前言
上篇分享《LangGraph实战项目:从零手搓DeepResearch(三)------LangGraph多智能体搭建与部署》中,我们从零构建了一个mini版的DeepResearch应用,通过LangGraph整合了任务规划、网络搜索和报告生成三个核心智能体,实现了完整的协同工作流程,并成功部署上线。不过mini-DeepResearch毕竟只是一个练手项目,大家要真正掌握智能体构建与大模型系统开发,仅仅停留在基础层面是远远不够的。我们需要深入研读业界顶级的开源项目,了解其设计思想和技术实现。
与我们的mini版本相比,当前开源的DeepResearch类系统在架构设计和执行效果上都有着显著优势。它们不再是简单的线性工作流(问题拆解→批量搜索→问答生成),而是构建了更加复杂的多路径验证机制,能够在研究过程中进行动态校验和证据交叉验证,大幅提升了信息搜索的准确率和答案的可信度。
本篇分享笔者将以LangChain官方发布的open_deep_research项目为例,深入解析一个成熟DeepResearch智能体系统的技术架构。通过本期的实战分享大家可以学习到: (1) 复杂工作流的设计与实现。(2) 多智能体协同的精细控制。(3) 验证机制与质量保障策略 (4) 本地部署的具体步骤和应用方法。接下来笔者将详细讲解open_deep_research项目的源码分析与部署实战,大家一起来看看吧~
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前已更新22讲,正在更新实战篇,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
一、OpenDeepResearch项目简介
opendeepresearch 是 LangChain 团队开源的多功能深度研究项目模板。该项目集成了多个不同应用场景的 DeepResearch 类智能体,每个智能体都针对特定类型的研究问题进行了优化,是学习 DeepResearch 智能体构建的"葵花宝典"。
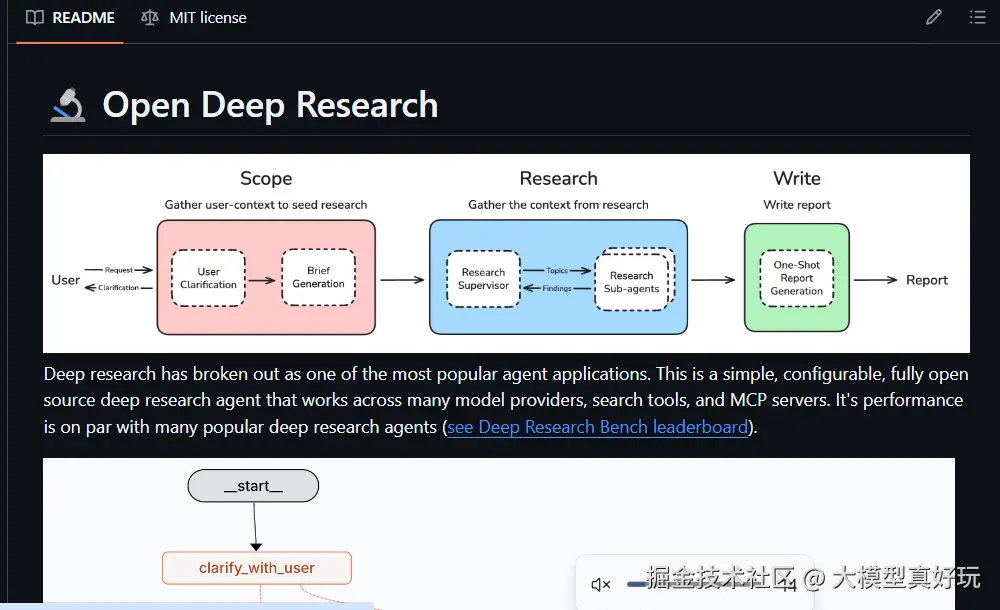
open deep researcher 旨在复现和拓展 DeepResearch 的核心能力,让用户能够使用 AI 自动化完成复杂的信息调研和报告撰写任务。用户只需输入研究主题或问题,open deep researcher便会自动生成精准的搜索查询,抓取并分析网页内容,通过多轮迭代不断完善研究成果,最终输出结构清晰的 Markdown 格式报告。与 mini 版本相比,open deepresearch 不仅能够返回原始信息,更重要的是能够人工介入信息筛选和内容整合,并通过多轮迭代自主发现知识空白并持续检索,最终最终生成的报告质量堪比专业研究员整理的成果,而非简单的信息堆砌。
二、 open deep research源码解析
