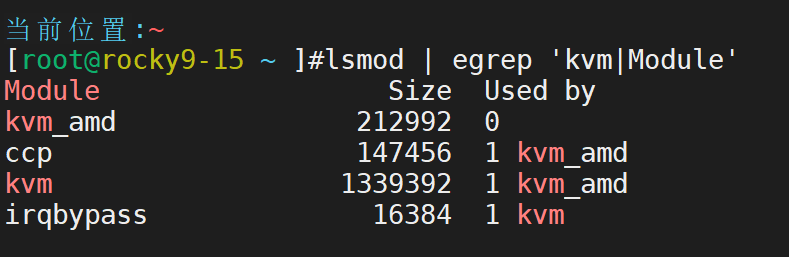
确认支持模块
安装软件

准备文件夹

查看软件状态
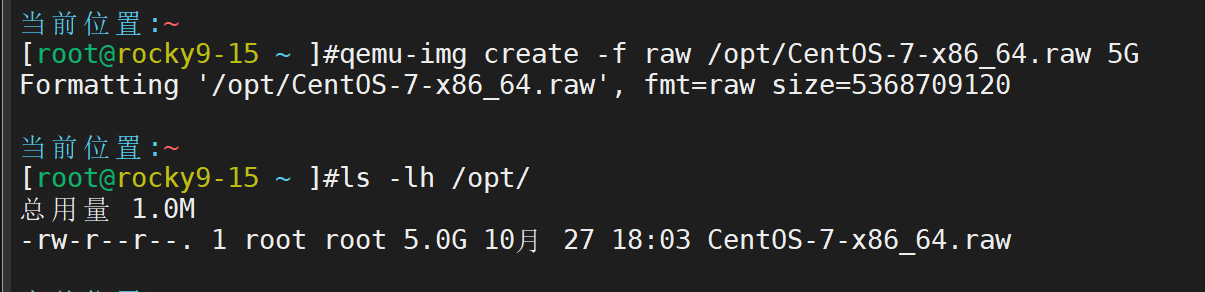
创建虚拟磁盘
创建虚拟机
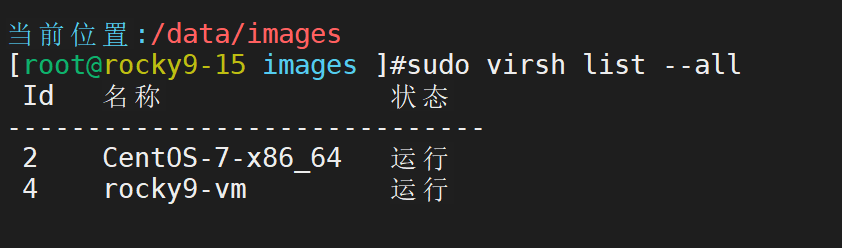
查看虚拟机状态
virsh list --all
启动虚拟机
virsh start centos-vm
控制台登录(退出按Ctrl+])
virsh console centos-vm
关机
virsh shutdown centos-vm

强制停止
virsh destroy centos-vm
重启
virsh reboot centos-vm

准备增加磁盘
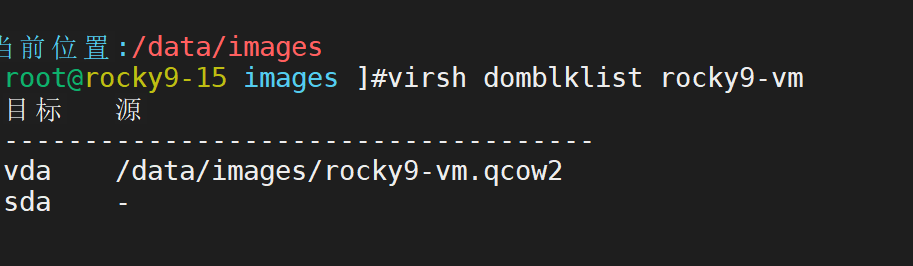

增加成功
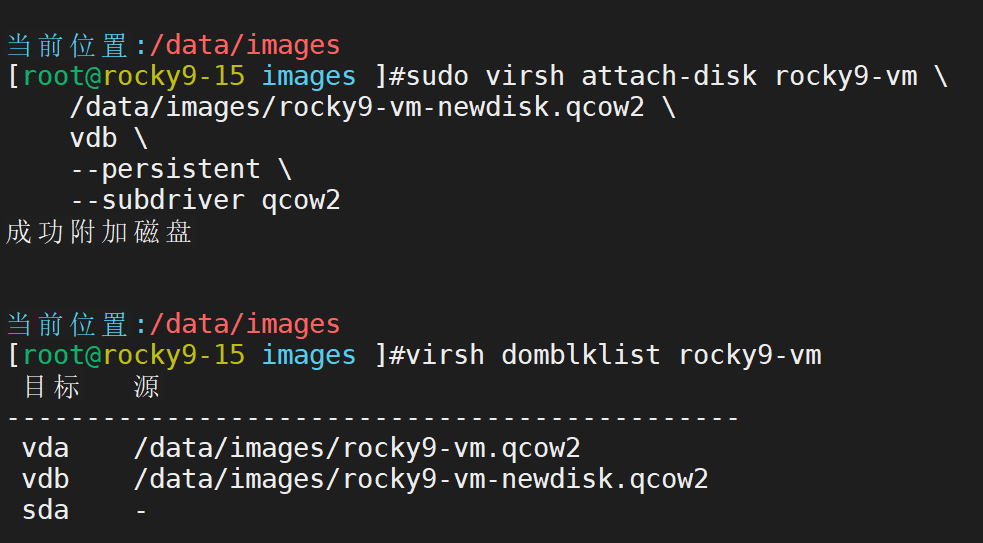
进入虚拟机内ping


