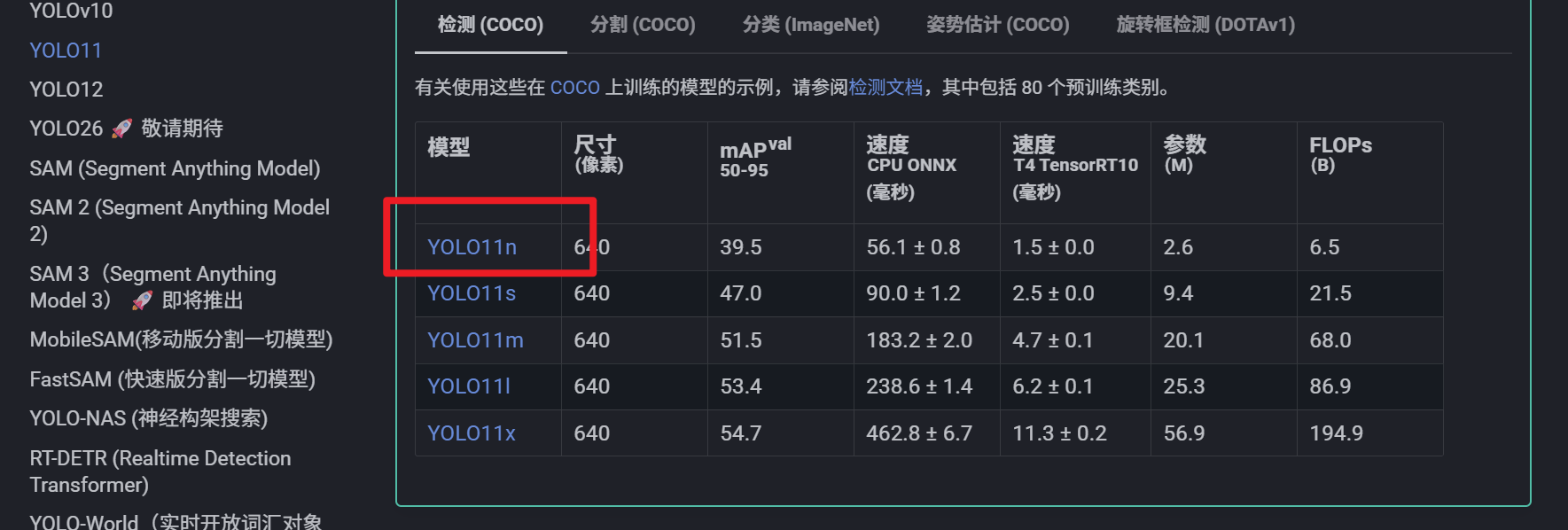
准备工作,需要下载一下yolo模型,我这里用的时yolo11,下载链接Ultralytics YOLO11 - Ultralytics YOLO 文档
将上面的文件放到文件夹里,并用vscode打开,为该项目创建自己的虚拟环境 crtl+shift+p

选择刚才创建的虚拟环境,进入终端安装所需要的包
pip install torch torchvision torchaudio
pip install ultralytics
pip install opencv-python
pip install pyautogui
pip install lap>=0.5.12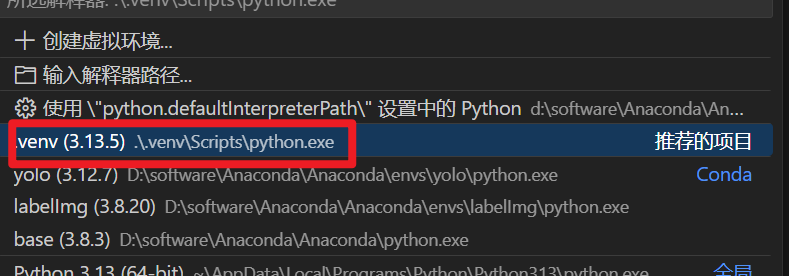
新建一个track.py文件对视频进行抽帧处理
import cv2 as cv
from ultralytics import YOLO
from time import sleep
rec = cv.VideoCapture('rec.mp4')
i=0
while True:
r,f = rec.read()
if not r:
print('没有更多的帧了')
break
if cv.waitKey(1)==ord('q'):
print('您按了q键')
break
#实际操作
i += 1
if i % 25 == 0:
cv.imwrite(f'{i}.jpg',f)
rec.release()
cv.destroyAllWindows()对抽帧的图片进行统一改名,改名网址Rename - 批量文件重命名工具
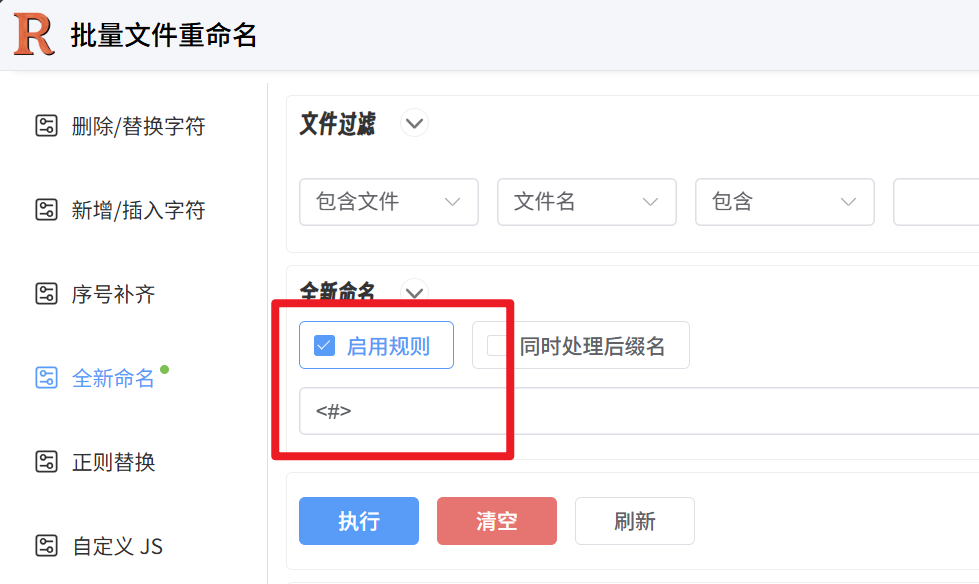
对图片进行标注 详细步骤看https://blog.csdn.net/qq_64556701/article/details/153980803?fromshare=blogdetail&sharetype=blogdetail&sharerId=153980803&sharerefer=PC&sharesource=qq_64556701&sharefrom=from_link
标注完成,将其分为训练集和验证集,其中(images和labels文件名不要进行修改)
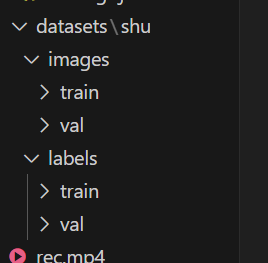
创建shu.yaml,指定训练和验证集的目录
train: datasets/shu/images/train
val: datasets/shu/images/val
names:
0: shu创建train.py进行训练
from ultralytics import YOLO
yolo = YOLO('yolo11n.pt')
yolo.train(data='shu.yaml',workers=0,epochs=300,batch=16)使用训练好的模型进行追踪