OpenDeepResearch 项目提供了两种不同的实现架构:基于工作流的有向图(Graph)模式 和多智能体(Multi-Agent)模式 。这两种架构各有侧重,分别适用于不同的应用场景和需求。大家可以关注笔者的同名微信公众号:大模型真好玩 ,并私信opendeepresearch便可获得opendeepresearch项目讲解的完整代码。
2.1 工作流的有向图(Graph)模式
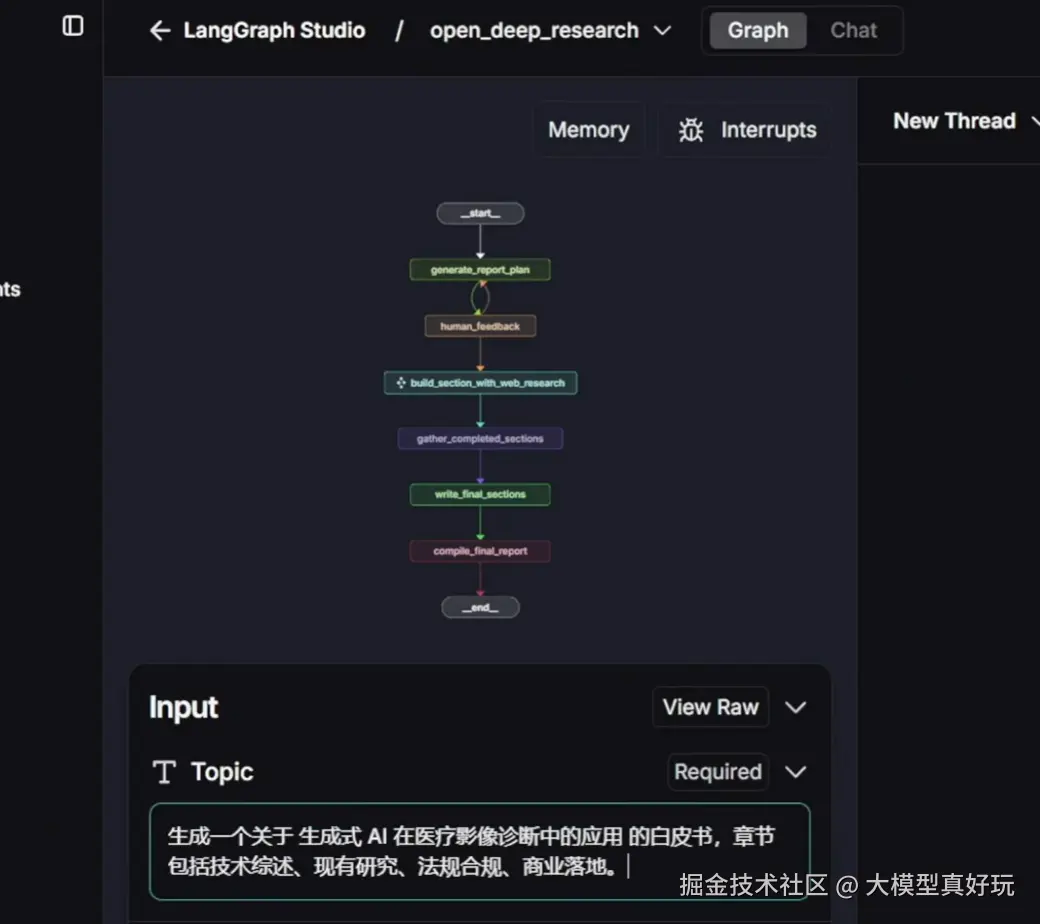
Graph 工作流模式采用规划---执行的顺序流程,将深度研究任务划分为固定阶段依次完成:首先使用"规划"大模型分析主题,生成报告的大纲和计划;然后经过人工反馈确认计划;接下来对每个章节依次进行检索和写作,每一章节都包含搜索---总结---反思的循环,确保信息充分;最后整合各章节内容并生成完整报告。其核心源代码位于 src/open_deep_research/graph.py。
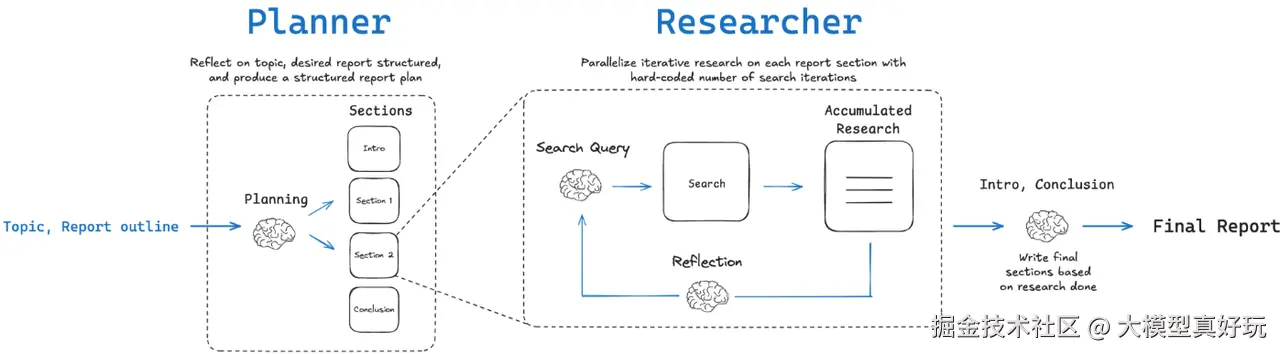
2.1.1 Graph工作流模式关键节点
- generate_report_plan
python
async def generate_report_plan(state: ReportState, config: RunnableConfig)- 工作流的首个主要步骤,基于报告主题生成初始计划
- 利用LLM创建搜索查询并获取上下文信息
- 根据网络搜索结果制定详细的章节结构
- 支持基于用户反馈重新生成计划
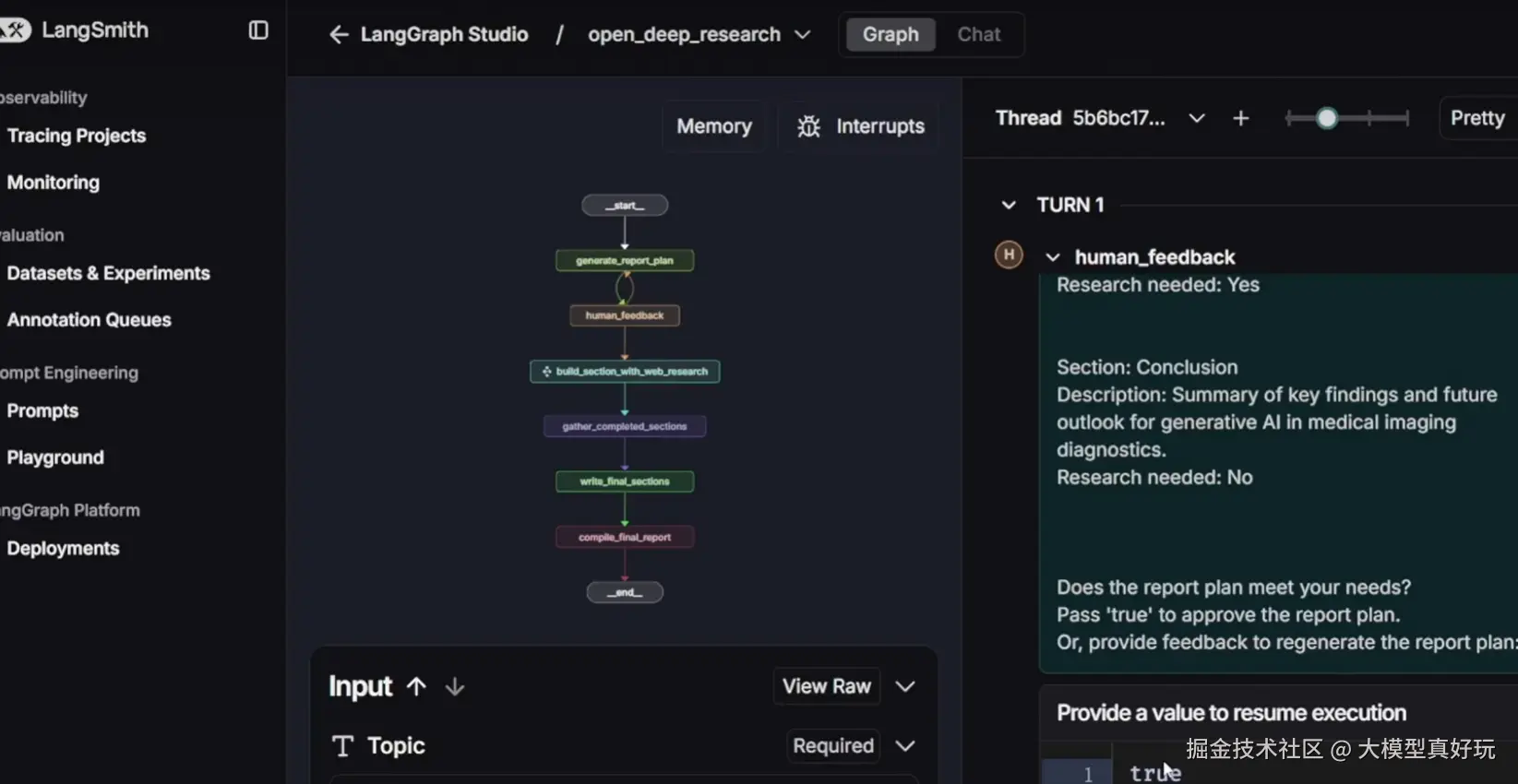
- human_feedback
python
def human_feedback(state: ReportState, config: RunnableConfig)- 交互式节点(用到interrupt, 该功能笔者LangGraph教程中并未提及,大家正好借此机会进行学习),获取用户对报告计划的反馈
- 展示当前计划供审查,通过中断机制等待用户输入
- 支持直接批准计划或提供修改意见触发重新规划
-
build_section_with_web_research
内嵌的章节构建子图,包含以下核心函数:
-
generate_queries :为特定章节生成针对性搜索查询
pythonasync def generate_queries(state: SectionState, config: RunnableConfig) -
search_web :执行网络搜索获取研究资料
pythonasync def search_web(state: SectionState, config: RunnableConfig) -
write_section :撰写章节内容,并自动评估质量以决定是否需要进一步研究
pythonasync def write_section(state: SectionState, config: RunnableConfig)
-
-
write_final_sections
