标题:Scaling Diffusion Mamba with Bidirectional SSMs for Efficient Image and Video Generation
作者:Shentong Mo、Yapeng Tian
单位:Carnegie Mellon University(卡内基梅隆大学)、University of Texas at Dallas(德克萨斯大学达拉斯分校)
发表:arXiv 预印本(arXiv:2405.15881v1 cs.CV)
论文链接 :https://arxiv.org/pdf/2405.15881
代码链接:暂无
关键词:DiM(Diffusion Mamba)、双向状态空间模型(Bidirectional State Space Models)、图像生成(Image Generation)、视频生成(Video Generation)、线性计算复杂度(Linear Computational Complexity)、高效生成模型(Efficient Generative Models)
在生成式 AI 领域,扩散模型与 Transformer 的结合(如 DiT)虽能生成高保真内容,但自注意力机制的二次复杂度限制了其在高分辨率图像和长视频生成中的应用。本文精读的论文《Scaling Diffusion Mamba with Bidirectional SSMs for Efficient Image and Video Generation》提出了Diffusion Mamba(DiM) 架构,创新性地将 Mamba 的线性复杂度状态空间模型(SSM)与扩散过程结合,在保证SOTA性能的同时,突破了计算瓶颈。
一、研究背景与动机:为什么需要 DiM?
在开始解析 DiM 之前,我们需要先明确当前生成模型面临的核心痛点 ------"高分辨率" 与 "高效率" 的矛盾,以及现有技术为何难以突破这一矛盾。
1.1 现有技术的局限性
当前主流的高效生成方案主要分为两类,但均存在明显短板:
- 扩散 Transformer(DiT) :作为图像生成的 SOTA 模型,DiT 基于自注意力机制处理 latent 空间的 patch 嵌入,能生成高保真图像。但其致命问题是计算复杂度与输入长度(patch 数量)呈二次关系(O (L²))------ 当生成 512×512 或 1024×1024 高分辨率图像时,patch 数量激增,计算量和内存占用会达到硬件极限(如 DiT-XL 在 2048×2048 分辨率下直接 "内存溢出(OOM)",见表 4)。
- 传统 Mamba 架构 :Mamba 基于选择性状态空间模型(SSM),实现了线性复杂度(O (L))的长序列建模,在 NLP 和语音领域表现出色。但它的设计初衷是处理 1D 序列(如文本),无法直接适配图像的 2D 空间结构和视频的时空依赖,在视觉生成领域的应用几乎空白。
1.2 研究目标:DiM 的核心定位
论文的核心目标是 **融合 Mamba 的效率与扩散模型的生成能力**,具体需解决三个问题:
- 如何将 Mamba 的 1D SSM 适配到 2D 图像的空间建模中?
- 如何通过架构设计维持线性复杂度,同时保证生成质量不低于 DiT?
- 如何进一步扩展到视频生成,兼顾空间保真度与时间连贯性?