import cv2 as cv
from ultralytics import YOLO
import pyautogui as pg
import numpy as np
yolo = YOLO('shu.pt')
while True:
if cv.waitKey(1) == ord('q'):
break
shot = pg.screenshot()
shot_np = np.array(shot)
shot_np = shot_np[:,:,::-1]
result = yolo.track(shot_np,persist=True)
for i in result[0].boxes.xywh:
pos = (i[0],i[1])
pg.click(pos)
cv.waitKey(0)
cv.destroyAllWindows()中间有延时,可能会导致有多个地鼠时,会来不及,可以进行下面优化,提高准确性能
import cv2 as cv
from ultralytics import YOLO
import pyautogui as pg
import numpy as np
import time
yolo = YOLO('shu.pt')
pg.FAILSAFE = False # 禁用安全退出,提高点击速度
pg.PAUSE = 0 # 移除pyautogui的默认延迟
# 设置鼠标移动参数
pg.MINIMUM_DURATION = 0
pg.MINIMUM_SLEEP = 0
while True:
if cv.waitKey(1) == ord('q'):
break
start_time = time.time()
# 截图
shot = pg.screenshot()
shot_np = np.array(shot)
shot_np = shot_np[:,:,::-1]
# 推理检测
result = yolo.track(shot_np, persist=True)
# 批量处理所有检测到的地鼠
if result[0].boxes is not None and len(result[0].boxes) > 0:
# 获取所有地鼠中心坐标
positions = []
for i in result[0].boxes.xywh:
x, y = int(i[0]), int(i[1])
positions.append((x, y))
# 快速点击所有检测到的位置
for pos in positions:
# 直接移动并点击,不添加延迟
pg.moveTo(pos[0], pos[1], duration=0)
pg.click()
# 控制帧率,避免过度占用CPU
elapsed = time.time() - start_time
if elapsed < 0.05: # 最小20FPS
time.sleep(0.05 - elapsed)
cv.destroyAllWindows()