python
async def write_final_sections(state: SectionState, config: RunnableConfig)- 编写不需要独立研究的章节(如总结、结论等)
- 基于已完成的研究内容进行整合撰写
- gather_completed_sections
python
def gather_completed_sections(state: ReportState)- 收集所有已完成研究的章节内容
- 为最终章节写作准备必要的上下文材料
- compile_final_report
python
def compile_final_report(state: ReportState, config: RunnableConfig)- 整合所有章节形成最终研究报告
- 可选择性地包含源材料引用,确保内容可追溯
2.1.2 Graph工作流执行流程解析
基于笔者前面对关键节点的分析,我们可以清晰地梳理出Graph工作流的完整执行流程:
核心执行阶段:
- 生成报告大纲:根据输入主题生成初步的报告结构
- 人类反馈确认:请求用户确认或提供修改意见
- 并行研究写作:对需要深入研究的章节并行执行"搜索-总结-反思"循环
- 编写静态章节:完成结论等无需额外研究的内容
- 编译最终报告:整合所有章节形成完整研究报告
架构演进亮点:
相较于我们之前实现的mini版本,Graph模式在架构上实现了重要升级:
- 意图识别与确认机制:新增用户意图识别环节,通过大纲确认确保研究方向准确
- 智能化任务分解:具备主题拆分与执行计划自动生成能力
- 迭代优化策略:采用多轮搜索迭代,在关键节点反复调用搜索引擎,持续优化内容质量
这一架构将简单的线性流程升级为具备反馈循环和并行处理能力的智能工作流,显著提升了研究报告的深度与准确性。
2.2 多智能体(Multi-Agent)模式
Multi-Agent模式并非采用顺序流程,采用监督者-研究员的多智能体协作机制,以提高调研效率。由一个监督Agent(Supervisor)负责总体规划和协调,多个研究Agent(Researcher)并行执行各章节的搜索与写作。具体而言,监督Agent首先根据用户主题拟定报告的大致章节计划,分配若干研究Agent分别处理不同的章节任务。各研究Agent接收到自己负责的章节后,并行地生成该章节的搜索查询,利用搜索工具检索资料,整理后撰写章节内容。所有章节同时开展研究,大大减少了总的报告生成时间。监督Agent在此过程中还可以提问澄清用户需求(如果启用的话),确保理解准确,然后在研究Agent完成各自章节后,监督Agent负责最后汇总各章节并撰写引言结论,组成完整报告。其核心源码位于\src\open_deep_research\multi-agent.py
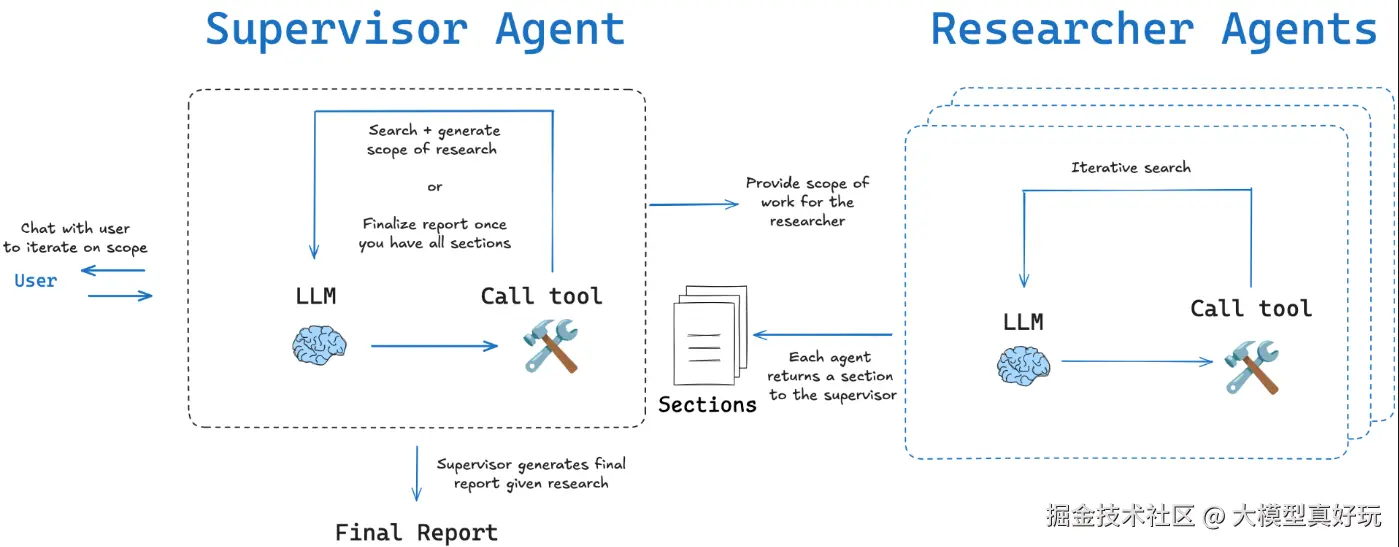
2.2.1 多智能体模式关键节点解析