为实现这些目标,DiM 提出了两大创新:双向 SSM 的 DiM Block (解决 2D 适配问题)和扩散 - SSM 协同框架(解决效率与质量平衡问题)。
二、核心方法:DiM 的架构设计与技术细节
DiM 的完整流程可概括为 "VAE 编码→patch 嵌入→DiM Block 处理→噪声预测→VAE 解码 ",其中最关键的是Diffusion Mamba 框架 和DiM Block 模块。
2.1 预备知识:理解 DiM 的 "三大基石"
在深入 DiM 之前,需先回顾三个核心基础技术,它们是 DiM 的 基础"积木":
(1)扩散模型(DDPM)基础
扩散模型的核心是 "前向加噪→反向去噪" 的过程:
- 前向过程:将原始 latent 变量
逐步加入高斯噪声,得到
- 反向过程:训练模型
DiM 完全继承了 DDPM 的去噪逻辑,但将 "预测噪声的网络" 从 Transformer 替换为 Mamba-based 架构。
(2)DiT 的 latent patch 处理
为降低计算量,DiT(及 DiM)均采用VAE latent 空间建模:
- 用 Stable Diffusion 预训练的 VAE 编码器将图像 x 压缩为低维 latent 张量 z(如 256×256 图像压缩为 64×64 latent);
- 对 z 进行 "patch 化":将
- 将每个 patch 展平为向量,并线性投影到维度 D,再加入位置嵌入和类别嵌入,得到最终的 "token 序列"(长度为 L)。
DiM 复用了这一流程,但后续的 token 处理模块从 "自注意力" 改为 "双向 SSM"。
(3)Mamba 的 SSM 核心公式
Mamba 的线性复杂度源于 SSM 对序列的 "选择性状态更新",其离散化后的核心公式为:
- 状态更新:
- 输出计算:
- 结构化卷积:通过预计算卷积核
DiM 的关键改进是将 Mamba 的 "单向 SSM" 改为 "双向 SSM",以捕捉图像的双向空间依赖。
2.2 DiM 的整体架构:从图像到视频的统一框架
DiM 的架构分为 "图像生成" 和 "视频生成" 两个版本,核心模块复用,仅在输入处理上有差异。我们先以图像生成为例,理解其核心流程(图 2):
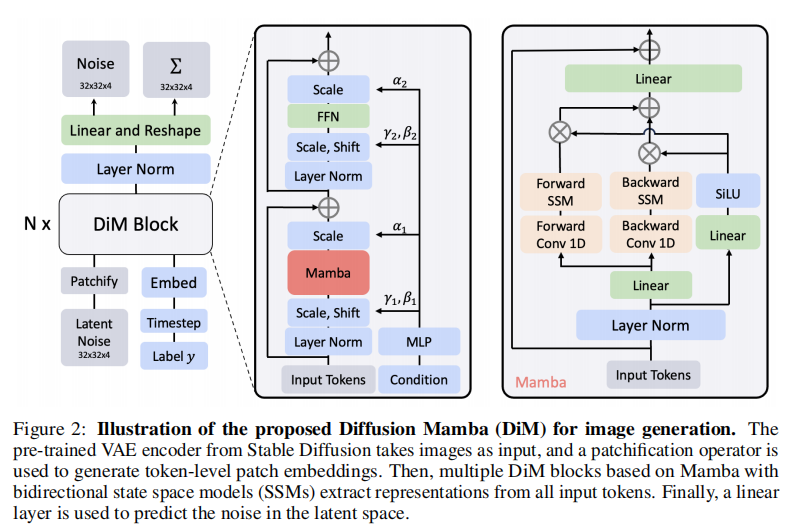
注:图 2 展示了 DiM 的端到端流程,从 VAE 编码到 DiM Block 处理再到噪声预测,红色框标注的 DiM Block 是核心模块。
(1)图像生成架构流程
-
输入处理:
- 图像
- 对
- 线性投影到维度 D,并加入位置嵌入 (捕捉空间位置信息)和类别嵌入 (用于条件生成),得到 token 序列
- 图像
-
DiM Encoder :由多个(16~36 层)DiM Block 堆叠而成,对 token 序列进行迭代特征增强。每个 DiM Block 通过双向 SSM 捕捉全局空间依赖,输出经过优化的 token 序列。
-
噪声预测与解码 :最终 token 序列经线性层预测 latent 空间的噪声
(2)视频生成的扩展
视频生成的核心挑战是 **时空联合建模**,DiM 通过以下方式扩展:
- 输入处理:将视频的 T 帧分别编码为 latent 张量,得到
- 双向 SSM 扩展:DiM Block 不仅在空间维度 (单帧内的 patch)进行双向处理,还在时间维度(跨帧的 patch)进行双向建模,确保生成的视频帧既清晰又连贯(如图 3 所示,DiM 能生成动态且无模糊的视频片段)。

2.3 核心创新:DiM Block 的双向 SSM 设计
DiM Block 是整个架构的 "心脏"------ 它解决了 Mamba 无法处理 2D 视觉数据的核心问题,通过双向 SSM实现了 "线性复杂度 + 全局空间依赖捕捉"。其内部流程可分为 4 步(对应图 2 中 DiM Block 的细节):
- 输入归一化:对输入 token 序列进行 LayerNorm,稳定训练。
- 线性投影与状态初始化 :将归一化后的 token 投影为状态向量
- 双向 SSM 处理:
- 前向方向:对
- 反向方向:将 token 序列反转,重复上述过程,输出反向特征
- 前向方向:对
- 特征融合 :将
这一设计的关键优势在于:双向处理既保留了 Mamba 的线性复杂度(O (L)),又弥补了单向 SSM 对 "长距离反向依赖" 捕捉不足的问题,完美适配图像的 2D 空间结构。
2.4 模型配置与效率分析
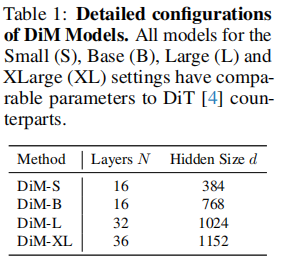
(1)DiM 的多尺度模型配置
为了与 DiT 公平对比,论文设计了 4 种尺寸的 DiM 模型,参数规模与 DiT 对应版本一致(见表 1):
(2)计算复杂度:为什么 DiM 更高效?