基于监督者-研究员的角色定位,多智能体模式功能可分为监督者函数和研究代理函数两大类。
监督者核心函数
supervisor
python
async def supervisor(state: ReportState, config: RunnableConfig)- 接收当前状态和历史对话信息
- 加载适当的工具集供决策使用
- 调用大模型进行任务规划、结构设计和任务分配
supervisor_tools
python
async def supervisor_tools(state: ReportState, config: RunnableConfig)- 执行监督者
supervisor决策调用的各类工具 - 调用处理问题的工具,向用户提问澄清需求
- 调用处理文章引言和结论的工具
- 调用处理文章不同章节的工具调用,同时触发研究代理团队启动,将不同节的任务分给不同的研究者
- 处理搜索工具调用并收集来源信息
supervisor_should_continue
python
async def supervisor_should_continue(state: ReportState) -> str- 决策监督者代理是否继续循环执行或结束流程
- 若调用
FinishReport或无工具调用则终止流程 - 否则继续执行工具调用循环
研究者核心函数
research_agent
python
async def research_agent(state: SectionState, config: RunnableConfig)- 接收监督者分配的特定章节任务
- 加载研究所需的相关工具集
- 调用大模型执行具体的研究和写作任务
- 确保至少调用一个工具完成研究工作
research_agent_tools
python
async def research_agent_tools(state: SectionState, config: RunnableConfig)- 执行研究代理决策调用的各类工具
- 处理章节工具调用,完成指定章节的写作
- 处理搜索工具调用,获取研究所需的资料信息
- 将完成的章节内容返回给监督者代理
research_agent_should_continue
python
async def research_agent_should_continue(state: SectionState) -> str- 决策研究代理是否继续研究或完成任务
- 若调用
FinishResearch则结束返回 - 否则继续执行工具调用循环进行深入研究
2.2.2 Multi-Agent工作流执行流程解析
基于笔者前面对关键节点的分析,我们同样可以清晰地梳理出Multi-Agent工作流的完整执行流程:
Multi-Agent系统通过双层级StateGraph构建完整的工作流架构,监督者代理工作流负责整体流程协调,集成并调度多个研究代理协同工作。研究代理工作流专注于单个章节的研究与写作,形成独立的任务执行单元。同时源码中值得注意的是Send api的使用,Send api笔者也没有在基础教程之中分享过。该API的主要作用是用于在运行时根据数据(如一个列表的长度)决定需要创建多少个分支任务,而不是在构建图时预先定义。比如源码supervisor_tools函数中
pyhton
return Command(goto=[Send("research_team", {"section": s}) for s in sections_list], update={"messages": result})就是通过Send api将列表中的执行结果分发到多个research_team节点去执行,可以根据sections_list中的结果动态创建多个research_team节点。
Multi-Agent模式完全基于工具调用模式设计,使代理行为高度可控且可预测。采用模块化设计,明确划分监督者与研究者的职责边界,这使得该系统可以支持多个章节同时由不同的研究代理独立处理,最大化利用计算资源。
三、OpenDeepResearch 本地部署与实践指南
3.1 本地部署完整流程
OpenDeepResearch基于LangGraph框架开发,具备优秀的模块化设计和部署便捷性。该项目通过LangGraph实现了复杂代理流程的标准化,为开发者提供了深度研究Agent定制和扩展的高效基础。安装部署open_deep_research十分简便,笔者这里推荐大家使用源码安装。大家可关注笔者的同名微信公众号:大模型真好玩 ,并私信opendeepresearch便可获得项目源码。
3.1.1 环境准备与配置
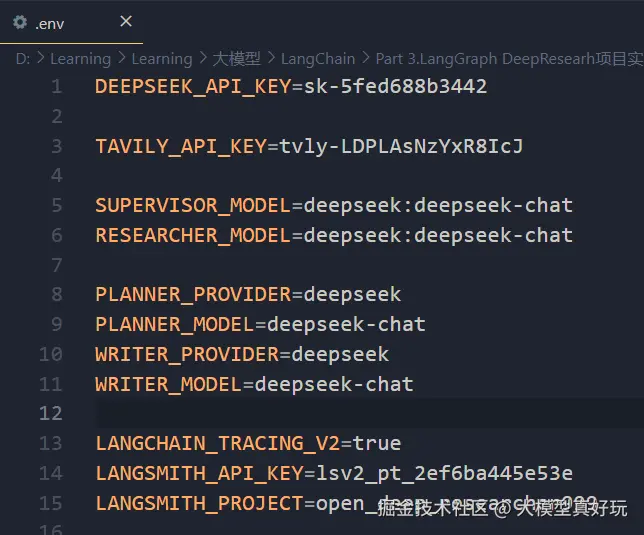
核心配置 :下载好源码后cd进入项目目录,部署前需准备以下API密钥并配置在.env文件中:
- 大模型接口:本项目使用DeepSeek作为核心大模型
- 搜索工具 :使用Tavily作为Web搜索API,注册地址:www.tavily.com/,大家可参考笔者文章深入浅出LangChain AI Agent智能体开发教程(六)---两行代码LangChain Agent API快速搭建智能体进行配置,这里不再赘述。
- 执行追踪 :配置LangSmith用于代理执行过程分析与调试,大家可参考笔者文章 深入浅出LangGraph AI Agent智能体开发教程(四)---LangGraph全生态开发工具使用与智能体部署
完整配置文件示例如下:
3.1.2 安装部署步骤
- 本次部署笔者在Windows系统上进行演示,安装
open_deep_researcher项目最好先创建一个anaconda虚拟环境并激活,然后安装open_deep_researcher项目依赖, 执行的命令如下:
python
# 创建虚拟环境
conda create -n open_deep_research python=3.12
conda activate open_deep_research
# 安装项目依赖
pip install -e .