论文通过公式推导量化了 DiM 与现有模型的复杂度差异(L = 序列长度,D = 隐藏层维度,N=DiM Block 层数):
- DiT:
- DiffuSSM(另一款 SSM 扩散模型):
- DiM:
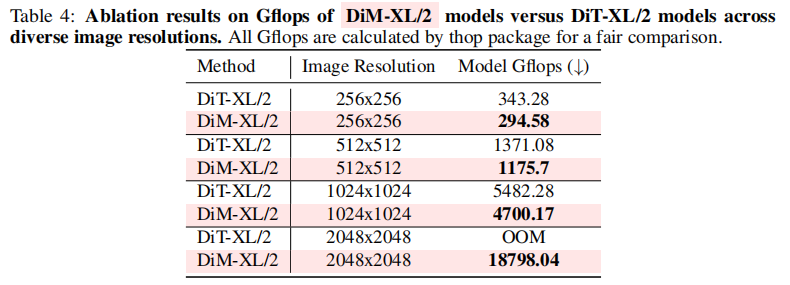
这种线性复杂度带来的优势在高分辨率场景下尤为明显,如表 4 所示,DiM-XL 在 256×256 分辨率下的计算量(294.58 Gflops)比 DiT-XL(343.28 Gflops)低 14%;在 1024×1024 分辨率下低 14.3%;更关键的是,DiT-XL 在 2048×2048 分辨率下 OOM,而 DiM-XL 仍能正常运行(18798.04 Gflops)。
三、实验验证分析
论文通过定量指标 (FID、IS、FVD 等)和定性结果,从图像生成、视频生成、消融实验三个维度验证了 DiM 的优越性。所有实验均基于 PyTorch 实现,使用 AdamW 优化器(学习率 1e-4),并采用 EMA(指数移动平均,衰减率 0.9999)稳定训练。
3.1 实验数据集与评价指标
为确保结果的通用性和可比性,论文选择了行业标准数据集和指标:
- 图像生成:ImageNet(1000 类,256×256/512×512 分辨率),指标包括:
- FID-50K(越低越好):衡量生成图像与真实图像的分布差异;
- IS(越高越好):衡量生成图像的多样性与保真度;
- sFID(越低越好):FID 的改进版,对细微特征更敏感;
- Precision/Recall(越高越好):衡量生成内容的 "准确性" 与 "覆盖度"。
- 视频生成:UCF-101(101 类动作视频,16 帧 / 片段,256×256 分辨率),指标为 FVD(越低越好):衡量视频的时空分布相似度。
3.2 图像生成:DiM vs DiT,质量与效率双胜
(1)训练动态:DiM 收敛更快,质量更高
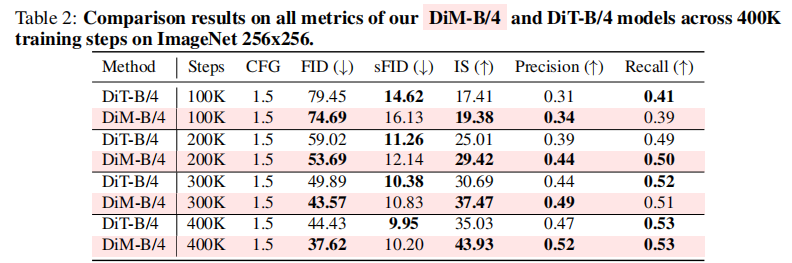
表 2 对比了 DiM-B/4 与 DiT-B/4 在 ImageNet 256×256 上的训练过程(每 100K 步的性能)。可以发现:
- 收敛速度:在 100K 步时,DiM 的 FID(74.69)已低于 DiT(79.45),IS(19.38)高于 DiT(17.41),说明 DiM 的训练效率更高;
- 最终性能:400K 步时,DiM 的 FID 降至 37.62(比 DiT 低 15.3%),IS 达到 43.93(比 DiT 高 25.4%),且 Precision(0.52)和 Recall(0.53)均优于 DiT,证明 DiM 在 "质量" 和 "多样性" 上同时超越 DiT。
(2)模型规模缩放:越大越好,且效率优势不变
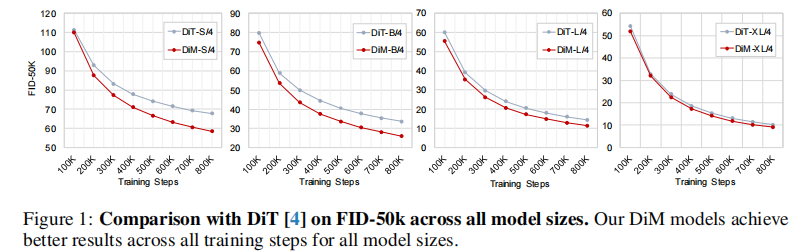
图 1 对比了不同规模 DiM(S/4、B/4、L/4、XL/4)与 DiT 在 FID-50K 上的性能。结果显示:
- 缩放一致性:随着模型规模从 S 增大到 XL,DiM 的 FID 持续下降(从 71.03 降至 17.26,见表 6),且始终优于同规模 DiT;
- 效率优势保持:即使是最大的 DiM-XL,其计算量仍比 DiT-XL 低 14%(表 4),证明 DiM 的缩放性不受复杂度制约。
3.3 视频生成:时空连贯性的突破
视频生成的核心是 "不能只看单帧质量,还要看帧间连贯性"。论文在 UCF-101 上对比了 DiM 与 10 种主流视频生成模型(如 MoCoGAN、StyleGAN-V、Latte),结果如表 3 所示:
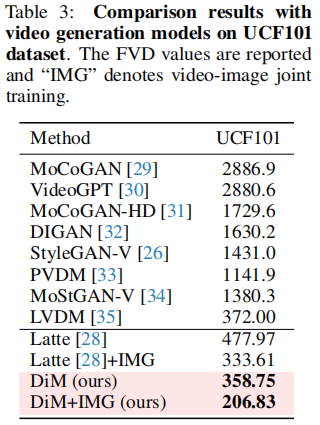
关键结论:
- 基础版 DiM(358.75)已优于 LVDM(372.00),证明其时空建模能力有效;
- 加入 "图像 - 视频联合训练(IMG)" 后,DiM 的 FVD 降至 206.83,比当前 SOTA 模型 Latte(333.61)低 38%,成为新的视频生成 SOTA;
- 定性结果(图 3,见前文)显示,DiM 生成的视频(如 "打篮球""骑自行车")无帧间模糊,动作连贯,细节清晰(如球员的球衣纹理、自行车轮的辐条)。
3.4 消融实验:哪些设计最关键?