- 安装LangGraph管理工具:
python
pip install -U "langgraph-cli[inmem]"
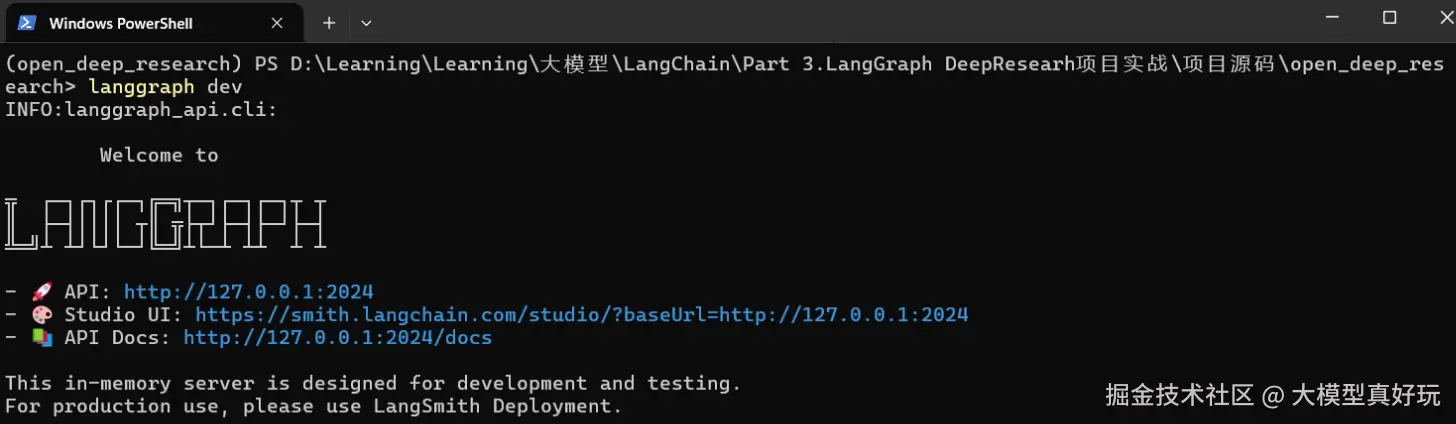
- 启动服务: 执行
langgraph dev在本地开启服务,点击命令行中的Studio UI链接即可进入深度研究助手界面。
3.2 多工作流模式详解
3.2.1 三种核心工作流
我们查看项目文件夹下的langgraph.json配置文件,可以看到系统启动时会加载三个不同的图工作流:
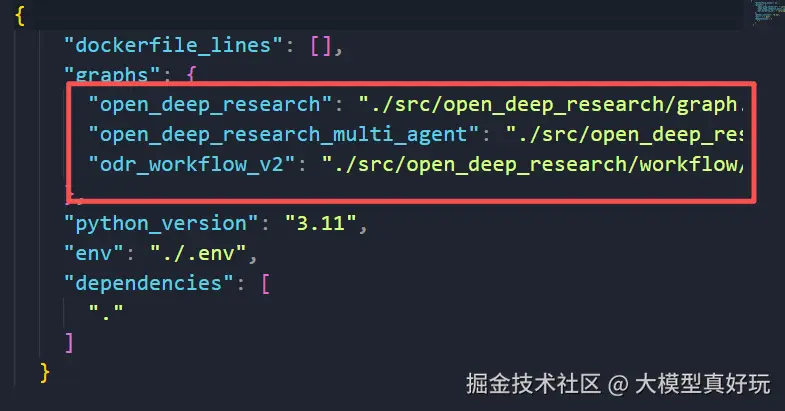
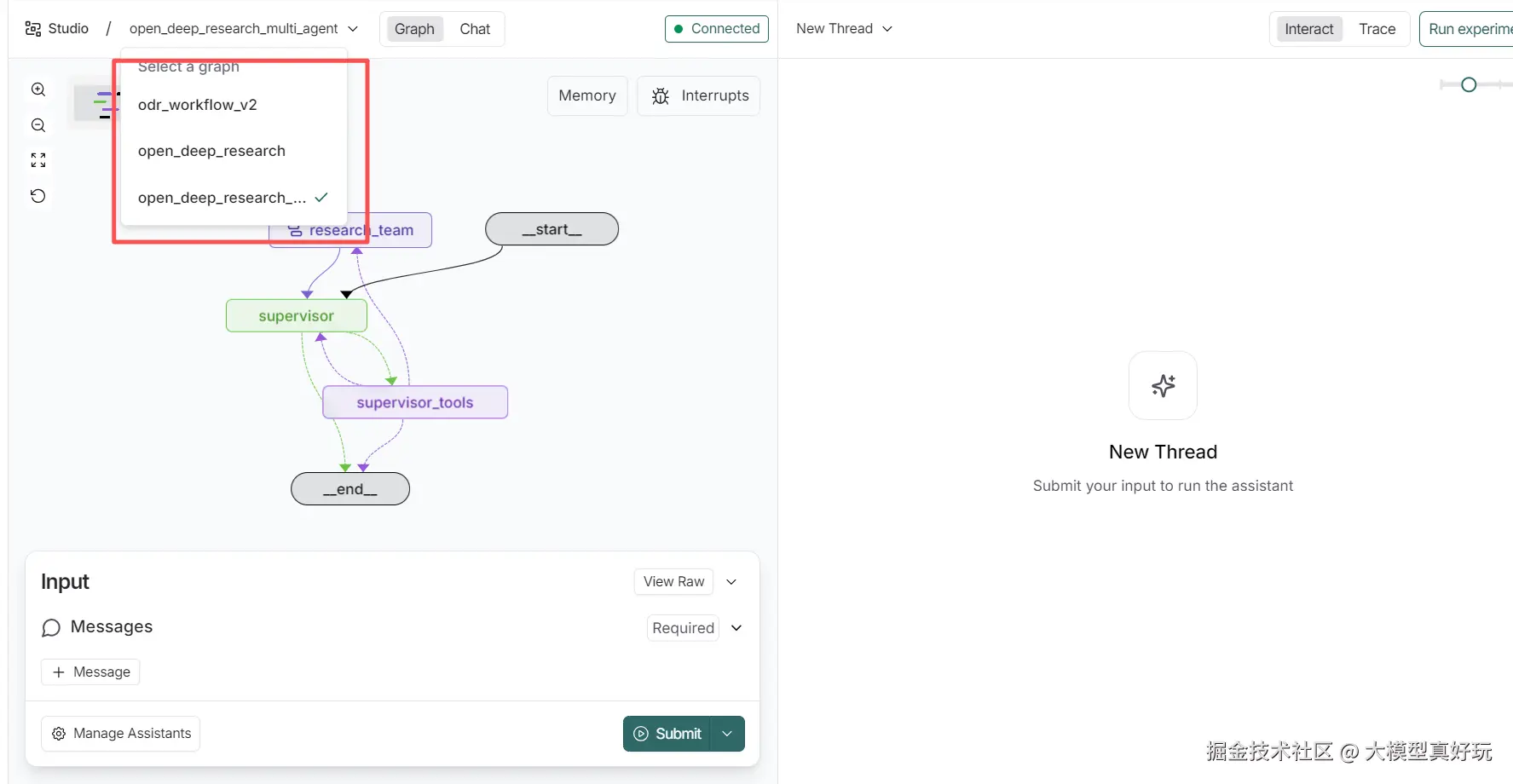
1. Graph工作流
- 架构:父-子图结构,外层控制整体流程,内层处理单个章节研究
- 流程:规划→检索→写作→自评→循环→总结的原子化控制
- 适用场景:需要深度多轮检索的市场分析、技术调研、政策研究等
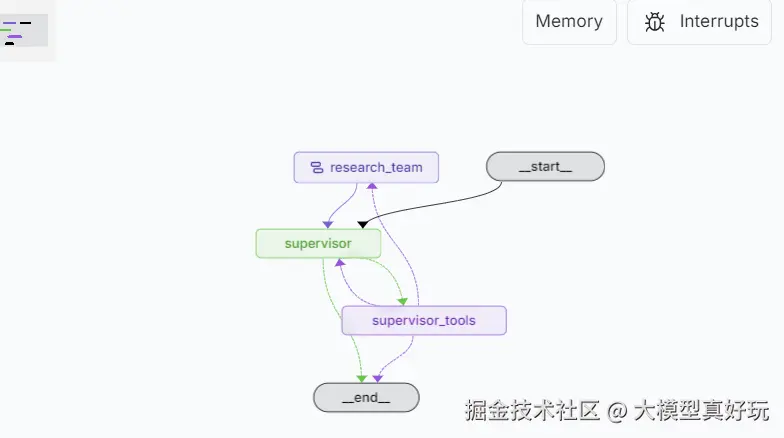