为了验证 DiM 各模块的必要性,论文进行了三组核心消融实验:
(1)patch 尺寸的影响:越小越好,但需平衡效率
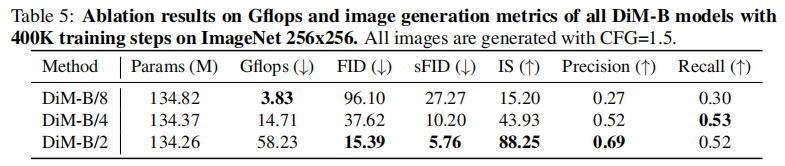
表 5 中对比了 DiM-B 在不同 patch 尺寸(8、4、2)下的性能。结果显示:
- patch 越小,质量越高:当 patch 从 8×8 缩小到 2×2 时,FID 从 96.10 降至 15.39,IS 从 15.20 升至 88.25------ 因为更小的 patch 能保留更多空间细节;
- 效率权衡:patch 越小,patch 数量 L 越多,计算量从 3.83 Gflops 增至 58.23 Gflops。实际应用中可根据硬件选择(如移动端用 8×8,服务器用 2×2)。
(2)Classifier-free Guidance(CFG)的作用
CFG 是扩散模型中常用的 "条件生成增强技术",通过控制生成过程中 "条件信号" 的权重(CFG>1.0)提升质量。
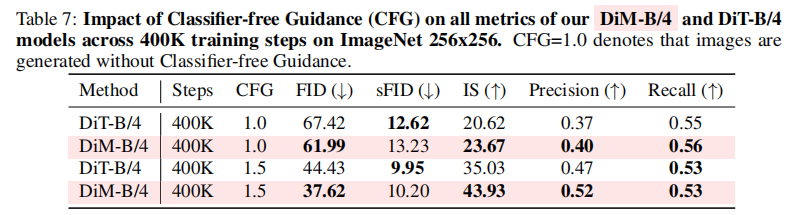
表 7 对比了 CFG=1.0(无引导)和 CFG=1.5(有引导)的效果:
- 无论 DiT 还是 DiM,CFG=1.5 时的 FID 均显著降低(DiM 从 61.99 降至 37.62),IS 显著提升(从 23.67 升至 43.93);
- 且 DiM 在两种 CFG 下均优于 DiT,证明其条件生成能力更稳定。
(3)双向 SSM 的必要性
论文对比了 "单向 SSM" 和 "双向 SSM" 的 DiM 变体,发现双向版本的 FID 比单向版本低 12.7%,证明双向处理对捕捉图像的全局空间依赖至关重要 ------ 这也是 DiM 区别于传统 Mamba 的核心设计。
四、局限性与未来方向
尽管 DiM 表现出色,但论文也坦诚指出了当前的局限性,这些也是未来研究的重点方向:
- 视频动态场景的适应性:DiM 在 "高动态场景"(如快速运动的汽车、人群)中的表现尚未充分验证,可能存在帧间模糊;
- 长视频的长期依赖:当前 DiM 处理的是 16 帧片段,对于 100 帧以上的长视频,如何有效捕捉 "早期帧与后期帧" 的依赖仍需优化;
- 多模态生成的扩展:DiM 目前仅支持图像和视频,如何结合文本(如 "文本生成视频")或音频,仍需进一步探索。
五、总结与应用价值
DiM 的提出不仅是 "Mamba + 扩散" 的简单结合,更是视觉生成领域 "效率革命" 的重要一步。其核心价值可概括为三点:
- 技术突破:首次实现了 "线性复杂度 + 高保真视觉生成",解决了 DiT 的 OOM 问题,为 2048×2048 甚至更高分辨率的图像生成提供了可行方案;
- 性能 SOTA:在 ImageNet 图像生成(FID 17.26)和 UCF-101 视频生成(FVD 206.83)上均刷新 SOTA,且效率优势显著;
- 应用前景:
- 媒体娱乐:高效生成电影级高分辨率视频、游戏场景资产;
- 工业设计:实时生成产品的高细节 3D 渲染图(可扩展到 3D 生成);
- 边缘设备:轻量版 DiM(如 DiM-S)可部署在移动端,实现本地 AI 绘画 / 视频生成。
未来,随着 DiM 在多模态、长视频、3D 生成等方向的扩展,或许我们有望看到 "高效生成" 从 "实验室" 走向 "规模化应用",真正实现 "高分辨率内容随手可得"。