2. Multi-Agent工作流
- 架构:督导者(Supervisor) + 多研究者(Researcher)的双层智能体系统
- 特点:角色分工明确,支持多章节并行调研
- 适用场景:多维度分析任务,如技术现状、经济性分析、政策激励等并行研究
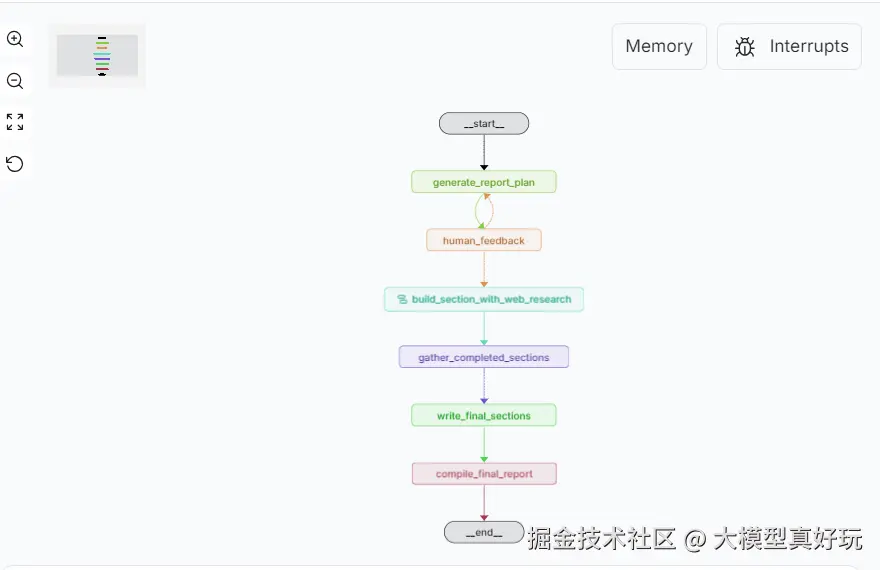
3. ODR_Workflow_V2工作流
该工作流笔者在源码分析阶段并没有分析,留给大家作为小作业自行学习~
- 架构:澄清→规划→并行研究→自评迭代→汇编的自动化报告生成
- 特点:交互式澄清机制,支持需求确认和人工审核
- 适用场景:需要前期澄清和用户审核的深度文档写作任务
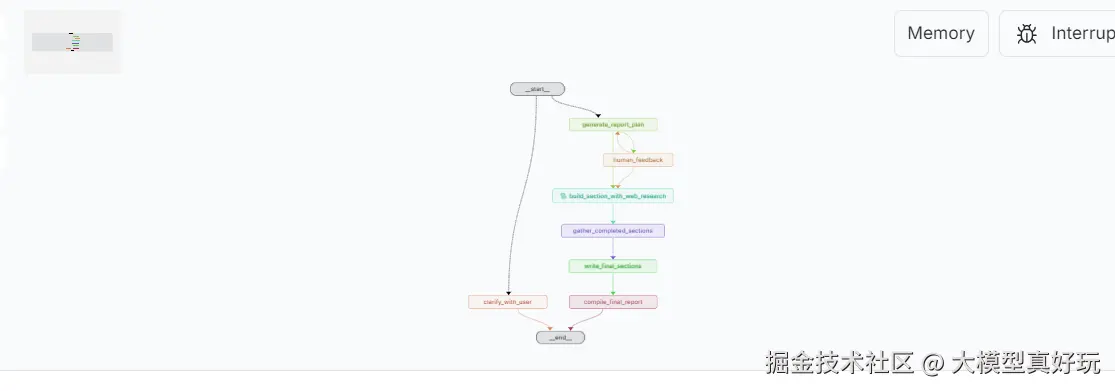
3.2.2 实际操作指南
在LangGraph Studio UI界面中,用户可以输入研究主题或问题,实时观察代理的自动检索和报告生成过程,还可以通过配置面板调整运行参数,在遇到人工操作确认可以使用JSON输入框进行流程控制(确认计划或提供修改意见),大家可以在本地部署并尝试使用不同模式完成DeepResearch专题报告的生成。
以上就是我们今天分享的全部内容~
四、总结
本篇内容深入解析了LangChain官方OpenDeepResearch项目,通过源码分析详细对比Graph工作流与Multi-Agent多智能体两种架构的设计思路与核心节点,提供从环境配置、依赖安装到本地部署的完整实践指南,帮助大家通过对复杂AI智能体系统的掌握学习智能体的构建方法,是我们LangGraph教程的完美补充!关于DeepResearch的LangGraph实战项目就到这里啦,不过这远远不是我们实战项目的终点!下一期实战项目我们就来实现当前火热的多模态RAG知识库系统,打造自己的知识管家,大家敬请期待!
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前已更新完基础知识和DeepResearch实战项目,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。